微信公众号:阿俊的学习记录空间
小红书:ArnoZhang
wordpress:arnozhang1994
博客园:arnozhang
CSDN:ArnoZhang1994
1. 介绍
Vavr(前称 Javaslang)是一个为 Java 8+ 提供的函数式库,提供持久数据类型和函数控制结构。
1.1. Vavr 中的 Java 8 函数式数据结构
Java 8 的 lambda(λ)使我们能够创建出色的 API,大大增强了语言的表现力。Vavr 利用 lambda 创建了许多基于函数式模式的新特性,其中之一是一个旨在替代 Java 标准集合的函数集合库。
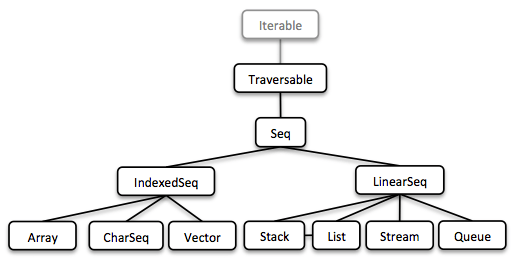
Vavr 集合
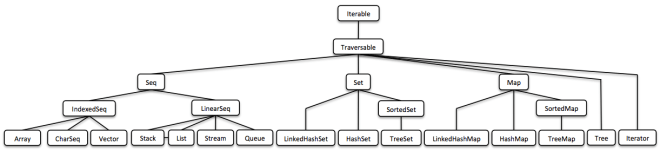
(这只是鸟瞰图,下面会有可读版本。)
1.2. 函数式编程
在深入数据结构的细节之前,我想先讨论一些基础知识。这将明确我为何创建 Vavr,尤其是新的 Java 集合。
1.2.1. 副作用
Java 应用程序通常充满副作用。它们会改变某种状态,可能是外部世界。常见的副作用包括在原地更改对象或变量、打印到控制台、写入日志文件或数据库。如果副作用以不希望的方式影响程序的语义,则被视为有害。
例如,如果一个函数抛出异常并对此进行解释,那么这被视为影响程序的副作用。此外,异常类似于非局部的 goto 语句,它们打破正常的控制流。然而,现实世界的应用确实会执行副作用。
int divide(int dividend, int divisor) {
// 如果除数为零则抛出异常
return dividend / divisor;
}
在函数式环境中,我们处于一个有利的局面,可以在 Try 中封装副作用:
// = Success(result) 或 Failure(exception)
Try<Integer> divide(Integer dividend, Integer divisor) {
return Try.of(() -> dividend / divisor);
}
这个版本的 divide 不再抛出任何异常。我们通过使用类型 Try 使可能的失败变得明确。
1.2.2. 引用透明性
如果可以用其值替换调用而不影响程序的行为,则称一个函数或更一般的表达式为引用透明。简单来说,给定相同的输入,输出总是相同的。
// 不是引用透明的
Math.random();
// 引用透明的
Math.max(1, 2);
如果所有相关表达式都是引用透明的,则该函数被称为纯函数。由纯函数组成的应用程序只要编译就很可能能正常工作。我们能够对此进行推理。单元测试易于编写,调试变成了过去的遗物。
1.2.3. 价值思维
Clojure 的创造者 Rich Hickey 进行了关于“价值的价值”的精彩演讲。最有趣的值是不可变值。主要原因是不可变值
- 本质上是线程安全的,因此不需要同步
- 在 equals 和 hashCode 方面是稳定的,因此是可靠的哈希键
- 不需要克隆
- 在未经检查的协变转换中表现出类型安全(Java 特有)
更好的 Java 的关键是使用不可变值配合引用透明的函数。Vavr 提供了必要的控制和集合,以实现这一目标,在日常 Java 编程中。
1.3. 数据结构概述
Vavr 的集合库由一组丰富的基于 lambda 的函数式数据结构组成。它们与 Java 原始集合唯一共享的接口是 Iterable。主要原因是 Java 集合接口的修改方法不返回底层集合类型的对象。
我们将通过查看不同类型的数据结构来了解这一点为何至关重要。
1.3.1. 可变数据结构
Java 是一种面向对象的编程语言。我们将状态封装在对象中,以实现数据隐藏,并提供修改方法来控制状态。Java 集合框架(JCF)建立在这个思想之上。
interface Collection<E> {
// 从该集合中删除所有元素
void clear();
}
今天,我把 void 返回类型视为一种气味。这是副作用发生的证据,状态被改变。共享可变状态是失败的重要来源,不仅在并发环境中。
1.3.2. 不可变数据结构
不可变数据结构在创建后不能被修改。在 Java 的上下文中,它们通常以集合包装器的形式使用。
List<String> list = Collections.unmodifiableList(otherList);
// 爆炸!
