文章目录
- 前言
- 流的起源及概念
- Java I/O 流概述
- 字节流
- 字符流
- 转换流
- 缓冲流
- 对象流与序列化
- NIO(New I/O)
- 流的关闭与资源管理
- 本期小知识
前言
这里是分享 Java 相关内容的专刊,每日一更。
本期将为大家带来以下内容:
- 流的起源及概念
- Java I/O 流概述
- 字节流
- 字符流
- 转换流
- 缓冲流
- 对象流与序列化
- NIO(New I/O)
- 流的关闭与资源管理
流的起源及概念
流的概念最早来自于操作系统中的 I/O 操作,尤其是 Unix 系统中“一切皆文件”的设计理念。操作系统将设备、文件、网络等各种数据源和目标统一视为文件。无论是读文件、读设备数据,还是网络通信,操作系统提供了一致的接口。为了让程序员不必关心底层复杂的数据操作,流的概念应运而生,流屏蔽了底层的数据传输细节。
在 Java 中,I/O 流(Input/Output Stream)是对数据传输的一种抽象,程序员通过操作流来读写数据,无需关心数据来自哪里或发送到哪里。流是一种有序的数据传输方式,就像水流一样,数据从源头流向目的地。
什么是流?
流是一个抽象的概念,表示从数据源到目标的 有序、连续、单向 的数据传输。它可以用来处理不同类型的数据,比如文件、网络连接、键盘输入等。Java 的流机制使得处理不同的数据源和目标时,操作非常一致。
流的关键特性:
- 单向性:流只能在一个方向上传输数据,要么是输入流(读数据),要么是输出流(写数据)。
- 顺序性:数据按顺序从源传递到目的地,不允许跳跃式访问。
- 实时性:数据是逐个传输的,程序不需要一次性把所有数据加载到内存中,适合处理大数据量。
Java I/O 流概述
Java 中的 I/O 流主要分为两类:
- 字节流(Byte Stream):以字节为单位读写数据。
- 字符流(Character Stream):以字符为单位读写数据。
此外,Java 还提供了 缓冲流、转换流、对象流 等处理流,进一步提升 I/O 操作的效率和功能。自 Java 1.4 起,还引入了 NIO(New I/O)以增强高效并发操作。
流的其他分类方式:
| 分类依据 | 类别 | 说明 | 示例 |
|---|---|---|---|
| 按数据单位 | 字节流 | 以字节为单位进行数据的读写,适合处理所有类型的数据,尤其是二进制文件(如图片、音频、视频)。 | FileInputStream、FileOutputStream |
| 字符流 | 以字符为单位进行数据的读写,专门处理文本数据,并且可以自动处理字符编码问题。 | FileReader、FileWriter | |
| 按数据方向 | 输入流 | 从数据源读取数据,数据从外部进入程序。 | InputStream、Reader |
| 输出流 | 向目标写入数据,数据从程序流向外部。 | OutputStream、Writer | |
| 按功能分类 | 基本流 | 直接与数据源或目标进行交互的流,进行最基本的读写操作。 | FileInputStream、FileOutputStream |
| 处理流 | 对基本流功能进行增强,提供例如缓冲、编码转换等功能,能够提高性能或简化操作。 | BufferedInputStream、BufferedReader |
