Jacobi Solver with HIP and OpenMP offloading — ROCm Blogs (amd.com)

作者:Asitav Mishra, Rajat Arora, Justin Chang
发布日期:2023年9月15日
Jacobi方法作为求解偏微分方程(PDE)的基本迭代线性求解器在高性能计算(HPC)应用中具有广泛的应用。通过数值方法(如有限差分法、有限体积法、有限元法或其他方法)对PDE进行离散化,会产生大型稀疏方程组。像Jacobi这样的静止迭代法可以利用现代异构分层系统(包括CPU和GPU)的优势,因为它更适合并行化并且相比传统的直接方法需要更少的内存。Jacobi迭代涉及大量重复的矩阵-向量乘积操作,在很大程度上限制了每次迭代中所有组件之间的通信。这使得Jacobi方法在GPU卸载方面更具优势。
在这篇博客中,我们探索了使用HIP和OpenMP目标指令进行GPU卸载的方法,并讨论了它们在实现成本和性能方面的相对优劣。
注意: 尽管大多数HPC应用今天都使用消息传递接口(MPI)进行分布式内存并行化,但在这篇博客中,我们仅考虑Jacobi方法的单进程实现以进行演示。
Jacobi 迭代方法
为了讨论 Jacobi 迭代方法,我们考虑一个具有 Dirichlet 边界条件的二维领域上的偏微分方程(Partial Differential Equation, PDE),以求解泊松方程:−∇²u(x,y) = f,这是一个广义拉普拉斯方程。在这里,u(x,y) 是域内的光滑函数。方程使用有限差分法 [1] 在笛卡尔坐标系下进行离散,采用 5 点模板:
上述有限差分拉普拉斯算子导致了矢量未知数 u 上的稀疏矩阵算子 A:Au = f。这里:
如果矩阵分解为对角线部分(D)、下三角部分(L)和上三角部分(U)(A = D + L + U),则 Jacobi 迭代方法可以表示为:
这里,k 指的是迭代次数。 的值是初始条件。
Jacobi代码结构
串行(CPU)Jacobi求解器的主要组件包括:
-
设置Jacobi对象
-
CreateMesh() -
InitializeData()
-
-
执行Jacobi方法
-
Laplacian() -
BoundaryConditions() -
Update() -
Norm()
-
以下代码显示了Jacobi求解器程序。在代码中,Jacobi_t Jacobi(mesh); 完成了Jacobi对象的设置,而 Jacobi.Run() 执行了Jacobi求解器。
int main(int argc, char ** argv)
{
mesh_t mesh;
// 从命令行参数中提取拓扑结构和域维度
ParseCommandLineArguments(argc, argv, mesh);
Jacobi_t Jacobi(mesh);
Jacobi.Run();
return STATUS_OK;
}设置Jacobi对象
Jacobi对象由两个主要部分组成:
-
设置Jacobi对象
-
CreateMesh() -
InitializeData()
-
例程 CreateMesh() 创建一个具有均匀网格间距的二维笛卡尔网格——参见图1。例程 InitializeData() 初始化主机变量u(代码中的 h_U),矩阵-向量乘积Au(h_AU),右侧向量f(h_RHS),以及残差向量f−Au(h_RES)。它还为这些变量应用边界条件。
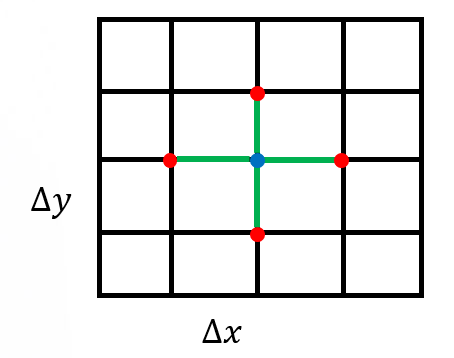
图1:用于离散化计算域的均匀矩形网格
执行雅可比方法
雅可比求解器的主要执行包括以下函数:
-
运行雅可比方法
-
Laplacian() -
BoundaryConditions() -
Update() -
Norm()
-
下面的代码展示了每个雅可比迭代中函数调用的顺序:
// 在雅可比方法中使用的标量因子
const dfloat factor = 1/(2.0/(mesh.dx*mesh.dx) + 2.0/(mesh.dy*mesh.dy));
const dfloat _1bydx2 = 1.0/(mesh.dx*mesh.dx);
const dfloat _1bydy2 = 1.0/(mesh.dy*mesh.dy);
while ((iterations < JACOBI_MAX_LOOPS) && (residual > JACOBI_TOLERANCE))
{
// 计算拉普拉斯算子
