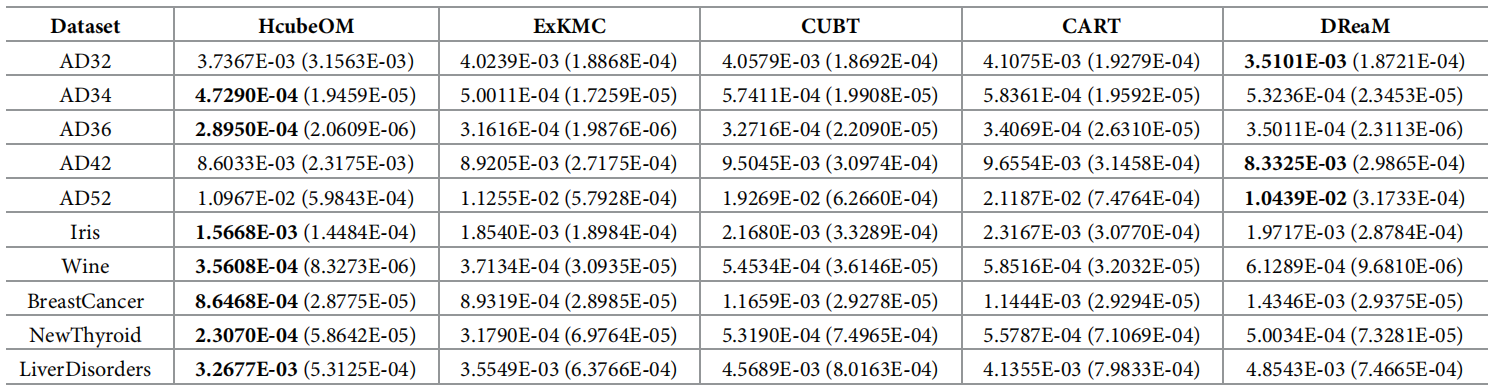
引言
解码器Transformer的规模不断壮大,轻松达到千亿级参数。同时由于该规模,基于提示或微调在各种NLP任务上达到SOTA结果。但目前为止解码器Transformer还无法应用在语义搜索或语句嵌入上。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。
作者提出了SGPT方法来解决这一问题,代码开源在 https://github.com/Muennighoff/sgpt 。
1. 总体介绍
现阶段主要依赖于类似BERT的仅编码器Transformer编码句嵌入以提供语义搜索。因为目前尚未清楚如何从解码器中提取语义嵌入。但这种做法的好处是明显的:
- 性能 解码器的参数量巨大,这有可能产生SOTA结果;
- 节省计算 只需要维护解码器架构,只训练一个大规模解码器并将其重用于搜索可以节省成本;
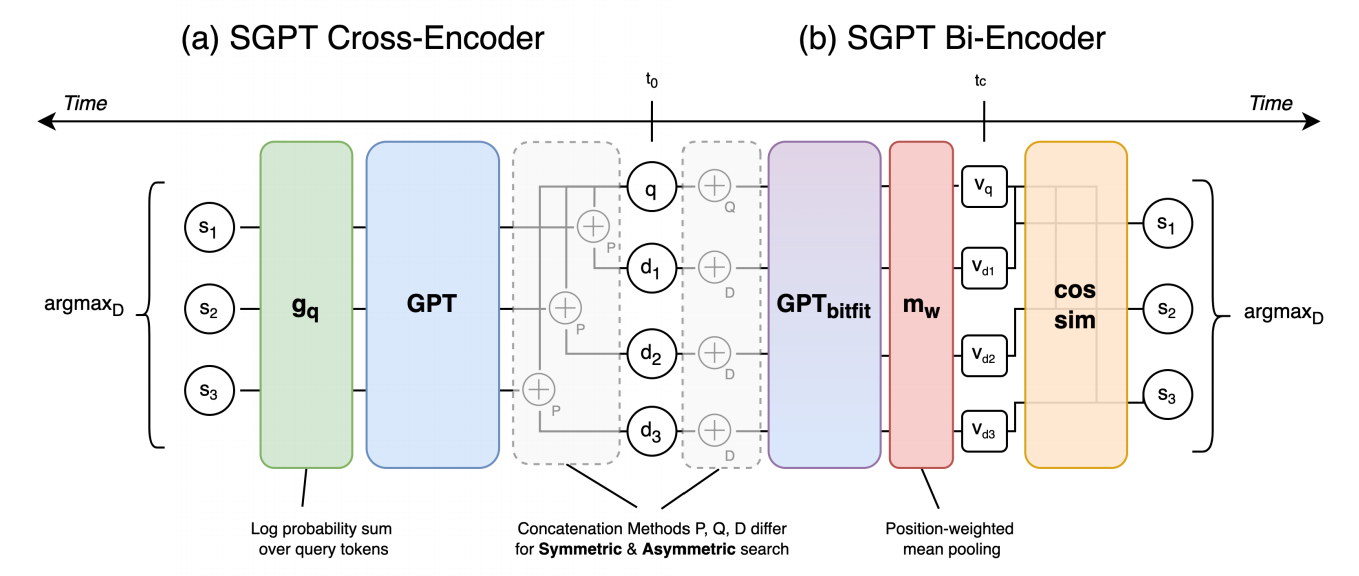
图1: 给定一个查询 q q q,文档 d 1 − 3 d_{1-3} d1−3,SGPT通过分数 s 1 − 3 s_{1-3} s1−3对文档进行排序。(a)Cross-Encoder拼接查询和文档然后一起编码。分数是对数概率。(b)Bi-Encoder分别对查询和文档进行编码,生成的文档向量 v 1 − 3 v_{1-3} v1−3可以缓存起来然后可以在新查询进来的时刻 t c t_c tc被访问。分数是预先相似度。
在本篇工作中,我们提出SGPT将仅解码器应用于语义搜索并提取有语义的句子嵌入。区分四种设置:Cross-Encoder、Bi-Encoder、对称以及非对称。
2. 相关工作
Cross-Encoder同时对查询和文档进行编码。
Bi-Encoder分别对查询和文档进行编码。有研究者提出了一个基于GPT的Bi-Encoder cpt-text。
