一.http协议的介绍
http应用层协议
超文本传输协议(比如网站上面的超链接)
作用:构建网站服务器,可以在客户端与网站服务器之间传输文本数据。
浏览器会将文本数据解析成对应的图片,视频进行展示。
1.网站类型
静态网页/静态网站
指的是所有的资源都是写死的,不管什么人什么时候去访问网站的时候,所有的数据都是一摸一样的,都是事先写死的。
任何一个网站都是由很多个网页组成的,开发语言是html语言,js。jquery都是写静态网页的,
动态网页本质上就是一段程序代码,可以根据访问者传递的参数不同展示不同的结果。
比如说购物车或者是需要登录的QQ邮箱,
开发语言:php,一般写出来的网页文件都是以*.php结尾的文件,
java也可以用来做动态网站开发,一般都是以*.jsp结尾的文件,
现在市面上的网页都是由静态网页和动态网页组合的
2.cookie/session
这两样东西的作用是一样的,让网站服务器来识别客户端身份的,
作用:识别客户端的身份,是否为一个已经登录的客户端。
比如126的网站服务器,同一时间点可能会有N多人访问这个服务器,客户端基于HTTP协议发送请求,如何发现这个客户端是否登录成功。
如何查看这个发送请求的客户,是否登录?
要么使用cookie的方式进行识别,要么使用session(会话)的方式来判断这个用户是否已经登录。
那么cookie和session的区别是什么呢?

如上图所示,这块随机数专业的词就叫做cookie。
cookie工作机制:客户端首次发送用户名,密码,服务器识别用户名密码正确后,会产生随机数,将随机数放到响应数据中返回给客户端,
客户端会将随机数保存到浏览器中,下次再发送请求的时候,会带有随机数。
将来客户端再向服务器发送请求的时候,会带着这串随机数,此时服务器会根据这串随机数来判断这个客户端是否已经登录,
当然这个随机数很关键,如果别人有这个随机数可以任意登录你的账户。

如上图所示,
session工作机制:客户端首次发送用户名,密码,服务器识别用户密码正确后,会在本地产生记录客户端登录的信息。
session和cookie的区别从工作机制来说的区别是:
1.cookie由服务器生成,保存到客户端
2.session由服务器生成,保存在服务器本地。
cookie会将用户是否已经登录的信息储存到客户端的浏览器中,而session会将用户是否已经登录的信息储存到服务器本地或者单独的缓存机器上。
二.HTTP协议特性
1.http/0.9
HTTP协议最早诞生的版本是http/0.9
只能传输文本数据,也就是说只能看见文字,
2.http/1.0
1.引入了MIME机制,即多用户互联网扩展机制
这个http协议可以结合着MIME机制去传输一些非文本数据,也就是(图片,视频,音频,动画)

如上图所示,每一行是一种非文本数据
2.缓存机制
作用:提升访问效率,
将客户端经常访问的资源缓存到内存中,尽可能地减少与硬盘交互。
和读取数据最慢的设备——硬盘的交互少了,访问的效率也就提升了。
文件资源都在服务器的硬盘上保存着,此时客户端往网站服务器发送请求,网站服务器存在接收和处理请求的网站进程存在,如果进程总是把硬盘中的资源作为响应返回给客户端,进程总是需要向硬盘中索取资源,同时所有的进程都是没有权限去操纵硬盘的,唯一能够操纵硬件的只有系统内核,因此进程要想拿到硬盘中的资源作为给客户端的响应,
需要进程向机器的系统内核发起请求,然后内核再去操纵硬盘获取文件内容,然后将系统内核将文件内容给进程,进程再将文件内容作为响应返回给客户端,

