我自己的原文哦~ https://blog.51cto.com/whaosoft/11491137
#BEVWorld
BEV潜在空间构建多模态世界模型,全面理解自动驾驶~一、引言
世界模型建模了有关环境的知识,其可以通过给定的条件对未来进行合理的想象。未来想象要求世界模型具有物理规律的理解能力以及零样本的探索能力,使得其在自动驾驶领域有着广泛的应用前景,比如:
- 长尾数据生成:生成鬼探头、前方车辆遗撒等稀缺数据,并通过条件拓展不同天气、光照等环境下的数据。
- 闭环仿真测试:自动驾驶模型的planning结果作为世界模型未来预测的条件,产出控车后的数据进行闭环测试。
- 对抗样本:对抗样本是自动驾驶模型的一个安全隐患,利用世界模型,采用同一场景变换condition的方式或者黑盒攻击方式,拿到模型失效的且逼真的样本,用于提升自动驾驶模型的安全性。
- foundation model:世界模型通常采用自监督的训练模式,这种方式可以利用大量的无标注数据进行训练,从而可以作为感知决策模型的foundation model来提升自动驾驶模型的泛化能力。
今天自动驾驶之心为大家分享百度最新开源的工作《BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space》中,作者提出了一种创新方法,通过统一的鸟瞰图(Bird's Eye View, BEV)潜在空间整合多模态传感器输入,进而构建世界模型。BEV的空间表达可以便捷地对齐多模态数据,提升多模态数据的生成一致性。同时,BEV表征可以自然地与端到端自动驾驶模型相结合,作为其辅助任务或预训练模型使用。本文将为大家详细解读这篇论文的核心思想、方法实现及其实验结果。代码即将开源https://github.com/zympsyche/BevWorld。
二、方法概述
BEVWorld主要由两部分组成:多模态tokenizer(Multi-modal Tokenizer)和潜在BEV序列扩散模型(Latent BEV Sequence Diffusion Model)。
2.1 多模态tokenizer
多模态tokenizer的核心功能是将原始多模态传感器数据压缩成一个统一的BEV潜在空间。具体实现步骤如下:

- BEV编码器网络:采用Swin-Transformer作为图像骨干网络,提取多视图图像特征;将点云分割成BEV空间上的支柱(Pillars),并使用Swin-Transformer作为LiDAR骨干网络,提取LiDAR BEV特征。之后,利用基于可变形注意力的机制融合LiDAR BEV特征和图像特征。
- BEV解码器网络:由于直接从BEV特征恢复图像和LiDAR存在高度信息缺失问题,BEV解码器首先将BEV标记转换为3D体素特征,然后使用基于体素的NeRF渲染技术恢复多视图图像和LiDAR点云。
- 多模态渲染网络:分为图像重建网络和LiDAR重建网络。图像重建通过沿射线路径采样点并聚合特征描述符,最后通过CNN解码器生成RGB图像。LiDAR重建则通过计算采样点的期望深度来模拟LiDAR观测。
2.2 潜在BEV序列扩散模型
潜在BEV序列扩散模型旨在预测未来帧的图像和点云,避免自回归方法的累积误差问题。具体实现步骤如下:

- 模型结构:采用基于空间-时间变换器的扩散方法,将顺序的噪声BEV标记转换为基于动作条件的干净未来BEV预测。
- 训练过程:以历史BEV标记和当前BEV标记为条件,学习添加到未来BEV标记中的噪声。
- 测试过程:使用DDIM调度器从纯噪声中恢复未来BEV标记,并通过多模态tokenizer的解码器渲染出未来的多传感器数据。
三、实验与结果3.1 数据集
实验在nuScenes和Carla两个数据集上进行:
- nuScenes:包含多视图图像和LiDAR扫描的多模态自动驾驶数据集,包含700个训练视频和150个验证视频。
- Carla:开源自动驾驶模拟器,包含多种天气和城镇环境,实验中收集了300万帧数据进行训练。
3.2 多模态tokenizer评估
通过消融研究评估不同设计决策对多模态tokenizer的影响:

- 不同模态的影响:结合LiDAR和多视图相机模态获得最佳重建性能。
- 渲染方法的影响:基于射线的采样方法在多视图重建中表现更好。
3.3 tokenizer下游任务验证
在3D检测和运动预测任务上验证BEVWorld的有效性:

- 3D检测:在nuScenes 3D检测基准上,使用tokenizer编码器作为预训练模型显著提升性能。
- 运动预测:在检测头基础上添加运动预测头,实现准确轨迹预测。
3.4 潜在BEV序列扩散模型评估


介绍了潜在BEV序列扩散模型的训练细节,并与现有方法比较:
- LiDAR预测质量:在nuScenes和Carla数据集上取得了与现有方法相当或更好的结果。
- 视频生成质量:在无额外条件情况下取得与使用手动标注条件方法相当或更好的结果。
BevWorld 还可以根据Action指令进行相应的生成控制。

四、结论与展望
本文提出的BEVWorld框架通过统一的BEV潜在空间构建多模态世界模型,能够在自监督学习范式下高效处理未标注多模态传感器数据,实现对驾驶环境的全面理解。实验结果表明,BEVWorld在下游自动驾驶任务中表现出色,并在多模态未来预测中取得满意结果。
然而,该工作仍存在一些局限性,如扩散模型推断过程缓慢且计算成本高,动态对象生成图像模糊等。未来研究可探索一步扩散方法提高效率,并引入专门针对动态对象的模块提升生成质量。
总之,BEVWorld为自动驾驶领域中的世界模型构建提供了新视角和方法,有望促进自动驾驶技术的进一步发展。
#DINO-Tracker
跟踪一切目标!DINO-Tracker成为单目跟踪里程碑
本文的DINO-tracker框架能够无视遮挡,实现对物体的长距离跟踪,突破了之前技术的局限,入选了ECCV24。
论文地址:
https://dino-tracker.github.io/assets/dino_tracker.pdf
开源地址:https://dino-tracker.github.io/
01 问题引入
近年来,在视频中建立密集点对应关系这一研究取得了巨大进展。在短期的密集运动估计方面,比如光流估计,研究界的关注焦点是监督学习——设计强大的前馈模型,并在各种合成数据集上进行训练,利用精确的监督信息。最近,这一趋势扩展到了视频中的长期点跟踪领域。随着新架构(如Transformers)和提供长期轨迹监督的新合成数据集的出现,各种监督跟踪器被开发出来,展示了令人印象深刻的成果。
然而,精准的跟踪视频中每一个运动点对此类基于监督学习的方法而言是一个极大的挑战:
首先,用于点跟踪的合成数据集通常包含在不现实配置中的移动物体,相对于自然视频中运动和物体的广泛分布,这些数据集在多样性和规模上受到限制;
此外,现有模型在跨越整个视频时空范围内聚合信息的能力仍然有限——这一点在长时间遮挡(例如在物体被遮挡之前和之后正确匹配一个点)中尤其重要。
为了应对这些挑战,Omnimotion(也就是23年的Tracking Everything)提出了一种测试的优化框架,通过预计算的光流和视频重建作为监督,将跟踪提升到3D层面。这种方法通过优化给定测试视频上的跟踪器,本质上一次性解决了所有视频像素的运动问题。然而,Omnimotion存在一个致命缺点:它严重依赖预计算的光流和单个视频中的信息,没有利用关于视觉世界的外部知识和先验。
在本文中,作者提出了一种新方法,训练与大量数据的学习结合起来,取长补短,形成一个针对特定视频特征提取匹配再到追踪优化框架,该框架结合由广泛的无标签图像训练的外部图像模型学习到的强大特征表示。受到最近自监督学习巨大进展的启发,作者的框架利用了预训练的DINOv2模型——一个使用大量自然图像进行预训练的视觉Transformers。DINO的特征提取已经被证明能够捕捉细粒度的语义信息,并被用于各种视觉任务,如分割和语义对应。
本项工作是首次将基于DINO提取的特征用于密集跟踪的研究。 作者展示了使用原始DINO特征匹配可以作为一个强大的跟踪baseline,但这些特征本身不足以支持亚像素精度的跟踪。因此,作者的框架同时调整DINO的特征以适应测试视频中的运动观察,同时训练一个直接利用这些精炼特征的跟踪器。为此,作者设计了一个新的目标函数,通过在精炼特征空间中培养稳健的语义特征级别对应关系,超越了光流监督实现的效果。

▲图1|效果演示©️【深蓝AI】编译
本文的核心贡献包括:
首次利用预训练的DINO特征进行点跟踪;
提出了第一个结合测试时训练和外部先验的跟踪方法;
在长时间,长遮挡的跟踪方面显著提升了性能。
02 实现细节

