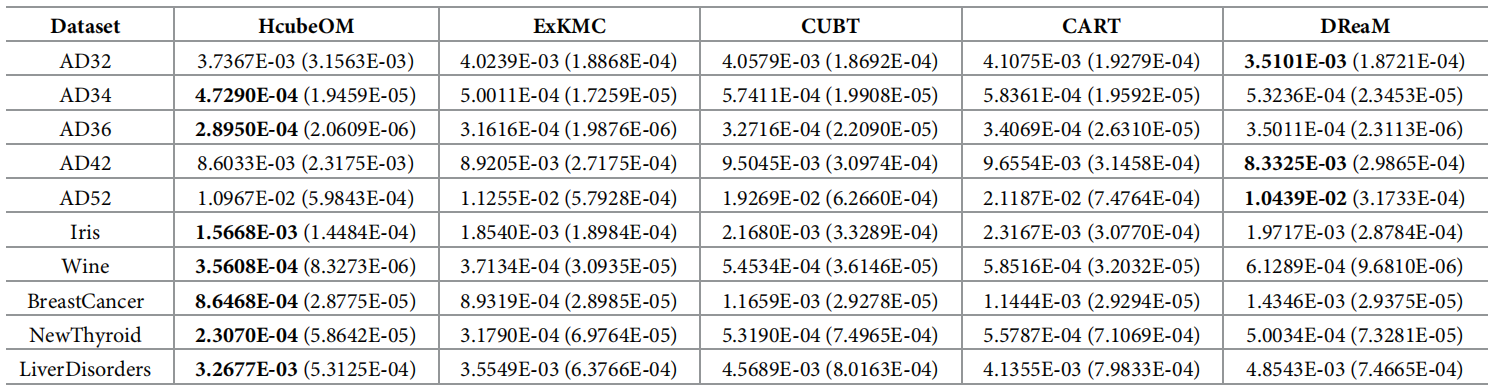
参考书籍:《数据流挖掘与在线学习算法》 李志杰
1.6.1 实验目的
本书内容以及课程实验主要涉及Java程序设计语言、数据挖掘工具Weka和数据流机器学习平台MOA,因此,需要安装、配置并熟悉实验环境。Java、Weka和MOA都是开源小软件,简单易用,都可以在个人电脑的这些实验环境下完成。
1.6.2 实验环境
(1) 操作系统:Windows 10
(2) Java:1.8.0_181-b13
(3) Weka:3.8.4
(4) MOA:release-2020.07.1
1.6.3 安装平台
(1) Java安装与配置
最新标准版Java 可从Oracle官方网站https://www.oracle.com/免费下载,如下图所示。
安装JDK后,必须配置PATH环境变量和CLASSPATH环境变量才能使用,操作如下。
右击“我的电脑”→属性→高级系统设置→环境变量,如图所示进行配置。
下图中,JAVA_HOME配置为JDK安装路径:C:/Program Files/Java/jdk1.8.0-181。Java的PATH环境变量和CLASSPATH环境变量直接加在后面,每项用“ ;”隔开。CLASSPATH最前面的“.”表示当前路径。
配置完成后,点击“开始”→Windows系统→命令提示符,输入:javac。如无错误提示,则配置成功。


(2) Eclipse集成开发环境
Eclipse是常用的Java集成开发环境,可以从官网http://www.eclipse.org/downloads/免费下载。
(3) Weka安装
安装配置好Java后,可以从官网http://www.cs.waikato.ac.nz/~ml/weka/免费下载Weka。也可从本书官网“下载专区”目录下获得weka-3-8-4-azul-zulu-windows安装文件。
安装完成后,安装路径的data子目录下自带23个ARFF格式的示例数据集。

(4) MOA安装
MOA基于Java和Weka环境,可从官方网站https://moa.cms.waikato.ac.nz/免费下载。也可从本书官网“下载专区”目录下获得MOA压缩文件moa-release-2020.07.1-bin。
MOA压缩包中包括moa.jar和sizeofag.jar等文件,无须安装。解包后双击子目录bin/moa.bat,即可启动MOA。

1.6.4 平台操作
(1) Weka图形用户界面
启动Weka,单击探索者Explorer按钮,Weka GUI如图1.37所示。加载一个数据集weather.nominal.arff,标签页Preprocess(预处理)、Classify(分类)、Cluster(聚类)、Associate(关联分析)、Select attributes(属性选择)、Visualize(可视化)等都变为可以使用。
(2) Eclipse环境下Weka API操作
除了GUI外,Weka还定义了应用程序编程接口API,很容易“嵌入”到Eclipse用户自己的Java项目中。
在Eclipse中新建一个名为Weka的项目,右击Weka,点击Properties,Java Build Path→Libraries→Add External JARs,选中Weka安装目录下的weka.jar,添加到库中,如图所示。

