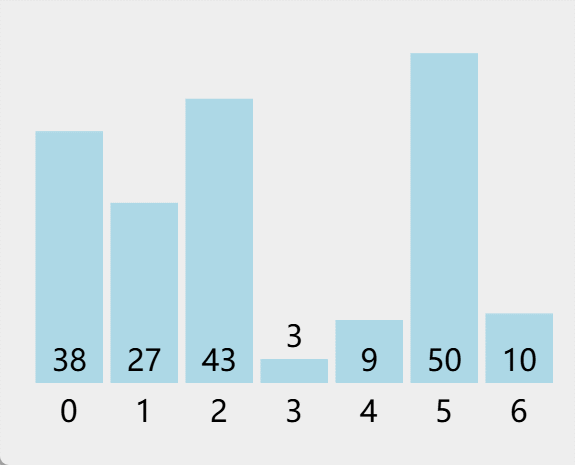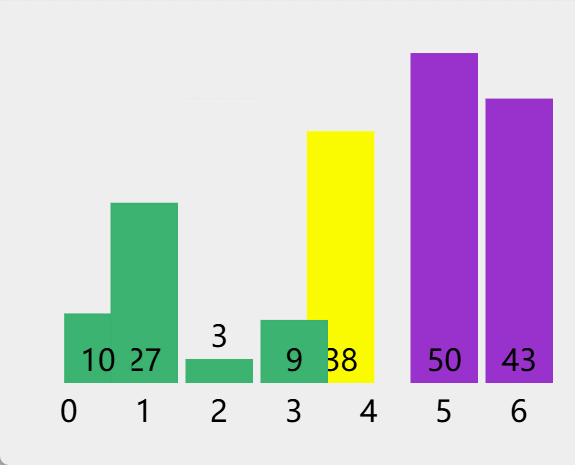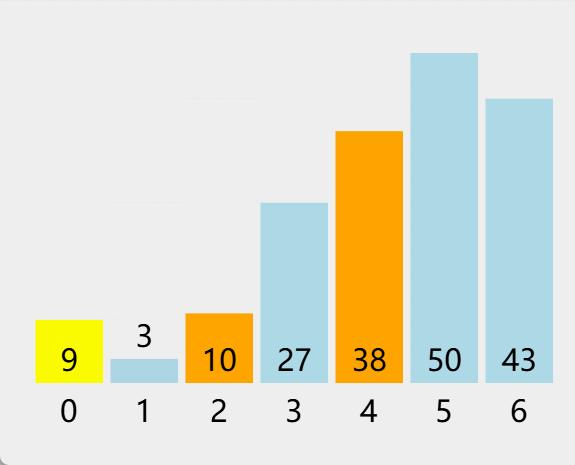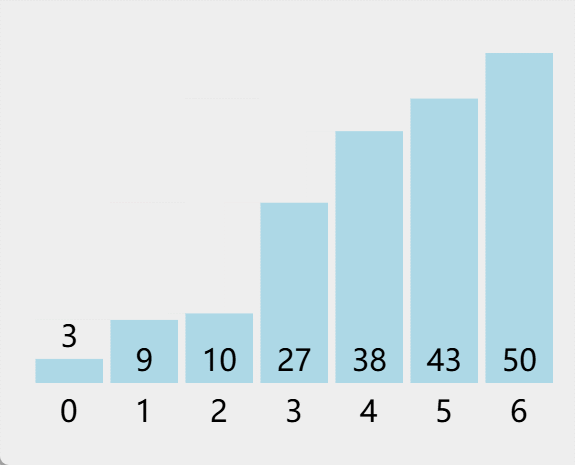文章目录
- 一.什么是多级缓存?
- 1.本地缓存
- 2.远程缓存
- 3.缓存层级
- 4.加载策略
- 二.适合/不适合的业务场景
- 1.适合的业务场景
- 2.不适合的业务场景
- 三.Redis与Caffine的对比
- 1. 序列化
- 2. 进程关系
- 四.各本地缓存性能测试对比报告(官方)
- 五.本地缓存Caffine如何使用
- 1. 引入maven依赖:
- 2.关于Caffine的各api操作介绍
- 六.多级缓存方案与实现思路
- 七.小结
一.什么是多级缓存?