如上图所示,如果客户端数量增多,此时对于同一个文件中的内容,就不需要重复多次得使得进程与硬盘交互,可以启动网站的缓存功能,将需要客户端多次访问的数据缓存到系统内存中,如果内存中有需要的资源就直接使用这个资源作为返回给客户端的响应,
服务器缓存
经常被访问的数据被缓存到服务器的内存中。
客户端缓存
这些经常会用到的数据被缓存到浏览器中。
3.http/1.1(主流版本)
大部分公司的都是使用的http协议的版本是1.1
1.增加了一个叫长连接的机制(keep alive)加速网站访问速度。
限制因素:
1.限制每一个长连接的超时时间,
如果客户端很多的话,同时不去限制长连接的超时时间的话,同时这些客户端如果长时间没有请求的话,那么很多可能会导致服务器CPU资源的严重浪费。
2.限制每个长连接可以支持的发送的最大请求数 比如是100
超过一百次请求后,服务器主动断开长连接。这主要是为了避免一些无意义的访问,

上图所示,如果连续规定时间内,客户端和服务器之间没有任何请求,则服务器和客户端之间的长连接断开,
一个网站是由多个网页构成的。
网页必然是将网页上的数据一点一点传送到客户端的。
http本身是一个无状态的协议,也就是说每一次服务器跟客户端传输完数据后,都要将http连接断开,当下一次传输数据的时候再创建http类型的连接等传输完数据后然后再断开。

如上图所示,对方服务器已经开启长连接机制。
连接和请求的区别?
连接就是访问网站的时候从敲下回车开始就是一个连接。
请求就是点击长连接,点击一个长连接就是一个请求。
2.管道机制
支持客户端同时发送多个请求,但是服务器的响应数据却是串行的即一个一个得回应请求。
3.增强对缓存机制的管理
应该缓存的是静态数据,但是缓存的数据应该有一个过期时间,
如果数据的缓存时间是一天,也就是说响应的数据从内存中响应,一天过后服务器响应的数据从硬盘中响应,找完之后依然缓存在内存中。
4.http/2.2版本
在管道机制上,同时可以发送多个请求,响应.
三.HTTP协议的状态码

可以根据状态码分析那里有错,

如上图所示,这就是状态码
2xx:开头的数字,代表的这是一次成功的响应,表示网站服务器正常响应客户端请求。
成功响应
3xx:成功响应,
301:永久重定向
302:临时重定向
比如使用360by.com去访问京东,结果的访问的网址是jd.com,这就是网站服务器把我们的网址给改了,这就是一种重定向。

如上图所示,就是一次数据的改写。
4xx:错误
403:代表权限拒绝。
404:文件找不到,路径错误,
5xx:错误
502或者是503.一般代表服务器配置有错,即服务器的配置文件中有错,
四.HTTP协议的请求方法
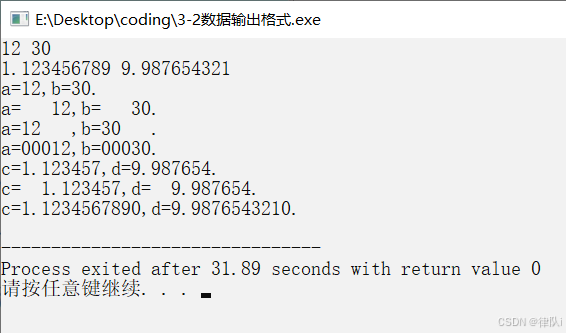
GET:的中文就是获取,使用get这个方法就是查看或者说是获取某一个网页上的内容,
POST:用于向网站上传数据,比如登录邮箱的时候,或者登录购物车的时候,这时候去登录就是在向网站上上传数据,

如上图所示,就是我在登录时往网站上传的用户名和密码。
HEAD:是用来获取HTTP响应数据的首部信息的,(只有运维会用。)


Host标识的是我要请求哪个网站,我要向哪个网站发请求,这个网站名叫什么。
![]()
这个记录的就是客户端所使用的浏览器类型以及客户端操作系统的版本。
cookie表示的就是服务器返回给客户端的随机数,
connection 表示的是连接的意思,keep-alive表示网站服务器提供的是长连接。
![]()
这串记录的是我进入这个网页的时候是从网站上哪个超链接进入的。
curl是Linux操作系统上的字符浏览器,
可以使用curl来获取响应数据的头部内容。

