全文链接:https://tecdat.cn/?p=38026
分析师:Fanghui Shao
在当今金融领域,风险管控至关重要。无论是汽车贷款违约预测、银行挖掘潜在贷款客户,还是信贷风控模型的构建,以及基于决策树的银行信贷风险预警,都是金融机构面临的关键挑战(点击文末“阅读原文”获取合集完整代码数据)。
相关视频
本银行信贷风控专题合集将通过代码和数据案例深入探讨这些金融场景中的问题与解决方案,通过对数据的深入分析、模型的构建与优化,为金融机构提供有效的风险管控策略,以促进金融市场的稳定与健康发展。
汽车贷款违约预测
作为违约预测类项目,本项目同样拥有数据不均衡的问题,即违约的数据相较于不违约的数据占比较小。此外,若不对数据进行深度理解、处理,模型的训练结果十分糟糕,F1分数仅有0.01。
解决方案
任务/目标
本项目以F1分数和准确率为评判标准,通过对数据的处理,机器学习模型的训练,尽可能提高违约预测的有效性。
数据预处理
 查看数据的分布情况,对ID等无效特征进行剔除。
查看数据的分布情况,对ID等无效特征进行剔除。
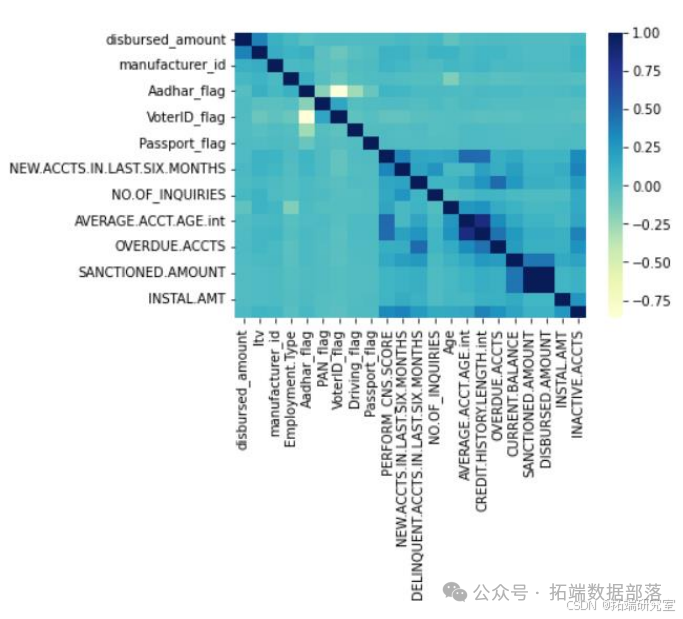
通过查看特征之间的相关性,去掉与其他特征相关性95%以上的特征,避免多重共线性。
对于形式为“X年X月”的特征,转换为月份数,以此将字符串数据转换为数值型数据。

对于文字类数据,通过对各个种类的理解用数字划分信用等级,数字越高代表借款人信用记录越好。
特征包含了主要账户和次要账户的各种信息,此处将两个账户的信息合并(例如:将主要账户余额、第二账户余额合并)。
由于很多特征对于大部分借款人来说是0,因此新增一个特征,记录每个借款人之前所有特征中数值为0的个数。
以上例举的只是部分特征。
构造
以上说明了如何抽取相关特征,我们大致有如下训练样本(只列举部分特征)。
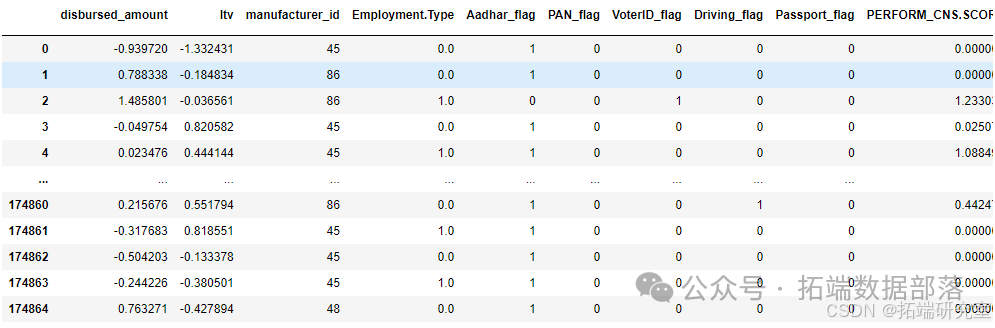
划分训练集和测试集
考虑到最终模型会预测将来的某时间段的销量,为了更真实的测试模型效果,切分训练集和验证集。具体做法如下:利用train\_test\_split()函数进行训练集、验证集划分,将30%的数据作为验证集,用于对机器学习模型调参。
建模
线性模型:利用AWS Sagemaker中的LinearLearner模型作为基准,通过对XGBoost模型的训练,调参以得到更好的预测效果。
XGBoost:
XGBoost是boosting算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为XGBoost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。
模型优化
优化方法:参数调参
结果

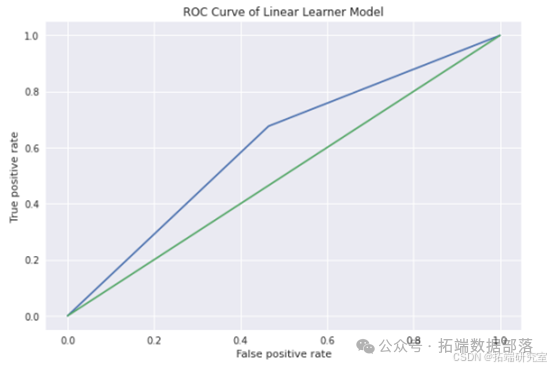
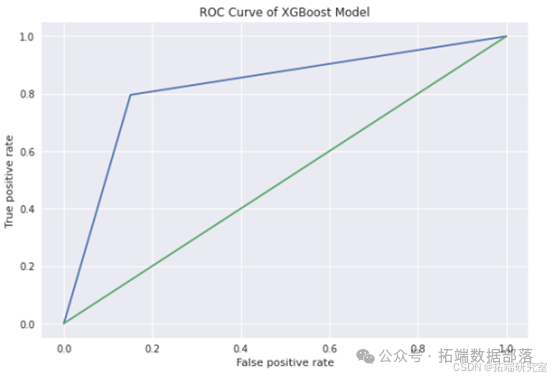
在此案例中,通过对数据的处理,即使最基本的线性模型也有0.6的F1分数,比最初的0.01有了大幅提高。此外,通过利用AWS Sagemaker的Hyperparameter Tuning相关函数,对XGBoost模进行调参、训练,最终F1结果达到了0.8以上,有了显著提升。对汽车贷款违约预测有效性有了大幅提高。
点击标题查阅往期内容

PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像

左右滑动查看更多
01
02

03
04

Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户|附数据代码
最近我们被客户要求撰写关于银行拉新活动的研究报告,包括一些图形和统计输出。
项目背景:银行的主要盈利业务靠的是贷款,这些客户中的大多数是存款大小不等的责任客户(存款人)。银行拥有不断增长的客户
该银行希望增加借款人(资产客户),开展更多的贷款业务,并通过贷款利息赚取更多利润。因此,银行希望将负债的客户转换为个人贷款客户。(同时保留他们作为存款人)。该银行去年针对负债客户开展的一项活动显示,成功实现了9%以上的成功转化率。该部门希望建立一个模型,来帮助他们确定购买贷款可能性更高的潜在客户。可以增加成功率,同时降低成本。
数据集
下面给出的文件包含5000个客户的数据 ( 查看文末了解数据获取方式 ) 。数据包括客户人口统计信息(年龄,收入等),客户与银行的关系(抵押,证券账户等)以及客户对上次个人贷款活动的因变量(个人贷款)。在这5000个客户中,只有480个(= 9.6%)接受了先前活动中提供给他们的个人贷款
data.head()
data.columns
属性信息
属性可以相应地划分:
变量 ID 一个人的客户ID与贷款之间没有关联,也无法为将来的潜在贷款客户提供任何一般性结论。我们可以忽略此信息进行模型预测。
二进制类别具有五个变量,如下所示:
个人贷款-该客户是否接受上一个广告系列提供的个人贷款? 这是我们的目标变量
证券帐户-客户在银行是否有证券帐户?
CD帐户-客户在银行是否有存款证明(CD)帐户?
网上银行-客户是否使用网上银行?
信用卡-客户是否使用银行发行的信用卡?
数值变量如下:
年龄-客户的年龄
工作经验
收入-年收入(元)
CCAvg-平均信用卡消费
抵押-房屋抵押价值
有序分类变量是:
家庭-客户的家庭人数
教育程度-客户的教育程度
标称变量是:
ID
邮政编码
data.shape

# 文件中没有列有空数据data.apply(lambda x : sum(x.isnull()))


两两变量散点图

年龄 特征通常是分布的,大多数客户年龄在30岁到60岁之间。
经验 大多分布在8年以上经验的客户。这里的 平均值 等于中 位数。有负数 。这可能是数据输入错误,因为通常无法衡量负数的工作经验。我们可以删除这些值,因为样本中有3或4条记录。
收入出现 正偏斜。大多数客户的收入在45,000到55K之间。我们可以通过说平均值 大于 中位数来确认这一点
CCAvg 也是一个正偏变量,平均支出在0K到10K之间,大多数支出不到2.5K
抵押 70%的人的抵押贷款少于4万。但是最大值为635K
家庭和教育变量是序数变量。家庭分布均匀
有52条记录经验为负数。在进一步进行之前,我们需要对这些记录进行清理
有52条负数经验的记录

以下代码执行以下步骤:
对于具有ID的记录,获取
Agecolumn的值对于具有ID的记录,获取
Educationcolumn的值从具有正数经验的记录的数据框中过滤符合以上条件的记录,并取中位数
将中位数填充原本负数经验的位置
data.loc\[np.where(\['ID'\]==id)\]\["Education"\].tolist()\[0\]df_filtered\['Experience'\].median()# 检查是否有负数经验的记录data\[data\['Experience'\] < 0\]\['Experience'\].count()
``````
收入和教育对个人贷款的影响

观察 :看来教育程度为1的客户收入更高。但是,接受了个人贷款的客户的收入水平相同

推论 :从上图可以看出,没有个人贷款的客户和拥有个人贷款的客户的抵押贷款较高。

观察 :大多数没有贷款的客户都有证券账户

观察:家庭人数对个人贷款没有任何影响。但是似乎3岁的家庭更有可能借贷。考虑未来的推广活动时,这可能是一个很好的观察结果。

观察:没有CD帐户的客户,也没有贷款。这似乎占多数。但是几乎所有拥有CD帐户的客户也都有贷款


观察:该图显示有个人贷款的人的信用卡平均费用更高。平均信用卡消费中位数为3800元,表明个人贷款的可能性更高。较低的信用卡支出(中位数为1400元)不太可能获得贷款。这可能是有用的信息。

观察 上图显示与经验和年龄呈正相关。随着经验的增加,年龄也会增加。颜色也显示教育程度。四十多岁之间存在差距,大学以下的人也更多
# 与热图的关联性corr = data.corr()plt.figure(figsize=(13,7))# 创建一个掩码,以便我们只看到一次相关的值a = sns.heatmap(corr,mask=mask, annot=True, fmt='.2f')
观察
收入和CCAvg呈中等相关。
年龄和工作经验高度相关
看下面的图,收入低于10万的家庭比高收入的家庭更不可能获得贷款。

应用模型
将数据分为训练集和测试集
train\_labels = train\_settest\_labels = test\_set决策树分类器
DecisionTreeClassifier(class\_weight=None, criterion='entropy', ...)dt\_model.score0.9773333333333334dt\_model.predict(test\_set)
``````查看测试集
test_set.head(5)
朴素贝叶斯
naive\_model.fit(train\_set, train\_labels)naive\_model.score0.8866666666666667随机森林分类器

randomforest\_model.score(test\_set,test_labels)0.8993333333333333KNN(K-最近邻居)
data.drop(\['Experience' ,'ID'\] , axis = 1).drop(labels= "PersonalLoan" , axis = 1)train\_set\_dep = data\["PersonalLoan"\]acc = accuracy\_score(Y\_Test, predicted)print(acc)0.9106070713809206模型比较
for name, model in models:kfold = model\_selection.KFold(n\_splits=10)cv\_results = model\_selection.cross\_val\_score(model, X, y, cv, scoring)# 箱线图算法的比较plt.figure()


