文章目录
- 一、什么是 Longhorn
- 二、架构设计
- 1、工作原理
- 2、工作流程
- 3、基于微服务设计的优势
- 三、安装
- 1、安装要求
- 2、使用 Longhorn 命令行工具(验证方式一)
- 3、使用环境检查脚本(验证方式之二)
- 3.1、安装 jq
- 3.2、运行脚本
- 4、安装 open-iscsi
- 4.1、SUSE 和 openSUSE
- 4.2、Debian 和 Ubuntu
- 4.3、RHEL、CentOS 和 EKS (带有 AmazonLinux2 映像的 EKS Kubernetes Worker AMI)
- 4.4、open-iscsi 安装程序
- 5、安装 NFSv4 客户端
- 5.1、Debian 和 Ubuntu
- 5.2、对于 RHEL、CentOS 和 EKS (EKS Kubernetes Worker AMI with AmazonLinux2 image)
- 5.3、SUSE/OpenSUSE
- 5.4、nfs 安装程序
- 6、检查 Kubernetes 版本
- 7、安装 Cryptsetup 和 LUKS
- 7.1、Debian 和 Ubuntu
- 7.2、RHEL、CentOS、Rocky Linux 和 EKS(EKS Kubernetes Worker AMI with AmazonLinux2 image)
- 7.3、SUSE/OpenSUSE
- 8、验证
- 9、【ERROR】kernel module iscsi_tcp is not enabled on k8s-node1/2
- 9.1、解决方案
- 四、部署
- 1、添加 Longhorn Helm 存储库
- 2、helm 安装 1.7.1 版本的 longhorn
- 3、查看应用 pod 状态
- 4、开启 UI
- 4.1、编辑使用 NodePort 类型的 svc 资源清单
- 4.2、创建 SVC
- 4.3、访问 Longhorn UI
- 5、查看默认创建的存储类 StorageClass
- 五、使用 Longhorn 为 MySQL 应用提供数据持久化
- 1、创建 PVC 测试使用 longhorn 动态创建 PV
- 2、部署一个 MySQL 应用来使用上面的 PVC 进行数据持久化
- 3、创建上面的 PVC、Deployment
- 4、进入容器内部创建数据
- 5、登录到 Pod 所在节点验证数据是否存在
- 6、重建 Pod 查看数据是否依然存在
- 7、【ERROR】Scheduling Failure Replica Scheduling Failure Error Message: replica scheduling failed
- 7.1、原因
- 7.2、解决方案
- 7.3、再次动态创建 PV 持久卷
- 六、使用 Longhorn 备份恢复
- 1、对测试的 MySQL 卷创建快照
- 2、查看 Pod 的调度节点数据目录
- 3、创建周期任务 Create Recurring Job
- 4、使用 Longhorn 的 StorageClass 创建快照
- 5、创建 RecurringJob 以创建重复快照和备份(重复作业)
- 5.1、配置参数
- 6、备份卷
- 6.1、配置备份目标为 NFS 服务以备份卷
- 6.2、【ERROR】为什么设置了备份目标 BackupTarget 选择卷 Create Backup选项是不可选的呢?
- 6.2.1、原因
- 6.2.2、解决方案
- 6.2.3、验证
- 6.3、查看对应备份数据
- 6.4、backupvolumes 对象
- 6.5、查看 NFS 服务器上备份的数据
- 6.6、选择需要备份的快照
- 6.7、基于备份数据恢复数据
- 七、ReadWriteMany 卷的使用
- 1、创建访问模式为 RWX 的 PVC
- 2、创建 Deployment 使用上面创建的 PVC 做持久化数据
- 3、查看 share-manager 的 Pod 日志信息
- 4、创建一个用来读取数据的 Pod
- 5、创建 NodePort 类型的 SVC 访问应用
- 6、通过 NodePort 访问应用
- 7、从 reader Pod 中写入数据验证 RWX 数据是否正确
- 八、CSI 卷快照
- 1、什么是卷快照
- 2、卷快照的生命周期
- 2.1、资源供应
- 2.2、资源绑定
- 2.3、对使用中的 PVC 的保护机制
- 2.4、资源删除
- 3、查看 csi-snapshotter Pod
- 4、安装CRDs
- 4.1、克隆 snapshotter 仓库地址
- 4.2、切换对应分支使用 kustomize 工具来构建指定目录下的资源配置
- 4.3、验证创建的 Snapshot CRDs
- 4.4、查看 csi-snapshotter Leader Pod 日志情况
- 4.5、安装通用快照控制器
- 4.5.1、【ERROR】snapshot-controller 拉取镜像在 ImagePullBackOff 与 ErrImagePull 状态间反复横跳
- 5、使用 CSI 卷快照功能
- 5.1、创建 VolumeSnapshot 对象
- 5.2、创建存储快照类 VolumeSnapshotClass
- 5.3、创建并查看资源对象
- 5.4、查看动态创建的 VolumeSnapshotContent 对象
- 6、基于快照创建/恢复新的 PVC
- 6.1、基于创建的 volumesnapshot 创建新的 PVC
- 7、卷克隆
- 7.1、对 mysql-pvc 存储卷克隆
- 7.2、与源 PVC 的对比
- 7.3、在 Longhorn UI 进行查看
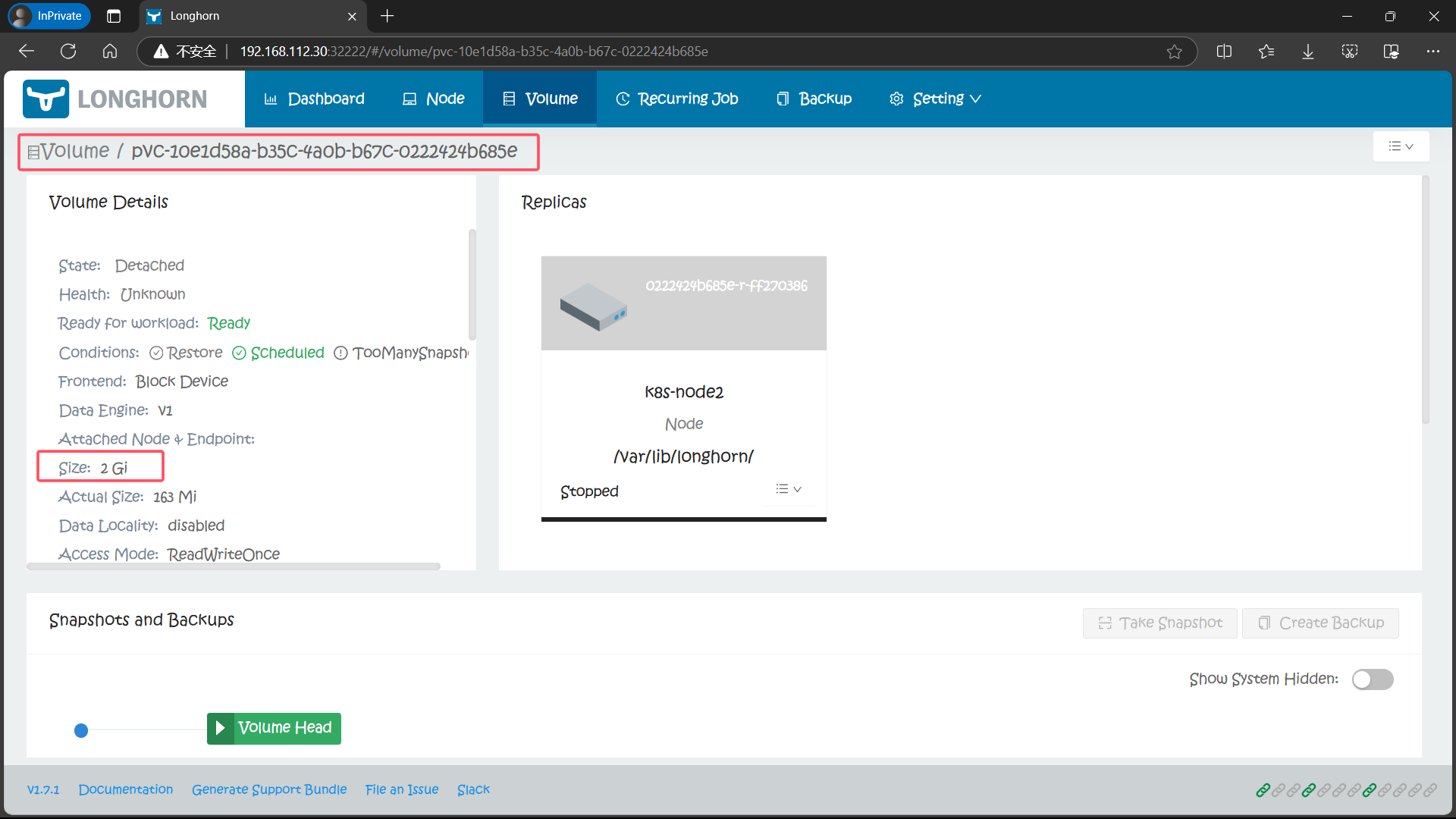
- 8、卷动态扩容
- 8.1、通过 Longhorn UI 进行卷扩容
- 8.2、通过 PVC 进行扩容
- 8.2.1、确认 StroageClass longhorn 开启了 allowVolumeExpansion
- 8.2.2、修改 spec.resources.requests.storage 的值
- 8.2.3、查看 PVC 的 events 信息
- 8.3、通过 Longhorn UI 查看
一、什么是 Longhorn
Longhorn官网
Longhorn 是针对 Kubernetes 的轻量级、可靠且易于使用的分布式块存储系统。
Longhorn 是一款免费的开源软件。它最初由 Rancher Labs 开发,目前正作为云原生计算基金会的孵化项目进行开发。
使用 Longhorn,可以:
- 使用 Longhorn 卷作为 Kubernetes 集群中分布式有状态应用程序的持久存储
- 将块存储分区为 Longhorn 卷,这样无论是否有云提供商,都可以使用 Kubernetes 卷
- 跨多个节点和数据中心复制块存储以提高可用性
- 将备份数据存储在外部存储中,例如 NFS 或 AWS S3
- 创建跨集群灾难恢复卷,以便可以从第二个 Kubernetes 集群的备份中快速恢复主 Kubernetes 集群的数据
- 安排卷的定期快照,并安排定期备份到 NFS 或 S3 兼容的辅助存储
- 从备份恢复卷
- 在不破坏持久卷的情况下升级 Longhorn
Longhorn 带有独立的 UI,可以使用 Helm、kubectl 或 Rancher 应用程序目录进行安装。
二、架构设计
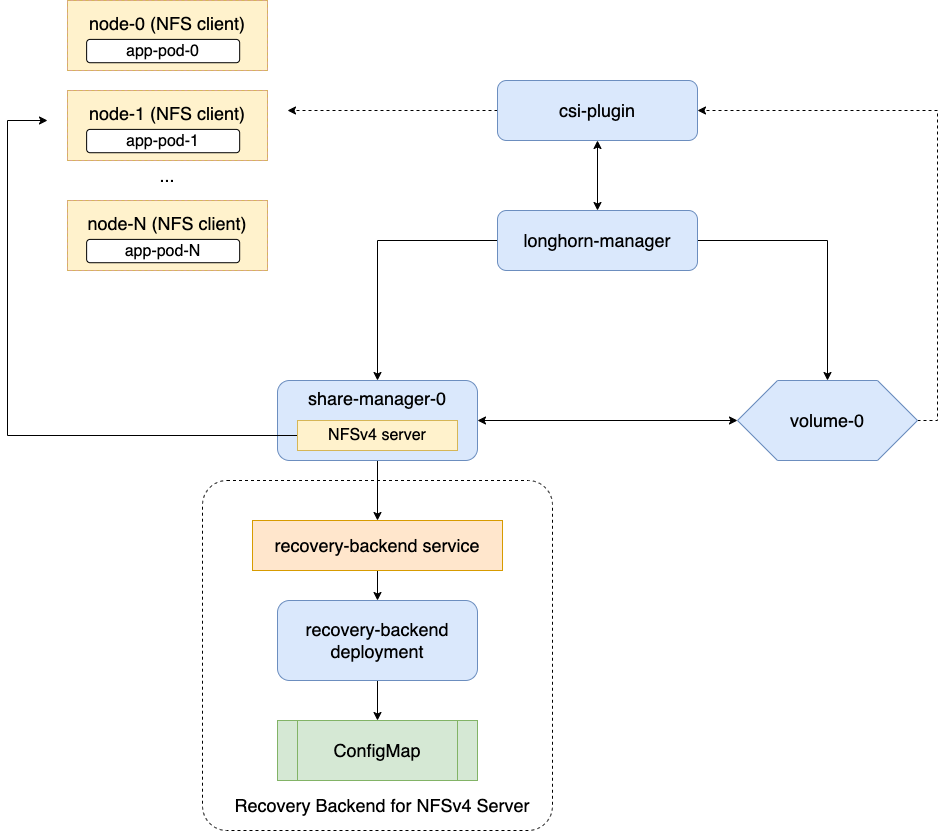
Longhorn 设计有两层:数据平面和控制平面。Longhorn Engine 是存储控制器,对应数据平面,Longhorn Manager 对应控制平面。
1、工作原理
Longhorn Manager Pod 作为 Kubernetes DaemonSet在 Longhorn 集群中的每个节点上运行。它负责在 Kubernetes 集群中创建和管理卷,并处理来自 UI 或 Kubernetes 卷插件的 API 调用。它遵循 Kubernetes 控制器模式,有时也称为操作员模式。
Longhorn Manager 与 Kubernetes API 服务器通信以创建一个新的 Longhorn 卷CR。然后 Longhorn Manager 监视 API 服务器的响应,当它看到 Kubernetes API 服务器创建了新的 Longhorn 卷 CR 时,Longhorn Manager 就会创建一个新的卷。
当 Longhorn Manager 被要求创建卷时,它会在卷所连接的节点上创建一个 Longhorn Engine 实例,并在将要放置副本的每个节点上创建一个副本。副本应放置在单独的主机上以确保最大可用性。
副本的多条数据路径保证了 Longhorn 卷的高可用性,即使某个副本或者 Engine 出现问题,也不会影响所有副本或者 Pod 对卷的访问,Pod 依然可以正常运行。
Longhorn Engine 始终与使用 Longhorn 卷的 Pod 运行在同一个节点上。它会在存储在多个节点上的多个副本之间同步复制该卷。
引擎和副本使用 Kubernetes 进行编排。
2、工作流程
Longhorn 引擎、副本实例和磁盘之间的读/写数据流
下图所示
- 有三个具有 Longhorn 卷的实例。
- 每个卷都有一个专用的控制器,称为 Longhorn Engine,作为 Linux 进程运行。
- 每个 Longhorn 卷都有两个副本,每个副本都是一个 Linux 进程。
- 图中的箭头表示卷、控制器实例、副本实例和磁盘之间的读写数据流。
- 通过为每个卷创建一个单独的 Longhorn Engine,如果一个控制器出现故障,其他卷的功能不会受到影响。

3、基于微服务设计的优势
在 Longhorn 中,每个 Engine 只需服务一个卷,从而简化了存储控制器的设计。由于控制器软件的故障域被隔离到各个卷,因此控制器崩溃只会影响一个卷。
Longhorn 引擎足够简单和轻量,因此我们可以创建多达 100,000 个独立引擎。Kubernetes 调度这些独立引擎,从一组共享磁盘中提取资源,并与 Longhorn 一起形成一个弹性分布式块存储系统。
由于每个卷都有自己的控制器,因此每个卷的控制器和副本实例也可以升级,而不会导致 IO 操作明显中断。
Longhorn 可以创建一个长期运行的作业来协调所有活动卷的升级,而不会中断系统的持续运行。为了确保升级不会导致不可预见的问题,Longhorn 可以选择升级一小部分卷,如果升级过程中出现问题,则回滚到旧版本。
三、安装
1、安装要求
安装 Longhorn 的 Kubernetes 集群中的每个节点都必须满足以下要求:
-
与 Kubernetes 兼容的容器运行时(Docker v1.13+、containerd v1.3.7+ 等)
-
Kubernetes >= v1.21
-
open-iscsi已安装,并且iscsid守护程序在所有节点上运行。Longhorn依赖于iscsiadm主机为 Kubernetes 提供持久卷。 -
RWX 支持要求每个节点都安装 NFSv4 客户端。
-
主机文件系统支持file extents存储数据的功能。目前支持:
- ext4
- XFS
-
bash,curl,findmnt,grep,awk,blkid,lsblk必须安装。 -
Mount propagation必须启用,它允许将一个容器挂载的卷与同一 pod 中的其他容器共享,甚至可以与同一节点上的其他 pod 共享- Mount propagation
为了正确部署和运行 Longhorn,Longhorn 工作负载必须能够以 root 身份运行。
2、使用 Longhorn 命令行工具(验证方式一)
该 longhornctl 工具是用于 Longhorn 操作的 CLI。要检查先决条件和配置,请下载该工具并运行 check 子命令:
# For AMD64 platform
curl -sSfL -o longhornctl https://github.com/longhorn/cli/releases/download/v1.7.1/longhornctl-linux-amd64
# For ARM platform
curl -sSfL -o longhornctl https://github.com/longhorn/cli/releases/download/v1.7.1/longhornctl-linux-arm64
chmod +x longhornctl
./longhornctl check preflight