Cross-Encoder往往优于Bi-Encoder,但速度较慢。
非对称搜索意味着查询和文档不可互换。
对称搜索意味着查询和文档可以互换。
3. SGPT Cross-Encoder
3.1 非对称搜索
给定查询
q
q
q和文档语料库
D
D
D,对最有可能的文档
d
∗
d^*
d∗感兴趣,使用贝叶斯理论可以表示为:
d
∗
=
arg
max
d
∈
D
P
(
d
∣
q
)
=
arg
max
d
∈
D
P
(
q
∣
d
)
P
(
d
)
P
(
q
)
=
arg
max
d
∈
D
P
(
q
∣
d
)
P
(
d
)
(1)
d^* = \arg \max_{d \in D}P(d|q) = \arg \max_{d\in D} \frac{P(q|d)P(d)}{P(q)} = \arg \max _{d \in D} P(q|d)P(d) \tag 1
d∗=argd∈DmaxP(d∣q)=argd∈DmaxP(q)P(q∣d)P(d)=argd∈DmaxP(q∣d)P(d)(1)
由于文档的长度是可变的且计算
P
(
q
∣
d
)
P(q|d)
P(q∣d)比
P
(
d
∣
q
)
P(d|q)
P(d∣q)容易,因此我们给定嵌入提示
P
P
P的文档标记,计算查询标记
q
i
,
⋯
,
n
q_{i,\cdots,n}
qi,⋯,n的联合概率为
p
(
q
i
,
⋯
,
q
n
∣
p
1
,
⋯
,
p
i
−
1
)
p(q_{i},\cdots,q_n|p_1,\cdots,p_{i-1})
p(qi,⋯,qn∣p1,⋯,pi−1)。因为
P
(
d
)
P(d)
P(d)通常在语料库
D
D
D中不会变化,而忽略
P
(
d
)
P(d)
P(d)。
在实践中使用对数概率——模型输出的softmax的对数。
3.2 对称搜索
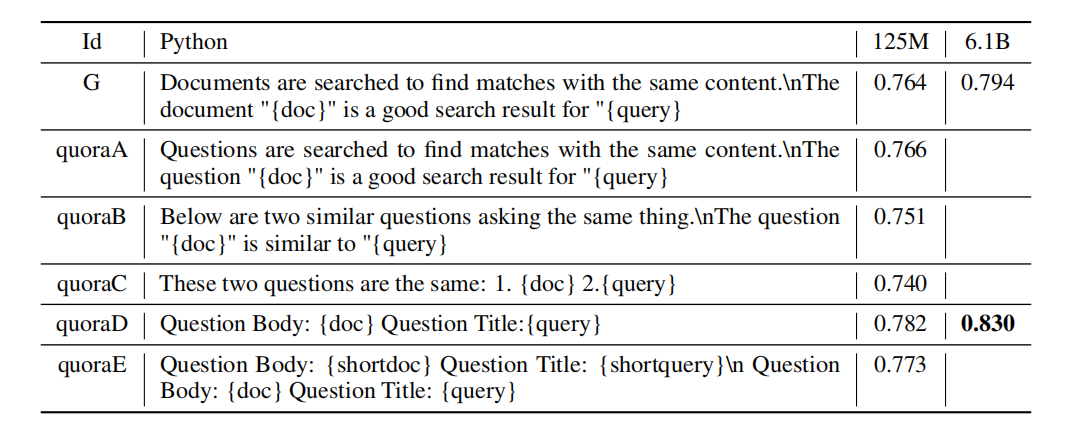