字节流
字节流是以 字节 为单位进行数据读写的流,适用于处理所有类型的数据,包括文本文件和二进制文件(如图片、音频、视频等)。字节流不关心数据的内容,仅仅按照字节操作数据。
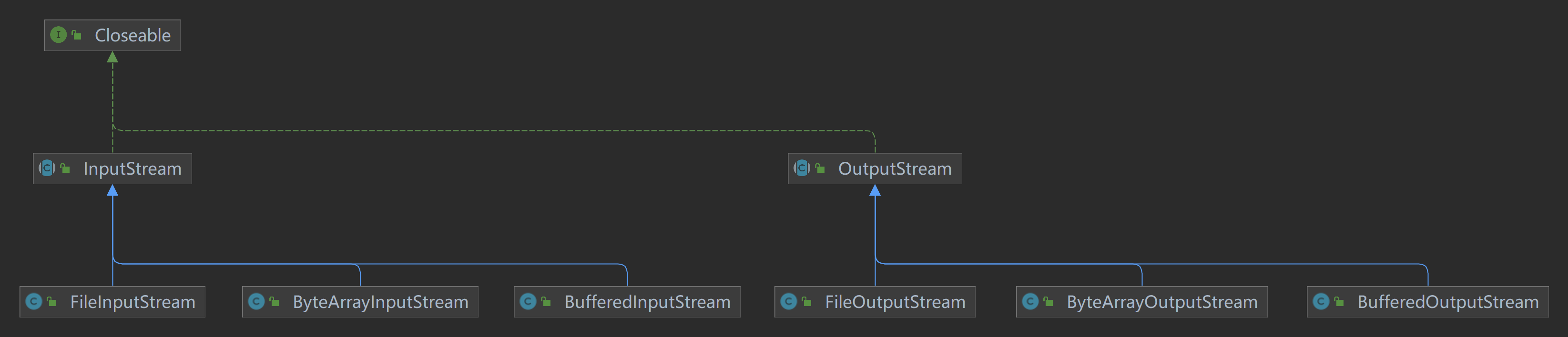
字节流的两个主要抽象类:
InputStream:字节输入流,用于从数据源读取字节数据。OutputStream:字节输出流,用于将字节数据写入目标。
常用子类:
FileInputStream和FileOutputStream:从文件中读取字节数据或向文件写入字节数据。ByteArrayInputStream和ByteArrayOutputStream:在内存中操作字节数组,常用于临时缓冲数据。BufferedInputStream和BufferedOutputStream:为字节流添加缓冲,提高读写效率。
使用字节流读取文件:
try (FileInputStream fis = new FileInputStream("example.txt")) {
// try-with-resources 语法:
// 1. `FileInputStream` 是字节输入流,用于从文件中读取字节数据。
// 2. `new FileInputStream("example.txt")` 打开名为 "example.txt" 的文件,以字节流的方式读取文件内容。
// 3. `fis` 是 FileInputStream 的实例,用来逐字节地读取文件内容。
// 4. try-with-resources 保证了在 try 语句块结束时,流会被自动关闭,避免手动关闭和可能的资源泄漏问题。
int data;
// 定义一个整型变量 `data` 用来存储每次从流中读取到的字节数据。
// `InputStream.read()` 方法每次会返回一个 0 到 255 之间的整数,表示读取到的字节,
// 当读到文件末尾时,`read()` 返回 -1,表示没有更多数据可读。
while ((data = fis.read()) != -1) {
// 循环条件:`fis.read()` 每次从文件中读取一个字节并将其赋值给 `data` 变量。
// 当 `data` 不等于 -1 时,继续读取并处理文件内容;当读取到文件末尾时,退出循环。
System.out.print((char) data);
// 将读取到的字节数据 `data` 强制转换为字符 `(char)` 类型,然后输出到控制台。
// 这对于读取文本文件时是有意义的,能够将字节直接转换为字符并输出。
}
} catch (IOException e) {
// 捕获可能的 I/O 异常,如文件不存在、读取错误等。
e.printStackTrace();
// `e.printStackTrace()` 打印异常的堆栈信息,方便调试和错误定位。
}
在这个例子中,程序逐个字节地读取文件内容并输出。字节流适用于处理非文本文件,比如图片、音频等。
字节流的适用场景:
- 处理二进制文件(如图片、音频、视频等)。
- 需要精确控制数据的字节读写,而不涉及字符编码转换。
字符流
