😻今天我们来学习启发式算法中的蚁群算法,据说,蚁群算法是路径规划算法中’最好’的群智能算法。快让我们开始吧!
目录
- 1. 蚁群算法基本介绍
- 1.1 算法简介
- 1.2 算法原理
- 2.蚁群算法的基本流程
- 2.1 路径构建
- 2.2 蚂蚁信息素的更新
- 3. scikit-opt实现蚁群算法
- 4. 改进的蚁群算法
- 4.1 精华蚂蚁
- 4.2 排列蚂蚁
- 4.3 最大最小蚂蚁
- 5. 参考资料
1. 蚁群算法基本介绍
1.1 算法简介
蚁群优化算法 (Ant Colony Opt imization, ACO)作为一种全局最优化搜索方法 , 同遗传算法一样来源于自然界的启示,并有着良好的搜索性能 。 不同的是,蚁群算法通过模拟蚂蚁觅食的过程,是一种天然的解决离散组合优化问题的方法,在解决典型组合优化问 题,如旅行商问题 (TSP ) 、车辆路径问题 CVRP ) 、车间作业调度问题 CJSP) 时具有明显的优越性 。 目前针对蚁群算法在数学理论、算法改进、实际应用等方面的研究是计算智能领域的热点,取得了一定的进展。
1.2 算法原理
蚂蚁在寻找食物的过程中往往是随机选择路径的 ,但它们能感知当前地 面上的信息素浓度,并倾向于往信息素浓度高的方向行进 。 信息素由蚂蚁自身释放,是实 现蚁群内间接通信的物质 。 由于较短路径上蚂蚁的往返时间比较短,单位时间内经过该路径的蚂蚁多,所以信息素的积累速度比较长路径快 。 因此,当后续蚂蚁在路口时,就能 感知先前蚂蚁留下的信息,并倾向 于选择一条较短的路径前行 。 这种正反馈机制使得越来越多的蚂蚁在巢穴与食物之间的最短路径上行进 。 由于其他路径上的信息素会随着时间蒸发,最终所有的蚂蚁都在最优路径上行进 。 蚂蚁群体的这种自组织工作机制适应环境的能力特别强 ,假设最优路径上突然出现障碍物 ,蚁群也能够绕行并且很快重新探索出一条新的最优路径。

2.蚁群算法的基本流程
AS 算法对 TSP 的求解流程主要有两大步骤 : 路径构建和信息素更新 。已知 n 个城市的集合 C = ( c 1 , c 2 , … , c n ) C = ({c1 , c2 , …, cn}) C=(c1,c2,…,cn)任意两个城市之间均有路径连接, d i j ( i , j = 1 , 2 , … , n ) d_{ij}(i,j =1,2, … , n) dij(i,j=1,2,…,n)表 示 城市i与j之间的距离,它是已知的(或者城市的坐标集合为已知, d i j d_{ij} dij即为城市i与j之间的欧几里德距离)。TSP 的目的是找到从 某个城市 c i {c_i} ci出发 ,访问所有城市且只访问一次 ,最后回到 c i {c_i} ci的最短封闭路线。
2.1 路径构建
每只蚂蚁都随机选择一个城市作为其出发城市,并维护一个路径记忆向量 ,用来存放该蚂蚁依次经过的城市。蚂蚁在构建路径的每一步中,按照一个随机比例规则选择下一个要到达的城市 。
AS 中的随机比例规则 (random proportional) : 对于每只蚂蚁 k,路径记忆向量
R
k
R^k
Rk 按照访问顺序记录了所有 k 已经经过的城市序号 。 设蚂蚁
k
k
k当前所在城市为
i
i
i,则其选择城市
j
j
j作为下一个访问对象的概率为:
p
k
(
i
,
j
)
=
{
[
τ
(
i
,
j
)
]
α
[
η
(
i
,
j
)
]
β
∑
u
∈
J
k
(
i
)
[
τ
(
i
,
u
)
]
α
[
η
(
i
,
u
)
]
β
,
j
∈
J
k
(
i
)
0
,
其他
\begin{equation*} p_{k}(i,j)= \begin{cases} \frac{[\tau(i,j)]^{\alpha}[\eta(i,j)]^{\beta}}{\sum_{u\in J_k(i)}[\tau(i,u)]^{\alpha}[\eta(i,u)]^{\beta}}, & j \in J_k(i) \\ \\ \text{0}, & \text{其他} \end{cases} \end{equation*}