▲图2|全文方法总览©️【深蓝AI】编译
结合图2,可以理解全文方法的pipeline:
对于给定的输入视频序列,此方法的目标是训练一个跟踪器 ,该跟踪器接受查询点作为输入,并输出一组位置估计,这个过程很容易理解,就是特征提取+匹配+预测,但是这里的特征提取采用了预训练的 DINOv2-ViT 模型进行特征提取。如果各位对DINO还不太了解,请详细阅读下面这段介绍——
我们可以将DINO(Distillation with No Labels)理解为一种无标签的学习训练方法,它广泛应用于计算机视觉领域,尤其是在自监督学习和特征表示学习中。DINO模型的一个显著特点是利用Vision Transformer(ViT)架构进行训练,无需人工标注数据,通过自监督的方式学习图像的语义特征,DINO有三个最显著的特点:
●无需标签数据:通过自监督学习方法,DINO 能够有效减少对大量人工标注数据的依赖,从而降低数据准备的成本和时间;
●高质量特征表示:由于使用了 Vision Transformer 和对比学习策略,DINO 可以学习到更加语义丰富和泛化能力强的特征表示;
●灵活适应多种任务:DINO 所学习到的特征表示不仅适用于图像分类,还可以通过微调,适用于其他各种视觉任务,如目标检测和语义分割等。
DINO在本文中的应用:DINO 的预训练特征为此方法的框架提供了初始的语义和局部表示,但缺乏准确的长时间跟踪所需的时间一致性和细粒度定位。因此,此方法训练了 Delta-DINO,这是一种特征提取器,用于预测预训练 DINO 特征的残差。
此方法的目标是优化这些特征,使它们可以作为“轨迹嵌入”,即沿着轨迹采样的特征应该收敛到一个独特的表示,同时保留原始的 DINO 先验。这个过程实际上解决的是长距离的跟踪问题,以往的方法往往不会对未来的位置进行预测,而是直接对下一帧图像中相同的特征点进行匹配,这样一旦遮挡物出现,特征点之间的匹配失败,就会跟丢目标,而此方法的预测能力,能够在遮挡物出现的时候通过将预测的点进行匹配,从而保证跟踪的连续性。
2.1 跟踪过程
DINO-Tracker的追踪过程可以分为三个阶段:特征提取+特征匹配+轨迹预测+全局一致优化。
关于特征提取,前文已经提到此方法主要采用预训练的DINO框架进行特征点的提取,这一部分主要利用了DINO框架的灵活性和高质量的特征表达,提取后的特征会形成一个特征图,用于后续的特征匹配。
在特征匹配阶段,比起传统的在特征点图中进行对应匹配,本文还提出了一个额外的匹配方式,就是用DINO提取的特征对应关系用于补充训练数据,提供额外的监督。通过识别“最佳配对点”提取可靠的匹配关系,其中每个点在一帧中的最近邻匹配第二帧中的最近邻。在训练期间,精炼特征改进其表示并发现新的可靠对应关系,形成持续更新的精炼最佳配对点集合,实现高质量的特征点匹配,这样得到的匹配关系更加精准,也为后续的长距离跟踪和障碍物遮挡打下了基础。
轨迹预测首先如前文所述,会训练一个Delta-DINO来进行初步的新特征点预测,也就是预测下一帧中特征点可能出现的位置,然而这个预测往往会存在一定的误差,此方法采自监督优化策略来优化这个误差。具体而言,就是使用从测试视频自动提取的监督信号来匹配沿轨迹的预测点。这些信号来自光流和DINO特征的对应关系。光流提供帧间精确的位移信息,通过链接这些位移创建短期轨迹。在预处理过程中,此方法通过计算出所有循环一致的光流对应关系,为短轨迹提供高质量的监督。笔者通俗地总结一下,轨迹预测分为两个阶段,第一阶段中采用Delta-DINO预测下一帧出现的特征点,在第二阶段中采用光流法计算当前特征点的位移信息,结合这个计算出来的位移信息以及预测得到的特征点信息进行联合优化,最终确定预测的轨迹,实际上是一个“双保险”的过程,光流发充分利用了已知的信息,Delta-DINO则使用了预训练DINO模型的强大先验。
通过特征提取+特征匹配,DINO-Tracker实现了每一帧中特征点的准确识别和配准,通过特征匹配+轨迹预测,实现了这一帧和下一帧的特征点准确跟踪,这个过程不断迭代,这就是DINO-Tracker能够实现长距离跟踪的核心。
2.2 遮挡处理
此方法还有一个很强的能力,就是对于遮挡的处理,图3很好地说明了DINO-Tracker是如何在遮挡物出现的时候仍然保持鲁棒跟踪的原理。要处理遮挡场景,首先要有能力判断遮挡的出现,这一点在本文中通过测量轨迹位移差实现,如图3所示,作者选择K1和K2作为锚点,计算追踪点X0是否存在遮挡关系,从图中来看,X0处的轨迹和K1与K2处的轨迹有明显的位移差异,当这种位移差异出现的时候,就会判断在X0处出现了遮挡。这个计算的原理十分简单,目的就是为了提升速度!
想必各位都能发现,本文并不是实时处理遮挡关系的,而是通过当前帧与前两帧来计算遮挡关系,如果判断出现遮挡,就会及时优化修正前一帧中错误的追踪,但是由于这样的计算方式速度很快,这些都发生在电光火石之间,因此对于全局的追踪速度没有太大的影响。
当遮挡关系被计算得到之后,轨迹的预测就会派上用场了,前文中我们提到了对于轨迹预测的“双保险”,即使用Delta-DINO预测下一帧的特征点位置+使用光流直接计算特征点位置共同进行预测,然而遮挡的关系出现会导致光流法失效,因此这个时候会赋予Delta-DINO更多的权重,从而保持跟踪,当物体穿过遮挡物之后,光流又会继续上线,帮助修正全局的跟踪轨迹,通过这个过程实现了对于遮挡关系的处理。
很多人对此都会产生一个疑问:
如果遮挡关系出现得太久,一直依靠Delta-DINO的预测,是否会出现轨迹上的偏差?
答案是:一定会出现的。
在“透视”技术被研究出来之前,理论上来说没有太好的方法能够处理长时间的遮挡关系,但本文方法对于短时间能出现的遮挡关系的处理,已经堪称“完美”,能够应对大多数场景了!

▲图3|遮挡处理示意图©️【深蓝AI】编译
03 实验效果
作者通过数值实验和可视化实验证明了本文方法的有效性,首先来看数值实验。

▲图4|数值实验结果©️【深蓝AI】编译
从图4中可以看到,作者在大部分的数据集中都超过了SOTA方法,并且这些SOTA方法大部分都不具备对于遮挡关系的处理能力。读者可能会觉得似乎作者的指标没有超出SOTA方法太多,我们需要注意的是,这里计算的是像素之间的距离,而由于投影关系,像素上个位数的差异经过投影变换到真实世界中,往往就会被放大到几米甚至十几米(根据不同的投影尺度),因此在这个领域,即便是很小的数值增长,也是很大的提升。
接下来是可视化实验,这里作者主要体现了本文方法对于遮挡和长距离跟踪的能力。

▲图5|可视化对比实验©️【深蓝AI】编译
从实验结果上来看,本文方法在遮挡出现的时候依旧能够实现鲁棒的跟踪,而对比方法基本上都会出现跟丢或者跟踪出错的问题(从图5左图看出),图五的右图主要体现的是长距离跟踪,图中的自行车选手在公路上“飙车”,速度很快,对比方法出现了不同程度的跟丢情况,而本文方法则死死“咬住”了目标,由此体现出本文方法的高性能。