Laplacian(mesh, _1bydx2, _1bydy2, h_U, h_AU);
// 应用边界条件
BoundaryConditions(mesh, _1bydx2, _1bydy2, h_U, h_AU);
// 更新解
Update(mesh, factor, h_RHS, h_AU, h_RES, h_U);
// 计算残差 = ||U||
residual = Norm(mesh, h_RES);
++iterations;
}Laplacian()函数执行如前所述的主要拉普拉斯算子运算,代码如下:
// AU_i,j = (-U_i+1,j + 2U_i,j - U_i-1,j)/dx^2 +
// (-U_i,j+1 + 2U_i,j - U_i,j-1)/dy^2
void Laplacian(mesh_t& mesh,
const dfloat _1bydx2,
const dfloat _1bydx2,
const dfloat * U,
dfloat * AU) {
int stride = mesh.Nx;
int localNx = mesh.Nx - 2;
int localNy = mesh.Ny - 2;
for (int j=0;j<localNy;j++) {
for (int i=0;i<localNx;i++) {
const int id = (i+1) + (j+1)*stride;
const int id_l = id - 1;
const int id_r = id + 1;
const int id_d = id - stride;
const int id_u = id + stride;
AU[id] = (-U[id_l] + 2*U[id] - U[id_r])/(dx*dx) +
(-U[id_d] + 2*U[id] - U[id_u])/(dy*dy);
}
}
}BoundaryConditions()函数用于将边界条件应用于Au项,代码如下:
void BoundaryConditions(mesh_t& mesh,
const dfloat _1bydx2,
const dfloat _1bydy2,
dfloat* U,
dfloat* AU) {
const int Nx = mesh.Nx;
const int Ny = mesh.Ny;
for (int id=0;id<2*Nx+2*Ny-2;id++) {
//根据id的大小获取节点的(i,j)坐标
int i, j;
if (id < Nx) { //底部
i = id;
j = 0;
} else if (id<2*Nx) { //顶部
i = id - Nx;
j = Ny-1;
} else if (id < 2*Nx + Ny-1) { //左侧
i = 0;
j = id - 2*Nx + 1;
} else { //右侧
i = Nx-1;
j = id - 2*Nx - Ny + 2;
}
const int iid = i+j*Nx;
const dfloat U_d = (j==0) ? 0.0 : U[iid - Nx];
const dfloat U_u = (j==Ny-1) ? 0.0 : U[iid + Nx];
const dfloat U_l = (i==0) ? 0.0 : U[iid - 1];
const dfloat U_r = (i==Nx-1) ? 0.0 : U[iid + 1];
AU[iid] = (-U_l + 2*U[iid] - U_r)*_1bydx2 +
(-U_d + 2*U[iid] - U_u)*_1bydy2;
}
}雅可比求解器的核心在于`Update()`函数,该函数执行雅可比迭代:
// U = U + D^{-1}*(RHS - AU)
void Update(mesh_t& mesh,
const dfloat factor,
dfloat* RHS,
dfloat* AU,
dfloat* RES,
dfloat* U)
{
const int N = mesh.N;
for (int id=0;id<N;id++)
{
const dfloat r_res = RHS[id] - AU[id];
RES[id] = r_res;
U[id] += r_res*factor;
}
}Norm()函数是执行归约运算并返回用于检查求解器收敛性的标量残差的主函数:
dfloat Norm(mesh_t& mesh, dfloat *U) {
