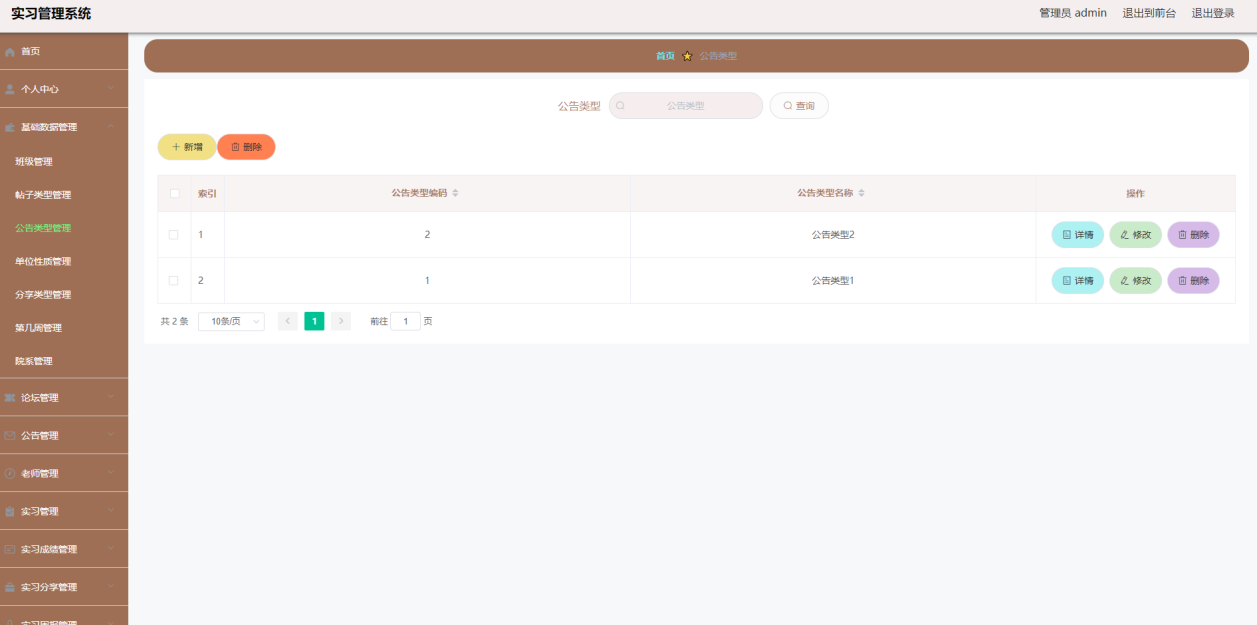
1.进程终止
(1)错误码
对于程序常见错误信息,C/C++提供了信息解释,保存在<string.h>,使用strerror(错误码)就可以查询

错误信息成立的前提是错误码要和错误信息匹配,我们需要结合C/C++给我们的错误码来配套使用。<errno.h>被引用后程序就多了一个全局变量errno,当某一步操作出现问题时,errno会更新,此时我们就可以打印错误获取具体信息了。我们当然可以手动验证errno的存在以及它的作用。唯一需要注意的是要及时使用,因为如果有两个错误,errno很有可能会被后面的错误码覆盖。

我们可以简单使用一下,当打开不存在的文件时,错误码就会更新。

归根到底,这些错误码的更新主要还是靠库函数自己的支持,是在库函数里遇上错误后使用errno = (错误码)的方式来更新的,如果遇上不支持C/C++错误码的函数,我们就要自定义错误信息了。
(2)区分退出码和错误码
错误码反映程序运行中的某一行代码触发的错误,并且多个错误可以覆盖;而退出码是指我们程序里return跟的数字,代表整个程序的运行状态,在不同状况下通常唯一。
main函数的返回值是返回给父进程的。echo $?指令会显示最近一个程序退出时的退出码,它能反应程序是为何退出的。一般来说,退出码0表示程序执行成功,非0表示失败。当代码执行到我们在main最后写的return语句时,程序至少走到了我们规定的结尾,一切结果也都是在我们可控的范围,所以默认都写0。当然我们可以自己约定一套规则来表明不同状态。