▲图6|DINO特征点选取可视化©️【深蓝AI】编译
图6则可以看到DINO特征点提取的优势,可以从图中看到DINO提取的特征点十分均匀地分布在跟踪物体的各个关键运动位置(关节,轮廓边缘)这些部分是物体运动的重要追踪位置,而其他对比方法则无法实现对这些关键位置的特征提取和鲁棒的追踪。
04 总结
本文提出了DINO-Tracker的追踪框架,能够很好地处理追踪过程中出现的遮挡关系以及长距离的汇总问题。通过利用DINO模型强大的先验知识,实现了对于任意物体的鲁棒追踪。DINO-Tracker不仅在短期内表现出色,还能在较长时间跨度内保持高精度的追踪能力,这主要得益于其特征点轨迹预测方法能够很好地忽略短时间内的遮挡,解决了追踪任务中的一个关键难题。
#MapLocNet
速度和精度都提升!MapLocNet:从粗到细视觉重定位
鲁棒定位是自动驾驶的基石,尤其是在GPS信号受多径误差影响的挑战性城市环境中。传统的定位方法依赖于由精确标注的地标组成的高精度(HD)地图。然而,构建高精度地图既昂贵又难以扩展。鉴于这些局限性,利用导航地图已成为一种有前景的低成本定位替代方案。当前基于导航地图的方法可以实现高精度定位,但其复杂的匹配策略导致不可接受的推理延迟,无法满足实时需求。为了克服这些局限性,这里提出了一种新颖的基于Transformer的重定位方法。受图像配准的启发,方法在导航地图和视觉鸟瞰图特征之间进行从粗到细的神经特征配准。在nuScenes和Argoverse数据集上,方法显著优于当前最先进的OrienterNet,在单视图和环视输入设置下,定位精度分别提高了近10%/20%,帧率分别提高了30/16 FPS。本研究为自动驾驶提供了一种无需高精度地图的定位方法,在挑战性驾驶环境中提供了经济高效、可靠且可扩展的性能。天皓智联 whaosoft开发板商城测试设备www.143ai.com
行业背景介绍
随着过去十年自动驾驶技术的最新发展,鲁棒定位起到了至关重要的作用。自动驾驶车辆和人工驾驶导航都高度依赖于全球导航卫星系统(GNSS)进行室外定位,但这些信号在城市区域中容易受到干扰。周围基础设施产生的多径传播误差以及建筑物、隧道、桥梁等造成的视线遮挡,会严重影响GPS定位的准确性。如果没有有效的全局定位源,位置会迅速漂移。
在GPS信号不可用的情况下,需要额外的主动定位方法。通过利用先前构建的地图,如3D点云和独特的视觉特征,可以使用基于激光雷达的和基于视觉的SLAM方法进行定位。然而,这种基于点的先验地图非常消耗内存,不能用于自动驾驶任务中的大型环境。自动驾驶在很大程度上依赖于包含精确地理参考的地标和几何形状的高精度(HD)地图,特别是在GPS信号不可用的区域。然而,制作和维护这些地图的高昂成本严重限制了它们在不同环境和地理位置的可扩展性。因此,对HD地图的依赖已成为阻碍自动驾驶技术更广泛应用的主要瓶颈。随着感知算法的发展,如HDMapNet和MapTR等方法已经实现了在线HD地图生成,即使在定位精度较低的情况下,也能实现自动驾驶。
另一方面,我们从生物学中得到了启示,即人类驾驶员仅凭导航地图就能识别位置。通过将视觉观察与地图信息相关联,人类可以在复杂的城市环境中大致确定自己的位置。人类从周围环境中提取出道路结构、建筑轮廓和地标等高级语义信息,并利用认知能力将这些语义信息与导航地图进行匹配。目前,在机器人和增强现实(AR)领域,已经提出了类似的方法来模拟人类定位方法。然而,这些方法往往采用复杂的匹配策略进行定位,导致无法实现实时推理。因此,它们无法应用于自动驾驶系统。为了解决上述挑战,我们提出了MapLocNet,这是一种在满足实时性能要求的同时实现高精度定位的新方法。我们将环视图像编码到鸟瞰图(BEV)空间中,并使用U-Net处理导航地图。关键的创新之处在于采用了基于Transformer的分层特征配准方法,该方法有效地将视觉BEV特征与地图特征进行对齐,从而实现高精度定位。
本文提出的方法在定位精度和推理延迟方面都超越了当前的最先进(SOTA)方法。总体而言,贡献如下:
• 提出了MapLocNet,通过融合环视图像和导航地图实现了高精度定位,特别是在GPS信号不可用且定位漂移显著的区域。天皓智联 whao开发板商城测试设备
• 引入了一种分层的由粗到细的特征配准策略,用于对齐鸟瞰图(BEV)和地图特征,与现有方法相比,实现了更高的定位精度和推理速度。
• 开发了一种新颖的训练准则,利用感知任务作为姿态预测的辅助目标。MapLocNet在nuScenes和Argoverse数据集上均达到了SOTA定位精度。
再次强调,这次研究提出了一种无需高清地图(HD-map-free)、可靠且类似于人类的定位方法,与现有方法相比,实现了更高的定位精度。
相关工作
构建高清地图成本高昂,因此近期的研究重点转向了基于轻量化导航地图的定位。Panphattarasap等人提出了一种新颖的基于图像的城市环境定位方法,该方法通过图像与二维地图之间的语义匹配来实现。Samano等人设计了一种新颖的方法,该方法通过学习低维嵌入空间来在二维导航地图上对全景图像进行地理定位。Zhou等人提出了一种基于2.5D地图的跨视图定位方法,该方法融合了二维图像特征和2.5D地图,以增强位置嵌入的区分度。OrienterNet提出了一种深度神经网络,该网络通过将神经鸟瞰图(BEV)与OpenStreetMap (OSM)中的可用地图进行匹配来估计查询图像的姿态,并实现了高精度定位。其他方法实现了跨视图地理定位,即将车辆上的摄像头图像与航拍图像或卫星图像进行匹配,以确定车辆的姿态。受先前研究的启发,我们提出了一种将视觉环境感知与导航地图相结合的定位方法。
将图像特征转换为鸟瞰图(BEV)网格的方法有很多,包括几何方法和基于学习的方法。Cam2BEV和VectorMapNet使用了几何方法,该方法利用逆透视映射(IPM)通过平面假设将图像特征转换为BEV空间。HDMapNet提出了一种新颖的view transformer,该转换器结合了神经特征提取和几何投影来获取BEV特征。LSS、BEVDepth、BEVDet通过学习图像特征的深度分布来将每个像素提升到三维空间。然后,它们使用相机的外部和内部参数将所有视锥体投影到BEV上。GKT提出了一种高效且鲁棒的二维到BEV的表示学习方法,该方法利用几何先验来引导转换器关注具有区分性的区域,并展开内核特征以获得BEV特征。BEVFormer利用预定义的网格状BEV查询来查找时空空间,并从图像中聚合时空信息,在三维目标检测方面取得了最先进(SOTA)的性能。为了平衡精度和效率,我们基于LSS架构设计了我们的BEV模块。
图像配准旨在找到一幅图像中的像素与另一幅图像中像素之间的空间映射,这一技术在医学成像和机器人技术研究中得到了广泛应用。传统的基于特征的方法利用从图像中检测到的关键点和其描述符来匹配不同的图像。最近,出现了基于卷积神经网络(CNN)和transformer的图像配准方法,以加快配准速度和提高配准精度。DIRNet提出了一种用于可变形图像配准的深度学习网络。该网络包括一个卷积神经网络(ConvNet)回归器、一个空间变换器和一个重采样器。C2F-ViT是一种基于学习的3D仿射医学图像配准方法,它利用自注意力机制的全局连接性和卷积前馈层的局部性,将全局方向和空间关系稳健地编码为一组几何变换参数。
最近的端到端(E2E)方法引入了有效的架构,这些架构直接从传感器输入和先验地图中估计自我姿态,从而避免了复杂的几何计算和手工制定的规则。PixLoc使用可微优化方法设计了一个端到端神经网络,通过将深度特征与参考三维模型对齐来估计图像的姿态。I2D-Loc提出了一种基于局部图像-激光雷达深度配准的有效网络,用于相机定位,并使用BPnP模块计算后端姿态估计的梯度,以进行端到端训练。BEV-Locator设计了一种新颖的端到端架构,用于从多视图图像和矢量化的全局地图中进行视觉语义定位。基于跨模态transformer结构,它解决了语义地图元素与相机图像之间跨模态匹配的关键挑战。EgoVM构建了一个端到端的定位网络,该网络使用轻量级矢量地图,并实现了厘米级定位精度。受上述工作的启发,我们的方法构建了一个基于transformer的端到端定位网络,以实现精确定位。
MapLocNet的总体架构
MapLocNet的总体架构包含三个主要模块:BEV模块、Map U-Net和神经定位模块。我们的方法采用了一种从粗到细的特征配准策略,从BEV解码器和Map解码器中提取多尺度特征,以执行分层特征对齐。在初始的粗配准阶段之后,该阶段会得出姿态偏移的粗略估计,对高分辨率的BEV特征应用空间变换,以促进后续的细配准过程。将两个阶段的预测结果相结合,得出最终的姿态偏移估计结果。
方法介绍
1)地图构建
由于我们的方法结合了导航地图输入和BEV语义分割标签,因此需要对不同的地图数据源进行适当的处理和融合:
- 地图光栅化:为了便于访问和全面覆盖,我们利用开放街道地图(OSM)作为导航地图数据源,如图3a所示。OSM使用多边形区域表示建筑物,使用多段线表示道路,使用节点表示交通信号灯和其他兴趣点(PoI)。如图3b所示,仅保留如建筑物、道路和PoI(交通信号灯、电线杆)等必要元素,它们的空间布局为定位提供了关键的几何约束。对于每个查询,我们检索一个以初始车辆定位坐标为中心的栅格化导航地图块。
- 分割标签:BEV语义分割标签来自两个来源。可行驶区域标签来自高精度地图数据,如nuScenes。作为补充来源,建筑物和PoI(兴趣点)标签来自导航地图,如OSM。
- 2)BEV模块
该模块旨在提取图像特征并将其投影到BEV空间以获得BEV特征。视觉输入可以是单目前视图像或多个环视图像。使用的图像越多,感知范围越广,从而提高定位精度。环视图像的一个示例如图3c所示。我们选择简单而有效的LSS架构作为主干。采用EfficientNet作为透视图(PV)编码器来提取图像特征。按照LSS程序,我们结合外部和内部参数将投影到大小为的BEV空间。我们认为纵向观测范围比横向范围宽,因此设置空间维度使得。在BEV解码器模块的不同上采样阶段,我们提取低分辨率、高通道数的粗特征 和高分辨率、低通道数的细特征,这些特征用于后续的两阶段粗到细特征配准。通过BEV语义分割辅助任务来监督该模块,这可以更好地约束模型的学习目标,同时有效提高定位精度。
3)Map U-Net
我们采用U-Net架构从光栅化地图中提取特征。为了缩小地图特征与视觉BEV特征之间的模态差距,创新性地为这个模块引入了一个BEV分割辅助任务。使用VGG-16作为编码地图特征的主干网络。与BEV模块类似,在地图解码器的不同阶段,我们也提取粗级和细级的地图特征 和 ,用于后续的分层特征配准。这里存在一个关系,即且,这有助于特征融合。我们使用与BEV模块相同的BEV分割标签来监督这个模块,从而约束两种特征之间的差异。
4)Neural Localization Module
该模块负责地图和视觉特征的融合以及姿态偏移的解码,是MapLocNet的核心模块。我们为姿态解码器设计了多种架构,并通过广泛的实验,确定了粗到细的特征配准作为最终的最优解决方案。
我们将神经定位表述为特征配准任务。受C2F-ViT的启发,这里采用Transformer编码器以粗到细的方式对融合的视觉BEV特征和地图特征进行自注意力计算。粗配准和细配准模块共享相同的架构。由于BEV特征和地图特征的宽度不同,我们在宽度维度上对BEV特征进行零填充,以匹配地图特征的宽度。考虑到计算消耗,我们在高度和宽度维度上将BEV和地图特征下采样4倍。遵循C2F-ViT的方法,我们还采用7x7的卷积核沿通道维度对它们进行融合,并将融合后的特征展平为顺序标记,以便对姿态隐藏特征进行自注意力编码。
由于这是一项与姿态相关的任务,位置编码至关重要。我们尝试了学习和固定位置编码两种方法,最终选择了正弦位置编码。然而,我们将位置编码坐标的原点移动到了特征图的中心。位置编码通过逐元素相加的方式注入到融合后的特征中。在每个神经定位模块中,我们设计了N个重复的Transformer编码器层,在实际应用中我们设置N=3。随后是一个由3层多层感知机(MLP)组成的姿态解码头。在粗略特征配准阶段估计出的3自由度姿态偏移量ξˆc被应用于精细的鸟瞰图(BEV)特征。随后,经过空间变换的BEV特征以及精细地图特征进行精细特征配准,以进一步缩小与真实姿态的差距,并获得ξˆf。两个阶段的累积输出共同作为最终的姿态偏移量估计。
5)损失函数
实验对比
数据集:为了确保全面评估,使用两个自动驾驶数据集nuScenes 和Argoverse 对我们提出的方法进行了训练和验证。nuScenes数据集包含在美国波士顿和新加坡采集的1000个驾驶序列。使用了nuScenes的默认训练集,其中包含850个序列。nuScenes验证集包含150个序列,用作我们的评估基准。Argoverse数据集包含在美国迈阿密和匹兹堡录制的113个场景,其中65个场景分配给训练集,24个场景分配给验证集。为了解决nuScenes和Argoverse数据集中缺少导航地图数据的问题,通过从开放街道地图(OSM)获取相应地理区域的导航地图来丰富我们的数据集。按照BLOSBEV 中概述的方法,通过定位坐标变换将导航地图与高清地图进行对齐。图3展示了导航地图信息局部部分与nuScenes数据集中同一位置的帧的对齐情况。
网络设置:除非另有说明,MapLocNet采用6张环视图像作为视觉输入。使用EfficientNet-B0 架构作为图像骨干网络,并将所有输入图像的分辨率调整为128×352。在训练阶段,应用必要的图像数据增强技术来提高模型的鲁棒性,包括随机裁剪、随机翻转和随机丢弃一个camera输入。在鸟瞰图(BEV)空间中,自车的感知范围被定义为沿纵向轴为[−64m, 64m],沿横向轴为[−32m, 32m],两者每像素的分辨率均为0.5米(mpp)。深度分布的区间为[4m, 60m],分辨率为1mpp。对于每一帧,从栅格化导航地图中以自车位置为中心截取一个128m×128m的区域,分辨率为0.5mpp。
模拟3自由度(3-DoF)GPS误差:首先将栅格化导航地图的姿态和比例与nuScenes和Argoverse数据集中的高清地图对齐。在训练过程中,从栅格化导航地图中截取一个以自车位置为中心的区域。为了模拟GPS误差,我们对这个区域应用随机旋转θ ∈ [−30°, 30°]和随机平移t ∈ [−30m, 30m]。然后,裁剪出中央的128m×128m区域,作为MapLocNet的偏差地图输入。
训练细节:使用8块NVIDIA V100 GPU对模型进行200个周期的训练,大约需要48小时才能收敛。模型使用AdamW优化器进行优化,权重衰减为1e-7,批量大小为8,初始学习率为1e-4。使用余弦退火调度器在训练过程中调整学习率。
结果对比
1)对比方法
a) OrienterNet:在nuScenes和Argoverse数据集上使用了OrienterNet的官方实现进行训练和评估。为了确保公平比较,考虑到OrienterNet仅限于单目输入,我们也使用单摄像头输入对我们的方法进行了一系列并行实验。
b) U-BEV:由于U-BEV的任务与我们的相似,直接引用了其论文中提供的数据。值得注意的是,其定位结果不包括方向预测。因此,初始定位可能缺乏航向角误差扰动,这在某种程度上简化了任务。考虑到它使用了6张环视图像,将其归类为6摄像头配置的参考组。
c) MapLocNet DETR:受到DETR中解码器设计的启发,创造性地将姿态偏移作为查询Q,以从视觉鸟瞰图(BEV)特征和地图特征中检索融合特征。DETR解码器处理的特征随后通过相同的3层多层感知机(MLP)姿态头进行姿态解码。
d) MapLocNet CA:受LoFTR和GeoTransformer的启发,使用交叉注意力(CA)模块设计了我们的神经网络定位模块。将视觉特征作为查询Q,将地图特征作为键K和值V,从而实现跨域注意力计算。然后,由相同的姿态头对得到的特征进行解码,以进行姿态估计。
e) MapLocNet 一阶段版:我们的方法是分层的,这在某种程度上影响了推理速度。本文想探究在计算资源有限的情况下,方法是否仅通过一个阶段,即粗略特征配准,就能满足使用要求。因此,在这里测试了MapLocNet的一阶段版本。为了最大限度地降低计算复杂度,在一阶段实验中使用了粗略特征,而不是精细特征。与分层版本唯一的区别是,省略了精细特征配准,并直接将初始粗略阶段的输出作为最终结果。我们期望一阶段版本能在定位精度和推理速度之间取得平衡,而由粗到精的版本则能提高定位精度的上限。
2)定位结果
a) nuScenes:为简化表述,将一阶段方法和由粗到精的方法统称为特征配准(FR)架构。如表I所示,在实验中,使用6个camera的由粗到精的FR架构实现了最佳的定位性能。我们的一阶段FR架构表现出了最高的效率,达到了每秒24.4帧(FPS)。在单目实验组中,将FR架构的定位性能与OrienterNet进行了比较。提出的方法在计算效率和准确性方面都超过了OrienterNet,尤其是在速度上,比OrienterNet快了约30 FPS。
b) Argoverse:为了进一步展示我们模型的能力,我们在Argoverse[37]数据集上进行了实验。利用从nuScenes数据集获得的预训练权重,我们在Argoverse数据集上对模型进行了微调。我们还采用了相同的训练策略,将我们的方法与OrienterNet进行了比较。值得注意的是,如表IV所示,我们的模型在单目摄像头和环视摄像头配置下都表现出了卓越的定位性能。在所有输入设置下,我们的模型在准确性方面都显著优于OrienterNet,这凸显了我们方法的稳健性和通用性。
3)结果可视化
为了直观地展示模型的性能,图4仅展示了第二阶段配准中使用的高分辨率、低通道数的鸟瞰图(BEV)特征和地图特征。由于初始粗略配准中使用的高维特征视觉复杂性较高,因此在此省略。实验发现,在夜间场景中,由于建筑物可见度降低,模型性能略有下降。尽管如此,该模型在白天和夜间条件下都表现出了稳健的定位能力。
4)消融实验
论文进行了全面的消融研究,以评估各种开放街道地图(OSM)元素组合和损失函数配置对模型性能的影响。
- 输入OSM元素:对三个关键地图元素进行了消融研究:车道、建筑物和节点(包括交通信号灯和标志)。考虑到它们在环境中的普遍性,依次从输入中移除了节点和建筑物。表II显示,这三个元素都对定位性能有积极影响。与节点相比,移除建筑物导致的性能下降更为显著,这表明建筑物对定位的影响更大。值得注意的是,仅使用车道,模型就保持了相当的性能,这表明车道在定位中起着至关重要的作用。我们认为,从鸟瞰图(BEV)的角度来看,学习复杂度从节点到建筑物再到车道依次降低,而它们在环境中的普遍性则依次增加。这种相关性与它们在定位性能中的重要性增加是一致的。