dfloat norm = 0;
const int N = mesh.N;
const dfloat dx = mesh.dx;
const dfloat dy = mesh.dy;
for (int id=0; id < N; id++) {
*norm2 += U[id] * U[id] * dx * dy;
}
return sqrt(norm)/N;
}接下来的两个部分将描述将此求解器移植到GPU上的两种可能方法。
使用 HIP 的 GPU 卸载
首先,我们考虑使用 HIP 进行端口移植,将 Jacobi 求解器卸载到 GPU 上。我们编写了 HIP 内核来移植上述四个主要代码区域。请注意,为了获得最优化的性能,我们为所有内核使用了 256 (BLOCK_SIZE) 的启动边界。以下代码片段显示了每次 Jacobi 迭代中的函数调用,其顺序与串行代码相同:
// Jacobi 方法中使用的标量因子
const dfloat factor = 1/(2.0/(mesh.dx*mesh.dx) + 2.0/(mesh.dy*mesh.dy));
const dfloat _1bydx2 = 1.0/(mesh.dx*mesh.dx);
const dfloat _1bydy2 = 1.0/(mesh.dy*mesh.dy);
auto timerStart = std::chrono::high_resolution_clock::now();
while ((iterations < JACOBI_MAX_LOOPS) && (residual > JACOBI_TOLERANCE))
{
// 计算拉普拉斯算子
Laplacian(mesh, _1bydx2, _1bydy2, HD_U, HD_AU);
// 应用边界条件
BoundaryConditions(mesh, _1bydx2, _1bydy2, HD_U, HD_AU);
//更新解
Update(mesh, factor, HD_RHS, HD_AU, HD_RES, HD_U);
// 计算残差 = ||U||
residual = Norm(mesh, HD_RES);
++iterations;
}一些内核启动配置在 InitializeData() 中设置,如以下代码片段所示:
// ...
// 内核启动配置
mesh.block.x = BLOCK_SIZE;
mesh.grid.x = std::ceil(static_cast<double>(mesh.Nx * mesh.Ny) / mesh.block.x);
mesh.grid2.x = std::ceil((2.0*mesh.Nx+2.0*mesh.Ny-2.0)/mesh.block.x);
// ...LaplacianKernel() 和启动该内核的 Laplacian() 例程的代码如下:
__global__
__launch_bounds__(BLOCK_SIZE)
void LaplacianKernel(const int localNx,
const int localNy,
const int stride,
const dfloat fac_dx2,
const dfloat fac_dy2,
const dfloat * U,
dfloat * AU)
{
int tid = GET_GLOBAL_ID_0;
if (tid > localNx + localNy * stride || tid < stride + 1)
return;
const int tid_l = tid - 1;
const int tid_r = tid + 1;
const int tid_d = tid - stride;
const int tid_u = tid + stride;
__builtin_nontemporal_store((-U[tid_l] + 2*U[tid] - U[tid_r])*fac_dx2 +
(-U[tid_d] + 2*U[tid] - U[tid_u])*fac_dy2, &(AU[tid]));
}
void Laplacian(mesh_t& mesh,
const dfloat _1bydx2,
const dfloat _1bydy2,
dfloat* U,
dfloat* AU)
{
int stride = mesh.Nx;
int localNx = mesh.Nx-2;