表3: Quora上的SGPE-CE(Cross-Encoder)对称搜索结果。来自{query}的对数概率之和作为重排名分数。从{doc}左侧截断过长的标记。重排名前100的文档,分数为nDCG@10。
使用§3.1中相同的方法,但调整对称搜索的提示。如表3所示。
4. SGPT Bi-Encoder
4.1 对称搜索
由于自回归解码器Transformer的因果注意掩码,即每个位置的token只能感知到其之前的信息。因此,只有最后一个token关注了序列中的所有标记。SGPT提出使用位置加权池化方法为后面的标记赋予更高的权重:
v
=
∑
i
=
1
S
w
i
h
i
where
w
i
=
i
∑
i
=
1
S
i
(2)
v = \sum_{i=1}^S w_ih_i \quad \text{where} \quad w_i = \frac{i}{\sum_{i=1}^S i} \tag 2
v=i=1∑Swihiwherewi=∑i=1Sii(2)
S
S
S是序列长度;
h
i
h_i
hi是第
i
i
i个隐藏状态;
v
v
v是查询或文档嵌入。
我们将加权均值池化与最后一个标记池化进行比较,其中最后一个标记的隐藏状态是嵌入或常规的均值池化。
使用批内负样本进行监督对比学习,给定查询-文档对
{
q
(
i
)
,
d
(
i
)
}
i
=
1
M
\{q^{(i)},d^{(i)}\}_{i=1}^M
{q(i),d(i)}i=1M,优化损失函数:
J
CL
(
θ
)
=
1
M
∑
i
=
1
M
log
exp
(
τ
⋅
σ
(
f
θ
(
q
(
i
)
)
,
f
θ
(
d
(
i
)
)
)
)
∑
j
=
1
M
exp
(
τ
⋅
σ
(
f
θ
(
q
(
i
)
)
,
f
θ
(
d
(
j
)
)
)
)
(3)
