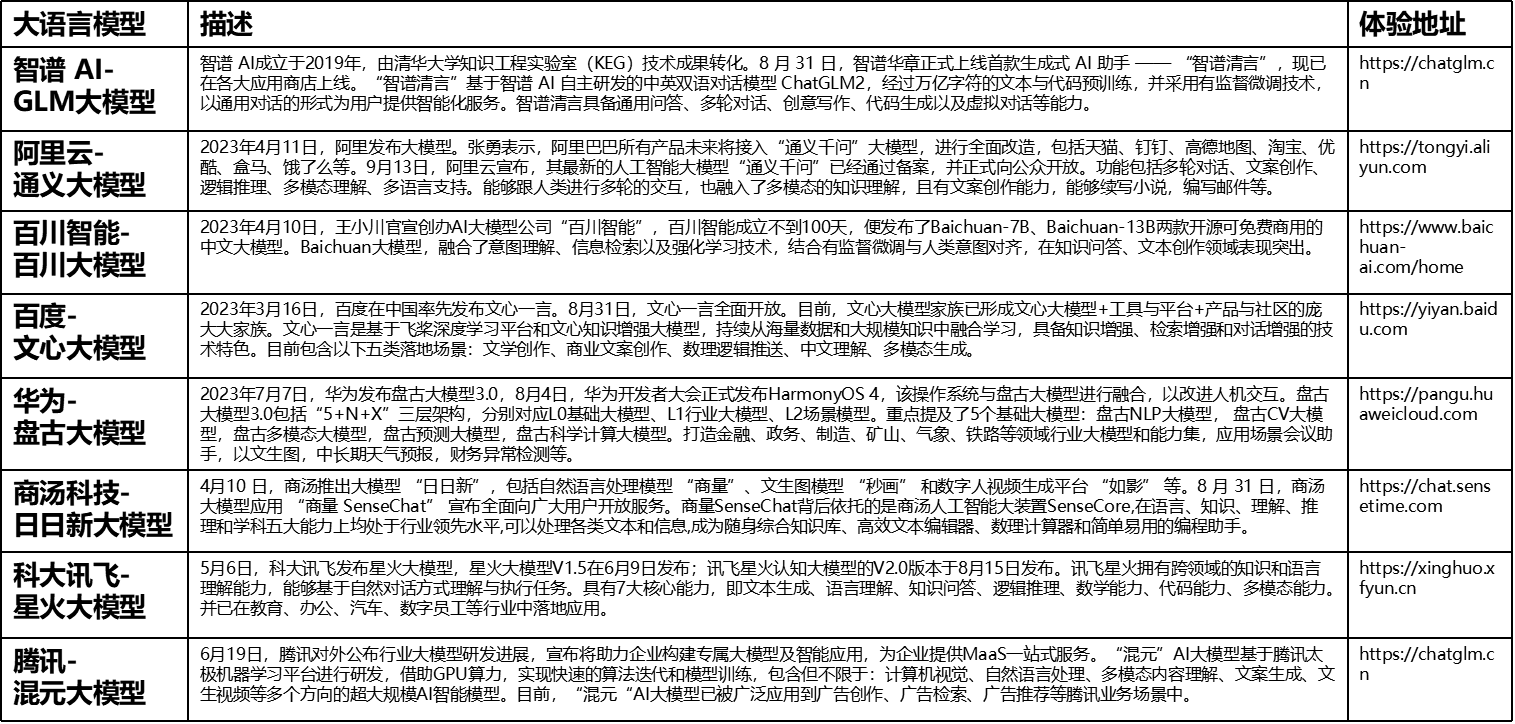
日前,腾讯AI Lab和中科大联合发布了100多页的类SORA模型研究报告,非常全面,很有学习和研究价值,今天和大家分享下,内容较多,可后台回复【类SORA报告】获取100多页pdf。
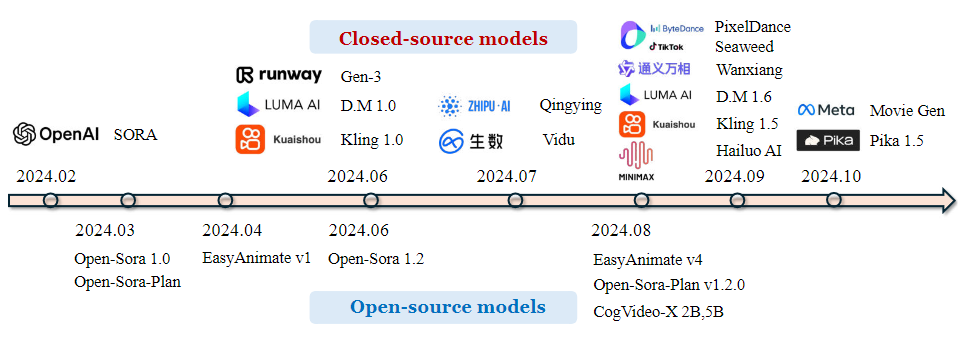
开源地址:https://ailab-cvc.github.io/VideoGen-Eval/
高质量视频生成,包括文本到视频(T2V)、图像到视频(I2V)和视频到视频(V2V)生成,在内容创作和世界模拟中具有重要意义,帮助人们以全新的方式表达其内在创造力,并用于建模和理解世界。像SORA这样的模型在生成高分辨率、更自然的运动、更好地对齐视觉与语言以及提高可控性,特别是在长视频序列方面,取得了显著进展。这些改进得益于模型架构的演变,从UNet转向了更具可扩展性和参数丰富的DiT模型,伴随着大规模数据扩展和优化的训练策略。然而,尽管基于DiT的闭源和开源模型不断涌现,针对其能力和局限性的全面研究仍然缺乏。此外,由于快速发展的技术,现有的基准测试难以充分涵盖类似SORA的模型,并认识到其重要的进展。此外,评估指标常常难以与人类偏好对齐。
本报告研究了一系列类似SORA的模型,旨在弥合学术研究与行业实践之间的差距,提供对视频生成最新进展的更深入分析。设计了超过700个提示,以系统的视角全面评估现有的T2V、I2V和V2V模型。随后,比较了10个闭源模型和3个开源模型,生成了超过8,000个视频案例。由于自动评估仍难以反映真实表现,鼓励读者访问我们的网站观看生成的视频结果,眼见为实。
报告亮点
- 对垂直领域应用模型的影响,如以人为中心的动画和机器人技术;
- 关键的客观能力,如文本对齐、视觉和运动质量、构图、稳定性、创造力等;
- 在十大现实应用中的应用;
- 潜在的使用场景和任务;
- 深入讨论了挑战和未来的研究方向;
- 所有结果将作为新的视频生成基准公开获取,也会持续更新结果。



内容目录
1 引言
1.1 任务定义与输入模式
1.2 类SORA模型目标
1.2.1 闭源模型
1.2.2 开源模型
1.3 评估过程
1.3.1 输入准备
1.3.2 模型设置详情
1.3.3 模型结果与比较2 通用类SORA模型与垂直领域模型对比
2.1 人体视频生成
2.2 机器人技术