pk(i,j)=⎩
⎨
⎧∑u∈Jk(i)[τ(i,u)]α[η(i,u)]β[τ(i,j)]α[η(i,j)]β,0,j∈Jk(i)其他
其中 , J k ( i ) J_k(i) Jk(i)表示从城市 i i i可以直接到达的且又不在蚂蚁访问过的城市序列 R k R^k Rk中的城市集合。 η ( i , j ) \eta(i,j) η(i,j)是一个启发式信息 ,通常由 η ( i , j ) = 1 / d i j \eta(i,j)=1/d_{ij} η(i,j)=1/dij直接计算。 τ ( i , j ) \tau(i,j) τ(i,j)表示边 ( i , j ) (i,j) (i,j)上的信息素量 。 由上述公式可知,长度越短、信息素浓度越大的路径被蚂蚁选择的概率越大, α \alpha α和 β \beta β是两个预先设置的参数 , 用来控制启发式信息与信息素浓度作用的权重关系 。 当 α = 0 \alpha=0 α=0时 ,算法演变成传统的随机贪婪算法 ,最邻近城市被选中的概率最大 。 当 β = 0 \beta=0 β=0时,蚂蚁完全只根据信息素浓度确定路径,算法将快速收敛,这样构建出的最优路径往往与实际目标有着较大的差异,算法的性能比较糟糕。实验表明,在 AS 中设置 α = 1 , β = 2 ∼ 5 \alpha=1,\beta=2\sim5 α=1,β=2∼5比较合适 。
2.2 蚂蚁信息素的更新
在算法初始化时,问题空间中所有的边上的信息素都被初始化为
τ
0
\tau_0
τ0。 如果
τ
0
\tau_0
τ0太小,算法容易早熟,即蚂蚁很快就全部集中在一条局部最优的路径上 。 反之 ,如果
τ
0
\tau_0
τ0太大,信息素对搜索方向的指导作用太低,也会影响算法性能 。 对 AS 来说 , 我们使用
τ
0
=
m
/
C
m
\tau_0=m/C^m
τ0=m/Cm是蚂蚁的个数 ,
C
m
C^m
Cm是由贪婪算法构造的路径的长度 。
当所有蚂蚁构建完路径后 ,算法将会对所有的路径进行全局信息素的更新 。 注意 , 我 们所描述的是 AS 的 ant-cycle 版本,更新是在全部蚂蚁均完成了路径的构造后才进行的 , 信息素的浓度变化与蚂蚁在这一轮中构建的路径长度相关 , 实验表明 ant-cycle 比 ant-density 和 ant-quantity 的性能要好很多 。
信息素的更新也有两个步骤:首先 ,每一轮过后,问题空间中的所有路径上的信息素都会发生蒸发,我们为所有边上的信息素乘上一个小于 1 的常数 。 信息索蒸发是自然界本身固有的特征 ,在算法中能够帮助避免信息素的无限积累,使得算法可以快速丢弃之前构建过的较差的路径 。 随后所有的蚂蚁根据自己构建的路径长度在它们本轮经过的边上释放信息素 。 蚂蚁构建的路径越短、释放的信息素就越多; 一条边被蚂蚁爬过的次数越 多、它所获得的信息素也越多 。 AS 中城市
i
i
i与城市
j
j
j的相连边上的信息素
τ
(
i
,
j
)
\tau(i,j)
τ(i,j)按照如下公式进行更新:
τ
(
i
,
j
)
=
(
1
−
ρ
)
+
∑
k
=
1
m
△
τ
k
(
i
,
j
)
\tau(i,j)=(1-\rho)+\sum_{k=1}^{m}\triangle\tau_k(i,j)
τ(i,j)=(1−ρ)+k=1∑m△τk(i,j)
△
τ
k
(
i
,
j
)
=
{
(
C
k
)
−
1
,
i
,
j
∈
R
k
0
,
其他
\begin{equation*} \triangle\tau_k(i,j)= \begin{cases} \ (C_k)^{-1}, & {i,j} \in R^k \\ \\ \text{0}, & \text{其他} \end{cases} \end{equation*}
