摘要
关键词:动态参数;多属性决策;critic权重法;DBSCA聚类分析
引言
云服务存储系统是一种基于互联网的数据存储服务,它可以为用户提供大规模、低成本、高可靠的数据存储空间。云服务存储系统的核心技术之一是数据容错技术,它可以保证在存储设备发生故障时,数据不会丢失或损坏。
随着互联网和大数据发展,云服务存储供应商面临的一个重要问题是数据存储。随着数据量的不断增长,如何在保证数据可靠性的同时,降低数据存储成本,是一个亟待解决的挑战。
数据可靠性是指数据在存储、传输和处理过程中不受损坏或丢失的能力。数据存储成本是指为了实现数据存储所需投入的资源和费用。数据可靠性和数据存储成本是两个相互制约的因素,一般来说,提高数据可靠性需要增加数据冗余度,而增加数据冗余度会导致增加数据存储成本。
为了解决这一矛盾,云服务存储供应商常用的方法是使用纠删码(Erasure Code)技术进行数据存储。纠删码是一种编码技术,它可以将原始数据分割成k个数据块,并通过编码生成m个冗余块块,使得任意k个块就可以恢复原始数据。纠删码具有高效利用存储空间、提高容错能力、降低恢复开销等优点。纠删码在云服务存储系统中得到了广泛的应用。
然而,纠删码技术也存在一些问题和挑战。其中一个重要的问题是如何确定最佳的纠删码参数(k,m),即被分割的数据块个数和冗余块个数。这两个参数会影响到纠删码技术的各项性能指标,例如数据冗余度、存储成本、传输开销、可靠性、恢复性能等。如果k或m过大,会导致数据冗余度和存储成本过高;如果k或m过小,会导致可靠性和恢复性能下降。
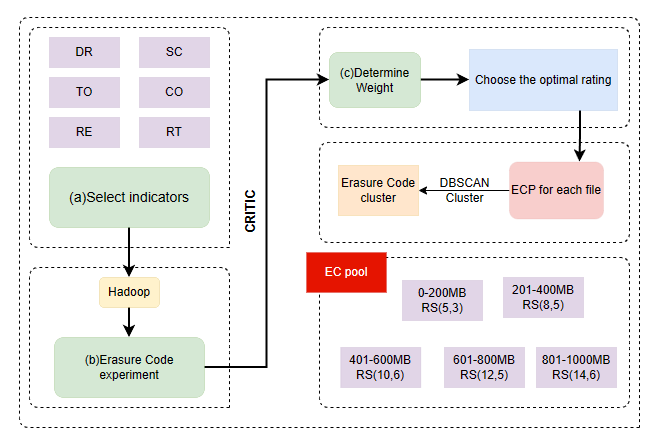
本文提出了一种基于文件大小的纠删码参数选择方法,该方法结合了分析模型和实验数据两种方法的优点,既可以得到接近理论的最优解,又可以节省时间和资源,而且可以适应不同的实验环境。该方法的基本思想是,根据文件的大小,选择合适的纠删码参数,以实现存储成本和可靠性的平衡。该方法分为两个步骤:首先,通过在Hadoop软件上模拟实验,得到不同文件大小和纠删码参数的性能指标,包括数据冗余度、存储成本、传输开销、可靠性、恢复性能等,然后使用CRITIC客观权重法为这些性能指标赋权,并进行归一化处理,得到每种文件大小和纠删码参数的综合评分,从中选出最优的纠删码参数作为该文件大小的最佳参数;其次,使用DBSCAN聚类算法,将不同文件大小的最佳纠删码参数进行聚类,得到几组纠删码参数,作为部署在云服务存储系统中的纠删码池参数。
相关工作
纠删码是一种基于编码理论的数据容错技术,它将数据切分成多个数据块,然后通过编码算法,生成一定数量的冗余块,存储在不同的节点上。纠删码的优点是存储开销低,容错能力强,可以容忍任意多个节点的故障。然而,纠删码的缺点是编码和解码需要计算开销,数据读写和恢复需要传输开销,以及对于小文件的处理效率低。