2.3 卡通动画
2.4 世界模型
2.5 自动驾驶
2.6 摄像头控制3 视频生成的客观能力
3.1 文本对齐
3.2 构图
3.3 转场
3.4 创造力
3.5 风格化
3.6 稳定性
3.7 动作多样性4 类SORA模型在十个现实应用中的使用
5 使用场景与任务的探索
6 开源与闭源类SORA模型对比
7 挑战与未来工作
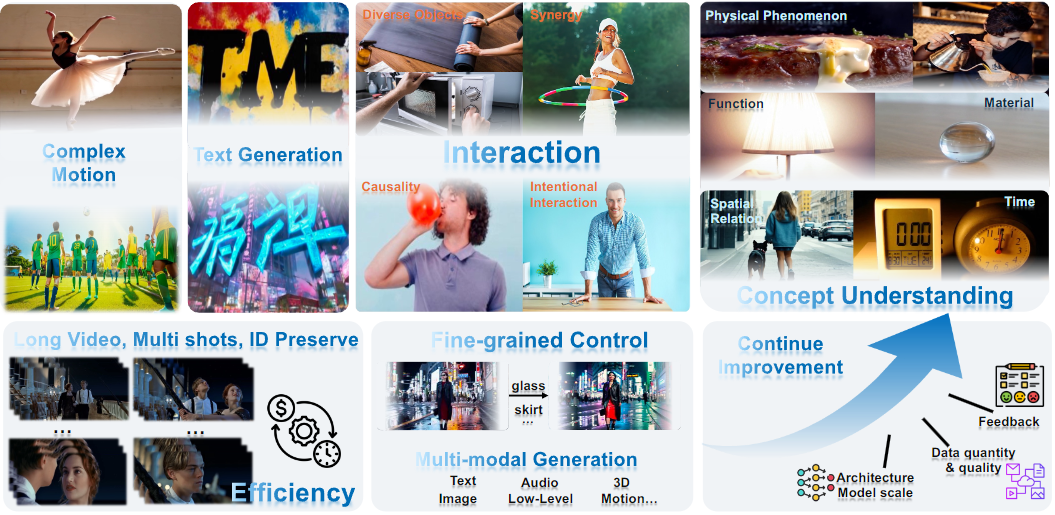
7.1 复杂动作
7.2 概念理解
7.3 交互
7.4 个性化
7.5 文本生成
7.6 细粒度可控生成
7.7 长视频、多镜头、身份保持
7.8 效率
7.9 多模态视频生成
7.10 视频生成的持续改进8 结论
SORA的出现使得根据文本指令创建高度真实和富有想象力的视频成为可能,视频时长可达到一分钟。这也表明,扩大视频生成模型的规模是构建通用物理世界模拟器的有希望的途径。值得注意的是,多个闭源模型已经推出了直接的网站和产品,而没有开源其相应的模型。同时,在模型训练、计算资源的大规模使用以及广泛数据集的收集和注释方面,开源模型和闭源模型之间依然存在显著的性能差距。这种差异导致了学术研究与工业发展之间的分歧。此外,视频生成中许多基础研究问题在研究角度上仍然未得到充分解决。
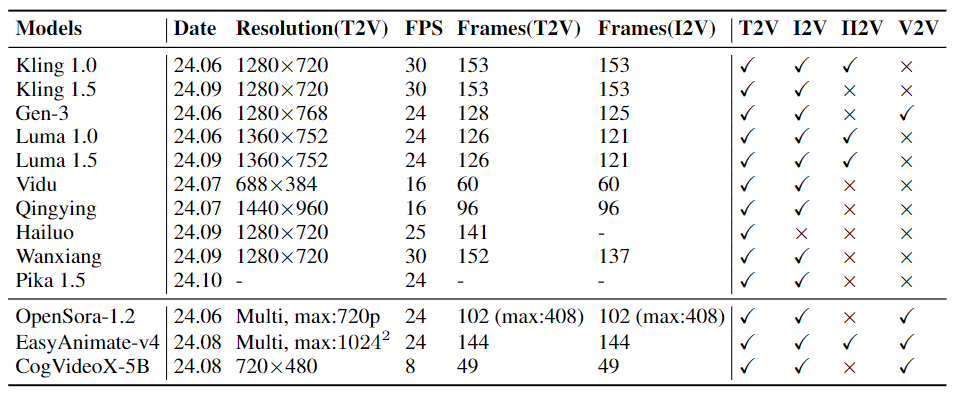
下表是展示发布日期、文本到视频生成的分辨率、 FPS、生成的长度和可用功能。II2V 意味着输入第一个和最后一个图像来生成视频的任务。上半部分列出了闭源代码模型,下半部分显示了开源模型。
在过去的一年里,多个基准测试致力于建立公平的比较方法,通过汇总和比较众多视频生成模型,同时引入全面的评估指标和详细的定量比较。然而,它们的评估对象往往过时,未能代表目前最先进模型的性能。这一局限性削弱了对该领域前沿问题的理解。此外,这些工作往往更侧重于多维度的定量评估。然而,开发完全与人类感知相一致的评估指标仍然具有挑战性,用户研究的评分也表现出偏差。最后,大多数提示是通过GPT设计的,而不是考虑各种专家领域知识和有意义的提示。
相较之下,视频生成的定性结果更直接反映了当前模型所面临的普遍问题。同时,许多视频应用工作依赖于基于开源基础模型(如Stable Diffusion(SD)、Stable video Diffusion(SVD)和Open-Sora)构建的微调和高度控制的视频生成探索。这些基础模型的能力显著影响这些努力,包括模型架构、数据构建、训练策略和最终性能。此外,尚不清楚基础模型的改进是否会解决许多现有研究挑战,或随着这些模型的不断扩展会出现新的挑战。
