问过神奇的chatgpt后,了解到iTextPdf这个库,应该是比较好的选择。
解决方案
我们先观察下真实的开票预览的模板。
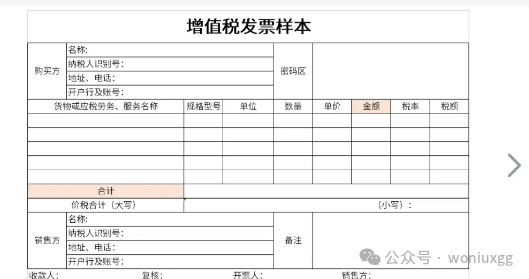
发票信息由两部分组成:
-
固定信息,例如购买方信息、销售方信息。
-
商品信息,可能有多行,需动态填充
很明显的一个主子结构。
了解了一下iTextPdf的相关api。要实现这个功能,其实我们需要分别生成两部分的发票信息,也就是两个pdf,然后将两个pdf拼接成同一个。
对于第一部分的固定信息,我们可以用Acrobat之类的pdf设计工具设计出一个模板,然后在java程序中读取并填充对应的模板值。
对于第二部分的商品信息,就需要获取商品数据,动态生成表格,当然iTextPdf是支持这一功能的。
分别得到两部分的pdf之后,再将其合并为同一个pdf就可以了。
具体实现
1.引入iTextPdf库
在pom文件中添加iTextPdf的对应依赖。其中 itext-asian 这个也是需要的,不然生成的pdf中无法显示中文
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13.2</version>
</dependency>
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>
2.编辑对应模板
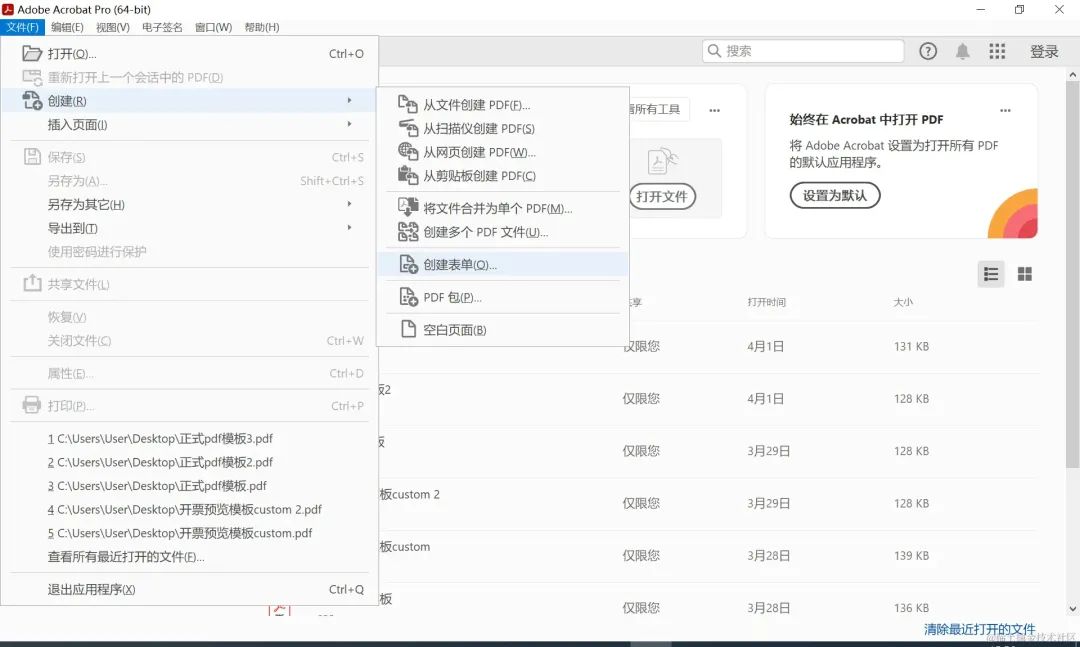
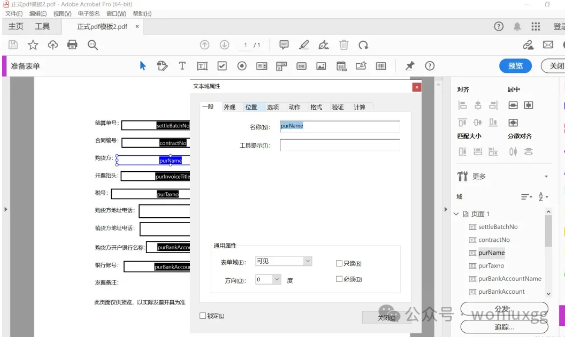
下载Adobe Acrobat工具,这部分就不细说了 点击文件-创建-表单。如果你有现成的pdf文件,也可以在这步选择单一文件开始,没有的话就从头新建
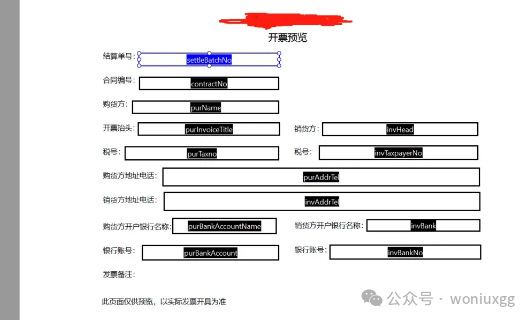
通过放置文字和文字域来设计好表单模板。
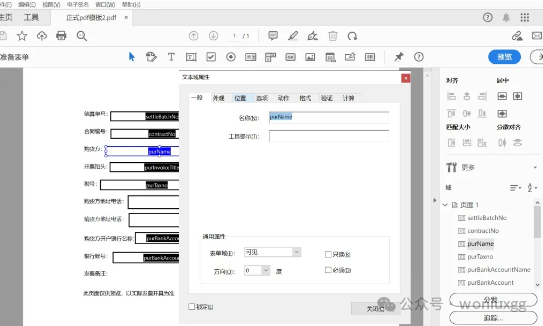
注意,文字域“属性”里的名称就是最后使用iTextPdf填充时需要填充的对应字段。
3.编写java PDF生成程序
使用框架还是老一套的SpringBoot,但为了方便测试,不展示最终的成品接口,而是写在一个可执行的主方法里main里。
3.1 读取PDF模板文件
iTextPdf负责读取文件的Class是PdfReader,支持多种解析方式
可以读取文件路径,也支持直接传入文件的字节流
线上环境使用了字节流的读取方式。演示的主方法中使用了直接读取本地文件路径的方式。
// 读取本地文件,当然线上环境肯定不这么写
PdfReader reader = new PdfReader("C:\\Users\\User\\Desktop\\开票预览模板.pdf");
// 线上环境使用了s3服务器,会提前得到字节流 byte[] bytes
PdfReader reader = new PdfReader(bytes);
3.2 填写模板文件并生成固定信息的PDF文件
iTextPdf负责填充表单字段的Class是PdfStamper
Stamper,译文压模;母盘;模子;印章
用来形容把动态数据填充进已有的表单里,还挺形象的
注意 form.setField("purName","购买方对应公司"); 这里设值的key就是我们在设计表单时,文字域的名称。
// 临时输出流-表单
ByteArrayOutputStream bos1 = new ByteArrayOutputStream();
PdfStamper stamper = new PdfStamper(reader, bos1);
// 获取表单
AcroFields form = stamper.getAcroFields();
form.setGenerateAppearances(true);
// 表单填充
form.setField("purName","购买方对应公司");
stamper.close();
在实际的实现中,这里使用了一个Map<String,String> map 遍历所有entrySet,将值通过setField(entrySet.key(),entrySet.value())方法填充至表单
3.3 动态创建表格并生成商品信息的PDF文件
