用AI+dify完成前后端开发+数据处理和数据清洗。
- 引言
- 数据获取和数据处理
- dify构建workflow进行数据清洗
- 前端页面构建和前后端交互
- 总结
引言
AI时代对开发人员的加强是非常明显的,一个开发人员可以依靠AI横跨数个自己不熟悉的领域包括前后端、算法等。让我们来做个实践,全程使用AI写代码+dify构建工作流快速完成一个获取每日热点新闻的前后端开发以及数据处理、数据清洗的任务,全程不需要我们自己动手写代码,仅跟AI聊天实现。
我们来理清一下步骤:
1、点击每日新闻按钮
2、自动获取每日新闻信息
3、用LLM获取到标题、概要、作者、新闻链接
4、用dify + LLM 清洗和处理数据,获取新闻概要内容和新闻标签
5、给前端返回作者、标题、新闻链接、新闻概要内容和新闻标签
6、展示在页面上,并且点击可以跳到对应新闻页面
最后效果:

数据获取和数据处理
从网上搜索一下头条的每日推荐新闻的接口,我们的每日新闻来源就从这里获取。实际处理可以换成自己需要的接口并进行处理,让模型编码。

其实就是很简单地发送一个请求,对应代码:
fetch('http://is.snssdk.com/api/news/feed/v51/')
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.json();
})
.then(data => {
console.log('Success:', data);
})
.catch(error => {
console.error('Error:', error);
});
粘贴代码观察一下结果

观察获取到的数据很明显我们只需要url source title abstract这四个字段,分别是对应的链接地址,作者,标题,摘要,做一下数据处理,让模型编码。
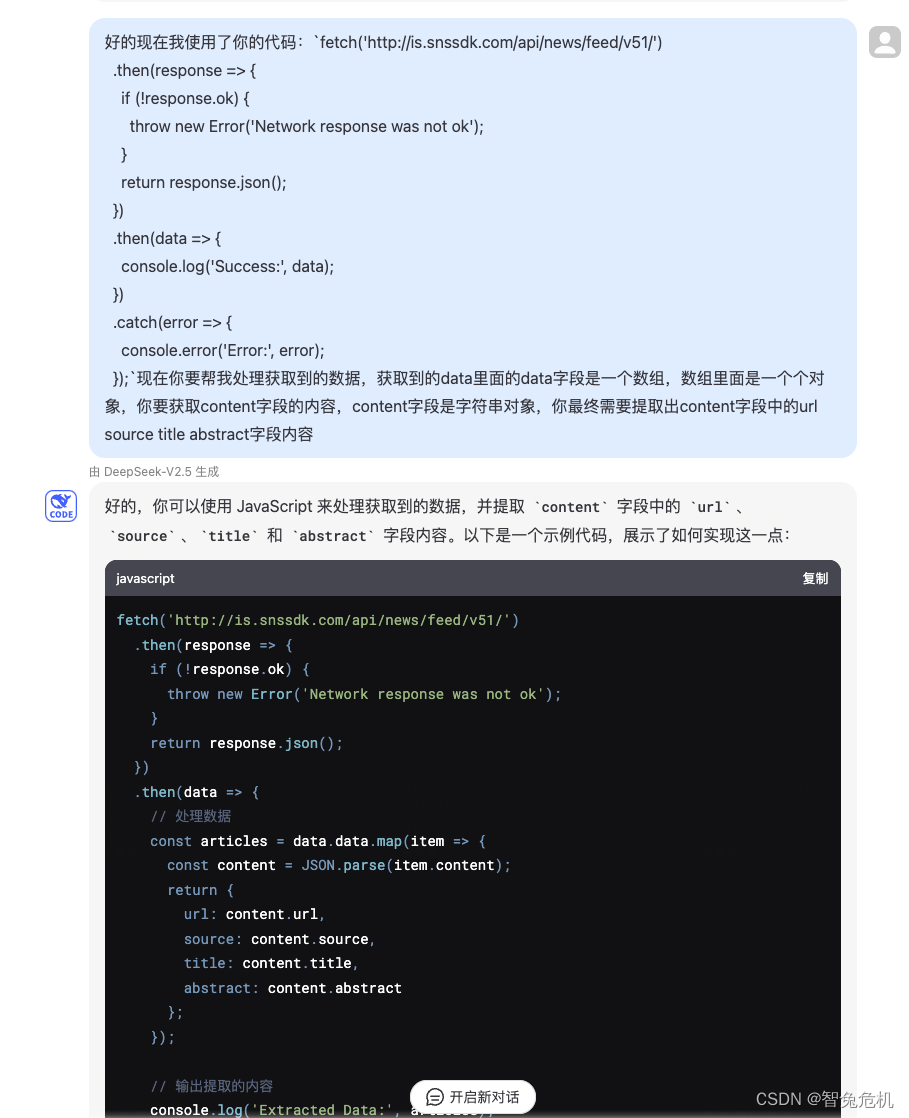
模型帮助我们在前面代码的基础上仅提取了我们需要的部分字段,获取的代码:
fetch('http://is.snssdk.com/api/news/feed/v51/')
