前情提要
如果有人看了我之前发的乱七八糟的博客的话,应该就能了解到,我之前是计算机专业大三的学生,好不容易get到了保研的名额,前段时间就一直在操练LeetCode,到处报夏令营啊,预推免什么的,最后喜提中科院计算所的offer(我之前都不敢想的)。但是比较sad的一点就是,因为计算机太卷了,我自觉能力有限,全力维持绩点,偶尔跟同学参加两个小竞赛,去社团划划水就是全部了,实在是无暇顾及科研经历部分了,这也就导致了我在这方面纯纯就是一个小白,现在大四,计算所老师给了我们一个课题,这也是我第一次正经搞科研。于是,理所当然的,遇到了一大堆问题。。。
这里,我们就先讲一下关于Linux服务器相关的问题好了。
首先就是Linux服务器怎么用?
这个问题对于很多人来说是很蠢的,但是对于我的话,确实是我遇到的第一个门槛。我们课题要参考的一个平台是基于Linux系统的,所以,我们首先就是需要配置一个Linux环境,说起这个来,我第一时间想到的是Ubuntu虚拟机,不过后来看了一下我电脑的配置,这个虚拟机八成是配不好这个环境的(存储空间太小了,施展不开)。所幸,我们还有plan B,也就是Linux服务器了。
但是这个的使用我又确实不太会,我向师兄申请了Linux账号,师兄发来了IP地址,端口号,用户名和密码。我看着这些,第一时间想到的是把IP地址用浏览器登录了一下,发现是Nginx平台,别的基本啥也没看出来。。。
然后我就不清楚怎么操作了,甚至是把Nginx也下载了下来,不过后来才反应过来,好像用不着这个。(确实是好久没有碰相关的东西了,比较僵化),于是,我下载了xshell(我知道xftp是配套的,但是我当时确实不知道这个是什么东西,就没有下)。然后按照IP地址,端口号这些信息,终于是成功的登录上了我们组的Linux服务器。
登录之后的一些操作
这个部分的话,我一开始就是上网查到了最最基础的两个指令:
rz:把文件上传进服务器
ls:查看当前目录
后来的话就是vim,cat,chmod这些各种不同功能的指令了。
在这一步,我们已经可以说是非常非常基础的能用上我们的Linux服务器了至少。那么接下来,我的目标就是利用Linux服务器,来执行我的python文件,进而慢慢的做到执行整个项目的部分。
如何执行python文件
这里我一开始想的是类似我们在Windows里面命令行的操作那样,直接把文件名输入就可以了,结果:
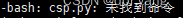
所以还是需要一些指令的,不过我一开始没明白,就开始上网搜,有些人说是在python文件的第一行输入!/usr/bin/python之类的一个路径,不过经过实测,完全不行。包括有些人说是要调整那个chmod +xxx的权限问题,也试了一下,差点惊动管理员(-_-||)。
最后搜到的一个比较靠谱的方案就是python +文件名。实测有效。
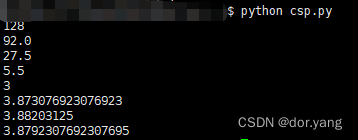
当然了,这个是基于我们这个服务器是之前有python环境的。如果是裸Linux的话,应该还是得先从python下起的,这个先不谈。
如何执行深度学习相关的python文件
就像之前的操作中,我能通过指令方式直接执行python文件了,但是那也只是最最基本的python代码罢了,对于深度学习相关的内容来说,他们的module需求才是我们需要着重考虑的。如果我们按照之前的操作,直接执行一个深度学习的python文件的话,就会: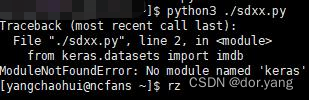
可以看到,我们这里是缺包的,所以我们首先需要做的就是在Linux服务器上重新构造一个python深度学习的环境。
所以,我首先下载了anaconda:
并提供权限进行了安装:
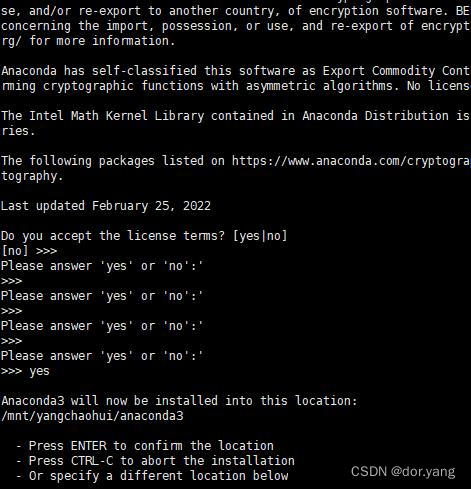
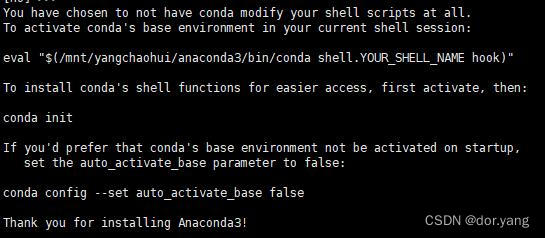
最后的话,他是通知我已经安装好了,不过环境变量也是因为Linux服务器的原因,默认是不能设置的。这里是按照他的要求,执行了conda init指令。
如果我们不进行init指令的话,对于conda -V这种类型的指令他们就是识别不出来。而在我们init完成之后,我们重新打开xshell,他应该是这个样子了:

也就是左边出现了(base)的标志,就说明init成功了。
接下来就是按照我们的需求,创建一个python环境,我这里是3.6的环境就可以了。设置好之后,输入conda env list就可以查看到目前的环境列表。接下来直接激活它就可以了,激活的指令为:conda activate [环境名字],之后我们可以看到左边标志的变化,说明改动成功。
但是,这样之后,不知道为什么,我还是没有成功执行,还是缺少module。于是决定缺啥补啥,少Keras我就pip install tensorflow。
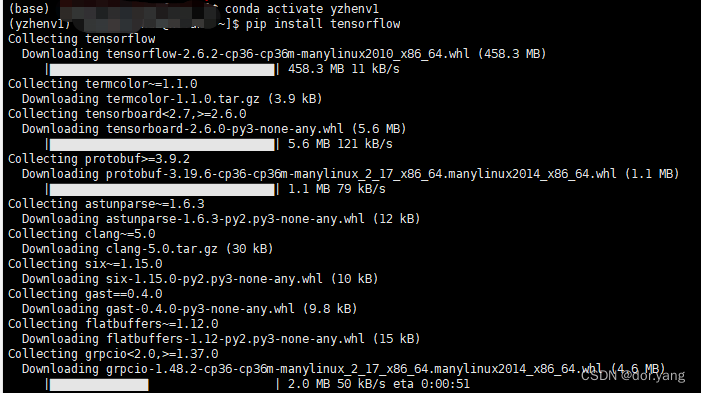
这个过程的话,不知道是不是学校网络的原因,下载过程特别慢,大概用了小三个小时吧,才完成下载,最后应该是下图状态:
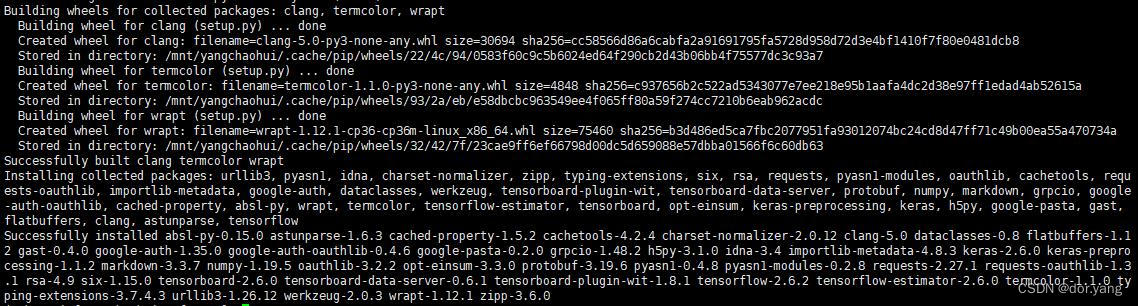
这时,我们再来执行之前的深度学习的python文件:

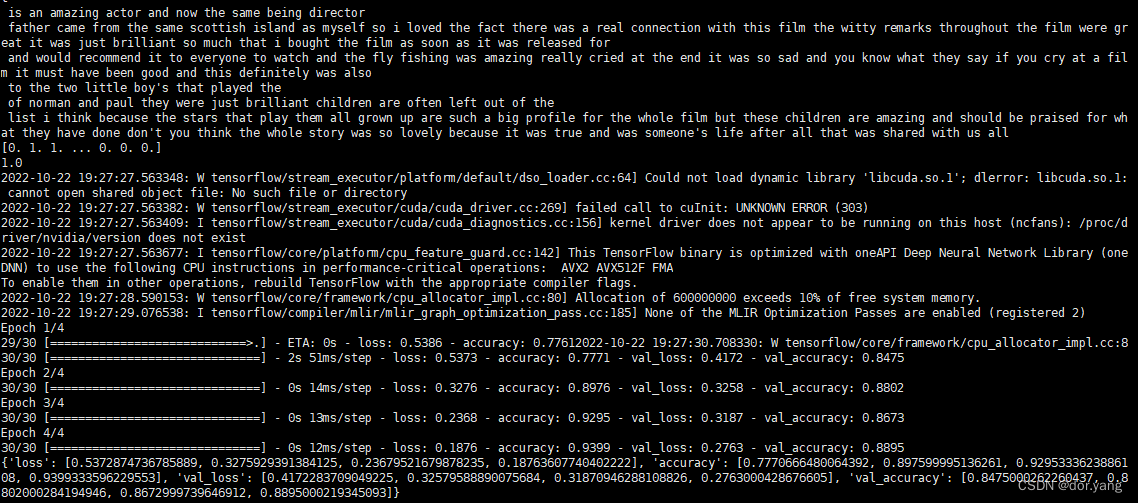
这里输出的有一些又多又杂了,总体来说的话就是,我们的python文件完成了深度学习并且每一步都有结果输出。不过美中不足的就是我们绘制图像部分没有能够出图片,不过也可以理解。毕竟服务器弹出个图片来,多少有点不严肃了。
另外补充一下,就是中间又报出了缺少matplotlib的包,也是直接pip install就可以,这个很小也很快。然后就没问题了。
至于代码,这个就是之前python深度学习中最开始的那个判断电影评论是正向还是负面的二分类问题。代码部分的话也附在这里吧,大家可以自己试一下:(前五行代码也是搜的用来解决这个文件执行问题的方法,不过没有用,可以不管)
import os
import sys
curPath = os.path.abspath(os.path.dirname(__file__))
rootPath = os.path.split(curPath)[0]
sys.path.append(rootPath)
# 加载IMDB数据集,并且只保留前一万个最常出现的单词,低频单词被舍弃,这样确保向量数据不会太太大。
import keras
from keras.datasets import imdb
(train_data,train_labels),(test_data,test_labels)=imdb.load_data(num_words=10000)
# 这里的data就是评论单词索引的列表,label就是评论的正负向
print(train_data[0])
print(train_labels[0])
# 因为只要了前一万个常用的单词,所以他们对应的索引编号不应该超过一万
print(max([max(sequence) for sequence in train_data]))
# 但是看一串数字多没意思啊,我们还得能转换回评论语句来
word_index=imdb.get_word_index()
reverse_word_index=dict([(value,key) for (key,value) in word_index.items()])
decoded_review=' '.join([reverse_word_index.get(i-3,'\n') for i in train_data[0]])
print(decoded_review)
# 我们现在有了数据集,但是我们不可能直接输入神经网络的,我们还需要将列表转化成张量
import numpy as np
# 这个函数的功能就是做了一个二维表,将每一个语句对应索引位置置1
def vectorsize_sequence(sequences,dimension=10000):
results=np.zeros((len(sequences),dimension))
for i,sequence in enumerate(sequences):
results[i,sequence]=1
return results
# 这里我们可以看到样本成了这个样子
x_train=vectorsize_sequence(train_data)
