原创内容第676篇,专注量化投资、个人成长与财富自由。
今天我们继续开发AI大模型自动读研报。
从研报到模型,大致分成几步:
["propose_hypo_exp", "propose", "exp_gen", "coding", "running", "feedback"]
首先,我们需要接入大模型API,我们使用openai的SDK来封装。
from openai import OpenAI
import os
class LLM:
def __init__(self, api_key=os.getenv('KIMI_KEY'), base_url="https://api.moonshot.cn/v1", model='moonshot-v1-128k',system_prompt=None):
self.client = OpenAI(
api_key=api_key,
base_url=base_url,
)
if not system_prompt:
system_prompt = "你是quantlab金融投资专家,由AI量化实验室 " \
"提供的人工智能助手,你更擅长中文和英文的对话。你会为用户提供安全,有帮助,准确的回答。同时,你会拒绝一切涉及恐怖主义,种族歧视,黄色暴力等问题的回答。Moonshot AI " \
"为专有名词,不可翻译成其他语言。 "
self.system_prompt = system_prompt
self.model = model
def chat(self, user_prompt):
completion = self.client.chat.completions.create(
model=self.model,
messages=[
{"role": "system",
"content": self.system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0.3,
)
return completion.choices[0].message.content
这样一个基础功能就完成了。
我们可以向它提问:
from core.llm import LLM
resp = LLM().chat('你是谁?A股会涨吗?')
print(resp)
输出结果如下:

准备好了16份研报:
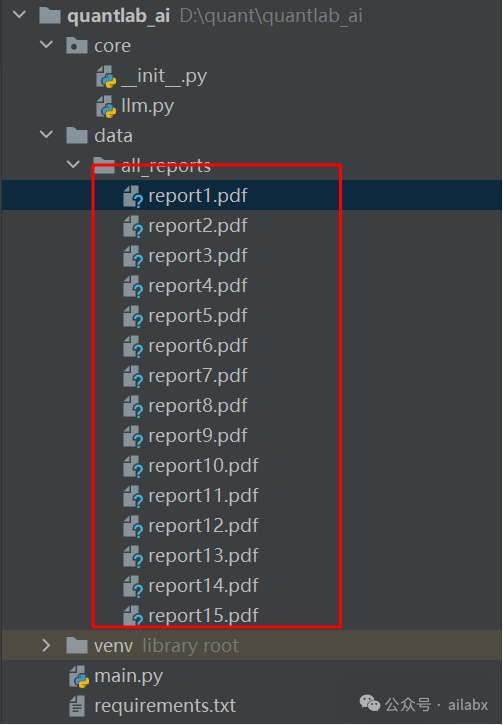
比如研报一,

我们的目标是AI自动读研报,然后自主建模复现研报。
研报基本都是pdf格式,因此我们需要一个pdf阅读器,langchain里实现了pdf解析,我们直接使用就好了。——langchain生态封装有点多,但工具也挺全的,我们可以使用它的周边。
from pathlib import Path
from langchain_community.document_loaders import PyPDFDirectoryLoader, PyPDFLoader
from langchain_core.documents import Document
def process_documents_by_langchain(docs: list[Document]) -> dict[str, str]:
content_dict = {}
for doc in docs:
if Path(doc.metadata["source"]).exists():
doc_name = str(Path(doc.metadata["source"]).resolve())
else:
doc_name = doc.metadata["source"]
doc_content = doc.page_content
if doc_name not in content_dict:
content_dict[str(doc_name)] = doc_content
else:
content_dict[str(doc_name)] += doc_content
return content_dict
def load_pdfs(path):
if Path(path).is_dir():
loader = PyPDFDirectoryLoader(path, silent_errors=True)
else:
loader = PyPDFLoader(path)
docs = process_documents_by_langchain(loader.load())
return docs
把研报一读取进来:
from loader.pdf_loader import load_pdfs
docs = load_pdfs(DATA_DIR.joinpath('all_reports').joinpath('report1.pdf'))
print(docs)
读进来是文本:

