Register pressure in AMD CDNA™2 GPUs — ROCm Blogs

注意: 此博客以前是 AMD实验室笔记 博客系列的一部分。
GPU kernel 中的寄存器压力对高性能计算 (HPC) 应用程序的整体性能有着巨大的影响。理解和控制寄存器的使用可以让开发者精心设计代码,以最大化硬件资源。下面的博客文章专注于一个实际演示,展示如何应用2022年8月23日的 OLCF培训讲座 中解释的建议。这里是 培训存档,你也可以在那里找到幻灯片。我们只专注于使用 ROCm 5.4 的 AMD CDNA™2 架构 (MI200系列GPU)。
寄存器和占用率
通用寄存器是传统处理器中最快三的内存类型。在大多数情况下,传统处理器和加速器(如GPU)中的算术逻辑单元(ALU)是唯一可以直接访问寄存器的组件。不幸的是,寄存器是一种稀缺且昂贵的资源,编译器会尽力“优化”局部变量分配到硬件寄存器以供ALU操作时使用。
当我们使用“优化”一词时,我们总是要澄清优化过程的目标。实际上,常规CPU和加速器(如GPU)由于其本质不同,它们执行程序和实现高性能的方法也不同。一方面,传统CPU是面向延迟设计的,旨在尽可能多地执行单个串行线程的指令。另一方面,GPU是面向吞吐量设计的,旨在尽可能利用独立线程之间的并行性。
在AMD GPU中,在同一个计算单元(CU)上运行的高数量并发波前(wavefront)使得GPU能够隐藏全局内存访问时间,比执行计算操作所需的时间更长,而此时其他波前正在执行操作。
“占用率”这个术语表示在同一个CU上能同时运行的最大波前数量。一般来说,较高的占用率有助于通过其他操作隐藏昂贵的内存访问操作,从而实现更好的性能,但这并不是总能如此。
在图1中,我们展示了CDNA™2架构中CU的示意图。矢量通用寄存器(VGPRs)用于存储在波前中各个工作项不同的数据,即每个工作项的数据是不同的。它们是CU中最通用的寄存器,可以直接由矢量ALU(VALU)操作。VALU负责执行CU中的大部分工作,包括浮点运算(FLOPs)、内存加载、整数和逻辑操作等。
标量通用寄存器(SGPRs)代表一组用于存储在编译时已知的波前中各工作项相同数据的寄存器。SGPRs由标量ALU(SALU)操作,而SALU与VALU不同,只能用于有限的操作集,如整数和逻辑操作。
本地数据共享(LDS)是一种快速的CU上管理的内存,可以在块内所有工作项之间高效共享数据。
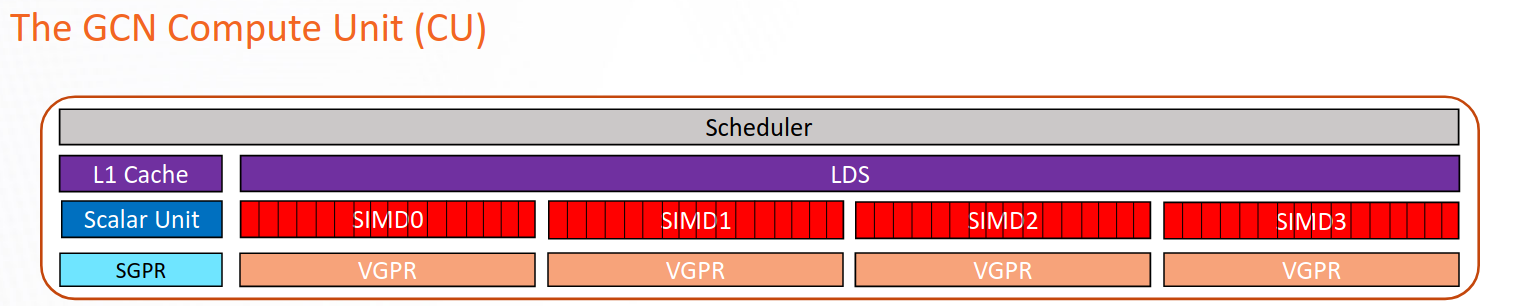
图1:CDNA™2架构中CU的示意图
理想情况下,我们希望始终有尽可能高的占用率。实际上,占用率受硬件设计选择和由运行在卡上的内核(如HIP、OpenCL等)所决定的资源限制。例如,每个基于AMD CDNA™2的GPU的CU有四组波前缓冲区,每个执行单元(EU,也称为图1中的SIMD单元)一个波前缓冲区,每个CU有四个EU。每个EU最多可以管理*八个*波前。这意味着CDNA™2中的物理占用率上限是每个CU 32个波前。
内核所需的寄存器数量是最常见的占用率限制因素之一。另一个常见的限制因素是LDS。以下表格总结了在AMD CDNA™2基于的GPU上,作为内核使用的VGPRs数量的函数,可以达到的最大占用率。
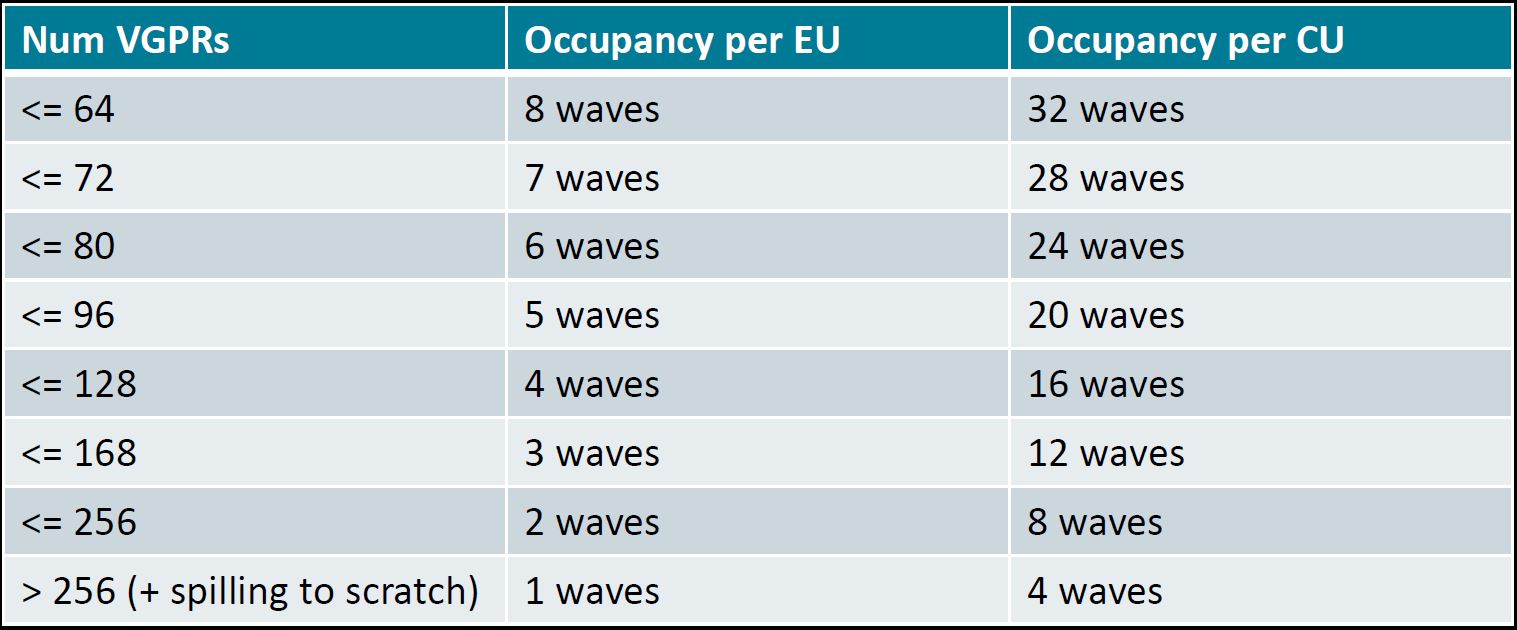
表1:MI200中与VGPRs使用相关的占用率
寄存器溢出
寄存器分配是将GPU内核的局部变量和表达式结果分配到硬件可用寄存器的过程。它由编译器在编译时进行,并受到指令调度等其他阶段的影响。找到该问题的最优解决方案是NP难题,因此必须采用启发式技术在合理时间内找到接近最优的解决方案。
编译器试图通过减少寄存器的需求来应用启发式技术以最大化占用率,遵循表1。当请求的寄存器数量变得过高时,性能会因“寄存器压力”而受到惩罚,这导致较低的占用率和临时存储器的使用。
有时,编译器可能认为,即使请求的寄存器数量超过表1中报告的限制,达到更高的占用率也是有益的。例如,应用程序需要134个寄存器,但编译器仅分配128个,其余的放在临时存储器中。通过在临时存储器中保存一些变量,可以实现更高的占用率:这是一个线程私有的局部存储器,由全局存储器支持,速度比寄存器存储器慢得多。这种技术被称为“寄存器溢出”。
虽然观察到变量被分配到临时存储器可能是高寄存器压力的前兆,但应该从更广泛的性能背景中考虑这一点。事实上,通过保存少量寄存器来实现更高的占用率,与没有任何临时存储器使用但占用率较低相比,可以提供显著的性能提升。
在请求的寄存器数远高于硬件可用寄存器数的情况下,性能将在低占用率(最坏情况下每个计算单元1个波前)和高成本访问被“溢出”到临时存储器的寄存器变量之间受到影响。
如何减少寄存器压力
如前所述,编译器通过采用启发式技术来最大化占用率,从而最小化某些GPU内核所需的寄存器数量。这些启发式技术有时未能接近最优解决方案,程序员需要重新构建代码以减少寄存器压力并提高性能。