int localNy = mesh.Ny-2;
LaplacianKernel<<<mesh.grid,mesh.block>>>(localNx, localNy, stride, _1bydx2, _1bydy2, U, AU);
}内核 BoundaryConditionsKernel() 和其启动函数如下所示:
__global__
__launch_bounds__(BLOCK_SIZE)
void BoundaryConditionsKernel(const int Nx,
const int Ny,
const int stride,
const dfloat fac_dx2,
const dfloat fac_dy2,
const dfloat * U,
dfloat * AU)
{
const int id = GET_GLOBAL_ID_0;
if (id < 2*Nx+2*Ny-2)
{
//根据 id 的大小获取节点的 (i,j) 坐标
int i = Nx-1;
int j = id - 2*Nx - Ny + 2;
if (id < Nx)
{ //底部
i = id; j = 0;
}
else if (id<2*Nx)
{ //顶部
i = id - Nx; j = Ny-1;
}
else if (id < 2*Nx + Ny-1)
{ //左侧
i = 0; j = id - 2*Nx + 1;
}
const int iid = i+j*stride;
const dfloat U_d = (j==0) ? 0.0 : U[iid - stride];
const dfloat U_u = (j==Ny-1) ? 0.0 : U[iid + stride];
const dfloat U_l = (i==0) ? 0.0 : U[iid - 1];
const dfloat U_r = (i==Nx-1) ? 0.0 : U[iid + 1];
__builtin_nontemporal_store((-U_l + 2*U[iid] - U_r)*fac_dx2 +
(-U_d + 2*U[iid] - U_u)*fac_dy2, &(AU[iid]));
}
}
void BoundaryConditions(mesh_t& mesh,
const dfloat _1bydx2,
const dfloat _1bydy2,
dfloat* U,
dfloat* AU) {
const int Nx = mesh.Nx;
const int Ny = mesh.Ny;
BoundaryConditionsKernel<<<mesh.grid2,mesh.block>>>(Nx, Ny, Nx, _1bydx2, _1bydy2, U, AU);
}以下代码展示了 UpdateKernel() 的 HIP 实现:
__global__
__launch_bounds__(BLOCK_SIZE)
void UpdateKernel(const int N,
const dfloat factor,
const dfloat *__restrict__ RHS,
const dfloat *__restrict__ AU,
dfloat *__restrict__ RES,
dfloat *__restrict__ U)
{
int tid = GET_GLOBAL_ID_0;
dfloat r_res;
for (int i = tid; i < N; i += gridDim.x * blockDim.x)
{
r_res = RHS[i] - AU[i];
RES[i] = r_res;
U[i] += r_res*factor;
}
}
void Update(mesh_t& mesh,
const dfloat factor,
dfloat* RHS,
dfloat* AU,
dfloat* RES,
dfloat* U)
{
UpdateKernel<<<mesh.grid,mesh.block>>>(mesh.N, factor, RHS, AU, RES, U);
}以下代码展示了 NormKernel() 的 HIP 实现,该实现基于 BabelStream 中的 HIP dot 实现:
#define NORM_BLOCK_SIZE 512
#define NORM_NUM_BLOCKS 256
