上一次讲解了如何在linux服务器上使用docker配置ELK中的E和K,这期着重讲解一下L怎么配置。
首先L在elk中指的是一个数据处理管道,可以从多种来源收集数据,进行处理和转换,然后将数据发送到 Elasticsearch。L的全称就是:Logstash,Logstsh的功能特别多,提供了大量的输入,过滤和输出插件,但是他的资源占用也比较多。
08_对接kafka案例展示_哔哩哔哩_bilibili
简单说一下什么是Filebeat
Filebeat是一种轻量型日志采集器,内置有多种模块(auditd、Apache、NGINX、System、MySQL 等等),可针对常见格式的日志大大简化收集、解析和可视化过程,只需一条命令即可。根据采集的数据形式不同,形成了由多个模块组成的Beats。Beats是开源数据传输程序集,可以将其作为代理安装在服务器上,将操作数据发送给Elasticsearch,或者通过Logstash,在Kibana中可视化数据之前,在Logstash中进一步处理和增强数据。
白话说:Filebeat占用内存小的日志采集器,它的作用是:1、可以代替Logstash将日志直接发送到Elasticsearch.2、可以在Filebeat收集完数据后统一发送给Logstash,然后又Logstash进一步处理数据后再发送给Elasticsearch。
Filebeat特点
(1)轻量型日志采集器,占用资源更少,对机器配置要求极低。
(2)操作简便,可将采集到的日志信息直接发送到ES集群、Logstash、Kafka集群等消息队列中。
(3)异常中断重启后会继续上次停止的位置。(通过${filebeat_home}\data\registry文件来记录日志的偏移量)。
(4)使用压力敏感协议(backpressure-sensitive)来传输数据,在 logstash 忙的时候,Filebeat 会减慢读取-传输速度,一旦 logstash 恢复,则 Filebeat 恢复原来的速度。
(5)Filebeat带有内部模块(auditd,Apache,Nginx,System和MySQL),可通过一个指定命令来简化通用日志格式的收集,解析和可视化。
bin/logstash -e ‘input { stdin{} } output { stdout{} }’
Filebeat与Logstash对比
(1)Filebeat是轻量级数据托运者,您可以在服务器上将其作为代理安装,以将特定类型的操作数据发送到Elasticsearch。与Logstash相比,其占用空间小,使用的系统资源更少。
(2)Logstash具有更大的占用空间,但提供了大量的输入,过滤和输出插件,用于收集,丰富和转换来自各种来源的数据。
(3)Logstash是使用Java编写,插件是使用jruby编写,对机器的资源要求会比较高。在采集日志方面,对CPU、内存上都要比Filebeat高很多。
为什么要先用Filebeat收集再发送到logstash呢?
假设我们有多个节点都需要收集日志数据,如果每一个节点都安装一个Logstash,那么消耗的内存就浪费了,但是如果每个都安装一个占用内存很小的Filebeat,然后将所有的Filebeat收集的数据都发送给统一的一个Logstash的话,那么Logstash只需要下载一遍就可以了。