在本节中,我们将介绍如何识别寄存器压力问题以及如何缓解它。
首先,可以通过两种方式检测GPU内核使用的寄存器数量:1) 使用 -Rpass-analyze=kernel-resource-usage 标志编译包含内核的文件,该标志将在编译时打印每个内核的资源使用情况;其中包括SGPRs(标量通用寄存器)、VGPRs(矢量通用寄存器)、ScratchSize(临时内存大小)、VGPR/SGPR溢出、占用率和LDS(本地数据共享)使用情况。2) 使用 --save-temps 进行编译,并检查 hip-amdgcn-amd-amdhsa-gfx90a.s 文件中的 .vgpr_spill_count。`-Rpass-analyze=kernel-resource-usage` 标志报告的所有信息也可以在这个文件中找到。
一旦评估/确认了寄存器压力情况,可以将以下几种技术应用于代码以减少寄存器压力。
-
为每个内核设置
__launch_bounds__限定符。默认情况下,编译器假设每个内核的块大小为1024个工作项。定义__launch_bounds__后,编译器可以适当地分配寄存器,从而潜在地降低寄存器压力。 -
将变量定义/赋值移动到接近它们使用的位置。在GPU内核顶部定义一个或多个变量,并在底部使用它们,这会迫使编译器将这些变量存储在寄存器或临时内存中,直到它们被使用,从而影响使用这些寄存器处理更多性能关键变量的可能性。将定义/赋值移动到它们第一次使用的位置将有助于启发式技术对其余代码做出更有效的选择。
-
避免在堆栈上分配数据。在堆栈上分配的内存,例如
double array[10],默认情况下会存在于临时内存中,编译器可能会将其优化存储到寄存器中。如果你的应用程序使用在堆栈上分配的内存,看到临时内存的使用不应感到惊讶。 -
避免将大对象作为内核参数传递。函数参数在堆栈上分配,可能作为优化存储到寄存器中。有时,将这些参数存储为
constant可能会有所帮助。 -
避免编写包含许多函数调用(包括数学函数和断言)的大型内核。当前,编译器总是内联设备函数,包括数学函数和断言。拥有许多这些函数调用会引入额外的代码和潜在的更高寄存器压力。例如,将
pow(var,2.0)替换为简单的var*var可以显著减少寄存器压力。 -
控制循环展开。可以通过在编译时已知迭代次数的循环上添加
#pragma unroll命令来实现循环展开。通过这样做,所有迭代都将完全展开,从而减少检查循环退出条件的开销。然而,循环展开会增加寄存器压力,因为需要同时存储更多变量。在寄存器压力成为问题的情况下,应限制使用循环展开。请注意,Clang编译器在展开循环方面往往比其他编译器更加字面化。 -
手动溢出到LDS。作为最后的手段,可以使用一些LDS内存手动存储变量,可能是那些生命周期最长的变量,从而为每个线程节省几个寄存器。
示例
接下来,我们将重点讨论以下代码:
__global__ void kernel (double *phi, double *laplacian_phi,
double *grad_phi_x, double *grad_phi_y, double *grad_phi_z,
double *f0, double *f1, double *f2, double *f3, double *f4,
double *f5, double *f6,
double *g0, double *g1, double *g2, double *g3, double *g4,
double *g5, double *g6, double* g7, double *g8, double *g9,
double *g10, double *g11, double *g12, double *g13, double *g14,
double *g15, double *g16, double *g17, double *g18,
int nx, int ny, int nz, int ldx, int ldy, int current, int next,
double k, double alpha, double phi2, double gamma,
double itauphi, double itauphi1, double ieta,
double itaurho, double grav,
double eg1, double eg2, double eg0, double egc0, double egc1, double egc2)
{
int i = (threadIdx.x + blockIdx.x * blockDim.x);
int j = (threadIdx.y + blockIdx.y * blockDim.y);
int z = (threadIdx.z + blockIdx.z * blockDim.z);
