经过24个小时,各个平台的相关选题投票、相关文章阅读量等各项数据进行统计,利用之前的评估办法(详见注释)。在开赛后24小时,我们基本确定各个赛题选题人数,以帮助大家更好地分析赛题局势。
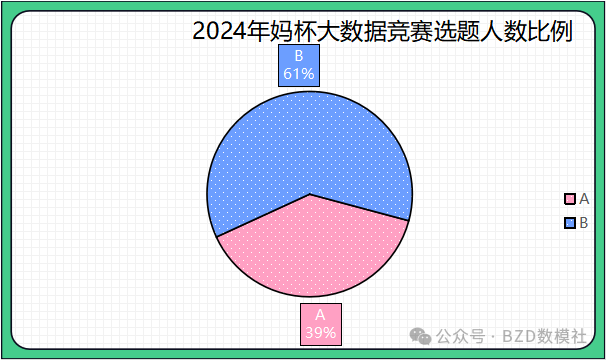
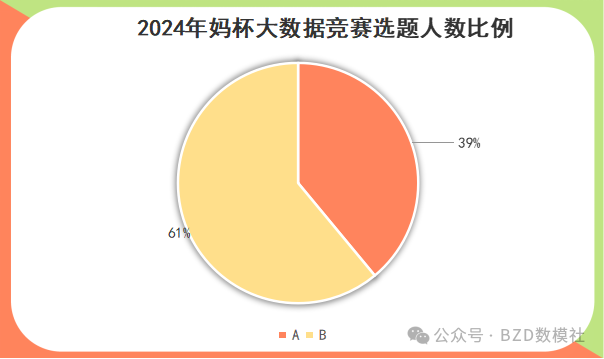
| 题目 | 人数 |
| A | 46 |
| B | 72 |
基于多模型方法的台风分类、路径预测及登陆后降水影响分析
摘要
台风作为全球最严重的自然灾害之一,具有极大的破坏性和复杂性,其预测和分类具有重要意义。本文基于历史台风数据,针对台风的特征分类、路径预测以及登陆后的降水量和风速变化进行了详细分析,并结合多种模型进行求解。
在数据预处理方面,本文对 1945 年至 2023 年的台风数据进行了系统性的处理,包括缺失值的插值填充、时间格式的转换、异常值的检测与剔除,以及对非数值型数据的编码处理。这些步骤为后续的模型建立提供了干净且高质量的数据基础。
问题一中,目标是对台风的特征参数(如强度、风速等)进行分类。该问题采用了 随机森林分类模型 来分析台风的特征与气象因素的关系,通过对历史数据的特征选择和分类模型训练,成功将台风分类为不同类别(例如夏台风与秋台风),并分析了各类别的主要特征与差异。该方法的创新点在于结合气象因素与多维度特征进行分类,有助于提高对台风性质的理解。
问题二中,目标是对台风路径进行预测。我们使用 函数型主成分分析 (FPCA) 与 多层感知器 (MLP) 相结合的方法对台风路径进行预测,提取了台风路径的主要变化模式,结合 FPCA 对路径特征进行了降维,再使用神经网络模型进行了时间序列预测,并通过 动态时间规整 (DTW) 算法与实际路径进行对比。结果表明,FPCA 有效提取了路径的主要特征,模型对路径的预测表现良好。创新点在于通过 FPCA 提取路径特征并结合 M

一、模型的建立与求解
5.1 数据预处理
5.1.1 数据编码
为了在模型中有效利用台风强度的分类信息,本研究对台风强度的数据进行了必要的编码转换。由于原始数据中使用汉字或者字母表示台风的强度类别,如"超强台风(Super TY)"、"强热带风暴(STS)"等,
表1:数据编码原始数据
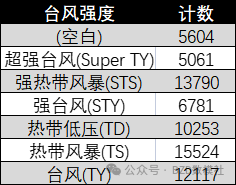
为了便于计算机处理并应用于后续模型建立,必须将这些分类转换为数值编码。具体编码方案如下:
·空白 (代表未记录的强度) : 0
·超强台风 (Super TY) : 1
·强热带风暴(STS):2
·强台风 (STY) : 3
·热带低压 (TD) : 4
电商品类货量预测及品类分仓规划
摘 要
电商企业在各区域的商品存储主要由多个仓库组成的仓群承担。其中存储的商品主要按照属性(品类、件型等)进行划分和打标,便于进行库存管理。商品品类各异,件数众多,必须将商品分散到各个仓库存储。品类分仓规划决定各商品存放在哪些仓库问题,合理的品类分仓规划对提升每个仓的管理效率、降低总体仓储成本至关重要。