注意echo $?要及时,如果运行多个程序,可能就会出现退出码的覆盖情况,这和错误码是一致的。但错误码是一个程序内部的多个错误信息覆盖,退出码是不同程序最终运行状态的覆盖,对象不一致。同时错误码和退出码之间没有必然联系,我们要分清。
退出码是给父进程看的,父进程一看就知道子进程任务完成的情况了。
(3)exit和_exit
函数的return代表返回上一层函数栈帧,返回值被上一层函数接收,对于main来说return的值才是退出码。还有两个函数,exit(1)和_exit(1)可以退出程序并返回值作为退出码,在代码任何地方都可以直接终止进程。但这两个函数有一点不同。

exit()会主动刷新缓冲区,将缓冲区的内容输出,但显然_exit()就不会,缓冲区里面的数据直接丢失。

这里也可验证当父进程先结束时,子进程会变成孤儿进程,交给系统保管,此时子进程也会变成后台进程,不会影响前台操作。

由于子进程变成孤儿进程,被系统带走了,因此bash不再是孤儿进程的父进程,bash得到的退出码也就只有父进程的退出码2。
_exit(1)偏向于系统层面,系统级别的头文件只能写<unistd.h>。exit()是语言级别的函数。语言级别的头文件可以写<cstdio><cstdlib>等。
我们需要知道,_exit()之所以被称为系统级函数,是因为_exit()就是操作系统的系统调用接口之一。我们的glibc等库是在系统调用接口之上,exit()是在_exit()的基础上加入了刷新缓冲区的功能。从这里我们就能发现,缓冲区这个概念在系统层面是不存在的,它是语言级别的。C和C++的缓冲区独立,分别适配各自语言的特性。
使用man 2 _wait可以查到系统级函数_wait(man手册第2页查系统级函数)

使用man 3 wait可以查到语言级函数wait(man手册第3页查语言级函数)

2.进程等待
(1)孤儿进程和僵尸进程
我们之前讲过当父进程退出而子进程还在工作时,子进程就会变成孤儿进程并被系统领养,孤儿进程会被自动移到后台运行。那么如何避免孤儿进程的产生呢?那就需要让父进程等一下子进程了。我们已经知道,如果什么都不做,父进程在执行完自己的任务后是会直接退出的,它是不会管子进程的。所以我们需要函数来阻挡它退出,那就是wait。
如果子进程完成后,其数据代码都会被释放,即进程地址空间里面堆区、栈区等对应的物理内存会被回收。但是最后还是会留下PCB的一些信息,以提供给父进程。父进程不会主动去读,当父进程结束退出后,子进程就变成了僵尸进程。我们依然需要父进程显式调用wait来读取子进程的信息。
注意,如果这个父进程是系统相关的进程,我们就无需担心,它会自己wait,但我们自己造的父子进程就要注意以上问题。
(2)wait
wait是语言级函数,我们可以查到它的相关参数,注意头文件的包含

我们使用wait(NULL)就可以等待任何进程,但注意每次wait都只能等待和读取一个进程,因此如果存在多进程情况,我们要保证wait的次数足够多。我们可以结合wait的返回值进行判断,当返回值是-1时就说明wait失败,该父进程下已经没有子进程了。

无论子进程跑得有多快,它最后都会变成僵尸等着父进程来回收,且按照上面的代码逻辑,只有wait到了一个子进程之后才会又fork,也就是说无论进程调度的公平性怎么样,无论子进程被调度得有多频繁,都会是上图结果,一父一子交替打印,导致这种结果和父进程被阻塞有很强关系。
父进程wait子进程除了避免僵尸或孤儿,还想要知道子进程任务完成的怎么样,也就是子进程的退出码。我们需要自己开辟一个int status,再将指针传过去,这样wait就可以通过指针修改传递子进程的退出码,同时返回子进程的pid给父进程