3、使用环境检查脚本(验证方式之二)
自 Longhorn v1.7.0 以来,引入了Longhorn 命令行工具。环境检查脚本environment_check.sh的功能与 Longhorn 命令行工具的功能重叠。因此,该脚本已在 v1.7.0 中弃用,并计划在 v1.8.0 中删除。
3.1、安装 jq
jq,在运行环境检查脚本之前可能需要在本地安装。
yum install -y jq
3.2、运行脚本
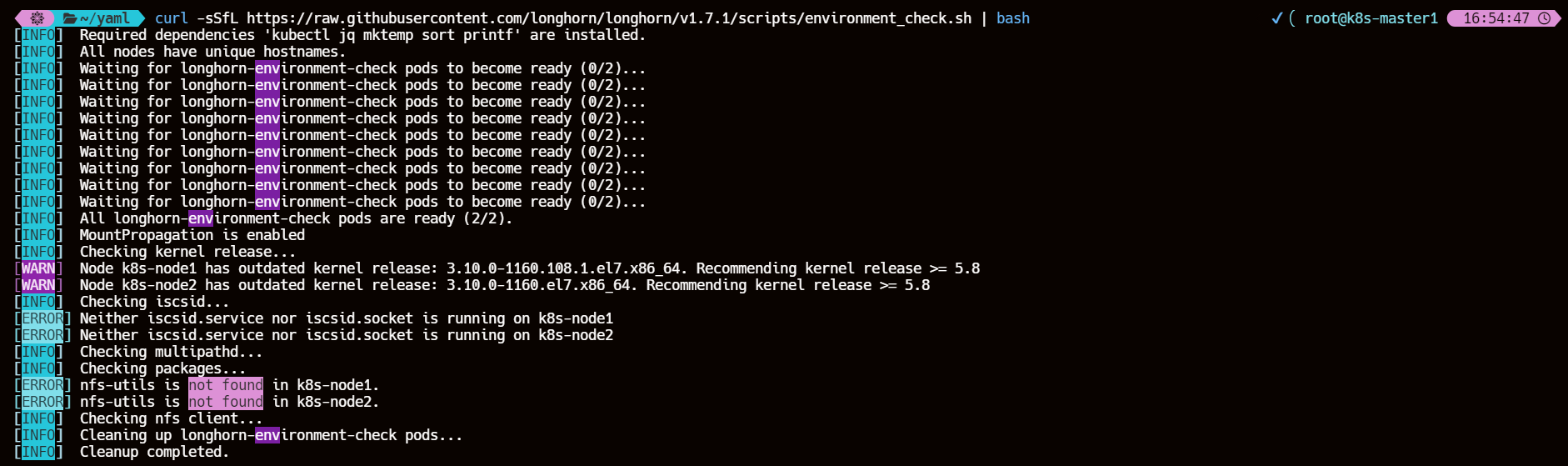
curl -sSfL https://raw.githubusercontent.com/longhorn/longhorn/v1.7.1/scripts/environment_check.sh | bash
4、安装 open-iscsi
4.1、SUSE 和 openSUSE
zypper install open-iscsi
systemctl enable iscsid
systemctl start iscsid
4.2、Debian 和 Ubuntu
apt-get install open-iscsi
4.3、RHEL、CentOS 和 EKS (带有 AmazonLinux2 映像的 EKS Kubernetes Worker AMI)
yum --setopt=tsflags=noscripts install iscsi-initiator-utils
echo "InitiatorName=$(/sbin/iscsi-iname)" > /etc/iscsi/initiatorname.iscsi
systemctl enable iscsid
systemctl start iscsid
4.4、open-iscsi 安装程序
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/v1.7.1/deploy/prerequisite/longhorn-iscsi-installation.yaml
# 检查安装程序的 pod 状态
kubectl get pod | grep longhorn-iscsi-installation
5、安装 NFSv4 客户端
在 Longhorn 系统中,备份功能需要 NFSv4、v4.1 或 v4.2,而 ReadWriteMany (RWX) 卷功能需要 NFSv4.1。在安装 NFSv4 客户端用户空间守护程序和实用程序之前,请确保在每个 Longhorn 节点上都启用了客户端内核支持。
- 检查NFSv4.1内核是否启用了支持
cat /boot/config-`uname -r`| grep CONFIG_NFS_V4_1
- 检查NFSv4.2内核是否启用了支持
cat /boot/config-`uname -r`| grep CONFIG_NFS_V4_2



5.1、Debian 和 Ubuntu
apt-get install nfs-common
5.2、对于 RHEL、CentOS 和 EKS (EKS Kubernetes Worker AMI with AmazonLinux2 image)
yum install -y nfs-utils
5.3、SUSE/OpenSUSE
zypper install nfs-client
5.4、nfs 安装程序
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/v1.7.1/deploy/prerequisite/longhorn-nfs-installation.yaml
# 检查安装程序的 pod 状态
kubectl get pod | grep longhorn-nfs-installation
6、检查 Kubernetes 版本
kubectl version --short



应该Server Version是> = v1.21。
7、安装 Cryptsetup 和 LUKS
7.1、Debian 和 Ubuntu
apt-get install cryptsetup
apt-get install dmsetup
7.2、RHEL、CentOS、Rocky Linux 和 EKS(EKS Kubernetes Worker AMI with AmazonLinux2 image)
yum install -y cryptsetup
yum install -y device-mapper
7.3、SUSE/OpenSUSE
zypper install cryptsetup
zypper install device-mapper
8、验证
curl -sSfL https://raw.githubusercontent.com/longhorn/longhorn/v1.7.1/scripts/environment_check.sh | bash

9、【ERROR】kernel module iscsi_tcp is not enabled on k8s-node1/2

9.1、解决方案
# 将iscsi_tcp模块加载到内核中
modprobe iscsi_tcp
# 验证模块是否成功加载
lsmod | grep iscsi_tcp


再次重新运行检查脚本应该就没有问题了
四、部署
- Rancher catalog app
- kubectl
- Helm
- Fleet
- Flux
- ArgoCD
我们使用 helm 部署
1、添加 Longhorn Helm 存储库
helm repo add longhorn https://charts.longhorn.io
helm repo update

2、helm 安装 1.7.1 版本的 longhorn
helm install longhorn longhorn/longhorn --namespace longhorn-system --create-namespace --version 1.7.1

3、查看应用 pod 状态
kubectl get pods -n longhorn-system
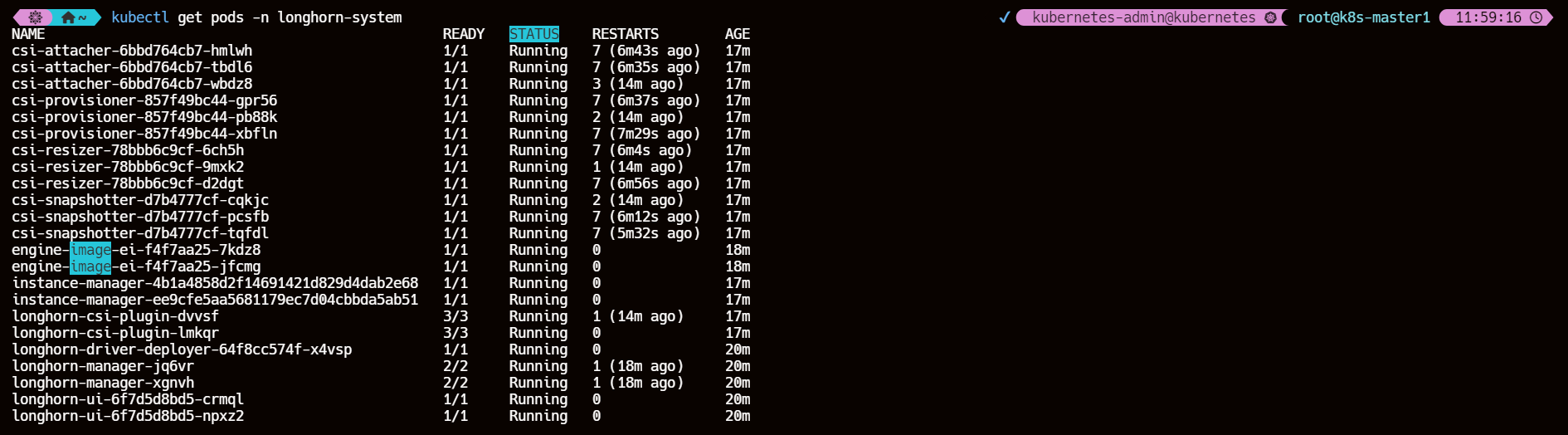
csi-attacher-xxx、csi-provisioner-xxx、csi-resizer-xxx、csi-snapshotter-xxx是 csi 原生的组件longhorn-manager-xxx是运行在每个节点上的 Longhorn Manager,是一个控制器,也为 Longhorn UI 或者 CSI 插件提供 API,主要功能是通过修改 Kubernetes CRD 来触发控制循环,比如 volume attach/detach 操作longhorn-ui-xxx提供 Longhorn UI 服务,提供一个可视化的控制页面- Longhorn Engine 数据平面,提供两种工作模式:Engine Mode(
instance-manager-e-xxx的 Pod)、Replica Mode(instance-manager-r-xxx的 Pod),Replica 负责实际数据的写入,每个副本包含数据的完整副本,Engine 连接到副本实现 volume 的数据平面,任何写操作都会同步到所有副本,读操作从任意一个副本读取数据
4、开启 UI
直接使用 NodePort 开放 longhorn UI 服务
4.1、编辑使用 NodePort 类型的 svc 资源清单
cat >> longhorn-ui-svc.yaml << EOF
kind: Service
apiVersion: v1
metadata:
name: longhorn-ui-nodeport
namespace: longhorn-system
labels:
app: longhorn-ui
spec:
ports:
- name: http
protocol: TCP
port: 80
targetPort: http
nodePort: 32222
selector:
app: longhorn-ui
clusterIP:
type: NodePort
EOF
4.2、创建 SVC
kubectl apply -f longhorn-ui-svc.yaml
4.3、访问 Longhorn UI
打开浏览器访问,http://集群任意节点IP:32222
http://192.168.112.10:32222
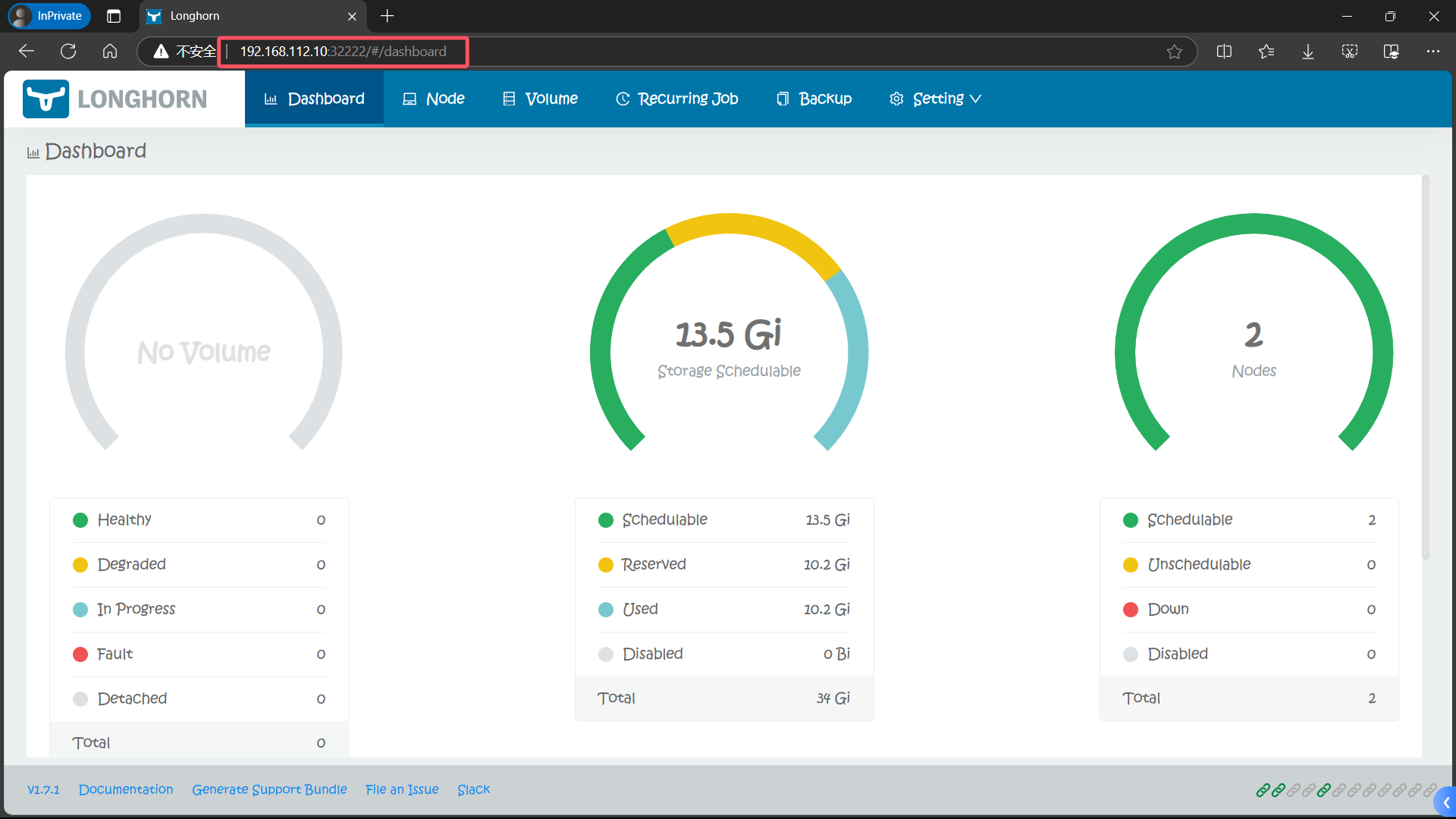
Longhorn UI 界面中展示了当前存储系统的状态。
关于存储的几种状态:
Schedulable: 可用于 Longhorn 卷调度的实际空间(actual space)Reserved: 为其他应用程序和系统保留的空间(space reserved)Used: Longhorn、系统和其他应用程序已使用的实际空间(space reserved)Disabled: 不允许调度 Longhorn 卷的磁盘/节点的总空间
在 Node 页面,Longhorn 会显示每个节点的空间分配、调度和使用信息:
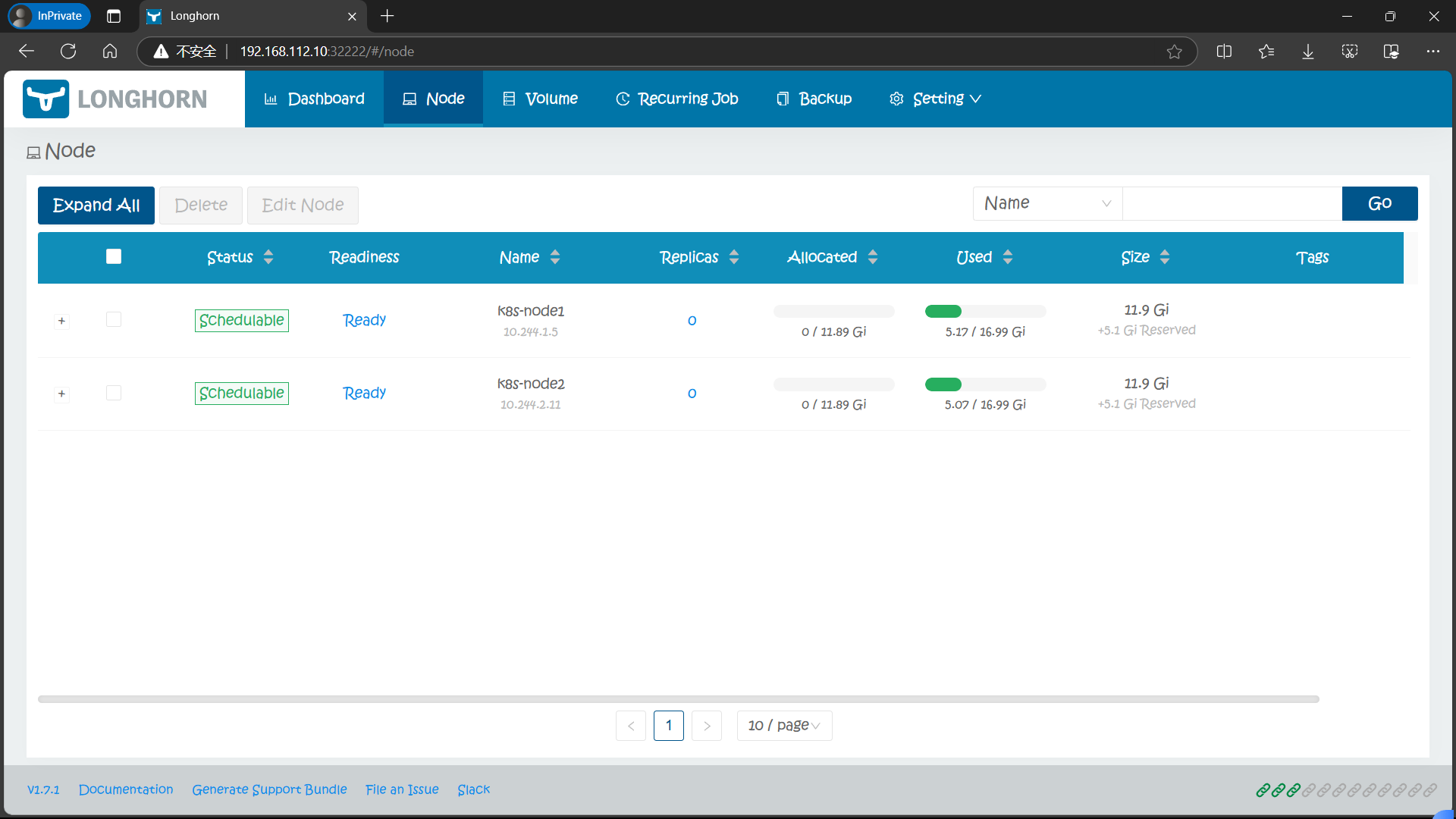
- Size 列:Longhorn 卷可以使用的最大实际可用空间,它等于节点的总磁盘空间减去保留空间。
- Allocated 列:左边的数字是**卷调度(volume scheduling)**已使用的大小,并不代表该空间已被用于 Longhorn 卷数据存储。右边的数字是卷调度的 max 大小,它是 Size 乘以 Storage Over Provisioning Percentage 的结果,因此,这两个数字之间的差异(我们称之为可分配空间 allocable space)决定了卷副本是否可以调度到这个节点。
- Used 列:左边部分表示该节点当前使用的空间,整个条形表示节点的总空间。
5、查看默认创建的存储类 StorageClass
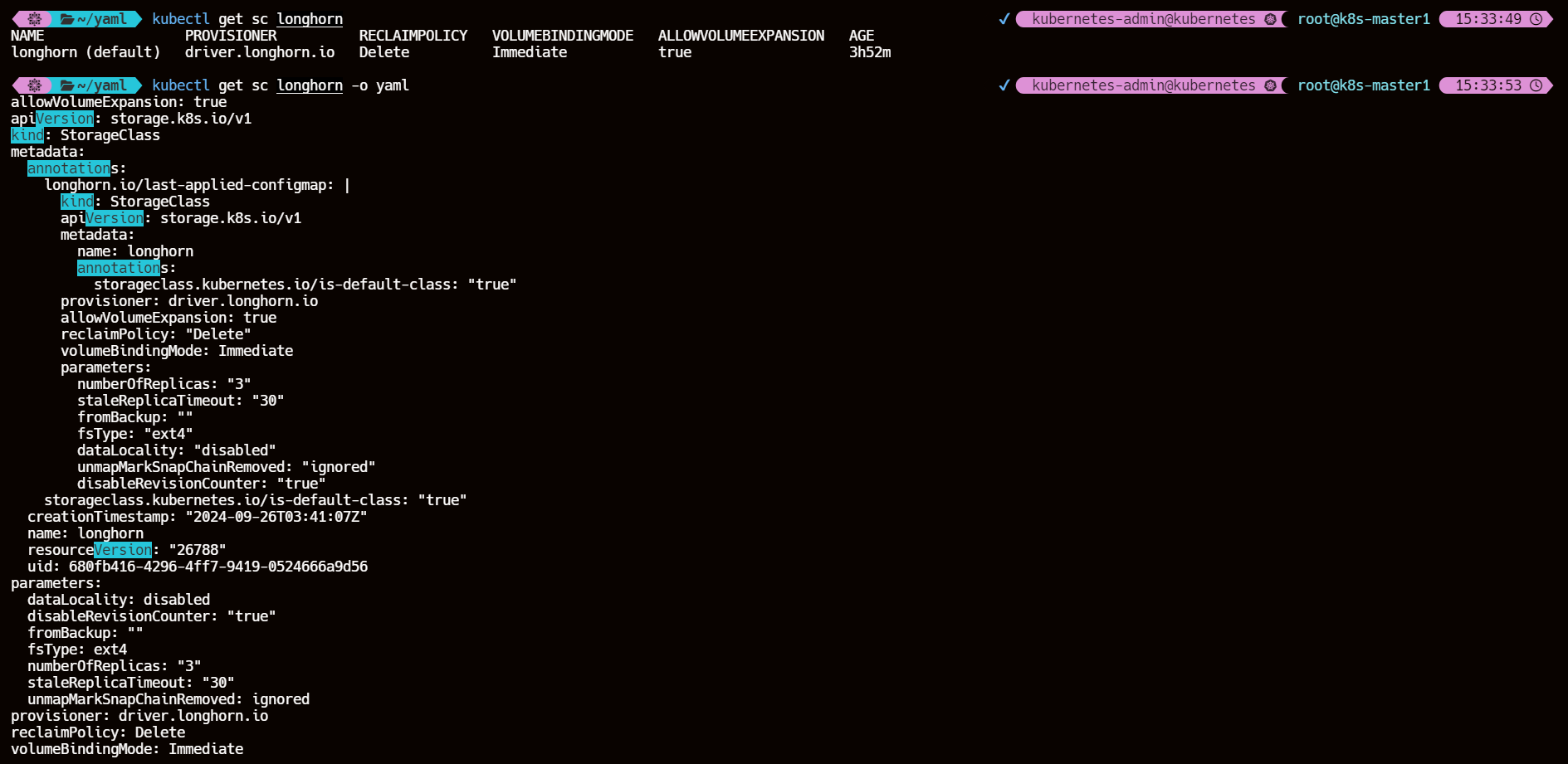
kubectl get sc longhorn
kubectl get sc longhorn -o yaml
五、使用 Longhorn 为 MySQL 应用提供数据持久化
1、创建 PVC 测试使用 longhorn 动态创建 PV
cat >> mysql-pvc.yaml << EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pvc
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Mi
EOF
2、部署一个 MySQL 应用来使用上面的 PVC 进行数据持久化
cat >> mysql-deploy.yaml << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: password
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
volumes:
- name: data
persistentVolumeClaim:
claimName: mysql-pvc
EOF
3、创建上面的 PVC、Deployment
kubectl apply -f mysql-pvc.yaml -f mysql-deploy.yaml
kubectl get pods -l app=mysql
kubectl get pvc -o wide
kubectl get pv -owide