结论
通用银行的目的是将负债客户转变为贷款客户。他们想发起新的营销活动;因此,他们需要有关数据中给出的变量之间的有联系的信息。本研究使用了四种分类算法。从上图可以看出,随机森林 算法似乎 具有最高的精度,我们可以选择它作为最终模型。
Python信贷风控模型:梯度提升Adaboost,XGBoost,SGD, GBOOST, SVC,随机森林, KNN预测金融信贷违约支付和模型优化 |附数据代码
最近我们被客户要求撰写关于信贷风控模型的研究报告,包括一些图形和统计输出。
在此数据集中,我们必须预测信贷的违约支付,并找出哪些变量是违约支付的最强预测因子?以及不同人口统计学变量的类别,拖欠还款的概率如何变化?
有25个变量:
1. ID: 每个客户的ID
2. LIMIT_BAL: 金额
3. SEX: 性别(1 =男,2 =女)
4.教育程度:(1 =研究生,2 =本科,3 =高中,4 =其他,5 =未知)
5.婚姻: 婚姻状况(1 =已婚,2 =单身,3 =其他)
6.年龄:
7. PAY_0: 2005年9月的还款状态(-1 =正常付款,1 =延迟一个月的付款,2 =延迟两个月的付款,8 =延迟八个月的付款,9 =延迟9个月以上的付款)
8. PAY_2: 2005年8月的还款状态(与上述相同)
9. PAY_3: 2005年7月的还款状态(与上述相同)
10. PAY_4: 2005年6月的还款状态(与上述相同)
11. PAY_5: 2005年5月的还款状态(与上述相同)
12. PAY_6: 还款状态2005年4月 的账单(与上述相同)
13. BILL_AMT1: 2005年9月的账单金额
14. BILL_AMT2: 2005年8月的账单金额
15. BILL_AMT3: 账单金额2005年7月 的账单金额
16. BILL_AMT4: 2005年6月的账单金额
17. BILL_AMT5: 2005年5月的账单金额
18. BILL_AMT6: 2005年4月
19. PAY_AMT1 2005年9月,先前支付金额
20. PAY_AMT2 2005年8月,以前支付的金额
21. PAY_AMT3: 2005年7月的先前付款
22. PAY_AMT4: 2005年6月的先前付款
23. PAY_AMT5: 2005年5月的先前付款
24. PAY_AMT6: 先前的付款额在2005年4月
25. default.payment.next.month: 默认付款(1 =是,0 =否)
现在,我们知道了数据集的整体结构。因此,让我们应用在应用机器学习模型时通常应该执行的一些步骤。
第1步:导入
import numpy as npimport matplotlib.pyplot as plt所有写入当前目录的结果都保存为输出。
dataset = pd.read_csv('Card.csv')现在让我们看看数据是什么样的
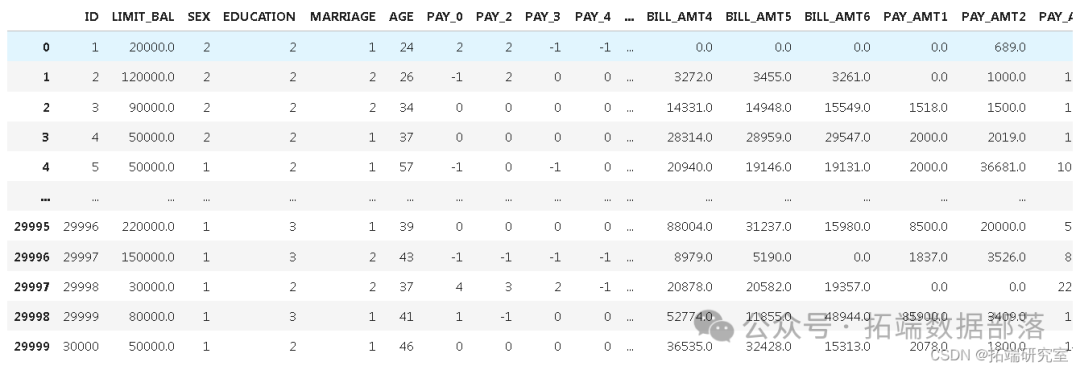
第2步:数据预处理和清理
dataset.shape
``````
(30000, 25)意味着有30,000条目包含25列
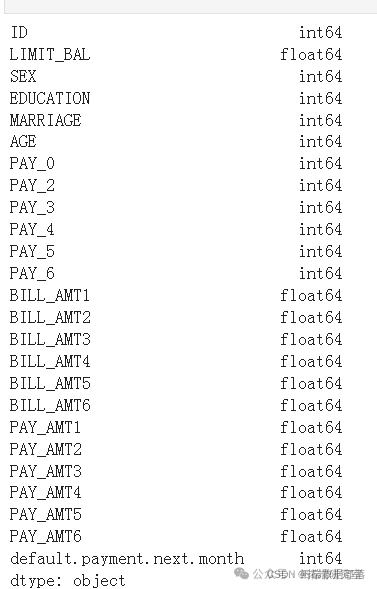
从上面的输出中可以明显看出,任何列中都没有对象类型不匹配。
#检查数据中Null项的数量,按列计算。dataset.isnull().sum()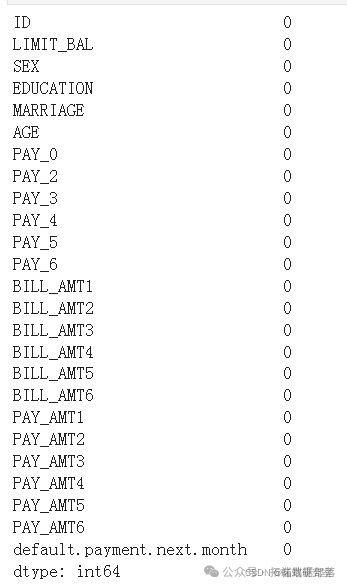
步骤3.数据可视化和探索性数据分析
# 按性别检查违约者和非违约者的计数数量sns.countplot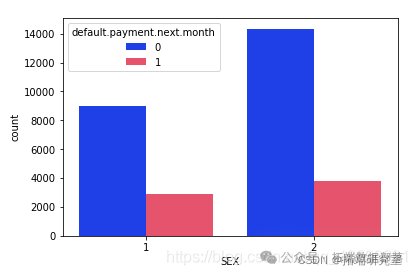
从上面的输出中可以明显看出,与男性相比,女性的整体拖欠付款更少