int m, current_pos;
double mu_phi, current_phi, current_phi_2;
double rho;
double fx, fy, fz;
double uf, ux, uy, uz, v;
double af, ag, cf;
double eg1ag, eg2ag, eg1rho, eg2rho;
double tmp1, tmp2;
if(i <= nx && j <= ny && z <= nz)
{
m = i + ldx * (j + ldy * z);
current_pos = m + current;
current_phi = phi[m];
current_phi_2 = pow(current_phi,2.0);
rho = g0[m] + g1[current_pos] + g2[current_pos] + g3[current_pos] + g4[current_pos] +
g5[current_pos] + g6[current_pos] + g7[current_pos] + g8[current_pos] + g9[current_pos] +
g10[current_pos] + g11[current_pos] + g12[current_pos] + g13[current_pos] + g14[current_pos] +
g15[current_pos] + g16[current_pos] + g17[current_pos] + g18[current_pos];
mu_phi = alpha * current_phi * ( current_phi_2 - phi2 ) - k * laplacian_phi[m];
fx = mu_phi * grad_phi_x[m];
fy = mu_phi * grad_phi_y[m];
fz = mu_phi * grad_phi_z[m];
ux = ( g1[current_pos] - g2[current_pos] + g7[current_pos] - g8[current_pos] + g9[current_pos] -
g10[current_pos] + g11[current_pos] - g12[current_pos] + g13[current_pos] - g14[current_pos] +
0.50 * fx ) * 1.0/rho;
uy = ( g3[current_pos] - g4[current_pos] + g7[current_pos] - g8[current_pos] - g9[current_pos] +
g10[current_pos] + g15[current_pos] - g16[current_pos] + g17[current_pos] - g18[current_pos] +
0.50 * fy ) * 1.0/rho;
uz = ( g5[current_pos] - g6[current_pos] + g11[current_pos] - g12[current_pos] - g13[current_pos] +
g14[current_pos] + g15[current_pos] - g16[current_pos] - g17[current_pos] + g18[current_pos] +
0.50 * fz ) * 1.0/rho;
af = 0.50 * gamma * mu_phi * itauphi;
cf = itauphi * ieta * current_phi;
f0[m] = itauphi1 * f0[m] + -3.0 * gamma * mu_phi * itauphi + itauphi * current_phi;
f1[current_pos] = itauphi1 * f1[current_pos] + af + cf * ux;
f2[current_pos] = itauphi1 * f2[current_pos] + af - cf * ux;
f3[current_pos] = itauphi1 * f3[current_pos] + af + cf * uy;
f4[current_pos] = itauphi1 * f4[current_pos] + af - cf * uy;
f5[current_pos] = itauphi1 * f5[current_pos] + af + cf * uz;
f6[current_pos] = itauphi1 * f6[current_pos] + af - cf * uz;
ag = 3.0 * current_phi * mu_phi + rho;
eg1ag = eg1 * ag;
eg2ag = eg2 * ag;
eg1rho = eg1 * rho;