在Linux操作系统上部署网站服务器的软件有httpd,nginx,Tom act
五.httpd软件应用
一.httpd软件介绍一般都叫阿帕奇即Apache
这款httpd软件默认只支持静态网页,想要使用httpd软件搭建的网站服务器也识别动态网页代码,就必须要软件php的参与。或者别的翻译动态网页代码的软件。
apache是一个开源的软件组的名称
作用:部署web服务器
Welcome! - The Apache HTTP Server Project
1.特性
1.开源,跨平台的软件
2.模块化的软件
3.支持多种虚拟主机
4.支持https部署虚拟主机
5.支持url重写的操作(类型于网址的改写)
2.安装方式
比如官网下载软件的源码安装包,
rpm格式
源码编译安装
3.版本
软件版本不同功能不同使用方式不同
2.4版本
2.2版本
六.httpd软件安装

这个软件的主要作用是用来构建网站服务器。
任何一个网站服务启动之后所使用的网络端口都是tcp的80端口。

如上图所示,默认版本是2.4

机器的tcp协议80端口启动之后,这个机器就可以当作最简单的网站服务器来使用。

主进程不负责接收客户端请求。

这是httpd软件提供的一个测试页面。

这个测试页面就是这样的一个文件,


如上图所示,这个就是httpd服务默认的数据目录。

index.html这是httpd默认的网站首页名称,

如上图所示,这个/代表的是httpd数据目录下的/var/www/html这个目录下的内容。
![]()
如上图所示,这个index.html是httpd软件的默认首页名称。
![]()
如上图所示,当我们不去写下一步目录的时候,访问的就是httpd软件的默认目录。
七.httpd相关文件目录

首先conf目录中有httpd软件的配置文件目录,主配置文件htppd.conf文件

这个目录称之为阿帕奇存放子配置文件路径。
将来如果需要可以在conf.d这个子目录下去创建。httpd软件也会读取conf.d/目录下以.conf结尾的文件,

如上图所示,httpd是一个模块化的软件,所有的功能都依赖于模块实现的,
而所有的模块都存在modules这个目录中。

如上图所示,这些配置文件都是模块的配置文件,

如上图所示,这个目录中主要保存httpd的pip文件,也就是这个httpd的进程文件,

如上图所示,这个pip文件就是保存的进程PID,并且这个文件不是一直都有,只有当这个进程启动的时候,才会有这个pip文件。

如上图所示,只有当对应的服务启动的时候,这个pip文件才会回来。
将来写脚本去判断这个文件是否是在正常运行,可以去查看这个服务对应的pip文件是否存在,如果这个服务对应的pip文件存在则这个服务是正在运行。

如上图所示,这个error_log是这个httpd的错误日志保存文件。

如上图所示,这个access_log文件是httpd服务的访问日志,即哪个客户端什么时候访问过我这个httpd服务器。

如上图所示,这个就是一个访问日志中保存的信息,即哪个客户端什么时候访问过我。
对于一个网站服务器来说。最重要的数据就是
第一个指标是页面访问量。
第二个指标是客户访问量。获知到客户群。


如上图所示,logs目录其实就是一个软链接,其真实目录是/var/log/httpd/
综上这个目录结果都是以rpm软件安装包的方式来说的,如果将来软件以源码方式安装的话,这个目录结构肯定和这个是不同的。

八.httpd的配置文件--httpd.conf
1.httpd文件的根目录

如上图所示,这行配置是用来指定阿帕奇的根目录的,这行配置不要去动,不然后续所有的配置都要改,
2.监听端口

上图所示,这个是用来指定阿帕奇启动时候的监听端口,
监听端口改了就影响客户端的访问,如果端口改了,只会影响客户端的访问,浏览器默认只访问80的端口。
3.加载模块功能的子配置文件

如上图所示,这个是用来指定阿帕奇子配置文件路径的,

如上图所示,如果把这个子配置文件路径给注释掉的话,那么这些文件也全都不生效了。
当然可以在这个httpd.conf文件中的Include写我们自己的子配置文件路径,然后让阿帕奇去启动我们自己编写的子配置文件路径。
4.指定进程启动的用户

