文章目录
- 1.numpy简介
- 2.初始化numpy
- 3.ndarry的使用
- 3.1numpy的属性
- 3.2numpy的形状
- 3.3ndarray的类型
- 4numpy生成数组的方法
- 4.1生成0和1数组
- 4.2从现有的数组生成
- 4.3生成固定范围的数组
- 4.4生成随机数组
- 5.数组的索引、切片
- 6.数组的形状修改
- 7.数组的类型修改
- 8.数组的去重
- 9.ndarray的运算
- 9.1逻辑运算
- 9.2通用判断函数
- 9.4三元运算符
- 9.4统计运算
- 10.数组间的运算
- 10.数组与数之间的运算
- 10.2数组与数组之间的运算
- 11.矩阵
1.numpy简介
numpy是一个开源的Python库,也就是相当于Python中的列表,即多维数组。那么为什么有了列表,我们还需要使用numpy呢?numpy可以计算大型的多维数组和矩阵操作,他的计算能力更强,运行的速度更快。
其实,Python中的列表,要想找到列表中对应的元素需要先通过寻找该元素的地址才可以访问到元素,因此,速度自然会慢一些。而Python中的numpy是存储在一片连续的地址空间上的,因此访问元素速度更快,类似于c++中的数组,物理空间是连续的。
而且,numpy内置了并行运算功能,当系统有多个核心的时候,做某种运算,numpy会自动做并行运算。

注意:Python中的列表可以存放不同的元素类型,而numpy只能存放相同的数据类型。
我们用过一个例子来看列表与numpy效率的对比:

我们可以看到numpy的效率更高。
2.初始化numpy
初始化numpy的操作如下:
通过 numpy.arry()进行numpy的初始化
import numpy as np
score = np.array(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
)
print(score)
执行结果如下:

3.ndarry的使用
3.1numpy的属性
| 属性名称 | 属性解释 |
|---|---|
| ndarry.shape | 数组维度,即几行几列 |
| ndarray.ndim | 数组的维数,即是几维的数组 |
| ndarray.size | 数组中总的元素个数 |
| ndarray.itemsize | 数组每个元素的大小,单位为字节 |
| ndarray.dtype | 数组中每个元素的类型 |
例如:
import numpy as np
score = np.array(
[
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
)
print(score.shape)
print(score.dtype)
print(score.size)
print(score.itemsize)
print(score.ndim)

3.2numpy的形状
首先我们先创建一些数组
#创建一些不相同形状的数组
a = np.array([[1, 2], [3, 4], [5, 6]])
b = np.array([1, 2, 3, 4])
c = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
print(a.shape)
print(b.shape)
print(c.shape)

3.3ndarray的类型
ndarray的主要类型有以下集中:
| 名称 | 描述 |
|---|---|
| np.bool | 用一个字节存储的布尔类型(True或是FALSE) |
| np.int32 | 整数,默认的整数大小,四个字节 |
| np.int64 | 八个字节的整数类型 |
| np.uint32 | 无符号整数,四个字节大小 |
| np.uint64 | 无符号整数,八个字节大小 |
| np.float32 | 默认浮点数类型,四个字节大小 |
| np.float64 | 浮点数类型,八个字节大小 |
| np.object_ | Python对象 |
| np.string_ | 字符串 |
我们在创建数组时,可以指定数组的类型,例如:

注意,当我们创建一维数组时,默认指的是列向量,例如:

即我们创建了一个一维向量,里面有三个元素,那么它是三行一列的矩阵。
4numpy生成数组的方法
4.1生成0和1数组
- np.ones(shape, dtype),生成全0的数组
- np.zeros(shape, dtype),生成全1的数组
- np.ones_like(a, dtype),生成像a那样维度的全0数组
- np.zeros_like(a, dtype),生成像a那样维度的全1数组
例如:


4.2从现有的数组生成
注意,我们要观察一个现象:
a = np.array([[1, 2, 3], [4, 5, 6]])
#从现有数组生成
a1 = np.array(a) #深拷贝
a2 = np.asarray(a) #浅拷贝
print(a1)
print(a2)
a[0][0] = 100
print(a1)
print(a2)

注意深拷贝和浅拷贝的区别,我们在修改a[0][0]元素后,a1没有发生改变,而a2发生了改变。浅拷贝:两个元素共用一块内存地址,深拷贝:重新申请一片内存,在把数据拷贝进去。 源数据的修改只会影响浅拷贝,不会对深拷贝造成影响。
4.3生成固定范围的数组
1.np.linspace(start, stop, num, endpoint),endpoint表示序列中是否包含stop值,默认是True。表示从start到stop中生成num个整形数据。

2.np.arange(start, stop, step, dtype),step表示步长,默认为1,不包含stop值。注意:arange不可以生成二维的数组,若想要生成二维的数组需要使用np.random.randint(),例如:
a = np.random.randint(40, 100, (10, 5))
print(a)
b = np.arange(40, 100, (10, 5)) #报错
print(b)