eg2rho = eg2 * rho;
v = 1.50 * ( ux*ux + uy*uy + uz*uz );
uf = ux * fx + uy * fy + uz * fz;
g0[m] = itaurho * g0[m] + eg0 * ( (rho - 6.0 * current_phi * mu_phi) - rho*v ) - egc0*uf;
tmp1 = eg1ag + eg1rho*( 0.50*ux*ux - v ) + egc1*( ux*fx - uf );
tmp2 = eg1rho*ux + egc1*fx;
g1[m+next + 1] = itaurho * g1[current_pos] + tmp1 + tmp2;
g2[m+next - 1] = itaurho * g2[current_pos] + tmp1 - tmp2;
tmp1 = eg1ag + eg1rho*( 0.50 * uy * uy - v ) + egc1 * ( uy * fy - uf );
tmp2 = eg1rho * uy + egc1 * fy;
g3[m+next + ldx] = itaurho * g3[current_pos] + tmp1 + tmp2;
g4[m+next - ldx] = itaurho * g4[current_pos] + tmp1 - tmp2;
tmp1 = eg1ag + eg1rho*( 0.50 * uz * uz - v ) + egc1 * ( uz * fz - uf );
tmp2 = eg1rho * uz + egc1 * fz;
g5[m+next + ldx*ldy] = itaurho * g5[current_pos] + tmp1 + tmp2;
g6[m+next - ldx*ldy] = itaurho * g6[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( ux + uy ) * ( ux + uy ) - v ) +
egc2 * ( ( ux + uy ) * ( fx + fy ) - uf );
tmp2 = eg2rho * ( ux + uy ) + egc2 * ( fx + fy );
g7[m+next + 1 + ldx] = itaurho * g7[current_pos] + tmp1 + tmp2;
g8[m+next - 1 - ldx] = itaurho * g8[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( ux - uy ) * ( ux - uy ) - v ) +
egc2 * ( ( ux - uy )*( fx - fy ) - uf );
tmp2 = eg2rho * ( ux - uy ) + egc2 * ( fx - fy );
g9[m+next + 1 - ldx] = itaurho * g9[current_pos] + tmp1 + tmp2;
g10[m+next - 1 + ldx] = itaurho * g10[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( ux + uz ) * ( ux + uz ) - v ) +
egc2 * ( ( ux + uz ) * ( fx + fz ) - uf );
tmp2 = eg2rho * ( ux + uz ) + egc2 * ( fx + fz );
g11[m+next + 1 + ldx*ldy] = itaurho * g11[current_pos] + tmp1 + tmp2;
g12[m+next - 1 - ldx*ldy] = itaurho * g12[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( ux - uz ) * ( ux - uz ) - v ) +
egc2 * ( ( ux - uz ) * ( fx - fz ) - uf );
tmp2 = eg2rho * ( ux - uz ) + egc2 * ( fx - fz );
g13[m+next + 1 - ldx*ldy] = itaurho * g13[current_pos] + tmp1 + tmp2;
g14[m+next - 1 + ldx*ldy] = itaurho * g14[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( uy + uz ) * ( uy + uz ) - v ) +
egc2 * ( ( uy + uz ) * ( fy + fz ) - uf );
