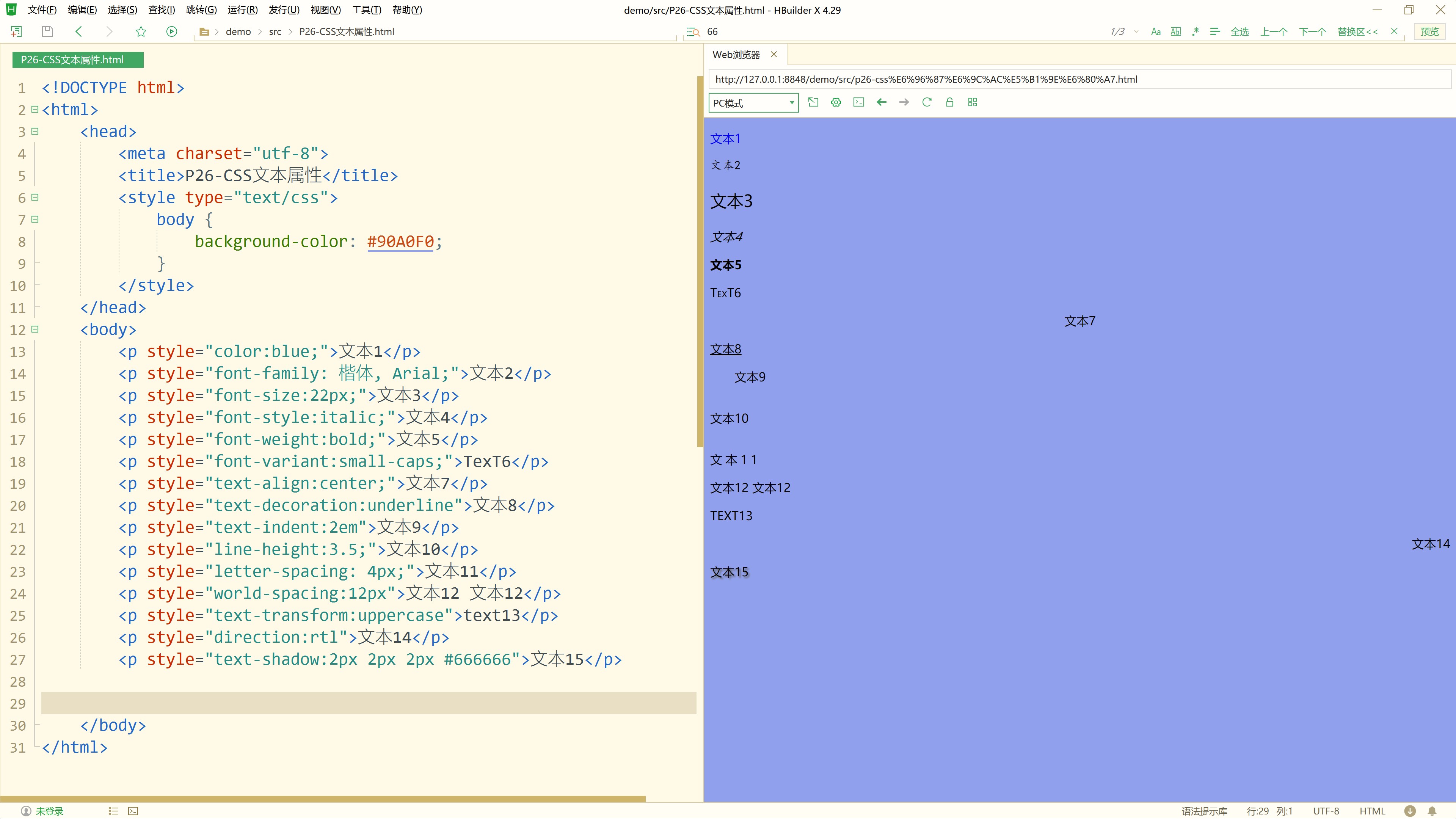
文章目录
- 集成学习
- 集成学习思想
- 概述
- 集成学习分类
- Bagging 思想
- Boosting思想
- Bagging 和 Boosting 的对比
- 随机森林算法
- 随机森林实现步骤
- 随机森林算法api
- API 代码实现
- Adaboost 算法
- 实现步骤
- 整体过程实现
- 算法推导
- Adaboost 案例 葡萄酒数据
- GBDT (梯度提升树)
- 提升树 BDT (Boosting Decision Tree)
- 梯度提升树 GBDT (Gradient Boosting Decision Tree)
- 案例
- 梯度提升树的构建流程
- 案例代码实现
- XGBoost 极端梯度提升树
- XGBoost 的实现步骤
- 总流程:
- XGB案例 红酒品质分类
- 代码实现
集成学习
集成学习思想
概述
集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型称为弱学习器(基学习器)。
训练时,使用训练集依次训练出这些弱学习器,对未知样本进行预测时,使用这些弱学习器联合进行预测。