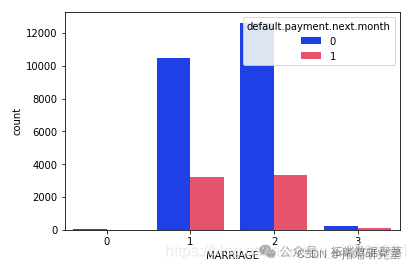
可以明显看出,那些拥有婚姻状况的人的已婚状态人的默认拖欠付款较少。
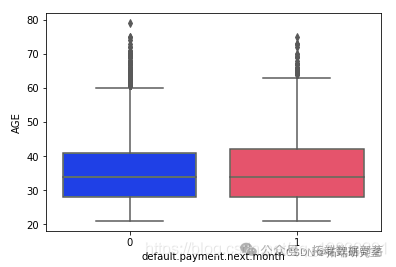
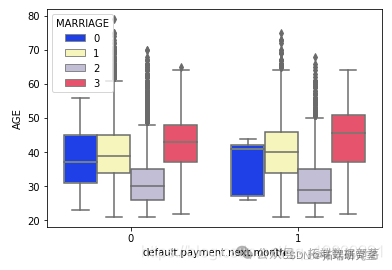
sns.pairplot
sns.jointplot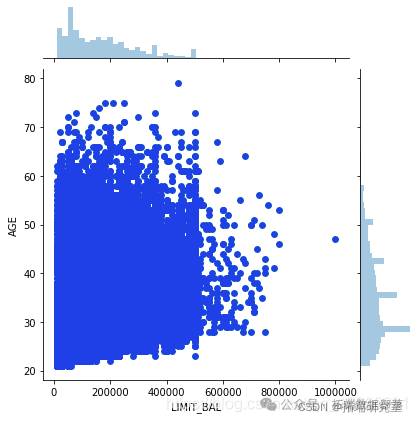
男女按年龄分布
g.map(plt.hist,'AGE')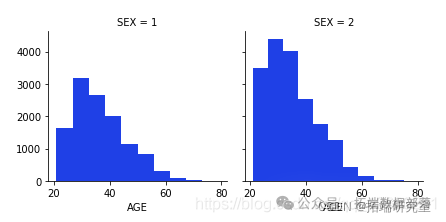
dataset\['LIMIT_BAL'\].plot.density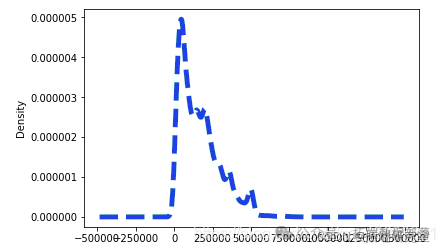
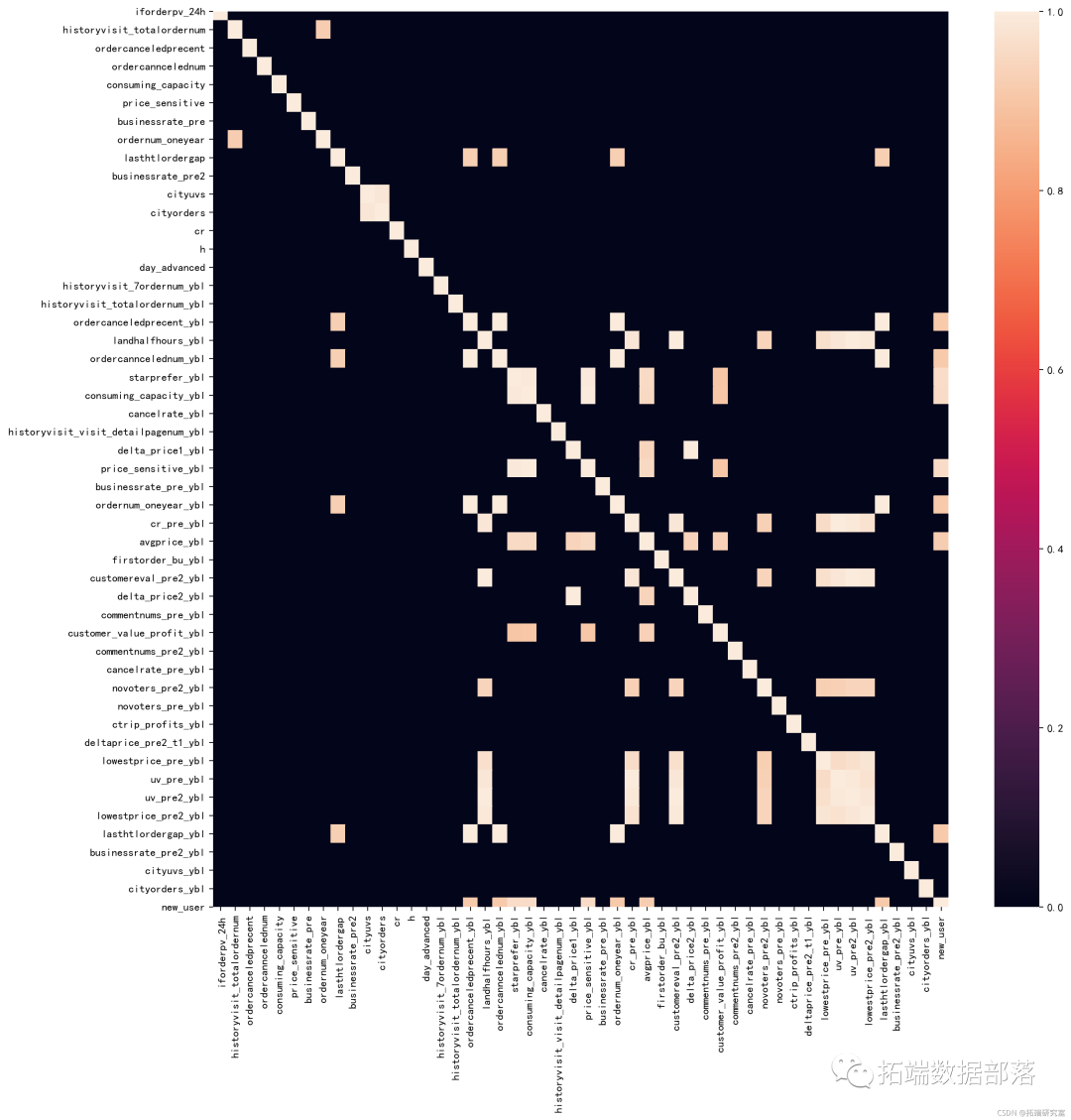
步骤4.找到相关性
X.corrwith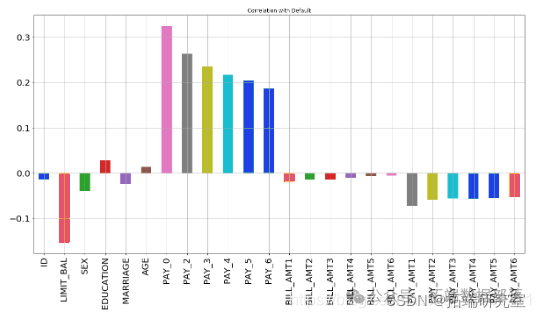
从上图可以看出,最负相关的特征是LIMIT_BAL,但我们不能盲目地删除此特征,因为根据我的看法,这对预测非常重要。ID无关紧要,并且在预测中没有任何作用,因此我们稍后将其删除。
# 绘制热图sns.heatmap(corr)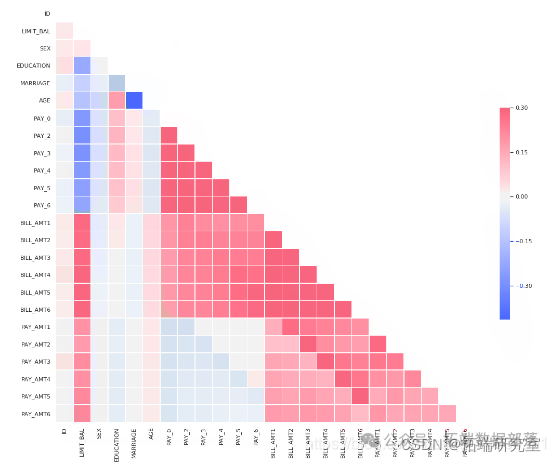
步骤5:将数据分割为训练和测试集
训练数据集和测试数据集必须相似,通常具有相同的预测变量或变量。它们在变量的观察值和特定值上有所不同。如果将模型拟合到训练数据集上,则将隐式地最小化误差。拟合模型为训练数据集提供了良好的预测。然后,您可以在测试数据集上测试模型。如果模型在测试数据集上也预测良好,则您将更有信心。因为测试数据集与训练数据集相似,但模型既不相同也不相同。这意味着该模型在真实意义上转移了预测或学习。
因此,通过将数据集划分为训练和测试子集,我们可以有效地测量训练后的模型,因为它以前从未看到过测试数据,因此可以防止过度拟合。
我只是将数据集拆分为20%的测试数据,其余80%将用于训练模型。
train\_test\_split(X, y, test\_size = 0.2, random\_state = 0)步骤6:规范化数据:特征标准化
对于许多机器学习算法而言,通过标准化(或Z分数标准化)进行特征标准化可能是重要的预处理步骤。
许多算法(例如SVM,K近邻算法和逻辑回归)都需要对特征进行规范化,
min\_test = X\_test.min()range\_test = (X\_test - min\_test).max()X\_test\_scaled = (X\_test - min\_test)/range\_test步骤7:应用机器学习模型
from sklearn.ensemble import AdaBoostClassifieradaboost =AdaBoostClassifier()
xgb\_classifier.fit(X\_train\_scaled, y\_train,verbose=True)end=time()train\_time\_xgb=end-start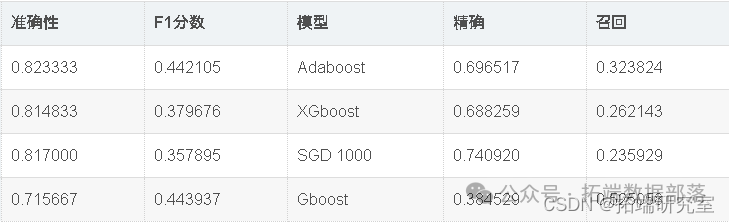
应用具有100棵树和标准熵的随机森林
classifier = RandomForestClassifier(random\_state = 47,criterion = 'entropy',n\_estimators=100)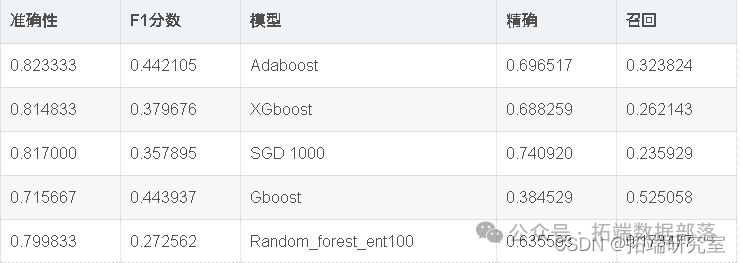
