目录
问题现象
问题分析
修改建议
总结
问题现象
近日,某用户反馈他们的MySQL数据库实例在凌晨时段会频繁出现IO负载急剧上升的情况,这种状态会持续一段时间,随后自行恢复正常。为了查明原因,该用户通过DBdoctor工具收集了相关的监控数据和审计日志进行分析。以下是他们收集到的关键数据:AAS监控数据和审计日志分析结果。
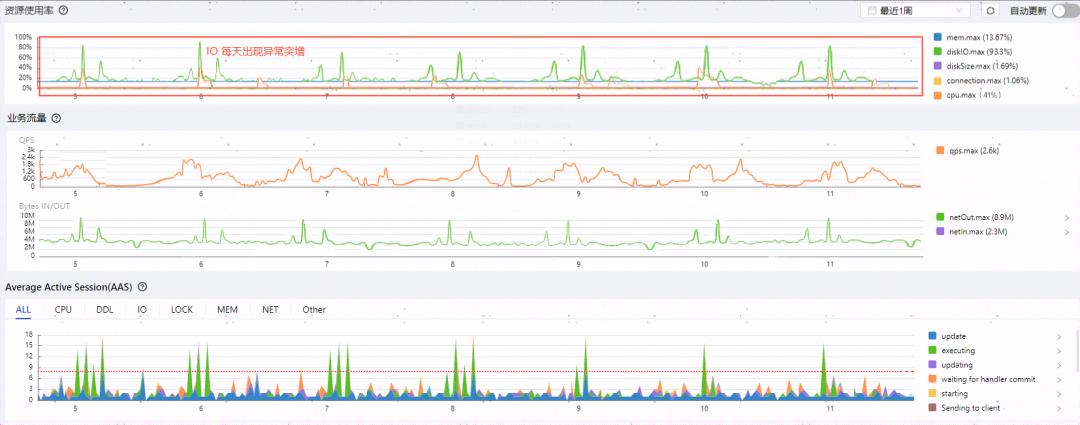

问题分析
通过审计日分析我们可以看到,在IO突增时间的时间段内, delete from order_info where id=? 这个SQL被执行超过了100万+次,这种短时间内的大量删除操作可能会对MySQL的IO性能造成影响。用户将分析数据提供给开发同学,开发团队通过追踪这个SQL语句,发现了一个新近添加的定时任务,该任务设置在每天凌晨运行,目的是清除历史数据。该代码如下:
public void cleanExpireData(long startTime, long endTime) {List<OrderInfo> orderList = orderInfoDao.findByTime(startTime, endTime);if (CollectionUtils.isEmpty(orderList)) {log.info("no data found between {} and {}", startTime, endTime);return;}for (OrderInfo orderInfo : orderList) {orderInfoDao.deleteById(orderInfo.getId());}log.info("clean all data success");}
通过分析这个 cleanExpireData 的目的是清理在指定时间范围内的过期数据。它通过以下步骤实现:
-
调用
orderInfoDao.findByTime(startTime,endTime)获取在startTime和endTime之间的所有数据的列表。 -
如果找到数据,则遍历每个对象
ID,并调用orderInfoDao.deleteById(id)方法逐个删除。
那原因找到了,这是因为该定时任务在批量删除数据时先进行了查询操作,再进行一条一条数据删除而导致的数据库IO异常,同时该逻辑还可能会产生OOM,具体分析如下:
1.潜在OOM风险:当查询时间范围内若数据量异常过大,一次查询出来,可能会占用大量内存,造成程序OOM。
2.逐个删除记录效率低下:
-
每次删除一条记录时,都会发起一次单独的数据库操作(
deleteById)。如果allIds列表中有很多条数据,逐条删除会导致大量的数据库请求,从而导致性能降低。
3.频繁大量进行MySQL删除操作会增加系统IO:
-
每次删除操作都会导致 MySQL 更新数据文件和索引文件,以标记删除的记录。这会触发大量的磁盘写入操作,特别是如果表中有大量索引需要更新。
-
对于 InnoDB 引擎,删除操作还会产生大量的 Undo Log 和 Redo Log 写操作,用于维护事务一致性和崩溃恢复。
-
如果 MySQL 开启了 二进制日志(binlog),每个删除操作都会记录到 binlog 中,以便进行事务恢复和主从复制。删除大量数据会导致 MySQL 频繁地将这些操作写入到 binlog 中,增加磁盘的 I/O 压力
-
删除大量数据后,表会产生空间碎片,尤其是在 InnoDB 引擎中,删除操作并不会立即释放磁盘空间,数据页中的记录会被标记为“已删除”,这可能导致表空间利用率降低。后续的操作(如
INSERT或UPDATE)会导致表空间整理,进一步增加 I/O 负载
修改建议
-