△τk(i,j)=⎩
⎨
⎧ (Ck)−1,0,i,j∈Rk其他
这里,m 是蚂蚁个数 ρ \rho ρ是信息素的蒸发率 0 < ρ ⩽ 1 0<\rho\leqslant1 0<ρ⩽1 ,规定在 AS 中通常设置为 ρ = 0.5 \rho=0.5 ρ=0.5。 △ τ k ( i , j ) \triangle\tau_k(i,j) △τk(i,j)是第 k 只蚂蚁在它经过的边上释放的信息素量 ,它等于蚂蚁 k 本轮构建路径长度的倒数。 C k C_k Ck表示路径长度,它是 R^k 中所有边的长度和。
下图展示一下伪代码:

3. scikit-opt实现蚁群算法
TSP问题使用蚁群算法进行解决
import numpy as np
from scipy import spatial
import pandas as pd
import matplotlib.pyplot as plt
#设置25个点的目标点
num_points = 25
#对这25个点生成随机的坐标
points_coordinate = np.random.rand(num_points, 2) # generate coordinate of points
# 对这25个点计算距离矩阵
distance_matrix = spatial.distance.cdist(points_coordinate, points_coordinate, metric='euclidean')
#目标函数,计算最短路径
def cal_total_distance(routine):
num_points,= routine.shape
return sum([distance_matrix[routine[i % num_points], routine[(i + 1) % num_points]] for i in range(num_points)])
# 导入scikit-opt包来配置蚁群算法计算最短路径
from sko.ACA import ACA_TSP
#使用蚁群算法 func代表目标函数、n_dim代表样本的维度、size_pop代表蚂蚁数量、max_iter是迭代次数
aca = ACA_TSP(func=cal_total_distance, n_dim=num_points,
size_pop=50, max_iter=200,
distance_matrix=distance_matrix)
#结果
best_x, best_y = aca.run()
# %% 画图
fig, ax = plt.subplots(1, 2)
best_points_ = np.concatenate([best_x, [best_x[0]]])
best_points_coordinate = points_coordinate[best_points_, :]
ax[0].plot(best_points_coordinate[:, 0], best_points_coordinate[:, 1], '^-b')
pd.DataFrame(aca.y_best_history).cummin().plot(ax=ax[1])
plt.show()
结果如下:
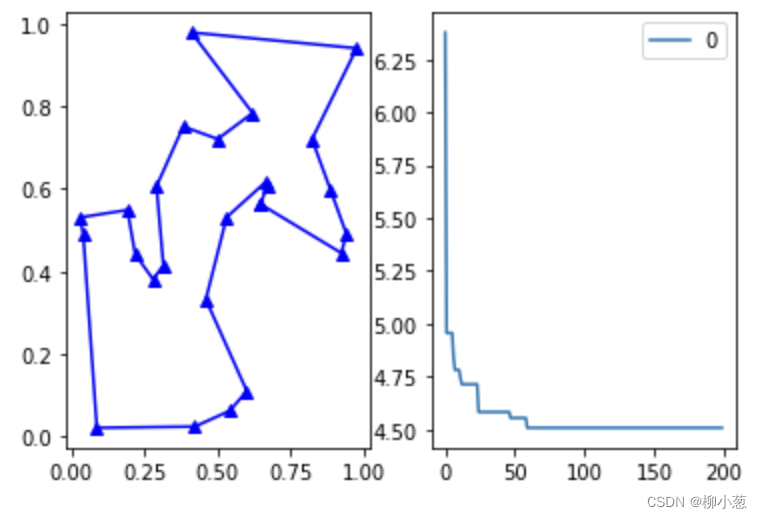
4. 改进的蚁群算法
4.1 精华蚂蚁
普通的蚁群算法 ,蚂蚁在其爬过的边上释放与其构建路径长度成反比的信息素量 , 蚂蚁构建的路径越好,属于路径的各个边上所获得的信息素就越多,这些边在以后的迭代中被蚂蚁选择的概率也就越大 。 但我们不难想象,当城市的规模较大时,问题的复杂度呈指数级增长 ,仅仅靠这样一个基础单一的信息素更新机制引导搜索偏向,搜索效率有瓶颈 。 我们能否通过一种’额外的手段’强化某些最有可能成为最优路径的边 ,让蚂蚁搜索的范围更快、更正确地收敛呢?