字符流是以 字符 为单位进行数据读写的流,专门用于处理文本数据。字符流能够根据编码规则将字节转换为字符,自动处理字符编码问题。

字符流的两个核心抽象类:
Reader:字符输入流,用于读取字符数据。Writer:字符输出流,用于写入字符数据。
常用子类:
FileReader和FileWriter:用于从文件中读取字符数据或向文件中写入字符数据。BufferedReader和BufferedWriter:带有缓冲功能的字符流,提供高效的读写操作,并支持按行读取或写入文本。
使用字符流按行读取文件:
try (BufferedReader reader = new BufferedReader(new FileReader("example.txt"))) {
// try-with-resources 语法:
// 1. `FileReader` 是字符输入流,专门用于从文件中读取字符数据,这里用于读取 "example.txt" 文件。
// 2. `BufferedReader` 是带缓冲功能的字符输入流,它包装了 `FileReader`,目的是提供更高效的字符读取。
// `BufferedReader` 能够一次性读取较大的块数据,并提供像 `readLine()` 这样的高级方法。
// 3. `reader` 是 `BufferedReader` 的实例,负责从文件中按行读取数据。
// 4. try-with-resources 保证了在 `try` 块结束时,无论是否抛出异常,`reader` 都会被自动关闭,避免资源泄漏。
String line;
// 定义一个字符串变量 `line`,用于存储每次从文件中读取的一行内容。
while ((line = reader.readLine()) != null) {
// 循环条件:`reader.readLine()` 读取文件中的一行文本,并将结果赋值给 `line`。
// 如果 `line` 不为 `null`,则表示读取成功,继续处理;当 `readLine()` 返回 `null` 时,表示已经读到文件末尾,退出循环。
System.out.println(line);
// 将读取到的每一行内容输出到控制台。
}
} catch (IOException e) {
// 捕获可能的 I/O 异常,如文件不存在、读取错误等。
e.printStackTrace();
// `e.printStackTrace()` 输出异常的堆栈跟踪信息,便于调试和定位错误。
}
这个例子展示了如何使用 BufferedReader 按行读取文本文件。字符流可以方便地处理多语言文本文件,自动处理编码转换。
字符流的适用场景:
- 处理文本文件,尤其是多语言文本。
- 需要自动处理字符编码转换的场景,如国际化应用。
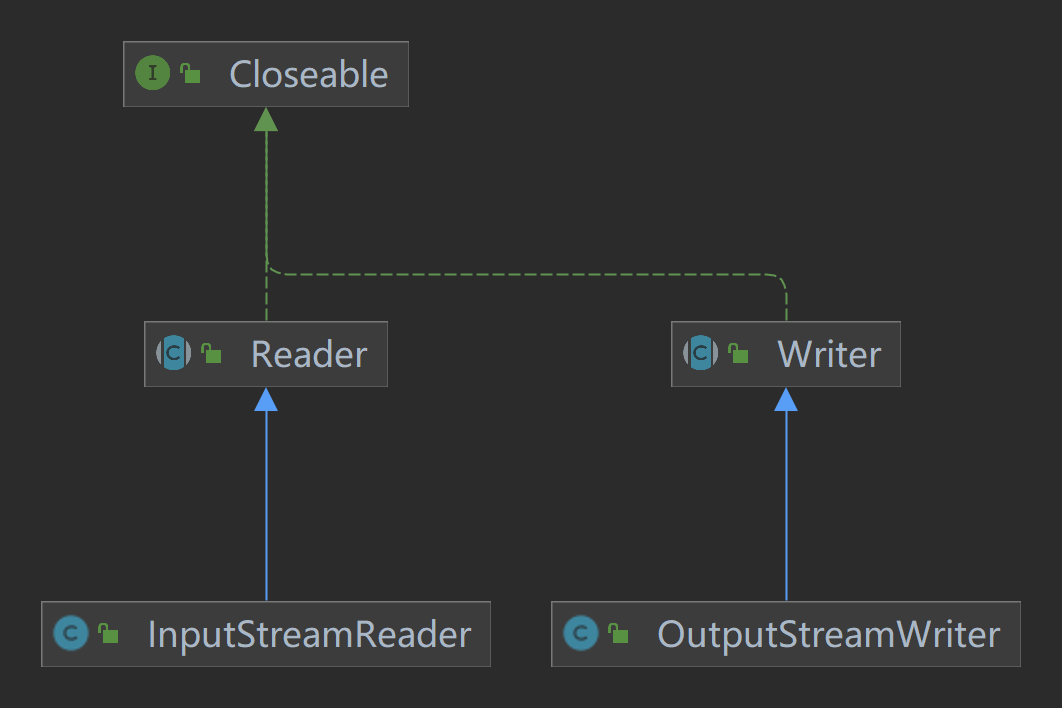
转换流
转换流 用于将字节流转换为字符流,或者将字符流转换为字节流。因为字节流不关心字符编码,而字符流需要根据编码转换字节数据,所以转换流对于处理不同编码格式的文本非常有用。
主要类:
InputStreamReader:将字节输入流转换为字符输入流,可以指定字符编码。OutputStreamWriter:将字符输出流转换为字节输出流,也可以指定字符编码。
