大型语言模型 (LLM)(如 GPT-4、BERT 和其他基于 Transformer 的模型)彻底改变了 AI 格局。这些模型需要大量计算资源来进行训练和推理。选择合适的 GPU 进行 LLM 推理可以极大地影响性能、成本效益和可扩展性。
在本文中,我们将探索最适合 LLM 推理任务的 NVIDIA GPU,并根据 CUDA 核心、Tensor 核心、VRAM、时钟频率和价格对它们进行比较。无论你是在设置个人项目、研究环境还是大规模生产部署,本指南都将帮助你选择最适合需求的 GPU。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、了解关键 GPU 规格
在深入了解列表之前,让我们简要介绍一下使 GPU 适合 LLM 推理的关键规格:
- CUDA 核心:这些是 GPU 的主要处理单元。更高的 CUDA 核心数量通常意味着更好的并行处理性能。
- Tensor 核心:专为深度学习任务设计的专用核心,例如矩阵乘法,这对于神经网络操作至关重要。
- VRAM(视频 RAM):这是 GPU 可用于存储数据和模型的内存。更多的 VRAM 可以高效处理更大的模型和数据集。
- 时钟频率:表示 GPU 运行的速度,以 MHz 为单位。频率越高,性能越好。
- 价格:GPU 的成本是一个关键因素,尤其是对于预算有限的企业或研究实验室而言。平衡性能需求和可负担性至关重要。
2、用于 LLM 推理的顶级 NVIDIA GPU
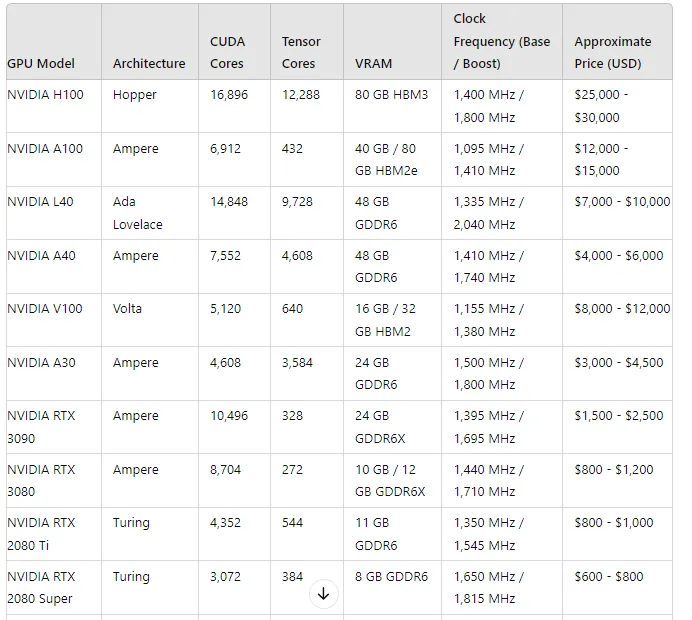
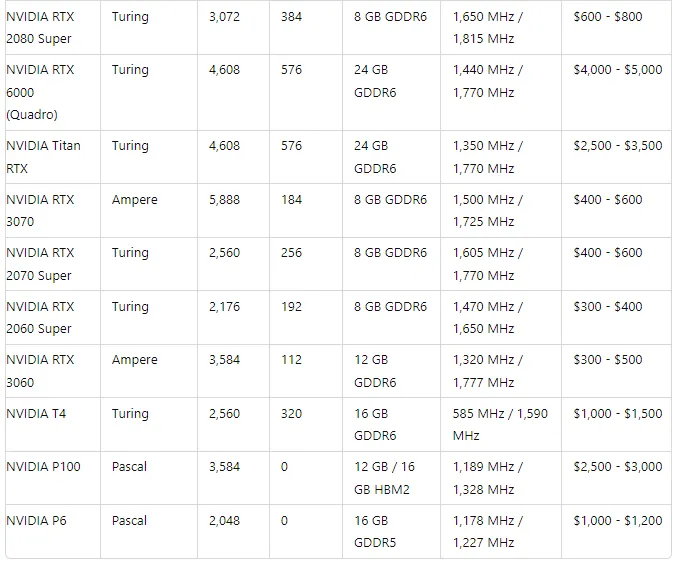
下表根据 NVIDIA GPU 对 LLM 推理的适用性对其进行排名,同时考虑了性能和价格:
3、LLM 推理的首选
- NVIDIA H100:作为 LLM 推理任务的无可争议的领导者,H100 提供最多数量的 Tensor Core 和 CUDA Core。它还配备了 80 GB 的 HBM3 内存,非常适合处理最大的模型。然而,这种能力的价格不菲,因此最适合预算充足的企业和研究实验室。
- NVIDIA A100:另一个强有力的竞争者 A100 凭借其高 Tensor Core 数量和灵活的内存选项(40 GB 或 80 GB HBM2e)为 LLM 任务提供了出色的性能。它比 H100 更具成本效益,同时仍提供顶级性能。
- NVIDIA L40:基于 Ada Lovelace 架构的 L40 在性能和成本之间实现了平衡。它拥有高 CUDA 和 Tensor Core 数量,以及 48 GB 的 GDDR6 内存。对于那些寻求高性能但又不想花太多钱购买 H100 或 A100 的人来说,这是一个不错的选择。
- NVIDIA A40:A40 拥有 4,608 个 Tensor Core 和 48 GB GDDR6 VRAM,性能稳定,适合以更适中的价格执行高性能推理任务。
- NVIDIA V100:虽然基于较旧的 Volta 架构,但 V100 仍凭借强大的 Tensor Core 数量和 HBM2 内存占据一席之地。对于那些想要强劲性能但又不想购买最新型号的人来说,这是一个不错的选择。
4、经济实惠的选择
对于预算紧张或项目规模较小的用户,仍有几种可行的选择:
- NVIDIA RTX 3090 和 RTX 3080:这些消费级 GPU 以其价格提供出色的性能,使其成为需要强大本地设置的开发人员或研究人员的理想选择。
- NVIDIA RTX 2080 Ti 和 RTX 2080 Super:这些 GPU 提供不错的 Tensor Core 数量,可以有效处理中等大小的模型。它们非常适合小规模推理任务或开发工作。
- NVIDIA RTX 3060、RTX 2060 Super 和 RTX 3070:虽然这些 GPU 的 Tensor Core 较少,但它们非常实惠,并且仍然可以充分执行轻量级推理任务。
5、结束语
选择适合 LLM 推理的 GPU 在很大程度上取决于你的特定需求和预算。如果你运营的是大型生产环境或研究实验室,投资 H100 或 A100 将提供无与伦比的性能。对于规模较小的团队或个人开发者来说,RTX 3090 或 RTX 3080 等 GPU 在成本和性能之间实现了良好的平衡。
原文链接:大模型推理GPU选型指南 - BimAnt