集成学习分类

- Bagging: 随机森林
- Boosting: Adaboost GBDT XGBoost LightGBM
Bagging 思想
- Bagging思想
- 又称装袋算法或者自举汇聚法
- 有放回的抽样(bootstrap抽样)产生不同的训练集,从而训练不同的学习器
- 通过平权投票、多数表决的方式决定预测结果
- 在分类问题中,会使用多数投票统计结果
- 在回归问题中,会使用求均值统计结果
- 弱学习器可以并行训练
- 基本的弱学习器算法模型,如: Linear、Ridge、Lasso、Logistic、Softmax、ID3、C4.5、CART、SVM、KNN均可

- Bagging 思想图
目标: 把图中的圈和方块进行分类

Boosting思想
-
Boosting思想
- 每一个训练器都重点关注前一个训练器不足的地方进行训练
- 通过加权投票的方式 得出预测结果
- 串行的训练方式
-
Boosting思想在生活中的举例
- 随着学习的积累从弱到强
- 每新加入一个弱学习器,整体能力就会得到提升
- 代表算法: Adaboost GBDT XGBoost LightGBM

滚球兽→亚古兽→暴龙兽→机械暴龙兽→战斗暴龙兽
Bagging 和 Boosting 的对比
| Bagging | Boosting | |
|---|---|---|
| 数据采样 | 对数据进行有放回的采样训练 | 全部样本,根据前一轮学习结果调整数据的重要性 |
| 投票方式 | 所有学习器平权投票 | 对学习器进行加权投票 |
| 学习顺序 | 并行的,每个学习器没有依赖关系 | 串行,学习有先后顺序 |
随机森林算法
随机森林是基于Bagging 思想实现的一种集成学习方法,采用决策树模型作为每一个弱学习器
- 训练:
(1)有放回的产生训练样本
(2)随机挑选 n 个特征(n 小于总特征数量) - 预测:平权投票,多数表决输出预测结果

随机森林实现步骤
- 随机选择m条数据
- 随机选取k个数据特征
- 训练决策树 默认为CART树
- 重复1-3布构造n个弱决策树
- 平权投票集成n个弱决策树

- 思考1:为什么要随机抽样训练集
- 如果不进行随机抽样,每颗决策树的训练集都是一样的,最终训练出来的树分类结果也是一样的
- 思考2:为什么要有放回原地抽样
- 如果不是有放回的抽样,那么每棵树的训练结果都是不同的,完全没有交集的,这样每棵树都是’有偏的’,也就是每棵树训练出来都有很大差异,而随机森林最后的分类取决于多棵树的投票表决.
- 综上: 弱学习器的训练样本既有交集也有差异数据,更容易发挥投票表决效果
随机森林算法api
sklearn.ensemble.RandomForestClassfier()
- n_estimators : 决策树数量 default = 10
- Criterion : entropy / giini (default = gini)
- max_depth : 最大深度 default = None 表示树会尽可能的生长
- max_features = ‘auto’ 决策树构建时使用的最大特征数量
- auto sqrt -> max_features = sqrt(n_features)
- log2 -> max_features = sqrt(n_features)
- None -> max_features = n_features
- Bootstrap : 是否采用有放回的抽样 如果为False 将会使用全部训练样本 default = True
- min_sample_split : 节点分裂所需最小样本数 default = 2
- 如果节点样本数少于min_samples_split 则不会在进行划分
- 如果样本数量不大 不需要设置这个值
- 如果样本量数量级非常大 则推荐增大这个值
- min_samples_leaf: 叶子节点的最小样本数(default = 1)
- 如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝
- 较小的叶子节点样本数量使模型更容易捕捉训练数据中的噪声
- min_impurity_split: 节点划分最小不纯度
- 如果某节点的不纯度(基尼系数 均方差) 小于这个阈值 ,则该节点不会再生成子节点,并变为叶子节点
- 一边不推荐改动 默认值1e-7
API 代码实现
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
def demo01():
# 获取数据集
data = pd.read_csv('../data/titanic_train.csv')
# 数据处理
# 获取数据特征值 和 目标值
x = data[['Pclass', 'Age', 'Sex']].copy()
y = data['Survived'].copy()
# 缺失值处理 用平均值填充age列的缺失值
x['Age'] = x['Age'].fillna(x['Age'].mean())
# one-hot 编码
x = pd.get_dummies(x)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 模型训练
# 获取决策树模型 随机森林模型 随机森林交叉网格搜索
dtc = DecisionTreeClassifier()
rfc = RandomForestClassifier()
estimator = RandomForestClassifier()
# 模型训练
dtc.fit(x_train, y_train)
rfc.fit(x_train, y_train)
# 网格搜索最优参数
param = {'n_estimators': [40, 50, 60, 70], 'max_depth': [2, 4, 6, 8, 10], 'random_state': [9]}
gird_search = GridSearchCV(estimator, param_grid=param, cv=2)
gird_search.fit(x_train, y_train)
# 预估
dtc_predict = dtc.predict(x_test)
rfc_predict = rfc.predict(x_test)
gird_predict = gird_search.predict(x_test)
# 评测
print('dtc 准确率:', accuracy_score(dtc_predict, y_test))
print('rfc 准确率:', accuracy_score(rfc_predict, y_test))
print('gird 准确率:', accuracy_score(gird_predict, y_test))
print('模型参数:', gird_search.best_estimator_)
if __name__ == '__main__':
demo01()
Adaboost 算法
Adaptive Boosting(自适应提升) 基于Boosting思想实现的一种集成学习算法
核心思想时通过逐步提高那些被前一步分类错误的样本权重来训练一个强分类器
实现步骤
1.训练第一个学习器