tmp2 = eg2rho * ( uy + uz ) + egc2 * ( fy + fz );
g15[m+next + ldx + ldx*ldy] = itaurho * g15[current_pos] + tmp1 + tmp2;
g16[m+next - ldx - ldx*ldy] = itaurho * g16[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( uy - uz ) * ( uy - uz ) - v ) +
egc2 * ( ( uy - uz ) * ( fy - fz ) - uf );
tmp2 = eg2rho * ( uy - uz ) + egc2 * ( fy - fz );
g17[m+next + ldx - ldx*ldy] = itaurho * g17[current_pos] + tmp1 + tmp2;
g18[m+next - ldx + ldx*ldy] = itaurho * g18[current_pos] + tmp1 - tmp2;
}
}我们注意到,使用大量的双精度变量来存储暂时的数学运算结果以及有意义的物理数量,可能会导致该核函数的性能受寄存器压力影响。为了验证这个假设,我们可以如下编译核函数,以获取核函数的资源使用情况:
hipcc --offload-arch=gfx90a lbm.cpp -Rpass-analysis=kernel-resource-usage -c
lbm.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]
{
^
lbm.cpp:16:1: remark: SGPRs: 98 [-Rpass-analysis=kernel-resource-usage]
lbm.cpp:16:1: remark: VGPRs: 102 [-Rpass-analysis=kernel-resource-usage]
lbm.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
lbm.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]
lbm.cpp:16:1: remark: Occupancy [waves/SIMD]: 4 [-Rpass-analysis=kernel-resource-usage]
lbm.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]虽然没有寄存器溢出,但我们注意到占用率仅为每SIMD单元4个波浪(wave);约为最佳可实现情况的一半。查看之前显示的占用率表格,我们发现需要将使用的VGPRs数量从102减少到96或以下,以达到每个SIMD单元5个波浪的占用率。
优化1:移除不必要的数学函数调用
查看以下代码,我们注意到变量 current_phi 进行平方时使用了 pow 函数。
if(i <= nx && j <= ny && z <= nz)
{
m = i + ldx * (j + ldy * z);
current_pos = m + current;
current_phi = phi[m];
current_phi_2 = pow(current_phi,2.0);如前所述,编译器会内联所有对设备函数的调用,包括数学函数。一个可能的优化是,将通用函数 pow 替换为用于对变量进行平方的具体代码,如下所示:
if(i <= nx && j <= ny && z <= nz)
{
m = i + ldx * (j + ldy * z);
current_pos = m + current;
current_phi = phi[m];
current_phi_2 = current_phi * current_phi;重新编译新代码,我们观察到这些改变将VGPRs使用量从102减少到100:
hipcc --offload-arch=gfx90a lbm_nopow_1.cpp -Rpass-analysis=kernel-resource-usage -c
lbm_nopow_1.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]
{
^
lbm_nopow_1.cpp:16:1: remark: SGPRs: 98 [-Rpass-analysis=kernel-resource-usage]
lbm_nopow_1.cpp:16:1: remark: VGPRs: 100 [-Rpass-analysis=kernel-resource-usage]
