1、背景
在线平台用的是公司自己的服务器上面搭建的 MongoDB,测试那边反馈珊瑚海平台 MongoDB 有时会掉线,于是计划将本地数据库迁移到云平台。
2、问题所在
1、因为平台测试的同事还在正在使用平台进行测试工作,所以不可能把平台停掉,进行数据库的整体迁移。
2、如果你使用 Binlog 同步的方式,在同步完成后再修改代码,将主库修改为新的数据库,这样就不满足可回滚的要求,一旦迁移后发现问题,由于已经有增量的数据写入了新库而没有写入旧库,不可能再将数据库改成旧库。
3、迁移过程需要满足的目标
1、迁移应该是在线的迁移,也就是在迁移的同时还会有数据的写入;
2、数据应该保证完整性,也就是说在迁移之后需要保证新的库和旧的库的数据是一致的;
3、迁移的过程需要做到可以回滚,这样一旦迁移的过程中出现问题,可以立刻回滚到源库不会对系统的可用性造成影响。
4、操作
- 将新的库配置为源库的从库用来同步数据;如果需要将数据同步到多库多表,那么可以使用一些第三方工具获取 Binlog 的增量日志(比如开源工具 Canal),在获取增量日志之后就可以按照分库分表的逻辑写入到新的库表中了。
- 同时我们需要改造业务代码,在数据写入的时候不仅要写入旧库也要写入新库。当然,基于性能的考虑,我们可以异步地写入新库,只要保证旧库写入成功即可。但是我们需要注意的是,需要将写入新库失败的数据记录在单独的日志中,这样方便后续对这些数据补写,保证新库和旧库的数据一致性。
- 然后我们就可以开始校验数据了。由于数据库中数据量很大,做全量的数据校验不太现实。你可以抽取部分数据,具体数据量依据总体数据量而定,只要保证这些数据是一致的就可以。
- 双写时加开关,默认关闭双写,上线完成后关闭同步,同时打开开关,在低峰期的话数据丢失的概率不高。再配合数据校验的工作,是可以保证一致性的
- 如果一切顺利,我们就可以将读流量切换到新库了。由于担心一次切换全量读流量可能会对系统产生未知的影响,所以这里最好采用灰度的方式来切换,比如开始切换 10% 的流量,如果没有问题再切换到 50% 的流量,最后再切换到 100%。
- 由于有双写的存在,所以在切换的过程中出现任何的问题都可以将读写流量随时切换到旧库去,保障系统的性能。
- 在观察了几天发现数据的迁移没有问题之后,就可以将数据库的双写改造成只写新库,数据的迁移也就完成了。
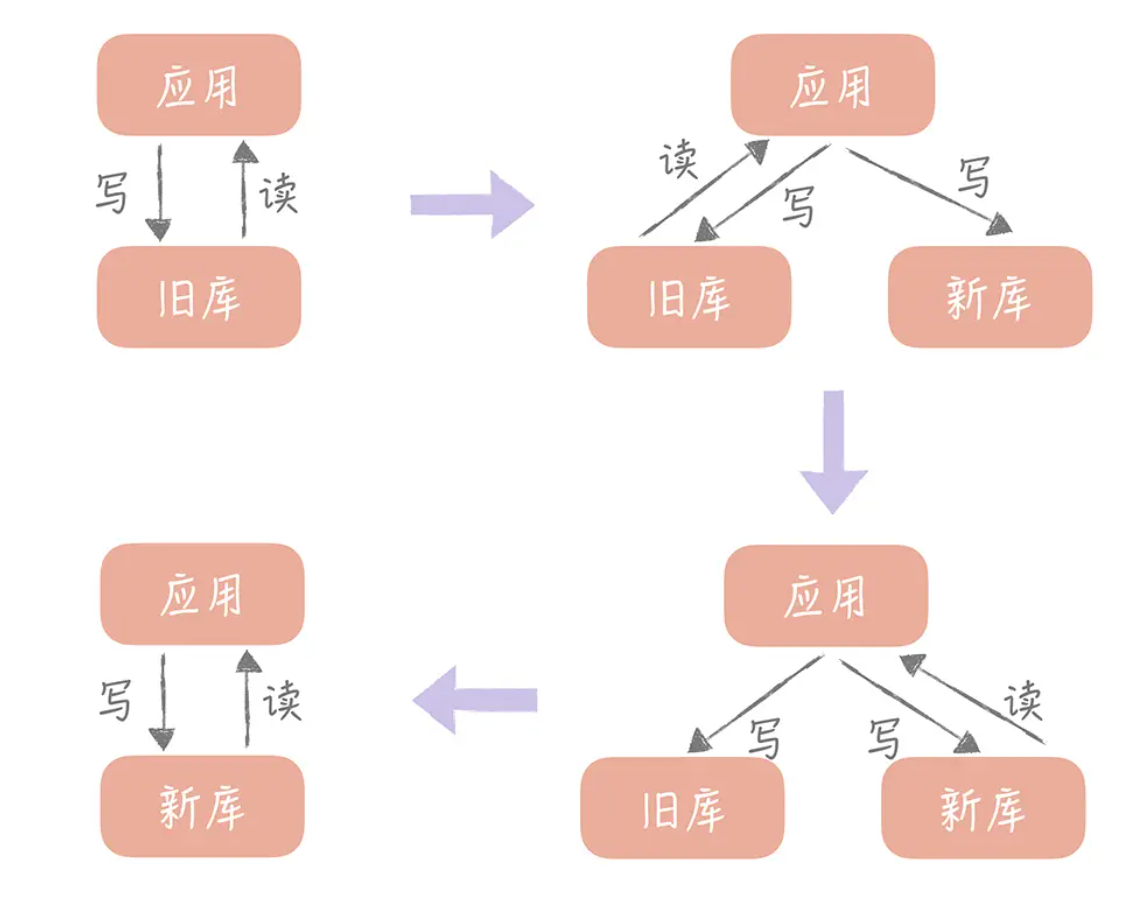
5、迁移计划
1、第一阶段:改造业务代码,写入接口同步写入新库和原库,查询业务查原库。
2、第二阶段:导出原库中的数据(可以将新数据库作为从库进行同步),批量写入新库。
4、第三阶段:业务代码修改为查新库,同步写新库和原库。(此时有问题就转回查原库)
5、第四阶段:查新库,写新库。(完成数据迁移)















![项目:微服务即时通讯系统客户端(基于C++QT)]四,中间界面搭建和逻辑准备](https://img-blog.csdnimg.cn/img_convert/3202a33734dc490865719c8cbc7c9c05.png)