本报告采用与以往评估研究不同的视角,更清晰地探讨当前SORA类视频生成模型的能力和局限性,通过综合比较生成的视频和定性结果,灵感来自于覆盖广泛领域和任务的研究。没有提供定量指标,而是通过超过700个设计输入系统展示、分析和比较这些最新模型的输出视频,展示了超过8000个非选择性生成的视频,主要关注四个核心方面:
- 第二部分的垂直领域视频生成;
- 第三部分的主观能力(如一致性、构图和身份保持);
- 第四部分结合数百名受访用户需求的实际视频应用;
- 第五部分对潜在特性和使用案例的探索,第六部分与开源模型的更详细比较,第七部分当前挑战和未来方向。
眼见为实。与文本和图像生成不同,视频生成需要更多的观察生成视频,以深入了解问题。具体而言,通过一系列初步探索总结我们的观察。
闭源模型的优越性: 从各个角度看,闭源模型在视觉和运动质量上均显著高于开源模型,并超越了之前的UNet模型,特别是在生成自然和动态视频运动方面,即使是在丰富的多镜头场景和情感表达中。这些模型在模拟场景的电影质量和纹理方面表现出色。
文本到视频(T2V)生成的优势: 在闭源模型中,Gen-3、Kling v1.5和Minimax在T2V任务上表现优越。具体而言,Minimax在文本控制方面表现突出,特别是在描绘人类表情、相机运动、多镜头生成和主体动态方面。相反,Gen-3在控制光照、纹理和电影技术方面表现出色。Kling v1.5则在视觉、可控性和运动能力之间表现出良好的权衡。有趣的是,所有模型都有一些好的特征。Luma强调更广泛的相机运动,同时保持主体的运动更加受限。相比之下,Vidu表现出更大的主体运动和更快的速度,而Qingying在与文本对齐的生成方面显示出适度的能力。每个模型由于不同的数据分布、模型规模和训练策略,具有独特的运动表示特征。
图像到视频(I2V)生成的优势: 得益于基础T2V模型更好的局部到全球运动建模,闭源模型能够用更合理和时间一致的运动来动画给定图像,与UNet模型相比。具体而言,从给定图像生成的新颖视角、姿势、自然光和纹理。对于Kling和Gen-3,角色动画的高质量表现为角色保持和生动的运动生成。有趣的是,它们还可以进行图像到视频的修补、扩展、插值、超分辨率和一般增强任务。Vidu和Luma倾向于展示高度动态的主体和相机运动。