如上图所示,user后面是用户名,group后面是用户组名称,

如上图所示,这是用来指定当阿帕奇这个服务启动时候httpd这个服务的子进程是用哪个用户身份启动的。



如上图所示,这是修改了httpd这个服务的子进程是以www用户的身份启动的。
5.指定网站管理员的邮箱地址

如上图所示,这是管理员邮箱地址。
6.指定网站名称

如上图所示,这是在指定网站的名称,即网站的名称,
网站不必以www开头,

如上图所示,这是使用kill -1加上这个进程的PID来重新使得这个进程去加载配置文件的。
7.指定网页目录

如上图所示,这是阿帕奇指定的网页目录的。
8.指定错误日志的存放位置,级别

如上图所示,这是阿帕奇错误日志

如上图所示,这是错误日志记录什么级别的信息。

如上图所示,是阿帕奇所错误日志级别
日志信息保存在机器硬盘中,如果把错误级别指定的过低,则会把机器硬盘的空间大量地占据。
机器中记录大量的日志,机器的性能会下降。
服务发生error级别以上的日志肯定会影响这个机器的运行,
9.指定访问日志的存放位置,记录格式

这个是顾客日志也就是访问日志,这个是指定访问日志存放位置以及名称,最后的combined这个是访问日志的格式名称,这个配置是以什么格式去记录访问日志,
不同的格式指定了我要去记录不同的信息,
![]()
还可以换成common
10.定义访问日志的格式

如上图所示,%h是用来记录客户端的IP地址的,%l和%u都是用来记录客户端的用户名的,%t是用来记录客户端的访问时间的,%r记录三样数据,第一样使用的http协议的版本,第二样使用的是cookie还是session即请求的方法,第三样访问的是网站上的哪个文件,
分析网站上的pv量就是拿这个%r分析的。
%>s这个是状态码
%b这个是用来记录的,客户端访问网站服务器,服务器返回的数据大小是多少字节的数据

这个是用来记录超链接的地址

这个是用来记录客户端所使用的浏览器的类型。
网站中哪个网页被访问的次数最多,就是在%r中查找的信息。


如上图所示,访问日志中记录什么样的数据的格式是可以自定义的。
11.定义网站的首页名称

这是网页目录下的默认内容,也就是网站的首页,
12.网站的目录进行授权


如上图所示,这是针对阿帕奇的网页目录进行授权,

如上图所示,这个是用来指定我这个网页目录都支持什么样的功能参数。
ALL表示这个目录支持所有的参数,NONE表示这个目录一个参数都不支持。
1.Options Indexes FollowSymLinks表示的是定义目录支持的功能参数
1)Indexes:这个参数的意思,当你网站没有默认首页的时候,会把/var/www/html中所有的目录都列出来。

如上图所示,如果网站即没有默认首页,也没有这个Indexes的参数,那么就会显示403权限拒绝。
将来在部署网站服务器的时候,如果网站服务器是正常运行某一个网站的话,这个参数默认不要,
否则当网站首页出意外的时候,这个/var/www/html中所有的目录都会显示出来,很有可能会造成隐私信息的泄露,
什么时候需要这个参数呢?
只有当这个网页目录中的数据是可以共享的,是不涉及隐私信息的时候,比如HTTP类型的yum源的时候,是需要这个参数将/var/www/html中的目录都显示出来的,从而达到共享数据的目录,
2)FollowSymLinks
作用:允许客户端正常访问该目录下的软链接文件
这个选项在搭建网站服务器的时候一般需要带着,
3)SymLinksifOwnerMatch
这个软链接的属主和属组必须和阿帕奇进程的属主和属组一致。才可以被访问。

如上图所示,这个软链接的属主和属组都必须是www,此时这个软链接文件才可以被访问。
这个参数加上一般会影响网站的访问速度。
4)Multiviews
用于多语言的网站,
5)ExecCGI
CGI:通用网关接口
静态
动态
阿帕奇只能识别静态网页的代码,
作用:可以让web进程可以通过改机制调用其他的应用程序,给客户端响应。
这个选项当网站中存有动态网页资源的时候,就需要加上这个选项。