使用 InputStreamReader 读取带有编码的文本文件:
try (InputStreamReader isr = new InputStreamReader(new FileInputStream("example.txt"), "UTF-8");
// 1. `FileInputStream("example.txt")`:字节输入流,用于从文件 "example.txt" 中以字节方式读取数据。
// 2. `InputStreamReader` 是一个字节流到字符流的转换流,它将字节流转换为字符流。
// 它接收一个字节输入流(如 `FileInputStream`),并将从中读取的字节按照指定的字符编码("UTF-8")转换为字符。
// 3. `"UTF-8"`:指定字符编码,确保读取的字节数据被正确转换为字符。如果文件内容使用 UTF-8 编码,这样转换能正确处理多字节字符(如中文)。
// 4. `isr` 是 `InputStreamReader` 实例,用于逐字符读取数据。
BufferedReader reader = new BufferedReader(isr)) {
// 5. `BufferedReader` 是带有缓冲区的字符流,用来增强 `InputStreamReader` 的功能。
// `BufferedReader` 一次性读取较大块的字符数据,能显著提高读取性能,尤其适合按行读取数据。
// 6. `reader` 是 `BufferedReader` 实例,用于从流中按行读取文本数据。
String line;
// 定义一个字符串变量 `line`,用于存储每次从文件中读取的一行内容。
while ((line = reader.readLine()) != null) {
// 循环条件:`reader.readLine()` 方法用于从文件中读取一行文本,并将结果赋值给 `line`。
// 如果 `line` 不为 `null`,则表示成功读取到一行内容,继续处理;当读取到文件末尾时,`readLine()` 返回 `null`,循环终止。
System.out.println(line);
// 输出读取到的每一行文本内容到控制台。
}
} catch (IOException e) {
// 捕获可能的 I/O 异常,如文件不存在、读取错误、编码不正确等。
e.printStackTrace();
// `e.printStackTrace()` 会打印出异常的堆栈跟踪信息,便于调试和错误定位。
}
转换流的适用场景:
- 需要处理特定编码格式的文件时,比如从网络下载的文件可能采用不同的编码。
- 在需要将字符数据转换为字节流以进行存储或传输时。
缓冲流
缓冲流 为基本的字节流或字符流添加了缓冲区,从而提高读写效率。它通过减少与底层系统的交互次数来加快数据的处理,尤其是在处理大文件时,缓冲流能够显著提高性能。
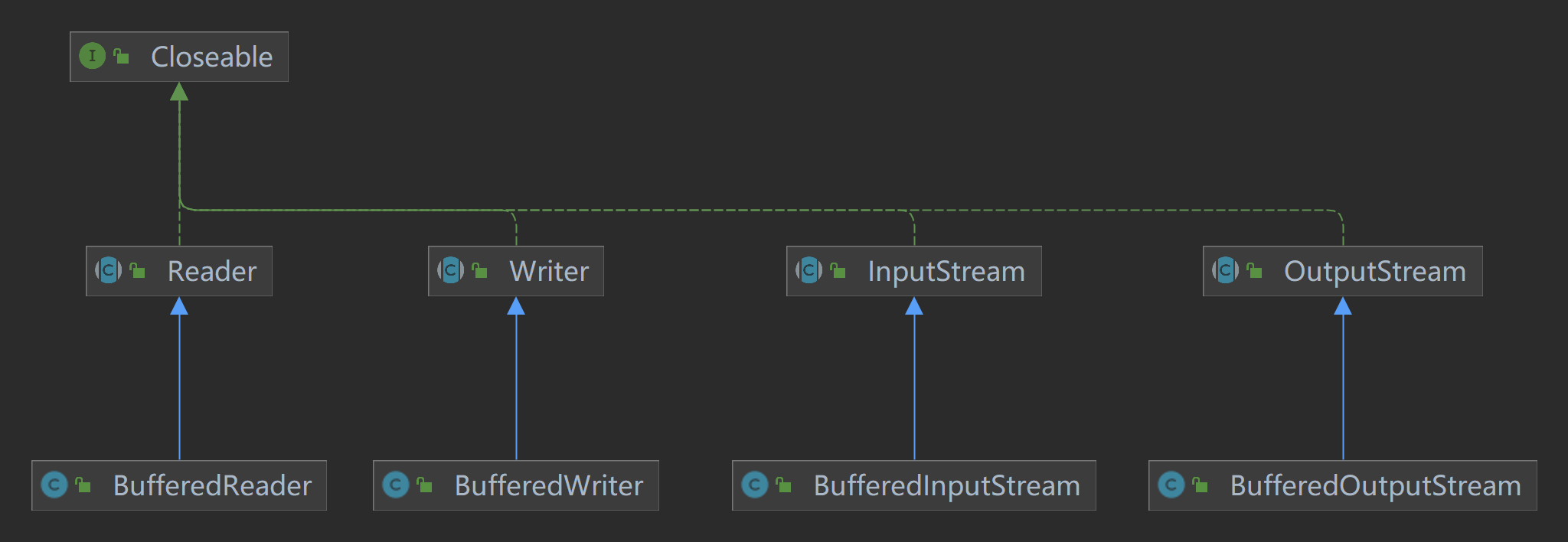
主要缓冲流类:
BufferedInputStream和BufferedOutputStream:为字节流提供缓冲功能,提高字节数据的读写效率。BufferedReader和BufferedWriter:为字符流提供缓冲功能,支持按行读取或写入文本。