T2V中的剩余局限性: 尽管闭源模型在整体质量(即从10%到40%)上显著提高,但在许多方面仍然无法做到完美。在T2V生成方面,闭源模型在文本对齐生成的空间和时间维度、低分辨率区域生成(例如,小脸)、动态运动、推理能力、长期序列(例如,10秒或更长时间)的身份一致性、多镜头场景、组成空间-时间关系、复杂物理交互和遵循物理规则(例如,破碎的玻璃、充气的气球和玩球)、多语言文本生成和稳定性方面存在共同缺陷。
I2V中的剩余局限性: 对于I2V任务,某些T2V模型的能力未能充分实现。这包括理解输入图像的详细和语义信息的困难,以及倾向于引入新对象而不是准确地动画现有元素或对象。此外,当运动高度动态时,保持物体和人类的一致性(外观、姿势、纹理、结构等)尤其困难。
垂直领域任务中的比较: 当前模型缺乏空间-时间细粒度的标题和领域特定知识,例如面部表情、语音、动作和专门的自动驾驶描述。这使得通过通用的I2V和输入文本进行精确视频生成控制变得具有挑战性。然而,通用模型增强了核心能力,如泛化、构图和多样性,提供有效的场景建模和对人-物/环境交互的更好理解。与显式关键点驱动的视频生成不同,后者遭受准确性条件问题,通用模型更稳健地处理人类动作建模,缓解了这些挑战。
十个应用场景中的表现: 这些I2V模型(如Gen-3和Kling v1.5)在景观场景、单一物体和动物运动、重光照、创意场景和细腻动画方面表现良好。然而,在涉及人类角色动画、复杂物理运动、小众运动场景、游戏相关上下文中的计数或逻辑变化以及在电影基础的多镜头变化中保持一致性和自然过渡的应用中,它们仍然面临重大挑战。这些问题在许多局部和细粒度细节或区域的缺陷中尤为明显。
多样化客观能力的评估: 在不同维度之间存在不同的强项和弱项。具体而言,目前的视频生成模型在基本语义对齐方面表现良好,例如外观、光照和风格。在此基础上,它们在组合多个实例和动作以及在合并不相关概念方面也表现出一定程度的熟练。关键点在于调整场景的分布,使其能够很好地工作,例如Kling的吃展示和拥抱动作、Pika的特效以及MiniMax的表现情感。然而,它们在处理高度多样化的泛化、细粒度运动和多个场景转换方面的能力仍然有限。特别是稳定性(或稳定性与多样性之间的权衡)需要显著改善,这意味着使用相同输入生成多个结果时的变化很大。