Require 这行配置才是用来做网站授权的。
阿帕奇有两种认证方式:
1)基于客户端IP认证,

如上图所示,分别表示我这个网站下的网页只允许IP地址为1.1.1.1的机器访问。
以及我这个网站不允许IP地址为1.1.1.1的机器访问。
Require all granted表示的是允许所有客户端访问。
Require all denied表示的是拒绝所有客户端访问。

如上图所示,这个表示的是处了IP地址是10.252.46.165的机器都能访问我这个网站。
实验如下:在IP地址是192.168.183.12的机器的/etc/hosts的目录下添加域名解析

随后在这台192.168.183.12的机器上是用curl的浏览器进行访问刚刚添加的域名解析。
但是现在这个网站只允许windows访问,
![]()
如上图所示,这是windos机器的IP地址。

如上图所示,这时Linux机器访问刚刚添加的域名解析失效。
2)基于用户名,密码认证

如上图所示,这个文件就是用来保存用户名和密码的文件,

这行配置代表客户端访问我的时候必须使用用户rbowen

如上图所示,这行配置代表客户端访问我的时候只需要是有效用户即可。即保存在文件/usr/local/apache/passwd/passwords中用户名和密码。

如上图所示,这行配置代表客户端访问我的时候必须使用用户B。


只有当这个网站服务器上有一些私密性的网页,这些网页存有重要数据,只有公司内部才可以查看。
九.阿帕奇核心功能使用-- 虚拟主机功能 VirtualHost
一.虚拟主机介绍
原则上来说一台服务器上只能运行一套网站,但是这样很可能会相当浪费资源。
因此现在所有的搭建网站服务器的软件都支持虚拟主机的功能,
作用:可以在一台服务器上运行多个网站。
从第一套网站就要用虚拟主机的方式去部署。
部署的网站必须要以虚拟主机的方式去部署网站,
注意:建议使用虚拟主机的方式来部署网站,方便后续扩展
当在httpd服务器配置虚拟主机以后,那么以前主配置文件中的网站就访问不了了,
类型:
1.基于名称的虚拟主机(用的最多)
2.基于IP地址的虚拟主机(不同的网站要监听在不同的IP地址上)(一套网站对应一套IP)

当然如何能让一台服务器拥有4个IP地址呢?
就是让一台服务器上拥有4块网卡。

问题:我如何知道客户端访问的是AA网站还是BB网站还是CC网站呢?

将来服务器就是根据服务器中httpd协议的请求字段来判断客户端具体要访问哪个网站。


如上图所示,就是创建了一台虚机主机

如上图所示,就是创建了一台虚机主机
ServerAlias就是在对这个网站起一个别名,通过这个别名也可以来访问我这个网站。
还建议给不同的虚拟主机指定不同的访问日志和不同的错误日志,有助于我们去分析不同网站的日志信息。

二.配置基于名称的虚拟主机
vedio.linux.com /var/www/html/vedio
audio.linux.com /audio
1.配置vedio.linux.com虚拟主机
1)创建网页目录,测试首页

2)创建虚拟主机的配置文件

3)重启httpd,测试虚拟主机访问

如上图所示,这是在测试httpd服务的配置文件有没有语法错误,

如上图所示,当第一个虚拟主机启动的时候,在/var/log/httpd这个目录下会生成这个虚拟主机的访问日志文件和错误日志文件。
2.配置audio.linux.com虚拟主机
1)创建网页目录,测试页面

2)编辑配置文件

三.基于IP地址的虚拟主机
可以直接从网站的IP地址来访问网站,

机器上多块网卡如果同网段的IP地址,那么网关和DNS服务器地址就不用重复写了,
1.配置多块网卡地址

在虚拟机上添加网卡然后给这两块网卡配置相应的IP地址。

如上图所示,创建网站目录,以及网站的测试首页。
2.虚拟主机配置文件

如上图所示,创建这个网站的配置文件。

如上图所示,编辑这个网站的配置文件,规定这个网站访问日志,以及错误日志,规定这个网站的目录的权限。
具体内容是这个网站负责的监听网段以及监听端口,
这个网站的名称
这个网站的目录
这个网站的错误日志,以及这个错误日志记录什么级别的错误。
这个网站的访问日志,以及记录访问日志的格式
随后就是对网站目录的授权操作。
如上图所示,编辑完这个网站的配置文件后,使用httpd -t来检查这个配置文件中有无语法错误,随后重启httpd服务。