搞定了第一部分的PDF文件,我们再来处理第二部分的PDF文件:生成商品列表。
这里我们需要新建一个Document,在这个Document中动态创建一个表格对象PdfPTable
最后将Document关闭。调用Document.close()时会触发输出流ByteArrayOutputStream的更新。
另外还有一个要点是,如果表格要显示中文,那么输出的内容格必须设置中文字体,否则无法显示。
我们来看一下填充一个最简单的Pdf表格是怎么做的
// 最简单的示例
import com.itextpdf.text.Document;
import com.itextpdf.text.DocumentException;
import com.itextpdf.text.PageSize;
import com.itextpdf.text.Paragraph;
import com.itextpdf.text.pdf.PdfPTable;
import com.itextpdf.text.pdf.PdfWriter;
import java.io.FileOutputStream;
public class AdjustTablePositionInPdf {
public static void main(String[] args) {
try {
// 创建一个新的 PDF 文档
Document document = new Document(PageSize.A4);
PdfWriter.getInstance(document, new FileOutputStream("C:\\Users\\User\\Desktop\\adjusted_table_position.pdf"));
document.open();
// 添加文本内容
document.add(new Paragraph("Test PDF with Table"));
// 创建表格
PdfPTable table = new PdfPTable(2);
table.addCell("Name");
table.addCell("Age");
table.addCell("Alice");
table.addCell("25");
table.addCell("Bob");
table.addCell("30");
// 设置表格之前的间距
table.setSpacingBefore(20f);
// 设置表格之后的间距
table.setSpacingAfter(20f);
// 设置表格的总宽度
table.setTotalWidth(300f);
// 将表格添加到 PDF
document.add(table);
document.close();
System.out.println("PDF 文件生成成功!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
声明PdfPTable对象后(需指定列的数目),通过调用Table.addCell()方法添加行数据。
Table.addCell()会自动切换行的。假如表有两列,连续调用三个Table.addCell()方法,第三个方法就会自动切换到第二行。
知道了这一点后,我们分析一下:对于表格的某一列,我们至少需要以下两个参数:表头中文名称,列的数据映射key
/**
* 表头信息
**/
@Data
@AllArgsConstructor
public class HeadRowMetaInfo {
// 列中文名
private String colName;
// 列key
private String colKey;
// 列宽度
private float width;
}
/**
* 自定义头部信息
* @return
*/
public static List<HeadRowMetaInfo> headInfos(){
List<HeadRowMetaInfo> infos = new ArrayList<>();
infos.add(new HeadRowMetaInfo("货物或应税劳务、服务名称","commodityName",80));
infos.add(new HeadRowMetaInfo("规格型号","model",80));