- 损失函数:本实验旨在探究辅助分割任务对定位性能的影响。这里引入了鸟瞰图(BEV)损失,用于指导视觉分支的特征学习,以及地图损失,该损失使用相同的语义标签来减少视觉分支和地图分支之间的特征模态差异。如表III所示,纳入视觉BEV分割损失监督可以显著提升模型的定位性能。我们认为,这种损失改善了模型对环境结构的理解,提供了更清晰的定位线索。在加入地图分割损失监督后,模型的定位性能得到了进一步提升。我们假设栅格化地图和视觉BEV表示之间存在模态差异。通过统一两个分支的语义监督,我们缩小了这种模态差异,从而提高了模型的定位能力。
#Sparse4Dv3
Sparse4Dv3的TensorRT部署调优指南~
本文分享主题:如何在个人工作站以及车载NVIDIA ORIN 上部署Sparse4Dv3端到端感知方案。Sparse4D是基于稀疏Transformer范式的高性能高效率的长时序融合的感知算法。截止2024年9月,该方案在nuscenes纯视觉榜单上以mAP=0.668排名位列第一:
图一:nuscenes纯视觉榜单
以下为算法的通用架构图[1]:
图二:基于时序融合稀疏Transformer范式算法算法架构
当前,我测试了该算法在多种数据集上的泛化效果,感觉确实还不错。基于此,我重构了源代码,主要工作:剔除了源代码对MMDetection3D和mmcv-full的依赖,这使得该算法更加轻量化,无论是训练、推理还是部署都变的更加友好。目前,该仓库测试下来,无论是在个人的工作站还是远程集群环境(这里主要测试了NVIDIA Ampere架构系列显卡、NVIDIA Volta架构系列显卡还有Hopper架构显卡),其安装简单无复杂依赖(如需升级,只要更新CUDA和torch相关组件版本即可),轻松完成大规模训练和推理任务。
其实对于大部分自动驾驶量产公司来说,当模型的算法方案确定后,数据的采集到标注爬坡是需要一定周期的,日常工作除了数据的处理和模型调优迭代外,大部分精力需要投入到模型的部署、模型的高性能推理和模型的车端C++代码开发,毕竟能上车才是王道。
本人在对Sparse4Dv3模型部署和C++代码开发过程中,感觉并不是一番风顺。因此,我想借这篇文章将个人踩过的所有坑和经验分享给大家,希望大家在使用过程中尽量少走弯路。号外号外,感兴趣的朋友可以clone我的GitHub Repo : SparseEnd2End。部署代码请大家关注仓库中的deploy文件夹,该代码目前已经开源。车端C++代码在持续更新填充中,请大家关注onboard文件夹。好记性,不如烂笔头,本文会长期更新,内容将会涉及后续的调优以及持续加速......
github.com/ThomasVonWu/SparseEnd2End
大家在使用该仓库过程中如果遇到什么问题也请分享给我,共同学习进步嘛。
在阅读本文之前,需具备以下基础知识和相关工具使用经验,这将方便大家快速理解本篇文章的核心内容(抱歉,时间有限,后续涉及基础工具的使用方法我就不详细展开了)。另外,本篇文章的部署方案无需依赖其他部署仓库,如:MMdeploy, etc:
- PyTorch模型导出ONNX中间格式的方法,熟悉可视化ONNX节点工具: netron的使用;
- 推理引擎 ONNX Runtime 和 TensorRT的安装及使用方法,包括:TensorRT python API 和 C++ API使用;
- 熟悉TensorRT 工具Polygraphy的python API使用方法和基本的命令行调用指令;
- 基本的CUDA编程知识:核函数的编写与启动,常用的内存模型:全局内存、共享内存,etc;
- Makefile编程语法,C++编译规则和nvcc 编译cuda程序规则;
通过这篇文章你将了解并学习到以下进阶知识:
- 模型转换完,如何确保数据流的无损传递以及推理结果的一致性验证方法,即:如何debug问题和校验结果准确性 (我想这是大家最关心的部分,毕竟网上大几百的课程也未必会详细的告诉大家这些方法);
- 如何在ONNX注册一个自定义算子?紧接着,如何将该自定义算子注册为TensorRT Plugin,最后你一定关心:如何将该自定义plugin加载到当前模型的engine中,并使用TensorRT python API完成python脚本推理链路和TesnsorRT C++ API完成车端推理链路;
好的,一切就绪,现在让我们愉快的开始吧~
Sparse4Dv3 Model Deployment Pipeline
本文配置的部署环境以及使用的工具版本,如下:
====================================================================================================================
|| Config Environment Below:
|| UBUNTU : 20.04
|| TensorRT LIB : /mnt/env/tensorrt/TensorRT-8.5.1.7/lib
|| TensorRT INC : /mnt/env/tensorrt/TensorRT-8.5.1.7/include
|| TensorRT BIN : /mnt/env/tensorrt/TensorRT-8.5.1.7/bin
|| CUDA_LIB : /usr/local/cuda-11.6/lib64
|| CUDA_ INC : /usr/local/cuda-11.6/include
|| CUDA_BIN : /usr/local/cuda-11.6/bin
|| CUDNN_LIB : /mnt/env/tensorrt/cudnn-linux-x86_64-8.6.0.163_cuda11-archive/lib
|| CUDASM : sm_86
|| PYTORCH : 1.13.0
|| ONNX : 1.14.1
|| ONNXRUNTIME : 1.15.0
|| ONNXSIM : 0.4.33
|| CUDA-PYTHON : 1.15.0
|| NETRON : 7.7.8
|| POLYGRAPHY : 0.49.9
====================================================================================================================部署的大体思路如下:
- Sparse4Dv3模型部署的过程需要将我们将训练好的模型.pth 文件,转换为中间文件.onnx,最后转换为*.engine 文件。该过程需要解决PyTorch模型与ONNX框架算子的兼容性以及模型运行加速两大需求; 模型pth下载链接:https://drive.google.com/file/d/1sSMNB7T7LPKSr8nD9S_tSiu1mJrFMZ1I/view?usp=sharing**
- Sparse4Dv3 PyTorch模型实际上就是一个计算图。模型部署时通常需要我们将模型转换成静态的计算图,即没有控制流(分支语句、循环语句)的计算图,这点很重要,Sparse4Dv3 Head模型转换过程我们就会遇到这个问题;
- PyTorch 框架自带对 ONNX 的支持,只需要我们构造一组随机的输入,并对模型调用 torch.onnx.export 即可,完成 PyTorch 到 ONNX 的转换。
- *推理引擎 ONNX Runtime 对 ONNX 模型有原生的支持,提供了python API 和 C++ API。给定一个 .onnx 文件,只需简单使用 ONNX Runtime 的 Python API 就可以完成模型推理。依据上述工具的使用,我们可以完成PyTorch到ONNX的推理一致性验证。
- 推理引擎 TensorRT 提供了Python API 和 C++ API。给定一个 .engine 文件,只需要简单使用 TensorRT 的 Python API 就可以在python脚本中完成模型推理。依据上述构造过程,我们可以完成PyTorch到ONNX的推理一致性验证。最后,通过调用C++ API就可以完成代码在车端仓库的部署了(简单点说,就是将TensorRT的python API做一次C++ API接口映射即可)。*
部署工作开始前,我们首先分析下Sparse4Dv3 PyTorch模型结构,这里以配置:输入img_size : 256x704, 模型backbone : Resnet50, 模型精度Precision : fp32为例,模型结构大体可以拆分成两个部分:imgBackbone和sparseTrans formerHead。
1)imgBackbone由Resnet50+FPN组成,详细结构如下:
(imgBackbone): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilatinotallow=1, ceil_mode=False)
(layer1): ResLayer(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(...)
...
)
***********************************************************Resnet50重复堆叠的模块我这里省略了哈
)
init_cfg={'type': 'Pretrained', 'checkpoint': 'ckpt/resnet50-19c8e357.pth'}
(img_neck): FPN(
(lateral_convs): ModuleList(...)
(fpn_convs): ModuleList(
(0): ConvModule(...)
)
init_cfg={'type': 'Xavier', 'layer': 'Conv2d', 'distribution': 'uniform'})2)sparseTrans formerHead 由 anchorencoder + 39个Op构成的ModuleList组成,其中,不包含instance_bank layer, loss_cls, loss_reg, loss_box, loss_cns, etc. 原因如下:
- instance_bank layer: 该模块主要功能,缓存历史帧instance实例,并将历史帧anchor投影到当前帧,最后更新trackid和confidence,而且,该模块并未包含有效的nn.Module部分(这里有效指的是训练过程并没有需要更新梯度的tensor变量,也就不涉及到权重和偏置组成部分),所以为了成功导出ONNX,后续会将该部分从head剥离开;
- 模型部署的数据流走的是推理链路,所以和训练相关的模块需要全都丢弃,这里包含:loss_cls, loss_reg, loss_box, loss_cns, depth_branch, grid_mask, etc;
(sparseTransformerHead): Sparse4DHead(
(anchor_encoder): SparseBox3DEncoder(
(pos_fc): Sequential(
(0): Linear(in_features=3, out_features=128, bias=True)
(1): ReLU(inplace=True)
(2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(3): Linear(in_features=128, out_features=128, bias=True)
(4): ReLU(inplace=True)
(5): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(6): Linear(in_features=128, out_features=128, bias=True)
(7): ReLU(inplace=True)
(8): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(9): Linear(in_features=128, out_features=128, bias=True)
(10): ReLU(inplace=True)
(11): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
*********************************************************size_fc/yaw_fc/vel_fc我省略了哈
)
(layers): ModuleList(
(0): DeformableAttentionAggr(...)
(1): AsymmetricFFN(...)
(2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(3): SparseBox3DRefinementModule(...)
(cls_layers): Sequential(...)
(quality_layers): Sequential(...)
(4): MultiheadAttention(...)
(5): MultiheadAttention(...)
***********************************************************head重复的op我也省略了哈
)
(fc_before): Linear(in_features=256, out_features=512, bias=False)
(fc_after): Linear(in_features=512, out_features=256, bias=False))Sparse4Dv3 SparseTransfomerHead Deployment Solution
核心内容,之所以先介绍head部署方案,一方面,因为head是算法的核心部分,和业务需求紧密联系,另一方面。head结构复杂,部署的主要工作量体现在这一部分。相比较imgBackbone,推理前向过程需要我们很清晰的掌握head模块的数据流向以及算法机理。
一)DFA自定义CUDA算子的部署方案
首先head在转换ONNX中间格式时,我们不难发现,其中存在自定义算子DFA(Deformable Feature Aggregation),其调用函数为deformable_aggregation_function()。很明显,该算子借用pybind11构建共享库完成了C++和CUDA扩展的自定义算子,从而解决PyTorch原算子并行问题,进而减小训练/推理显存,加速训练/推理速度。PyTorch的C++和CUDA扩展自定义算子一般流程如下:
- 第一步:使用C++编写算子的forward函数和backward函数;
- 第二步:将该算子的forward函数和backward函数使用pybind11绑定到python上;
- 第三步:使用setuptools/JIT/CMake编译打包C++工程为*.so文件;
- 第四步:在python端继承PyTorch的torch.autograd.Function类,实现静态函数forward和backward,并调用上述过程生成的动态库*.so;
Q∶什么是DFA算子,它又具备什么样的功能?论文中这样写道:[2]
图三:DFA算子将原始的3D关键点:固定关键点和可学习关键点,与图像特征对齐,从而提取有效的图像特征
DFA算子实现流程:
- 第一步:首先,将900个query instance 的 13(6KFP+7KLP)个3D关键点全部投影current timestamp的FeatureMap上,接下来通过双线性插值方法在MultiView FeatureMap上进行特征采样;
- 第二步:紧接着,在MultiView的不同的MultiScale层(即不同分辨率的特征图层)上重复执行双线性插值操作,以捕获从粗粒度到细粒度的特征特区,这有助于模型在不同尺度上理解物体的结构和细节;
- 第三步:最后,网络会使用预测的权重(通过线性层计算得到)进行加权,完成特征的聚合。这确保算法具备了:根据检测任务的贡献大小,对不同视角和尺度的特征进行合适的特征融合;
P.S.其中KFP为固定关键点,KLP为可学习关键点,文中DeformableAttention Aggr,DeformableFeatureAggregation, DFA都指的同一个自定义算子
Q:为什么需要对DFA算子做CUDA加速?
HBM(High Bandwidth Memory)[3]高带宽存储,是一种常用显存介质。顾名思义,这个存储介质有着"High Bandwidth"。在多视角多尺度特征聚合过程中,DFAOp涉及了多次HBMIO过程,因此,存储了大量的临时变量。训练过程梯度回传以及推理过程频繁的HBM访问,一方面,其占用了大量显存。另一方面,频繁IO降低了推理速度。原码中调用的是torch.nn.functional.
for fm in feature_maps:
features.append(nn.functional.grid_sample(fm.flatten(end_dim=1), points_2d))
features = torch.stack(features, dim=1)
features = features.reshape(
bs, num_cams, num_levels, -1, num_anchor, num_pts).permute(0, 4, 1, 2, 5, 3)针对上述问题,作者提出了加速的需求,并给出了加速方案:
图四:使用CUDA多线程并行化加速DFA特征聚合
DFA算法加速流程:
- 第一步:将基本可变形聚合中的MultiScale/MultiView维度输入,同可学习的权重系数加权操作,作为CUDA线程的原子操作;
- 第二步:在K×C的维度上分配线程,实现K, C维度的完全的并行化计算;
核心代码见位置:modules/ops/src/deformable_aggregation_cuda.cu,摘取部分如下:
__global__ void deformable_aggregation_kernel(
const int num_kernels,
float* output,
const float* mc_ms_feat,
const int* spatial_shape,
const int* scale_start_index,
const float* sample_location,
const float* weights,
int batch_size,
int num_cams,
int num_feat,
int num_embeds,
int num_scale,
int num_anchors,
int num_pts,
int num_groups
) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= num_kernels) return;
const float weight = *(weights + idx / (num_embeds / num_groups));
const int channel_index = idx % num_embeds;
idx /= num_embeds;
const int scale_index = idx % num_scale;
idx /= num_scale;
const int cam_index = idx % num_cams;
idx /= num_cams;
const int pts_index = idx % num_pts;
idx /= num_pts;
int anchor_index = idx % num_anchors;
idx /= num_anchors;
const int batch_index = idx % batch_size;
idx /= batch_size;
anchor_index = batch_index * num_anchors + anchor_index;
const int loc_offset = ((anchor_index * num_pts + pts_index) * num_cams + cam_index) << 1;
const float loc_w = sample_location[loc_offset];
if (loc_w <= 0 || loc_w >= 1) return;
const float loc_h = sample_location[loc_offset + 1];
if (loc_h <= 0 || loc_h >= 1) return;
int cam_scale_index = cam_index * num_scale + scale_index;
const int value_offset = (batch_index * num_feat + scale_start_index[cam_scale_index]) * num_embeds + channel_index;
cam_scale_index = cam_scale_index << 1;
const int h = spatial_shape[cam_scale_index];
const int w = spatial_shape[cam_scale_index + 1];
const float h_im = loc_h * h - 0.5;
const float w_im = loc_w * w - 0.5;
atomicAdd(
output + anchor_index * num_embeds + channel_index,
bilinear_sampling(mc_ms_feat, h, w, num_embeds, h_im, w_im, value_offset) * weight
);
}由于单个线程的计算负载是 N X S ,而每个点最多投影到两个视角,因此,计算复杂度最多2S。到这里,我们知道了为什么需要对DFA算子做CUDA加速以及如何进行加速,那这些原理对实际部署又有什么影响呢?根据作者的加速方案,其实,我们可以进一步的优化该算子,比如,减少HBMIO次数、引入share_memory、使用半精度CUDA fp16等方法。以上内容将会在我的下一篇文章中做详细介绍,大家感兴趣的可以关注我的仓库日志更新哦~
P.S.其中N为使用的环视相机的数量,S为多尺度的层数,K为关键点的数量
Q:DFA算子怎么部署呢?具体开发流程是什么?
这里先说结论:
- 首先,在PyTorch代码中使用符号函数:symbolic:构建DFA自定义算子PyTorch 到 ONNX 映射规则;
- 其次,将带有自定义算子DFA,PyTorch 到 ONNX 映射规则的*.pth模型文件转化为ONNX中间文件;
- 最后,基于指定版本的TensorRT C++ 注册plugin的 API,构建自定义DFA plugin,构建编译规则,编译该plugin,在本地将会生成动态库*.so文件;
- 对比验证PyTorch推理结果和TensorRT推理结果,确保结果的一致性;
- 通过trtexec command line 加载上述动态库到目标trt engine中,生成带有plugin的目标模型engine;
这里,不得不提下我之前幻想能够实现部署目标的几个解决方案的思路,以及后续为什么我最终敲定了上述方案:
被我舍弃的思路一:拆分法
由于DFA是自定义算子,这意味着:PyTorch的ATen[5]基本库没有官方实现、ONNX节点Op不支持该算子、TensorRT(包含官方实现的Plugin)不支持该算子。因此,在转换ONNX过程必定面临失败,更别提转换TensorRT Engine了。那么比较容易想到的方法是:在自定义算子 出现的位置,我们把模型逐个拆分开,最后,在C++车端代码中逐个把模型串联起来不就可以了?一般来说这种方案没啥问题,但在Sparse4Dv3中,我们不推荐这么做,请看下面:
图五:Sparse4D Head 单次推理DFA出现次数
很显然,DFAOp单帧推理出现了6次,若要拆分模型,单单Head部分就会1拆7,这不是越搞越复杂吗??思路一显然太笨不合适!
被我舍弃的思路二:集成Custom DFA Plugin放入TensorRT OSS整编
TensorRT OSS[6](TensorRT Open Source Software) 是NVIDIA 高性能推理SDK仓库。我们先指定TensorRT版本,然后clone下来,在plugin文件我们可以找到官方实现的plugin。到了这里,很多博客还有视频教程会告诉我们,参考官方自定义Plugin的方法实现自定义Plugin,然后在对应的API中注册新的算子名,最后,整体编译生成新的libnvinfer.so替换原始动态库完成自定义plugin的注册。听起来逻辑清晰,好像没有什么问题,但是,实际操作下来发现问题太多了:
- 辛辛苦苦的把DFA算子按规则注册好了,准备开始编译,紧接着,各种依赖问题出现。解决了一上午,诶?还是有环境问题,这时候的你冷静思考了一下:好像关于算子的开发的工作,以及推理正确与否还没开始验证呀?我一上午在干啥呢?
- 下午的你有些焦虑,先打开google ,把问题搜索一下?额,什么都搜不到,心想:全世界就我一个人遇到了这个问题吗,不是吧???忍不了了,于是你开始在issue上提问,同时你打开google翻译,精心准备好问题,并确定没有语法错误,激动的把问题提交去了,坐等仓库维护者帮忙解答。不知不觉过了几天,你很烦躁,心想:他们是太忙了吗?还是有时差呀?又或者放假了?怎么现在还没有回复我的问题,怎么办?我再试试自己解决一下,突然一条消息弹出,issue有更新啦,但你赫然看到的是那句熟悉又恼火的答复:How about using the latest version TensorRT?
哈哈,这个情况不知道大家遇到的多不多,我反正经常遇到。即使这些问题在本地工作站解决了,NVIDIA ORIN 部署还是有隐患的。即使,我们在本地编译通过或者升级TensorRT完美避开旧板本的bug,最终生成新的libnvinfer.so,可是,这玩意部署到NVDIA ORIN上也用不了呀,架构不同!要么,我们在本地借用交叉编译工具完成基于ARM的共享库生成。要么,我们直接上ORIN开发板编译。且不说编译速度慢吧,谁能确保不会遇到其他环境问题?这工作量目测是个无底洞,而关于plugin开发验证工作我们实际还未开展起来,显然侧重点有问题呀!抱歉,这个思路也不适合我。
被我舍弃的思路三:借用其他开源的仓库
借用仓库,如:tensorRT_Pro | tensorrtx | torch2trt 等。一方面需要了解并学习其使用方法。另外,也不能保证这些仓库的维护者一直持续更新,及时修复里面的BUG。最重要的是,自动驾驶使用的相关自定义算子,上述仓库大概率也没有呀(大部分是关于2D目标检测、目标分类和分割相关的算法部署方案)。所以说,准备工作挺耗费时间的,性价比不高。
基于上面的思考,最适合的方案还是一开始给出的结论最靠谱。言归正传,
第一步:建立PyTorch算子与ONNX节点映射关系:
图六:使用symbolic符号函数以及g.op()搭建算子映射关系
第二步:生成ONNX中间文件。有了映射关系,我们就可以生成ONNX文件了,netron可视化如下:
图七:Custom op:DeformableAttentionAggrPlugin ONNX node
这里的ONNX文件是无法成功转换trt engine,因为,ONNX中的DeformableAttentionAggrPlugin节点只是一个接口,没有对应的TensorRT Op实现的。因此,下一步需要在TensorRT中注册该算子,并将核心实现填充进去。
第三步:Custom Operator Plugin: DeformableAttentionAggrPlugin注册(我用最简单的话来解释):
- 打开浏览器搜索github 仓库 TensorRT,指定版本8.5,打开plugin文件夹,这里以官方的实现的第一个plugin: batchTilePlugin为例:
图八:以batchTilePlugin为例模仿搭建DeformableAttentionAggrPlugin
我们需要构建四个文件分别为:
- deformableAttentionAggrPlugin.h
- deformableAttentionAggrPlugin.cpp
- deformableAttentionAggrPlugin.cu
- Makefile
P.S.其中我们会多一个文件: deformable Attention AggrPlugin.cu,这个文件为CUDA实现的核心代码,其实和Plugin注册没什么关系,是CustomOperator :DFA实现的逻辑代码。至于使用Make file还是CMakeLists编译,依据习惯就可,无特别要求
先说第一个文件,头文件一般用来定义接口,注册自定义plugin需要构建三部分:
- part1: 注册Plugin名称DeformableAttentionAggrPlugin,它需和ONNX节点保持一致
static const char* PLUGIN_NAME{"DeformableAttentionAggrPlugin"};
static const char* PLUGIN_VERSION{"1"};- part2: 定义Plugin类:DeformableAttentionAggrPlugin,这里包含了核心实现函数enqueue,除了这个函数需要我们定义实现,其他函数基本都是依据模板直接套用(是不是很简单),DeformableAttentionAggrPlugin类具体又可以划分三部分组成,如下:
/// @brief PART1: Custom Plugin Class: DeformableAttentionAggrPlugin -> nvinfer1::IPluginV2DynamicExt Methods
/*
* clone()
* getOutputDimensions()
* supportsFormatCombination()
* configurePlugin()
* getWorkspaceSize()
* enqueue() /// 它是核心哦!
* attachToContext()
* detachFromContext()
*/
/// @brief PART2: Custom Plugin Class: DeformableAttentionAggrPlugin -> nvinfer1::IPluginV2Ext Methods
/*
* getOutputDataType()
*/
/// @brief PART3: Custom Plugin Class: DeformableAttentionAggrPlugin -> nvinfer1::IPluginV2 Methods
/*
* getPluginType()
* getPluginVersion()
* getNbOutputs()
* initialize()
* getSerializationSize()
* serialize()
* destroy()
* terminate()
* setPluginNamespace()
* getPluginNamespace()
*/- part3: 定义Plugin创建类:DeformableAttentionAggrPluginCreator,这部分没什么好说的,直接套用模板,改改变量名称就可以了:
/// @brief Second define a PluginCreator Class:DeformableAttenionAggrPluginCreator -> IPluginCreator
/*
* DeformableAttentionAggrPluginCreator()
* ~DeformableAttentionAggrPluginCreator()
* getPluginName()
* getPluginVersion()
* getFieldNames()
* createPlugin()
* deserializePlugin()
* setPluginNamespace()
* getPluginNamespace()
*/完成头文件定义,源文件实现基本都可以复用batchTilePlugin的实现,根据需要更新对应的变量名和使用即可。而主要的工作量,需要我们完成核心函数接口DeformableAttentionAggrPlugin::enqueue()的实现,而加速并行CUDA代码在*.cu实现即可(接口函数:thomas_deform_attn_cuda_forward()),完成这一步可以说大功告成了!
int32_t DeformableAttentionAggrPlugin::enqueue(const nvinfer1::PluginTensorDesc* inputDesc,
const nvinfer1::PluginTensorDesc* outputDesc,
const void* const* inputs,
void* const* outputs,
void* workspace,
cudaStream_t stream) noexcept
{
int32_t const batch = inputDesc[0].dims.d[0];
int32_t spatial_size = inputDesc[0].dims.d[1];
int32_t channels = inputDesc[0].dims.d[2];
int32_t num_cams = inputDesc[1].dims.d[0];
int32_t num_levels = inputDesc[1].dims.d[1];
int32_t num_query = inputDesc[3].dims.d[1];
int32_t num_point = inputDesc[3].dims.d[2];
int32_t num_groups = inputDesc[4].dims.d[5];
int32_t rc = 0;
const float* value = static_cast<const float*>(inputs[0]);
const int32_t* spatialShapes = static_cast<const int32_t*>(inputs[1]);
const int32_t* levelStartIndex = static_cast<const int32_t*>(inputs[2]);
const float* samplingLoc = static_cast<const float*>(inputs[3]);
const float* attnWeight = static_cast<const float*>(inputs[4]);
float* output = static_cast<float*>(outputs[0]);
rc = thomas_deform_attn_cuda_forward(stream,
value,
spatialShapes,
levelStartIndex,
samplingLoc,
attnWeight,
output,
batch,
spatial_size,
channels,
num_cams,
num_levels,
num_query,
num_point,
num_groups);
return rc;
}第四步:DFA Operators PyTorch vs. TensorRT 推理一致性验证:
代码详情见:deploy/dfa_plugin/unit_test/deformable_feature_aggregation_infer-consistency-val_pytorch_vs_trt_unit_test.py。在构建推理一致性代码前,我们需要加载Plugin动态库:这里,我们import ctyp,调用方法为 ctypes.cdll.LoadLibrary ::
ctypes.cdll.LoadLibrary(soFile)
def getPlugin(plugin_name) -> trt.tensorrt.IPluginV2:
for i, c in enumerate(trt.get_plugin_registry().plugin_creator_list):
logger.debug(f"We have plugin{i} : {c.name}")
if c.name == plugin_name:
return c.create_plugin(c.name, trt.PluginFieldCollection([]))有了动态库文件,推理链路的开发,需要熟悉指定版本的TensorRT Python API接口的使用方法,不同版本本接口略有不同,v8.4和v8.3基本一致,而v8.5和v8.6基本一致。以v8.4(old)版本为例,举几个常用的方法:
ICuda.Engin.e类类常用方法:
图九:ICudaEngine类的实例对象就是我们反序列化后生成的engine对象
图十:engine.get_binding_dtype获得绑定的tensor类型,它和ONNX输入输出类型保持一致
图十一:engine.get_binding_name获得绑定的tensor名称,它和ONNX输入输出名称保持一致
I EaecutionConteat类常用方法:

图十二:IExecutionContext实例化:context = engine.create_execution_context()
图十三:get_bind_shape 获得execute_v2接口完成模型的推理
CoreCodeBelow:
def inference(
feature: np.ndarray,
spatial_shapes: np.ndarray,
level_start_index: np.ndarray,
instance_feature: np.ndarray,
anchor: np.ndarray,
time_interval: np.ndarray,
image_wh: np.ndarray,
lidar2img: np.ndarray,
engine: str,
trt_old: bool,
logger,
):
bufferH = []
bufferH.append(feature)
bufferH.append(spatial_shapes)
bufferH.append(level_start_index)
bufferH.append(instance_feature)
bufferH.append(anchor)
bufferH.append(time_interval)
bufferH.append(image_wh)
bufferH.append(lidar2img)
if trt_old:
nIO = engine.num_bindings
lTensorName = [engine.get_binding_name(i) for i in range(nIO)]
nInput = sum([engine.binding_is_input(lTensorName[i]) for i in range(nIO)])
for i in range(nInput, nIO):
bufferH.append(
np.zeros(
engine.get_binding_shape(lTensorName[i]),
dtype=trt.nptype(engine.get_binding_dtype(lTensorName[i])),
)
)
for i in range(nInput):
logger.debug(
f"LoadEngine: Input{i}={lTensorName[i]}:\tshape:{engine.get_binding_shape}\ttype:{str(trt.nptype(engine.get_binding_dtype))} ."
)
for i in range(nInput, nIO):
logger.debug(
f"LoadEngine: Output{i}={lTensorName[i]}:\tshape:{engine.get_binding_shape}\ttype:{str(trt.nptype(engine.get_binding_dtype))} ."
)
else:
nIO = engine.num_io_tensors
lTensorName = [engine.get_tensor_name(i) for i in range(nIO)]
nInput = [engine.get_tensor_mode(lTensorName[i]) for i in range(nIO)].count(
trt.TensorIOMode.INPUT
)
context = engine.create_execution_context()
for i in range(nInput, nIO):
bufferH.append(
np.zeros(
context.get_tensor_shape(lTensorName[i]),
dtype=trt.nptype(engine.get_tensor_dtype(lTensorName[i])),
)
)
for i in range(nInput):
logger.debug(
f"LoadEngine: BindingInput{i}={lTensorName[i]} :\tshape:{context.get_tensor_shape(lTensorName[i])},\ttype:{str(trt.nptype(engine.get_tensor_dtype(lTensorName[i])))}"
)
for i in range(nInput, nIO):
logger.debug(
f"LoadEngine: BindingOutput{i}={lTensorName[i]}:\tshape:{context.get_tensor_shape(lTensorName[i])},\ttype:{str(trt.nptype(engine.get_tensor_dtype(lTensorName[i])))}"
)
bufferD = []
for i in range(nIO):
bufferD.append(cudart.cudaMalloc(bufferH[i].nbytes)[1])
for i in range(nInput):
cudart.cudaMemcpy(
bufferD[i],
bufferH[i].ctypes.data,
bufferH[i].nbytes,
cudart.cudaMemcpyKind.cudaMemcpyHostToDevice,
)
if trt_old:
binding_addrs = [int(bufferD[i]) for i in range(nIO)]
context.execute_v2(binding_addrs)
else:
for i in range(nIO):
context.set_tensor_address(lTensorName[i], int(bufferD[i]))
context.execute_async_v3(0)
for i in range(nInput, nIO):
cudart.cudaMemcpy(
bufferH[i].ctypes.data,
bufferD[i],
bufferH[i].nbytes,
cudart.cudaMemcpyKind.cudaMemcpyDeviceToHost,
)
for b in bufferD:
cudart.cudaFree(b)
return nInput, nIO, bufferH评价指标一般使用以下两种方法:
- 其一:逐元素相减取其中绝对值最大值的方法:max(abs()),下图可以看到只有万分之一的误差;
- 其二:计算cosine_distance,即高维向量的余弦距离,从结果上看误差在1e-7这个级别;
图十四:DeformableAttentionAggrPlugin: PyTorch vs. TensorRT API 推理一致性验证结果
综上所述,DFA算子完成了PyTorch vs. TensorRT Python API 一致性验证,顺利通过。
第五步:使用trtexec指令参数:--plugins加载Custom Operator Plugin:DeformableAttentionAggrPlugin,完成带有自定义plugin的TensorRT模型转换。