__global__
__launch_bounds__(NORM_BLOCK_SIZE)
void NormKernel(const dfloat * a, dfloat * sum, int N)
{
__shared__ dfloat smem[NORM_BLOCK_SIZE];
int i = GET_GLOBAL_ID_0;
const size_t si = GET_LOCAL_ID_0;
smem[si] = 0.0;
for (; i < N; i += NORM_BLOCK_SIZE * NORM_NUM_BLOCKS)
smem[si] += a[i] * a[i];
for (int offset = NORM_BLOCK_SIZE >> 1; offset > 0; offset >>= 1)
{
__syncthreads();
if (si < offset) smem[si] += smem[si+offset];
}
if (si == 0)
sum[GET_BLOCK_ID_0] = smem[si];
}
void NormSumMalloc(mesh_t &mesh)
{
hipHostMalloc(&mesh.norm_sum, NORM_NUM_BLOCKS*sizeof(dfloat), hipHostMallocNonCoherent);
}
dfloat Norm(mesh_t& mesh, dfloat *U)
{
dfloat norm = 0.0;
const int N = mesh.N;
const dfloat dx = mesh.dx;
const dfloat dy = mesh.dy;
NormKernel<<<NORM_NUM_BLOCKS,NORM_BLOCK_SIZE>>>(U, mesh.norm_sum, N);
hipDeviceSynchronize();
for (int id=0; id < NORM_NUM_BLOCKS; id++)
norm += mesh.norm_sum[id];
return sqrt(norm*dx*dy)*mesh.invNtotal;
}请注意,缓冲区 mesh.norm_sum 是非一致性的固定内存,这意味着它被映射到 GPU 的地址空间中。有关这种内存的更详细讨论,请参阅这篇文章。参数 NORM_BLOCK_SIZE 和 NORM_NUM_BLOCKS 可以且应该根据您的硬件进行优化。
下表总结了 Jacobi 求解器中的主要内核在 HIP 端口化后的每次迭代耗时。网格大小为 4096×4096。在 1000 次迭代中,整个过程的总壁钟时间为 858 毫秒,单个 MI250 GPU 核心上实现了 332 GFLOP/s 的计算性能。最耗时的代码区域是 Jacobi 的 Update() 例程。
| 内核 | 平均时间 (ms) | 百分比 |
|---|---|---|
| Update | 0.51 | 60.9 |
| Laplacian | 0.22 | 25.7 |
| Norm | 0.10 | 12.3 |
| BoundaryConditions | 0.01 | 0.9 |
使用OpenMP进行GPU卸载
在本节中,我们探讨了OpenMP卸载。我们考虑了结构化和非结构化的目标数据映射方法。使用 -fopenmp标志的clang++编译器用于构建openmp目标卸载区域。更多详情可以在codes/Makefile中找到。例如,以下命令显示了如何编译Jacobi.cpp文件:
/opt/rocm/llvm/bin/clang++ -Ofast -g -fopenmp --offload-arch=gfx90a -c Jacobi.cpp -o Jacobi.o结构化目标数据映射
让我们考虑在HIP移植的Jacobi求解器中观察到的最昂贵的代码区域,Update()。一种简单的OpenMP目标卸载方法如下:
void Update(mesh_t& mesh,
const dfloat factor,
dfloat* RHS,
dfloat* AU,
dfloat* RES,
dfloat* U)
{
const int N = mesh.N;
#pragma omp target data map(to:RHS[0:N],AU[0:N]) map(from:RES[0:N]) map(tofrom:U[0:N])
#pragma omp target teams distribute parallel for
for (int id=0;id<N;id++)
{
