时间戳记录API
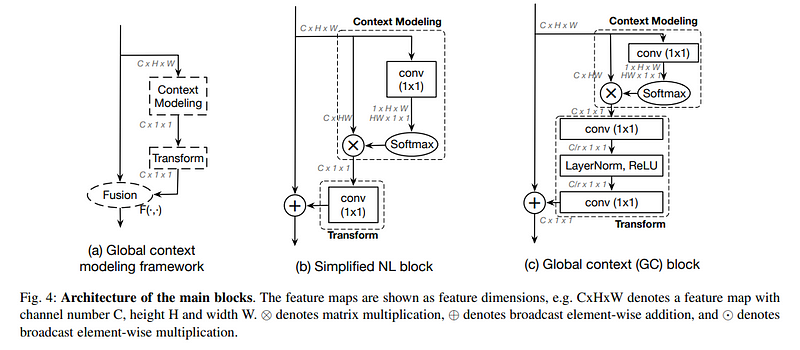
使用constant内存,究竟带来多少性能提升,如何尽可能精确的测量GPU完成某项任务所花的时间?CUDA提供了cudaEvent_t 以及 CUDA event API来做运行时间的测量。
cudaError_t cudaEventCreate(cudaEvent_t *event);
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0);
cudaError_t cudaEventSynchronize(cudaEvent_t event);
cudaError_t cudaEventElapsedTime(float *ms, cudaEvent_t start, cudaEvent_t end);
cudaError_t cudaEventDestroy(cudaEvent_t event);
CUDA的event本质上是一个时间戳,用户通过调用cudaEventRecord指定记录当前时刻。完成某一时刻记录只需三步:
cudaEvent_t start;
cudaEventCreate(&start);
cudaEventRecord(start, 0);不再使用时,也不要忘了清除event。
cudaEventDestroy(start);要测量某一块代码运行的时间,除了记录起点的时间点,还需要记录结束的时间点。将两者相减,即可获得运行时间。需要注意的是,当我们在结束点调用cudaEventRecord后,并不能保证event的值马上就可用了。cudaEventRecord是异步,它没有等到GPU更新event的时间就返回了,所以在使用event之前,必须调用cudaEventSynchronize,确保event有效。
event记录的时间戳的差值由CUDA API函数cudaEventElapsedTime来计算,结果由第一个参数传回。
添加时间测量到光线追踪
有了前面的经验,整个代码不需要做进一步解释了。贴出没有使用constant内存和使用了constant内存的代码,做个对照。
non constant内存代码:
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
#define DIM 1024
#define rnd( x ) (x * rand() / RAND_MAX)
#define INF 2e10f
struct Sphere {
float r,b,g;
float radius;
float x,y,z;
__device__ float hit( float ox, float oy, float *n ) {
float dx = ox - x;
float dy = oy - y;
if (dx*dx + dy*dy < radius*radius) {
float dz = sqrtf( radius*radius - dx*dx - dy*dy );
*n = dz / sqrtf( radius * radius );
return dz + z;
}
return -INF;
}
};
#define SPHERES 20
__global__ void kernel( Sphere *s, unsigned char *ptr ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float ox = (x - DIM/2);
float oy = (y - DIM/2);
float r=0, g=0, b=0;
float maxz = -INF;
for(int i=0; i<SPHERES; i++) {
float n;
float t = s[i].hit( ox, oy, &n );
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset*4 + 0] = (int)(r * 255);
ptr[offset*4 + 1] = (int)(g * 255);
ptr[offset*4 + 2] = (int)(b * 255);
ptr[offset*4 + 3] = 255;
}
// globals needed by the update routine
struct DataBlock {
unsigned char *dev_bitmap;
Sphere *s;
};
int main( void ) {
DataBlock data;
// capture the start time
cudaEvent_t start, stop;
HANDLE_ERROR( cudaEventCreate( &start ) );
HANDLE_ERROR( cudaEventCreate( &stop ) );
HANDLE_ERROR( cudaEventRecord( start, 0 ) );
CPUBitmap bitmap( DIM, DIM, &data );
unsigned char *dev_bitmap;
Sphere *s;
// allocate memory on the GPU for the output bitmap
HANDLE_ERROR( cudaMalloc( (void**)&dev_bitmap,
bitmap.image_size() ) );
// allocate memory for the Sphere dataset
HANDLE_ERROR( cudaMalloc( (void**)&s,
sizeof(Sphere) * SPHERES ) );
// allocate temp memory, initialize it, copy to
// memory on the GPU, then free our temp memory
Sphere *temp_s = (Sphere*)malloc( sizeof(Sphere) * SPHERES );
for (int i=0; i<SPHERES; i++) {
temp_s[i].r = rnd( 1.0f );
temp_s[i].g = rnd( 1.0f );
temp_s[i].b = rnd( 1.0f );
temp_s[i].x = rnd( 1000.0f ) - 500;
temp_s[i].y = rnd( 1000.0f ) - 500;
temp_s[i].z = rnd( 1000.0f ) - 500;
temp_s[i].radius = rnd( 100.0f ) + 20;
}
HANDLE_ERROR( cudaMemcpy( s, temp_s,
sizeof(Sphere) * SPHERES,
cudaMemcpyHostToDevice ) );
free( temp_s );
// generate a bitmap from our sphere data
dim3 grids(DIM/16,DIM/16);
dim3 threads(16,16);
kernel<<<grids,threads>>>( s, dev_bitmap );
// copy our bitmap back from the GPU for display
HANDLE_ERROR( cudaMemcpy( bitmap.get_ptr(), dev_bitmap,
bitmap.image_size(),
cudaMemcpyDeviceToHost ) );
