python爬虫--tx动漫完整信息抓取
news2026/2/13 18:44:54




本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2202820.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

CPU超线程技术是什么,怎么启用超线程技术
超线程技术是一种允许单个物理CPU核心模拟成两个逻辑核心的技术,从而提升处理器的并行性能和效率。以下是对超线程技术的详细介绍:
基本概念:超线程(Hyper-Threading,HT)是Intel公司研发的一种技术&#x…
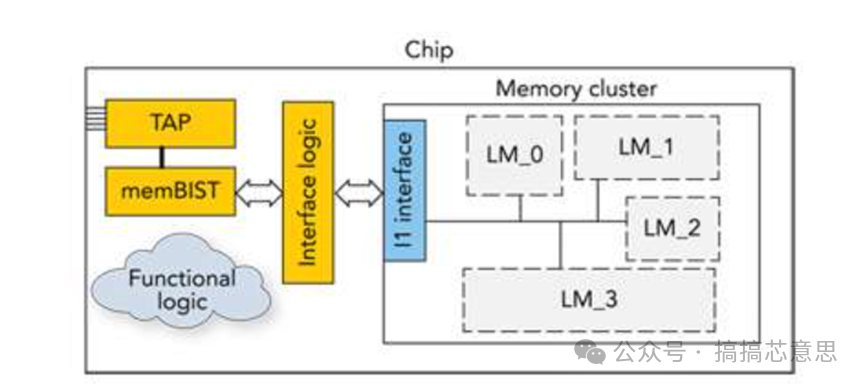
mbist之sharebus知识小结
本文摘录至微信公众号 搞搞芯意思 为何用sharebus? CPU/NPU/GPU等关键模块对性能要求很高,对功耗、时序、面积敏感,是整个芯片设计瓶颈。常规mbist设计插入的额外电路会对function时序收敛带来负面影响,而且会造成布线拥堵,给芯片性能和pd设计带来挑战。sharebus方…

【环境搭建】远程服务器搭建ElasticSearch
参考:
非常详细的阿里云服务器安装ElasticSearch过程..._阿里云服务器使用elasticsearch-CSDN博客
服务器平台:AutoDL
注意:
1、切换为非root用户,su 新用户名,否则ES无法启动
2、安装过程中没有出现设置账号密码…

python发送邮件带附件:配置全指南与步骤?
python发送邮件带附件教程?python如何发邮件带附件?
无论是工作报告、项目文档还是个人通知,邮件都能快速传递信息。而当这些信息需要附带文件时,Python发送邮件带附件的功能就显得尤为重要。AokSend将详细介绍如何使用Python发送…



C# 创建Windows服务,bat脚本服务注册启动删除
1、创建Windows服务,如下图。.NET Framework 4。Visual Studio 2019 。 2、在项目文件夹下创建文件夹LogConfig用于配置log4net,在LogConfig文件夹下新建log4net.config文件,如下图。 log4net.config文件内容如下。
<?xml version"…

能自动铲屎的自动猫砂盆是智商税吗?双十一热门自动猫砂盆推荐
大家平时一天要给猫咪铲几次屎呢?大多数应该都是早中晚各一次吧,在家的时候尚且能办到,但是一到了上班、出差、旅游的日子,我们又要如何保证猫咪的猫砂盆得到及时的清洁呢?要知道小猫咪的屎也很臭,猫砂盆长…

Linux云计算 |【第四阶段】RDBMS2-DAY4
主要内容:
MHA概述、部署MHA集群 一、MHA概述
1、MHA简介
MHA(Master High Availability)是一款开源的MySQL的高可用程序,由日本DeNA公司youshimaton开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的…

Vue组件继承与扩展
Vue组件继承与扩展
前言
与Class继承类似,在Vue中可以通过组件继承来达到复用和扩展基础组件的目的,虽然它可能会带来一些额外的性能损耗和维护成本,但其在解决一些非常规问题时有奇效。本文将通过一些非常规的功能需求来讨论其实现过程。 …

广州自闭症寄宿学校有哪些?选择最适合孩子的学校
在广州这座繁华而充满人文关怀的城市里,有一群特殊的孩子,他们被称为“星星的孩子”——自闭症儿童。他们生活在自己的世界里,对外界的刺激反应迟钝或过度敏感,社交互动困难,语言表达受限。然而,在广州&…

