文章目录
- 1.定时器的介绍
- 2.线程池
- 2.1为什么需要使用线程池
- 2.2如何进行线程池的创建
- 2.3普通的构造方法的局限性
- 2.4该种对象创建的方法的特点
- 2.5线程池的模拟实现的逻辑
- 3.ThreadPoolExecutor类的介绍
- 3.1构造方法
- 3.2四种拒绝的策略
1.定时器的介绍
下面的这个就是我们的这个定时器的使用:
首先,我们为什么需要了解这个定时器:定时器其实就是约定一个时间,时间到达之后,我们就会执行某一个代码的逻辑,其实这个定时器非常常见,尤其是进行这个网络之间的通信的时候;
例如一个真实的情况下,我们的这个客户端和服务器端进行交互,我们的这个客户端发出去了请求,但是我们的这个服务器迟迟没有进行响应,这个时候我们是不知道这个问题出现你在什么地方的,可能是这个请求没有发过去,也可能是发过去但是这个相应丢失了,也可能是这个服务器出问题了;
对于我们的这个客户端而言,不可能会无限地进行等待,这个等待需要一个时间的最大的限制:就是我们等到一定的时间之后就不会继续进行等待,这个等待的时间就是通过这个定时器的方式进行实现的;
就是我们的这个程序的执行的时刻,以基准时间作为参照,然后查看我们的这个线程任务什么时候会被执行
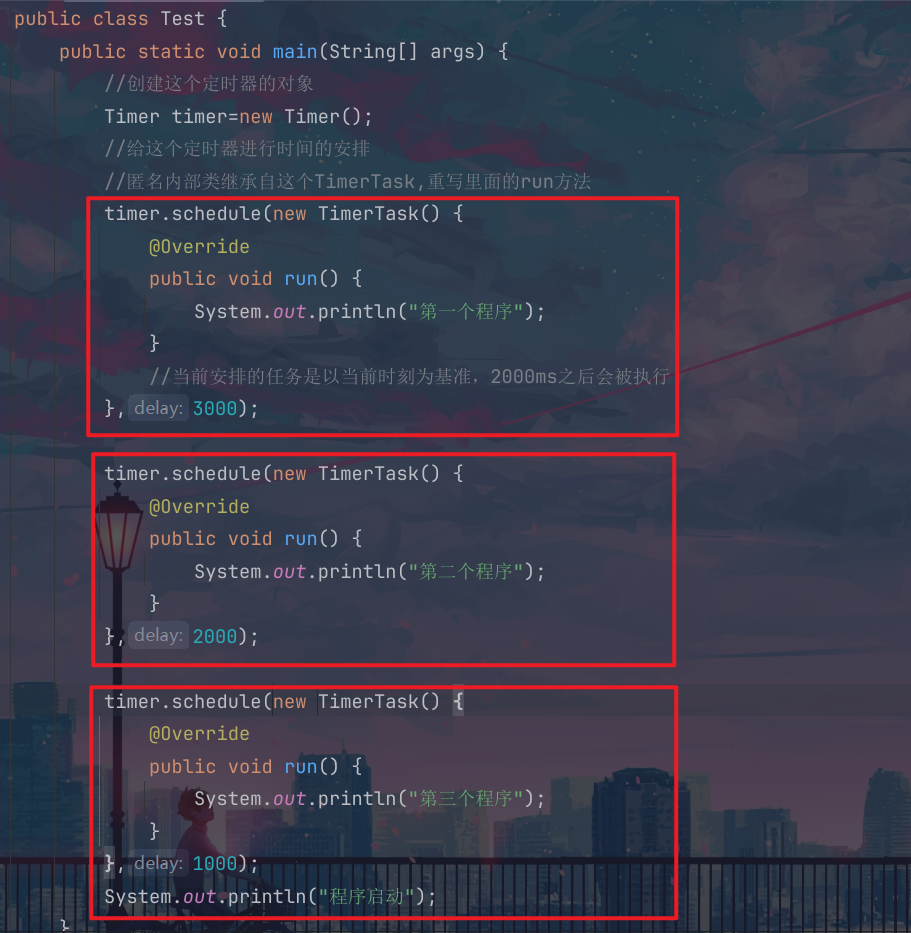
上面的这个其实我们使用的就是这个schedule方法,这个方法里面其实是由两个参数的的,第一个就是我们的这个匿名内部类,这个类是继承自我们的这个TimerTask父类,并且对于这个父类里面的这个run方法进行重写,我们的这个方法的第二个参数就是我们的程序的这个delay的时间,即从当前时间开始计时我们的这个任务在什么时间会被执行;
我们上面是写了三个任务,分别是100,200,3000ms的时间之后分别进行任务的执行,因此这个就是经过1000ms之后,这个第三个程序就会被执行,然后就是我们的2000ms的,最后就是这个1000ms的,因此虽然我们的第一个程序在这个代码里面的位置是第一个,但是这个程序是最后才执行的;
定时器的整体实现逻辑:
- 定义出来一个类,对于这个需要执行的任务进行描述;
- 创建优先级队列,组织所有的执行的任务,设置时间看看哪一个任务需要先被执行,哪一个是后被执行的;
- 扫描线程,判断这个队首元素是不是可以执行任务;(这个地方为什么需要进行判断,主要就是这个队列里面的这个队首的这个元素,其实就是线程是不是可以去执行任务,因为这个线程的执行可能会有先决条件,或者叫做前置条件,因此我们需要扫描判断这个队列里面的第一个线程是不是可以去执行这个任务)