答案是肯定的,精华蚂蚁系统 ( Elitist Ant System, EAS)是对基础 AS 的第一次改进 ,它在原 AS 信息素更新原则的基础上增加了一个对至今最优路径的强化手段 。 在每轮信息素更新完毕后,搜索到至今最优路径(我们用
T
b
T_b
Tb表示)的那只蚂蚁将会为这条路径添加额外的信息素 。 EAS 中城市
i
i
i与城市
j
j
j的相连边上的信息索量
τ
(
i
,
j
)
\tau(i,j)
τ(i,j)的更新如下:
τ
(
i
,
j
)
=
(
1
−
ρ
)
∗
τ
(
i
,
j
)
+
∑
k
=
1
m
△
τ
k
(
i
,
j
)
+
e
△
b
(
i
,
j
)
\tau(i,j)=(1-\rho)*\tau(i,j)+\sum_{k=1}^{m}\triangle\tau_k(i,j)+e\triangle_b(i,j)
τ(i,j)=(1−ρ)∗τ(i,j)+k=1∑m△τk(i,j)+e△b(i,j)
△
τ
k
(
i
,
j
)
=
{
(
C
k
)
−
1
,
i
,
j
∈
R
k
0
,
其他
\begin{equation*} \triangle\tau_k(i,j)= \begin{cases} \ (C_k)^{-1}, & {i,j} \in R^k \\ \\ \text{0}, & \text{其他} \end{cases} \end{equation*}
△τk(i,j)=⎩
⎨
⎧ (Ck)−1,0,i,j∈Rk其他
△
τ
b
(
i
,
j
)
=
{
(
C
b
)
−
1
,
i
,
j
在路径
T
b
上
0
,
其他
\begin{equation*} \triangle\tau_b(i,j)= \begin{cases} \ (C_b)^{-1}, & {i,j} \text{在路径}T_b 上 \\ \\ \text{0}, & \text{其他} \end{cases} \end{equation*}
△τb(i,j)=⎩
⎨
⎧ (Cb)−1,0,i,j在路径Tb上其他
在 EAS 中,新增了
△
b
(
i
,
j
)
\triangle_b(i,j)
△b(i,j),并定义参数 e 作为
△
b
(
i
,
j
)
\triangle_b(i,j)
△b(i,j)的权值。
C
b
C_b
Cb是算法开始至今最优路径的长度。可见,EAS 在每轮迭代中为属于
T
b
T_b
Tb的边增加了额外的
e
/
C
b
e/C_b
e/Cb的信息素量 。
4.2 排列蚂蚁
人们的思想总是与时俱进的,在精华蚂蚁系统被提出后 , 我们又会思考 ,有没有更好 的一种信息素更新方式 ,它同样使得
T
b
T_b
Tb各边的信息索浓度得到加强 ,且对其余边的信息素更新机制亦有改善?