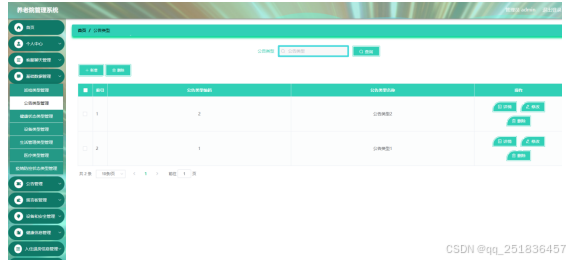
基于springboot和vue.js 养老院管理系统设计与实现
博主介绍:专注于Java(springboot ssm springcloud等开发框架) vue .net php phython node.js uniapp小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆…
LLM-RAG相关常见面试题
#############【持续更新】##############
LLM-RAG相关常见面试题
1. RAG技术体系的总体思路
RAG可分为5个基本流程:知识文档的准备;嵌入模型(embedding model);向量数据库;查询检索和生产回答。 参考&a…
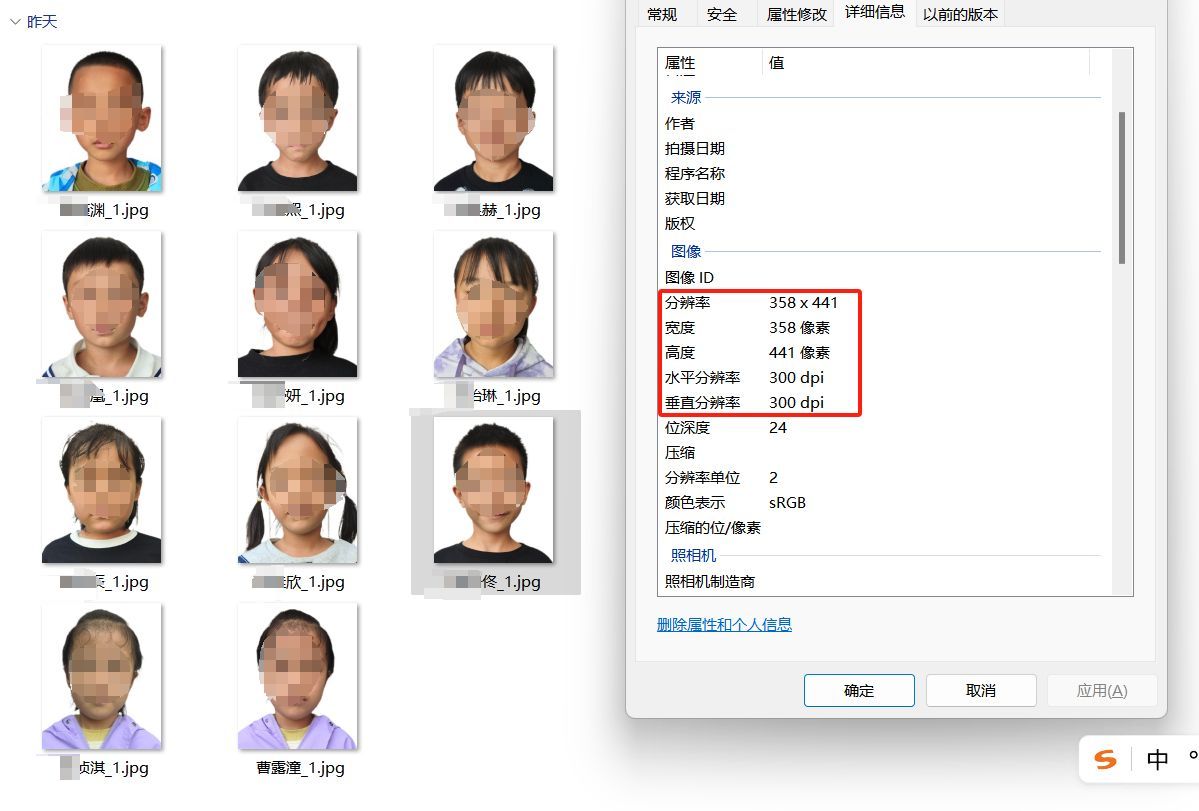
山西省中小学生学籍照片手机拍照集中采集指南
随着山西省教育信息化的持续发展,学校管理的数字化转型中,学籍信息的精确记录变得尤为关键。在这一背景下,学籍管理系统的优化升级显得尤为重要。为了保障学生资料的精确无误,山西省对中小学生学籍系统中的照片采集和上传流程提出…

5本一投就中的极速期刊,性价比高,1周-1个月录用,见刊极快!
在当今快节奏的学术界,研究者们不仅追求高质量的研究成果,还希望能够迅速地将这些成果分享给全球的同行。为此,科检易学术精心挑选了10本以高效审稿流程著称的期刊,这些期刊不仅性价比高,而且从投稿到录用的时间极短&a…

使用API有效率地管理Dynadot域名,设置域名服务器(NS)的ip信息
前言
Dynadot是通过ICANN认证的域名注册商,自2002年成立以来,服务于全球108个国家和地区的客户,为数以万计的客户提供简洁,优惠,安全的域名注册以及管理服务。
Dynadot平台操作教程索引(包括域名邮箱&…
决策树(descision tree)
一:决策树的基础介绍
决策树(descision tree)是一种基本的分类与回归的方法。决策树是一种对实例进行预测的树型结构。
下面是一个完整的二叉决策树,根据西瓜的几个特征判断西瓜的好坏。
纹理<1.5代表第一个判断条件,根据纹理<1.5是…

【JDK17 | 16】Java 17 深入剖析:密封类(二)
一、密封类的使用场景和优势
什么是密封类?
密封类(sealed class)是 Java 17 引入的一种新特性,允许开发者控制哪些类可以继承或实现某个类或接口。通过使用密封类,开发者可以定义一组特定的子类,从而提供…

【springboot9733】基于springboot+vue的藏区特产销售平台
作者主页:Java码库 主营内容:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app等设计与开发。 收藏点赞不迷路 关注作者有好处 文末获取源码 项目描述
“互联网”的战略实施后,很多行业的信息化水…