svc_model = SVC(kernel='rbf', gamma=0.1,C=100)
knn = KNeighborsClassifier(n_neighbors = 7)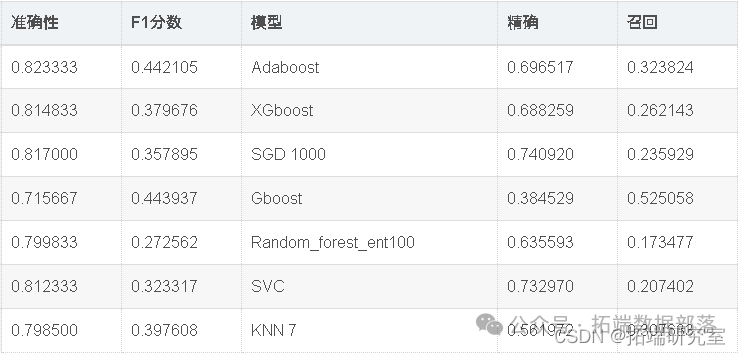
步骤8:分析和比较机器学习模型的训练时间
Train\_Time = \[train\_time\_ada,train\_time\_xgb,train\_time\_sgd,train\_time\_svc,train\_time\_g,train\_time\_r100,train\_time_knn\]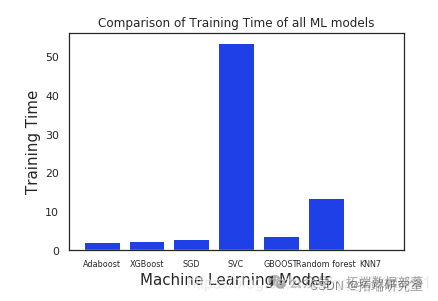
从上图可以明显看出,与其他模型相比,Adaboost和XGboost花费的时间少得多,而其他模型由于SVC花费了最多的时间,原因可能是我们已经将一些关键参数传递给了SVC。
步骤9.模型优化
在每个迭代次数上,随机搜索的性能均优于网格搜索。同样,随机搜索似乎比网格搜索更快地收敛到最佳状态,这意味着迭代次数更少的随机搜索与迭代次数更多的网格搜索相当。
在高维参数空间中,由于点变得更稀疏,因此在相同的迭代中,网格搜索的性能会下降。同样常见的是,超参数之一对于找到最佳超参数并不重要,在这种情况下,网格搜索浪费了很多迭代,而随机搜索却没有浪费任何迭代。
现在,我们将使用Randomsearch cv优化模型准确性。如上表所示,Adaboost在该数据集中表现最佳。因此,我们将尝试通过微调adaboost和SVC的超参数来进一步优化它们。
参数调整
现在,让我们看看adaboost的最佳参数是什么
random\_search.best\_params_
``````
{'random\_state': 47, 'n\_estimators': 50, 'learning_rate': 0.01}
random\_search.best\_params_
``````
{'n\_estimators': 50, 'min\_child\_weight': 4, 'max\_depth': 3}
random\_search.best\_params_
``````
{'penalty': 'l2', 'n\_jobs': -1, 'n\_iter': 1000, 'loss': 'log', 'alpha': 0.0001}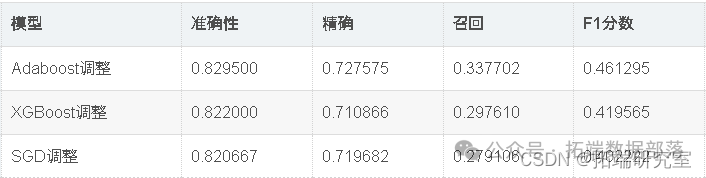
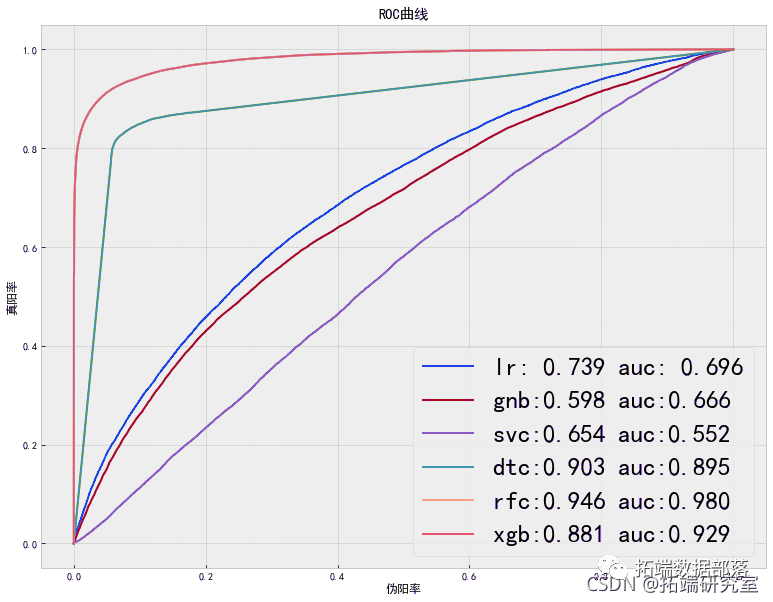
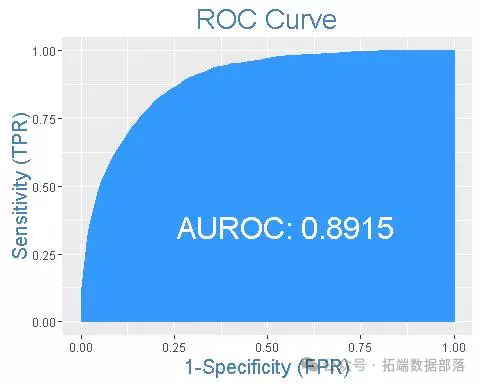
出色的所有指标参数准确性,F1分数精度,ROC,三个模型adaboost,XGBoost和SGD的召回率现已优化。此外,我们还可以尝试使用其他参数组合来查看是否会有进一步的改进。
ROC曲线图
auc = metrics.roc\_auc\_score(y\_test,model.predict(X\_test_scaled))plt.plot(\[0, 1\], \[0, 1\],'r--')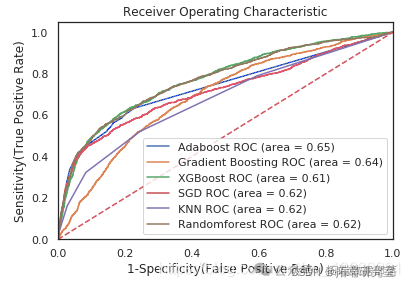
# 计算测试集分数的平均值和标准差test\_mean = np.mean# 绘制训练集和测试集的平均准确度得分plt.plot# 绘制训练集和测试集的准确度。plt.fill\_between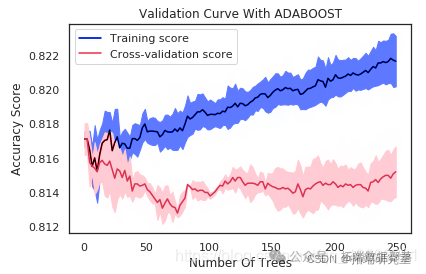
验证曲线的解释