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.json();
})
.then(data => {
// 处理数据
const articles = data.data.map(item => {
const content = JSON.parse(item.content);
return {
url: content.url,
source: content.source,
title: content.title,
abstract: content.abstract
};
});
// 输出提取的内容
console.log('Extracted Data:', articles);
})
.catch(error => {
console.error('Error:', error);
});
处理完之后就是比较简单的我们想要的数据了。
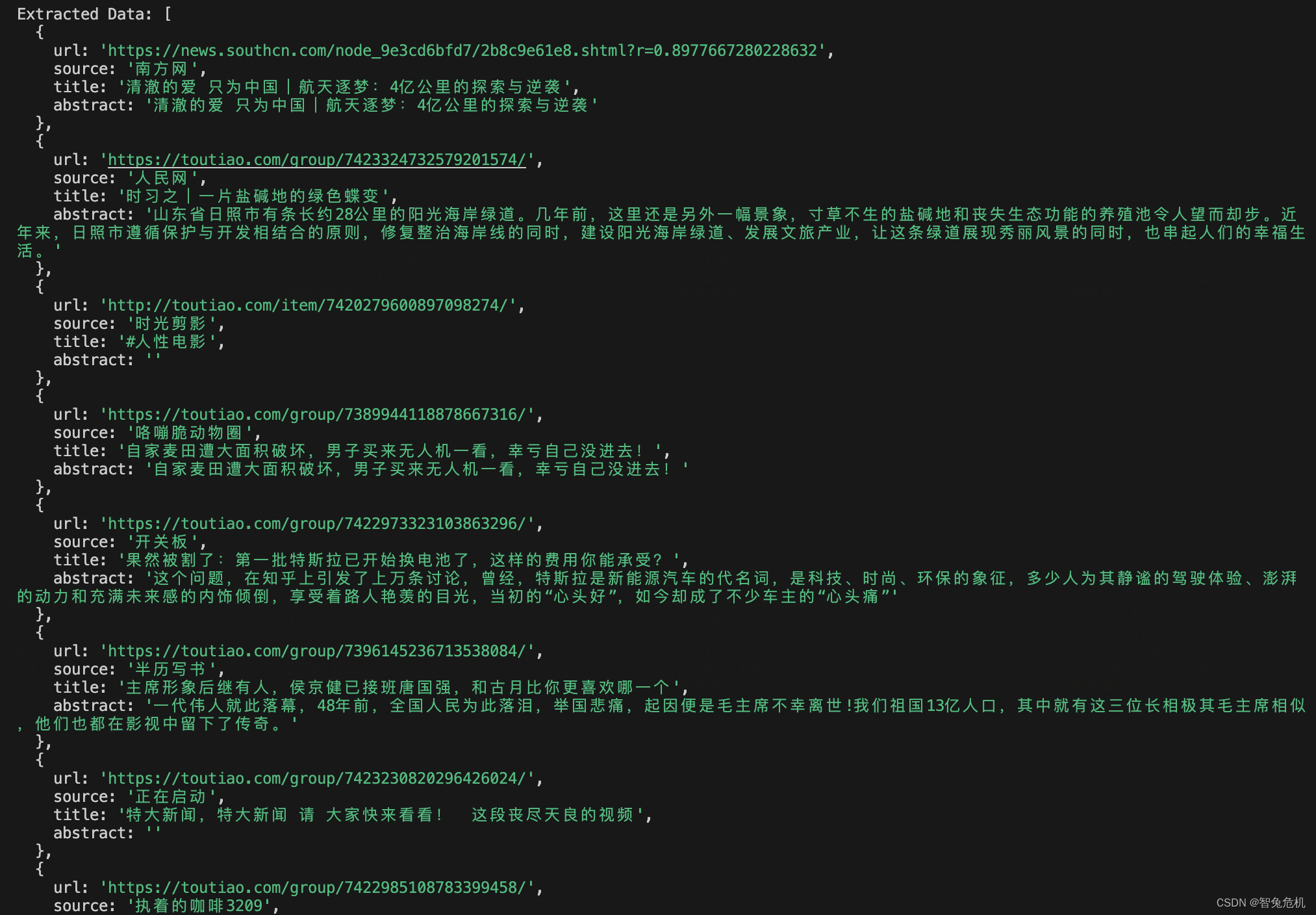
现在的数据只有链接标题还有一些没意义的摘要(实际上只是截取的文章前面部分),我们需要阅读前,模型就已经帮我们大致总结了一下内容以及对新闻进行了对应的打标签,这个就需要我们通过模型去完成了,我们下面用dify的工作流去完成这件事。
dify构建workflow进行数据清洗
接下来我们来做数据清洗,我希望对标题进行对应的改写,且我需要模型帮我总结内容和对内容打标签。通过dify搭建工作流(注意这里可以使用别的工具,并不一定依赖dify)。
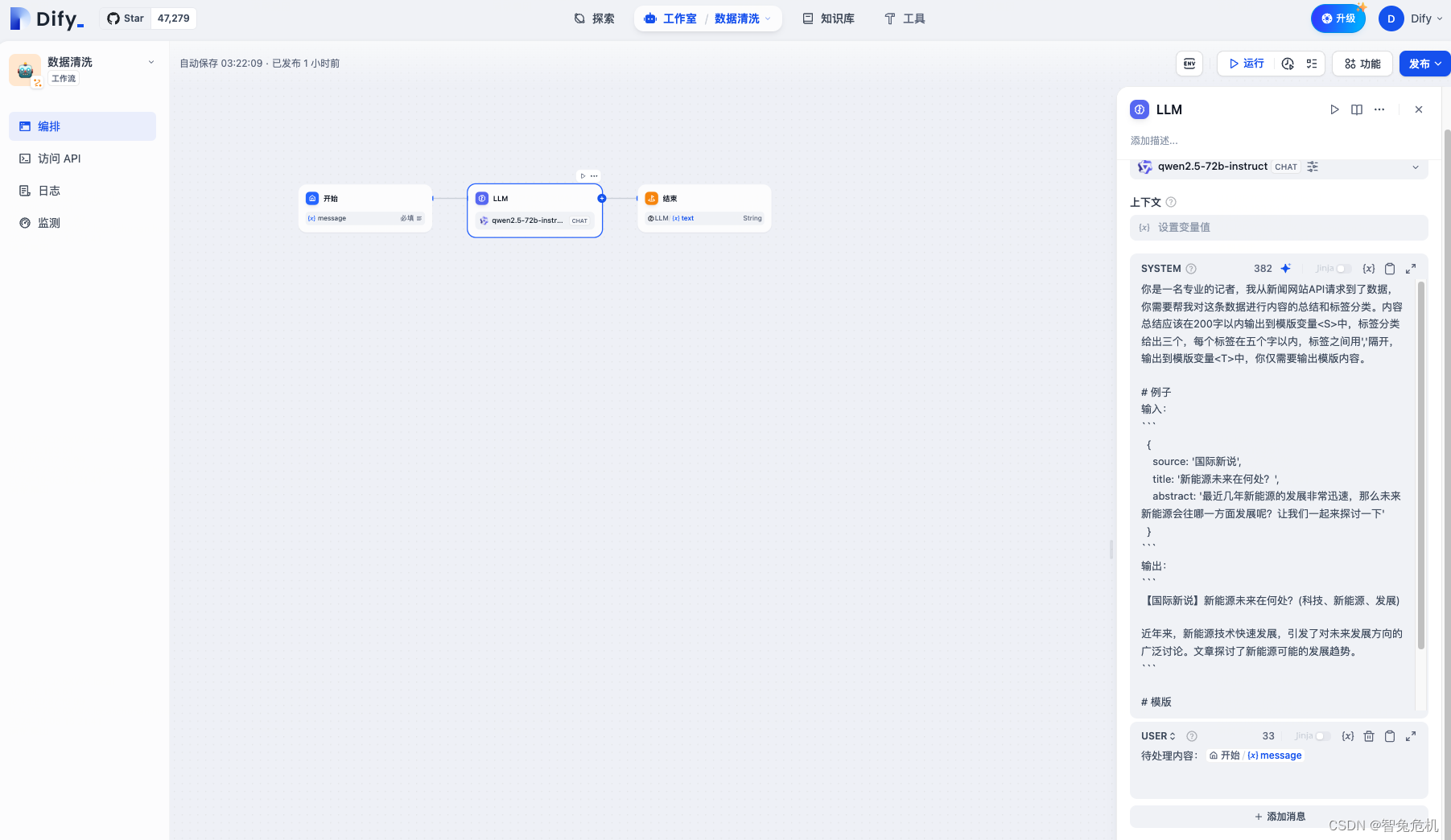
使用的Prompt如下,注意我们Prompt里面需要精确提到 背景(激活参数)、任务(明确目标)、输出需求(明确要求)、例子(明确要求):
你是一名专业的记者,我从新闻网站API请求到了数据,你需要帮我对这条数据进行内容的总结和标签分类。内容总结应该在200字以内输出到模版变量<S>中,标签分类给出三个,每个标签在五个字以内,标签之间用','隔开,输出到模版变量<T>中,你仅需要输出模版内容。
# 例子
输入:
{
source: '国际新说',
title: '新能源未来在何处?',