4、进入容器内部创建数据
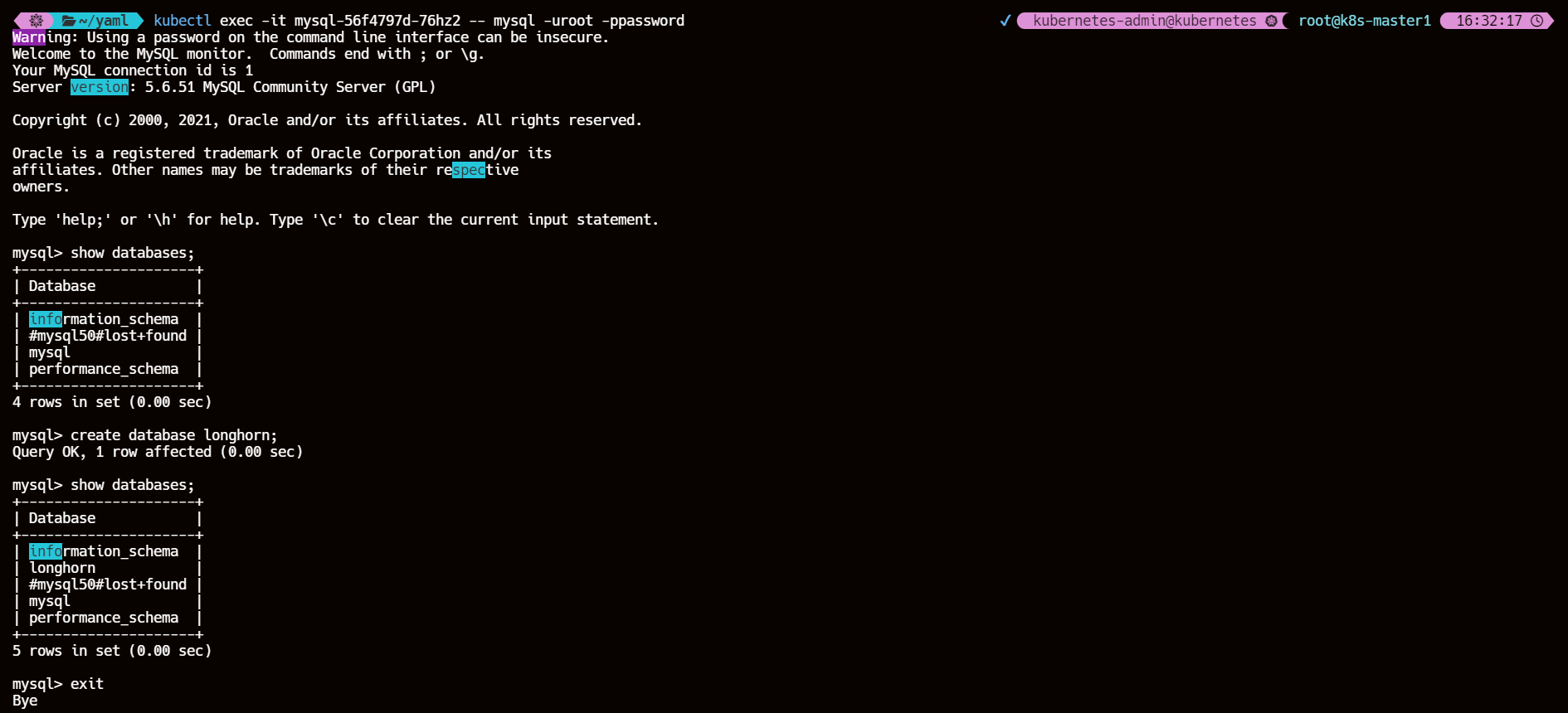
kubectl exec -it mysql-56f4797d-76hz2 -- mysql -uroot -ppassword
show databases;
create database longhorn;
show databases;
5、登录到 Pod 所在节点验证数据是否存在
我的测试 pod 调度到 k8s-node1
ls /var/lib/longhorn/
ls /var/lib/longhorn/replicas/
ls pvc-4b35bd04-a6ff-45d4-8701-7f6ab934a896-dd42df6b

- volume-head-000.img:
- 这个文件是当前活动的数据文件,包含了最新的数据快照。在 Longhorn 中,卷的数据是以快照形式存在的,每次数据更新都会创建一个新的快照。
volume-head-000.img指的是最新一次的快照数据文件,通常这个文件名会随着快照版本号的增加而改变,但是在某些情况下,它可能是固定的名称,代表当前正在读写的数据。
- 这个文件是当前活动的数据文件,包含了最新的数据快照。在 Longhorn 中,卷的数据是以快照形式存在的,每次数据更新都会创建一个新的快照。
- volume-head-000.img.meta:
- 这是快照的元数据文件,它包含了与
volume-head-000.img相关的信息,比如文件的大小、快照的时间戳等。
- 这是快照的元数据文件,它包含了与
- volume.meta:
- 这是一个包含了整个卷的元数据信息的文件,包括卷的大小、快照列表等。
volume.meta文件记录了卷的所有状态信息。
- 这是一个包含了整个卷的元数据信息的文件,包括卷的大小、快照列表等。
6、重建 Pod 查看数据是否依然存在
kubectl get pods -l app=mysql -owide
kubectl delete po mysql-56f4797d-76hz2
kubectl exec -it mysql-56f4797d-fxxcp -- mysql -uroot -ppassword
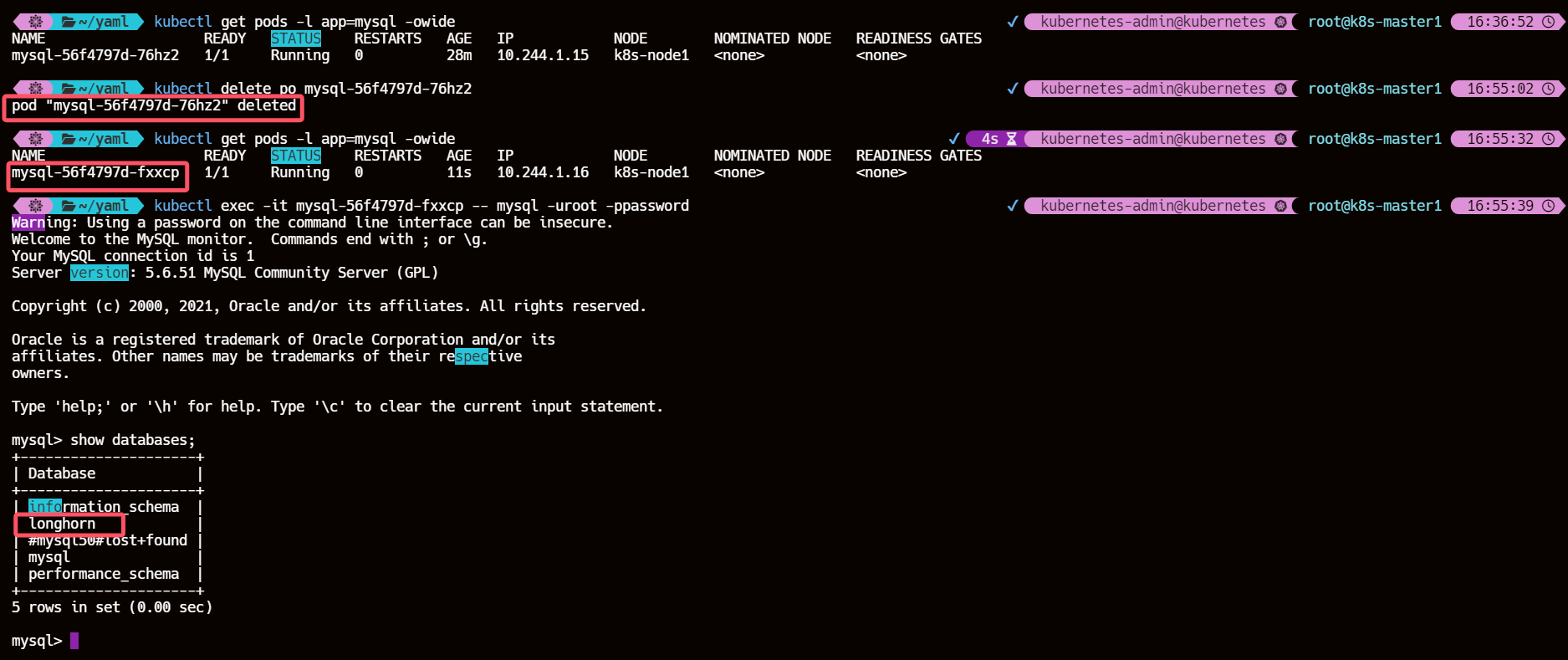
可以看到上一个被销毁的 Pod 创建的数据库依然存在,说明数据持久化成功
7、【ERROR】Scheduling Failure Replica Scheduling Failure Error Message: replica scheduling failed
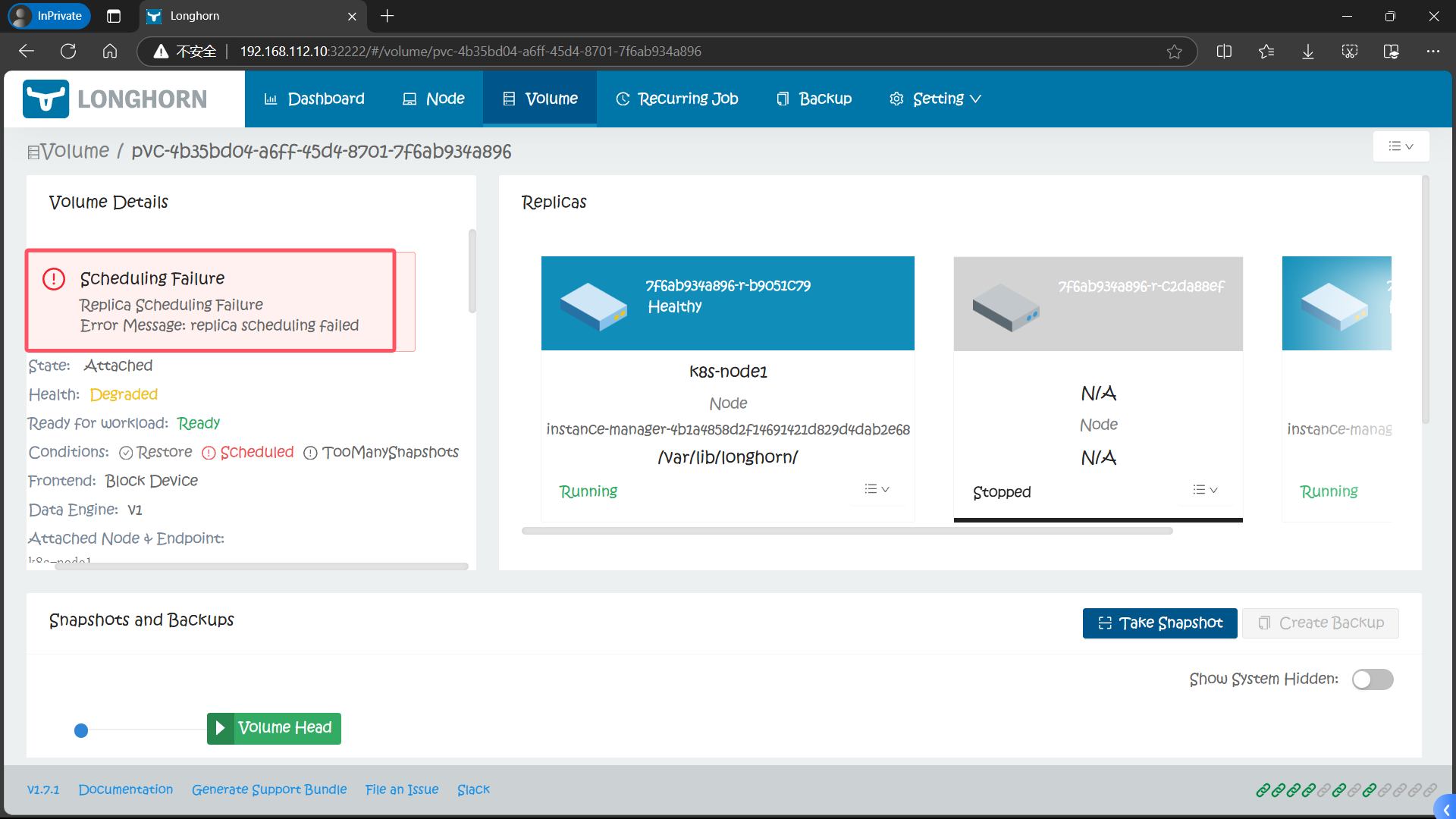
7.1、原因
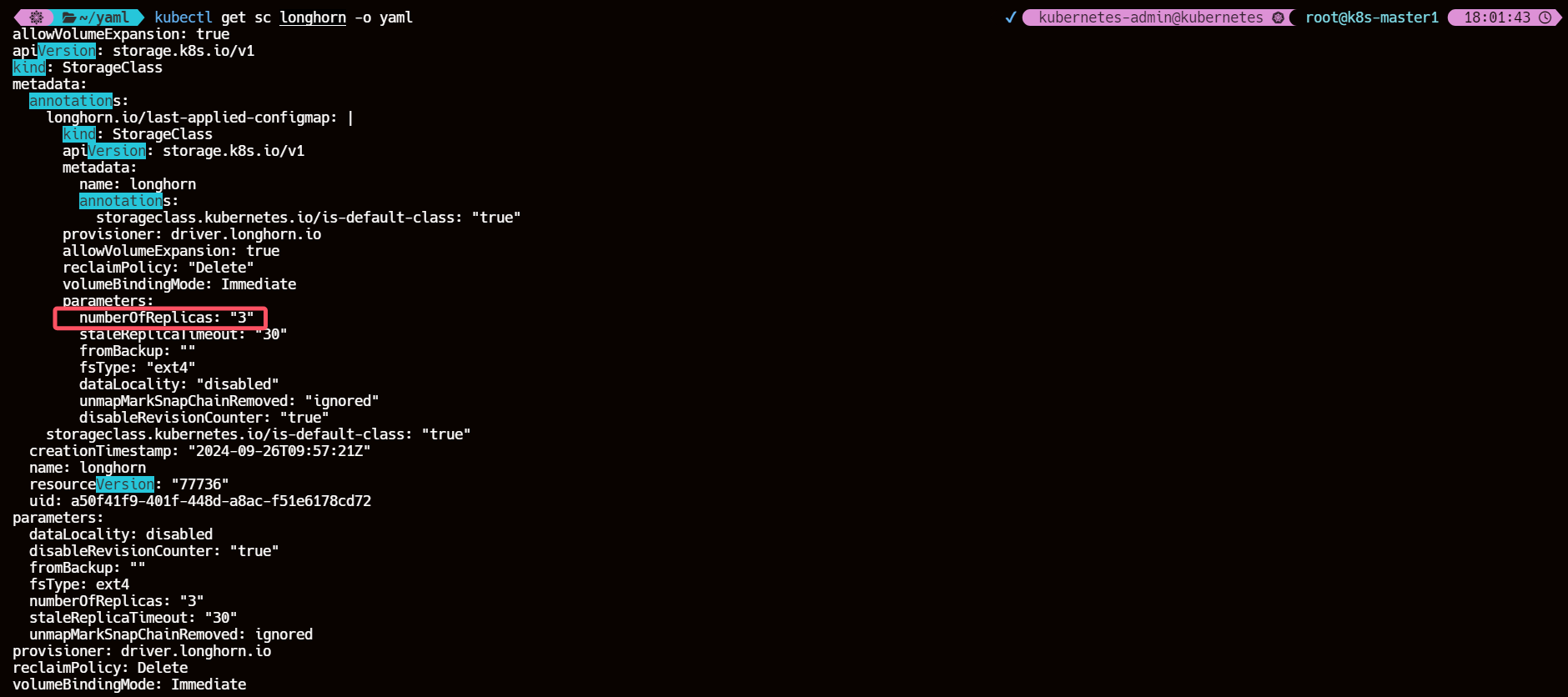
默认 Longhorn 的 StorageClass 的副本数 replica 设置为 3
这意味着 Longhorn 将始终尝试在三个不同的节点上为三个副本分配足够的空间,如果不满足此要求比如集群的节点数少于3个,则卷调度会失败
kubectl get sc longhorn -o yaml
kubectl get nodes