如上图所示,编辑机器的hosts文件,添加相应的DNS服务器的IP地址以及网站名称,随后使用linux机器上的curl文本浏览器来通过网站名称访问这两个网站。

四.基于https虚拟主机配置
一.https介绍
http
明文,80/tcp
https
密文,443/tcp
将来需要保证客户端和服务器之间的通信是安全的需要从三方面来讲:
二.安全性保障
1.保证数据本身的安全性,即数据在传输的过程当中不被别人窃取,或者说这个数据被别人窃取后不被别人看懂,
可以通过数据加密,
2.数据完整性
3.验证身份的真实性,有效性
三.数据安全性
手段:加密
发送方加密数据,接收方解密数据
原数据通过加密算法和密钥对原数据进行加密,将原数据加密成加密的数据,
在加密领域中真正重要的不是加密算法而是加密所使用的密钥。
对称加密算法
加密,解密数据时使用的密钥是一样的。

代表性算法:
DES, 3DES, AES
非对称加密算法
加密,解密数据时使用的密钥是不一样的
基于密钥对实现的,
公钥加密数据,私钥解密数据
公钥和私钥之间存在唯一对应关系,
不同的机器之间实现公钥的交互可以通过人为敲命令来实现或者是通过软件自动传输

密钥对中最关键的就是私钥。
代表性算法:
DSA,RSA

实际应用:使用对称算法加密真实的数据,使用非对称算法加密对称算法使用的密钥。

对称加密算法

非对称加密算法:
借助gpg工具
四.数据的完整性
借助数学算法对数据进行校验,
主机A利用算法对数据进行校验,生成校验码,同时将校验码,数据发送给主机B
主机B接收到数据后,利用相同的数学算法再进行校验运算,对比校验码

校验码一致则数据完整,校验码不一致则数据不完整。
代表性算法:
MD5,SHA统称为哈希算法。
校验算法在对数据进行校验的时候是对数据本身校验不是对文件校验。
只要数据一致校验码就一致,只要数据不一致校验码就不一致。

如上图所示,校验码一致则数据一致。

如上图所示,验证数据的备份是否成功即验证数据的校验码是否一致,当数据的校验码一致时,这个数据的备份是成功的。

如上图所示,这是使用sha算法进行校验的过程。
从网上下载的安装包是否完整,需要查看校验码是否一致,一般只看后四位。



如上图所示,这是在官网上获取的校验码与机器上的校验码进行的比对。
五.身份真实性验证
密钥对:私钥签名,公钥验证签名

如上图所示,机器通过联系网上的CA服务器来验证电商网站的证书的合法性,机器无条件信任CA服务器。

如上图所示,就是网上的合法CA

客户端一旦确定这个电商服务器的证书合法之后,就会获取这个电商服务器的公钥,但是不会使用公钥加密数据速度太慢,客户端会自己选择一种对称加密算法,以及这个算法需要用到的密钥,然后用公钥信息将对称算法本身的密钥进行加密,加密完传给服务器,随后服务器就会使用私钥对这个客户端发送过来的用公钥加密的对称算法信息和密钥进行解密,然后服务器就会知道客户端使用什么样的对称算法对数据进行加密,以及客户端用这种对称算法生成的密钥,

PKI叫做公钥认证体系结构,CA是这个PKI结构的核心。
对于CA服务器来说,证书从电商服务器发送给CA服务器私钥签名,证书从客户端发送给CA服务器公钥验证签名,
对于客户端来说,使用证书上的公钥加密,然后将用公钥加密的对称算法和密钥发送给电商服务器,然后电商服务器使用自身的私钥进行解密。
如何申请证书呢?