纠删码的性能受到其参数的影响,主要包括数据块个数、冗余块个数和故障编码块个数。数据块个数和冗余块个数决定了纠删码的存储效率和容错能力,故障编码块个数决定了纠删码的恢复效率。不同的纠删码参数可能适合不同的文件大小,因为文件大小会影响数据的切分、编码和传输。因此,如何根据文件大小选择合适的纠删码参数,是一个重要的问题。
动机
云服务存储供应商面临的一个重要问题是如何在现代计算系统的高度动态、不断变化的性质与计算系统不断增长的存储需求相结合的情况下,高效地配置和管理存储资源。
当使用固定参数配置的管理方法时,所有传入的数据都使用一套纠删码参数进行配置,这可能导致资源利用的不均衡。不同大小的文件可能需要不同的纠删码配置来实现最佳的纠删码效果。如果使用固定的纠删码参数,较小的文件可能会浪费存储资源,因为它们使用了比实际需要更多的冗余数据。相反,较大的文件可能会受到不足的保护,因为它们未能获得足够的冗余数据。不当的纠删码参数可能会导致性能下降,浪费更多的存储成本和计算成本,而没有实际的好处。
当依赖于手动管理方法时,手动确定计算系统的适当纠删码配置通常会导致次优配置,而且从一个特定的EC配置更改到另一个EC配置可能是昂贵的或麻烦的。我们需要的是一种技术解决方案,以减轻管理员在动态变化的计算和存储系统中确定和实施纠删码的负担。
尽管使用不同的纠删码参数去适应不同大小的文件可能会增加系统的复杂性(需要维护一个最低存储成本和最高可靠性的表),但也可以提供更大的灵活性和性能优化的机会。复杂性的增加可能需要更多的管理和维护工作,但可以根据实际需求来权衡这些问题。
本文的主要贡献如下:
- 提出了一种纠删码参数选择方法,该方法可以综合考虑多个性能指标,如数据冗余度、存储成本、传输开销、可靠性、恢复性能等,并为每个文件自动地确定最佳的纠删码参数。
- 设计了一种基于文件大小的在线文件存储的分组策略,该策略可以将文件按照不同的大小范围分组到不同的数据池中,并为每个数据池设置不同的纠删码参数,以实现实际最低存储成本和最高可靠性的权衡。
- 在Hadoop平台上进行了实验,结果表明,该方法可以有效地降低数据存储成本,提高数据可靠性,并优化数据恢复和应用程序性能。
这些贡献对于云服务存储供应商来说具有重要的实际意义。我们的目标是为云服务存储供应商提供一种有效的解决方案,以应对现代计算环境中的存储挑战。我们希望这种方法能够帮助云服务存储供应商,为存储不同大小的数据的纠删码技术选择合适的纠删码参数,以便更好地管理他们的存储资源,提高服务质量,降低成本,最终实现更高的客户满意度。
准备工作