# 应该是这样的关系
numberOfReplicas <= nodes
7.2、解决方案
- 设置Node Level Soft Anti-affinity为true。
- 或者,创建一个新的 StorageClass,并将副本数设置为1或2。
- 或者,向集群添加更多节点。
kubectl -n longhorn-system edit cm longhorn-storageclass
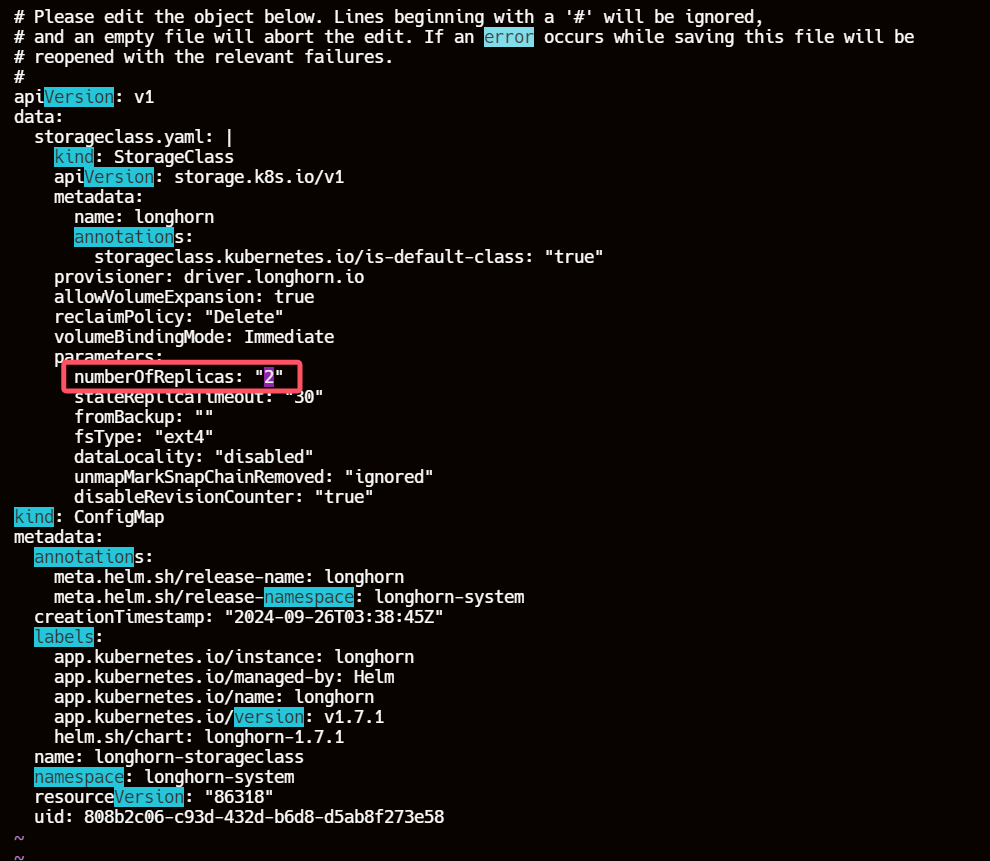
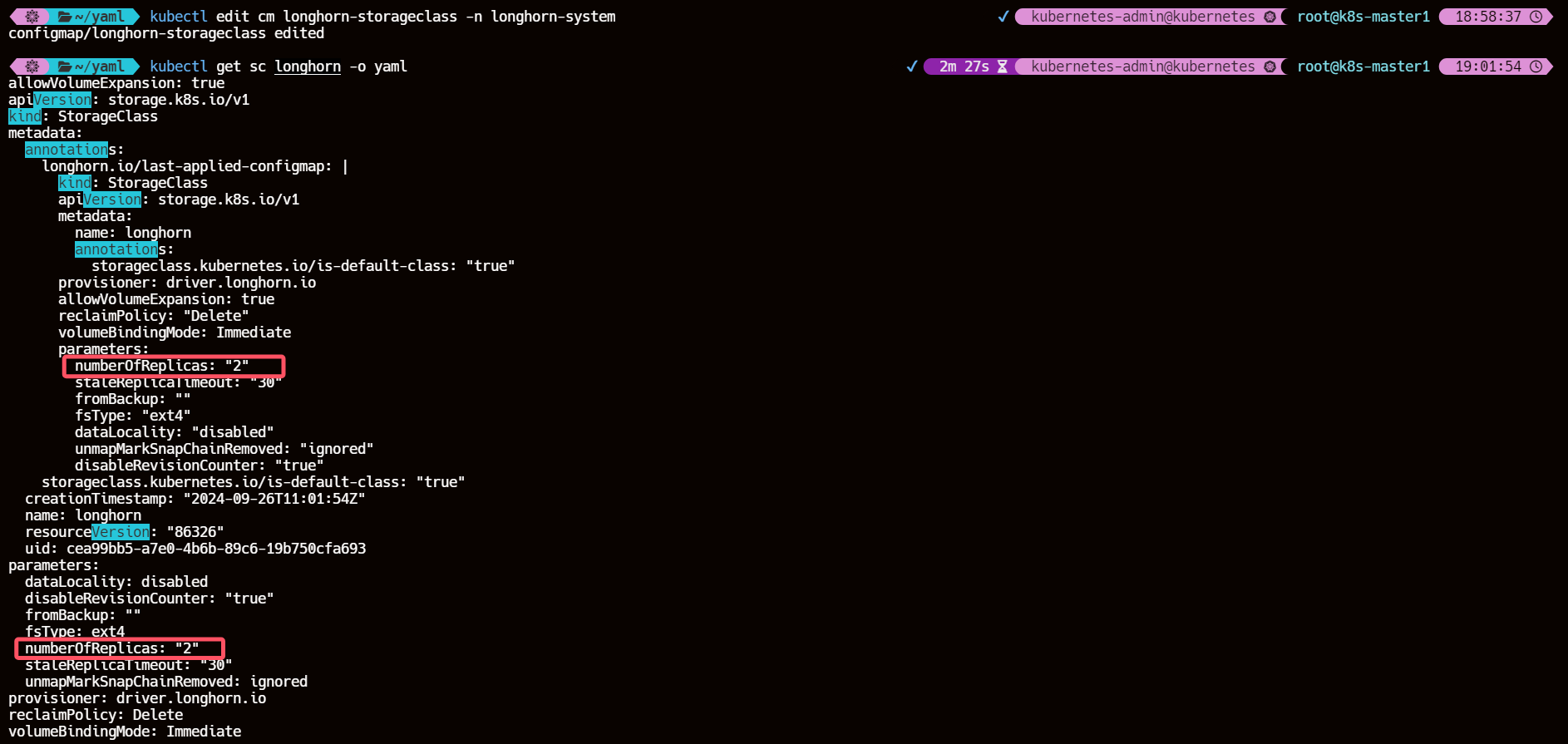
7.3、再次动态创建 PV 持久卷
没有问题
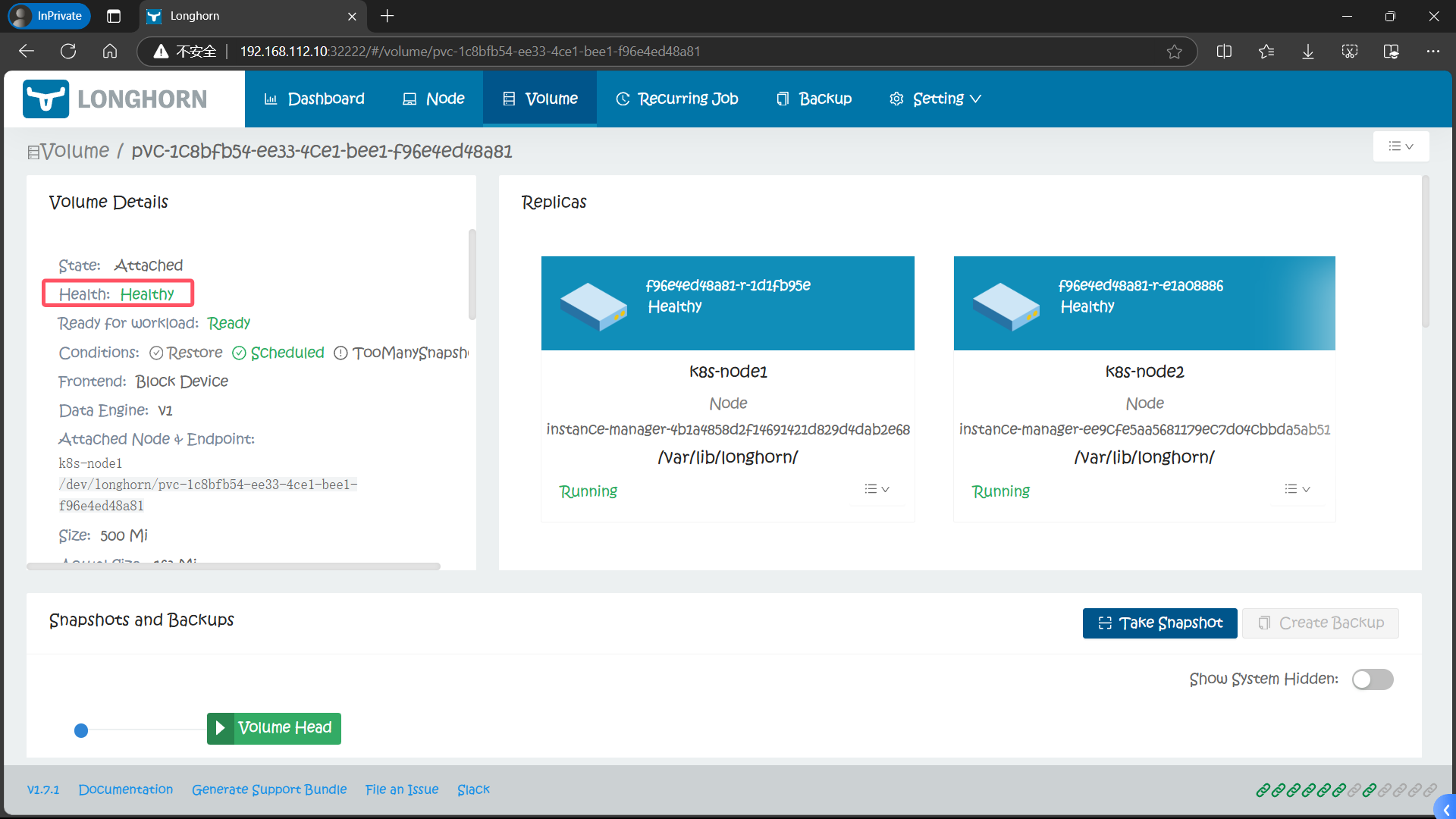
六、使用 Longhorn 备份恢复
Longhorn 提供了备份恢复功能,要使用这个功能我们需要给卷创建一个 snapshot 快照,快照是 Kubernetes Volume 在任何指定时间点的状态。
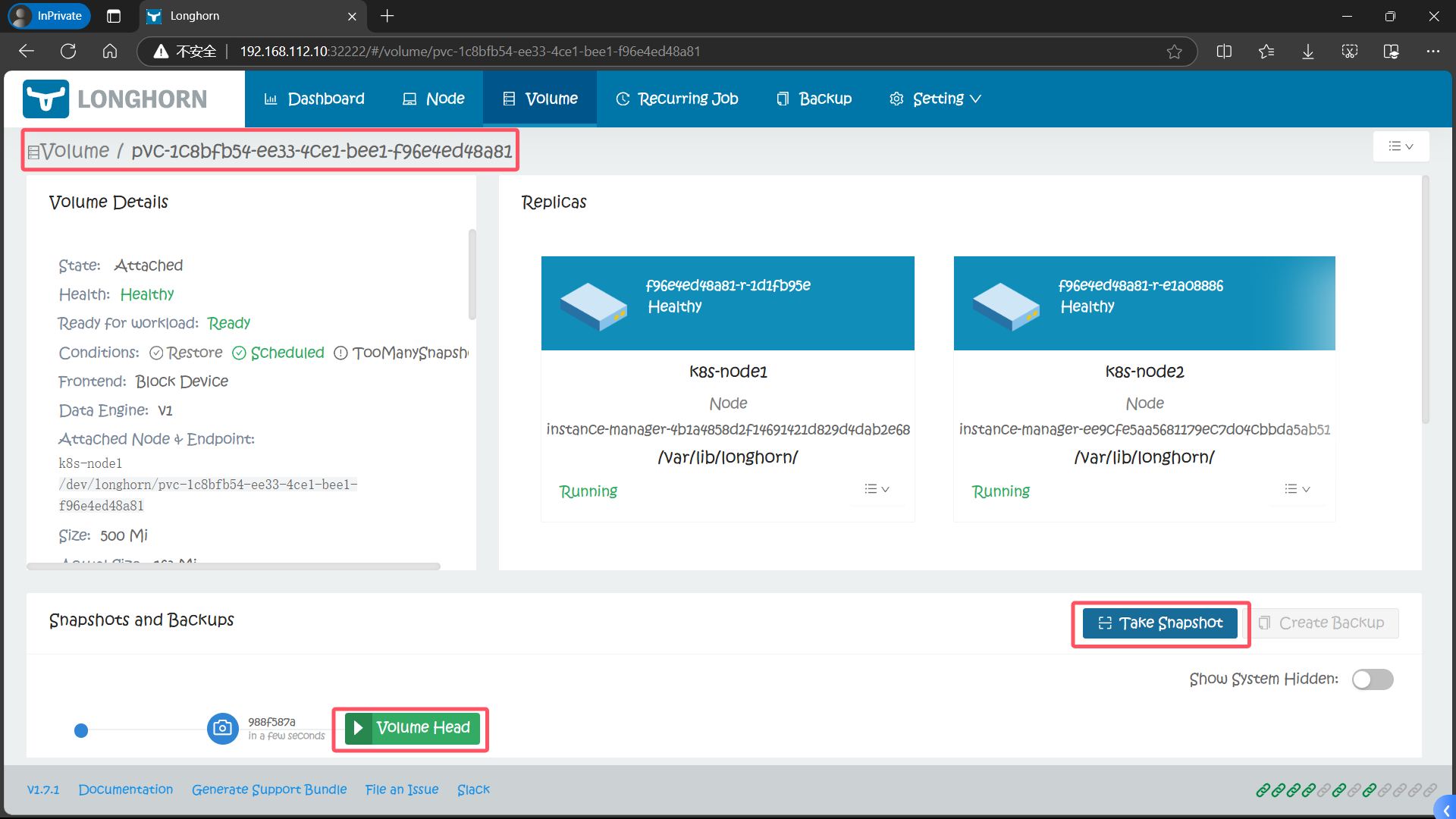
在 Longhorn UI 的 Volume 页面中点击要创建快照的卷,进入卷的详细信息页面,点击下方的 Take Snapshot 按钮即可创建快照了,创建快照后,将在卷头(Volume Head)之前的快照列表中可以看到它。
1、对测试的 MySQL 卷创建快照
2、查看 Pod 的调度节点数据目录
同样在节点的数据目录下面也可以看到创建的快照数据:
k8s-node1


其中的 volume-snap-xxx 后面的数据和页面上的快照名称是一致的,比如页面中我们刚刚创建的快照名称为 988f587a-c765-441b-9c7b-c5bae5a113a4,其中的 .img 文件是镜像文件,而 .img.meta 是保存当前快照的元信息:
cat volume-snap-988f587a-c765-441b-9c7b-c5bae5a113a4.img.meta
{"Name":"volume-head-000.img","Parent":"","Removed":false,"UserCreated":true,"Created":"2024-09-26T12:10:35Z","Labels":null}