如上图所示,就是申请网站证书的流程。
只要这个服务是面向互联网的,那么这个证书必须有,
公司内部的ftp服务器和MySQL数据库,这些软件中数据的传输都是明文的,我希望公司内部服务器和服务器之间的数据进行加密通信,那么各个服务器也要有证书.或者说在公司内部自己搭建一个CA服务器,然后这个CA只能面向于公司内部使用。
六.配置https虚拟主机
自己构建一个CA服务器
需求:基于https协议部署虚拟主机,名称为www.linux.com
环境要求:一台是ca.linux.comIP是192.162.183.12
部署CA服务器
借助软件openssl软件
第一在机器上生成一个密钥对
第二为CA服务器生成一个自签证书
这两件事都可以通过软件openssl软件来完成。
一.部署CA服务器

如上图所示,openssl软件通常是默认安装的。

如上图所示,/etc/pki/tls/openssl.cnf是这个openssl软件的配置文件。

如上图所示,是关于CA服务器的一些默认配置,
dir这个参数指代的是/etc/pki/CA这个目录
database这行配置说明了将来需要我们在/etc/pki/CA这个目录创建一个index.txt的数据库文件,这个文件的作用是用来保存这个CA服务器都给哪几个机器颁发过证书,这些机器的信息都会被保存在这个CA服务器的数据库文件中,
如上图所示,这个数据库文件不会被自动创建,需要我们自己创建,

如上图所示,这个文件也是一个数据库文件只不过其中记录的是这个CA服务器往外颁发了几个证书,即CA服务器往外颁发的证书的个数。

如上图所示,这个记录证书颁发个数的文件不会自动创建,需要我们自己去创建,
![]()
如上图所示,这是将来存放CA服务器中密钥对的路径信息,我们需要自己创建这个文件去存放密钥对信息。
![]()
如上图所示,这是用来存放CA服务器自身证书的路径信息,这个文件也是需要我们去自己创建的。
1.创建CA服务器所需要的数据库文件(一共需要两个)

如上图所示,这第二个记录CA服务器颁发证书个数的文件中必须要有初始值,初始值定为1
2.创建CA服务器需要的密钥对

如上图所示,基于RSA算法生成密钥对长度是1024

3.最后生成自签证书 CA的证书

如上图所示,需要使用-key选项指定密钥对,即在证书上写上密钥对的信息。

如上图所示,这个信息编写的意思是这个CA服务器只负责颁发中国的北京省的北京市的证书颁发。

如上图所示,就是这个自签证书的信息,其中最重要的就是这个自签证书服务于那台机器,这个机器的主机名是什么,

如上图所示,就是这个自签证书的文件。
二.部署https协议的虚拟主机
1.生成网站需要的密钥对

如上图所示,这是在https协议的虚拟主机中生成需要的密钥对,
2.生成证书申请,
如上图所示,这是虚拟主机在向CA服务器申请证书。-key是密钥对中的虚拟主机中密钥对的公钥信息,-out是这个证书在虚拟主机中的保存位置,

如上图所示,这是虚拟主机在向CA服务器申请证书的过程,在这个过程中最重要的就是这个证书要给哪个服务器使用,即这个服务器的主机名。
3.将证书申请发送给CA

4.在CA服务器上签署证书

如上图所示,-in证书申请,-out指定证书,-days指定证书有效期

如上图所示,作为CA服务器签署的证书都需要存放在/etc/pki/CA/certs这个文件中。

如上图所示,就是签署证书的命令

如上图所示,签署证书的命令就如上图所示,


如上图所示,当我们在CA服务器上签署完成一个证书的时候,以上两个数据库文件会更新数据。
5.将证书拷贝到网站服务器

如上图所示,这是在CA服务器上将证书拷贝到网站服务器的操作

如上图所示,此时回到网站服务器,会发现证书申请文件,证书文件,网站服务器的密钥对。
6.使用httpd软件构建https协议的网站,需要在这个软件上安装相应的mod_ssl模块。