多级缓存技术是一种通过多个层次的缓存来提高数据访问速度和降低延迟的策略。多级缓存通过在不同层次上缓存数据来减少对底层存储系统的访问次数,提高系统的整体性能。在Java中,常见的多级缓存结构包括:本地缓存与远程缓存。
1.本地缓存
Caffeine/Guava/jdk下的线程安全Map等等,因为Caffine性能最高,我这里本地缓存都代指Caffine。在应用程序的内存中存储数据,访问速度极快,但容量有限。
Caffeine是一个基于Java 8的高性能缓存库,它提供了高性能、高命中率、低内存占用的特性,被誉为最快的缓存之一
Caffeine是一个基于Java 8的高性能缓存库,它提供了高性能、高命中率、低内存占用的特性,被誉为最快的缓存之一。
JDK内置的Map可作为缓存的一种实现方式,然而严格意义来讲,其不能算作缓存的范畴。原因如下:一是其存储的数据不能主动过期;二是无任何缓存淘汰策略。
2.远程缓存
如Redis/Memcached:在网络中存储数据,容量大,但访问速度相对较慢。因为我没用过Memcached,这里远程缓存代指Redis。
3.缓存层级
- 一级缓存(本地缓存):直接与应用程序关联,适合频繁访问的数据。
- 二级缓存(远程缓存):作为一级缓存的补充,存储相对较不常访问的数据。
4.加载策略
- 先从本地缓存获取数据,如果不存在,再去远程缓存获取,最后如仍不存在,则从数据库获取并缓存到远程和本地。
这种多级缓存结构能有效提高应用程序性能,降低数据库压力。
二.适合/不适合的业务场景
1.适合的业务场景
Caffeine 适合需要快速访问、短期存储的数据场景,如频繁查询的热点数据、计算结果缓存等,尤其是在高并发环境下表现优异。
它特别适用于以下业务场景:
- 常用数据的枚举值:例如类目数据,这类数据变更频率低,且对实时性要求不高,适合使用Caffeine进行缓存。
- 依赖第三方系统的一些不频繁变更的键值对:先在本地缓存中查找,如果存在则直接返回,不存在则调用第三方系统获取数据并存入本地缓存中。这种模式适用于那些不是经常变化的数据,可以减少对外部系统的依赖,提高系统响应速度。
2.不适合的业务场景
Caffeine不适合实时性要求高或数据变更频繁的场景,对于需要持久存储的数据,或是数据更新频繁且需要实时一致性的场景,就不太适合,因为 Caffeine 的数据是保存在内存中的,可能会导致数据丢失或不一致。因为这些场景对数据的实时性和准确性要求极高,而Caffeine的设计初衷是为了提供高性能的本地缓存,而不是实时同步外部数据源的变化。此外,Caffeine也不适合需要强一致性保证的数据存储,因为它主要关注性能和命中率,而不是数据的一致性。
总的来说,Caffeine适合那些对数据变更频率不高、对实时性要求不是特别严格的应用场景,通过减少对外部数据源的访问次数,提高系统的整体性能和响应速度。
个人认为:其实不单单是我们本地缓存,就是分布式缓存Redis也不适合数据变更频繁的业务场景。引入缓存的本质是为了提高性能减少db操作,但是面对db修改频繁的场景又是引入本地缓存又是分布式缓存,又用其他中间件去解决这个不一致性(更何况哪天你们公司真正高并发起来这个不一致性还无法完全解决,这就是系统的一个坑埋在这了),所以个人觉得db修改频繁就不应该使用缓存!!!
网上人家经常说什么高并发下如何保证缓存与数据库一致性: 比如1.通过延时双删。2.使用canal(增量日志并提供增量数据的订阅与消费)获取到变更数据则更新缓存, 3.使用消息队列等等一系列措施。个人觉得这本来就是个伪命题,高并发下你对数据变更频繁的场景使用缓存真的就合适吗?真正高并发下用了这些,但凡一丁点中间件的网络波动一致性也是无法完全保证的,高并发下缓存与数据库一致性就是个无法完全解不了的问题,只能减少不一致。 当然如果并发量少使用上述的方案基本不会有问题,但是想想我们这个使用缓存+ 中间件的成本真的就比查询一次db低吗。
三.Redis与Caffine的对比
从横向对常用的缓存进行对比,有助于加深对缓存的理解,有助于提高技术选型的合理性。下面对比缓存:Redis、Caffeine。
1. 序列化
- Redis必须实现序列化。进程间数据传输,因此必须实现序列化。大多数情况下涉及内网网络传输;作为缓存数据库使用,持久化是标配。
- Caffeine不需要实现序列化。Map对象的改进型接口,不涉及任何形式的网络传输和持久化,因此完全不需要实现序列化接口。
2. 进程关系
- Redis与业务进程独立,业务系统重启对缓存服务无影响,Redis服务与业务服务独立,互相影响较小
- Caffeine附着于业务进程,业务系统重启缓存数据会全部丢失,纯内存型缓存与业务系统属于同一个JVM
四.各本地缓存性能测试对比报告(官方)
以下是Caffeine官方给出的基准测试结果,在与其他的本地缓存性能对比中身居第一位!。Caffeine的读写性能要远好于Guava,甚至超过不带缓存特性的ConcurrentHashMap。
具体详见官方给出的基本测试报告:https://github.com/ben-manes/caffeine/wiki/Benchmarks-zh-CN
生成计算
在这个 基准测试 中,缓存是无界且被完全填充的,并且生成计算的结果将返回一个常量。这个基准测试体现了生成计算元素的时候将当前元素加锁产生的开销。如果调用不存在,Caffeine 首先会进行一次无锁的预筛选,在进行原子操作。绘图的场景是所有线程对(“sameKey”)进行查询,并基于Zipf在各个线程中查询不同的key(“spread”)。

读 (100%)
在这个基准测试中, 8 线程对一个配置了最大容量的缓存进行并发读。

读 (75%) / 写 (25%)
在这个基准测试 中,对一个配置了最大容量的缓存,6 线程 进行并发读,2 线程进行并发写。

写 (100%)
在这个基准测试 中,8 线程对一个配置了最大容量的缓存进行并发写。

五.本地缓存Caffine如何使用
通过官方的基准测试,所以我们既然要用到本地缓存机制(例如需要用到缓存过期、过期监听、淘汰策略)等,选型那就用性能最厉害的Caffine,它支持多种缓存策略,如基于大小、时间的过期策略等。下面是一些常用的操作 API 及其示例代码。
1. 引入maven依赖:
<!-- 本地缓存 -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.9.3</version>
</dependency>
