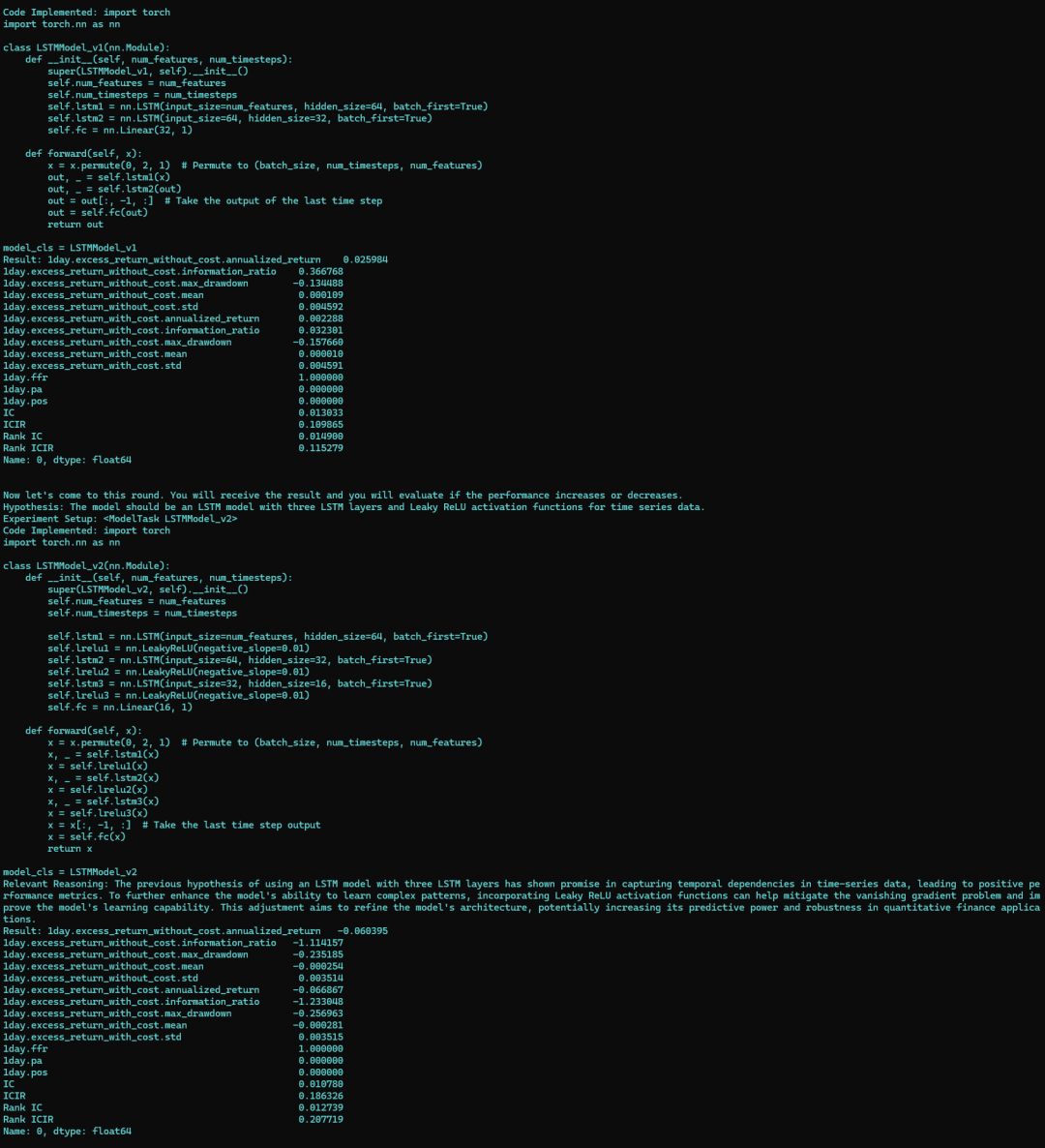
1. C/C++ 内存分布
在 C 和 C++ 中,内存可以分为多个区域,包括栈、堆、数据段、代码段等。这些区域分别用来存储不同类型的数据。通过以下示例代码,我们可以直观地理解这些区域的作用:
int globalVar = 1; // 全局变量
static int staticGlobalVar = 1; // 静态全局变量
void Test() {
static int staticVar = 1; // 静态局部变量
int localVar = 1; // 局部变量
int num1[10] = {1, 2, 3, 4}; // 局部数组
char char2[] = "abcd"; // 字符数组
const char* pChar3 = "abcd"; // 字符指针常量
int* ptr1 = (int*)malloc(sizeof(int) * 4); // 动态分配内存
int* ptr2 = (int*)calloc(4, sizeof(int)); // 动态分配并初始化
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4); // 重新分配内存
free(ptr1); // 释放内存
free(ptr3);
}以下是对应变量在内存中的分布情况:
内存区域分类:
介绍主要的几个:
栈(Stack):存储局部变量(如 localVar),以及函数调用时的参数和返回值。
堆(Heap):存储动态分配的内存(如通过 malloc、calloc、realloc 分配的内存)。
数据段(Data Segment):存储全局变量和静态变量(如 globalVar 和 staticGlobalVar)。
代码段(常量区)(Code Segment):存储程序的可执行代码以及只读常量(如 pChar3 所指向的字符串)。

2. C语言中的动态内存管理
C 语言提供了几种用于动态分配内存的函数:malloc、calloc、realloc 和 free。这些函数用于在程序运行时动态地分配和释放内存。
2.1 malloc、calloc 和 realloc 的区别
malloc:用于分配指定大小的内存块,内存中的内容未初始化。
calloc:类似于 malloc,但会将内存初始化为零。它的参数为元素的数量和每个元素的大小。
realloc:用于调整之前分配的内存块的大小,如果新大小大于原大小,可能会移动内存块的位置。
示例代码:
int* ptr1 = (int*)malloc(sizeof(int) * 4); // 分配4个int类型大小的内存块
int* ptr2 = (int*)calloc(4, sizeof(int)); // 分配并初始化4个int类型大小的内存块
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4); // 重新分配内存
free(ptr1);
free(ptr3);2.2 malloc 实现原理
glibc中malloc实现原理
malloc 底层通常通过操作系统的 brk 或 mmap 系统调用分配内存。具体实现可能因平台和 C
标准库的不同而有所区别。在 GNU C 库(glibc)中,malloc
通过维护一个自由链表来跟踪已分配和未分配的内存块,并根据请求的大小寻找合适的内存块进行分配。
3. C++ 内存管理
C++ 继承了 C 语言的内存管理方式,并在此基础上引入了 new 和 delete 操作符,提供更方便的动态内存管理机制。与 malloc 和 free 不同,new 和 delete 适用于对象的动态内存分配,并且会自动调用构造函数和析构函数。
3.1 new 和 delete 操作符
在 C++ 中,new 和 delete 操作符可以用于动态分配和释放内置类型(如 int、float 等)的内存。对于单个变量和数组,使用 new 和 delete 具有一些特定的规则,特别是在内存初始化和释放时。以下是对 new 和 delete 及其在数组中的使用进行的详细解析。
示例代码:
#include <iostream>
int main() {
// 使用 new 动态分配单个 int,未初始化
int* ptr = new int; // 分配内存,未初始化,内容是随机值