如果树的数量在10左右,则该模型存在高偏差。两个分数非常接近,但是两个分数都离可接受的水平太远,因此我认为这是一个高度偏见的问题。换句话说,该模型不适合。
在最大树数为250的情况下,由于训练得分为0.82但验证得分约为0.81,因此模型存在高方差。换句话说,模型过度拟合。同样,数据点显示出一种优美的曲线。但是,我们的模型使用非常复杂的曲线来尽可能接近每个数据点。因此,具有高方差的模型具有非常低的偏差,因为它几乎没有假设数据。实际上,它对数据的适应性太大。
从曲线中可以看出,大约30到40的最大树可以最好地概括看不见的数据。随着最大树的增加,偏差变小,方差变大。我们应该保持两者之间的平衡。在30到40棵树的数量之后,训练得分就开始上升,而验证得分开始下降,因此我开始遭受过度拟合的困扰。因此,这是为什么30至40之间的任何数量的树都是一个不错的选择的原因。
结论
因此,我们已经看到,调整后的Adaboost的准确性约为82.95%,并且在所有其他性能指标(例如F1分数,Precision,ROC和Recall)中也取得了不错的成绩。
此外,我们还可以通过使用Randomsearch或Gridsearch进行模型优化,以找到合适的参数以提高模型的准确性。
我认为,如果对这三个模型进行了适当的调整,它们的性能都会更好。
R语言基于决策树的银行信贷风险预警模型 |附数据代码
我国经济高速发展,个人信贷业务也随着快速发展,而个人信贷业务对提高内需,促进消费也有拉动作用。有正必有反,在个人信贷业务规模不断扩大的同时,信贷的违约等风险问题也日益突出,一定程度上制约着我国的信贷市场的健康发展。
挑战
近年来,个人消费贷款的类型呈现出多元化的变化与发展,由原本的单一贷款种类发展到今天各式各样的贷款种类,汽车按揭贷款,教育助学贷款,耐用消费品贷款(家电,电脑,厨具等),结婚贷款等在我国陆续开展。违约风险是指债务人由于各种原因不能按时归还贷款债务的风险,对于商业银行来说,违约风险主要是指由于贷款人得还款能力下降或者信用水平降低从而违约。
理论相关概述
决策树
决策树(Decision Tree)是用于分类和预测的主要技术,它着眼于从一组无规则的事例推理出决策树表示形式的分类规则,采用自顶向下的递归方式,在决策树的内部节点进行属性值的比较,并根据不同属性判断从该节点向下分支,在决策树的叶节点得到结论。因此,从根节点到叶节点就对应着一条合理规则,整棵树就对应着一组表达式规则。决策树是数据分析中一种经常要用到且非常重要的技术,既能够用于数据分析,也能够作预测。基于决策树算法的一个最大的优点是它在学习过程中不需要使用者了解很多背景知识,只要训练事例能够用属性即结论的方式表达出来,就能使用该算法进行学习。
基于决策树的分类模型有如下几个特点:(1)决策树方法结构简单,,便于理解;(2)决策树模型效率高,对训练集数据量较大的情况较为适合;(3)树方法通常不需要接受训练集数据外的知识;(4)决策树方法具有较高的分类精确度。
预警方案设计
数据在进行操作的过程中,我们一共分了四步,分别是数据分析和分离数据集,建立训练数据集决策树,评估模型性能,提高模型性能。
数据分析和分离数据集
在数据进行分析时,可以从中知道所有申请者的违约情况在分离数据集这一步,我们将数据分成两部分:用来建立决策树训练数据集和用来评估模型性能的测试数据集,按照80%训练集和20%测试集来分离样本。总的来看,这两个数据集的比例是大致相同的,所以分离的两个数据集是合理的。
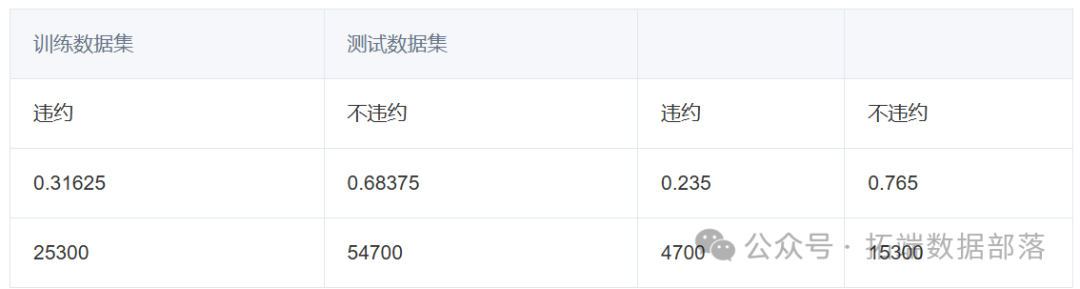
建立训练数据集决策树