演示如何安装部署L部分
前言:记得elk中的几个工具都用一样版本的,不同版本可能会出现版本不兼容,看上一篇博客说的,我们继续使用 7.12.1版本的。
上一个服务器也就是ELK中EK都是在ip: 121.196.217.190上的,E在9200端口,K在5601端口。
我要把L也就是收集器就模拟放到一个节点上,放到另外一个服务器上,ip: 8.148.4.43,注意提前关闭防火墙和打开端口访问,
这个服务器使用到的端口是5044端口。
下载Filebeat
# 进入文件夹
cd /www/zzntest/
# 下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.12.1-linux-x86_64.tar.gz
# 解压文件
tar -zxvf filebeat-7.12.1-linux-x86_64.tar.gz
# 重命名
mv filebeat-7.12.1-linux-x86_64 filebeat
下载好了之后
#进入filebeat
cd filebeat
#指定监控日志的输入输出路径
vim filebeat.yml
改下面这两部分内容:意思就是允许从/www/zzntest/log/*.log 路径下的日志输入到filebeat
# Unique ID among all inputs, an ID is required.
id: my-filestream-id
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /www/zzntest/log/*.log
此时如果启动filebeat他就会监听/www/zzntest/log/*.log 的日志文件了,但是我们还没有写输出到哪里,所以先不启动,
先测试第一种情况,
1、将日志用filebeat收集后输出到logstash上
下载logstash
下载filebeat差不多
cd /www/zzntest/
# 下载
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.12.1-linux-x86_64.tar.gz
# 解压文件
tar -zxvf logstash-7.12.1-linux-x86_64.tar.gz
# 重命名
mv logstash-7.12.1 logstash
在logstash里面创建文件夹job编写数据采集文件:filebeat_to_logstash.conf
mkdir job
vim filebeat_to_logstash.conf
#本次采用的数据为数仓项目中的模拟数据
#1562065564549|{"cm":{"ln":"-54.7","sv":"V2.9.8","os":"8.1.0","g":"9NY0AL0L@gmail.com","mid":"m140","nw":"WIFI","l":"pt","vc":"13","hw":"1080*1920","ar":"MX","uid":"u737","t":"1562030978430","la":"-7.4","md":"HTC-14","vn":"1.1.3","ba":"HTC","sr":"M"},"ap":"gmall","et":[{"ett":"1561996979060","en":"display","kv":{"newsid":"n925","action":"1","extend1":"1","place":"4","category":"37"}},{"ett":"1562031053551","en":"newsdetail","kv":{"entry":"3","newsid":"n332","news_staytime":"10","loading_time