std::cout << "未初始化的值: " << *ptr << std::endl;
// 使用 new 动态分配并初始化为 0
int* ptrZero = new int(); // 初始化为 0
std::cout << "初始化为 0 的值: " << *ptrZero << std::endl;
// 使用 new 动态分配并初始化为 5
int* ptrValue = new int(5); // 初始化为 5
std::cout << "初始化为 5 的值: " << *ptrValue << std::endl;
// 释放动态分配的单个内存
delete ptr;
delete ptrZero;
delete ptrValue;
// 使用 new 动态分配数组,未初始化
int* arr = new int[5]; // 分配5个元素的数组,未初始化,内容是随机值
for (int i = 0; i < 5; ++i) {
std::cout << "arr[" << i << "] = " << arr[i] << std::endl;
}
// 使用 new 动态分配并初始化数组
int* arrInit = new int[5]{1, 2, 3, 4, 5}; // 初始化数组,指定每个元素的初始值
for (int i = 0; i < 5; ++i) {
std::cout << "初始化的 arrInit[" << i << "] = " << arrInit[i] << std::endl;
}
// 释放动态分配的数组
delete[] arr;
delete[] arrInit;
return 0;
}代码解析:
1. 单个变量分配(未初始化):
int* ptr = new int;
作用:动态分配一个 int,但不进行初始化。此时分配的内存包含随机值(未定义的内容。
输出:*ptr 中的值是不确定的,可能会输出垃圾值。
2. 单个变量分配并初始化为 0:
int* ptrZero = new int();
作用:通过使用 (),将分配的 int 初始化为 0。
输出:*ptrZero 输出的值为 0。
3. 单个变量分配并初始化为指定值:
int* ptrValue = new int(5);
作用:使用 new 初始化分配的 int 为指定值 5。
输出:*ptrValue 的值为 5。
4. 释放内存:
delete ptr;
delete ptrZero;
delete ptrValue;
作用:delete 用于释放通过 new 分配的内存。如果不及时释放,可能会导致内存泄漏。每次 new 都必须有对应的 delete。
5. 数组分配(未初始化):
int* arr = new int[5];
作用:动态分配一个包含 5 个 int 元素的数组。数组中的元素不会被初始化,内存中包含随机值。
输出:输出数组中每个元素 arr[i],这些值是未定义的。
6. 数组分配并初始化:
int* arrInit = new int[5]{1, 2, 3, 4, 5};
作用:通过 {} 进行数组初始化,指定数组中每个元素的初始值。
输出:arrInit 数组的元素分别被初始化为 {1, 2, 3, 4, 5},并依次输出。
7. 释放数组内存:
delete[] arr;
delete[] arrInit;
作用:对于通过 new 分配的数组,必须使用 delete[] 来释放内存。注意,不能使用 delete 来释放数组,否则会导致未定义行为。
关键点总结:
new 的单个元素分配:
未初始化:new int 分配的内存未初始化,包含随机值。
初始化为 0:new int() 分配的内存被初始化为 0。
初始化为指定值:new int(5) 将分配的内存初始化为指定的值(如 5)。
new 的数组分配:
未初始化:new int[5] 分配的数组元素不进行初始化,包含随机值。
使用 {} 进行数组初始化:new int[5]{1, 2, 3, 4, 5} 将数组每个元素初始化为指定值。
内存释放:
单个元素释放:使用 delete 释放通过 new 分配的单个元素内存。
数组释放:必须使用 delete[] 来释放通过 new 分配的数组内存。否则可能会引发内存管理错误或未定义行为。
区别于 malloc/free:
new 分配并初始化内存,而 malloc 只负责分配内存,不会进行初始化。
delete 负责释放内存并调用析构函数(如果是类对象),而 free 只负责释放内存。