3、创建周期任务 Create Recurring Job
除了手动创建快照之外,从 Longhorn UI 上还可以进行周期性快照和备份,同样在卷的详细页面可以进行配置,在 Recurring Jobs Schedule 区域点击 Add 按钮即可创建一个定时的快照。
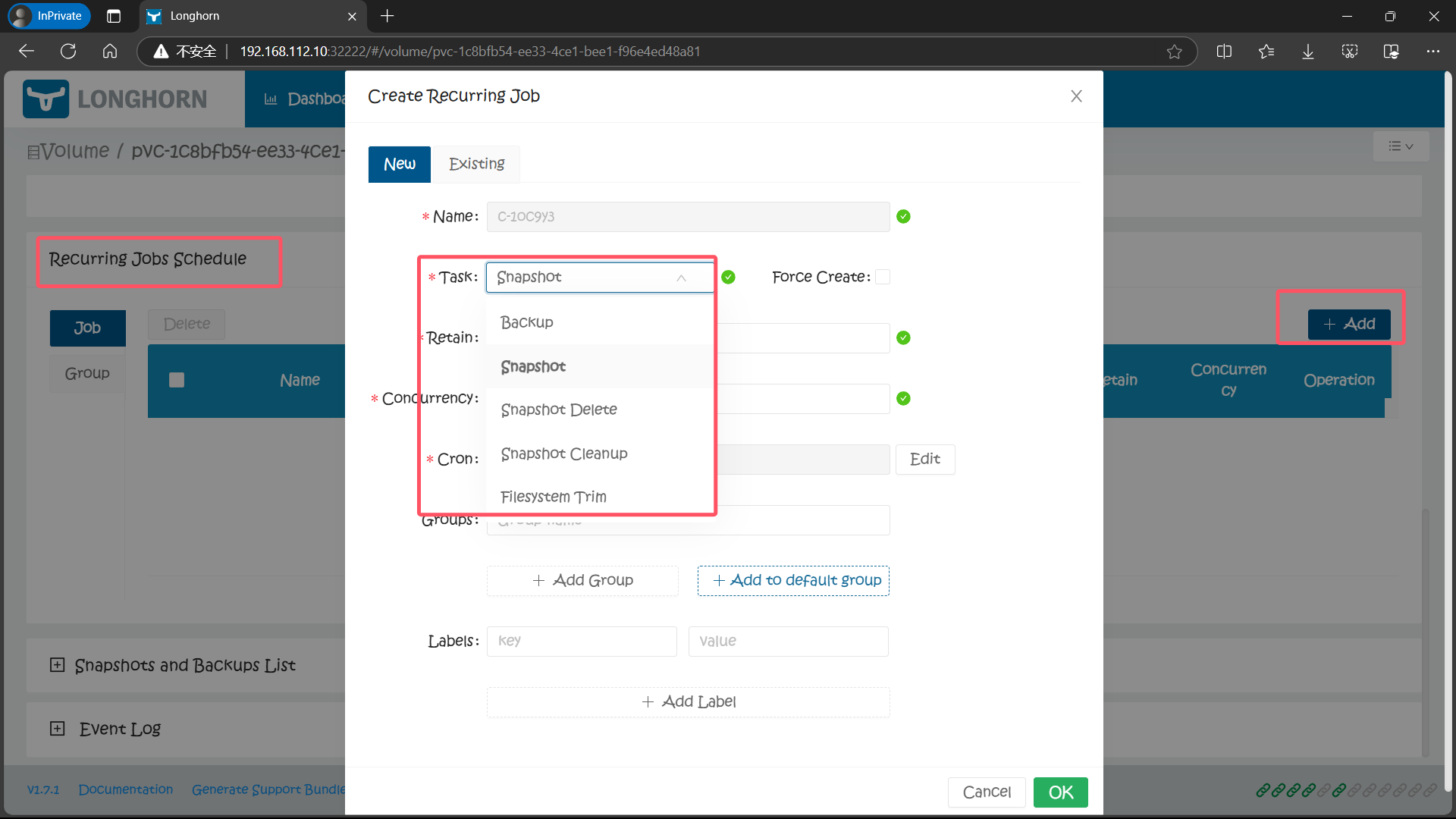
创建任务的时候可以选择任务类型是备份(backup)或快照(snapshot),任务的时间以 CRON 表达式的形式进行配置,还可以配置要保留的备份或快照数量以及标签。
为了避免当卷长时间没有新数据时,recurring jobs 可能会用相同的备份和空快照覆盖旧的备份/快照的问题,Longhorn 执行以下操作:
Recurring backup job仅在自上次备份以来卷有新数据时才进行新备份Recurring snapshot job仅在卷头(volume head)中有新数据时才拍摄新快照
4、使用 Longhorn 的 StorageClass 创建快照
我们还可以通过使用 Kubernetes 的 StorageClass 来配置定时快照,可以通过 StorageClass 的 recurringJobs 参数配置定时备份和快照,recurringJobs 字段应遵循以下 JSON 格式:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: longhorn
provisioner: driver.longhorn.io
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "30"
fromBackup: ""
recurringJobs: '[
{
"name":"snap",
"task":"snapshot",
"cron":"*/1 * * * *",
"retain":1
},
{
"name":"backup",
"task":"backup",
"cron":"*/2 * * * *",
"retain":1
}
]'
- name:任务的名称,不要在一个
recurringJobs中使用重复的名称,并且 name 的长度不能超过 8 个字符 - task:任务的类型,它仅支持 snapshot 或 backup
- cron:Cron 表达式,指定任务的执行时间
- retain:Longhorn 将为一项任务保留多少快照/备份,不少于 1(最大不可变量为250)
使用这个 StorageClass 创建的任何卷都将自动配置上这些
recurring jobs。
5、创建 RecurringJob 以创建重复快照和备份(重复作业)
apiVersion: longhorn.io/v1beta1
kind: RecurringJob
metadata:
name: snapshot-1
namespace: longhorn-system
spec:
cron: "* * * * *"
task: "snapshot"
groups:
- default
- group1
retain: 1
concurrency: 2
labels:
label/1: a
label/2: b
5.1、配置参数
-
name: 循环任务的名称,请勿使用重复的名称,且长度name不超过40个字符。
-
task: 工作类型。Longhorn 支持以下内容:
-
backup: 定期创建快照,然后在清理过期快照后进行备份
-
backup-force-create: 定期创建快照并进行备份
-
snapshot: 定期清理过期快照后创建快照
-
snapshot-force-create: 定期创建快照
-
snapshot-cleanup: 定期清除可移动快照和系统快照
- 注意:保留值对此任务没有影响,Longhorn 会自动将该retain值更改为 0。
-
filesystem-trim: 定期修剪文件系统以回收磁盘空间
-
snapshot-delete: 定期删除并清除所有超出保留计数的快照。
-
注意:该retain值与每个重复作业无关。
以具有 2 个重复作业的卷为例:
- snapshot保留值设置为 5
- snapshot-delete:保留值设置为 2
- 最终一次任务执行完成后会保留2个快照snapshot-delete。
- cron: Cron表达式。它告诉作业的执行时间。
- retain: Longhorn 将为每个卷作业保留多少个快照/备份。它不应少于 1。
- concurrency: 同时运行的作业数,不小于1。
可以指定可选参数:
- groups: 作业应属于的任何组。归入default组将自动将此重复作业安排到没有重复作业的任何卷。
- labels: 应应用于备份或快照的任何标签。
6、备份卷
要想使用 Longhorn 的备份卷功能就需要配置应该备份目标,可以是一个 NFS 服务或是 S3 兼容的对象存储服务,用于存储 Longhorn 卷的备份数据。
备份目标可以在 Settings/General/BackupTarget 中配置,最好的方式是定制 values 文件中的 defaultSettings.backupTarget(也是网上大部分教程使用的方式),也可以在 Longhorn UI 中配置
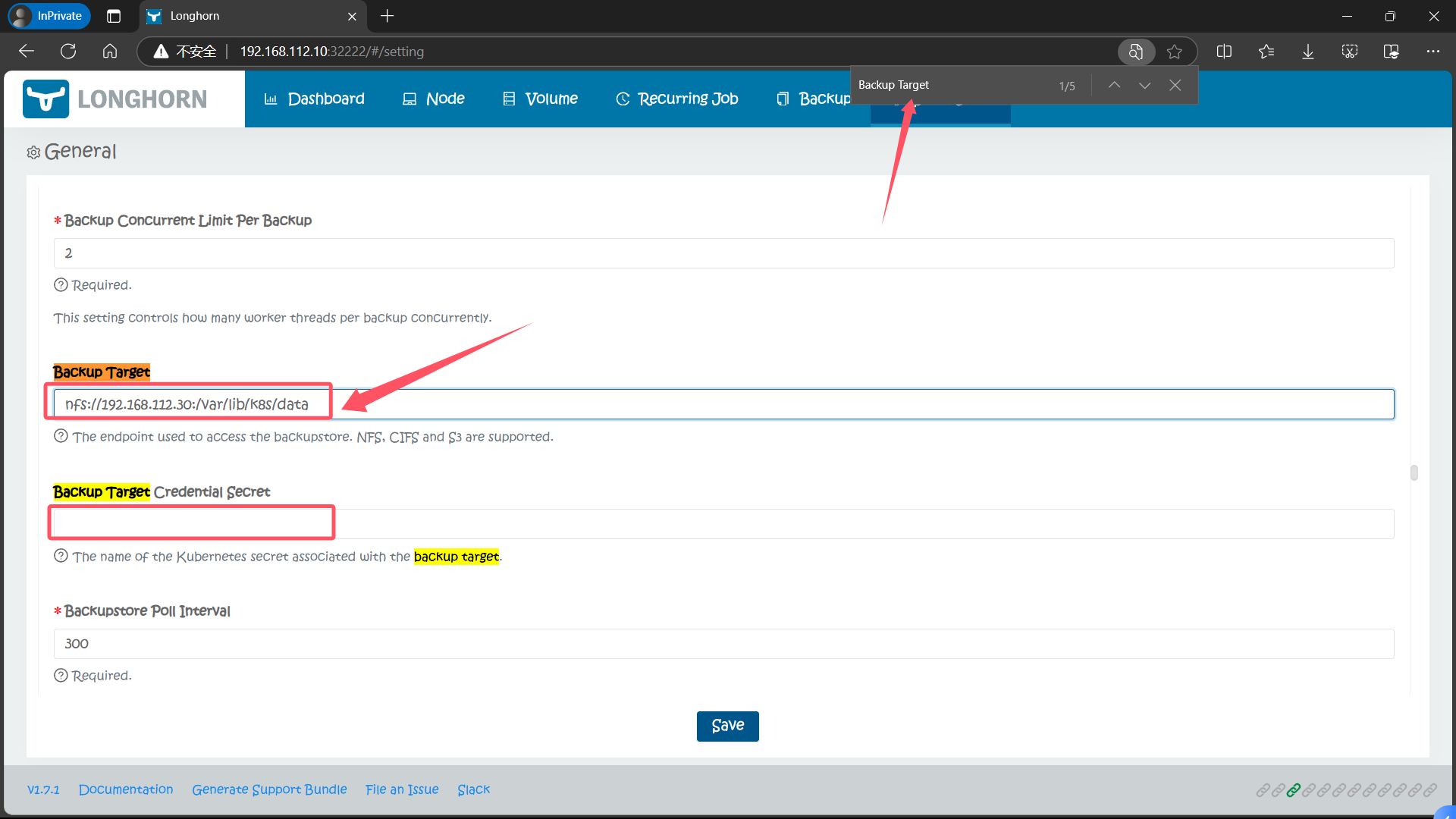
6.1、配置备份目标为 NFS 服务以备份卷
比如这里我们先配置备份目标为 nfs 服务,Backup Target 值设置为 nfs://192.168.112.30:/var/lib/k8s/data(要确保目录存在),Backup Target Credential Secret 留空即可,然后拉到最下面点击 Save:
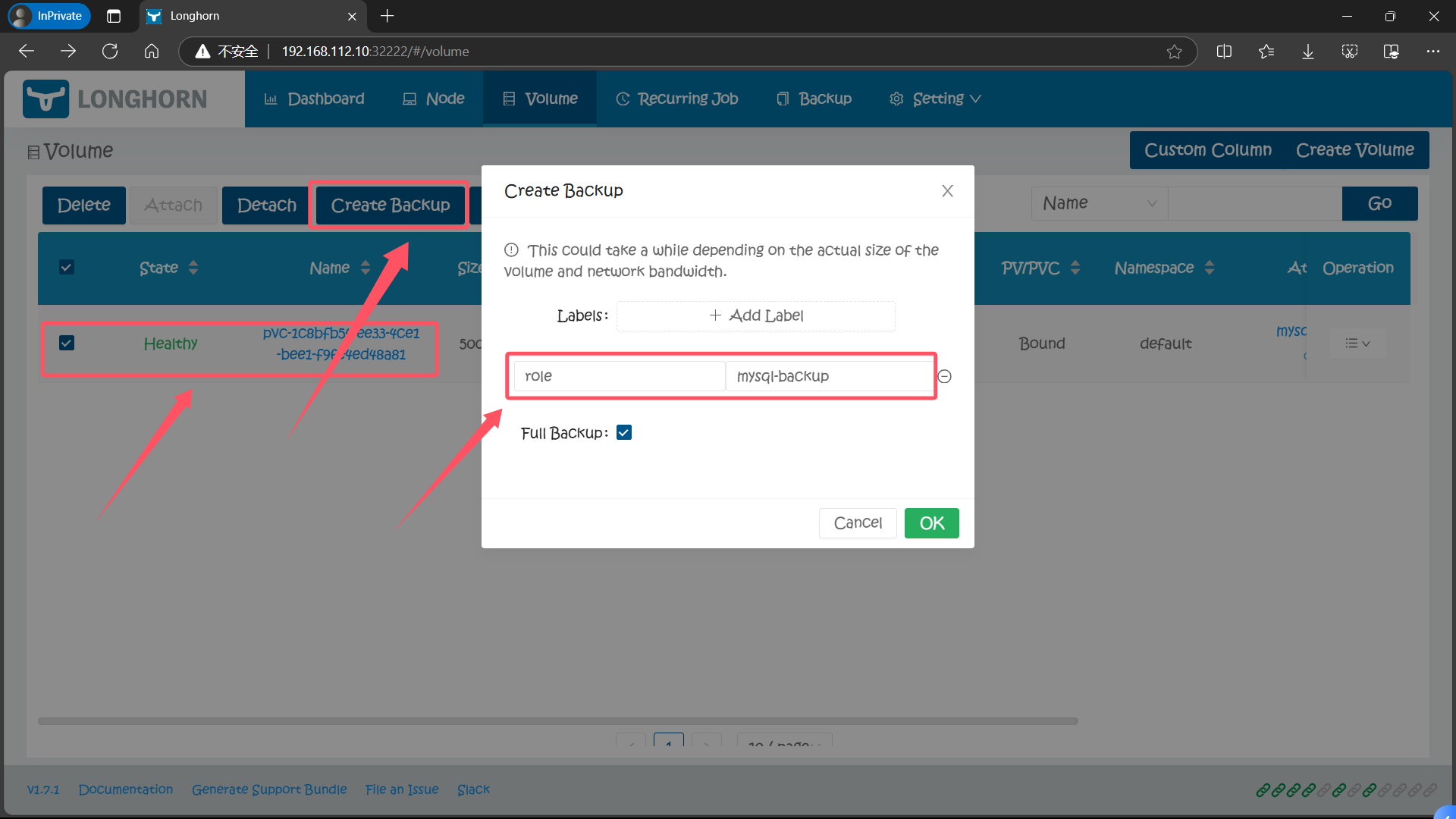
备份目标配置后,就可以开始备份了,同样导航到 Longhorn UI 的 Volume 页面,选择要备份的卷,点击 Create Backup,然后添加合适的标签点击 OK 即可。
6.2、【ERROR】为什么设置了备份目标 BackupTarget 选择卷 Create Backup选项是不可选的呢?
6.2.1、原因
NFS 配置问题,我们前面只安装了 NFS 服务并启动并开机自启但是并未配置服务,因此 Longhorn 将卷无法挂载到指定的 NFS 服务器的共享目录
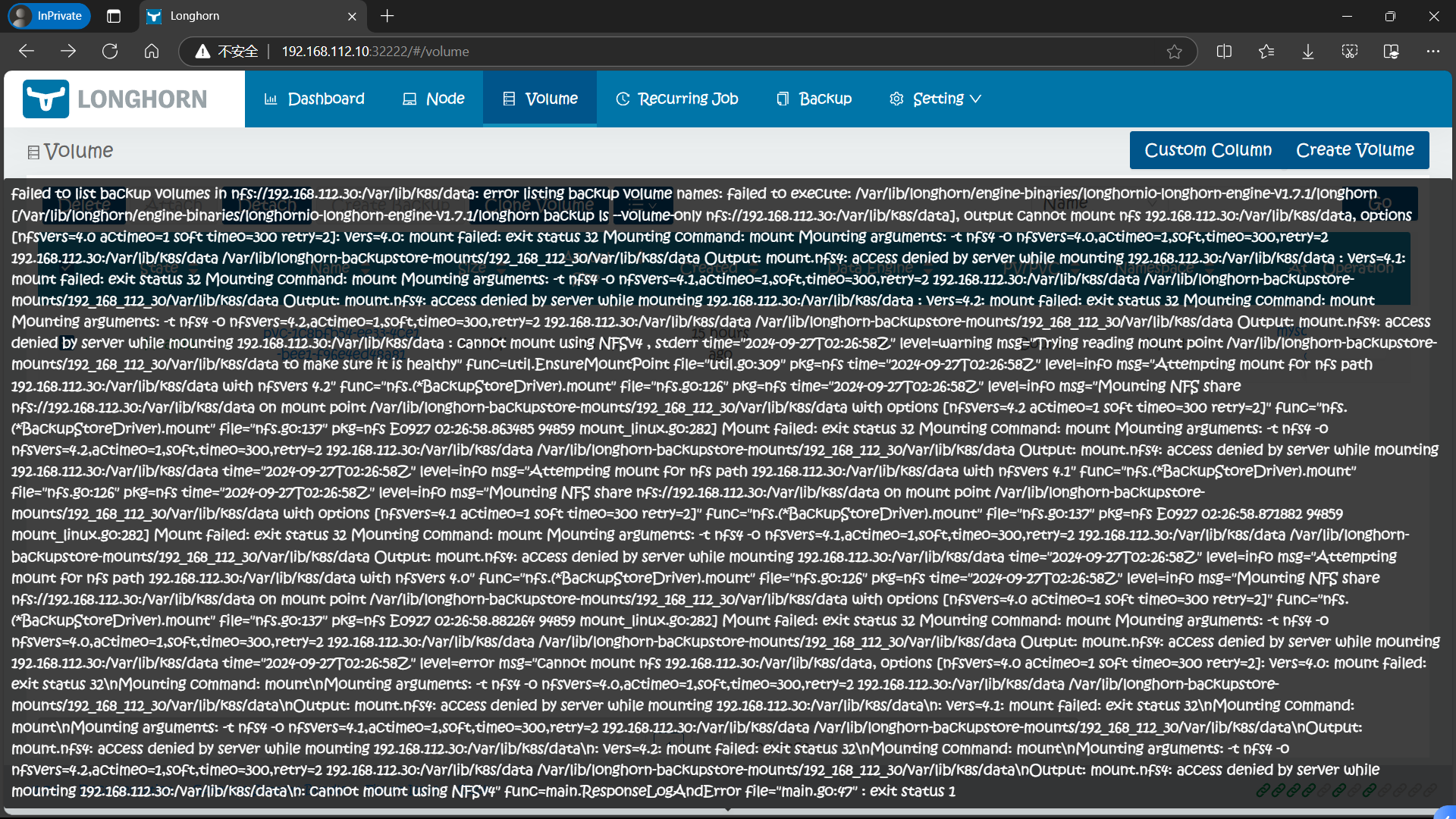
6.2.2、解决方案
配置 NFS 服务器
mkdir -pv /var/lib/k8s/data
echo "/var/lib/k8s/data 192.168.112.0/24(rw,sync,no_root_squash)" > /etc/exports
exportfs -arv
systemctl restart nfs
showmount -e localhost