图1
图1是训练数据集决策树的基本情况。
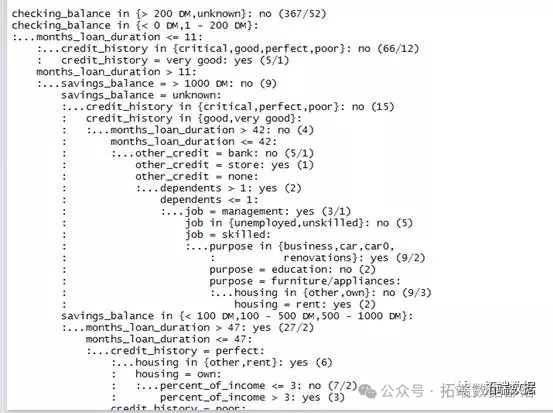
图2
图2是训练数据集的部分决策树。
由于我们我们的数据庞大,生成的决策树非常的大,上图的输出显示了决策树的部分分枝,我们用简单的语言来举例解释前五行:
(1)如果支票账户余额是未知的,则归类为不太可能违约。
(2)否则,如果支票账户余额少于0,或者1〜200之间;
(3)月贷款期限少于或等于11个月的
(4)信用记录是危及,好的,优秀的,差的,归类为不太可能违约。
(5)信用记录是非常优秀的,就归类为很有可能违约。
括号中的数字表示符合该决策准则的案例的数量以及根据该决策不正确分类的案例的数量。
在决策树中我们不难发现,为什么一个申请者的信用记录非常优秀,却被判成很有可能违约,而那些支票余额未知的申请者却不太可能违约呢?这些决策看似没有逻辑意义,但其实它们可能反映了数据中的一个真实模式,或者它们可能是统计中的异常值。
在决策树生成后,输出一个混淆矩阵,这是一个交叉列表,表示模型对训练数据错误分类的记录数:
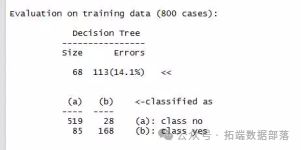
众所周知,决策树有一种过度拟合训练数据模型的倾向,由于这个原因,训练数据中报告的错误率可能过于乐观,因此,基于测试数据集来评估决策树模型是非常重要的。
评估模型性能
在这一步中使用测试数据集做预测。
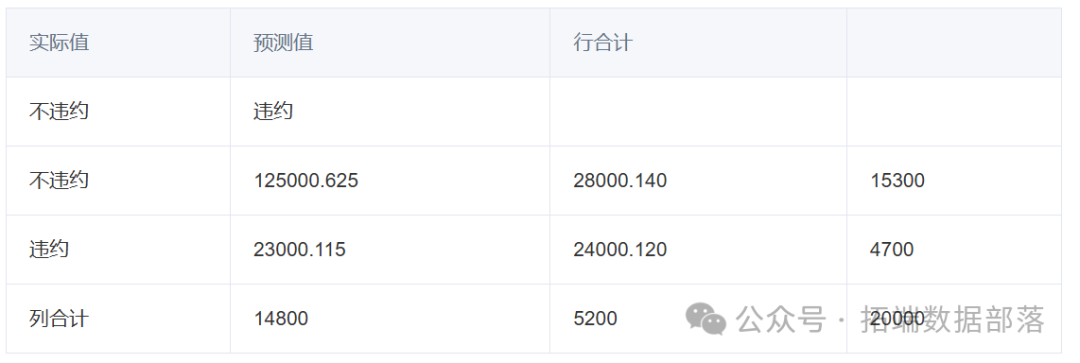
可以得知,在测试集样本中,实际不违约被判为不违约的数量,占比为0.625;实际不违约被判为违约的数量,占比为0.140;而实际违约被判为不违约的数量占比为0.115;实际违约被判为违约的数量,占比为0.120。
从银行角度出发,申请人实际不违约被判为违约的影响远没有实际违约被判为不违约的影响大。原因有以下几点:一,申请人实际不违约被判为违约,银行可能不会通过贷款申请,从而不发放贷款,这样银行不会遭受贷款发放出去却收不回来的风险,只是少收部分贷款利息而已。二,申请人实际违约被判为不违约,银行可能会同意申请人的贷款申请同意发放贷款,在发放贷款后,被判为不违约的申请人可能会因为缺乏诚信,不遵守合约规定按时还款,这样银行不仅损失了利息的收入,连本金都有可能收不回来三,在测试数据集数据中,实际不违约的数量,占比0.183;而实际违约的数量,被判为不违约的数量,占比0.489。
由以上三点可以得出结论,基于训练测试集得出的模型,用测试数据集中的数据进行检验,最终出来的结果并不是很好。从银行角度出发,如果使用该模型引用到实际生活中,会因为申请人实际违约被误判为不违约的概率太大,而使银行做出错误的决定,从而产生损失。
模型优化方案 - 增加迭代次数,代价矩阵
由上面的评估模型性能可以得知,基于训练数据集得出的模型不太理想,因此我们来提高模型的性能。
1,迭代10次
首先我们选择使用迭代10次的方法进行对模型性能的提高。
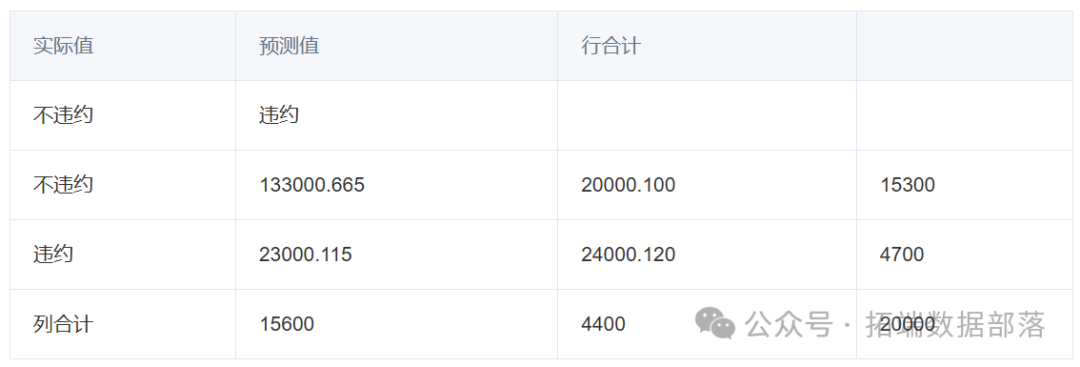
3可以知道经过10次迭代,实际违约被判为不违约的数量占比0.115,与训练数据集的模型相比没有变化;而实际不违约被判为违约的数量,占比0.100。
从银行角度出发,这次的模型性能提高没有很大的实际意义,因为影响银行是否亏损的最主要因素是看实际违约被判为不违约的比重,而这次的性能提高并没有减少实际违约被判为不违约的数量,所以我们还要继续提高模型的性能。
2,迭代100次
根据上面的步骤知道,迭代10次出来的模型效果并不是很好,所以我们在这一步进行迭代100次的操作。