lbm_nopow_1.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_nopow_1.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_nopow_1.cpp:16:1: remark: Occupancy [waves/SIMD]: 4 [-Rpass-analysis=kernel-resource-usage]
lbm_nopow_1.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_nopow_1.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_nopow_1.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]虽然减少的幅度看起来并不显著,但这为后续优化提供了更大的空间。
优化 n.2:将变量定义尽量靠近其首次使用的位置
一旦一个变量被定义,它的值会存储在寄存器中以备将来使用。如果在内核开头定义变量并在结尾使用,会显著增加寄存器的使用量。一个可能带来显著收益的优化是查找这些变量定义与其首次使用之间“距离较远”的情况,并手动重新排列代码。
经过快速的目视检查,我们可以看到数组位置 f[m] 的定义并不依赖于 ux、`uy` 或 uz,与其他数组 f1 到 f6 不同。
mu_phi = alpha * current_phi * ( current_phi_2 - phi2 ) - k * laplacian_phi[m];
fx = mu_phi * grad_phi_x[m];
fy = mu_phi * grad_phi_y[m];
fz = mu_phi * grad_phi_z[m];
ux = ( g1[current_pos] - g2[current_pos] + g7[current_pos] - g8[current_pos] + g9[current_pos] -
g10[current_pos] + g11[current_pos] - g12[current_pos] + g13[current_pos] - g14[current_pos] +
0.50 * fx ) * 1.0/rho;
uy = ( g3[current_pos] - g4[current_pos] + g7[current_pos] - g8[current_pos] - g9[current_pos] +
g10[current_pos] + g15[current_pos] - g16[current_pos] + g17[current_pos] - g18[current_pos] +
0.50 * fy ) * 1.0/rho;
uz = ( g5[current_pos] - g6[current_pos] + g11[current_pos] - g12[current_pos] - g13[current_pos] +
g14[current_pos] + g15[current_pos] - g16[current_pos] - g17[current_pos] + g18[current_pos] +
0.50 * fz ) * 1.0/rho;
af = 0.50 * gamma * mu_phi * itauphi;
cf = itauphi * ieta * current_phi;
f0[m] = itauphi1 * f0[m] + -3.0 * gamma * mu_phi * itauphi + itauphi * current_phi;
f1[current_pos] = itauphi1 * f1[current_pos] + af + cf * ux;
f2[current_pos] = itauphi1 * f2[current_pos] + af - cf * ux;
f3[current_pos] = itauphi1 * f3[current_pos] + af + cf * uy;
f4[current_pos] = itauphi1 * f4[current_pos] + af - cf * uy;
f5[current_pos] = itauphi1 * f5[current_pos] + af + cf * uz;
f6[current_pos] = itauphi1 * f6[current_pos] + af - cf * uz;将 f[m] 的定义移动到 ux 定义之前:
mu_phi = alpha * current_phi * ( current_phi_2 - phi2 ) - k * laplacian_phi[m];
f0[m] = itauphi1 * f0[m] + -3.0 * gamma * mu_phi * itauphi + itauphi * current_phi;