基于排列的蚂蚁系统 (rank-based Ant System,
A
S
r
a
n
k
AS_{rank}
ASrank)就是这样一种改进版本,它在 AS 的基础上给蚂蚁要释放的信息素大小
△
τ
k
(
i
,
j
)
\triangle\tau_k(i,j)
△τk(i,j)加上一个权值,进一步加大各边信息 素量的差异 , 以指导搜索 。 在每一轮所有蚂蚁构建完路径后,它们将按照所得路径的长短进行排名 ,只有生成了至今最优路径的蚂蚁和排名在前
(
w
−
1
)
(w- 1)
(w−1)的蚂蚁才被允许释放信息素,蚂蚁在边
(
i
,
j
)
(i,j)
(i,j)上释放的信息素
△
τ
k
(
i
,
j
)
\triangle\tau_k(i,j)
△τk(i,j)的权值由蚂蚁的排名决定 。
A
S
r
a
n
k
AS_{rank}
ASrank中的信息素更新规则如下所示 :
τ
(
i
,
j
)
=
(
1
−
ρ
)
∗
τ
(
i
,
j
)
+
∑
k
=
1
m
−
1
(
w
−
k
)
△
τ
k
(
i
,
j
)
+
w
△
b
(
i
,
j
)
\tau(i,j)=(1-\rho)*\tau(i,j)+\sum_{k=1}^{m-1}(w-k)\triangle\tau_k(i,j)+w\triangle_b(i,j)
τ(i,j)=(1−ρ)∗τ(i,j)+k=1∑m−1(w−k)△τk(i,j)+w△b(i,j)
△
τ
k
(
i
,
j
)
=
{
(
C
k
)
−
1
,
i
,
j
∈
R
k
0
,
其他
\begin{equation*} \triangle\tau_k(i,j)= \begin{cases} \ (C_k)^{-1}, & {i,j} \in R^k \\ \\ \text{0}, & \text{其他} \end{cases} \end{equation*}
△τk(i,j)=⎩
⎨
⎧ (Ck)−1,0,i,j∈Rk其他
△
τ
b
(
i
,
j
)
=
{
(
C
b
)
−
1
,
i
,
j
在路径
T
b
上
0
,
其他
\begin{equation*} \triangle\tau_b(i,j)= \begin{cases} \ (C_b)^{-1}, & {i,j} \text{在路径}T_b 上 \\ \\ \text{0}, & \text{其他} \end{cases} \end{equation*}
△τb(i,j)=⎩
⎨
⎧ (Cb)−1,0,i,j在路径Tb上其他
构建至今最优路径
T
b
T_b
Tb的蚂蚁(该路径不一定出现在当前迭代的路径中 ,各种蚁群算法均假设蚂蚁有记忆功能 ,至今最优的路径总是能被记住)产生信息素的权值大小为
w
w
w, 它将在
T
b
T_b
Tb的各边上增加
w
/
C
b
w /C_b
w/Cb的信息素量 ,也就是说,路径
T
b
T_b
Tb将获得最多的信息素量。 其余的,在本次迭代中排名第
k
(
k
=
1
,
2
,
…
,
w
—
1
)
k(k = 1,2 , … ,w— 1)
k(k=1,2,…,w—1)的蚂蚁将释放
(
w
—
k
)
/
C
k
(w — k) / C_k
(w—k)/Ck 的信息素 。 排名越前的蚂蚁释放的信息素量越大,权值
(
w
—
k
)
(w— k)
(w—k)对不同路径的信息素浓度差异起到了一个放大的作用,
A
S
r
a
n
k
AS_{rank}
ASrank能更有力度地指导蚂蚁搜索。一般设置
w
=
6
w= 6
w=6。
4.3 最大最小蚂蚁
在上述两种蚁群算法中有一下问题:
问题一 : 对于大规模的 TSP, 由于搜索蚂蚁的个数有限,而初始化时蚂蚁的分布是随机的 ,这会不会造成蚂蚁只搜索了所有路径中的小部分就以为找到了最好的路径 ,所有的蚂蚁都很快聚集在同一路径上 ,而真正优秀的路径并没有被探索到呢?
问题二 : 当所有蚂蚁都重复构建着同一条路径的时候,意味着算法已经进入停滞状态。此时,不论是基本 AS 、 EAS 还是
A
S
r
a
n
k
AS_{rank}
ASrank ,之后的迭代过程都不再可能有更优的路径出现。这些算法收敛的效果虽然是“单纯而快速的”,但我们都懂得”欲速则不达”的道理 , 我们有没有办法利用算法停滞后的迭代过程进一步搜索以保证找到更接近真实目标的解呢?