准确的仓储货量预测是品类分仓规划的重要依据,对于准确的预测结 果能够预见性地决定未来的仓储资源使用决策,以提前规划仓储资源,减少冗余场地的投入。一般来说,该场景需要预测两个目标,分别为库存量 和销量。其中,库存量为该品类在全部仓库所需存放的总库存,分仓结果 中受到仓库的仓容限制;销量为该品类在全部仓库所需打包出库的总量,分仓结果中受到产能限制。在得到未来各品类的预测货量后,各个品类的分仓规划是供应链规划者的重要研究问题。若将品类集中存放在数量较少的仓库中,则将超过该 仓的仓容及产能上限,造成履约问题;若同一品类分在多个仓库中,则会显著增加仓库数量,增大品类库存的管理难度及总成本。此场景需考虑的上限包括两个,分别为仓容上限和产能上限,其中仓容上限为某仓库可以 存放的最高库存量,产能上限为某仓库一天可以出库的最高销量。另外,若将相似的品类(使用品类关联度衡量相似性)放在同一个仓库中,同一订单中的商品更可能集中出货,可以在实际履约中减少包裹数量,从而降低履约成本。
针对问题一,首先进行数据预处理,采用IQR技术处理异常值去除噪声,并平滑数据。再将采用XGboost方法用于不连续的时间序列数据来预测库存量数据的月均值,采用LSTM预测7-9月份每日销量数据。针对问题二,通过混合整数规划来解决,目标是最小化仓租成本和提高仓库利用率。主要要求基于问题1中的预测结果,解决“一品一仓”的品类分仓问题,即每个品类只能存放在一个仓库中。目标是通过规划模型,找到合理的分仓方案,满足仓库的仓容和产能限制。规划的重点在于
3 模型假设和符号分析
3.1 模型假设
1、时间序列的平稳性假设:我们假设商品的销量具有某种周期性或季节性变化特征,在没有其他重大市场变化的情况下,过去的销量数据能够反映未来的趋势。
2、产品独立性假设:不同品类的销量相互独立,不考虑品类之间的互补性或替代性对销量的影响。
3、库存影响销量的假设:商品的销量受限于当前的库存水平,如果库存不足,销量不会超过库存量。
4、每日销售波动性假设:日销售量可能存在波动,波动幅度依赖于市场供求关系和随机性。
5、一品一仓假设:每种品类只能分配到一个仓库中,且每个仓库可以容纳多个品类,但每个品类必须只
4 模型建立与求解
4.1 问题1模型建立与求解
4.1.1 数据预处理
1、数据预处理
(1)日期处理
使用 pd.to_datetime() 函数将月份列中的字符串转换为 datetime 格式,以此再python中让 pandas 识别并处理这些日期,采用日期格式转换,提取时间特征,生成滞后特征和移动平均特征。然后从日期中提取出特征,这些时间特征可以帮助模型捕捉季节性和周期性趋势。通过创建滞后特征(lag features),引入过去的库存量和销量信息,帮助模型了解过去的库存状况如何影响未来的库存量。通过移动平均平滑短期波动,捕捉长期趋势。
(2)异常值检测
通过箱线图(boxplot)对库存量进行可视化。箱线图能够显示数据的分布情况,并帮助识别出明显的异常值(通常表现为箱线图中的“飞点”)。通过散点图进一步检查月份和库存量之间的关系以及日期和日销售量的关系,帮助直观识别在时间序列上是否存在异常的库存值。根据 IQR(四分位距)规则清除库存量数据中的异常值,以获得更干净的数据集。
图1是库存量的箱线图,绝大多数数据点集中在较低的库存量范围内,约在0到50,000之间,符合较大部分品类的库存实际情况。但是箱线图右侧延伸出许多异常值,显示了有相当一部分数据远高于正常范围。特别是,库存量超过200,000的极值非常突出,这些可能是异常库存或者极少数库存量异常高的情况。这种库存量的高度偏离说明数据中存在较大的异质性,可能需要进一步清洗和处理,以确保模型分析结果的准确性。