图十五:--plugins支持同时加载多个外部生成的Plugin动态库
trtexec --notallow=head1.onnx \
--plugins=deploy/dfa_plugin/lib/deformableAttentionAggr.so \
--memPoolSize=workspace:2048 \
--saveEngine=head1.engine \
--verbose \
--warmUp=200 \
--iteratinotallow=50 \
--dumpOutput \
--dumpProfile \
--dumpLayerInfo \
--exportOutput=${ENVTRTDIR}/buildOutput_head1.json \
--exportProfile=${ENVTRTDIR}/buildProfile_head1.json \
--exportLayerInfo=${ENVTRTDIR}/buildLayerInfo_head1.json \
--profilingVerbosity=detailed![]()
图十六:TensorRT trtexec转换模型成功flag
二) sparseTrans formerHead转ONNX方案
上面,我们已经解决了Head棘手的Custom Operator:DFA算子如何映射ONNX节点,并注册TensorRT plugin的问题。接下来,基于上面的结论我们直接将转换ONNX中间文件,还是会遇到若干问题。这主要涉及了时序Head数据流向的理解。
我先上结论:我们需要将Head分成两部分转换ONNX:第一帧的head,第二帧及后续帧的head。
第一帧head,输入有8个张量,分别为:
- feature : Backbone输出的图像编码特征;
- spatial_shapes : Backbone输出的图像编码特征图的尺度w/h;
- level_start_index : Backbone输出的图像编码特征图拉平后,起始位置索引;
- instance_feature : 当前帧获得的实例特征;
- **anchor : 当前帧900个query anchor信息:x,y,z,w,l,h,cos_yaw,sin_yaw,vx,vy,vz; **
- time_interval : 默认时间间隔0.5s;
- image_wh : Backbone输入图像的w/h;
- lidar2img : lidar 投影到图像的转换矩阵;
第一帧head, 输出有4个张量,如下图所示:
图十七:Sparse4D Head 第一帧的ONNX输入输出tensor name
第二帧及后续帧head,输入有12个张量,多出的4个张量分别为:
- temp_instance_feature : t-1时刻上一帧获得的实例特征;
- temp_anchor : t-1时刻instance_bank缓存的600个query anchor信息:x,y,z,w,l,h,cos_yaw,sin_yaw,vx,vy,vz;
- mask : bool类型,t时刻和t-1时刻的时间gap有没有超过最大时间间隔2s;
- track_id : instance_bank 缓存的t-1时刻track_id;
P.S.其实trackid和mask可以剥离并不作为模型的输入,本文为了最大程度还原代码逻辑,选择保留在模型中。
第二帧及后续帧head, 输出有5个张量,如下图所示:
图十八:Sparse4D Head 第二帧及后续帧的ONNX输入输出tensor name
Q: sparseTrans formerHead为什么需要分成两部分,依据是什么?
首先Spase4dv3 Head其中不仅包含了模型部分,其实还耦合了InstanceBank部分,InstanceBank主要功能:
- head 模型开始推理前,instance bank::get()生成instance_feature,anchor,time_interval,temp_instance_feature,temp_anchor这五个变量;
- 上述变量会做为head的39个Operator的输入。其中,head 的refine Op模块,会将模型预测的instance_feature, anchor, confidence作为输入,和instance_bank内部维护的历史帧t-1时刻的instance_feature, anchor分别做融合,以更新当前帧预测的instance_feature, anchor;
- 在39个op执行完后,head将会调用instance::cache(), 缓存当前帧t时刻模型预测的:instance_feature,anchor, confidence;
由TensorRT前向推理支持的是静态图,需要明确的输入输出张量,同时,内部也不支持if判断语句。因此,不难得出,我们必须解偶InstanceBank模块。我们按时间维度将head划分为两部分:第一部分为第一帧的head,输入8个张量,第二部分为第二帧及后续帧的head,输入为12个张量。
第一帧head转ONNX核心代码见:deploy/export_head_onnx.py
@staticmethod
def head_forward(
self,
feature,
spatial_shapes,
level_start_index,
instance_feature,
anchor,
time_interval,
image_wh,
lidar2img,
):
# Instance bank get inputs
temp_instance_feature = None
temp_anchor_embed = None
# DFA inputs
metas = {
"image_wh": image_wh,
"lidar2img": lidar2img,
}
anchor_embed = self.anchor_encoder(anchor)
feature_maps = [feature, spatial_shapes, level_start_index]
prediction = []
for i, op in enumerate(self.operation_order):
print("i: ", i, "\top: ", op)
if self.layers[i] is None:
continue
elif op == "temp_gnn":
instance_feature = self.graph_model(
i,
instance_feature,
temp_instance_feature,
temp_instance_feature,
query_pos=anchor_embed,
key_pos=temp_anchor_embed,
)
elif op == "gnn":
instance_feature = self.graph_model(
i,
instance_feature,
value=instance_feature,
query_pos=anchor_embed,
)
elif op == "norm" or op == "ffn":
instance_feature = self.layers[i](instance_feature)
elif op == "deformable":
instance_feature = self.layers[i](
instance_feature,
anchor,
anchor_embed,
feature_maps,
metas,
)
elif op == "refine":
anchor, cls, qt = self.layers[i](
instance_feature,
anchor,
anchor_embed,
time_interval=time_interval,
return_cls=(
len(prediction) == self.num_single_frame_decoder - 1
or i == len(self.operation_order) - 1
),
)
prediction.append(anchor)
if i != len(self.operation_order) - 1:
anchor_embed = self.anchor_encoder(anchor)
return instance_feature, anchor, cls, qt第二帧及后续帧head转ONNX核心代码见:deploy/export_head_onnx.py
@staticmethod
def head_forward(
self,
feature,
spatial_shapes,
level_start_index,
instance_feature,
anchor,
time_interval,
temp_instance_feature,
temp_anchor,
mask,
track_id,
image_wh,
lidar2img,
):
mask = mask.bool() # TensorRT binding type for bool input is NoneType.
anchor_embed = self.anchor_encoder(anchor)
temp_anchor_embed = self.anchor_encoder(temp_anchor)
# DAF inputs
metas = {
"lidar2img": lidar2img,
"image_wh": image_wh,
}
feature_maps = [feature, spatial_shapes, level_start_index]
prediction = []
for i, op in enumerate(self.operation_order):
print("op: ", op)
if self.layers[i] is None:
continue
elif op == "temp_gnn":
instance_feature = self.graph_model(
i,
instance_feature,
temp_instance_feature,
temp_instance_feature,
query_pos=anchor_embed,
key_pos=temp_anchor_embed,
)
elif op == "gnn":
instance_feature = self.graph_model(
i,
instance_feature,
value=instance_feature,
query_pos=anchor_embed,
)
elif op == "norm" or op == "ffn":
instance_feature = self.layers[i](instance_feature)
elif op == "deformable":
instance_feature = self.layers[i](
instance_feature,
anchor,
anchor_embed,
feature_maps,
metas,
)
elif op == "refine":
anchor, cls, qt = self.layers[i](
instance_feature,
anchor,
anchor_embed,
time_interval=time_interval,
return_cls=(
len(prediction) == self.num_single_frame_decoder - 1
or i == len(self.operation_order) - 1
),
)
prediction.append(anchor)
# update in head refine
if len(prediction) == self.num_single_frame_decoder:
N = (
self.instance_bank.num_anchor
- self.instance_bank.num_temp_instances
)
cls = cls.max(dim=-1).values
_, (selected_feature, selected_anchor) = topk(
cls, N, instance_feature, anchor
)
selected_feature = torch.cat(
[temp_instance_feature, selected_feature], dim=1
)
selected_anchor = torch.cat([temp_anchor, selected_anchor], dim=1)
instance_feature = torch.where(
mask[:, None, None], selected_feature, instance_feature
)
anchor = torch.where(mask[:, None, None], selected_anchor, anchor)
track_id = torch.where(
mask[:, None],
track_id,
track_id.new_tensor(-1),
)
if i != len(self.operation_order) - 1:
anchor_embed = self.anchor_encoder(anchor)
if len(prediction) > self.num_single_frame_decoder:
temp_anchor_embed = anchor_embed[
:, : self.instance_bank.num_temp_instances
]
return instance_feature, anchor, cls, qt, track_id拆分Head为两部分模型分别转ONNX过程后,我们又遇到一些奇怪的问题,类似下面图示:
图十九:RuntimeError:r INTERNAL ASSERT FAILED, ATen Err
![]()
图二十:Failed: Squeeze Op Err

