声明:以上内容全是学习Andrej Karpathy油管教学视频的总结。
---------------------------------------------------------------------------------------------------------------------------------
大家好。在今天我们学习llm中的Tokenization,即分词器部分。许多人可能之前对于这个过程没有太多的重视。但是实际上,LLM中许多奇怪的问题都可以追溯到Tokenization的过程中:
- 无法拼写单词
- 无法倒写单词
- 处理"<|endoftext|>"之类特殊字符时易出现混乱
- 为什么LLM相比于JSON而言,面对YAML文件更加友好。
- ...
这一切的根源都是在于模型的Tokenization部分。下面我为大家进行一一讲解。在讲解之前,我需要首先给大家简单的讲解一下,什么是模型的Tokenization?
原理
这里我引入State of GPT文章中的一些插图。文章里详细的解释了ChatGPT等LLM的技术路线,建议大家去看一下原视频。

如上图所示,在LLM的基础模型训练过程中,模型的输入是 (B, T) 的Token序列。而模型所得到的输出也即是预测下一个Token出现的概率分布。而这些数字,则是通过Tokenizer得到的。其生成流程如下。

这里我们看见,我们把文本按照一种奇怪的方式分割成了一个又一个的 sub word。目前大家只需要理解 Tokens部分一个颜色的块则对应模型训练的一个Token,而对于每一个Token,模型内部会有一个字典 vocab 对应一个 int 整数。这就是Tokenazition的过程。简而言之,Tokenization可以理解为把一串字符串转换成整数的列表。
现在我们理解了Tokenization的基本原理,我们对于上面的四个问题先给予一下简单的答复。
1. 无法拼写单词?
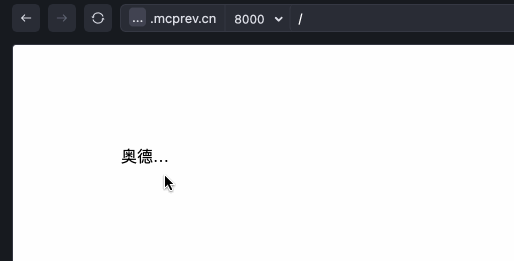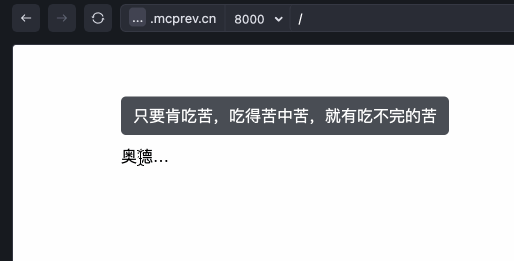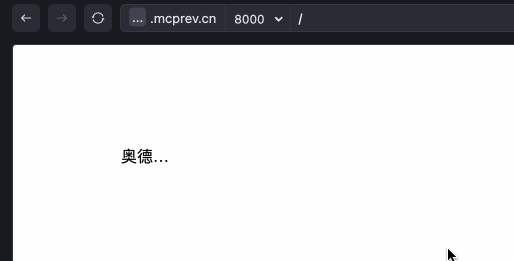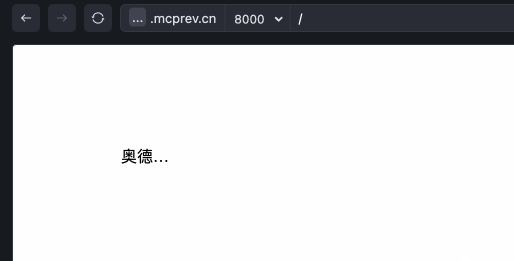
这里我们以一个单词 .DefaultCellStyle 为例子。在GPT4的分词器中,将这一长串文本分为了一个Token 98518。因此单词里的所有信息被压缩在了一个Token中。

因此若你询问GPT4有多少个l,会得到怎样的结果?如图...