J_\text{CL}(\theta) = \frac{1}{M} \sum_{i=1}^M \log \frac{\exp(\tau \cdot \sigma(f_\theta(q^{(i)}), f_\theta(d^{(i)})))}{\sum_{j=1}^M \exp(\tau \cdot \sigma(f_\theta(q^{(i)}), f_\theta(d^{(j)})))} \tag 3
JCL(θ)=M1i=1∑Mlog∑j=1Mexp(τ⋅σ(fθ(q(i)),fθ(d(j))))exp(τ⋅σ(fθ(q(i)),fθ(d(i))))(3)
f
θ
f_\theta
fθ是SGPT模型,输出固定大小的向量;
σ
\sigma
σ是余弦相似度;
τ
\tau
τ是一个温度参数,设为
20
20
20,相当于除以
0.05
0.05
0.05。在训练和推理期间,将序列长度限制为75个标记。
4.2 非对称搜索
遵守§4.1中同样的设置。对于非对称搜索,将模型序列长度限制为300个标记。增加括号使模型区分查询和文档,将查询 q q q的标记增加两个中括号作为 [ q 0 − n ] [q_{0-n}] [q0−n],文档使花括号 { d 0 − n } \{d_{0-n}\} {d0−n}。
5. 结论
这篇工作介绍了SGPT,提出对GPT模型进行修改,将它们用于语义搜索的Cross-或Bi-编码器。
SGPT-BE使用位置加权均值得到最先进的句子嵌入,可以用于语义搜索或其他嵌任务。
SGPT-CE提取预训练GPT模型的对数概率产生无监督的最先进的搜索结果,但只能用于语义搜索。
B任务和实验细节
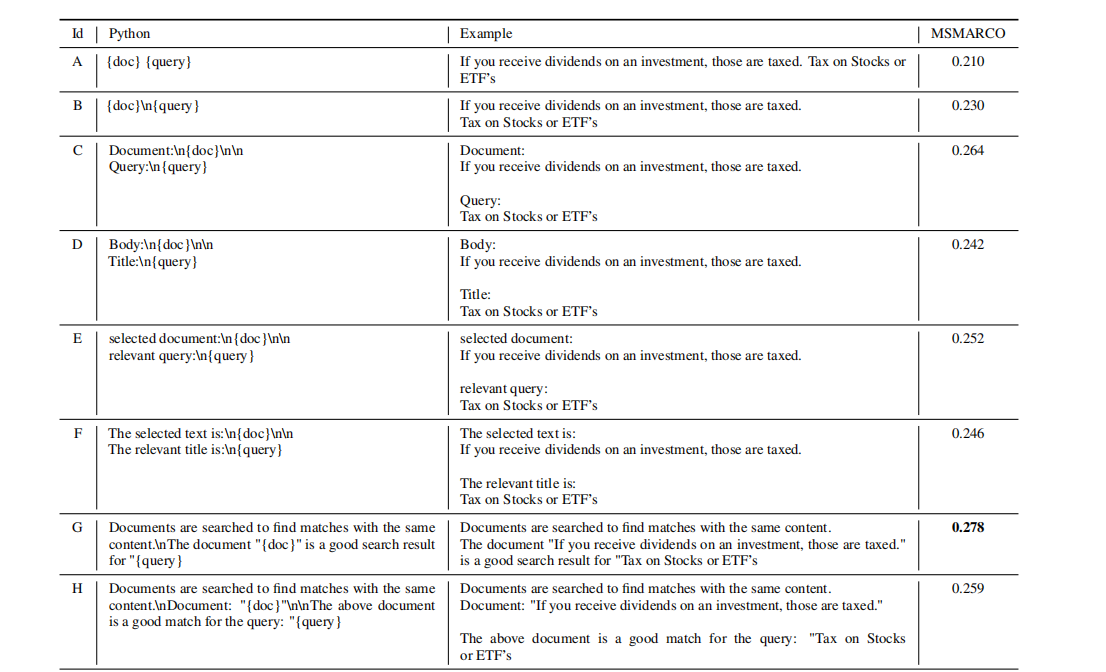
B.1 提示

总结
⭐ 作者提出了利用仅编码器的类GPT架构来产生句子嵌入以支持语义检索和其他嵌入任务。在Bi-Encoder设置中,使用位置加权平均池化来得到具有语义信息的句子嵌入。在Cross-Encoder设置中,提取预训练GPT模型的对数概率产生无监督结果。