const dfloat r_res = RHS[id] - AU[id];
RES[id] = r_res;
U[id] += r_res*factor;
}
}状态变量被映射到设备区域,并在目标区域中调用Jacobi更新函数。这是一个结构化目标映射构造的示例。对于Laplacian和Norm函数,也进行了类似的结构化目标映射。
void Laplacian(mesh_t& mesh,
const dfloat _1bydx2,
const dfloat _1bydy2,
dfloat* U,
dfloat* AU)
{
int stride = mesh.Nx;
int localNx = mesh.Nx-2;
int localNy = mesh.Ny-2;
#pragma omp target data map(to:U[0:mesh.N]) map(tofrom:AU[0:mesh.N])
#pragma omp target teams distribute parallel for collapse(2)
for (int j=0;j<localNy;j++) {
for (int i=0;i<localNx;i++) {
const int id = (i+1) + (j+1)*stride;
const int id_l = id - 1;
const int id_r = id + 1;
const int id_d = id - stride;
const int id_u = id + stride;
AU[id] = (-U[id_l] + 2*U[id] - U[id_r])*_1bydx2 +
(-U[id_d] + 2*U[id] - U[id_u])*_1bydy2;
}
}
}
dfloat Norm(mesh_t& mesh, dfloat *U)
{
dfloat norm = 0.0;
const int N = mesh.N;
const dfloat dx = mesh.dx;
const dfloat dy = mesh.dy;
#pragma omp target data map(to: U[0:mesh.N])
#pragma omp target teams distribute parallel for reduction(+:norm)
for (int id=0; id < N; id++) {
norm += U[id] * U[id] * dx * dy;
}
return sqrt(norm)/N;
}然而,这种实现导致求解器的性能非常差,每次主循环迭代需要51.4毫秒,而使用HIP则只需要1.1毫秒。这大约慢了超过46倍。查看图2,我们发现大量时间花费在`hsa_signal_wait_scacquire`和特别是`async-copy`内核中,这是由于每次迭代所需的映射。
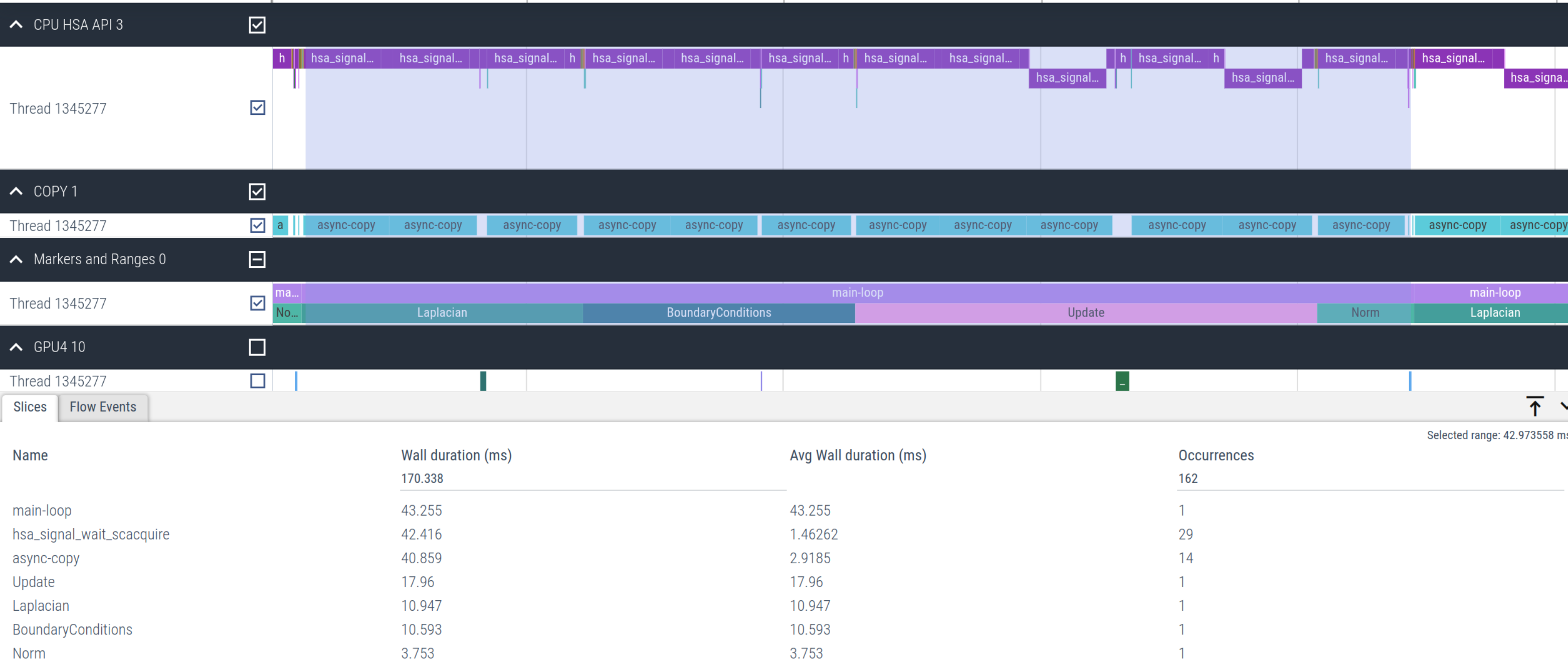
图 2:使用结构化目标数据映射的Jacobi卸载内核的时间轴
非结构化 target 数据映射
我们注意到,Jacobi 求解器所需的大多数状态变量可以驻留在设备上。仅在输出最终的残差和需要状态解的数据时,才需要将数据映射到主机(CPU)。因此,我们可以切换到_非结构化_目标数据映射构造,它确保数据在 target enter data 和 target exit data 映射构造之间驻留在设备上。在 Jacobi 迭代之前执行主机到设备的拷贝,并在循环结束之后释放设备数据,如下所示:
void Jacobi_t::Run()
{
const int N = mesh.N;
#pragma omp target enter data map(to: mesh,h_U[0:N],h_AU[0:N],h_RES[0:N],h_RHS[0:N])
...
while ((iterations < JACOBI_MAX_LOOPS) && (residual > JACOBI_TOLERANCE))
{
Laplacian(mesh, _1bydx2, _1bydy2, HD_U, HD_AU);
BoundaryConditions(mesh, _1bydx2, _1bydy2, HD_U, HD_AU);
Update(mesh, factor, HD_RHS, HD_AU, HD_RES, HD_U);
residual = Norm(mesh, HD_RES);
++iterations;
}
...