3.np.logspace(start, stop, num),创建等比数列,num为创建的个数,默认是50个。都是10的幂次方

4.4生成随机数组
使用np.random模块
一、np.random.normal(均值,标准差,生成个数),服从正态分布
x1 = np.random.normal(1.75, 1, 1000000)
#画出正态分布图
plt.figure(figsize=(20, 10), dpi=100)
plt.hist(x1, 1000) #绘制直方图
plt.show()

二、均匀分布
类似于Python中的random函数的随机种子,random函数如下(复习一下):
1.random.random(),返回0-1之间的浮点数,例如;

2.random.randint(a, b),返回a-b之间的整数,包含a和b,例如:

3.random.uniform(a, b),返回a-b之间的浮点数,包含a和b,例如:

4.random.randrange(a, b, c),返回从a-b,步长为c的随机数,
注意:np没有这个api,其他的都是有的。
例如:

返回的就是0, 10, 20, …, 100之间的数。
关于random生成随机种子的方式还有很多很多,
我们再来看一下均值分布:np.random.uniform(a, b, num):最经常使用

5.数组的索引、切片
与Python中的列表操作类似

6.数组的形状修改
1.ndarray.reshape(new_shape, order),当不知道设置成多少行或者列的时候,可以直接设置成-1.
2.ndarray.resize(new_shape),与reshape类似。
3.ndarray.T:矩阵转置

7.数组的类型修改
ndarray.astype(new_type)

8.数组的去重
np.unique(a)

9.ndarray的运算
9.1逻辑运算

9.2通用判断函数
1.np.all():判断所有
2.np.any():判断是否存在

9.4三元运算符
np.where()

9.4统计运算
np…
max()
min()
median():中位数
mean():平均值
std()::标准差
var():方差
argmax()
argmin()

10.数组间的运算
10.数组与数之间的运算

10.2数组与数组之间的运算
数组与数组之间的运算两个矩阵的维度不是必须保持一致的。
广播机制:


11.矩阵
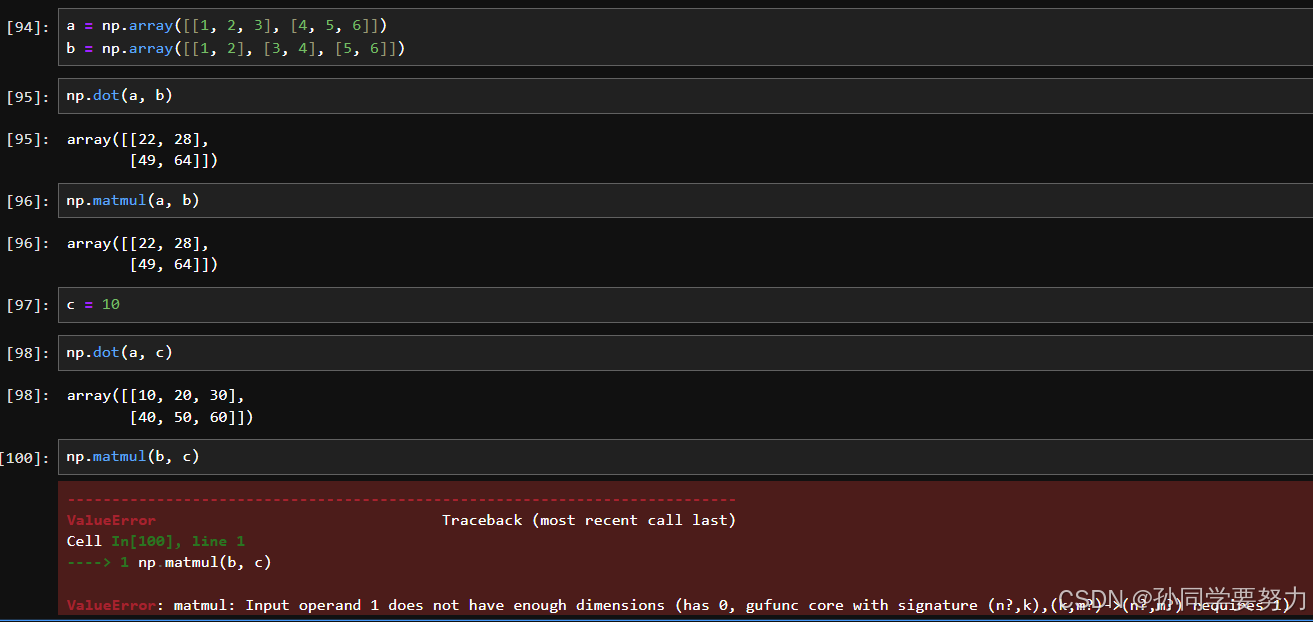
np.matmul
np.dot
是一样的,都是矩阵的点乘,但是matmul不支持矩阵和标量的乘法