x_test=vectorsize_sequence(test_data)
print(x_train[0])
# 但是label相对就好处理很多
y_train=np.asarray(train_labels).astype('float32')
y_test=np.asarray(test_labels).astype('float32')
print(y_train[0])
# 开始构建网络
from keras import models
from keras import layers
# 我知道你很急,但是你先别急
# 我们现在只要相信他们给出的网络就可以
model=models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
# 模型架构就是这样了,简单设置了一下优化器,损失函数和指标
model.compile(optimizer='rmsprop',loss='binary_crossentropy',metrics=['accuracy'])
# 这里是为了把之前整个的数据分开,一部分做训练集,一部分做验证集,训练验证分开是为了防止过拟合导致结果失真
x_val=x_train[:10000]
partial_x_train=x_train[10000:]
y_val=y_train[:10000]
partial_y_train=y_train[10000:]
# 开始训练,512个样本为小批量,连上20次,fit函数会返回一个history对象,内有全部训练过程的数据。
history=model.fit(partial_x_train,partial_y_train,epochs=4,batch_size=512,validation_data=(x_val,y_val))
history_dict=history.history
print(history_dict)
# 现在我们可以绘制出来训练过程的效果如何
import matplotlib.pyplot as plt
# 绘制训练损失和验证损失
loss_value=history_dict['loss']
val_loss_value=history_dict['val_loss']
epochs=range(1,len(loss_value)+1)
plt.plot(epochs,loss_value,'bo',label='Training loss')
plt.plot(epochs,val_loss_value,'b',label='Validation loss')
plt.title('Training and Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# 同理,绘制训练精度和验证精度
plt.clf()
accy=history_dict['accuracy']
val_accy=history_dict['val_accuracy']
plt.plot(epochs,accy,'bo',label='Training acc')
plt.plot(epochs,val_accy,'b',label='Validation acc')
plt.title('Training and Validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('acc')
plt.legend()
plt.show()
# 如果你认真看了这两个图片,就会发现很奇怪的事情,随着我们训练轮次的增加,似乎训练集精度的提高反而带来了验证集损失的增加和精度的下降
# 这就是过拟合,训练轮子太多,导致学习到了训练集本身的属性
result=model.evaluate(x_test,y_test)
print(result)
print(model.predict(x_test))
最后补充一下xftp好了
xftp的功能其实是和Rz,rm指令类似,rz,rm可以指定文件上传和删除,而xftp的作用我目前来看的话就是把这个部分的功能可视化了一下。(虽然我觉得应该不只,但是目前用到的就这个)