// get stop time, and display the timing results
HANDLE_ERROR( cudaEventRecord( stop, 0 ) );
HANDLE_ERROR( cudaEventSynchronize( stop ) );
float elapsedTime;
HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,
start, stop ) );
printf( "Time to generate: %3.1f ms\n", elapsedTime );
HANDLE_ERROR( cudaEventDestroy( start ) );
HANDLE_ERROR( cudaEventDestroy( stop ) );
HANDLE_ERROR( cudaFree( dev_bitmap ) );
HANDLE_ERROR( cudaFree( s ) );
// display
bitmap.display_and_exit();
}
constant内存代码:
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_bitmap.h"
#define DIM 1024
#define rnd( x ) (x * rand() / RAND_MAX)
#define INF 2e10f
struct Sphere {
float r,b,g;
float radius;
float x,y,z;
__device__ float hit( float ox, float oy, float *n ) {
float dx = ox - x;
float dy = oy - y;
if (dx*dx + dy*dy < radius*radius) {
float dz = sqrtf( radius*radius - dx*dx - dy*dy );
*n = dz / sqrtf( radius * radius );
return dz + z;
}
return -INF;
}
};
#define SPHERES 20
__constant__ Sphere s[SPHERES];
__global__ void kernel( unsigned char *ptr ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float ox = (x - DIM/2);
float oy = (y - DIM/2);
float r=0, g=0, b=0;
float maxz = -INF;
for(int i=0; i<SPHERES; i++) {
float n;
float t = s[i].hit( ox, oy, &n );
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
maxz = t;
}
}
ptr[offset*4 + 0] = (int)(r * 255);
ptr[offset*4 + 1] = (int)(g * 255);
ptr[offset*4 + 2] = (int)(b * 255);
ptr[offset*4 + 3] = 255;
}
// globals needed by the update routine
struct DataBlock {
unsigned char *dev_bitmap;
};
int main( void ) {
DataBlock data;
// capture the start time
cudaEvent_t start, stop;
HANDLE_ERROR( cudaEventCreate( &start ) );
HANDLE_ERROR( cudaEventCreate( &stop ) );
HANDLE_ERROR( cudaEventRecord( start, 0 ) );
CPUBitmap bitmap( DIM, DIM, &data );
unsigned char *dev_bitmap;
// allocate memory on the GPU for the output bitmap
HANDLE_ERROR( cudaMalloc( (void**)&dev_bitmap,
bitmap.image_size() ) );
// allocate temp memory, initialize it, copy to constant
// memory on the GPU, then free our temp memory
Sphere *temp_s = (Sphere*)malloc( sizeof(Sphere) * SPHERES );
for (int i=0; i<SPHERES; i++) {
temp_s[i].r = rnd( 1.0f );
temp_s[i].g = rnd( 1.0f );
temp_s[i].b = rnd( 1.0f );
temp_s[i].x = rnd( 1000.0f ) - 500;
temp_s[i].y = rnd( 1000.0f ) - 500;
temp_s[i].z = rnd( 1000.0f ) - 500;
temp_s[i].radius = rnd( 100.0f ) + 20;
}
HANDLE_ERROR( cudaMemcpyToSymbol( s, temp_s,
sizeof(Sphere) * SPHERES) );
free( temp_s );
// generate a bitmap from our sphere data
dim3 grids(DIM/16,DIM/16);
dim3 threads(16,16);
kernel<<<grids,threads>>>( dev_bitmap );
// copy our bitmap back from the GPU for display
HANDLE_ERROR( cudaMemcpy( bitmap.get_ptr(), dev_bitmap,
bitmap.image_size(),
cudaMemcpyDeviceToHost ) );
// get stop time, and display the timing results
HANDLE_ERROR( cudaEventRecord( stop, 0 ) );
HANDLE_ERROR( cudaEventSynchronize( stop ) );
float elapsedTime;
HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,
start, stop ) );
printf( "Time to generate: %3.1f ms\n", elapsedTime );
HANDLE_ERROR( cudaEventDestroy( start ) );
HANDLE_ERROR( cudaEventDestroy( stop ) );
HANDLE_ERROR( cudaFree( dev_bitmap ) );
// display
bitmap.display_and_exit();
}
以下是我在RTX 2060上运行得到的结果:
没有使用constant内存

使用constant内存之后

测试时数据有浮动。
我将球体个数改成400个后,两者的数据分别为~4ms, ~5ms。大约能带来20%左右的性能提升。