infos.add(new HeadRowMetaInfo("单位","pushUnitName",80));
infos.add(new HeadRowMetaInfo("数量","orderNum",80));
infos.add(new HeadRowMetaInfo("单价","orderPriceNoTax",80));
infos.add(new HeadRowMetaInfo("不含税金额","orderAmount",80));
infos.add(new HeadRowMetaInfo("税额","taxAmt",80));
infos.add(new HeadRowMetaInfo("含税金额","orderAmountTax",80));
infos.add(new HeadRowMetaInfo("税率","taxRate",80));
return infos;
}
好了,我们继续来看我们的主方法
// 临时文件流-商品
ByteArrayOutputStream bos2 = new ByteArrayOutputStream();
// 获取原页面的尺寸和样式
Document document = new Document(reader.getPageSize(1));
PdfWriter writer = PdfWriter.getInstance(document, bos2);
document.open();
//新创建一页来存放后面生成的表格
document.newPage();
// 获取商品导出数据
List<Map<String, Object>> mapData = otherService.getData();
// 全局统一字体,不设置无法显示中文
// 创建支持中文的字体
BaseFont bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", false);
Font font = new Font(bfChinese, 12, Font.NORMAL, BaseColor.BLACK);
PdfPTable table = generatePdfPTable(720f,font,mapData,headInfos());
document.add(table);
// 文档流关闭
// 关闭后才会触发ByteArrayOutputStream的流更新
document.close();
writer.close();
主方法中声明的,生成PDF表格的子方法为:
public static PdfPTable generatePdfPTable(float totalWidth, Font font, List<Map<String, Object>> data, List<HeadRowMetaInfo> headRowMetaInfos) throws DocumentException {
// 多少列
PdfPTable table = new PdfPTable(headRowMetaInfos.size());
// 表宽度
table.setTotalWidth(totalWidth);
// 设置每列的宽度
List<Float> flist = headRowMetaInfos.stream().map(HeadRowMetaInfo::getWidth).collect(Collectors.toList());
float[] farr = new float[flist.size()];
for(int i = 0;i<flist.size();i++){
farr[i] = flist.get(i);
}
table.setWidths(farr);
Map<Integer,String> indexToKeyMap = new HashMap<>();
// 根据表头信息插入表头
for(int i = 0 ;i < headRowMetaInfos.size();i++){
table.addCell(new Phrase(headRowMetaInfos.get(i).getColName(),font));
indexToKeyMap.put(i,headRowMetaInfos.get(i).getColKey());