使用缓冲流写入数据:
try (BufferedWriter writer = new BufferedWriter(new FileWriter("output.txt"))) {
// 1. `FileWriter("output.txt")`:字符输出流,用于向文件 "output.txt" 写入字符数据。如果文件不存在,会自动创建该文件。
// 2. `BufferedWriter` 是带缓冲区的字符输出流,包装了 `FileWriter`,其作用是通过缓冲区减少对文件的直接写入操作,提高写入效率。
// 3. `writer` 是 `BufferedWriter` 的实例,用于将字符数据写入文件。
// 4. try-with-resources 语法保证在 `try` 块结束时,`BufferedWriter` 会自动关闭,避免资源泄漏。
writer.write("这是缓冲流的写入示例");
// 5. `writer.write()`:通过 `BufferedWriter` 写入一行字符串到文件中。这段代码将 "这是缓冲流的写入示例" 写入到 "output.txt" 文件。
// 字符数据会先写入 `BufferedWriter` 的缓冲区,并在适当的时候(如缓冲区满或者流关闭时)刷新到文件中。
writer.newLine();
// 6. `writer.newLine()`:写入一个行分隔符(通常是换行符,如 `\n`),表示当前行结束,换到下一行。
// `newLine()` 方法可以根据操作系统自动选择合适的换行符,保证跨平台的一致性(如 Windows 上是 `\r\n`,Linux 和 macOS 上是 `\n`)。
writer.write("使用缓冲流可以提高效率");
// 7. `writer.write()`:再次通过 `BufferedWriter` 写入另一行字符串到文件中。
// 这一行写入的是 "使用缓冲流可以提高效率"。
} catch (IOException e) {
// 捕获可能的 `IOException` 异常,例如文件无法创建、写入时发生错误等。
e.printStackTrace();
// `e.printStackTrace()` 打印出异常的详细堆栈跟踪信息,帮助开发者调试和定位问题。
}
缓冲流的适用场景:
- 处理大文件时,减少读写次数,提高效率。
- 需要按行读取或写入文本的场景。
对象流与序列化
对象流 允许 Java 程序将对象进行序列化(即将对象转换为字节流),从而可以将对象写入文件或通过网络传输。序列化的过程是将对象的状态保存为字节序列,而反序列化则是将字节序列恢复为对象。
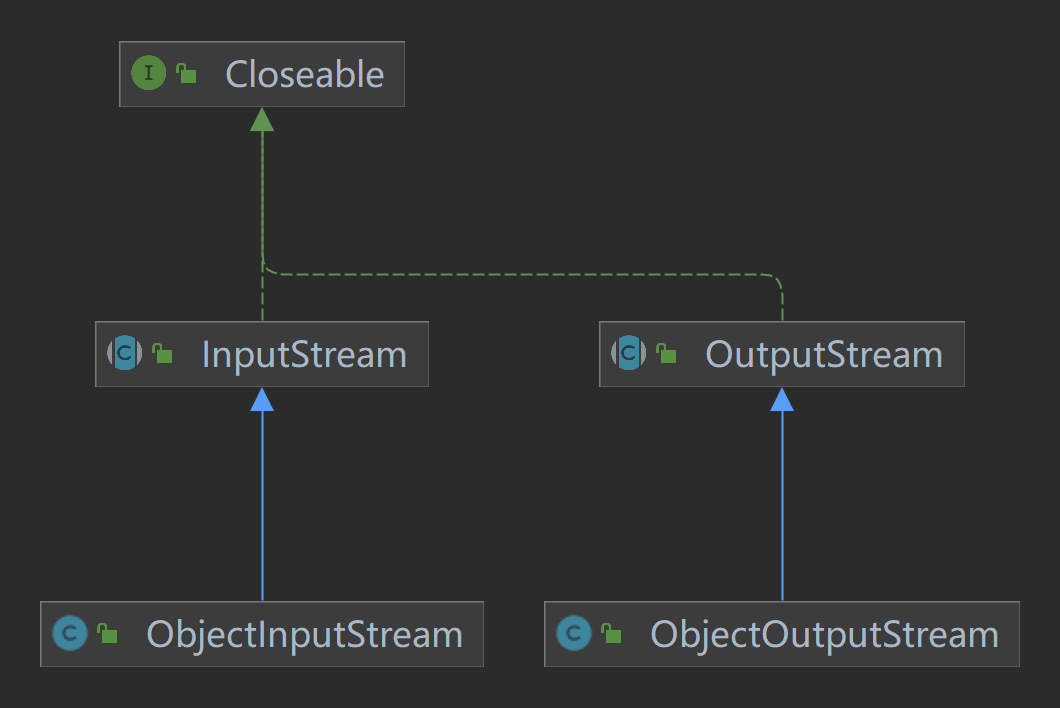
主要类:
ObjectOutputStream:用于将对象序列化并写入输出流。ObjectInputStream:用于从输入流中读取序列化对象并将其反序列化。
对象序列化与反序列化:
// 序列化对象到文件
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("object.dat"))) {