2. 无法倒写单词
同理,如果我问如果反过来拼写 .DefaultCellStyle, 他会回答我一个奇怪的答案。

3. 处理"<|endoftext|>"之类特殊字符时易出现混乱
这是因为这些特殊字符有时在模型中具有其意义。因此某些时候存在问题。在Karpathy的视频里是存在问题的,不过目前我现在GPT是4o,貌似效果还好。
4.为什么LLM相比于JSON而言,面对YAML文件更加友好
这是因为相同内容的JSON和YAML文件,YAML文件的Token数更少,这是相当大的改进。Token少可以减少上下文长度。


代码
训练流程
在这里我们需要了解一个核心数据压缩算法BPE (字节对编码, Byte Pair Encoder) 。 简单的文字叙述可能不好理解,这里我直接以代码案例帮助大家理解。
text = "aaabdaaabac"
ids = list(text.encode(encoding="utf-8", errors="replace"))
print(ids)
# [97, 97, 97, 98, 100, 97, 97, 97, 98, 97, 99]这里我们list的作用是把utf-8的字节流转换成int,并且处理成int的形式。那么接下来我们就要统计这一个ids列表里面出现的字节对的次数。
def get_stats(ids: list, count=None) -> dict:
"""
找到字节对的统计次数
Example: [1, 2, 1, 2, 3] -> {(1, 2): 2, (2, 1): 1, (2, 3): 1}
:params ids: list, 字节流
:return count: dict, 字节对的统计次数
"""
count = {} if count is None else count
for (p0, p1) in zip(ids, ids[1:]):
count[(p0, p1)] = count.get((p0, p1), 0) + 1
return count
counts = get_stats(ids)
print(counts)
# {(97, 97): 4, (97, 98): 2, (98, 100): 1, (100, 97): 1, (98, 97): 1, (97, 99): 1}这里我们就知道97,97是出现了4次的。那么接下来,我们就要把(97, 97)这个字节对用一个新的id来替代。
def merge(ids: list, pair: tuple, idx: int) -> list:
"""
将字节对用最新idx替换
Example: ids=[1, 2, 3, 1, 2], pair=(1, 2), idx = 4 -> [4, 3, 4]
:params ids: list, 原字节串
:params pair: tuple, 原字节对
:params idx: int, 新索引
:return new_ids: list, 新字节串
"""
new_ids = []
i = 0
while i < len(ids):
if i < len(ids) - 1 and ids[i] == pair[0] and ids[i + 1] == pair[1]:
new_ids.append(idx)
i = i + 2
else:
new_ids.append(ids[i])
i = i + 1
return new_ids
new_id = merge(ids, (97, 97), 256)
print(new_id)
# [256, 97, 98, 100, 256, 97, 98, 97, 99]以上的流程就完成了一次字节对的替换。同时我们的词汇也增加了一。这里大家可能疑惑词汇是什么。这里需要解释一下,由于utf-8编码是字节的变长排序。所以在训练的过程中,我们一般会把0-255的字节默认存储在字典中。同时替换一次,我们的词汇就会增加一。替换次数越多,词汇量越多,压缩的就越多,训练过程中能承载的原始文本原理上可以更多。
但是,词汇量并不是越多越好,了解Transformer结构的同学应该能理解,词汇量增多的话,会出现几个问题:
- 出现许多低频词汇,学习变得困难
- 参数量增多,增加计算成本
- 过拟合
- ...