fx = mu_phi * grad_phi_x[m];
fy = mu_phi * grad_phi_y[m];
fz = mu_phi * grad_phi_z[m];
ux = ( g1[current_pos] - g2[current_pos] + g7[current_pos] - g8[current_pos] + g9[current_pos] -
g10[current_pos] + g11[current_pos] - g12[current_pos] + g13[current_pos] - g14[current_pos] +
0.50 * fx ) * 1.0/rho;
uy = ( g3[current_pos] - g4[current_pos] + g7[current_pos] - g8[current_pos] - g9[current_pos] +
g10[current_pos] + g15[current_pos] - g16[current_pos] + g17[current_pos] - g18[current_pos] +
0.50 * fy ) * 1.0/rho;
uz = ( g5[current_pos] - g6[current_pos] + g11[current_pos] - g12[current_pos] - g13[current_pos] +
g14[current_pos] + g15[current_pos] - g16[current_pos] - g17[current_pos] + g18[current_pos] +
0.50 * fz ) * 1.0/rho;
af = 0.50 * gamma * mu_phi * itauphi;
cf = itauphi * ieta * current_phi;
f1[current_pos] = itauphi1 * f1[current_pos] + af + cf * ux;
f2[current_pos] = itauphi1 * f2[current_pos] + af - cf * ux;
f3[current_pos] = itauphi1 * f3[current_pos] + af + cf * uy;
f4[current_pos] = itauphi1 * f4[current_pos] + af - cf * uy;
f5[current_pos] = itauphi1 * f5[current_pos] + af + cf * uz;
f6[current_pos] = itauphi1 * f6[current_pos] + af - cf * uz;我们注意到新的 VGPRs 使用量为 96,这使我们在 SIMD 上的占用从四个波提高到五个波:
hipcc --offload-arch=gfx90a lbm_rearrage_2.cpp -Rpass-analysis=kernel-resource-usage -c
lbm_rearrage_2.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]
{
^
lbm_rearrage_2.cpp:16:1: remark: SGPRs: 94 [-Rpass-analysis=kernel-resource-usage]
lbm_rearrage_2.cpp:16:1: remark: VGPRs: 96 [-Rpass-analysis=kernel-resource-usage]
lbm_rearrage_2.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_rearrage_2.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_rearrage_2.cpp:16:1: remark: Occupancy [waves/SIMD]: 5 [-Rpass-analysis=kernel-resource-usage]
lbm_rearrage_2.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_rearrage_2.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_rearrage_2.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]使用 restrict 关键字的说明