2.调整数据分布 预测错误的数据权重放大 正确的数据权重变小

3.训练第二个学习器

4.再次调整数据分布 错误的数据权重变大 正确的数据权重变小 之前的正确数据进一步缩小

5.依次训练学习器,调整数据分布

整体过程实现

算法推导
1 初始化训练数据权重相等,训练第 1 个学习器
- 如果有 100 个样本,则每个样本的初始化权重为:1/100
据预测结果找一个错误率最小的分裂点,计算、更新:样本权重、模型权重
2 根据新权重的样本集 训练第 2 个学习器
- 根据预测结果找一个错误率最小的分裂点计算、更新:样本权重、模型权重
3 迭代训练在前一个学习器的基础上,根据新的样本权重训练当前学习器
- 直到训练出 m 个弱学习器
4 m个弱学习器集成预测公式:

- a_i 为模型的权重,输出结果大于 0 则归为正类,小于 0 则归为负类。
5 模型权重计算公式:

6 样本权重计算公式:

Adaboost 案例 葡萄酒数据
需求: 已知葡萄酒数据,根据数据进行葡萄酒分类

- 思路分析
# 1 读取数据
# 2 特征处理
# 2-1 Adaboost一般做二分类 去掉一类(1,2,3)
# 2-2 准备特征值和目标值
# 2-3 类别转化 (2,3)=>(0,1)
# 2-4 划分数据
# 3 实例化单决策树 实例化Adaboost-由500颗树组成
# 4 单决策树模型训练和评估
# 5 AdaBoost模型训练和评估
- 代码实现
import pandas as pd
from sklearn.preprocessing import LabelEncoder # 编码器
from sklearn.model_selection import train_test_split # 数据集切分
from sklearn.tree import DecisionTreeClassifier # 决策树
from sklearn.metrics import accuracy_score # 评估
from sklearn.ensemble import AdaBoostClassifier # 集成学习
def demo01():
# 读取数据
data = pd.read_csv('../data/wine0501.csv')
# 数据预处理
data = data[data['Class label'] != 1]
x = data[['Alcohol', 'Hue']].copy()
y = data[['Class label']].copy()
# 特征工程
y = LabelEncoder().fit_transform(y)
# 划分数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=1)
# 模型训练
# 单决策树
dtc = DecisionTreeClassifier()
dtc.fit(x_train, y_train)
# adaboost
abc = AdaBoostClassifier(n_estimators=500, estimator=dtc,learning_rate=0.1)
abc.fit(x_train, y_train)
print('集成学习准确率:', abc.score(x_test, y_test))
if __name__ == '__main__':
demo01()
GBDT (梯度提升树)
提升树 BDT (Boosting Decision Tree)
- 思想
- 通过拟合残差思想进行提升
- 残差: 真实值 - 预测值
- 生活中的列子
- 预测某人的年龄为100岁
- 第1次预测:对100岁预测,预测成80岁;100 – 80 = 20(残差)
- 第2次预测:上一轮残差20岁作为目标值,预测成16岁;20 – 16 = 4 (残差)
- 第3次预测:上一轮的残差4岁作为目标值,预测成3.2岁;4 – 3.2 = 0.8(残差)
- 若三次预测的结果串联起来: 80 + 16 + 3.2 = 99.2
- 通过拟合残差可将多个弱学习器组成一个强学习器,这就是提升树的最朴素思想
梯度提升树 GBDT (Gradient Boosting Decision Tree)
- 梯度提升树不再拟合残差,而是利用梯度下降的近似方法,利用损失函数的负梯度作为提升树算法中的残差近似值。