如上图所示,在安装完这个模块之后,会生成一个ssl.conf的https协议的模板文件。
7.编辑ssl的配置文件

如上图所示,这个https模板文件中表明这个协议监听443的端口。

如上图所示,第一行配置是指定这个网站的目录
第二行配置是这个网站的名称。

如上图所示,这是在表明这个网站的证书存放路径。

如上图所示,这是在表明这个网站的密钥对的存放路径。

如上图所示,这是对这个网站的目录进行授权操作。
8.创建这个网站的测试页面


一个是http协议的的80端口一个是测试网站提供的443端口。

如上图所示,随后可以在windows机器上的hosts文件中添加上这样一条信息,用于测试https网站的创建是否成功。

如上图所示,不是我们创建的测试网站,因为浏览器默认只认80端口,也就是基于http协议,但是我们搭建的这个测试网站是基于htpps协议的网站,所以需要我们手写协议名称也就是在网站名称前头加上https://

如上图所示,这是因为我们搭建的CA服务器只适用于公司内部,所以显示这个。

那么为什么京东或者百度的网站就不需要手写https协议呢?
七.实现https的自动跳转,也就是说为了方便客户端的访问,因为浏览器默认访问的是网站服务器的80端口,但是https协议的网站却是监听的443端口
这里会用到httpd软件的url地址重写功能。

如上图所示,这就是一个url地址的结构。

如上图所示,也就是说客户端将请求发送给网站服务器,然后由网站服务器来写这个协议名称,
也就是说客户端敲的是www.linux.com,但是服务器将客户端敲的地址改写成https://www.linux.com
同时对于服务器来说什么样的请求应该加上https的协议名称,什么样的请求是不应该加上https的协议名称?

如上图所示,这个判断的依据就是客户端所访问的网址是否是基于https协议的网站。

阿帕奇是模块化的软件,具体的url地址改写功能就是通过mod rewrite模块实现的。

阿帕奇是模块化的软件,具体的url地址改写功能就是通过mod rewrite模块实现的。
如上图所示,这个RewriteEngine On就表示启动这个httpd软件的url地址改写功能。这个配置表示将url地址重写功能给打开。

如上图所示,第一行配置是符合什么条件时才进行url地址的改写。
第二行配置是如何改写这个url地址,


如上图所示,如果将来我的服务器收到一个请求,会拿我请求的uri地址,与配置中的uri地址进行匹配,如果配置得上就拿这个新地址取代原来的url地址,uri地址表示的就是客户端要访问我机器上的哪个文件。

如上图所示,蓝色标注之前的是主机名,灰色编著的就是uri地址,也就是这个客户端要访问我哪个机器上的哪个文件。

如果客户端所写的uri地址和上述的条件是匹配的,则将这个url地址改写为新地址,当然这个uri地址就是进行url地址改写的条件,条件的编写格式是以正则表达式的方式写的,

只要uri地址是/开头的,后面随便是什么,这样的条件,即^/,就可以匹配到任何的想要访问我机器的请求,并将这些请求的url地址进行重新改写。

如上图所示,这三行配置是需要改写到虚拟主机的/etc/httpd/conf.d/audio.conf配置文件中。


如上图所示,就是对url地址进行改写的操作,
%{HTTP_HOST}这个变量获取到的就是客户端发来请求的网站的主机名称,随后的是如果请求的地址是www.linux.com即应用url地址改写功能。
最后的一行配置RewiteRule的意思是,凡是以^/开头的uri地址都改写成新的url地址。
NC的意思是忽略主机名中的大小写,
L的意思是阿帕奇立刻拿改写的地址进行跳转

如上图所示,重启httpd服务使得配置生效。
![]()
如上图所示,这个表示的是凡是以/开头的uri地址都被改写成这个网址。但是如果我们想访问这个网站中的一个网页呢?
如果我对此配置不做任何修改那么别人访问我这个网站任何一个网页都是访问的首页。这没什么意义。

如上图所示,将条件改写成如上的形式,$1表示的是第一个小括号中.*所代表的所有数据。

重启阿帕奇进行测试,

如上图所示,测试成功,可以正常访问www.linux.com网站中的除了网站首页的其他网页。