#pragma omp target exit data map(release: h_U[0:N],h_AU[0:N],h_RES[0:N],h_RHS[0:N])
}这避免了在每次迭代中需要对主机到设备和设备到主机的数据进行重复映射,这些在_结构化_target数据映射构造在所有例程中都需要:Laplacian、BoundaryConditions、Update 和 Norm。这意味着在这些例程中移除了 #pragma omp target data map() 构造。
下面代码示例了现在更新的 Norm 函数在目标区域不再有结构化映射构造。这里,状态向量 U 在 Jacobi 求解器开始时已经使用非结构化数据映射构造映射到设备。
dfloat Norm(mesh_t& mesh, dfloat *U)
{
dfloat norm = 0.0;
const int N = mesh.N;
const dfloat dx = mesh.dx;
const dfloat dy = mesh.dy;
#pragma omp target teams distribute parallel for reduction(+:norm)
for (int id=0; id < N; id++) {
norm += U[id] * U[id] * dx * dy;
}
return sqrt(norm)/N;
}下图3展示了主要的 Jacobi 求解器内核的时间轴。图中清楚地显示,与图 2 中的第一次简单卸载实现相比,总的 hsa_signal_wait_scacquire 内核调用次数显著减少。

图 3:使用非结构化映射优化 Jacobi 卸载内核的时间轴
下表总结了使用 Clang 编译器进行 OpenMP 卸载实现的 Jacobi 求解器主要内核的时间。网格尺寸为4096×4096,与 HIP 版本一致。在一千次迭代中的总墙时钟时间为999毫秒,与早期在 MI250 GPU 上观察到的 HIP 实现值非常接近。285 GFLOPs 的计算性能与 HIP 实现中观察到的值相当。总体而言,使用 OpenMP 卸载的主要代码区域计算时间与 HIP 端口化所得的数值非常相近。
| 内核 | 平均时间 (ms) | 百分比 |
|---|---|---|
| Update | 0.51 | 57.9 |
| Laplacian | 0.25 | 27.6 |
| Norm | 0.11 | 12.2 |
| BoundaryConditions | 0.02 | 2.2 |
HIP 与 OpenMP Offload
由于稀疏矩阵操作的雅可比求解器(其算术强度 AI = FLOPs/带宽约为 0.17)处于内存受限状态,因此我们对比了 HIP 和 OpenMP offload 实现中内核实现的内存带宽(BW)。下表对比了 HIP 和 OpenMP offload 实现的 HBM 带宽(GB/s)值。