- GBDT 拟合的负梯度就是残差。如果我们的 GBDT 进行的是分类问题,则损失函数变为 logloss,此时拟合的目标值就是该损失函数的负梯度值
案例



梯度提升树的构建流程
1 初始化弱学习器(目标值的均值作为预测值)
2 迭代构建学习器,每一个学习器拟合上一个学习器的负梯度
3 直到达到指定的学习器个数
4 当输入未知样本时,将所有弱学习器的输出结果组合起来作为强学习器的输出
案例代码实现
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV
def demo01():
# 读取数据
df = pd.read_csv('../data/titanic_train.csv')
# 数据预处理
x = df[['Pclass', 'Age', 'Sex']].copy()
y = df['Survived'].copy()
# 缺失值填充
x['Age'] = x['Age'].fillna(x['Age'].mean())
# one-hot 热编码
x = pd.get_dummies(x)
# 数据集切分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 获取训练对象
estimator = GradientBoostingClassifier()
# 模型训练
estimator.fit(x_train, y_train)
# 模型预测准确率
myscore = estimator.score(x_test, y_test)
print('准确率:', myscore)
# GBDT 网格搜索交叉验证
# 获取训练对象
estimator = GradientBoostingClassifier()
# 网格搜索参数
param = {'n_estimators': [100, 110, 120, 130], 'max_depth': [2, 3, 4], 'random_state': [9]}
# 网格搜索
estimator = GridSearchCV(estimator, param_grid=param, cv=3)
estimator.fit(x_train, y_train)
myscore = estimator.score(x_test, y_test)
print('gbdt准确率:', myscore)
print('最佳参数:\n', estimator.best_params_)
if __name__ == '__main__':
demo01()

XGBoost 极端梯度提升树
-
极端梯度提升树,集成学习方法的王牌,在数据挖掘比赛中,大部分获胜者用了XGBoost
-
XGBoost 的构建思想
- 1.构建模型的方法是最小化训练数据的损失函数 训练的模型复杂度较高,容易过拟合

- 2.在损失函数中加入正则化想 提高对未知的测试数据的泛化性能

- XGBoost(Extreme Gradient Boosting)是对GBDT的改进,并且在损失函数中加入了正则化项

-
正则化项用来降低模型的复杂度

- γT 中的 T 表示一棵树的叶子结点数量。
- λ||w||^2中的 w 表示叶子结点输出值组成的向量, ||w||^ 向量的模; λ对该项的调节系数
XGBoost 的实现步骤
- 假设我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分:

- 训练出tree1和tree2,类似之前GBDT的原理,两棵树的结论累加起来便是最终的结论

- 树tree1的复杂度表示为

-
进行 t 次迭代的学习模型的目标函数如下为:

-
直接对目标函数求解比较困难,通过泰勒展开将目标函数换一种近似的表示方式
- 泰勒展开复习

-
目标函数对 yi(t-1) 进行泰勒二阶展开,得到如下近似表示的公式:

- 其中gi 和 hi 的分别为损失函数的一阶导、二阶导:

- 观察目标函数,发现以下两项表示t-1个弱学习器构成学习器的目标函数,都是常数,我们可以将其去掉:

- 从样本角度转为按照叶子节点输出角度,优化损失函数

-
上式中:
- gi 表示每个样本的一阶导,hi 表示每个样本的二阶导
- ft(xi) 表示样本的预测值
- T 表示叶子结点的数目
- ||w||2 由叶子结点值组成向量的模
-
举个栗子:请计算10样本在叶子结点上的输出表示




总流程:

最终目标函数为:

该公式也叫做打分函数 (scoring function),从损失函数、树的复杂度两个角度来衡量一棵树的优劣。当我们构建树时,可以用来选择树的划分点,具体操作如下式所示:

XGB案例 红酒品质分类
- 已知 : 数据集共包含 11 个特征,共计 3269 条数据. 我们通过训练模型来预测红酒的品质, 品质共有 6个类别,
分别使用数字:0、 1、2、3、4、5 来表示

- 需求:对红酒品质进行多分类
- 分析: 从数据可知 1、目标是多分类 2、数据存在样本不均衡问题
代码实现
# 导入数据包
import joblib # 模型保存包
import numpy as np
import pandas as pd
from sklearn.utils import class_weight
from xgboost import XGBClassifier # XGBoost包
from collections import Counter # 统计包
from sklearn.model_selection import train_test_split, GridSearchCV # 训练集、测试集包
from sklearn.metrics import accuracy_score, classification_report # 模型评估包
from sklearn.model_selection import StratifiedKFold # 分层K折包
def demo01():
"""
数据读取及基本数据处理
:return:
"""
# 加载数据
data = pd.read_csv('../data/红酒品质分类.csv')
# 数据预处理
x = data.iloc[:, :-1]
y = data.iloc[:, -1] - 3
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 数据存储
pd.concat([x_train, y_train], axis=1).to_csv('../data/红酒品质分类-train.csv')
pd.concat([x_test, y_test],axis=1).to_csv('../data/红酒品质分类-test.csv')
def demo02():
"""
模型训练
:return:
"""
# 2.1 加载数据集
train_data = pd.read_csv('../data/红酒品质分类-train.csv')
test_data = pd.read_csv('../data/红酒品质分类-test.csv')
# 2.2 准备数据 训练集测试集
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
# 3.XGBoost模型训练
estimator = XGBClassifier(n_estimators=100, objective='multi:softmax',eval_metric='merror', eta=0.1, use_label_encoder=False, random_state=22)
estimator.fit(x_train, y_train)
# 4.XGBoost模型预测及评估
y_pred = estimator.predict(x_test)
print( classification_report(y_true=y_test, y_pred=y_pred))
# 5.模型保存
joblib.dump(estimator, '../data/mymodelxgboost.pth')
def demo03():
"""
模型训练 样本不均衡问题处理
:return:
"""
# 2.数据读取及数据预处理
# 2.1 加载数据集
train_data = pd.read_csv('../data/红酒品质分类-train.csv')
test_data = pd.read_csv('../data/红酒品质分类-test.csv')
# 2.2 准备数据 训练集测试集
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
# 2.3 样本不均衡问题处理
classes_weights = class_weight.compute_sample_weight(class_weight='balanced', y=y_train)
# 3.XGBoost模型训练
estimator = XGBClassifier(n_estimators=100, objective='multi:softmax',eval_metric='merror', eta=0.1, use_label_encoder=False, random_state=22)
# 训练的时候,指定样本的权重
estimator.fit(x_train, y_train, sample_weight=classes_weights)
# 4.XGBoost模型预测及评估
y_pred = estimator.predict(x_test)
print(classification_report(y_true=y_test, y_pred=y_pred))
def demo04():
"""
交叉验证和网格搜索
:return:
"""
# 2.读取数据及数据预处理
# 2.1 加载数据集
train_data = pd.read_csv('../data/红酒品质分类-train.csv')
test_data = pd.read_csv('../data/红酒品质分类-test.csv')
# 2.2 准备数据 训练集测试集
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_test = test_data.iloc[:, :-1]
y_test = test_data.iloc[:, -1]
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
# 2.3 交叉验证时,采用分层抽取
spliter = StratifiedKFold(n_splits=5, shuffle=True)
# 3.模型训练
# 3.1 定义超参数
param_grid = {'max_depth': np.arange(3, 5, 1),
'n_estimators': np.arange(50, 150, 50),
'eta': np.arange(0.1, 1, 0.3)}
# 3.2 实例化XGBoost
estimator = XGBClassifier(n_estimators=100,
objective='multi:softmax',
eval_metric='merror',
eta=0.1,
use_label_encoder=False,
random_state=22)
# 3.3 实例化cv工具
estimator = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=spliter)
# 3.4 训练模型
estimator.fit(x_train, y_train)
# 4.模型预测及评估
y_pred = estimator.predict(x_test)
print(classification_report(y_true=y_test, y_pred=y_pred))
print('estimator.best_estimator_-->', estimator.best_estimator_)
print('estimator.best_params_-->', estimator.best_params_)
if __name__ == '__main__':
demo01()
demo02()
demo03()
demo04()