在类似 C++ 的 C 语言类型中,别名是实现高性能的主要限制之一。为了避免这个问题,C99 标准引入了“受限指针”:一种用户告知编译器不同的对象指针类型和函数参数数组不指向重叠内存区域的方式。这允许编译器执行更激进的优化,否则由于别名问题,这些优化可能无法进行。使用受限指针可能会增加寄存器压力,因为编译器会尝试通过将更多数据存储在寄存器中来重用数据。在 AMD 硬件上并非总是如此,有时使用 restrict 有助于减少 SGPR 和 VGPR 的压力。作为经验法则,在函数参数上使用 restrict 会倾向于减少 SGPR 的使用,同时可能会增加 VGPR 的使用。
例如,让我们在 g14 数组上添加 restrict 关键字,因为它在其余代码中多次重复使用,重新使用可能会带来更高的性能。
__global__ void kernel (double * phi, double * laplacian_phi,
double * grad_phi_x, double * grad_phi_y, double * grad_phi_z,
double * f0, double * f1, double * f2, double * f3, double * f4,
double * f5, double * f6,
double * g0, double * g1, double * g2, double * g3, double * g4,
double * g5, double * g6, double* g7, double * g8, double * g9,
double * g10, double * g11, double * g12, double * g13, double * __restrict__ g14,
double * g15, double * g16, double * g17, double * g18,
int nx, int ny, int nz, int ldx, int ldy, int current, int next,
double k, double alpha, double phi2, double gamma,
double itauphi, double itauphi1, double ieta,
double itaurho, double grav,
double eg1, double eg2, double eg0, double egc0, double egc1, double egc2)结果是 SGPR 和 VGPR 的寄存器压力都减少了:
lbm_2_restrict.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]
{
^
lbm_2_restrict.cpp:16:1: remark: SGPRs: 86 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: VGPRs: 94 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: Occupancy [waves/SIMD]: 5 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]通过将 restrict 添加到变量 g7,我们观察到 SGPR 的使用量进一步减少,但 VGPR 略有增加,但仍保持在每 SIMD 5 波的占用率:
lbm_2_restrict.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]
{
^
lbm_2_restrict.cpp:16:1: remark: SGPRs: 78 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: VGPRs: 96 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: Occupancy [waves/SIMD]: 5 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
lbm_2_restrict.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]结论
在这篇文章中,我们高层次地描述了在AMD的CDNA™2架构上运行的HPC应用和算法中,寄存器压力的性质和影响。我们还提供了一组被证明可以有效减少寄存器压力并提高占用率的规则。需要强调的是,这篇博客文章中所展示的结果仅能在使用ROCm 5.4的基于CDNA™2的GPU上完全复制。由于编译器及其启发式方法的不断变化,当使用不同于5.4版本的ROCm时,代码示例的结果可能会有所不同。我们鼓励读者尝试这些代码示例,并在不同的ROCm版本上评估每次更改后的性能。
配套代码示例
作者们感谢Justin Chang、Maria Ruiz Varela和Gina Sitaraman的有益评论和建议。如果您有任何问题或意见,请在GitHub的讨论版联系我们。