因此,这个词汇量也是在模型训练过程中需要权衡的一个点。要既能捕捉复杂语言的细微差别,也要权衡上面的因素。
上面的流程只是一次字节对替换的流程,接下来我把完整的训练流程以及中间变量尽可能详细的给大家通过代码展示出来。
vocab_size = 256 + 3 # 词汇量大小
num_merges = vocab_size - 256 # merge次数
idx = 256
vocab = {i: bytes([i]) for i in range(256)} # 初始的词汇
merges = {} # (int, int) -> int
text = "aaabdaaabac"
ids = list(text.encode(encoding="utf-8", errors="replace"))
# 进行字节对的替换
for i in range(num_merges):
new_id = idx + i # 字节对的新编号
stats = get_stats(ids)
pair = max(stats, key=stats.get) # 出现次数最多的字节对
ids = merge(ids, pair, new_id) # 替换字节对
vocab[new_id] = vocab[pair[0]] + vocab[pair[1]]
merges[pair] = new_id
print(f"{pair} -> {new_id} {vocab[new_id].decode("utf-8")}")
# (97, 97) -> 256 aa
# (256, 97) -> 257 aaa
# (257, 98) -> 258 aaab接下来,我们还需要编写两个重要的函数 encoder 与 decoder。作用当然大家也清楚:完成文本与ids之间的转换。
def decode(ids):
tokens = b"".join(vocab[idx] for idx in ids)
text = tokens.decode("utf-8", errors="replace")
return text
# 这里要注意BPE的合并顺序
def encode(text):
tokens = list(text.encode("utf-8"))
while len(tokens) >= 2:
stats = get_stats(tokens)
pair = min(stats, key=lambda p: merges.get(p, float("inf")))
if pair not in merges:
break
tokens = merge(tokens, pair, merges[pair])
return tokens大家可以自己尝试一下。
以上即为一次完整的训练过程。当然这相比于GPT的部分还是缺少了一些东西。不过不要紧,在下面我会以下面的内容为基础,为大家构建简单的Tokenizer。
Base
这里我们在文件夹下的base.py中创建一个用于继承的基础类,完成一些基本函数,制定标准。
import unicodedata
def get_stats(ids: list, count=None) -> dict:
"""
找到字节对的统计次数
Example: [1, 2, 1, 2, 3] -> {(1, 2): 2, (2, 1): 1, (2, 3): 1}
:params ids: list, 字节流
:return count: dict, 字节对的统计次数
"""
count = {} if count is None else count
for (p0, p1) in zip(ids, ids[1:]):
count[(p0, p1)] = count.get((p0, p1), 0) + 1
return count
def merge(ids: list, pair: tuple, idx: int) -> list:
"""
将字节对用最新idx替换
Example: ids=[1, 2, 3, 1, 2], pair=(1, 2), idx = 4 -> [4, 3, 4]
:params ids: list, 原字节串
:params pair: tuple, 原字节对
:params idx: int, 新索引
:return new_ids: list, 新字节串
"""
new_ids = []
i = 0
while i < len(ids):
if i < len(ids) - 1 and ids[i] == pair[0] and ids[i + 1] == pair[1]:
new_ids.append(idx)
i = i + 2
else:
new_ids.append(ids[i])
i = i + 1
return new_ids
def replace_control_charactors(s: str) -> str:
"""
去除字符串中的控制字符, 如"\n" 用unicode码表示
Example: "hello \n world" -> "hello \u000a world"
:params s: str, 原字符串
:return : str, 新字符串
"""
chars = []
for ch in s:
if unicodedata.category(ch)[0] == "C":
chars.append(f"\\u{ord(ch):04x}")
else:
chars.append(ch)
return "".join(chars)
def render_token(t: bytes) -> str:
"""
将字节流转换成str 并去除控制字符
Example: 0x68 0x65 0x6c 0x6c 0x6f 0x20 0x0a 0x20 0x77 0x6f 0x72 0x6c 0x64 -> hello \u000a world
:params t: bytes 字节流
:return s: str 字符串
"""
s = t.decode(encoding="utf-8", errors="replace")
s = replace_control_charactors(s)
return s
class Tokenizer():
"""Base class for Tokenizers"""
def __init__(self):
"""
Attributes:
merges (dict): 存储合并的对和新ID的映射。
vocab (dict): 存储字典,包含字符及其对应的字节表示。
special_tokens(dict): 特殊字符
pattern(str): 模式
"""
self.merges = {} # (int, int) -> int
self.pattern = "" # str
self.special_tokens = {} # str -> int, e.g. {{'<|endoftext|>': 100257}}
self.vocab = self._build_vocab() # int -> bytes
def train(self, text, vocab_size, verbose=False):
raise NotImplementedError
def encode(self, text):
raise NotImplementedError
def decode(self, ids):
raise NotImplementedError
def _build_vocab(self):
vocab = {idx: bytes(idx) for idx in range(256)}
for (p0, p1), idx in self.merges.items():