":"8","action":"4","showtype":"3","category":"11","type1":"433"}},{"ett":"1561986545246","en":"loading","kv":{"extend2":"","loading_time":"7","action":"1","extend1":"","type":"1","type1":"102","loading_way":"1"}},{"ett":"1562053433842","en":"active_foreground","kv":{"access":"1","push_id":"1"}},{"ett":"1562030443443","en":"favorites","kv":{"course_id":2,"id":0,"add_time":"1562049124751","userid":0}}]}
#上面是即将使用的模拟数据,下面就是输入输出使用的端口5044,语言默认“GBK”,过滤器filter就是接收的message使用“|”切分,最后拿到数据转换为json,然后output->stdout即输出到控制台。
input {
beats {
port=>5044
codec=>plain{
charset=>"GBK"
}
}
}
filter {
mutate{
split=>["message","|"]
add_field => {
"field1" => "%{[message][0]}"
}
add_field => {
"field2" => "%{[message][1]}"
}
remove_field => ["message"]
}
json{
source => "field1"
target => "field2"
}
}
#输出数据到控制台
output{
stdout{
codec=>rubydebug
}
}
这个文件写好之后就回到logstash的目录下启动logstash
bin/logstash -f job/filebeat_to_logstash.conf
启动完之后不要关闭这个窗口,再开一个窗口进入到filebeat文件夹中
进入之后再次打开配置修改 vim filebeat.yml
要修改的内容就是将output部分中的Elasticsearch给注释掉,然后把Logstash需要的部分给打开和输入要传输的目的地。
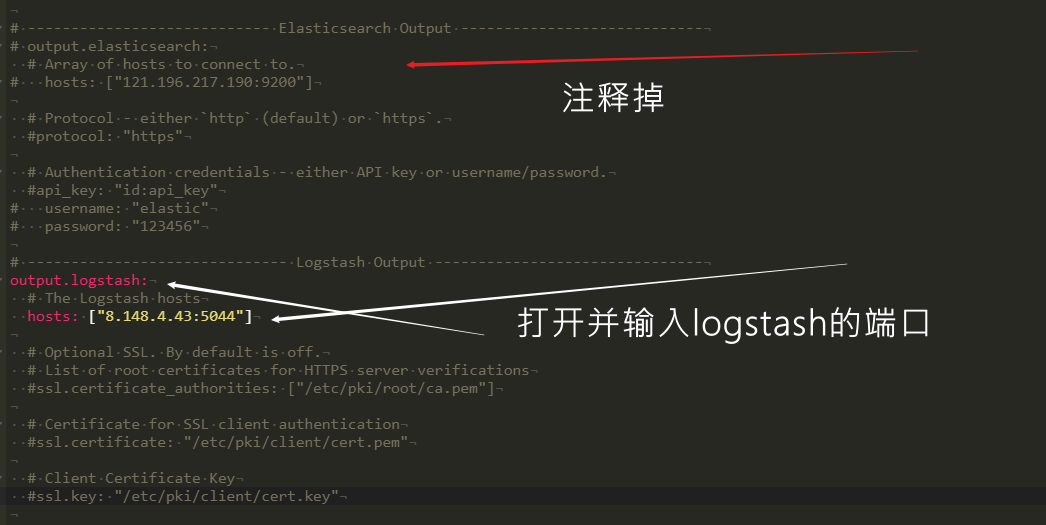
此时就可以去运行filebeat了, ./filebeat -e 即携带日志运行,
注意一下,此时开了两个页面,窗口1是运行logstash的,窗口2是运行filebeat的,都不要关,去打开窗口3进入到zzntest/log/文件夹下
准备输入日志 echo hello >> 1.log 输入之后,就会看到窗口2是这样的
注意:在这里是输入数据到端口,一定要把端口使用权限打开,不然会报error说连接端口失败。
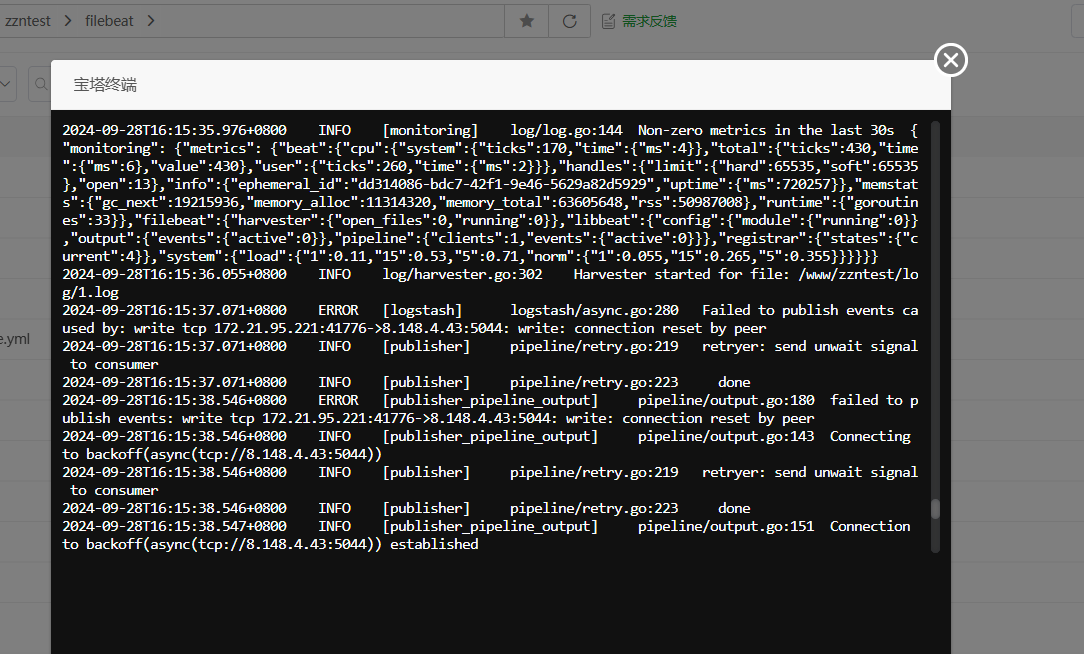
端口2将数据处理好之后就会发送到5044端口,然后窗口1就会看到刚才输入的hello,但格式虽然和最初的不太符合,但这起码映射成功了。
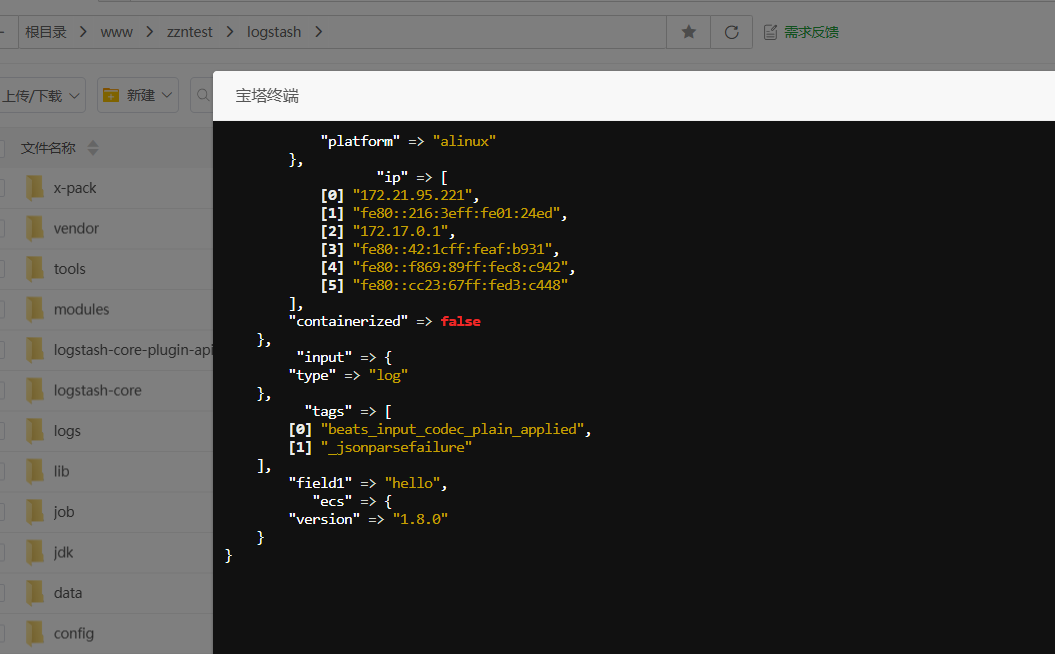
如果此时把最初准备好的日志内容输入vim test.log