2.关于Caffine的各api操作介绍
1. 创建缓存
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
Cache<String, String> cache = Caffeine.newBuilder()
// 设置最大缓存条目数
.maximumSize(100)
// 设置写入后的过期时间
.expireAfterWrite(10, TimeUnit.MINUTES)
// 初始的缓存空间大小
.initialCapacity(20)
// 缓存的最大条数
.maximumSize(100)
.removalListener(((key,value,cause)->{
log.info("缓存失效通知,key:{},原因:{}",key,cause);
}))
.build();
2. 基本的缓存操作,添加、查询、删除缓存值
// 存入缓存
cache.put("key1", "value1");
// 获取缓存值
String value = cache.getIfPresent("key1");
System.out.println(value); // 输出: value1
// 缓存中有key2则返回缓存中的值,缓存中没有key2的值,则通过loadFromDatabase方法从数据库或其他来源加载数据并存入缓存。
String value = cache.get("key2", key -> loadFromDatabase(key));
// 输出从数据库加载的值
System.out.println(value);
// 删除某个缓存项
cache.invalidate("key1");
// 清空所有缓存项
cache.invalidateAll();
3. 异步加载缓存
Caffeine 也支持异步加载缓存,当缓存项不存在时,异步调用加载方法。
AsyncCache<String, String> asyncCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(10, TimeUnit.MINUTES)
.buildAsync();
// 异步获取缓存值
CompletableFuture<String> futureValue = asyncCache.get("key3", key -> loadFromDatabaseAsync(key));
// 异步处理获取结果
futureValue.thenAccept(value -> System.out.println("Value: " + value));
4. 基于时间的过期策略
Caffeine 支持基于时间的缓存过期机制,如写入后的过期、访问后的过期等。
写入后过期
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterWrite(5, TimeUnit.MINUTES) // 写入后 5 分钟过期
.build();
访问后过期
Cache<String, String> cache = Caffeine.newBuilder()
.expireAfterAccess(5, TimeUnit.MINUTES) // 访问后 5 分钟过期
.build();
5. 基于缓存大小的淘汰策略
你可以通过 maximumSize 或 maximumWeight 方法设置缓存的大小限制。
按照缓存项的数量限制
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(100) // 最多存储 100 条记录
.build();
按照缓存项的权重限制
Cache<String, String> cache = Caffeine.newBuilder()
.maximumWeight(1000) // 总权重限制为 1000
.weigher((key, value) -> value.length()) // 以值的长度为权重
.build();
6. 基于软引用或弱引用的缓存
Caffeine 支持使用软引用或弱引用存储缓存值,当 JVM 内存不足时可以自动回收这些缓存。
使用弱引用存储键
Cache<String, String> cache = Caffeine.newBuilder()
.weakKeys() // 使用弱引用存储键
.build();
使用软引用存储值
Cache<String, String> cache = Caffeine.newBuilder()
.softValues() // 使用软引用存储值
.build();
7. 统计缓存命中率
Caffeine 支持记录缓存的命中率、加载时间等统计信息。
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(100)
.recordStats() // 启用统计信息
.build();
// 获取统计信息
System.out.println(cache.stats());
8. 与 LoadingCache 的结合
LoadingCache 是 Caffeine 提供的一个更高级的缓存操作类,它支持自动同步加载数据的功能。
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(key -> loadFromDatabase(key)); // 自动加载缓存
// 直接获取缓存值,如果缓存中没有则调用 `loadFromDatabase`
String value = loadingCache.get("key1");
System.out.println(value);
总结:Caffeine 提供了丰富的 API 来满足不同业务场景的缓存需求。它不仅支持基本的缓存操作,还提供了多种淘汰策略、异步缓存以及统计功能,适用于多种场景。
从上面8点中,有没人发现第8点:loadingCache.get(“key1”)与第2点 cache.get(“key2”, key -> loadFromDatabase(key)); 功能基本一致?都是实现缓存中有则从缓存中取,缓存中没有则从db查询并存入缓存中。 只不过是加载逻辑的定义不同,一个是在 build() 时预定义,一个是每次 get() 时传递加载逻辑。
- 何时选择 LoadingCache ?