vocab[idx] = vocab[p0] + vocab[p1]
for special, idx in self.special_tokens.items():
vocab[idx] = special.encode("utf-8", errors="replace")
return vocab
def save(self, file_prefix):
# 保存模型文件,用于导入
model_file = file_prefix + ".model"
with open(model_file, 'w') as f:
f.write("minbpe v1\n")
f.write(f"{self.pattern}\n")
f.write(f"{len(self.special_tokens.items())}\n")
for special, idx in self.special_tokens.items():
f.write(f"{special} {idx}\n")
for idx1, idx2 in self.merges:
f.write(f"{idx1} {idx2}\n")
# 保存vocab 用于人工检查
vocab_file = file_prefix + ".vocab"
inverted_merges = {idx: pair for pair, idx in self.merges.items()}
with open(vocab_file, 'w', encoding="utf-8") as f:
for idx, token in self.vocab.items():
s = render_token(token)
if idx in inverted_merges:
idx0, idx1 = inverted_merges[idx]
s0 = render_token(self.vocab[idx0])
s1 = render_token(self.vocab[idx1])
f.write(f"[{s0}][{s1}] -> [{s}] {idx}\n")
else:
f.write(f"[{s}] {idx}\n")
def load(self, model_file):
assert model_file.endswith(".model")
# 读取model文件
merges = {}
special_tokens = {}
idx = 256
with open(model_file, 'r') as f:
version = f.readline().strip()
assert version == "minbpe v1"
self.pattern = f.readline().strip()
num_special = int(f.readline().strip())
for _ in range(num_special):
special, special_idx = f.readline().strip().split()
special_tokens[special] = int(special_idx)
for line in f:
idx1, idx2 = map(int, line.split())
merges[(idx1, idx2)] = idx
idx += 1
self.merges = merges
self.special_tokens = special_tokens
self.vocab = self._build_vocab()Basic
接下来我们按照上面的BPE算法,不考虑特殊字符与正则化分割,创建一个最基本的Tokenizer类。
from base import Tokenizer, get_stats, merge
class BasicTokenizer(Tokenizer):
"""
最简单的BPE进行分词
"""
def __init__(self):
super().__init__()
def train(self, text, vocab_size, verbose=False):
"""
对text进行训练,通过BPE得到merge
params text: str, 文本训练内容
params vocab_size: int(>=256), 得到merge个数为(vocab_size - 256)
params verbose: bool, 是否打印
"""
assert vocab_size >= 256
num_merges = vocab_size - 256
idx = 256
text_bytes = text.encode("utf-8", "replace")
ids = list(text_bytes)
vocab = {i : bytes([i]) for i in range(256)}
merges = {}
for i in range(num_merges):
new_id = idx + i
stats = get_stats(ids)
pair = max(stats, key=stats.get)
merges[(pair)] = new_id
ids = merge(ids, pair, new_id)
vocab[new_id] = vocab[pair[0]] + vocab[pair[1]]
if verbose:
print(f"merge {i + 1}/{num_merges}:{pair} -> {idx}erges: {pair} -> {idx} ({vocab[idx]}) had {stats[pair]} occurrences")
self.merges = merges
self.vocab = vocab
def encode(self, s):
s_bytes = s.encode(encoding="utf-8", errors="replace")
ids = list(s_bytes)
while len(ids) >= 2:
stats = get_stats(ids)
# merge需要按照训练时的先后顺序
pair = min(stats, key=lambda p: self.merges.get(p, float("inf")))
if pair not in self.merges:
break
ids = merge(ids, pair, self.merges[pair])
return ids
def decode(self, ids):
t = b"".join(self.vocab[i] for i in ids)
return t.decode(encoding="utf-8", errors="replace")
if __name__ == "__main__":
tokenizer = BasicTokenizer()
text = "aaabdaaabac"
tokenizer.train(text, 256+3)
print(tokenizer.encode(text))
print(tokenizer.decode([258, 100, 258, 97, 99]))
tokenizer.save("toy")
regex
接下来又是一个重要的知识点。即在BPE算法中,我们希望一些字节对永远不要出现,因而我们需要利用regex库提前对于regex进行分割。同时需要对于特殊字符进行一定的处理。分割原理如下:
import regex as re
gpt2pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
print(re.findall(gpt2pat, "Hello've world123 how's are you!!!?"))