1562065564549|{"cm":{"ln":"-54.7","sv":"V2.9.8","os":"8.1.0","g":"9NY0AL0L@gmail.com","mid":"m140","nw":"WIFI","l":"pt","vc":"13","hw":"1080*1920","ar":"MX","uid":"u737","t":"1562030978430","la":"-7.4","md":"HTC-14","vn":"1.1.3","ba":"HTC","sr":"M"},"ap":"gmall","et":[{"ett":"1561996979060","en":"display","kv":{"newsid":"n925","action":"1","extend1":"1","place":"4","category":"37"}},{"ett":"1562031053551","en":"newsdetail","kv":{"entry":"3","newsid":"n332","news_staytime":"10","loading_time":"8","action":"4","showtype":"3","category":"11","type1":"433"}},{"ett":"1561986545246","en":"loading","kv":{"extend2":"","loading_time":"7","action":"1","extend1":"","type":"1","type1":"102","loading_way":"1"}},{"ett":"1562053433842","en":"active_foreground","kv":{"access":"1","push_id":"1"}},{"ett":"1562030443443","en":"favorites","kv":{"course_id":2,"id":0,"add_time":"1562049124751","userid":0}}]}
在窗户一就可以看到想要的结果了。也就是完成了。

2、将filebeat的内容直接放到es里
如果发送到logstash的话就是不需要考虑什么索引表名什么都不用考虑,但是es是要注意发送到哪一个索引(index)
先去修改Filebeat中的配置,因为我们是日志,就简单做一下分区
把logstash给注释掉,然后打开elasticsearch,和添加下面的索引,大概意思就是:如果输入的日志字段含有WARN字段,就放到索引warning里面就可以。如果包含ERR就放到,,,,索引中另外两个也是同样的作用。
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["8.148.4.43:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "changeme"
#通过判断数据中包含的字符串 可以分流数据
#通过语法%{}可以调用元数据信息和特殊信息
#error-8.5.2-2022-12-02
indices:
- index: "warning"
when.contains:
message: "WARN"
- index: "error-%{[agent.version]}-%{+yyyy.MM.dd}"
when.contains:
message: "ERR"
- index: "info"
when.contains:
message: "INFO"
修改好之后就打开es和重新运行filebeat。./filebeat -e 然后再用重新的方法在窗口3里输入日志。
输出好之后就打开es所在地,因为之前已经配置好kibana,所以就直接打开kibana的端口,看有没有把数据写进去就行
注意:看上面的配置是把日志文件分成了三个索引存入,在输入日志之前要提前在es里面创建好这三个索引的,这样filebeat才能够成功将日志输入到es中。
121.196.217.190:5601
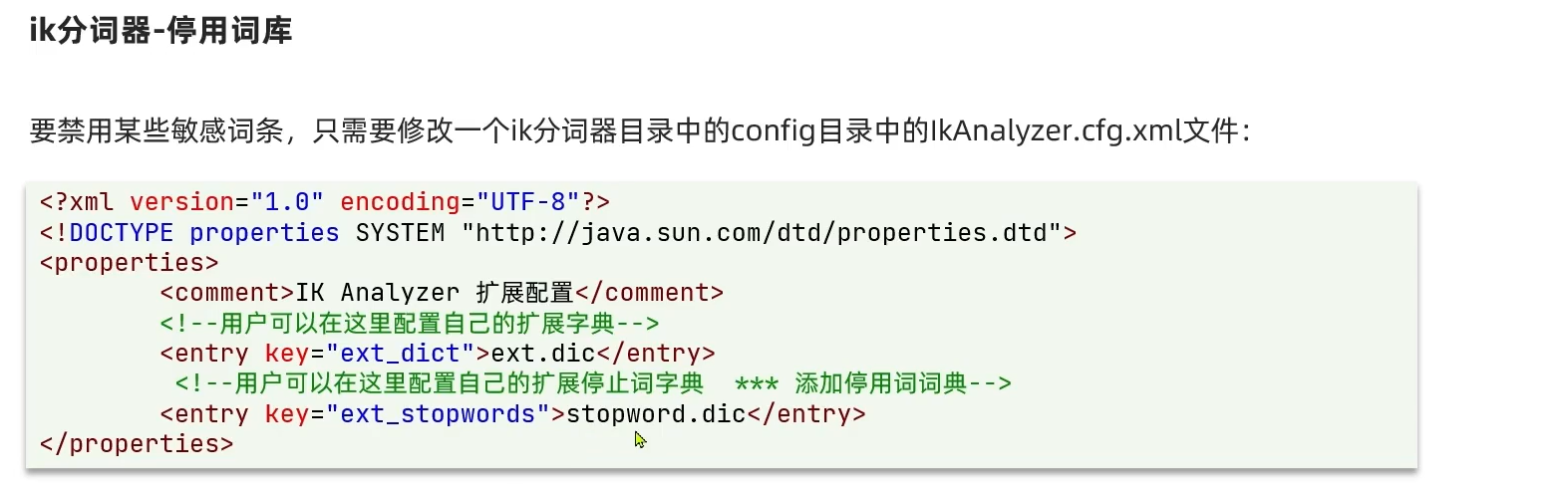