纠删码被广泛应用于云存储系统领域,产生低存储开销和高可靠性。通过应用纠删码,一段数据被划分为k块数据块,这k块数据块通过矩阵编码被编码为m块校验块,编码块k+m总数被分发以存储在k+m节点上,数据可以从k+m个编码块中选择k个块进行恢复,纠删码存储、恢复数据整体图如下所示:
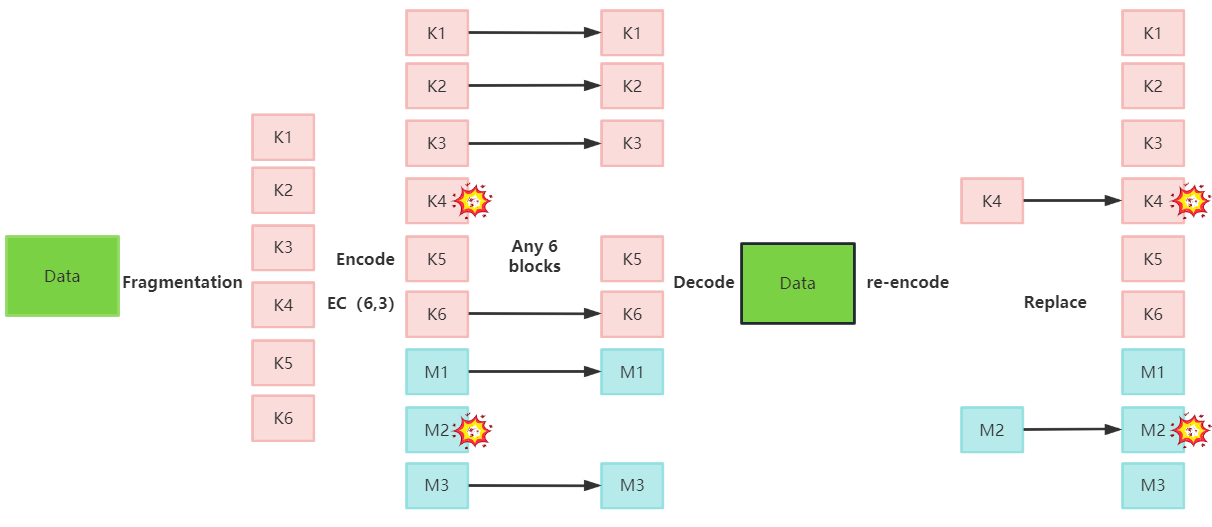
纠删码的原理是将数据乘以编码矩阵,利用矩阵反演技术实现译码过程。实际上,为了确保乘法的结果保持在固定的大小内,通过将矩阵乘法映射到有限域来获得纠删码中的矩阵乘法结果。
模型与问题制定
各符号与对应解释:
| Notation | Description |
|---|---|
| file_size | 原始的文件大小 |
| k | X使用纠删码的数据块个数 |
| m | X使用纠删码的冗余块个数 |
| m’ | 故障编码块的个数 |
方案框架图:
问题表述
传入存储系统的文件file,目的是根据其文件大小自适应匹配纠删码存储成本和可靠性达到平衡的纠删码方案以及最佳参数k和m,根据选定的性能指标可知,这是一个多目标优化的问题,存在帕累托最优解。我们的目标就是获得帕雷依托最优解。
将各种不同大小的文件输入Hadoop中进行纠删码实验:文件的分割、编码、放置和恢复等操作,得到纠删码实验的性能指标,然后将得到的数据使用CRITIC客观权重赋权法为每一项性能指标赋权,将赋权后的性能参数相加得到评分,选出每一个file的最高评分,作为file的纠删码参数,最后得到一张最低存储成本和最高可靠性权衡下的(filesize,k,m)表。
然后将这张表根据DBSCAN算法,一种基于空间密度的聚类算法,分别建立几个数据池,应用于实现生活中的纠删码配置部署的低成本,最终实现纠删码存储系统低存储成本和高可靠性之间的最佳权衡。
纠删码参数自适应匹配问题(ECP-AMP)的优化目标是最小化总存储成本和最大化可靠性之间的权衡,即Cost Reliability Trade-off,它是根据存储在纠删码存储系统中的编码块和数量、大小以及数据可靠性计算的。
存储限制
在这项研究中,我们研究了最一般的编码放置场景,其中数据存储系统中的每个边缘服务器上最多有一个编码块。
此存储限制概括了每台边缘服务器上可以存储的编码块数。允许在每个边缘服务器上存储多个编码块将更容易找到存储解决方案,但会降低存储在系统中的数据的可靠性。以一个极端情况为例,所有的k+m编码块仅存储在边缘存储系统中的一台边缘服务器上,以便为所有用户提供服务。如果该边缘服务器出现故障,则所有用户都无法使用数据。相反,如果每个边缘服务器上只能存储一个编码块,则边缘服务器的故障不会显着降低数据的可靠性。事实上,只要所有用户仍然可以检索k编码块,边缘存储系统可能仍然能够为所有用户提供服务。存储限制还通过放宽应用程序供应商在单个边缘服务器上保留大量存储资源的需求。



