为了解决上面的两个问题,最大最小蚂蚁系统 (MAX-MIN Ant System , MMAS) 在基本 AS 算法的基础上进行了以下改进:
- 只允许迭代最优蚂蚁(在本次迭代构建出最短路径的蚂蚁),或者至今最优蚂蚁释放信息素 。
- 信息素量大小的取值范围被限制在一个区间内。
- 信息素初始值为信息素取值区间的上限,并伴随一个较小的信息素蒸发速率 。
- 每当系统进入停滞状态,问题空间内所有边上的信息素量都会被重新初始化 。
在 EAS 中 ,只允许至今最优的蚂蚁释放信息素,而在 MMAS 中 ,释放信息素的不仅有可能是至今最优蚂蚁,还有可能是迭代最优蚂蚁。实际上,迭代最优更新规则和至今最优更新规则 在 MMAS 中会被交替使用。这两种规则使用的相对频率将会影响算法的搜索效果。如果只使用至今最优更新规则进行信息素的更新,搜索的导向性很强,算法会很快收敛到
T
b
T_b
Tb附近 ;反之,如果只使用迭代最优更新规则,则算法的探索能力会得到增强,但收敛速度会下降 。
在 MMAS 中,为了避免某些边上的信息素浓度增长过快,算法出现早熟现象,即所改进 (2) 和 (3)为我们解决了本小节开头提出的问题一 ,下面我们讨论问题二的解决有的蚂蚁都搜索一条较优而不是最优的路径,提出了改进(2)。 信息素量的大小被限定在一个取值范围即
[
τ
m
i
n
,
τ
m
a
x
]
[\tau_{min},\tau_{max}]
[τmin,τmax]内 。 我们知道,蚂蚁是依据启发式信息和信息素浓度选择下城市节点的,其中启发式信息为蚂蚁当前所在城市
i
i
i到下一可能城市
j
j
j的距离的
d
i
j
d_{ij}
dij的倒数,由于各个
d
i
j
d_{ij}
dij的大小是事先给定的,取值范围已经确定,所以当信息素浓度也被限制在一个范围内以后,位于城市
i
i
i的蚂蚁
k
k
k选择城市
j
j
j作为下一城市的概率
p
k
(
i
,
j
)
p_k(i,j)
pk(i,j)也将被限制在一个区间内,实际上,我们无需计算 Pmin 和 Pmax的值的大小,只 要知道
0
<
p
m
i
n
<
p
k
(
i
,
j
)
<
p
m
a
x
<
1
0 < p_{min} < p_k (i , j) <p_{max}<1
0<pmin<pk(i,j)<pmax<1就可以确定算法巳经有效避免了陷入停滞状态的可能性 。
由改进 (3)我们知道,算法在初始化阶段,问题空间内所有边上的信息素均被初始化为
τ
m
a
x
\tau_{max}
τmax的估计值,且信息素蒸发速率非常小(在 MMAS 中, 一般将 p 置为 0.02), 这样一来,不同边上的信息素浓度差异只会缓慢地增加,因此在算法的初始化阶段, MMAS 有着 较基本 AS 、EAS 和
A
S
r
a
n
k
AS_{rank}
ASrank更强的探索能力。增强算法在初始阶段的探索能力有助于蚂蚁 “视野开阔地”进行全局范圉内的搜索,随后再逐渐缩小搜索范围,最后定格在一条全局最优路径上 。
之前的蚁群算法,不论是 AS 、 EAS 还是
A
S
r
a
n
k
AS_{rank}
ASrank均属于 ”一次性探索”,即 随着算法的执行,某些边的信息素量变得越来越小,某些路径被选择的概率也越来越小,系统的探索范即不断减小直至陷入停滞状态。在 MMAS 中,当算法接近或是进入停滞状态时,问题空间内所有边上的信息素浓度都将被重新初始化,从而有效地利用系统进入 停滞状态后的迭代周期继续进行搜索,使算法具有更强的全局寻优能力 。 我们通常通过对各条边上信息素量大小的统计或观察算法在指定次数的迭代内至今最优路径有无被更新来判断算法是否停滞 。
5. 参考资料
- 《计算智能》
- scikit-opt开发文档