# ['Hello', "'ve", ' world', '123', ' how', "'s", ' are', ' you', '!!!?']然后同样的,我们则是多了一个循环,对于每一个块进行统计与字节对替换的操作。以此为基础创建regex类。
import regex as re
from base import Tokenizer, get_stats, merge
# the main GPT text split patterns, see
# https://github.com/openai/tiktoken/blob/main/tiktoken_ext/openai_public.py
GPT2_SPLIT_PATTERN = r"""'(?:[sdmt]|ll|ve|re)| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+"""
GPT4_SPLIT_PATTERN = r"""'(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+"""
class RegexTokenizer(Tokenizer):
"""
添加正则化和特殊令牌的分词器
"""
def __init__(self, pattern=None):
super().__init__()
self.pattern = GPT4_SPLIT_PATTERN if pattern is None else pattern
self.compiled_pattern = re.compile(pattern=self.pattern)
self.special_tokens = {} # str -> int, example: {'<|endoftext|>': 100257}
self.inverse_special_tokens = {}
def train(self, text, vocab_size, verbose=False):
ids_chunks = [list(ck.encode("utf-8", errors="replace") for ck in self.compiled_pattern.findall(text))]
vocab_size = 256 + 3
num_merges = vocab_size - 256
vocab = {i: bytes([i]) for i in range(256)}
merges = {}
idx = 256
for i in range(num_merges):
new_id = idx + i
stats = {}
for chunk in ids_chunks:
if len(chunk) >= 2:
stats = get_stats(chunk, stats)
pair = max(stats, key=stats.get)
ids_chunks = [merge(chunk, pair, new_id) for chunk in ids_chunks]
merges[pair] = new_id
vocab[new_id] = vocab[pair[0]] + vocab[pair[1]]
if verbose:
print(f"{pair} -> {new_id}")
self.merges = merges
self.vocab = vocab
def register_special_tokens(self, special_tokens):
self.special_tokens = special_tokens
self.inverse_special_tokens = {v: k for k, v in special_tokens.items()}
def decode(self, ids):
part_bytes = []
for idx in ids:
if idx in self.vocab:
part_bytes.append(self.vocab[idx])
elif idx in self.inverse_special_tokens:
part_bytes.append(self.inverse_special_tokens[idx].encode(encoding="utf-8", errors="replace"))
else:
raise ValueError(f"invalid token id: {idx}")
text_bytes = b"".join(part_bytes)
text = text_bytes.decode(encoding="utf-8", errors="replace")
return text
def _encode_chunk(self, text_bytes):
"""
就是正常的encode,只不过这里没有对于special tokens的处理
"""
ids = list(text_bytes)
while len(ids) >= 2:
stats = get_stats(ids)
pair = min(stats, key=lambda p: self.merges.get(p, float("inf")))
if pair not in self.merges:
break
idx = self.merges[pair]
ids = merge(ids, pair, idx)
return ids
def encode_ordinary(self, text):
"""Encoding that ignores any special tokens."""
text_chunks = re.findall(self.compiled_pattern, text)
ids = []
for chunk in text_chunks:
chunk_bytes = chunk.encode("utf-8") # raw bytes
chunk_ids = self._encode_chunk(chunk_bytes)
ids.extend(chunk_ids)
return ids
def encode(self, text, allowed_special="none_raise"):
# decode the user desire w.r.t. handling of special tokens
special = None
if allowed_special == "all":
special = self.special_tokens
elif allowed_special == "none":
special = {}
elif allowed_special == "none_raise":
special = {}
assert all(token not in text for token in self.special_tokens)
elif isinstance(allowed_special, set):
special = {k: v for k, v in self.special_tokens.items() if k in allowed_special}
else:
raise ValueError(f"allowed_special={allowed_special} not understood")
if not special:
# shortcut: if no special tokens, just use the ordinary encoding
return self.encode_ordinary(text)
special_pattern = "(" + "|".join(re.escape(k) for k in special) + ")"
special_chunks = re.split(special_pattern, text)
ids = []
for part in special_chunks:
if part in special:
ids.append(special[part])
else:
ids.extend(self.encode_ordinary(part))
return ids
regex基本实现了GPT4的简易功能。当然还是有一些不同,欢迎大家去Karpathy的Github仓库看一下他的代码。我太懒了,最后的gpt4tokenizer没有实现。
以上则是个人总结的所有内容。欢迎大家交流讨论~