近年来,随着大型语言模型(LLMs)的迅猛发展,我们在寻求更精确、更可靠的语言生成能力上取得了显著进展。其中,检索增强生成(Retrieval-Augmented Generation)作为一种创新方法,极大地提升了语言模型在知识密集型任务中的表现。然而,RAG并非尽善尽美,其依赖检索文档的特点也带来了相关性和准确性的挑战。为了克服这些挑战,研究者们提出了多种衍生框架,包括纠错检索增强生成(CRAG)、自我反思检索增强生成(Self-RAG)以及HyDe(Hypothetical Document Embeddings)等,这些框架在提升语言模型性能上展现出了巨大潜力。
RAG:基础与挑战
RAG(Retrieval-Augmented Generation)通过引入外部信息检索来增强语言模型的生成能力。在生成文本时,RAG模型不仅依赖其内部参数知识,还会从外部数据源(如文档数据库)中检索相关信息作为输入。这种方法在回答知识密集型问题时尤为有效,因为模型可以直接利用检索到的具体事实来生成准确的答案。

然而,RAG方法也面临着几个核心挑战:
-
相关性挑战:检索到的文档可能与查询不相关,从而降低生成答案的准确性。
-
效率问题:不必要的检索和整合会增加模型的计算负担,影响生成速度。
-
泛化能力:模型在面对新的、未在训练集中出现的情况时,可能表现不佳。
为了解决这些问题,研究者们提出了多种改进方案,其中CRAG、Self-RAG和HyDe是其中的佼佼者。
CRAG:纠错检索增强生成
CRAG(Corrective Retrieval Augmented Generation)是在RAG基础上进行的一种改进,其核心思想是引入纠错机制来提高检索的准确性和相关性。
核心架构与工作原理:
- 检索评估机制(Retrieval Evaluator):
-
1、CRAG使用一个经过微调的T5-large模型作为检索评估器,用于评估针对特定用户请求所获取文档的总体品质,并计算相关性分数。
-
2、在模型微调过程中,正样本(positive samples)被标记为“1”,负样本(negative samples)被标记为“-1”。
-
3、模型推理阶段,评估器为每篇文档计算一个相关性分数,这些分数根据特定阈值被分为“正确”、“错误”和“不确定”三个类别。
- 知识精炼算法(Knowledge Refinement Algorithm):
-
1、CRAG采用“细分再整合”的策略来深度挖掘文档中的核心知识信息。
-
2、首先,使用启发式规则将文档分解为多个细粒度的知识点。
-
3、然后,计算每个知识点的相关性得分,并滤除得分较低的部分。
-
4、最后,将高相关性的知识点重组,形成内部知识库,供生成模型使用。
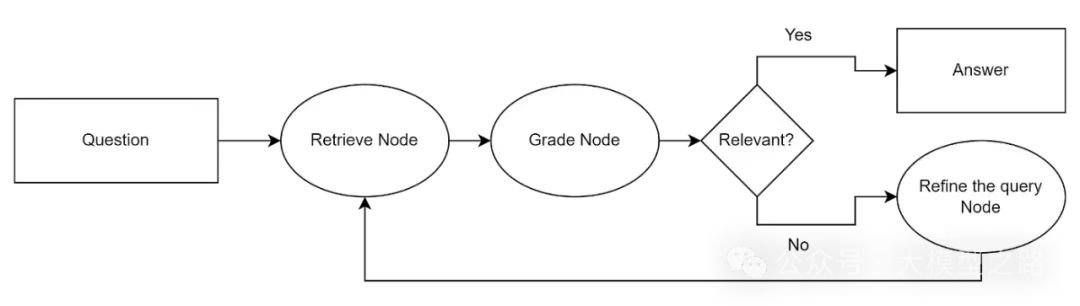
- 处理流程:
-
1、CRAG首先通过检索评估器评估检索文档与用户查询之间的相关性。
-
2、若检索结果被判定为“正确”,则使用知识精炼算法对文档内容进行优化。
-
3、若检索结果被判定为“错误”,则使用网络搜索引擎检索更多外部知识。
-
4、若检索结果被判定为“不确定”,则既需要运用知识精炼算法,也需要搜索引擎的辅助。
-
5、最终,经过处理的信息被转发给大语言模型(LLM),生成最终的模型响应
CRAG技术通过这种方式提高了检索结果的准确性,并减少了无关信息的干扰,从而提升了模型回答的质量。
CRAG的优势在于其能够自动识别和纠正检索过程中的错误,减少不相关文档对生成答案的负面影响。同时,通过引入纠错机制,CRAG还能够提升模型在处理复杂查询时的鲁棒性。