2.线程池
2.1为什么需要使用线程池
这个线程出现的目的就是为了简化这个进程的开销,因此我们的这个线程又被称为轻量化进程,但是当我们的这个线程的数量很多的时候,我们的这个效率其实是有待提高的,这个就是我们要了解学习的这个线程池;
如何正确理解线程池:就是我们在操控这个线程1的时候,线程2,3,4等等诸多线程就会已经被创建出来,这样的好处就是我们想要使用线程的时候,不用进行线程的创建,而是直接从这个线程池里面取出来线程;(这个时候创建线程的开销就被降低了);
为什么直接从这个池子里面去出来线程,比我们创建新的线程的效率更高?—因为我们的这个线程池是存粹的用户态的操作,而我们如果去创建新的线程,这个时候就需要可能调用这个系统的方法,因此这个创建新的线程就是用户态和内核态的操作,因此相比之下,我们自己对于这个线程的操控远比这个内核态+用户态的效率更加高效
这个就是我们的线程池的效率更加高效的原因!!!!
2.2如何进行线程池的创建
我们的这个线程池的创建不是使用这个普通的new方法去创建的,而是调用这个系统的方法去返回一个线程池的对象;
下面的这个展示的就是三种创建的方式:
第一个就是创建一个普通的线程池,第二个是创建一个线程冲,但是对于这个线程池里面的这个线程的数量进行了指定,第三个就是创建一个只包含了一个线程的线程池;
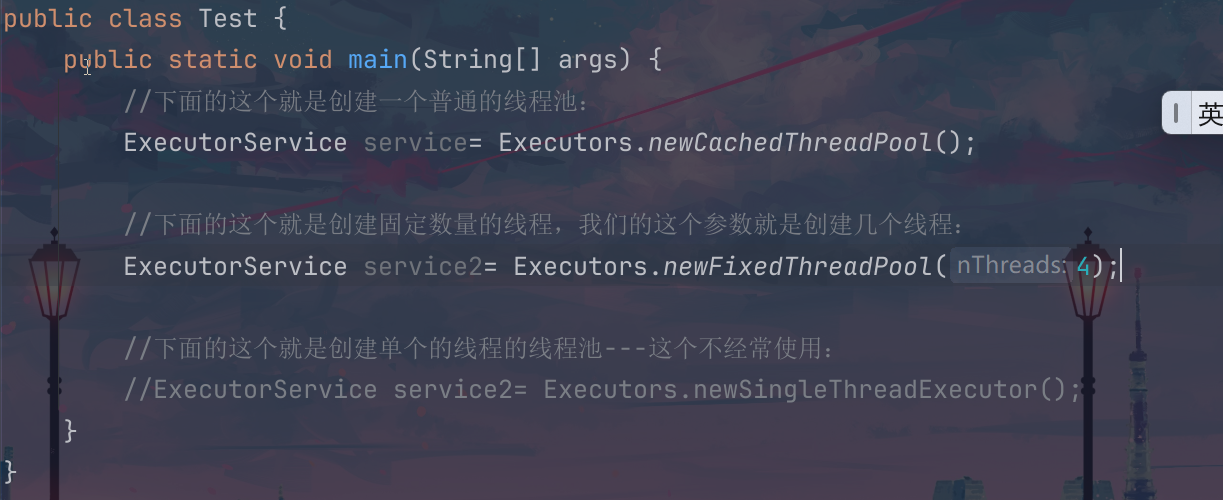
相比于这个普通的构造方法的局限性,我们上面的这个使用方法的返回值创建的这个线程池的思路其实就是大名鼎鼎的设计模式----工厂模式;
2.3普通的构造方法的局限性
我们的这个普通的构造方法的局限性:我们的这个构造方法要求我们的这个方法的名字必须要是一样的,如果想要实现不同的构造方法需要通过这个不同的重载的方式进行这个区分;
但是我们很多时候,创建对象的时候,需要多种构造的方式,这个多种方式需要我们使用多个版本的构造方法去实现,因此我们使用这个方法的调用去返回这个线程池的对象,这个就是工厂模式的一个特点;
工厂模式是给这个构造方法填坑的;
2.4该种对象创建的方法的特点
ExecutorService service= Executors.newCachedThreadPool();
在这个创建方式之下,我们的线程池里面的这个线程的数量是可以进行动态的调整的—这个是这个方式的一个基本的特点;