4. operator new 与 operator delete
operator new 和 operator delete 是系统提供的全局函数,分别用于动态分配和释放内存。它们实际上是 new 和 delete 操作符的底层实现。在 C++ 中,new 操作符首先调用 operator new 分配内存,然后调用构造函数初始化对象;而 delete 操作符首先调用析构函数清理对象,然后调用 operator delete 释放内存。
4.1 operator new 的实现原理
operator new 的实现原理可以用如下代码描述:
void* operator new(size_t size) {
void* p;
// 尝试分配 size 字节的内存
while ((p = malloc(size)) == nullptr) {
// 如果 malloc 分配失败,尝试执行内存不足的应对措施
if (_callnewh(size) == 0) {
// 如果没有用户设置的处理措施,抛出 std::bad_alloc 异常
throw std::bad_alloc();
}
}
return p;
}
可以看到,operator new 本质上是通过 malloc 来分配内存的。不同的是,如果内存分配失败,operator new 会尝试调用用户设置的内存不足处理程序(_callnewh()),而 malloc 只是简单返回 NULL。
4.2 operator delete 的实现原理
operator delete 的实现则相对简单,它直接调用 free 来释放内存:
void operator delete(void* p) {
free(p);
}这两个类似的就不再介绍了
new T[N]的原理:
调用operator new[]函数,在operator new[]中实际调用operator new函数完成N个对象空间的申请
在申请的空间上执行N次构造函数
delete[]的原理:
在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理
调用operator delete[]释放空间,实际在operator delete[]中调用operator delete来释
放空间
5. new 和 delete 的工作过程
5.1 内置类型的内存管理
对于内置类型(如 int、float 等),new 和 malloc 在内存分配上是类似的。它们都分配指定大小的内存并返回指向该内存的指针。然而,new 与 malloc 的不同之处在于:单个元素的分配:new 可以分配单个内置类型的内存,而 malloc 只能分配一块指定大小的内存。
异常处理:当内存分配失败时,new 会抛出异常,而 malloc 则返回 NULL。
示例代码:
int* p1 = new int; // 分配单个int类型空间
delete p1; // 释放内存
int* p2 = (int*)malloc(sizeof(int)); // 使用malloc分配内存
free(p2); // 释放内存5.2 自定义类型的内存管理
对于自定义类型,new 和 delete 的作用更加明显,因为它们除了分配和释放内存之外,还会自动调用构造函数和析构函数。这一特性使得 new 和 delete 成为管理复杂对象的首选。
5.2.1 new 的工作过程:
调用 operator new 分配内存:为对象分配所需的内存。
在已分配的内存上调用构造函数:通过构造函数来初始化对象。
5.2.2 delete 的工作过程:
调用析构函数:析构函数会清理对象占用的资源(如释放动态分配的内存等)。
调用 operator delete 释放内存:通过 free 或类似的机制将内存归还给操作系统。
示例代码:
class A {
public:
A(int a) : _a(a) {
std::cout << "Constructor called" << std::endl;
}
~A() {
std::cout << "Destructor called" << std::endl;
}
private:
int _a;
};
int main() {
A* obj = new A(10); // 动态分配并调用构造函数
delete obj; // 调用析构函数并释放内存
}6. malloc/free 和 new/delete 的区别