以加载weather.nominal.arff和weather.numeric.arff为例,示例代码见程序清单1.1。
程序清单1.1 加载ARFF文件
package weka;
import weka.core.Instances;
import weka.core.converters.ArffLoader;
import weka.core.converters.ConverterUtils.DataSource;
import java.io.File;
public class LoadArffFile {
public static void main(String[] args) throws Exception {
Instances data1=DataSource.read("C:/Program Files/Weka-3-8-4/data/weather.nominal.arff");
System.out.println(data1);
ArffLoader loader=new ArffLoader();
loader.setSource(new File("C:/Program Files/Weka-3-8-4/data/weather.numeric.arff"));
Instances data2=loader.getDataSet();
System.out.println(data2);
}
}(3) MOA图形用户界面
双击MOA子目录bin下moa.bat文件,即可启动MOA GUI。如图所示,通过点击Configure来设置某项任务。

(4) Eclipse环境下MOA API操作
与Weka类似,除了GUI外,MOA还定义了应用程序编程接口API,很容易“嵌入”到Eclipse用户自己的Java项目中。
在Eclipse中新建一个MOA的项目,右击该项目,点击Properties,Java Build Path→Libraries→Add External JARs,选中下载包中的moa.jar和sizeofag.jar等文件,添加到库中,如图所示。

B 实验1报告-2 数据分类
2.5.1 实验目的
(1) 理解有监督数据分类原理与过程。
(2) 熟悉Weka分类操作。
(3) 熟悉MOA分类操作。
2.5.2 实验环境
(1) 操作系统:Windows 10
(2) Java:1.8.0_181-b13
(3) Weka:3.8.4
(4) MOA:release-2020.07.1
2.5.3 Weka分类
(1) 使用C4.5算法分类器
C4.5算法在Weka中实现为J48分类器,下面在Weka平台中使用J48分类器训练weather.nominal.arff数据集。

启动Weka→Explorer→Open file→weather.nominal.arff→Classify→Choose→trees→J48→Start,训练集构建J48分类器模型如上图所示。
右击图2.10的Result list区域中新生成条目→Visualize tree,弹出下图所示的决策树视图窗口。

(2) 使用分类器预测未知数据
构建图2.12所示的测试数据集test.arff,使用图2.11的决策树进行预测。
 图2.10的Test options区域,点击Supplied test set→Set→Open file→test.arff→Close→More options→Choose→PlainTest→OK→Start,则启动评估过程后,会发现多了一项测试集的预测结果,如下图所示。结果表明,测试集三个实例,其中两个预测正确,一个预测错误。
图2.10的Test options区域,点击Supplied test set→Set→Open file→test.arff→Close→More options→Choose→PlainTest→OK→Start,则启动评估过程后,会发现多了一项测试集的预测结果,如下图所示。结果表明,测试集三个实例,其中两个预测正确,一个预测错误。

(3) 构建J48批量分类器
本示例用Java代码构建一个J48批量分类器,示例代码见程序清单2.1。
程序清单2.1构建J48批量分类器
import weka.classifiers.trees.J48;
import weka.core.Instances;
import weka.core.converters.ArffLoader;
import java.io.File;
public class J48Classifier {
public static void main(String[] args) throws Exception {
ArffLoader loader=new ArffLoader();
loader.setFile(new File("C:/Program Files/Weka-3-8-4/data/weather.nominal.arff"));
Instances data=loader.getDataSet();
data.setClassIndex(data.numAttributes()-1);
String[] options=new String[1];
options[0]="-U";
J48 tree=new J48();
tree.setOptions(options);
tree.buildClassifier(data);
System.out.println(tree);
}
}在Eclipse中运行代码,输出训练好的决策树模型,如下图所示。

2.5.4 MOA分类
(1) 使用NaiveBayes分类器
① LearnModel
启动MOA→Classification→Configure→tasks.LearnModel。
选择:learner→bayes.NaiveBayes,stream→WaveformGenerator,maxInstances→1000000,taskResultFile→modelNB.moa。
点击Run,则NaiveBayes模型存储到modelNB.moa中。
② EvaluateModel
点击Configure→tasks.EvaluateModel。
选择:stream→WaveformGenerator→instanceRandomSeed→2,maxInstances→1000000,然而,model无法选择到modelNB.moa,所有这里我们需要自己创建一个modelNB.moa。
点击“确定”返回到Configure→右击命令行→Copy configuration to clipboard→Enter configuration→编辑配置-m file: modelNB.moa。任务命令行变为:EvaluateModel -m file:modelNB.moa -s (generators.WaveformGenerator -i 2) -i 1000000。
点击Run运行。由于输出频率为100000步,中间面板有10项文字输出,结果如下图所示。

③ EvaluatePeriodicHeldOutTest
点击Configure→tasks. EvaluatePeriodicHeldOutTest。
选择:learner→bayes.NaiveBayes,stream→WaveformGenerator,testSize→100000,trainSize→10000000,sampleFrequency→1000000。
点击Run运行。从下图可看到,中间面板有10项文字输出,底部面板显示最终统计与可视化结果。最终的准确率是80.48%。

④ EvaluateInterleavedTestThenTrain
点击Configure→tasks. EvaluateInterleavedTestThenTrain。
选择:learner→bayes.NaiveBayes,stream→WaveformGenerator,instanceLimit→1000000,sampleFrequency→10000。
点击Run运行。从下图可看到,中间面板有100项文字输出,底部面板显示最终统计与可视化结果。最终的准确率是80.47%。