使用场景和任务的探索: 这包括一些先进的技术,如视频外扩、超分辨率、纹理生成和将其他风格转变为逼真风格。这展示了视频生成模型适应复杂场景并超越传统任务的潜力。
未来方向: 视频生成仍处于初期阶段,尚有大量研究课题待探索。我们将其总结如下:建模多模态生成以有效模拟世界,统一视频感知、理解和生成任务,为互动和实时视频生成设计新颖架构,结合少量学习技术以适应稀有场景的适应和测试时的领域适应,以及针对电影制作进行长序列建模、多镜头和身份一致性。此外,应该努力吸收用户反馈,以不断提高生成视频的质量、可控性和定制化,增强模型的稳健性和稳定性,同时保持多样性,并解决伦理和道德问题,以更好地适应未来的应用需求。
总结
总之,本报告全面探讨了SORA类模型在高质量视频生成中的应用,涵盖了T2V、I2V和V2V任务。通过设计一系列详细的提示和案例研究,系统地评估了这些模型在各种场景中的进展、挑战和潜在应用。分析突显了视频生成领域所取得的显著进展,尤其是在视觉质量、运动自然性和动态性以及视觉-语言对齐方面。
尽管取得了这些成就,仍然发现学术研究与行业实践之间可能存在的差距,建议在可控视频生成的细粒度和分层视频标题和理解、效率、可扩展性、稳定性、人类反馈以不断改进和修改结果、复杂交互建模、带有多镜头和身份一致性的长视频生成、自动人类对齐的评估策略以及多模态互动生成系统等方面开展未来研究。
希望本研究及我们生成的视频能成为新的视频生成基准,并激励更多研究。鼓励社区使用我们的公共提示和视频进行进一步研究,例如继续对生成视频的学习。通过直接观察生成的视频,我们希望为视频生成能力的更细致理解做出贡献。随着这一领域的快速发展,我们对未来的突破充满乐观,并期待进一步提升视频生成的质量和多样性。同时,我们承诺更新我们的发现,以反映持续的进展,并提供更全面和详细的提示,涵盖视频的各个方面,探索可靠的定量评估,并深化对这一快速发展的领域的洞察。
参考文献
[1] The Dawn of Video Generation: Preliminary Explorations with SORA-like Models






![[Python] 使用Python自定义生成二维码](https://img-blog.csdnimg.cn/img_convert/c4b96402514efaefbfbd312351560308.png)