可解释聚类是机器学习领域一个非常重要的研究方向,它通过引入解释性强的特征和模型,让我们更直观地理解聚类结果,从而提升聚类分析的准确性和可靠性。
这种方法在一些敏感领域如医疗、金融等非常适用,因为它与传统方法不同,不仅关注聚类结果的准确性和效率,还强调了对聚类结果形成机制的理解,而这对增强模型信任度、优化决策过程非常有效。
但如今的可解释聚类依然存在很多问题没有解决,不过也说明了这个方向创新空间大、可挖掘idea多,如果有同学想发论文,这也是个不错的研究方向。
另外,推荐找思路的各位从现有的三类可解释聚类方法(聚类前、聚类中、聚类后)入手,比较成熟,参考多。这里为了给大家省一些查找资料的时间,我根据这三类方法整理了11篇可解释聚类论文,基本都是最新的,希望可以给大家的论文添砖加瓦。
论文原文合集需要的同学看文末
模型构建阶段(聚类中)
An exemplars-based approach for explainable clustering: Complexity and efficient approximation algorithms
方法:作者通过解释性AI在无监督学习中最小化聚类直径,结合深度嵌入生成易于理解的代表性实例,以解决传统特征解释在现代非可解释特征情境下的不足,通过实验验证其在文本和面部数据上生成的实例在解释复杂模型方面的有效性和实用性。
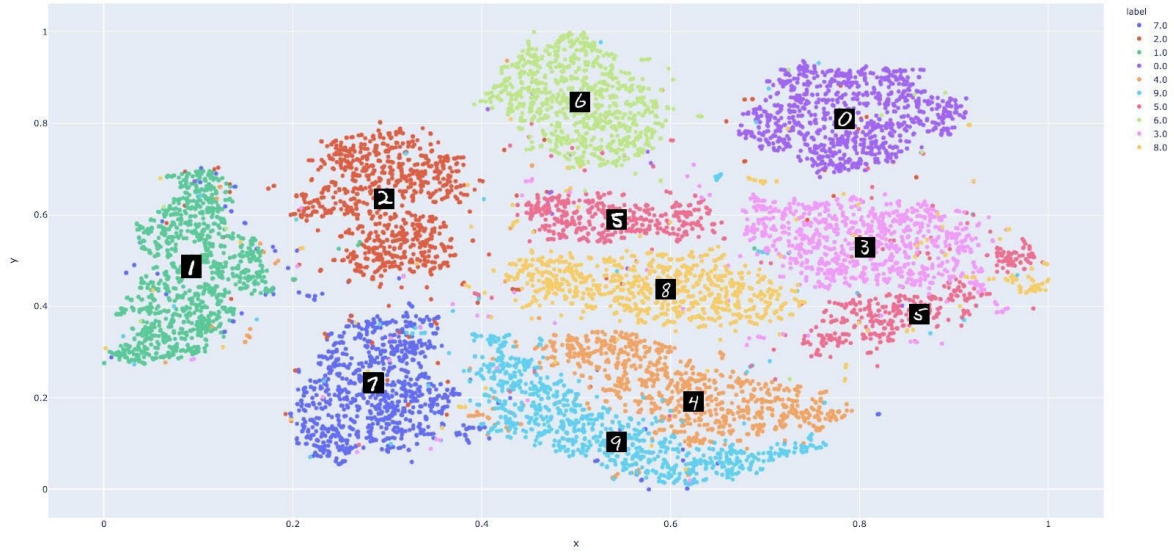
创新点:
-