就是我们的这个线程池里面随着这个线程的任务的增加,我们的这个线程池里面的这个线程就会被根据需要自动的创建出来;
创建出来这个线程也不会着急销毁,会在这个池子里面被保留一段时间,以备我们的随时使用;这个主要就是这个方法里面的这个cache缓存,就是用过之后不会很着急的释放,方便后续的使用;
2.5线程池的模拟实现的逻辑
- 创建消息队列;
- 通过submit方法把我们的这个任务添加到这个消息队列里面去;
- 创建出来线程,并且去执行这个队列里面的任务;
3.ThreadPoolExecutor类的介绍
这个类是干什么的,其实我们上面介绍的三个创建线程池的方法,底层都是对于这个ThreadPoolExecutor这个类进行的封装,这个类里面有很多你的这个功能,有很多的参数,标准库里面的工厂方法其实就是让这个类填充不同的参数达到的不同的效果;
3.1构造方法
下面的这个就是我们的这个类里面的很常见的构造方法:
其中这个官方文档里面的这个第四个构造方法的参数是最全面的,我们就以这个第四个进行介绍;

corePoolSize就是指的这个核心的线程数量;
maxinumPoolSize表示的就是这个最多的线程数量;
我们的这个线程池里面的这个线程的数量可以进行这个动态的调整,但是这个数量必须要介于这个核心线程数量和这个最大线程数量之间;
keepAliveSize表示的就是这个最大的线程数量的存活的时间,其中这个后面的这个unit就是我们的这个存活时间的单位;
blockingquene就是一个阻塞队列,作用就是用来存储这个线程池里面的这个线程任务(我们的这个地方的队列可以使用优先级队列,也可以不使用优先级队列);
threadFactory就是这个工厂类,也是我们的工厂模式的体现,这个工厂类负责线程的创建,使用工厂类去创建线程,主要是想要在这个线程的创建过程中,对于这个线程的属性进行相应的控制;
handled这个参数就是线程池的拒绝策略,就是我们的这个线程池里面的这个线程的数量已经都达到了这个maxnum了,这个时候我们还是往这个线程池里面去添加线程,这个时候就会被线程池拒绝;
3.2四种拒绝的策略
1.直接抛出来一场进行处理;
2.添加的这个新的任务,由这个添加任务的这个线程自己负责执行;
3.丢弃我们的这个任务队列里面的这个最老的一个任务;
4.丢弃当前的这个新被添加进来的任务;

这个线程自己负责执行;
3.丢弃我们的这个任务队列里面的这个最老的一个任务;
4.丢弃当前的这个新被添加进来的任务;