// 1. `FileOutputStream("object.dat")`:字节输出流,用于将数据写入文件 "object.dat"。如果文件不存在,它会自动创建。
// 2. `ObjectOutputStream`:对象输出流,用于将对象转换为字节序列,并将其写入底层输出流(这里是 `FileOutputStream`)。
// 它支持序列化(将对象转换为字节序列,便于存储或传输)。
// 3. `oos` 是 `ObjectOutputStream` 的实例,负责将对象写入文件。
oos.writeObject(new String("对象序列化示例"));
// 4. `oos.writeObject()`:将一个对象写入到 `object.dat` 文件中。
// 这里序列化的对象是 `String` 类型,内容为 "对象序列化示例"。
// 对象序列化的前提是该对象实现了 `Serializable` 接口,而 `String` 类已经实现了该接口。
} catch (IOException e) {
e.printStackTrace();
// 捕获可能的 I/O 异常,例如文件写入错误、权限问题等,并输出异常信息以便调试。
}
// 从文件反序列化对象
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.dat"))) {
// 1. `FileInputStream("object.dat")`:字节输入流,用于从文件 "object.dat" 中读取数据。
// 2. `ObjectInputStream`:对象输入流,用于从输入流中读取字节序列,并将其反序列化为对象。
// 它负责将文件中的字节数据还原为 Java 对象。
// 3. `ois` 是 `ObjectInputStream` 的实例,用于从文件中读取对象。
String str = (String) ois.readObject();
// 4. `ois.readObject()`:从文件中读取对象,并返回一个 `Object`。由于读取的对象是 `String` 类型,
// 需要将其强制转换为 `String` 类型,保存到 `str` 变量中。
// 该操作是反序列化,目的是将字节序列还原为原来的 Java 对象。
System.out.println(str);
// 5. 打印反序列化得到的对象内容,这里会输出 "对象序列化示例"。
} catch (IOException | ClassNotFoundException e) {
// 6. 捕获两个可能的异常:
// - `IOException`:文件读取错误等 I/O 问题。
// - `ClassNotFoundException`:当反序列化时找不到对应的类定义时抛出,例如源文件中的类已被删除或修改。
e.printStackTrace();
// 输出异常信息以便调试。
}
序列化的适用场景:
- 保存对象状态到文件中,便于下次启动时恢复。
- 在网络传输中发送复杂对象。
NIO(New I/O)
NIO 是 Java 1.4 引入的高效 I/O 操作模型,提供了非阻塞 I/O 的支持。它通过通道(Channel)和缓冲区(Buffer)进行数据操作,适合处理高并发和大数据量的场景。