避免大数据查询:简单的删除操作,可根据过滤条件直接从数据库中删除,无需查询出来再删除。
-
批量删除:根据指定时间范围内直接删除,同时限制批量删除个数,防止数据量过大,对数据库造成负载。
修改后代码如下:
public void cleanExpireData(long startTime, long endTime) {long effectNum = 1;long totalDeleted = 0; // 记录删除的总数while (effectNum > 0) {effectNum = orderInfoDao.deleteByTimeAndLimit(startTime, endTime, 10000);totalDeleted += effectNum; // 累积删除的数量}log.info("Successfully cleaned {} records between {} and {}", totalDeleted, startTime, endTime);}##SQL如下:delete from orderInfo where start_time > #{startTime} and end_time < #{endTime} limit #{num}
修改后的代码实现了直接删除满足条件的数据,避免了先查询再删除的步骤。为了提高效率并防止一次性删除大量数据,我们采用了分批删除的策略,每次删除不超过10000条记录。这样的改进使得代码更加简洁,执行速度也得到了显著提升。代码修改点如下:
1. 避免一次性处理大量数据,采取批量操作
在处理大数据量的操作时(如删除、更新等),避免一次性加载或操作过多数据,防止耗尽内存及造成的数据库性能问题。分批次处理(如使用 LIMIT)可以有效降低系统压力,同时避免长时间的锁定资源,保持系统的稳定性。
2. 循环操作和停止条件
在执行分批操作时,我们引入了循环机制,并设定了明确的停止条件,以确保所有数据都能被逐一处理。通过限制每次操作处理的数据量,并让循环持续执行直到没有更多数据需要处理,我们能够有效地避免数据遗漏,确保数据处理的完整性和准确性。
3. 记录并跟踪处理结果
通过记录每次操作的结果(如删除的条数)来追踪进度,能够帮助我们准确了解批量操作的效果。此外,正确处理并累积删除的记录总数,有助于调试、日志输出和分析。
4. 灵活选择批量操作的数量
设定合适的批量操作数量(如每次删除 10,000 条),根据数据库的规模和性能动态调整。过大可能导致数据库负载过高,过小则会使效率低下。
总结
在执行数据库定期清理任务时,建议采用分批删除策略,以减少对数据库性能的影响。首先,根据设定的条件筛选出待删除的数据。然后,为了避免一次性删除大量数据导致数据库压力过大,可以实施分批处理。此外,如果数据库频繁出现性能问题,应检查是否有定时任务在特定时间点执行。利用DBdoctor审计日志分析工具,可以帮助我们迅速诊断并定位问题源头。
**************************************************************************************************************
DBdoctor-1分钟定位数据库性能问题DBdoctor是一款企业级数据库监控、巡检、性能诊断、SQL审核与优化平台,利用eBPF透视数据库内核,可一分钟定位数据库性能问题,实现根因诊断,并给出优化建议。![]() https://www.dbdoctor.cn/?utm=4cf70f49547b4b45864ac76d1da334bf
https://www.dbdoctor.cn/?utm=4cf70f49547b4b45864ac76d1da334bf