6.2.3、验证
kubectl get backuptargets -n longhorn-system

6.3、查看对应备份数据
备份完成后导航到 Backup 页面就可以看到对应的备份数据了
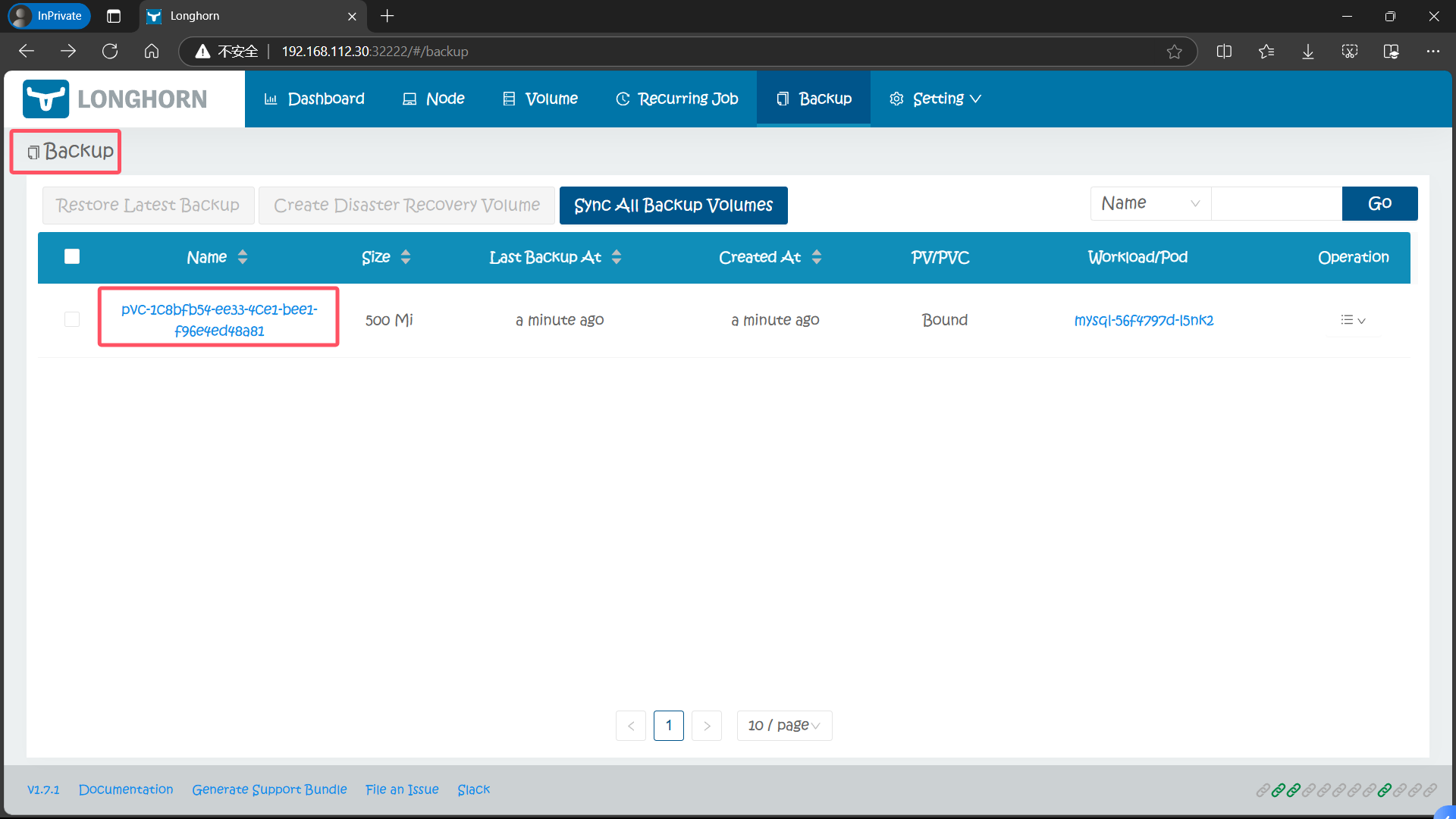
6.4、backupvolumes 对象
kubectl get backupvolumes -n longhorn-system

6.5、查看 NFS 服务器上备份的数据
然后我们去到 NFS 服务器上查看会在挂载目录下面创建一个 backupstore 目录,下面会保留我们备份的数据:
tree -L 6 /var/lib/k8s/data/backupstore

6.6、选择需要备份的快照
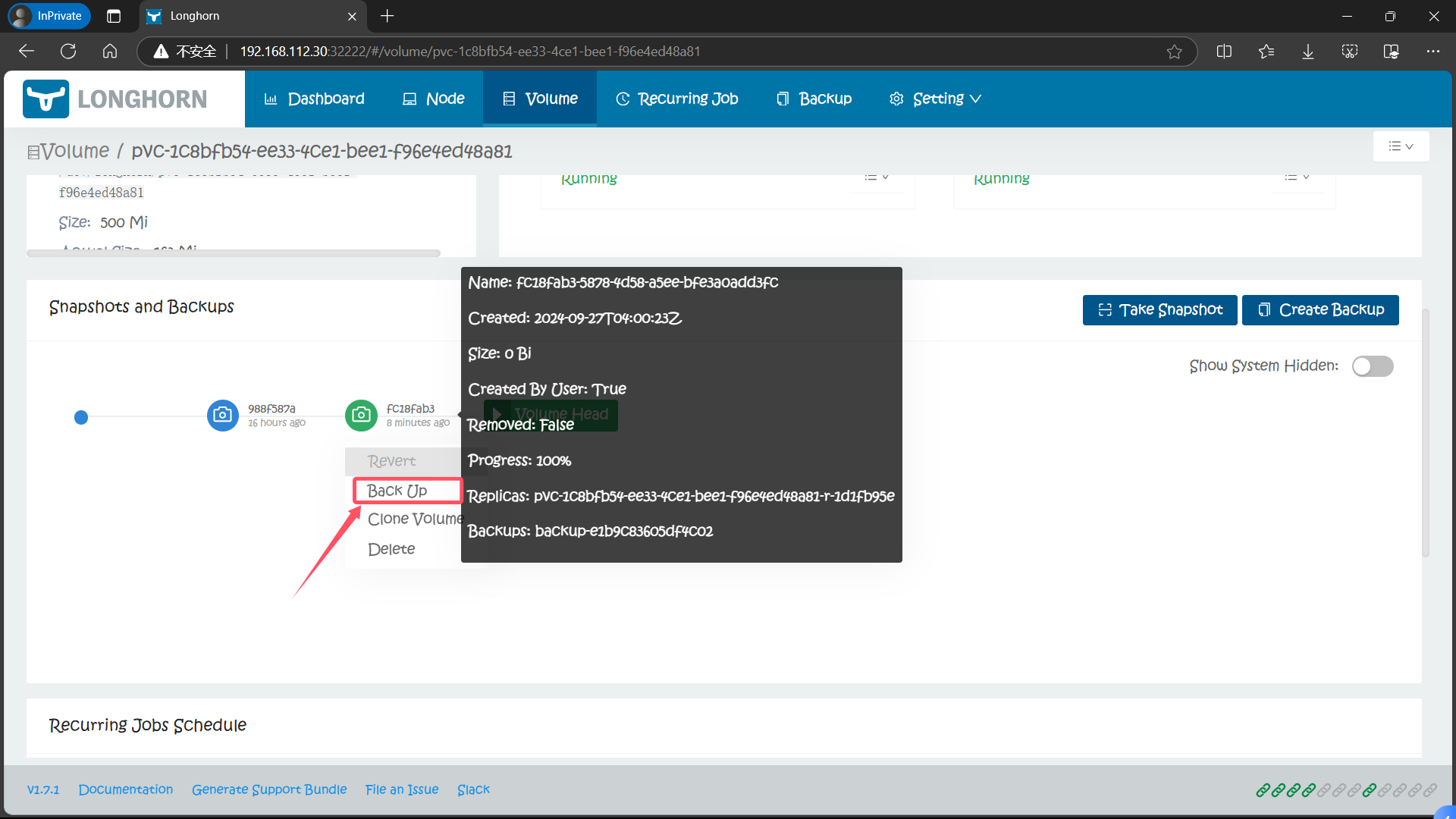
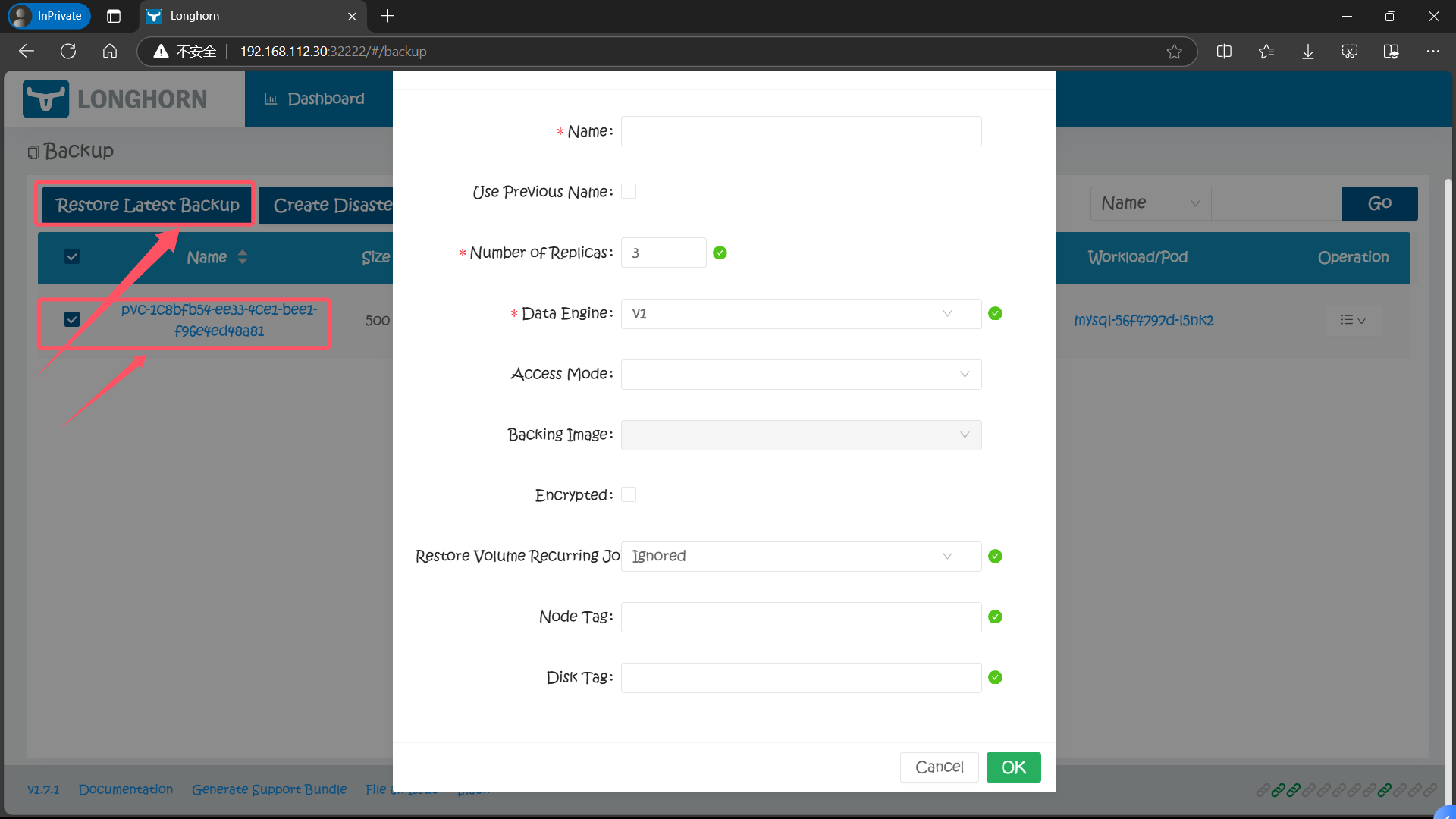
6.7、基于备份数据恢复数据
有了备份数据后要想要恢复数据,只需要选择对应的备份数据,点击 Restore Latest Backup 恢复数据即可:
七、ReadWriteMany 卷的使用
Longhorn 可以通过 NFSv4 服务器暴露 Longhorn 卷,原生支持 RWX 工作负载。
Longhorn 在命名空间 longhorn-system 内为当前正在使用的每个 RWX 卷创建一个专用的share-manager- Pod。该 Pod 有助于通过内部托管的 NFSv4 服务器导出 Longhorn 卷。此外,还为每个 RWX 卷创建相应的服务,作为实际 NFSv4 客户端连接的指定端点。
1、创建访问模式为 RWX 的 PVC
cat >> html-vol.yaml << EOF
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: html
spec:
accessModes:
- ReadWriteMany
storageClassName: longhorn
resources:
requests:
storage: 1Gi
EOF
kubectl apply -f html-vol.yaml
会发现刚创建的 PVC 就会有 PV 动态生成并绑定了