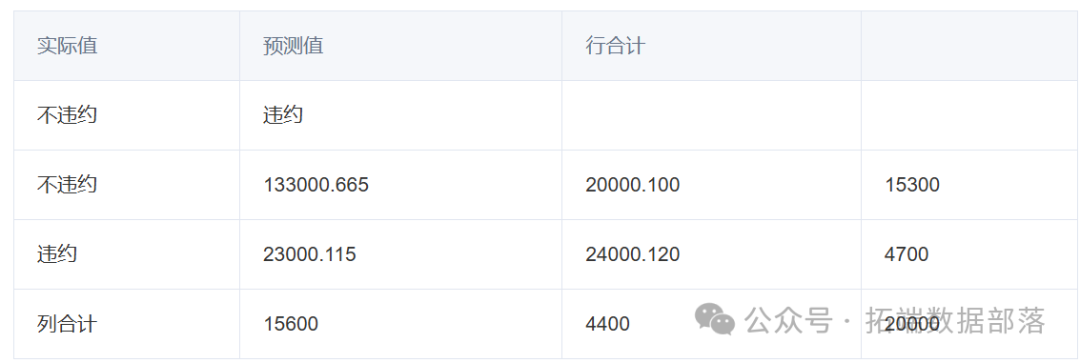
经过迭代100次的过程出来的结果由表4所示,与训练数据集的结果图相比,由此可以看出该次模型性能的提升没有较大效果。
3,代价矩阵
由于上述两次操作均没有使得模型的性能得到较大的提升,所以在这一步我们决定采用代价矩阵的方式来进行。
这里我们假设将一个违约用户错误的分类为不违约相比于将不违约用户错误的分类为违约来说,前者相较于后者会给贷款方造成4倍的损失,故代价矩阵为:
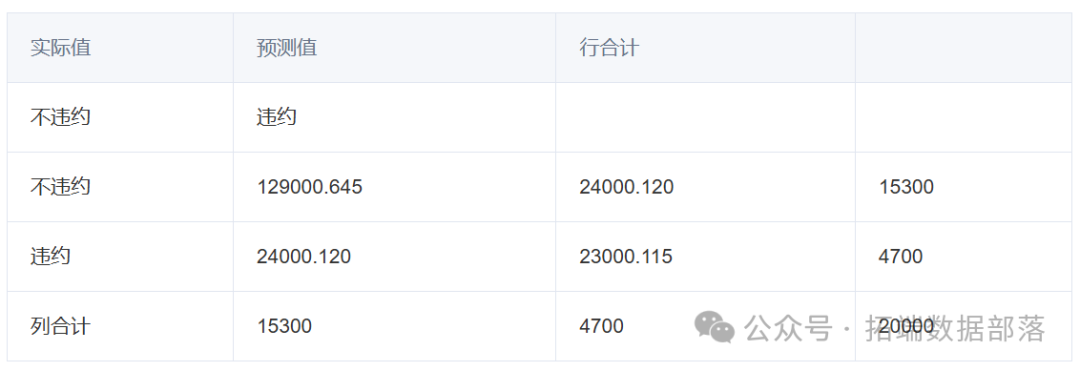
上述矩阵行表示真实值,列表示预测值,第一列和第一行代表不违约,第二列和第二行代表违约。假如该算法正确分类时,则没有分配代价。图6是加入代价矩阵的模型分类结果汇总。
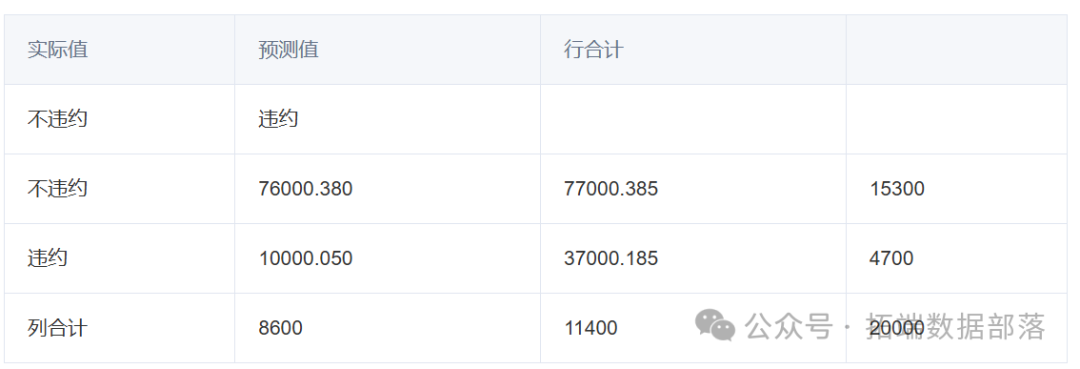
相较于前面的结果,在加入代价矩阵后的模型效果不错,在实际违约被判为不违约的比例上得到了较大程度的下降。
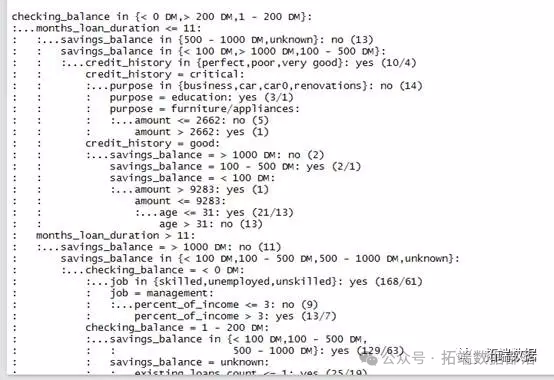
图3
图3是测试数据集的部分决策树。
建议
现今,我国的生活水平逐步提升,个人的消费水平也跟着上升,但仍有很多人的工资薪酬涨幅跟不上消费的增长,就会从商业银行贷款作为经济生活维持,已提升自己的生活水平,不仅是车辆按揭贷,房产按揭贷款,教育助学贷款,耐用消费品贷款,结婚贷款等在我国陆续开展,数量与规模也越来越庞大。商业银行要从贷款中获利,就必须加强对于贷款的风险管理,在进行单一评估的同时从大量规律中获取经验,对于人力无法理解的大规模数据,就需相关研究来获取有用的规律,帮助商业银行及其他金融机构做出决策,而决策树对银行及金融机构来说就是一种很好的决策管理方法。
通过决策树的每一个子节点可以看出哪一个自变量会对贷款违约有多大的影响,从而商业银行可以更加的关注客户的这一方面,在这方面严格把关。算法能够为影响较大的错误分类进行误判代价值的设定,从而使模型在这类误判中的增加重视,降低这类错误发生的概率。假设银行将实际上不违约的客户判成了违约,银行仅仅是少获得几笔贷款的利息,不至于把整笔贷款都亏掉变成坏账;但假如银行使用了这种算法,对客户的违约可能性做出更为准确的判断,便能减少银行对实际违约的客户错判成不违约的情况,降低银行出现贷款无法追收的情况。
关于分析师

在此对 Fanghui Shao 对本文所作的贡献表示诚挚感谢,他在卡耐基梅隆大学完成了数理金融专业的硕士学位,专注量化金融、数据分析、统计分析领域。擅长 Python、R 语言、Excel。
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!


点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《银行信贷风控专题:Python、R 语言机器学习数据挖掘实例合集:xgboost、决策树、随机森林、贝叶斯等》。
点击标题查阅往期内容
数据分享|Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户
PYTHON银行机器学习:回归、随机森林、KNN近邻、决策树、高斯朴素贝叶斯、支持向量机SVM分析营销活动数据|数据分享
用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言用FNN-LSTM假近邻长短期记忆人工神经网络模型进行时间序列深度学习预测4个案例
Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类



![]()