}
// 添加行数据
for(Map<String,Object> dataItem:data){
for(int i=0;i<headRowMetaInfos.size();i++){
if(dataItem.get(indexToKeyMap.get(i)) != null){
table.addCell(new Phrase(dataItem.get(indexToKeyMap.get(i)).toString(),font));
}else{
table.addCell("-");
}
}
}
// 计算表格在页面上的位置并添加到页面
// 注意:这里的坐标可能需要根据实际情况调整
table.setLockedWidth(true);
return table;
}
3.4 拼接两个PDF文件
public static byte[] copy(List<byte[]> files) throws DocumentException, IOException {
// 创建文档对象
Document document = new Document();
// 创建PdfCopy对象
ByteArrayOutputStream bos = new ByteArrayOutputStream();
PdfCopy copy = new PdfCopy(document, bos);
// 设置只读
copy.setEncryption(null, null, PdfWriter.ALLOW_PRINTING, PdfWriter.STANDARD_ENCRYPTION_128);
// 打开文档
document.open();
PdfReader reader;
int n;
// 循环遍历所有PDF文件
for (byte[] file : files) {
reader = new PdfReader(file);
// 获取每个PDF文件的页数
n = reader.getNumberOfPages();
for (int page = 0; page < n; ) {
// 向PdfCopy添加每一页
copy.addPage(copy.getImportedPage(reader, ++page));
}
// 关闭PdfReader
reader.close();
}
// 关闭文档,否则输出流不会刷新
document.close();
byte[] bytes = bos.toByteArray();
// 关闭流
bos.close();
return bytes;
}
3.5 输出
用于线上环境的接口,在此处得到了字节流之后就上传s3了 在演示用的主函数里,将字节流保存为了本地文件
log.info(returnPath +" pdf模板填充成功,进行合并");
List<byte[]> files = new ArrayList<>();
files.add(bos1.toByteArray());
files.add(bos2.toByteArray());
// 合并两个pdf流
byte[] s3bytes = copy(files);
// 关闭流
bos1.close();
bos2.close();
reader.close();
// 有流之后 可以把流存储至本地文件,也可以上传s3了
String outputPath = "C:\\Users\\User\\Desktop\\test3.pdf";
FileOutputStream fileOutputStream = new FileOutputStream(outputPath);
fileOutputStream.write(s3bytes);
fileOutputStream.close();
总结
通过这次的需求学习到了JAVA里生成操作pdf文件的方法。先制作PDF表格模板,设置文字域,可以处理掉导出数据中的固定部分数据 针对表格类的数据,长度不固定,需要通过生成PDF表格来进行处理。
最后说一句(求关注!别白嫖!)
如果这篇文章对您有所帮助,或者有所启发的话,求一键三连:点赞、转发、在看。
关注公众号:woniuxgg,在公众号中回复:笔记 就可以获得蜗牛为你精心准备的java实战语雀笔记,回复面试、开发手册、有超赞的粉丝福利!