接下来是重点,system prompt,要求LLM从研报中抽取出因子,以及对因子的模型。
extract_factors_system: |-
用户会提供一篇金融工程研报,其中包括了量化因子和模型研究,请按照要求抽取以下信息:
1. 概述这篇研报的主要研究思路;
2. 抽取出所有的因子,并概述因子的计算过程,请注意有些因子可能存在于表格中,请不要遗漏,因子的名称请使用英文,不能包含空格,可用下划线连接,研报中可能不含有因子,若没有请返回空字典;
3. 抽取研报里面的所有模型,并概述模型的计算过程,可以分步骤描述模型搭建或计算的过程,研报中可能不含有模型,若没有请返回空字典;
user will treat your factor name as key to store the factor, don't put any interaction message in the content. Just response the output without any interaction and explanation.
All names should be in English.
Respond with your analysis in JSON format. The JSON schema should include:
{
"summary": "The summary of this report",
"factors": {
"Name of factor 1": "Description to factor 1",
"Name of factor 2": "Description to factor 2"
},
"models": {
"Name of model 1": "Description to model 1",
"Name of model 2": "Description to model 2"
}
}
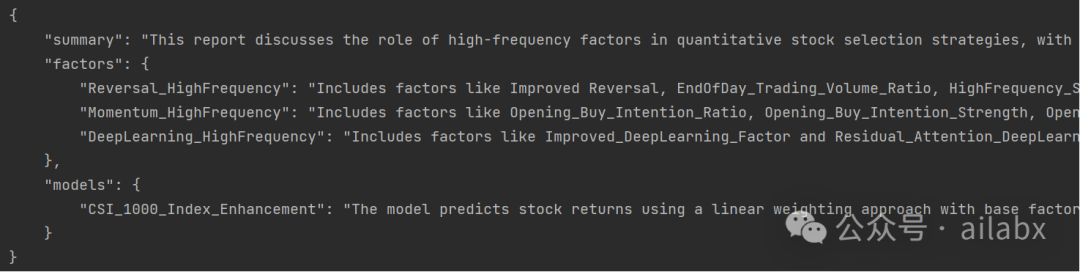
看下代码运行的结果:
系统按要示的字典格式,把因子和模型都抽取出来了。
{
"summary": "This report discusses the role of high-frequency factors in quantitative stock selection strategies, with a case study on the enhancement of the CSI 1000 index. The report categorizes high-frequency factors into reversal, momentum, and deep learning types, and tests their stock selection capabilities on a monthly and weekly basis. It also examines the impact of incorporating these factors into the CSI 1000 index enhancement strategy under various constraints.",
"factors": {
"Reversal_HighFrequency": "Includes factors like Improved Reversal, EndOfDay_Trading_Volume_Ratio, HighFrequency_Skewness, Downside_Volume_Ratio, Average_Single_Outflow_Amount_Ratio, and LargeOrder_Push_Increase. These factors characterize investor overreaction and tend to select stocks with large previous drops or low turnover rates.",
"Momentum_HighFrequency": "Includes factors like Opening_Buy_Intention_Ratio, Opening_Buy_Intention_Strength, Opening_LargeOrder_NetBuy_Ratio, and Opening_LargeOrder_NetBuy_Strength. These factors characterize investor buying intentions, capital flow in the order book, or trading behavior of informed investors.",
"DeepLearning_HighFrequency": "Includes factors like Improved_DeepLearning_Factor and Residual_Attention_DeepLearning_Factor. These factors use past high-frequency features to dynamically fit recent trading patterns and are suitable for short-term windows."
},
"models": {
"CSI_1000_Index_Enhancement": "The model predicts stock returns using a linear weighting approach with base factors including market value, mid-cap (cube of market value), valuation, turnover, reversal, and volatility. High-frequency factors are incrementally introduced to examine changes in portfolio performance. The optimization objective maximizes expected returns under various constraints such as stock deviation, factor exposure, industry deviation, turnover frequency, and turnover rate limits."
}
}
代码结果如下,已经打包发布至星球:

AI量化实验室 星球,已经运行三年多,1200+会员。
quantlab代码交付至5.X版本,含几十个策略源代码,因子表达式引擎、遗传算法(Deap)因子挖掘引擎等,每周五迭代一次。
(国庆优惠券)


(限时免费,感兴趣可入,关注读书,超级个体,AGI与财富自由)
作者:AI量化实验室(专注量化投资、个人成长与财富自由)
扩展 • 历史文章
• 年化从19.1%提升到22.5%,全球大类资产轮动,加上RSRS择时,RSRS性能优化70倍。(附策略源码)
• quantlab5.9代码更新:提供RSRS择时和小市值股票策略(附代码和数据)
• AI量化实验室——2024量化投资的星辰大海