主要组件:
- 通道(Channel):通道是双向的,可以同时进行读写操作。
- 缓冲区(Buffer):用于存储数据,通道与缓冲区配合进行数据传输。
- 选择器(Selector):可以监听多个通道,实现多路复用。
使用 NIO 读取文件:
try (FileChannel fileChannel = FileChannel.open(Paths.get("example.txt"))) {
// 1. `Paths.get("example.txt")`:使用 NIO(New I/O)包中的 `Paths` 类获取文件路径,这里表示文件 "example.txt"。
// 2. `FileChannel.open()`:打开文件通道 `FileChannel`,这是 NIO 中的一种 I/O 通道,用于文件的读写操作。它比传统的 I/O 流更加高效,特别是处理大文件时。
// `FileChannel` 是基于字节的通道,用于从文件中读取或向文件中写入字节数据。
// 3. `fileChannel` 是 `FileChannel` 实例,用于对文件进行读取操作。
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 4. `ByteBuffer.allocate(1024)`:分配一个大小为 1024 字节的 `ByteBuffer`,这是 NIO 中的一个缓冲区,用于暂存从文件中读取的字节数据。
// `ByteBuffer` 是一个字节缓冲区,支持在读取和写入之间切换。
// `buffer` 是 `ByteBuffer` 实例,将用于从文件中读取数据并临时存储。
while (fileChannel.read(buffer) > 0) {
// 5. `fileChannel.read(buffer)`:从文件通道中读取数据,并将数据存入 `buffer` 缓冲区。
// 返回值为读取的字节数,如果文件还未读完,返回值大于 0;如果已读取到文件末尾,返回值为 -1,循环终止。
// 每次读取时,`buffer` 中会填充读取的字节数据。
buffer.flip();
// 6. `buffer.flip()`:将缓冲区从“写模式”切换到“读模式”。在写模式下,数据被写入缓冲区;在读模式下,数据被从缓冲区中读取。
// `flip()` 会将缓冲区的当前位置设置为 0,同时将限制设置为之前写入数据的位置,准备好读取操作。
while (buffer.hasRemaining()) {
// 7. `buffer.hasRemaining()`:检查缓冲区中是否还有未读的字节数据。如果有剩余数据,返回 `true`,否则返回 `false`。
// 循环的目的是读取缓冲区中的所有数据,直到全部读取完。
System.out.print((char) buffer.get());
// 8. `buffer.get()`:从缓冲区中读取一个字节数据,并将缓冲区的当前位置向前移动一位。
// 这里将读取到的字节转换为字符并输出到控制台(假设文件中存储的是文本数据)。
}
buffer.clear();