| 内核 | HIP HBM 带宽(GB/s) | OpenMP Offload HBM 带宽 (GB/s) |
|---|---|---|
| 更新Update | 1306 | 1297 |
| 拉普拉斯Laplacian | 1240 | 1091 |
| 范数Norm | 1325 | 1239 |
| 边界条件BoundaryConditions | 151 | 50 |
大多数内核的带宽值非常接近 MI250 的可实现峰值带宽(约 1300-1400 GB/s)。边界条件的工作量太小,无法使 GPU 饱和,因此值较小。下图(图4)展示了使用 HIP 和 OpenMP offload 实现的更新内核的屋顶线(Roofline [3] )。从屋顶线图中可以看出,更新内核在两种实现中都非常接近内存受限状态下的屋顶线。这与上表中的 HBM 数据一致。

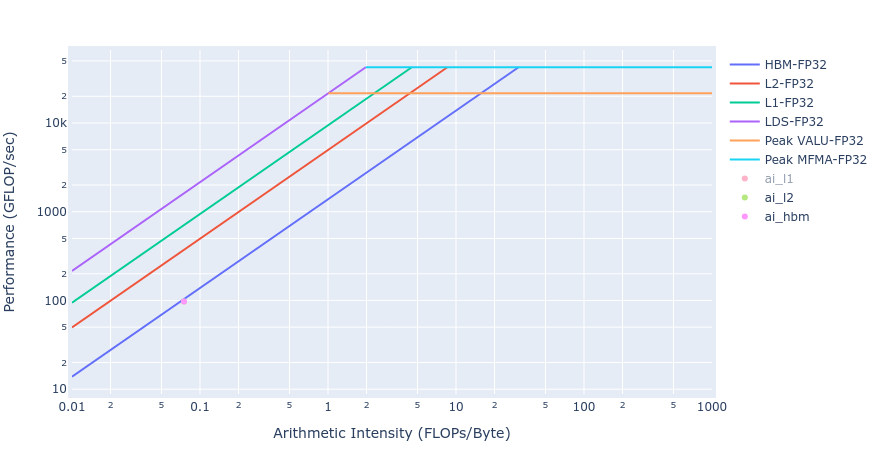
图4: 使用 HIP(左)和 OpenMP offload(右)的更新内核屋顶线
类似的观察结果也适用于拉普拉斯内核中,从下图(图5)展示的两种 GPU offload 实现的屋顶线可以看出。
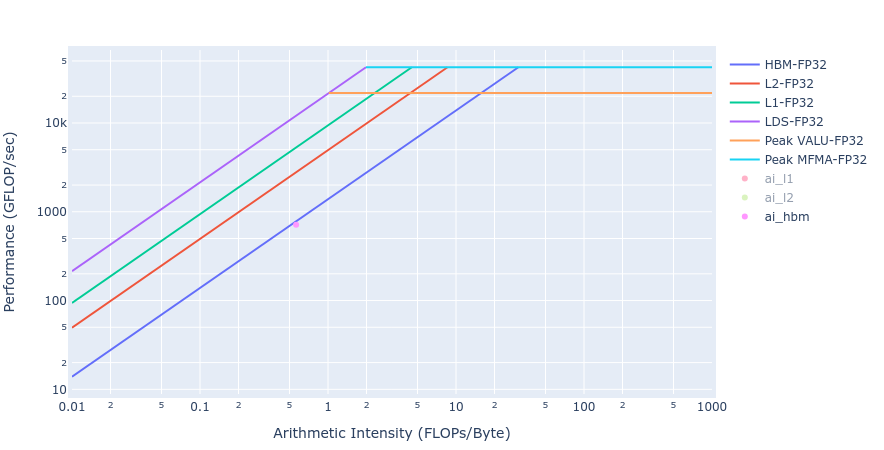

图5: 使用 HIP(左)和 OpenMP offload(右)的拉普拉斯内核屋顶线
结论
在这篇博客文章中,我们展示了使用 HIP 和 OpenMP 目标卸载进行有限差分 Jacobi 求解器的 GPU 卸载。HIP 实现需要将主机代码替换为新的 HIP 内核,并优化内核启动参数,包括线程块和网格大小以及启动界限。而 OpenMP 卸载实现则是基于指令,仅需对现有主机代码库进行较少的修改。对于所考虑的问题规模,OpenMP 卸载可以实现与 HIP GPU 移植相媲美甚至有时更好的计算性能和带宽指标,而编码工作量则大大减少。这说明了像 OpenMP 卸载这样的指令集 GPU 移植相较于需要重写代码的 HIP 移植方法所能提供的优势。值得一提的是,对于更复杂的应用程序,OpenMP 可能在优化目标卸载结构和参数方面提供的选择有限,从而限制了额外的性能提升。
未来,我们将跟进这篇博客文章,发布 Jacobi 求解器的 Fortran OpenMP 卸载版本。
作者要感谢 Brian Cornille 和 Mahdieh Ghazimirsaeed 对文稿的有益评论和反馈。
附带代码示例
如果您有任何问题或评论,请在 GitHub 讨论区 与我们联系。
[1]
请参见 有限差分 博客文章。
[2]
结果是通过 ROCM v.5.6.0-67 获得的。这些数据并非经过验证的性能数据,仅用于展示代码修改带来的相对性能提升。实际性能结果将依赖于多个因素,包括系统配置和环境设置。
[3]
这些屋顶线图是使用 AMD 的 Omniperf 工具获取的。