我们通过status可以得到退出相关信息,但是上图所示似乎不太对劲,每一次打印都是得到6144,而进程的退出码应该都是24才对。事实上,如果在status里只存退出码那就过于浪费了,在32bit里面仅有8bit用于存储退出码。
(3)进程退出信息
在wait返回的退出信息中,status除了退出码,还保存了一些其它信息。
①正常退出
正常退出是指程序通过我们自己写的return语句退出的,相当于程序整体在我们手上是可控的。我们可以根据退出码诊断程序的问题。

在退出信息status的32bit中,使用了低16bit,退出码的范围是0 ~ 255,刚好一字节。
②异常退出
异常退出是指程序根本就没有走到return我们写的语句就退出了,是被系统强制杀掉的。这种情况我们需要进一步得到进程的终止信息,就要用到前8位。
注意,异常退出后退出码的内容没有意义,根本就没走到我们的return语句,何来退出码?
终止信号是什么?是当出现很严重的问题时,系统会强制终止我们进程使用的信号。(如野指针(segmentation fault),0做除数(float point exception)等都会触发进程终止)当进程收到对应的信号,就会做出反应并修改自己的退出信息。这种信号和我们kill使用的选项一致

我们的kill -9之所以能杀掉进程,也是因为这条指令是向进程发送了9这个终止信号,这才让进程停下来。我们也能发现,kill没有0选项,这是因为终止信号不能为0,为0的话那就是程序正常退出。
还有一个就是core dump标志。当发生进程异常终止时,有可能会生成一个core dump文件,用于记录终止时进程调用的相关信息。如果有这个文件生成,那就是1,如果异常终止但没有生成文件或程序正常退出,那就是0.
③获取进程退出信息
使用位运算我们可以解读进程退出信息,我们只需要在自己需要的范围按位与1即可

每一个16进制都可以转为4bit,我们可以灵活控制16进制来控制这4bit中哪些是0,哪些是1,进而通过与运算将我们需要的信息拿到。
当然也有一些宏函数可以参考,不过只要我们记住了结构,获取到信息还是很容易的。
WIFEXITED(status):检查子进程是否正常退出
WEXITSTATUS(status):如果正常退出,获取子进程的退出状态码
WIFSIGNALED(status):检查子进程是被终止信号控制终止
WTERMSIG(status):获取导致子进程终止的终止信号
WCOREDUMP(status):检查子进程是否生成了 core dump 文件
(4)waitpid
我们刚刚的man 3 wait还显示了一个函数,waitpid,这是一个功能更强大的wait,为我们在读取子进程信息上留出了更多选择。
wait的出现已经能够消灭僵尸进程和控制孤儿进程了,并且也能得到退出信息。但我们其实有的时候不想让父进程一直被阻塞,这会降低程序的效率;并且有的时候我们想要创造孤儿进程,不想让父进程一直等着一个相当长时间不会退出的子进程,所以我们需要选择我们想要wait的进程。
waitpid的第一个参数是pid_t pid,表示选择wait的子进程的pid,当pid是-1时表示不受限制,等待任意子进程,和wait功能一致;waitpid的第二个参数int* status和wait一致,都是接收退出信息的指针。
waitpid的第三个参数int options是决定waitpid受不受阻塞的问题。受阻塞时options为0;当机器被阻塞时,一般叫做hang住了。当第三个参数是WNOHANG时,就说明waitpid采用非阻塞等待。非阻塞等待的意思是只在调用waitpid时去读取相应进程的退出信息,如果读到了就返回该子进程的pid,如果这个进程还没有退出就返回0,如果没有子进程了就返回-1
这就意味着wait或者options为0的waitpid会一直等进程把事情办完,而WNOHANG的waitpid看一眼进程就走了。我们可以减少wait的时间,但相应wait的次数就会增加,因为看一眼可能进程还没有退出,那就一定要多来看几眼直到进程全部退出,只不过这中间的时间进程可以干其他事,不会被阻塞而已。它和wait的本质功能没有差异。

我们能看到在子进程运行期间父进程还做了很多事情。注意waitpid一定要做到多次定期调用,防止僵尸进程出现