⑤ EvaluatePrequential
点击Configure→tasks. EvaluatePrequential。
选择:learner→bayes.NaiveBayes,stream→WaveformGenerator,evaluator→WindowClassificationPerformanceEvaluator→width→1000,instanceLimit→1000000,sampleFrequency→10000。
点击Run运行。从下图可看到,中间面板有100项文字输出,底部面板显示最终统计与跳跃的锯齿形可视化结果。最终的准确率是80.30%。

(2) 使用Hoeffding树分类器
① 使用EvaluateModel嵌套LearnModel评估Hoeffding树
点击Configure→tasks.EvaluateModel。
选择:model→tasks.LearnModel→learner →trees. HoeffdingTree→stream→WaveformGenerator→maxInstances→1000000,stream→WaveformGenerator→instanceRandomSeed→2,maxInstances→1000000。
点击“确定”返回到Configure。任务命令行为:EvaluateModel -m (LearnModel -l trees.HoeffdingTree -s generators.WaveformGenerator -m 1000000) -s (generators.WaveformGenerator -i 2) -i 1000000 -f 10000。
点击Run运行,结果如下图所示。

② EvaluatePeriodicHeldOutTest、EvaluateInterleavedTestThenTrain和EvaluatePrequential
与NaiveBayes类似,Hoeffding树也可以分别使用数据流三种评估方式:EvaluatePeriodicHeldOutTest(在一个保留测试集上周期性截取性能快照)、EvaluateInterleavedTestThenTrain(交错式测试-训练评估法)和EvaluatePrequential(先序评估法)。评估Hoeffding树具体操作与上面(1)中NaiveBayes的操作类似。
事实上,MOA GUI底部可同时显示当前任务和之前任务的可视化结果,当前任务为红色,之前任务为蓝色。因此,比较NaiveBayes与Hoeffding树分类器性能非常方便和直观。
C 实验1报告-3 数据聚类
3.9.1 实验目的
(1) 理解无监督数据聚类原理与过程。
(2) 熟悉Weka聚类操作。
(3) 熟悉MOA聚类操作。
3.9.2 实验环境
(1) 操作系统:Windows 10
(2) Java:1.8.0_181-b13
(3) Weka:3.8.4
(4) MOA:release-2020.07.1
3.9.3 Weka聚类
聚类属于典型的的无监督学习方式,聚类对象是没有标签的实例或数据点。聚类的任务是要根据实例间的相似性进行分组,之前这些分组是未知的。
(1) 使用K-Means算法聚类
K-Means算法又称为K均值算法,是一种对数据集进行批量聚类的无监督学习算法。它依靠数据点彼此之间的距离远近对其进行分组,将一个给定的数据集分类为k个聚类。算法不断进行迭代计算和调整,直到达到一个理想的结果。K-Means算法在Weka平台实现为SimpleKMeans。
SimpleKMeans算法有两个重要参数,一个是distanceFunction,默认EuclideanDistance ;另一个是numClusters,默认值2。
下面以weather.numeric.arff数据集为例,使用SimpleKMeans算法聚类操作。聚类结果如图3.15所示。
启动Weka→Explorer→Open file→weather.numeric.arff→Cluster→Choose→SimpleKMeans→Ignore attributes→play→Select。
单击Start,聚类过程开始。

(2) 使用DBSCAN和OPTICS算法
这里我们的waka里面是没有这两个算法的,需要自己导包进去
导包过程参考:向weka 中添加DBSCAN算法_weka dbscan-CSDN博客
DBSCAN是经典的密度批量聚类算法,其基本思想是邻域内含有大量点的核心点构建聚类。算法以任意顺序访问数据点,如果该点为核心点,则该点与其所有可达的数据点形成新的聚类。非核心点则标为“离群值”,直到有一个新的核心点与“离群值”可达,“离群值”才加入该聚类。
DBSCAN密度方法可以聚类非球形形状的数据,这是K -均值聚类方法难以做到的。OPTICS算法则在层次聚类方面扩展了DBSCAN算法。
以鸢尾花数据集为例,使用Weka平台的DBSCAN和OPTICS算法,操作和显示结果如下。
启动Weka→Explorer→Open file→iris.arff→Cluster→Choose→DBSCAN,选择了DBSCAN聚类算法。
点击Choose右边DBSCAN的文本框→参数epsilion=0.2→参数minPoints=5→OK。
点击Ignore attributes→class→Select。
单击Start,DBSCAN聚类结果如下图所示。

使用OPTICS对鸢尾花数据集聚类,操作过程类似于DBSCAN。
选择OPTICS聚类算法后,设OPTICS参数epsilion=0.2、minPoints=5。
单击Start运行,OPTICS可视化窗口自动弹出,窗口包括Table和Graph两个标签,分别以表格和图形显示聚类结果。
下图的图形标签页中,峰值中间夹着的两个山谷,对应OPTICS找到的两个簇。