abstract: '最近几年新能源的发展非常迅速,那么未来新能源会往哪一方面发展呢?让我们一起来探讨一下'
}
输出:
【国际新说】新能源未来在何处?(科技、新能源、发展)
近年来,新能源技术快速发展,引发了对未来发展方向的广泛讨论。文章探讨了新能源可能的发展趋势。
# 模版
【source】title (<T>)
<S>
看看结果。
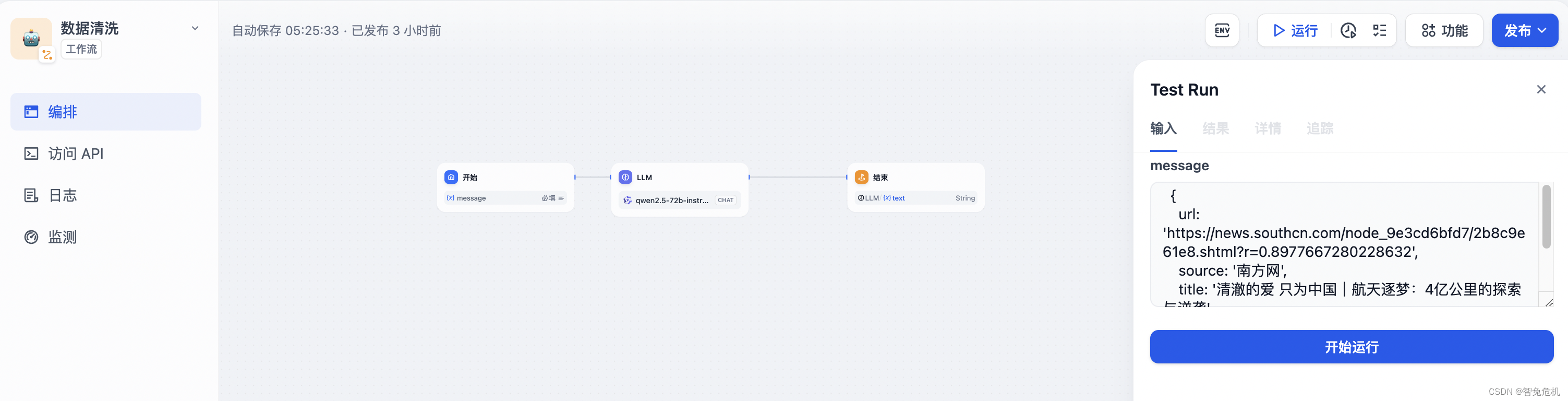
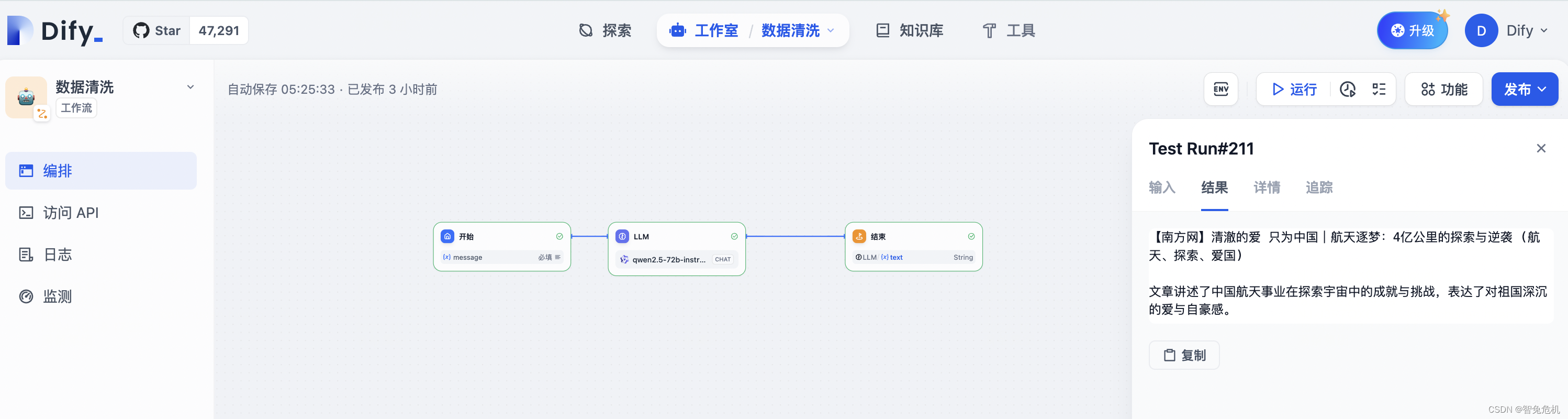
可以看到,输入我们刚才整理好的数据已经可以完成标题改写 + 打标签 + 内容总结了
现在我们可以使用我们刚才提取的数据,结合dify的这个工作流去完成总结文章内容 + 给文章打标签的功能。接下来只需要直接调用dify生成对应的接口,让模型帮我们接口,注意跟模型描述详细的接口需求。
这个是DIFY的接口文档
让模型编码
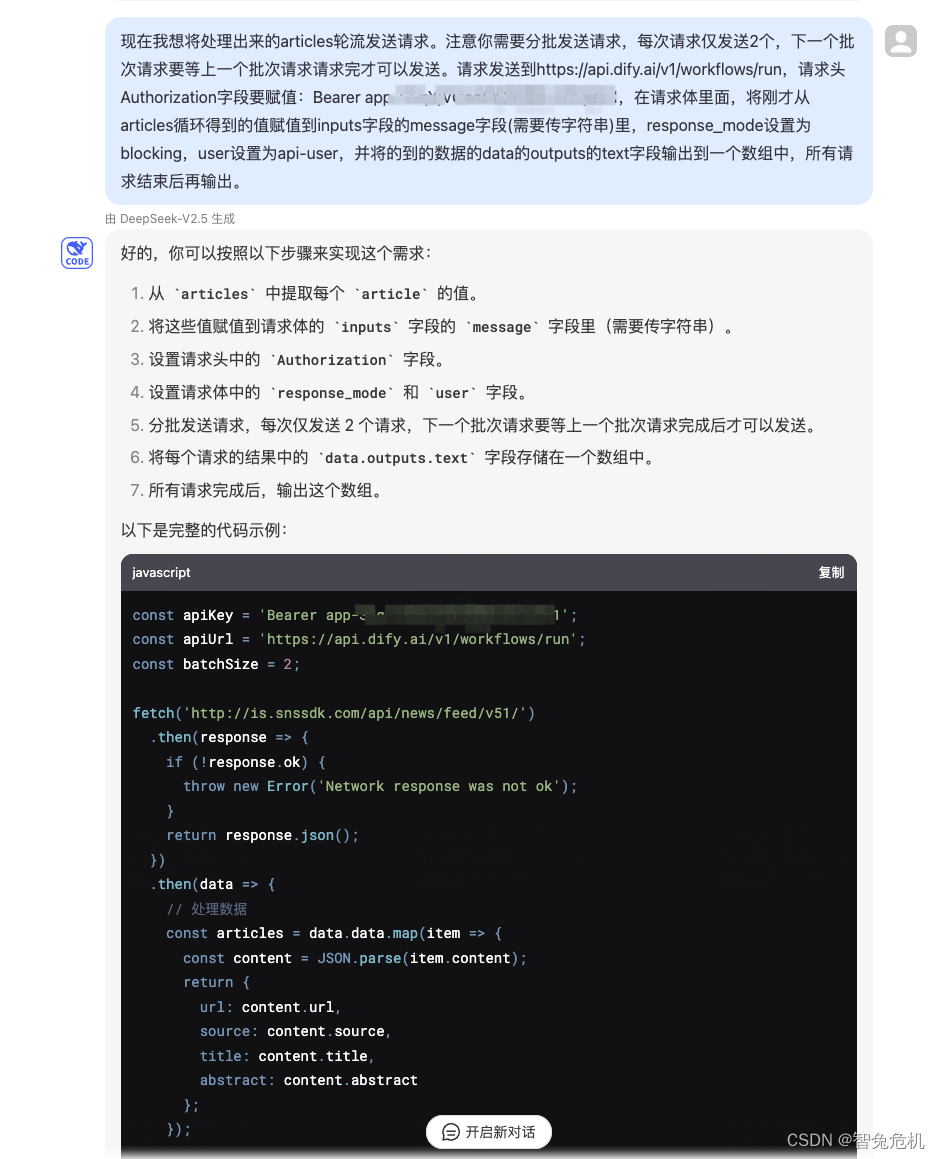
后端代码,主要就是调用了dify生成的接口,然后处理了一下输出:
const apiKey = 'YOUR_KEY';
const apiUrl = 'https://api.dify.ai/v1/workflows/run';
const batchSize = 2;
fetch('http://is.snssdk.com/api/news/feed/v51/')
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.json();
})
.then(data => {
// 处理数据
const articles = data.data.map(item => {
const content = JSON.parse(item.content);
return {
url: content.url,
source: content.source,
title: content.title,
abstract: content.abstract
};
});
// 发送请求并收集结果