list.add("why not?");
有各种库为我们提供类似的实用方法。结果总是特定集合的不可修改视图。通常在调用修改方法时会在运行时抛出异常。
1.3.3. 持久数据结构
持久数据结构在被修改时保留其之前的版本,因此实际上是不可变的。完全持久的数据结构允许对任何版本进行更新和查询。
许多操作只执行小的变化。仅仅复制之前的版本效率不高。为了节省时间和内存,识别两个版本之间的相似性并尽可能共享数据至关重要。
此模型不强加任何实现细节。函数式数据结构在此发挥作用。
1.4. 函数式数据结构
也称为纯函数数据结构,这些是不可变且持久的。函数式数据结构的方法是引用透明的。
Vavr 具有广泛使用的函数式数据结构。以下示例将深入解释。
1.4.1. 链表
最流行且最简单的函数式数据结构之一是(单向)链表。它有一个头元素和一个尾链表。链表的行为类似于遵循后进先出(LIFO)方法的堆栈。
在 Vavr 中,我们这样实例化一个链表:
// = List(1, 2, 3)
List<Integer> list1 = List.of(1, 2, 3);
每个链表元素形成一个独立的链表节点。最后一个元素的尾部是 Nil,表示空链表。

这使我们能够在不同版本的链表中共享元素。
// = List(0, 2, 3)
List<Integer> list2 = list1.tail().prepend(0);
新头元素 0 链接到原链表的尾部。原链表保持不变。
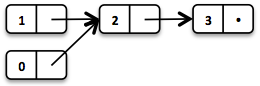
这些操作在常量时间内进行,换句话说,它们与链表大小无关。其他大多数操作需要线性时间。在 Vavr 中,这通过接口 LinearSeq 表达,我们可能已经在 Scala 中了解过。
如果我们需要在常量时间内可查询的数据结构,Vavr 提供 Array 和 Vector。两者均具有随机访问能力。
Array 类型由一个 Java 对象数组支持。插入和删除操作需要线性时间。Vector 在 Array 和 List 之间表现良好,既适用于随机访问,也适用于修改。
实际上,链表也可以用于实现队列数据结构。
1.4.2. 队列
基于两个链表可以实现非常高效的函数式队列。前面的链表保存被出队的元素,后面的链表保存入队的元素。两个操作入队和出队的时间复杂度均为 O(1)。
Queue<Integer> queue = Queue.of(1, 2, 3)
.enqueue(4)
.enqueue(5);
初始队列由三个元素创建。在后链表上入队两个元素。
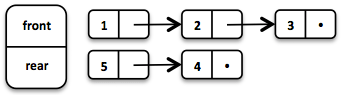
如果在出队时前链表没有元素,后链表会被反转并成为新的前链表。
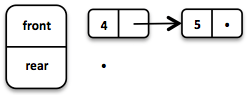
出队一个元素时,我们得到一个第一个元素和剩余队列的配对。必须返回队列的新版本,因为函数式数据结构是不可变且持久的。原队列不受影响。
Queue<Integer> queue = Queue.of(1, 2, 3);
// = (1, Queue(2, 3))
Tuple2<Integer, Queue<Integer>> dequeued =
queue.dequeue();
当队列为空时,会抛出 NoSuchElementException。以函数式方式处理时,我们更希望得到一个可选结果。
// = Some((1, Queue()))
Queue.of(1).dequeueOption();
// = None
Queue.empty().dequeueOption();
可选结果可以进一步处理,无论其是否为空。
// = Queue(1)
Queue<Integer> queue = Queue.of(1);
// = Some((1, Queue()))
Option<Tuple2<Integer, Queue<Integer>>> dequeued =
queue.dequeueOption();
// = Some(1)
Option<Integer> element = dequeued.map(Tuple2::_1);
// = Some(Queue())
Option<Queue<Integer>> remaining =