ik安装
-
下载 IK 分词器插件:(很麻烦且速度慢,不建议)
你可以在本地下载与你的 Elasticsearch 版本对应的 IK 分词器插件文件(.zip格式)。可以在 IK Analyzer 的 GitHub releases 页面 中找到对应版本。 -
创建本地目录:
假设你已经下载了 IK 插件压缩包(例如elasticsearch-analysis-ik-7.12.1.zip),将其解压缩后命名ik放在一个本地目录中。例如,将其放在/www/plugins目录。此时因为之前就已经启动了es了,此时需要新添加一个容器卷,所以要把之前的给删掉
docker rm -f es
之后去linux的elk目录添加一个plugins的文件夹,等会把它挂载到docker里面
然后添加这个容器卷重新运行容器
-
使用 Docker 启动 Elasticsearch 挂载插件:
在启动 Elasticsearch Docker 容器时,可以将本地的插件目录挂载到容器中的plugins目录下。以下是一个示例命令:前面是自己的目录路径:后面是不用改的是容器内的路径
docker run -d --name es \ --net elk \ -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ --privileged=true \ -v $PWD/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v $PWD/elasticsearch/data/:/usr/share/elasticsearch/data \ -v $PWD/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ elasticsearch:7.12.1docker run -d --name your_elasticsearch_container \ -v /path/to/your/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /path/to/your/data:/usr/share/elasticsearch/data \ -v /path/to/your/plugins:/usr/share/elasticsearch/plugins \ -e "discovery.type=single-node" \ docker.elastic.co/elasticsearch/elasticsearch:7.10.1确保将命令中的版本号和路径替换为你实际使用的。
之后就进入容器后测试一下是否加载(不行的话可以再重启一下:
docker rm -f es) -
确认插件是否加载:
启动容器后,你可以进入容器内部,查看插件是否成功加载。执行以下命令:docker exec -it your_elasticsearch_container /bin/bash ./bin/elasticsearch-plugin list如果
ik显示在列表中,那么你就成功安装了 IK 分词器。 -
验证功能:
启动 Es 后,可以在 Kibana 或使用 curl 来测试 IK 分词器是否正常工作。例如:POST /_analyze { "analyzer": "ik_max_word", "text": "中文分词器" }
如果一切顺利,你应该能够在 Docker 中通过挂载方式成功安装并使用 IK 分词器。这样做的好处是避免了网络问题导致的插件下载失败。
你会在结果中看到是中文、分词、器 也就是分成了三个词
如果使用的是默认的分词器就会分成中、文、分、词、器五个词了。
ik分词器中的词汇是可以修改的打开挂载的容器卷所在的ik文件夹就可以找到。