提出了一种通过示例进行解释的聚类算法,解决了传统聚类算法无法生成示例的问题。
-
结合聚类质量和解释质量,将二者的参数统一简化为一个参数,便于操作。
-
开发了多项式时间近似算法,提供了群集直径和使用示例数量的可证明性能保证。
Interpretable clustering: an optimization approach
方法:论文开发了一种新的基于树的无监督学习方法,称为ICOT,以解决可解释性聚类的问题。ICOT通过使用MIO框架来创建全球最优的聚类树,提高了算法的可解释性,并在Silhouette Metric和Dunn Index上提供了显著的性能改进。
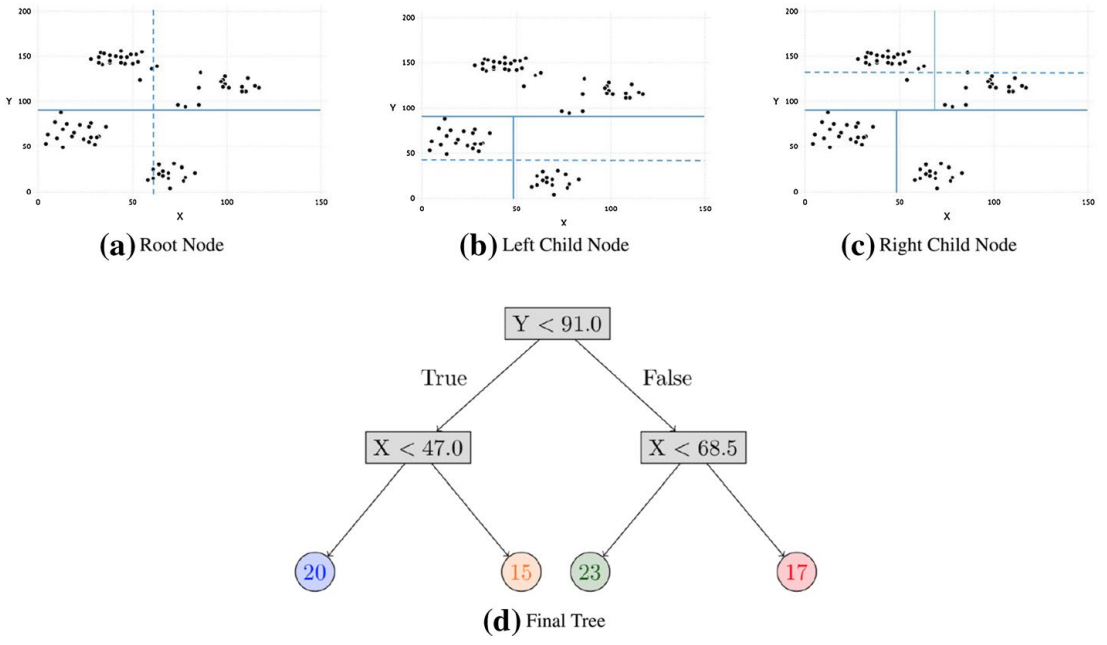
创新点:
-
提出了一种基于混合整数优化(MIO)的无监督学习问题公式,开发了新的算法ICOT,实现全局最优的聚类树构建。
-
提出了新的加权距离度量方法,有效处理混合数值和分类数据,防止单一变量类型主导距离计算。
-
开发了无需调节树的复杂度的算法,损失函数同时考虑了类内密度和类间分隔。
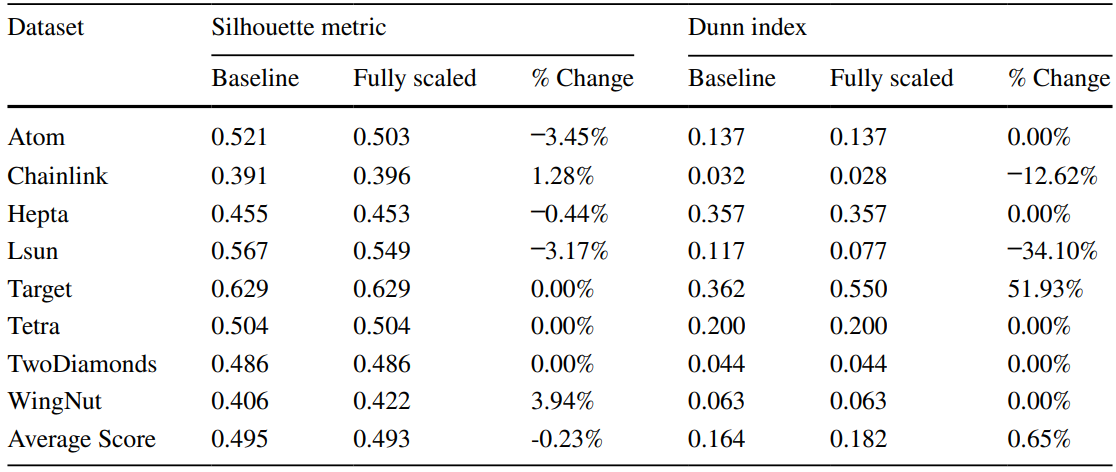
模型解释阶段(聚类后)
Explainable k-means and k-medians clustering
方法:论文开发一种名为“迭代错误最小化”的算法(IMM),通过构建带有k个叶子的阈值树来近似k-均值或k-中值聚类。算法通过动态规划有效地寻找分割点,目标是最小化每个节点的错误数。

创新点:
-
提出了基于阈值树的聚类方法,使得聚类结果更易解释。
-
通过使用小型决策树来划分数据集,使得每个簇的分配可以通过少量特征进行解释。
-
开发了一种高效的迭代错误最小化算法,生成具有 k 个叶子的阈值树,作为聚类的可解释近似。
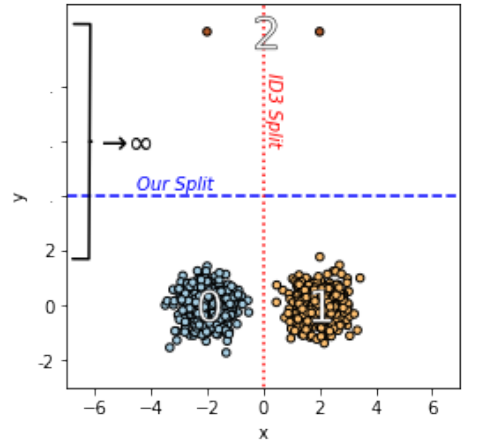
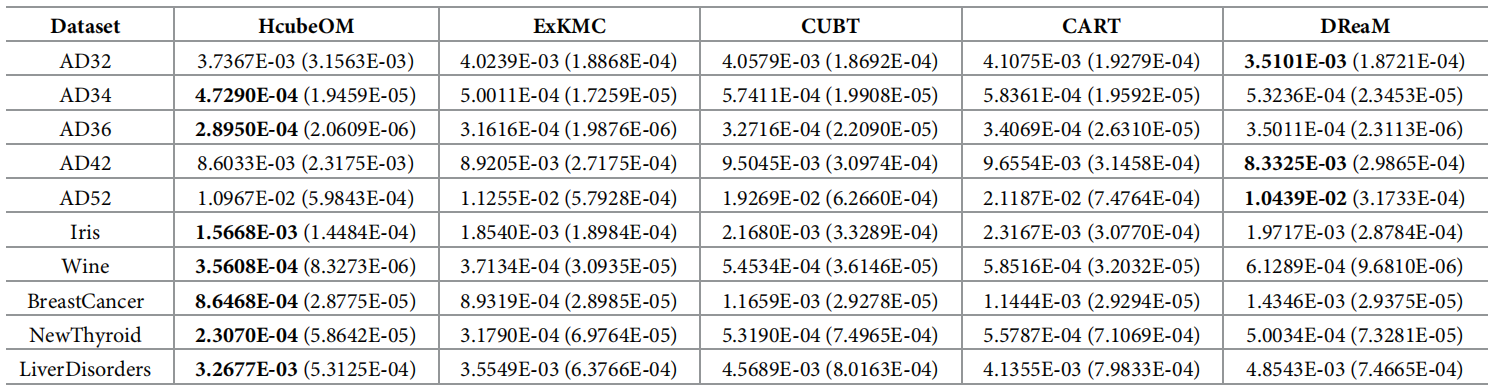
Explanation of clustering result based on multi-objective optimization
方法:本文提出了一种基于多目标优化的超立方体叠加模型(HcubeOM),旨在通过优化叠加方案生成聚类结果的简洁解释,填补现有模型解释性不足的研究空白;该方法通过设计两个目标函数以确定每个聚类的最优超立方体覆盖方案,并通过实验验证其在解释简洁性和一致性方面的优越性。
创新点:
-
提出了一种基于多目标优化的聚类结果解释框架,使用多个超立方体覆盖每个聚类的结果,并通过整合超立方体的特征生成每个聚类的解释。
-
设计了两个目标函数,用于确定每个聚类的超立方体覆盖方案。一个目标是确定超立方体的最佳数量,另一个目标是优化超立方体的紧凑性和重叠最小化。
-
设计了一种简洁性指标,用于验证每个聚类生成的解释的性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“可解释聚类”获取全部论文合集
码字不易,欢迎大家点赞评论收藏