Self-RAG:自我反思检索增强生成
Self-RAG(Self-Reflective Retrieval-Augmented Generation)则更进一步,通过引入自我反思机制来提升语言模型的生成质量。Self-RAG不仅关注检索的准确性,还关注模型生成过程的可控性和反思能力。具体而言,Self-RAG通过以下方式实现:
-
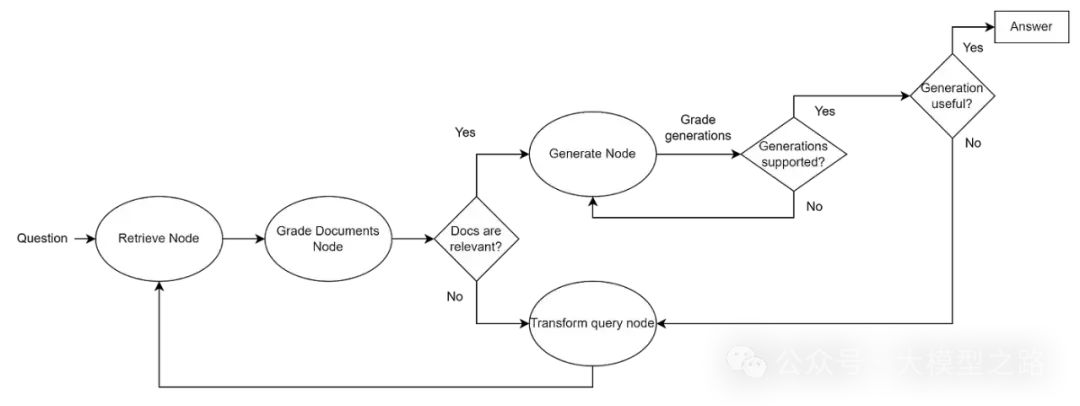
反思Token生成:在生成过程中,模型会生成特殊的反思Token,如Retrieve、ISREL、ISSUP和ISUSE等,这些Token分别用于指示是否需要检索、评估检索文档的相关性、支持度和整体效用。
-
按需检索:根据反思Token的指示,模型决定是否需要进一步检索相关文档,并并行处理多个检索到的段落。
-
生成与评估:在生成答案后,模型利用反思Token进行自我评估,选择最佳输出。
Self-RAG的优势在于其能够按需检索,减少不必要的检索操作,并通过自我反思提高生成答案的事实准确性和整体质量。此外,Self-RAG还通过引入反思Token增强了模型的可控性,使其能够根据不同任务需求调整生成行为。
HyDe:假设文档嵌入
HyDe(Hypothetical Document Embeddings)是一种创新的检索增强方法,它不同于传统的基于用户查询的检索方式,而是利用语言模型生成一个假设性的响应(即虚拟文档),然后利用这个响应进行检索。
HyDE的核心架构和工作原理如下:
-
生成假设文档:HyDE利用语言学习模型(如GPT)根据用户的查询生成一个假设性的答案或文档。这个文档虽然不是真实存在的,但它旨在模拟相关文档的内容,从而捕获查询的相关性模式。
-
文档编码:生成的假设文档随后被一个无监督对比学习的编码器(如Contriever)转换成一个嵌入向量。这个向量在语料库的嵌入空间中确定了一个邻域,基于向量相似性从中检索出相似的真实文档。
-
相似性检索:使用生成的文档向量在本地知识库中进行相似性检索,寻找最终结果。HyDE通过这种方式能够以零样本的方式工作,即不依赖于具体的相关性标签进行训练,从而适应多种语言和任务,即使在没有明确训练数据的情况下也能进行有效的文档检索。
HyDE的工作原理可以概括为:
-
输入指令和查询:HyDE接收一个查询指令,例如“写一个段落来回答这个问题”。
-
生成文档:基于GPT的语言模型生成一个假设的文档。
-
文档编码与检索:生成的文档被送入对比学习的编码器,该编码器将文档转换成嵌入向量,然后这个向量被用来在语料库中查找最相似的真实文档。
-
返回结果:模型根据生成的文档与真实文档之间的语义相似性返回查询结果。
HyDE的优势在于它能够处理更复杂和多样化的查询,特别适用于需要高度解释性和语义理解的领域,如医疗、法律和科研文献检索。它通过创造性地解释和拓展查询内容,提供更深层次的匹配和理解,从而提高了检索的相关性和准确性
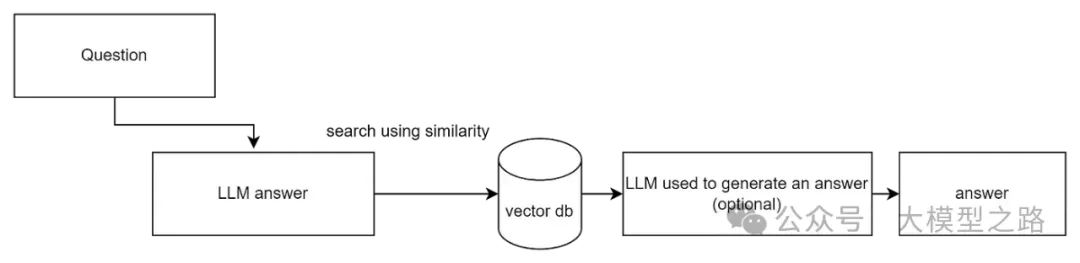
HyDe的优势在于其能够处理那些过于抽象或缺乏具体上下文的用户查询。通过生成假设文档,HyDe为检索过程提供了更多的上下文信息,从而提高了检索的准确性和相关性。

RAG及其衍生技术(CRAG、Self-RAG、HyDe)在提升语言模型准确性和适用性方面发挥了重要作用。这些技术通过引入纠正机制、自我反思和假设性文档嵌入等方法,解决了RAG在相关性和准确性方面的不足,提高了语言模型在处理知识密集型任务时的性能。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。