const results = [];
const sendBatchRequests = (batch) => {
const requests = batch.map(article => {
const requestBody = {
inputs: {
message: JSON.stringify(article)
},
response_mode: 'blocking',
user: 'api-user'
};
return fetch(apiUrl, {
method: 'POST',
headers: {
'Authorization': apiKey,
'Content-Type': 'application/json'
},
body: JSON.stringify(requestBody)
})
.then(response => {
if (!response.ok) {
throw new Error(`Request failed with status ${response.status}`);
}
return response.json();
})
.then(result => {
if (result.data && result.data.outputs && result.data.outputs.text) {
results.push(result.data.outputs.text);
}
})
.catch(error => {
console.error('Error:', error);
});
});
return Promise.all(requests);
};
// 限制调用速率
const processArticlesInBatches = async (articles) => {
for (let i = 0; i < articles.length; i += batchSize) {
const batch = articles.slice(i, i + batchSize);
await sendBatchRequests(batch);
}
};
return processArticlesInBatches(articles).then(() => results);
})
.then(results => {
console.log('All results:', results);
})
.catch(error => {
console.error('Error:', error);
});
看看结果。

这时候清洗其实已经完成了,不过为了让整个过程更自动化和可视化,我们再用一个前端页面来展示。
前端页面构建和前后端交互
我们已经成功完成了数据处理和清洗,接下来简单地构建一下前端页面和前后端交互,注意key换成自己的,让AI编码。
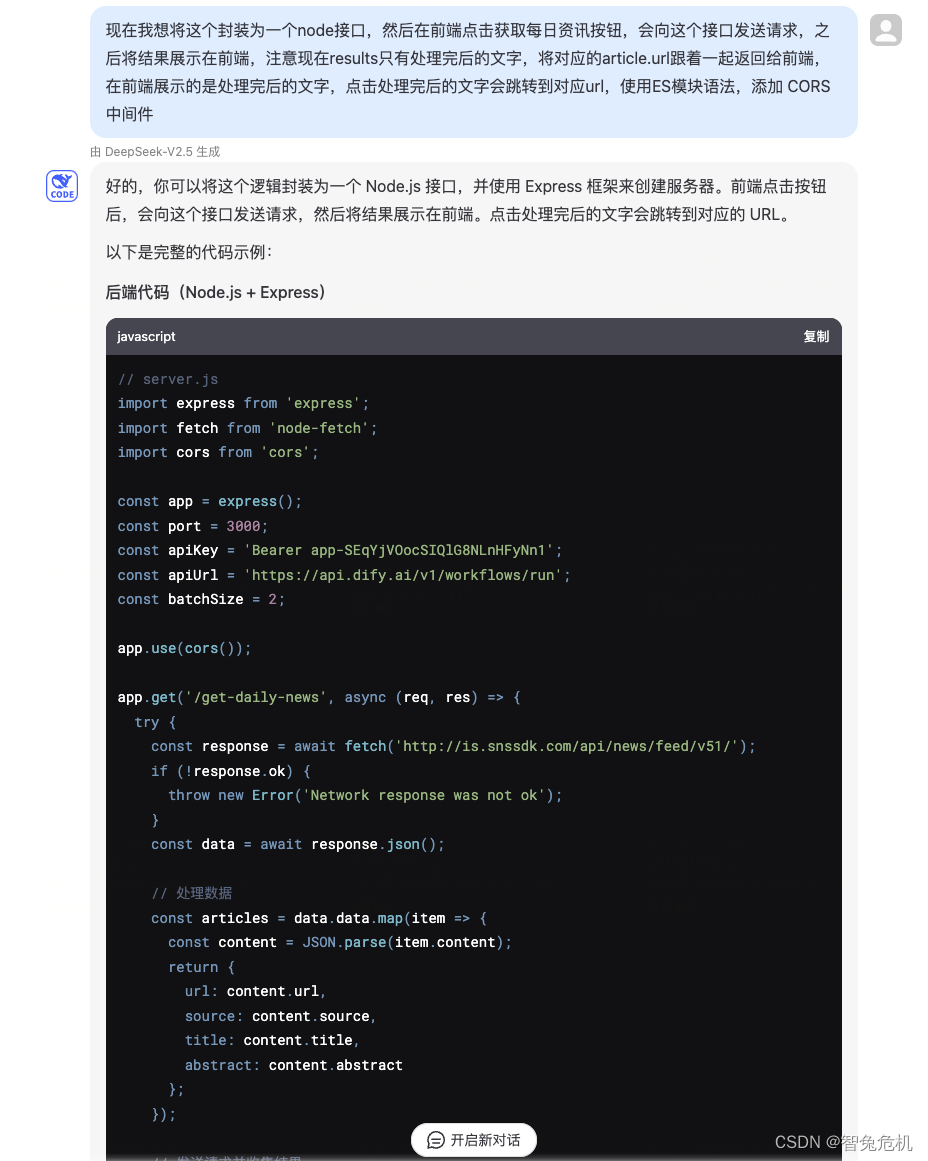
后端代码,主要是做成了端口形式,将数据按格式返回给前端:
// server.js
import express from 'express';
import fetch from 'node-fetch';
import cors from 'cors';
const app = express();
const port = 3000;
const apiKey = 'Bearer app-xxx';
const apiUrl = 'https://api.dify.ai/v1/workflows/run';
const batchSize = 2;
app.use(cors());
app.get('/get-daily-news', async (req, res) => {
try {
const response = await fetch('http://is.snssdk.com/api/news/feed/v51/');
if (!response.ok) {
throw new Error('Network response was not ok');
}
const data = await response.json();
// 处理数据
const articles = data.data.map(item => {