// 9. `buffer.clear()`:清空缓冲区,准备下一轮的数据读取。`clear()` 并不会真正清除数据,而是将缓冲区的当前位置和限制重置,准备接受新的数据写入。
}
} catch (IOException e) {
e.printStackTrace();
// 捕获 I/O 异常(如文件不存在、读写错误等),并打印异常的堆栈跟踪信息,方便调试和定位问题。
}
NIO 的适用场景:
- 处理大文件的读写。
- 高并发网络编程,如聊天室、服务器应用。
流的关闭与资源管理
流在使用时会占用底层系统资源(如文件句柄、网络连接等),如果不及时关闭,可能导致:
- 资源泄漏:系统资源耗尽。
- 数据丢失:未关闭的输出流可能导致数据未完全写入文件。
- 文件锁定:未关闭的文件流会导致文件无法被其他程序访问。
如何正确关闭流?
- 手动关闭:调用
close()方法,确保在finally中进行。 - try-with-resources:Java 7 引入的特性,自动关闭流。
try (FileInputStream fis = new FileInputStream("example.txt")) {
// 1. `new FileInputStream("example.txt")`:打开名为 "example.txt" 的文件,并创建一个 `FileInputStream` 实例 `fis`。
// `FileInputStream` 是一个字节输入流,用于从文件中读取原始字节数据。如果文件不存在,抛出 `FileNotFoundException`。
// 2. `fis`:`FileInputStream` 实例,表示已经打开的文件,准备进行数据读取操作。
// 在这里可以通过 `fis.read()` 方法读取文件内容,比如读取字节或字节数组等。
// 读取的具体内容并没有显示在此代码中,但 `FileInputStream` 主要用于读取二进制文件(如图片、音频)或简单文本文件的字节数据。
} catch (IOException e) {
// 3. 捕获所有可能的 I/O 异常,如文件读取错误、文件权限问题等。
// `IOException` 是输入/输出异常的父类,处理文件无法读取、流无法打开等问题。
e.printStackTrace();
// 4. `e.printStackTrace()`:打印异常的详细堆栈跟踪信息,帮助开发者定位问题,便于调试。
}
// 5. `try-with-resources`:在 Java 7 引入的一种语法结构,用于自动管理资源。
// 在 `try` 块结束后(无论是否抛出异常),`FileInputStream` 会自动关闭,无需手动调用 `fis.close()`。
// 自动关闭资源避免了资源泄漏的问题,特别是在处理文件或网络连接等资源时。
本期小知识
System.out.println() 是我们最常用的输出语句之一,但实际上它背后使用的是 PrintStream(一种输出流)。System.out 是 PrintStream 的一个静态实例,表示标准输出流,默认指向控制台。你可以将其重定向到文件或其他输出设备。
System.out.println("这行文本会输出到 log.txt 中");