dequeued.map(Tuple2::_2);
1.4.3. 排序集合
排序集合是比队列更常用的数据结构。我们使用二叉搜索树以函数式方式对其建模。这些树由每个节点最多有两个子节点和值构成。
我们在有顺序的情况下构建二叉搜索树,由元素比较器表示。任何给定节点的左子树的所有值严格小于
该节点的值,右子树的所有值严格大于该节点。
// = TreeSet(1, 2, 3, 4, 6, 7, 8)
SortedSet<Integer> xs = TreeSet.of(6, 1, 3, 2, 4, 7, 8);
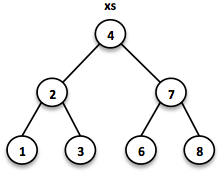
对这些树的搜索运行时间为 O(log n)。我们从根节点开始搜索,判断是否找到该元素。由于值的完全排序,我们知道接下来在哪一侧的分支上搜索。
// = TreeSet(1, 2, 3);
SortedSet<Integer> set = TreeSet.of(2, 3, 1, 2);
// = TreeSet(3, 2, 1);
Comparator<Integer> c = (a, b) -> b - a;
SortedSet<Integer> reversed = TreeSet.of(c, 2, 3, 1, 2);
大多数树操作本质上是递归的。插入函数的行为类似于搜索函数。当达到搜索路径的末端时,创建一个新节点,并重新构建整个路径直至根节点。尽可能引用现有子节点。因此,插入操作的时间和空间复杂度均为 O(log n)。
// = TreeSet(1, 2, 3, 4, 5, 6, 7, 8)
SortedSet<Integer> ys = xs.add(5);
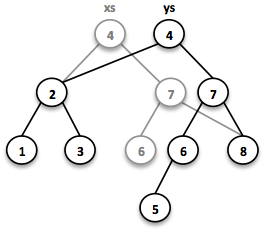
为了保持二叉搜索树的性能特征,树必须保持平衡。从根到叶子的所有路径必须具有大致相同的长度。
在 Vavr 中,我们基于红黑树实现了二叉搜索树。它使用特定的着色策略来保持插入和删除时树的平衡。有关此主题的更多信息,请参阅 Chris Okasaki 的书《Purely Functional Data Structures》。
### 1.4.4. HashMap
HashMap 是一种常用的不可变数据结构,用于存储键值对。Vavr 的 HashMap 是基于持久性和不可变性构建的。它允许对键值对进行高效的插入、删除和查找操作。
在 Vavr 中,我们可以这样创建一个 HashMap:
```java
// = HashMap(1 -> "one", 2 -> "two")
HashMap<Integer, String> map = HashMap.of(1, "one", 2, "two");
每次插入或删除操作都会返回一个新的 HashMap 实例,原始 HashMap 不会被修改。
1.4.5. 其他函数式数据结构
除了上面提到的链表、队列和 HashMap,Vavr 还提供了其他多种常用的函数式数据结构,包括:
- 树:如 TreeSet 和 TreeMap,它们提供了基于排序的集合和映射。
- 集合:如 HashSet,它是一种基于哈希表的不可变集合。
- 数组:如 Array 和 Vector,提供高效的随机访问能力。
这些数据结构使得在 Java 中使用函数式编程模式变得更加简单和高效。
1.5. 总结
Vavr 是一个强大的库,通过提供持久和不可变的数据结构,使得函数式编程在 Java 中变得可行。通过使用 Vavr,开发者可以减少副作用,提高代码的可读性和可维护性,从而在日常开发中实现更高的效率和可靠性。
Vavr 使我们能够更深入地探索函数式编程的世界,为 Java 开发者提供了更多的工具和思路。

![[自然语言处理]RNN](https://i-blog.csdnimg.cn/direct/9de5107d0c3e41108bca45e6b40de160.png)











![[nmap] 端口扫描工具的下载及详细安装使用过程(附有下载文件)](https://i-blog.csdnimg.cn/direct/722011a7bcd84360960ad7e42fef03ab.png)