2、创建 Deployment 使用上面创建的 PVC 做持久化数据
cat >> html-writer.yaml << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: writer
spec:
selector:
matchLabels:
app: writer
template:
metadata:
labels:
app: writer
spec:
containers:
- name: content
image: alpine:latest
volumeMounts:
- name: html
mountPath: /html
command: ["/bin/sh", "-c"]
args:
- while true; do
date >> /html/index.html;
sleep 5;
done
volumes:
- name: html
persistentVolumeClaim:
claimName: html
EOF
kubectl apply -f html-writer.yaml
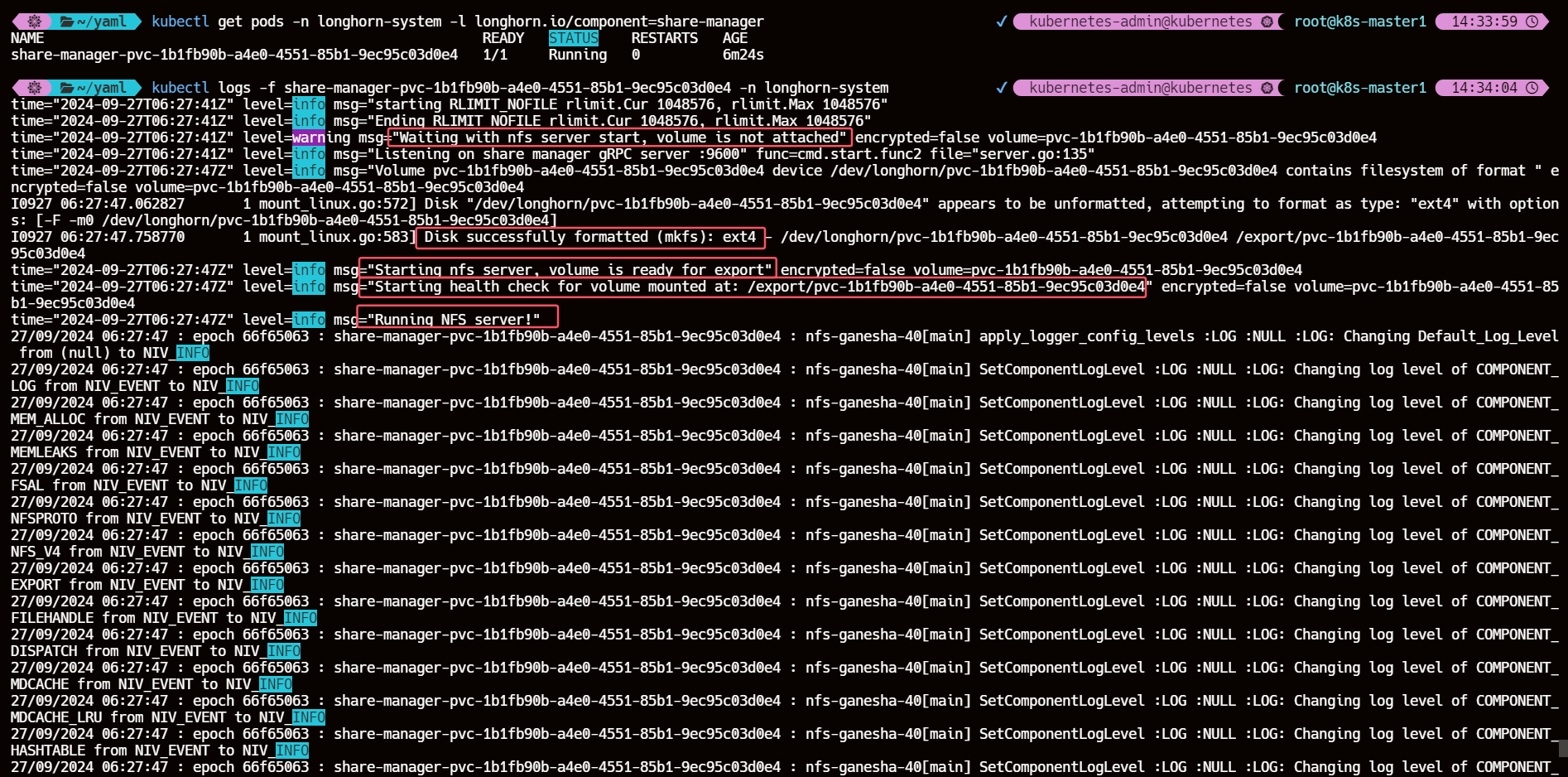
3、查看 share-manager 的 Pod 日志信息
kubectl get pods -n longhorn-system -l longhorn.io/component=share-manager
kubectl logs -f share-manager-pvc-1b1fb90b-a4e0-4551-85b1-9ec95c03d0e4 -n longhorn-system
4、创建一个用来读取数据的 Pod
cat >> html-reader.yaml << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: reader
spec:
replicas: 3
selector:
matchLabels:
app: reader
template:
metadata:
labels:
app: reader
spec:
containers:
- name: nginx
image: nginx:1.16.0
ports:
- containerPort: 80
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
volumes:
- name: html
persistentVolumeClaim:
claimName: html
EOF
5、创建 NodePort 类型的 SVC 访问应用
cat >> reader.yaml <<EOF
apiVersion: v1
kind: Service
metadata:
name: reader
spec:
selector:
app: reader
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 80
EOF
6、通过 NodePort 访问应用
# 创建 reader Deployment 以及 SVC
kubectl apply -f html-reader.yaml -f reader.yaml
# 查看 reader Pod 状态
kubectl get pods -l app=reader
# 查看 NodePort 类型的 SVC 以获取端口号
kubectl get svc reader
# 访问服务 集群节点任意ip+SVC端口号
curl -v http://192.168.112.10:31137
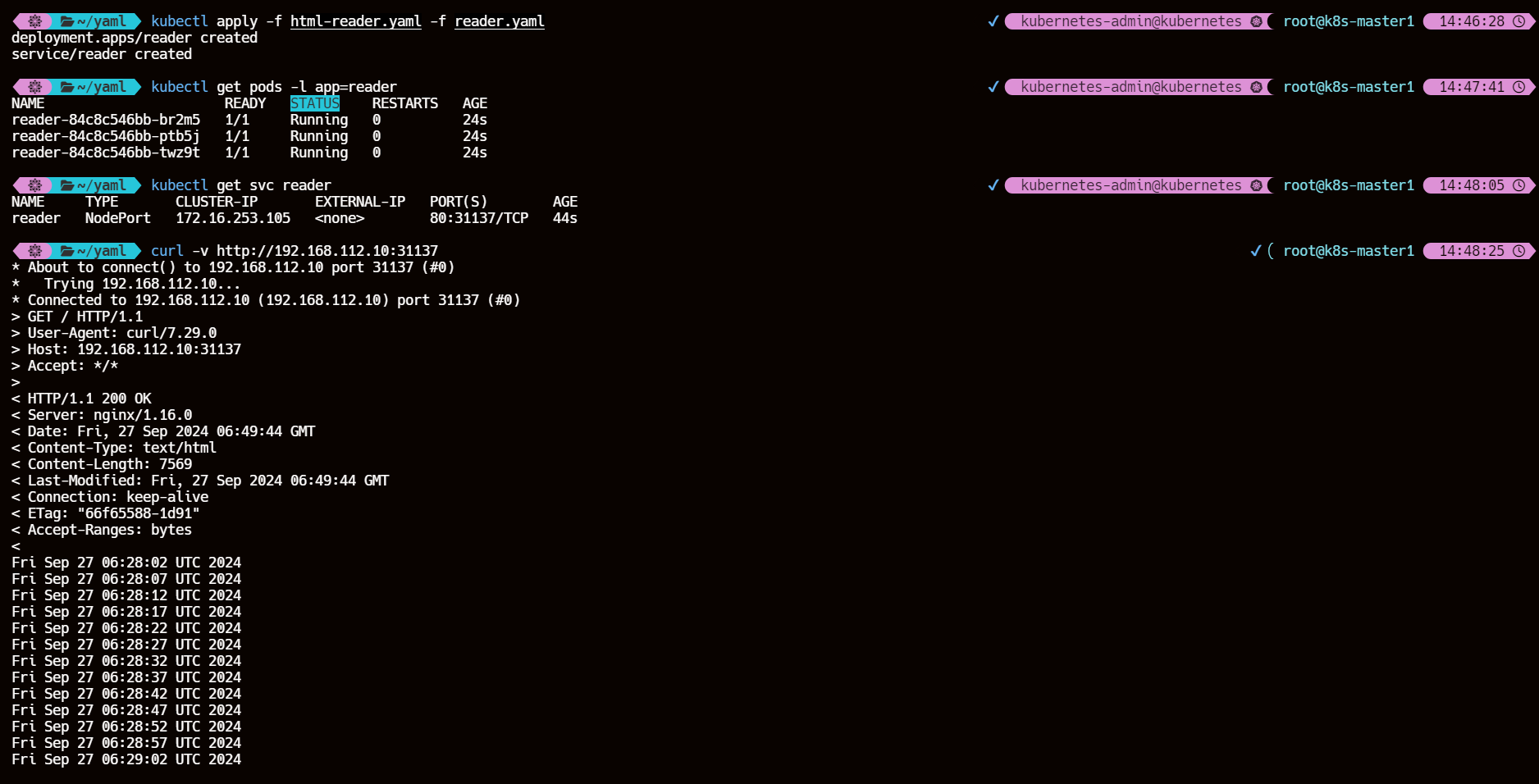
时间同步没做好将就看吧
7、从 reader Pod 中写入数据验证 RWX 数据是否正确
kubectl exec -it reader-84c8c546bb-br2m5 -- /bin/sh -c "echo hello from reader pod >> /usr/share/nginx/html/index.html"
curl http://192.168.112.10:31137
......
Fri Sep 27 06:56:14 UTC 2024
Fri Sep 27 06:56:19 UTC 2024
Fri Sep 27 06:56:24 UTC 2024
Fri Sep 27 06:56:29 UTC 2024
Fri Sep 27 06:56:34 UTC 2024
hello from reader pod
Fri Sep 27 06:56:39 UTC 2024
Fri Sep 27 06:56:44 UTC 2024
Fri Sep 27 06:56:49 UTC 2024
Fri Sep 27 06:56:54 UTC 2024
Fri Sep 27 06:56:59 UTC 2024
以上结果就验证了在 Longhorn 中使用 ReadWriteMany 访问模式的 Volume 卷。
八、CSI 卷快照
上面演示了如何使用 Longhorn 对卷进行快照管理,还可以通过 kubernetes 实现对卷的快照管理,比如在集群中开启 CSI 快照
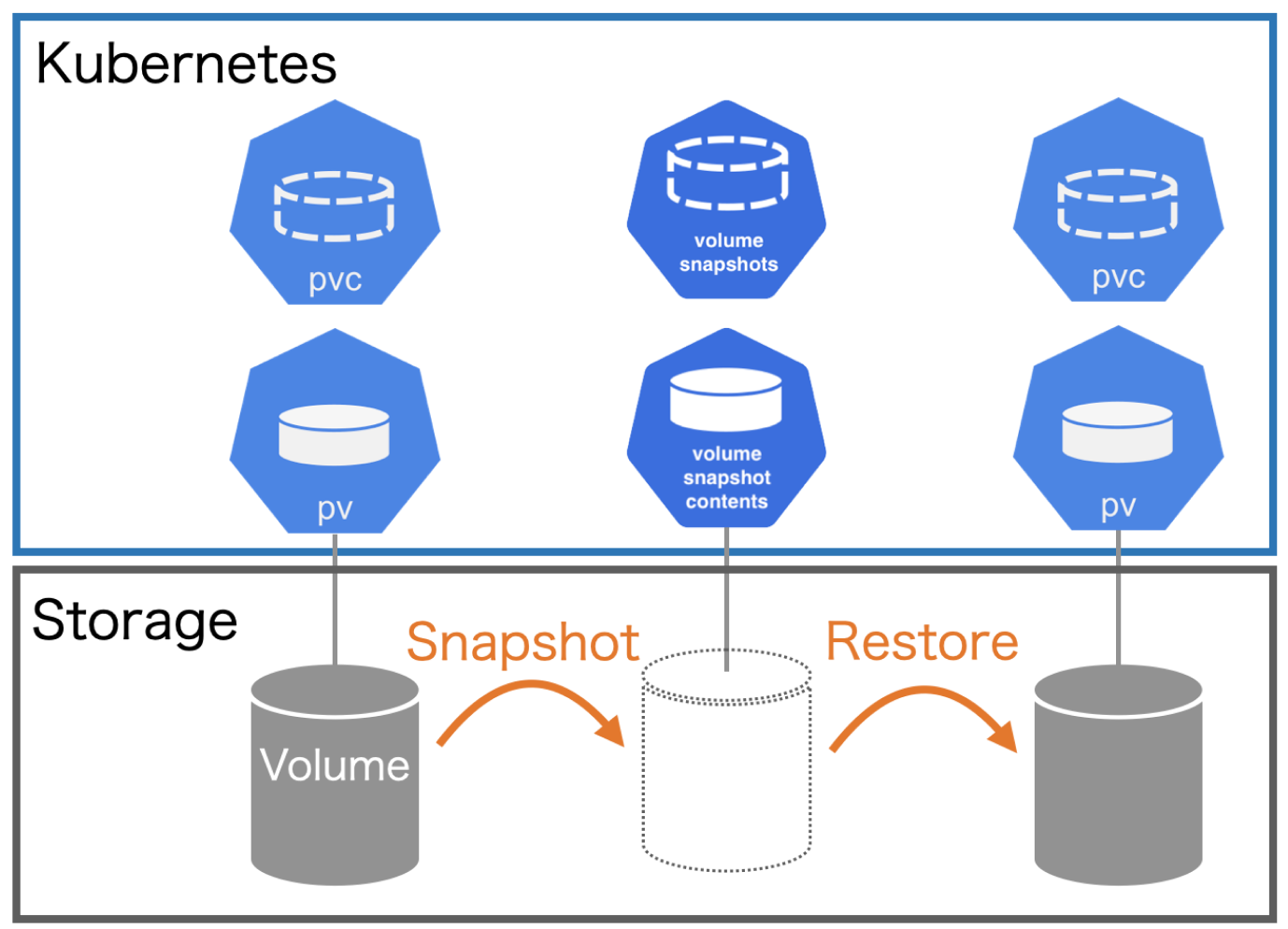
1、什么是卷快照
Kubernetes 从 1.12 版本开始引入了存储卷快照功能,在 1.17 版本进入 Beta 版本,和 PV、PVC 两个资源对象类似,Kubernetes 提供了 VolumeSnapshotContent、VolumeSnapshot、VolumeSnapshotClass 三个资源对象用于卷快照管理。
VolumeSnapshotContent 是基于某个 PV 创建的快照,类似于 PV 的资源概念;VolumeSnapshot 是用户对卷快照的请求,类似于持久
化声明 PVC 的概念;VolumeSnapshotClass 对象可以来设置快照的特性,屏蔽 VolumeSnapshotContent 的细节,为
VolumeSnapshot 绑定提供动态管理,就像 StorageClass 的“类”概念。

卷快照能力为 Kubernetes 用户提供了一种标准的方式来在指定时间点复制卷的内容,并且不需要创建全新的卷,比如数据库管理员可以
在执行编辑或删除之类的修改之前对数据库执行备份。
但是在使用该功能时,需要注意以下几点:
- VolumeSnapshot、VolumeSnapshotContent 和 VolumeSnapshotClass 资源对象是 CRDs, 不属于核心 API。
- VolumeSnapshot 支持仅可用于 CSI 驱动。
- 作为 VolumeSnapshot 部署过程的一部分,Kubernetes 团队提供了一个部署于控制平面的快照控制器,并且提供了一个叫做 csi-snapshotter 的 Sidecar 容器,和 CSI 驱动程序一起部署,快照控制器会去监听 VolumeSnapshot 和 VolumeSnapshotContent 对象,并且负责创建和删除 VolumeSnapshotContent 对象。 csi-snapshotter 监听 VolumeSnapshotContent 对象,并且触发针对 CSI 端点的 CreateSnapshot 和 DeleteSnapshot 的操作,完成快照的创建或删除。
- CSI 驱动可能实现,也可能没有实现卷快照功能,CSI 驱动可能会使用 csi-snapshotter 来提供对卷快照的支持,详见 CSI 驱动程序文档
2、卷快照的生命周期
VolumeSnapshotContents 和 VolumeSnapshots 的生命周期包括资源供应、资源绑定、对使用 PVC 的保护机制和资源删除等各个阶段,这两个对象会遵循这些生命周期。
2.1、资源供应
与 PV 的资源供应类似,VolumeSnapshotContent 也可以以静态或动态两种方式供应资源。
- 静态供应:集群管理员会预先创建好一组 VolumeSnapshotContent 资源,类似于手动创建 PV
- 动态供应:基于 VolumeSnapshotClass 资源,当用户创建 VolumeSnapshot 申请时自动创建 VolumeSnapshotContent,类似于 StorageClass 动态创建 PV
2.2、资源绑定
快照控制器负责将 VolumeSnapshot 与一个合适的 VolumeSnapshotContent 进行绑定,包括静态和动态供应两种情况,VolumeSnapshot 和 VolumeSnapshotContent 之间也是一对一进行绑定的,不会存在一对多的情况。
2.3、对使用中的 PVC 的保护机制
当存储快照 VolumeSnapshot 正在被创建且还未完成时,相关的 PVC 将会被标记为正被使用中,如果用户对 PVC 进行删除操作,系统不会立即删除 PVC,以避免快照还未做完造成数据丢失,删除操作会延迟到 VolumeSnapshot 创建完成(readyToUse 状态)或被终止(aborted 状态)的情况下完成。
2.4、资源删除
对 VolumeSnapshot 发起删除操作时,对与其绑定的后端 VolumeSnapshotContent 的删除操作将基于删除策略 DeletionPolicy 的设置来决定,可以配置的删除策略有:
- Delete:自动删除 VolumeSnapshotContent 资源对象和快照的内容。
- Retain:VolumeSnapshotContent 资源对象和快照的内容都将保留,需要手动清理。
3、查看 csi-snapshotter Pod
kubectl get pods -n longhorn-system | grep csi-snapshot

这其实是启动的 3 个副本,同一时间只有一个 Pod 提供服务,通过 leader-election 来实现的选主高可用,比如当前这里提供服务的是 csi-snapshotter-d7b4777cf-cqkjc,我们可以查看对应的日志信息:
kubectl logs -f csi-snapshotter-d7b4777cf-cqkjc -n longhorn-system
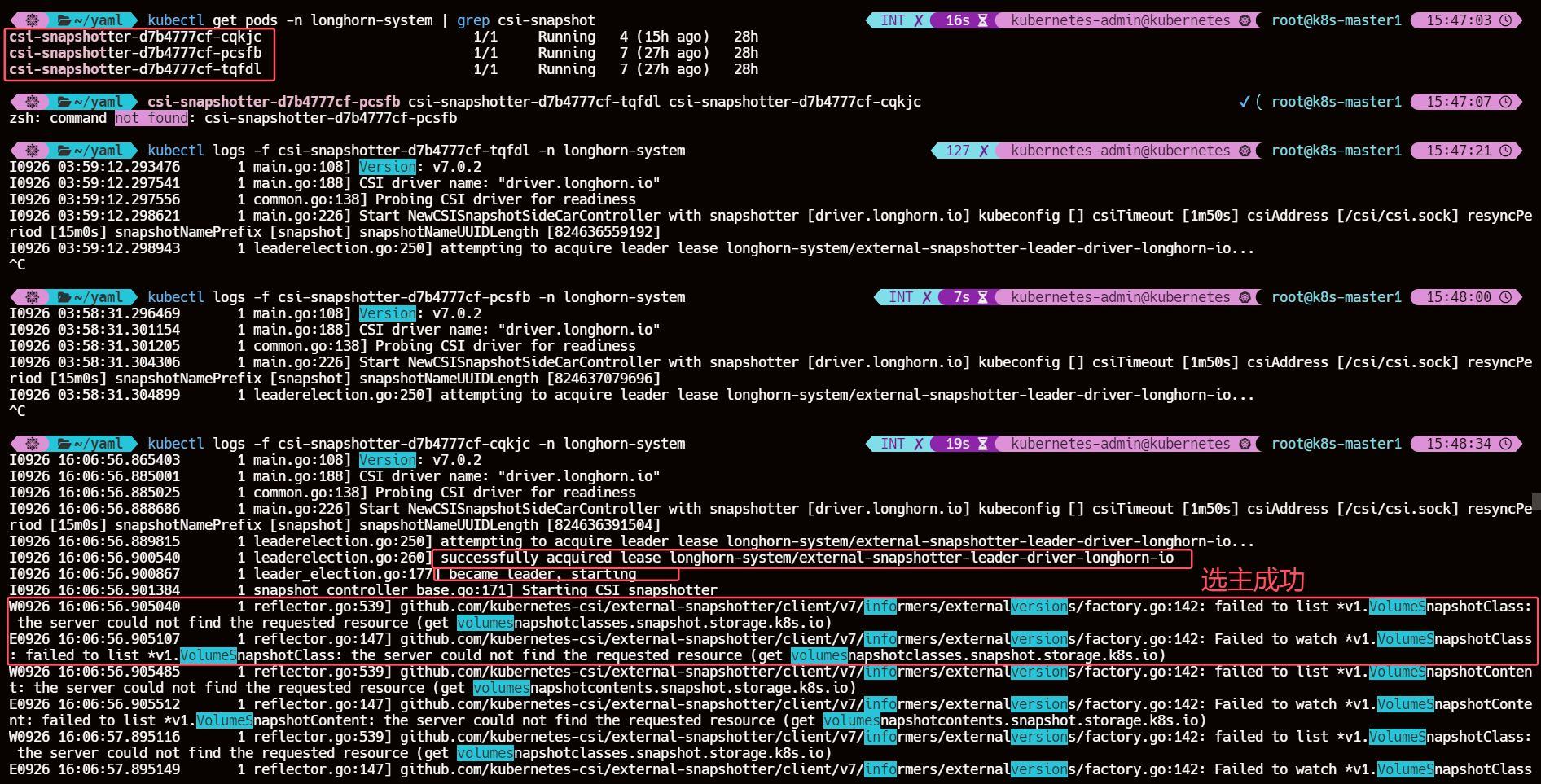
日志里的错误信息其实是集群中没有安装 VolumeSnapshotClass 和 VolumeSnapshotContent 的自定义资源定义(CRD)。
因为这两个资源都是 CRDs 不是 k8s 内置的资源对象,所以 csi-snapshotter Pod 在进行监视(watch)时获取不到
4、安装CRDs
- 根据自身 Longhorn官方文档对应安装
- enable-csi-snapshot-support
- 比如我的 Longhorn 版本为 1.7.1 安装 CSI external-snapshotter v6.3.2
- external-snapshotter
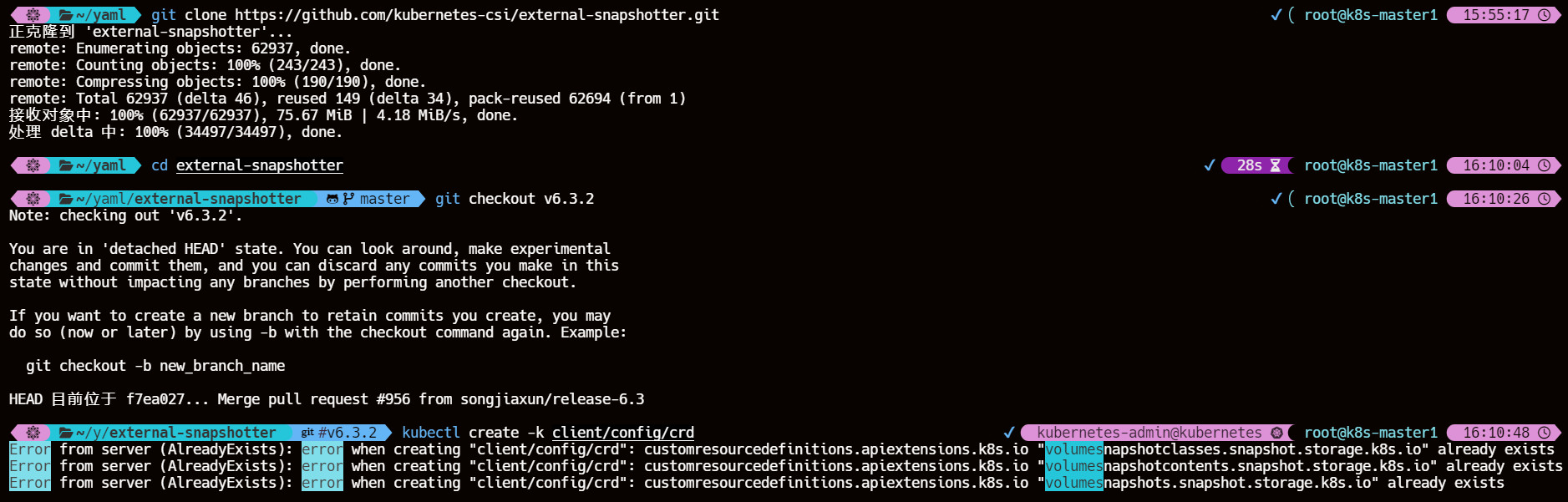
4.1、克隆 snapshotter 仓库地址
git clone https://github.com/kubernetes-csi/external-snapshotter.git
cd external-snapshotter
4.2、切换对应分支使用 kustomize 工具来构建指定目录下的资源配置
我这里在另一个标签页执行过构建命令了
git checkout v6.3.2
kubectl create -k client/config/crd