const content = JSON.parse(item.content);
return {
url: content.url,
source: content.source,
title: content.title,
abstract: content.abstract
};
});
// 发送请求并收集结果
const results = [];
const sendBatchRequests = (batch) => {
const requests = batch.map(article => {
const requestBody = {
inputs: {
message: JSON.stringify(article)
},
response_mode: 'blocking',
user: 'api-user'
};
return fetch(apiUrl, {
method: 'POST',
headers: {
'Authorization': apiKey,
'Content-Type': 'application/json'
},
body: JSON.stringify(requestBody)
})
.then(response => {
if (!response.ok) {
throw new Error(`Request failed with status ${response.status}`);
}
return response.json();
})
.then(result => {
if (result.data && result.data.outputs && result.data.outputs.text) {
results.push({
text: result.data.outputs.text,
url: article.url
});
}
})
.catch(error => {
console.error('Error:', error);
});
});
return Promise.all(requests);
};
const processArticlesInBatches = async (articles) => {
for (let i = 0; i < articles.length; i += batchSize) {
const batch = articles.slice(i, i + batchSize);
await sendBatchRequests(batch);
}
};
await processArticlesInBatches(articles);
res.json(results);
} catch (error) {
console.error('Error:', error);
res.status(500).json({ error: 'Internal Server Error' });
}
});
app.listen(port, () => {
console.log(`Server is running on http://localhost:${port}`);
});
前端代码,没什么好说的就是点击按钮然后获取新闻资讯接口数据,处理一下输出展示:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>每日新闻</title>
<style>
.news-item {
border: 1px solid #ccc;
padding: 10px;
margin-bottom: 10px;
margin-top: 10px;
border-radius: 5px;
}
</style>
</head>
<body>
<h1>每日新闻</h1>
<button id="getNewsBtn">获取每日新闻</button>
<div id="newsResults"></div>
<script>
document.getElementById('getNewsBtn').addEventListener('click', async () => {
try {
const response = await fetch('http://localhost:3000/get-daily-news');
if (!response.ok) {
throw new Error(`Network response was not ok: ${response.status}`);
}
const results = await response.json();
const newsResultsDiv = document.getElementById('newsResults');
newsResultsDiv.innerHTML = '';
results.forEach(result => {
// 去除 ```符号
const cleanedText = result.text.replace(/```/g, '');
// 创建超链接
const link = document.createElement('a');
link.href = result.url;
link.target = '_blank';
link.innerHTML = cleanedText.replace(/\n/g, '<br>'); // 将文本内容替换为带有换行符的HTML
const paragraph = document.createElement('p');
paragraph.appendChild(link);
const newsItem = document.createElement('div');
newsItem.classList.add('news-item');
newsItem.appendChild(paragraph);
newsResultsDiv.appendChild(newsItem);
});
} catch (error) {
console.error('Error:', error);
}
});
</script>
</body>
</html>
来看看最后效果。
点击后会跳到新闻页面,这样我们整个项目就完成了。
总结
全程不需要自己写一行代码,我们就完成了前后端开发和数据处理、数据清洗,效率提升肉眼可见。实际上这也是未来的趋势,在AI的加持下,我们每一个人的能力都会被无限放大,早日尝试并习惯高效使用AI才能帮助我们在新时代的变革中保持竞争力。