如果所有的键加载逻辑相同,你可以事先定义加载方式,并希望缓存缺失时自动加载数据,LoadingCache 是理想的选择。它提供了简洁的接口和良好的同步处理。 - 何时选择 Cache.get(key, keyMapper) ?
如果每个键的加载逻辑不同,或你希望在每次获取时灵活指定加载方式,那么 Cache.get(key, keyMapper) 更加合适。它提供了更大的灵活性来动态处理不同的缓存加载需求。 - 两种方案实现缓存中有?从缓存中取 :db查询再塞入缓存,总结:
LoadingCache 适用于需要统一加载策略、且不需要每次都指定加载逻辑的场景。Cache.get(key, keyMapper) 适用于需要根据具体情况动态指定加载逻辑的场景,更加灵活但相对复杂。你可以根据自己的业务场景选择合适的缓存操作方式。
六.多级缓存方案与实现思路
下面是一个简单的多级缓存实现示例,结合了Caffeine作为本地缓存和Redis作为远程缓存。我们在项目里面可以把缓存定义成配置bean, redis可以使用RedisTemplate。 这样一个多级缓存机制就实现啦,是不是很简单。
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import redis.clients.jedis.Jedis;
import java.util.concurrent.TimeUnit;
public class MultiLevelCache {
private final Cache<String, String> localCache;
private final Jedis remoteCache;
public MultiLevelCache() {
// 创建本地缓存Caffine
localCache = Caffeine.newBuilder()
// 设置最大缓存条目数
.maximumSize(100)
// 设置写入后的过期时间
.expireAfterWrite(10, TimeUnit.MINUTES)
// 初始的缓存空间大小
.initialCapacity(20)
// 缓存的最大条数
.maximumSize(100)
.removalListener(((key,value,cause)->{
log.info("缓存失效通知,key:{},原因:{}",key,cause);
}))
.build();
// Redis连接
remoteCache = new Jedis("localhost");
}
public String getData(String key) {
// 先从本地缓存获取
String value = localCache.getIfPresent(key);
if (value != null) {
return value;
}
// 本地缓存未命中,尝试从远程缓存获取
value = remoteCache.get(key);
if (value != null) {
// 更新本地缓存
localCache.put(key, value);
return value;
}
// 最后从数据库获取(假设为getDataFromDatabase方法)
value = getDataFromDatabase(key);
// 更新远程和本地缓存
remoteCache.set(key, value);
localCache.put(key, value);
return value;
}
private String getDataFromDatabase(String key) {
// 模拟数据库查询
return "DatabaseValueFor:" + key;
}
}
七.小结
- 主要介绍了什么是多级缓存:什么是本地缓存、什么是分布式缓存,本地缓存比分布式缓存快的原因。各本地缓存的性能对比中Caffine的性能是最高的,Caffine的Api使用,多级缓存的设计与实现等等。
- 谈到接口性能优化,我们除了sql调优还能从哪些方面优化?ok,当然是多级缓存技术方案啦!合适的业务场景下使用redis配合本地缓存,效率又能提升些。
- 除了缓存技术呢? ok,比如使用数据传输上的压缩,像请求参数,或者使用OpenFeign进行rpc调用响应值等等这些都可以使用GZIP压缩数据传输。 像OpenFeign底层http连接是通过jdk下的URLConnection,我们可以引入Apach 下的HttpClient, 或者okhttp 等,这些底层有用到连接池,可以复用连接等等。这些全都是我们接口性能的一些优化手段。