malloc/free 和 new/delete 都是从堆上分配内存,并且都需要用户手动释放,但它们之间存在一些关键区别:
6.1 语法上的区别
malloc/free 是函数:malloc 和 free 是 C 标准库中的函数,用于动态内存管理。
new/delete 是操作符:new 和 delete 是 C++ 的内置操作符,主要用于对象的动态内存管理。
6.2 初始化的区别
malloc 不会初始化内存:malloc 只是分配一块内存,而不负责初始化内容。如果想初始化,必须手动进行赋值操作或使用 calloc。
new 会调用构造函数:new 不仅分配内存,还会调用构造函数来初始化对象,因此适用于分配类对象时的动态内存管理。
6.3 内存分配失败的处理方式
malloc 分配失败返回 NULL:如果 malloc 无法分配内存,它会返回 NULL,程序员需要手动检查返回值。
new 分配失败抛出 std::bad_alloc 异常:当 new 失败时,它会抛出 std::bad_alloc 异常,程序员可以使用 try-catch 语句捕获异常,进行相应处理。
6.4 自定义类型的对象分配
malloc/free 不会调用构造函数和析构函数:malloc 仅仅分配内存,无法初始化对象,也不会调用析构函数来清理对象的资源,因此需要手动处理对象的初始化和销毁。
new/delete 会调用构造函数和析构函数:new 在分配内存后会调用构造函数,delete 在释放内存前会调用析构函数,适合处理类对象的动态内存分配和释放。
6.5 异常安全性与内存泄漏问题
new/delete 提供更好的异常安全性:由于 new 操作符会在对象构造失败时自动释放分配的内存,并抛出异常,因此相比 malloc/free,new/delete 更安全,能有效避免内存泄漏。
malloc/free 的内存管理需要额外小心:使用 malloc 时,由于不调用构造和析构函数,程序员需要手动处理内存释放和对象销毁,容易出现内存泄漏。
示例代码对比:
// 使用 malloc/free
A* obj1 = (A*)malloc(sizeof(A)); // 仅仅分配内存,不调用构造函数
free(obj1); // 仅仅释放内存,不调用析构函数
// 使用 new/delete
A* obj2 = new A(10); // 分配内存并调用构造函数
delete obj2; // 调用析构函数并释放内存7. 定位 new 表达式 (Placement-new)
定位 new 表达式是一种高级用法,它允许在已分配的内存上构造对象,而不需要重新分配内存。通常用于内存池、嵌入式系统或者需要精细控制内存分配的场景中。
7.1 定位 new 的使用方式
定位 new 表达式的语法如下:
new (place_address) type;
其中 place_address 是要放置对象的内存地址,type 是要构造的对象类型。通常用在已经手动分配的内存(比如通过 malloc)上,避免重复分配内存。示例代码:
class A {
public:
A(int a = 0) : _a(a) {
std::cout << "A() called" << std::endl;
}
~A() {
std::cout << "~A() called" << std::endl;
}
private:
int _a;
};
int main() {
void* buffer = malloc(sizeof(A)); // 手动分配一块内存
A* obj = new(buffer) A(10); // 在指定的内存上构造对象
obj->~A(); // 手动调用析构函数
free(buffer); // 释放内存
}7.2 定位 new 的注意事项
手动调用析构函数:由于定位 new 表达式不负责释放内存,因此在对象生命周期结束时,必须显式调用对象的析构函数来清理资源。
内存释放:使用定位 new 时,必须手动释放内存(如使用 free)。定位 new 仅在已经存在的内存上构造对象,不会负责内存的分配与释放。
7.3 定位 new 的应用场景
内存池管理:在高性能应用中(如游戏引擎、嵌入式系统),为了减少频繁的内存分配和释放,通常使用内存池。定位 new 允许在预分配的内存中灵活构造和销毁对象,提高了内存管理的效率。
嵌入式系统:在内存受限的环境中,定位 new 可以避免重复分配内存,节省开销,且提高了系统的性能。