图二十一:UserWarning: The shape inference of prim::Constant type is missing
这里先说结论:
- ONNX不支持Silce操作,如:output[..., [X, Y, Z, W, L, H]],需要转换为output[..., :6];
- ONNX不支持if判断语句,PyTorch中的data.squeeze()常常会造成ONNX产生if节点,需转换data.squeeze(-1)为slice操作,如:data[...,0];
- ONNX自身是支持bool类型的张量输入,但是,TensorRT是不支持的,在做一致性验证过程保存bin文件也会遇到问题,为了避免bool和int来回转换的烦恼,这里推荐使用int类型作为输入,模型内部转换为bool类型;
- PyTorch临时定义的常量tensor一般会造成Warning,所以,我们一般不用关心。但是,如果我们希望ONNX能够tracing这个数据流,那么丢失会造成致命错误,解决方案是将其作为ONNX的输入tensor之一即可;
- ONNX输入输出变量需要为torch.tensor类型,类似str, numpy.ndarray, dict类型会直接模型模型转换失败;
1)先说第一条:ONNX支持的Pytorch Ops以及Types,我们可以查看官方仓库:onnx-tensorrt和onnx,一般支持的操作有:data[..., a:b], data[..., a], data[..., a:], data[..., :b], data[:,:, a:b]等,data[..., []]这种操作一般不支持!
图二十二:Slice 支持的操作数据类型
图二十三:Slicez支持的ONNX版本
2)针对第二条:ONNX的tracing机制决定了ONNX会先根据PyTorch数据流,跟踪PyTorch所有的操作函数,而其底层都是由Aten基本操作库排列组合成高级函数的。如果Aten不支持的操作,显然ONNX也无法转换。另外,如果出现if操作,ONNX只能支持其中一条分支数据流跟踪,逻辑上也会损失信息。在本文中,data.squeeze()操作会被ONNX分解为equal和if节点,而if是Aten不支持的操作,因此,ONNX转换失败。
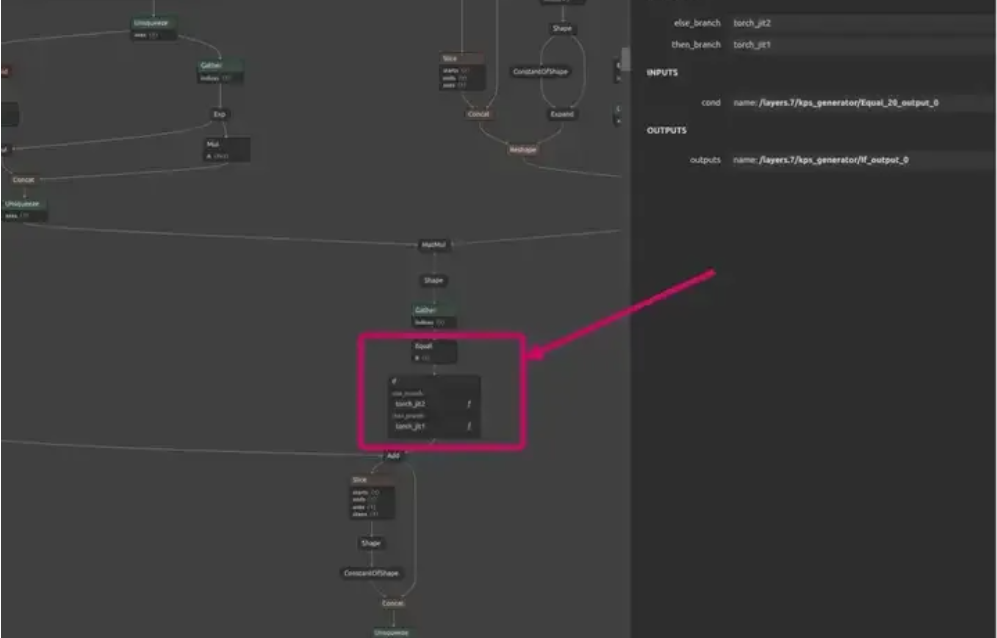
图二十四:ONNX转换失败:if node出现导致
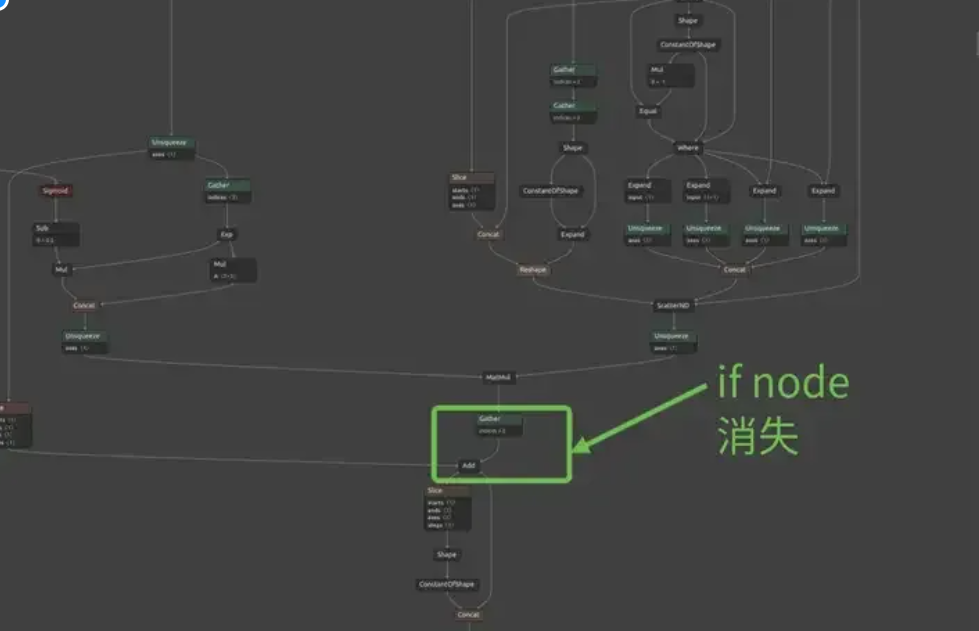
图二十五:ONNX转换成功:ONNX消除了if node
3)针对第三条:第二帧及后续帧Head 模型的其中一个输入张量mask,在PyTorch中输入原本应该是bool类型,这里为了方便转换TensorRT以及做推理一致性验证保存二进制bin文件的便利性,我们使用int类型替换:
# 转ONNX伪造输入张量
dummy_mask = torch.randint(0, 2, size=(bs,)).int().cuda()
# bin文件保存格式
mask = self._mask.int().detach().cpu().numpy()
mask.tofile("mask.bin")最后,相关问题代码整理如下,共大家参考:
### Head Forward 以下三部分会导致onnx导出错误:
### Part1:SparseBox3DEncoder:
anchor_embed = self.anchor_encoder(anchor)
# 函数内部相关实现如下:
def forward(self, box_3d: torch.Tensor):
pos_feat = self.pos_fc(box_3d[..., [X, Y, Z]])
size_feat = self.size_fc(box_3d[..., [W, L, H]])
yaw_feat = self.yaw_fc(box_3d[..., [SIN_YAW, COS_YAW]])
### Part2:SparseBox3DKeyPointsGenerator:
elif op == "deformable":
instance_feature = self.layers[i](
instance_feature,
anchor,
anchor_embed,
feature_maps,
metas)
# 函数内部相关实现如下:
key_points = key_points + anchor[..., None, [X, Y, Z]]
# Part3:SparseBox3DRefinementModule:
elif op == "refine":
anchor, cls, qt = self.layers[i](
instance_feature,
anchor,
anchor_embed,
time_interval=time_interval,
return_cls=(
self.training
or len(prediction) == self.num_single_frame_decoder - 1
or i == len(self.operation_order) - 1),)
# 函数内部相关实现如下:
self.refine_state = [X, Y, Z, W, L, H]
if self.refine_yaw:
self.refine_state += [SIN_YAW, COS_YAW]
output[..., self.refine_state] = (
output[..., self.refine_state] + anchor[..., self.refine_state])修改更新方案如下:
### Part1: SparseBox3DEncoder修改如下:
SparseBox3DEncoder:
def forward(self, box_3d: torch.Tensor):
pos_feat = self.pos_fc(box_3d[..., X:W])
size_feat = self.size_fc(box_3d[..., W:SIN_YAW])
yaw_feat = self.yaw_fc(box_3d[..., SIN_YAW:VX])
### Part2: SparseBox3DKeyPointsGenerator修改如下:
key_points = key_points + anchor[..., None, :3] # deploy friendly
### Part3: SparseBox3DRefinementModule修改如下:
if self.refine_yaw:
output[..., :SIN_YAW] = output[..., :SIN_YAW] + anchor[..., :SIN_YAW]
else:
output[..., :VX] = output[..., :VX] + anchor[..., :VX]三) sparseTrans formerHead Plorch vs.TensorRT us.Polygraphy推理一致性验证
首先,我们构建带有plugin:DeformableAttentionAggrPlugin的first frame Head端到端推理逻辑脚本,详情见:deploy/unit_test/sparse4d_head_first_frame_infer-consistency-val_pytorch_vs_trt_unit_test.py。下面两张图展示:PyTorch vs. TensorRT的误差max(abs()) 和cosine_distance非常小,都在期望的结果内(误差1e-3级别)。实验结果再次验证了上述模型转换逻辑以及注册Plugin逻辑正确性。
图二十六:sparse transformer head first frame PyTorch推理结果
图二十七:sparse transformer head first frame TensorRT推理结果
图二十八:sparse transformer head first frame Polygraphy推理结果
最后我们使用Polygraphy工具快速验证下基于TensorRT python API搭建的推理链路是否可靠:
polygraphy run deploy/onnx/sparse4dhead1st.onnx --trt --verbose --load-inputs=deploy/utils/first_frame_head_inputs.json --trt-outputs mark all --save-results=deploy/utils/first_frame_head_outputs.json --plugins deploy/dfa_plugin/lib/deformableAttentionAggr.so如上图:我们关注的4个维度的指标:Max, Min, SumAbs 以及前五个 first5、后五个元素last5肉眼可见的无差异,也和预期的结果保持一致。Good!到这里,first frame head部署已经结束了,关于sceond frame 以及后续帧head部署逻辑类似,这里就不展开了。
Attention: 其中,Polygraphy输入JSON格式文件:deploy/utils/first_frame_head_inputs.json、生成的结果JSON格式文件:first_frame_head_outputs.json,保存和解析都需使用Polygraphy指定的函数接口,调用方式见我的脚本:SparseEnd2End/deploy/utils/polygraphy_save_json_parser.py
CoreCodeBelow:
# save json
save_json(
[
{
"feature": feature,
"spatial_shapes": spatial_shapes,
"level_start_index": level_start_index,
"instance_feature": instance_feature,
"anchor": anchor,
"time_interval": time_interval,
"image_wh": image_wh,
"lidar2img": lidar2img,
},
],
input_json_path,
)
# parser json
onnx_outputs, trt_outputs = info_onnx["lst"][0][1][0], info_trt["lst"][0][1][0]
onnx_layers_outputs, trt_layers_outputs = (
onnx_outputs["outputs"],
trt_outputs["outputs"],
)
trouble_layers, ok_layers = [], []
for layer, value in onnx_layers_outputs.items():
if layer in trt_layers_outputs.keys():
onnx_out = pjson.from_json(json.dumps(value)).arr
trt_out = pjson.from_json(json.dumps(value)).arr
print(np.size(onnx_out), np.size(trt_out), layer)图二十九:polygraphy.json.from_json()/save_json()使用说明
最后补充下Polygraphy命令行指令使用方法,参见官方文档:Polygraphy Docs。常用的参数如下:
- --validate : 快速验证ONNX转engine推理结果是否会出现Nan或者Inf
- --trt : 启动TensorRT后端推理
- --onnxrt : 启动onnxruntime后端推理
- --plugins : 加载动态库
- --load-inputs : 加载指定输入数据推理
- --atol : 指定绝对容忍误差
- --rtol : 指定相对容忍误差
- --fp16 : 指定精度fp16
- save-engine : 指定engine保存位置,你没看错,这个指令也可以转模型
图三十:Polygraphy Docs --validate 解释
SparseImgBackbone Deployment Pipeline
imgBackbone部署属于常规操作,没有特别需要注意的问题,毕竟Sparse4Dv3 imgBackbone的组成为:Resnet50+FPN,大家再熟悉不过了。这里,我随机测试三个样本,下图直接贴上验证结果:
图三十一:PyTorch vs. ONNX Runtime 推理一致性验证结果
图三十二:PyTorch vs. TensorRT API 推理一致性验证结果
![]()
图三十三:imgBackbone polygraphy验证通过
imgBackbone推理使用了ONNX Runtime后端,ONNX Runtime 调用函数如下:
def onnx_infer(
onnx_model,
dummy_img,
):
session = ort.InferenceSession(onnx_model.SerializeToString())
ort_inputs = {session.get_inputs()[0].name: dummy_img}
ort_outs = session.run(["feature"], ort_inputs)
return ort_outs[0]Summary
本文主要关注ONNX | ONNX Runtime | TensorRT | Polygraphy在模型部署中的应用,归纳总结了常用的方法、实用指令和部署过程中踩过的实坑解决经验。最后,本文串联完成部署过程的各个子环节、闭环验证了部署模型推理的一致性。本人技术有限,如有理解上的误区,望不吝赐教。
Portal
ONNX支持的算子及版本对应关系:
github.com/onnx/onnx/blob/main/docs/Operators.md
ONNX支持的算子操作类型:docs/operators.md
github.com/onnx/onnx-tensorrt/tree/10.4-GA
TensorRT docs, 这里介绍了TensorRT python API, TensorRT C++ API和Polygraphy使用方法:
docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#overview
ONNX Runtime API: https://onnxruntime.ai/docs/api/
Polygraphy docs: Polygraphy - Polygraphy 0.49.13 documentationAPI DocsPolygraphy docs: Polygraphy - Polygraphy 0.49.13 documentation
TensorRT python API docx: https://developer.nvidia.com/docs/drive/drive-os/6.0.6/public/drive-os-tensorrt/api-reference/docs/python/index.html
Q&A
下面是我收集的有关算法细节的部分问题及回答,希望对大家有用哈~
Q: 你好,我看代码加了一个衰减参数保证Temporal的anchor能够尽可能传到下一帧,但是是怎么保证在下一帧中它能够继续传递,而不是由下一帧的top 300个anchor中产生?因为非temporal的部分也是正常产生所有的检测,取topk后也是基本上是当帧所有的检测,temp_gnn是如何保证最后输出的结果是从temporal的600个而不是当前top k的300个anchor产生?我的理解是通过与temporal anchor做cross attention达到隐式去除?但这一部分并没有做一些监督,是如何做到的?
A: 这是一个优化问题,temporal anchor的质量远优于currrent anchor,训练中temporal instance匹配上的概率就会远大于current instance,使得它能稳定跟踪上。而且temporal feature和current feature具备显著差异,所以网络能很轻松的判断哪些是temporal传过来的。cross attention提供了一部分temporal的信息,但不是主要原因。Q: I would like to extract BEV lanes from images, and I was thinking about include a 2D lane detector like YOLO-pv2 along with your model. I was wondering whether you have some transformation matrices that can be exploited to extract 3D/BEV information from lane segmentation on the image. I would like to detect lanes onto the image, and then project them into BEV/3D space if possible?A: To project from 2D to 3D, you need to know the pixel depth, and then utilize the formula
T_cam2lidar * T_img2cam * [u * d, v * d, d], where[u,v]are pixel coordinates,T_img2camis the inverse of the intrinsic matrix, anddis the depth. By the way, with sparse4d, the inverse projection sampling method is employed. This involves first setting 3D points and then projecting them onto 2D sampled features, rather than projecting 2D onto 3D in a direct projection.Q: I found you set the
instance_featuregradient toFalsein thecode. Is that intentional? If it is, may I know what's the reason? Is that because you always want the instance features initialized to be zeros? I also saw a few other places that you set the gradient toFalse, for instance in theKeyPointGeneratorand just to confirm with you, the reason for this False is because it is fix-scale key points, right? A: The input instance feature actually has no physical meaning, and it will not be retained in the computation graph during tracing. The computation graph retains only the key points from the first layer, so we consider the gradient of this instance feature to be unimportant. Disabling the gradient offix_scalefrom our original design intention to fix key points, ensuring that these points can always sample features.
参考
- 算法架构分析:https://zhuanlan.zhihu.com/p/637096473
- Sparse4Dv2: https://arxiv.org/pdf/2305.14018
- High Bandwidth Memory: https://en.wikipedia.org/wiki/High_Bandwidth_Memory
- PyTorch compute grid sample: https://pytorch.org/docs/stable/generated/torch.nn.functional.grid_sample.html
- Pytorch C++ API: https://pytorch.org/cppdocs/
- TensorRT OSS: https://github.com/NVIDIA/TensorRT