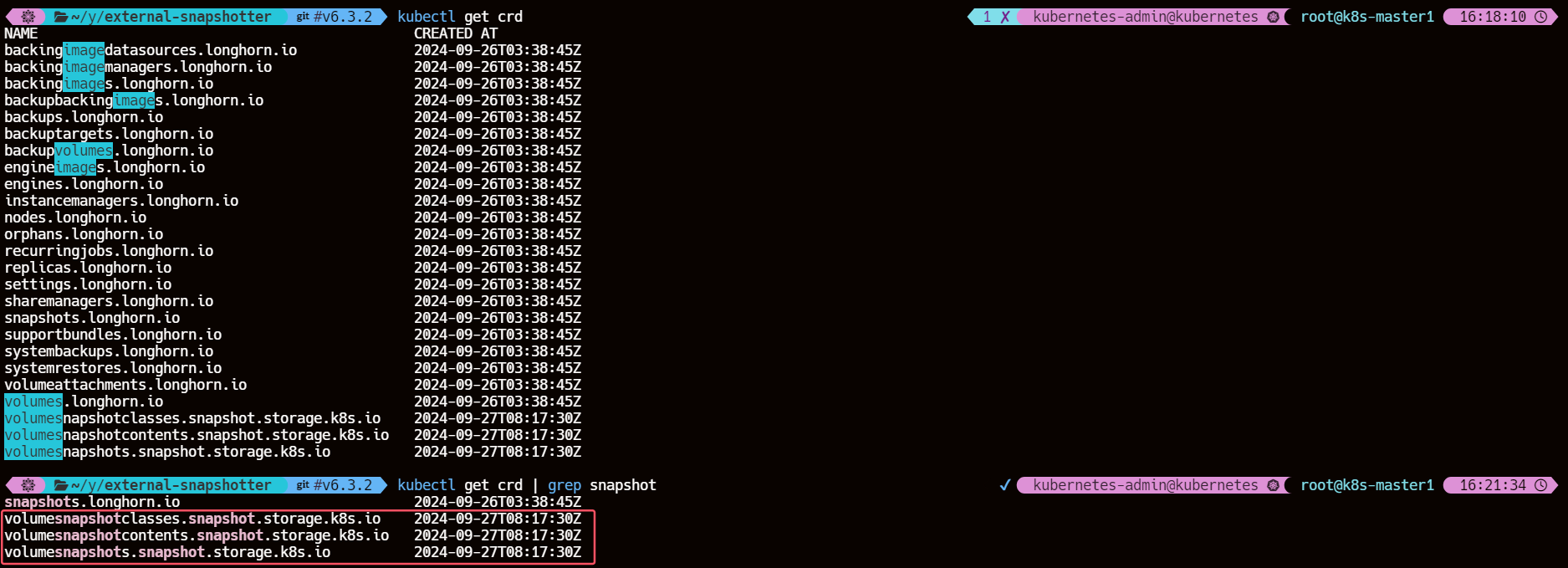
4.3、验证创建的 Snapshot CRDs
kubectl get crd | grep snapshot
4.4、查看 csi-snapshotter Leader Pod 日志情况
kubectl logs -f csi-snapshotter-d7b4777cf-cqkjc -n longhorn-system
会发现日志以及恢复正常了

4.5、安装通用快照控制器
- 同样的按照官网推荐版本对应下载
- 比如我的 Longhorn 版本为 1.7.1 安装 snapshot-controller v6.3.2
kubectl create -k deploy/kubernetes/snapshot-controller
4.5.1、【ERROR】snapshot-controller 拉取镜像在 ImagePullBackOff 与 ErrImagePull 状态间反复横跳
镜像拉取失败,换国内源
修改 deploy/kubernetes/snapshot-controller/setup-snapshot-controller.yaml 镜像地址为 cnych/csi-snapshot-controller:v5.0.0
kubectl edit deploy snapshot-controller -n kube-system
kubectl get pods -n kube-system -l app=snapshot-controller
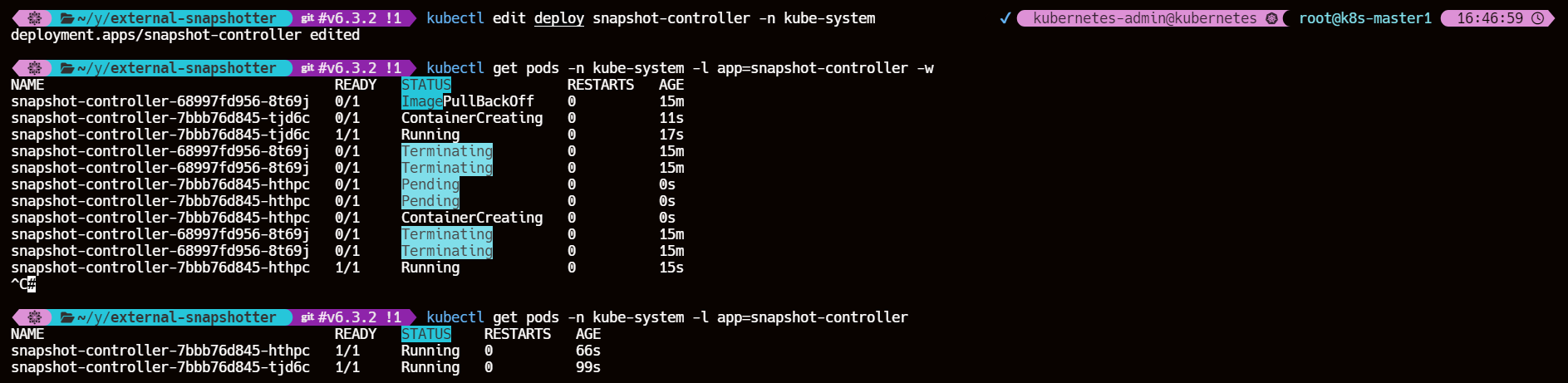
至此配置 CSI 快照环境安装完成
5、使用 CSI 卷快照功能
以最开始创建的 PVC mysql-pvc 为例
kubectl get pvc mysql-pvc -owide

5.1、创建 VolumeSnapshot 对象
cat >> snapshot-mysql.yaml << EOF
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: mysql-snapshot-demo
spec:
volumeSnapshotClassName: longhorn
source:
persistentVolumeClaimName: mysql-pvc
# volumeSnapshotContentName: test-content
EOF
主要是两个配置参数:
- volumeSnapshotClassName:指定
VolumeSnapshotClass的名称,这样就可以动态创建一个对应的VolumeSnapshotContent与之绑定,如果没有指定该参数,则属于静态方式,需要手动创建VolumeSnapshotContent。 - persistentVolumeClaimName:指定数据来源的 PVC 名称。
- volumeSnapshotContentName:如果是申请静态存储快照,则需要通过该参数来指定一个
VolumeSnapshotContent。
5.2、创建存储快照类 VolumeSnapshotClass
cat >> snapshotclass.yaml << EOF
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: longhorn
# annotations: # 如果要指定成默认的快照类
# snapshot.storage.kubernetes.io/is-default-class: "true"
driver: driver.longhorn.io
deletionPolicy: Delete
EOF
每个 VolumeSnapshotClass 都包含 driver、deletionPolicy 和 parameters 字段,在需要动态配置属于该类的 VolumeSnapshot 时使用。
- driver:表示 CSI 存储插件驱动的名称,这里我们使用的是 Longhorn 插件,名为 driver.longhorn.io
- deletionPolicy:删除策略,可以设置为 Delete 或 Retain,如果删除策略是 Delete,那么底层的存储快照会和
- VolumeSnapshotContent 对象一起删除,如果删除策略是 Retain,那么底层快照和 VolumeSnapshotContent 对象都会被保留。
- parameters:存储插件需要配置的参数,有 CSI 驱动提供具体的配置参数。
如果想将当前快照类设置成默认的则需要添加 snapshot.storage.kubernetes.io/is-default-class: “true” 这样的 annotations。
5.3、创建并查看资源对象
kubectl apply -f snapshot-mysql.yaml -f snapshotclass.yaml
kubectl get volumesnapshotclass
kubectl get volumesnapshot

5.4、查看动态创建的 VolumeSnapshotContent 对象
kubectl get VolumeSnapshotContent

kubectl get volumesnapshotContent snapcontent-ce841bd5-8fbb-4d43-bb0c-b52247597137 -o yaml
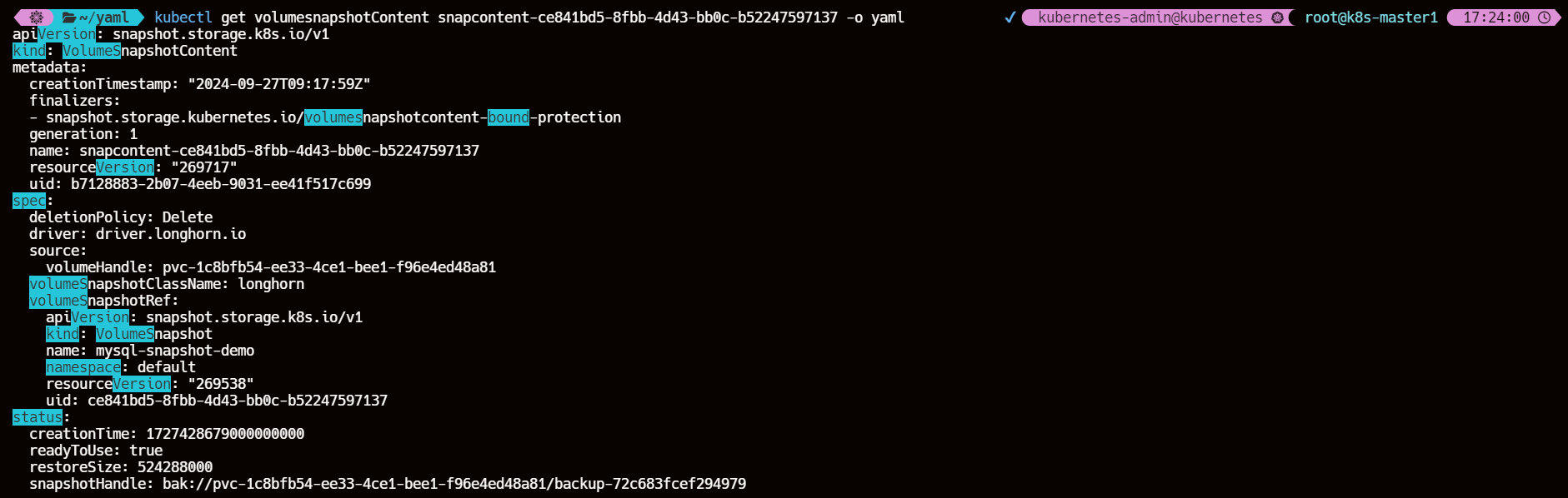
其中的 source.volumeHandle 字段的值是在后端存储上创建并由 CSI 驱动在创建存储卷期间返回的 Volume 的唯一标识符,在动态供应模式下需要该字段,指定的是快照的来源 Volume 信息
volumeSnapshotRef 下面就是和关联的 VolumeSnapshot 对象的相关信息。当然这个时候我们在 Longhorn UI 界面上也可以看到上面我们创建的这个快照了,快照名称为 snapshot-ce841bd5-8fbb-4d43-bb0c-b52247597137(snapshot-.spec.volumeSnapshotRef.uid)

后面的 ID 与上面的 VolumeSnapshotContent 名称保持一致
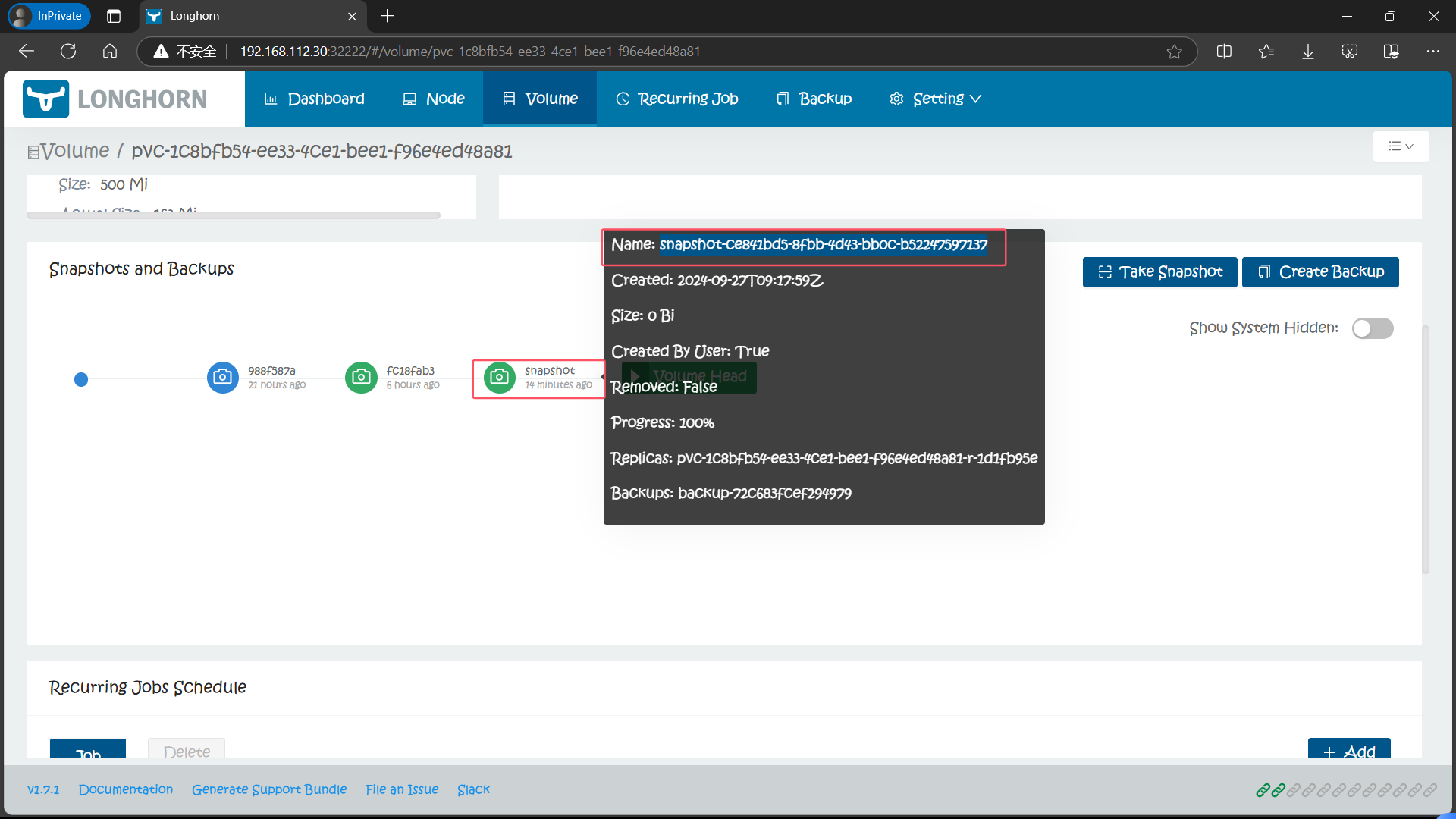
并且也会进行一次对应的 Backup 备份操作
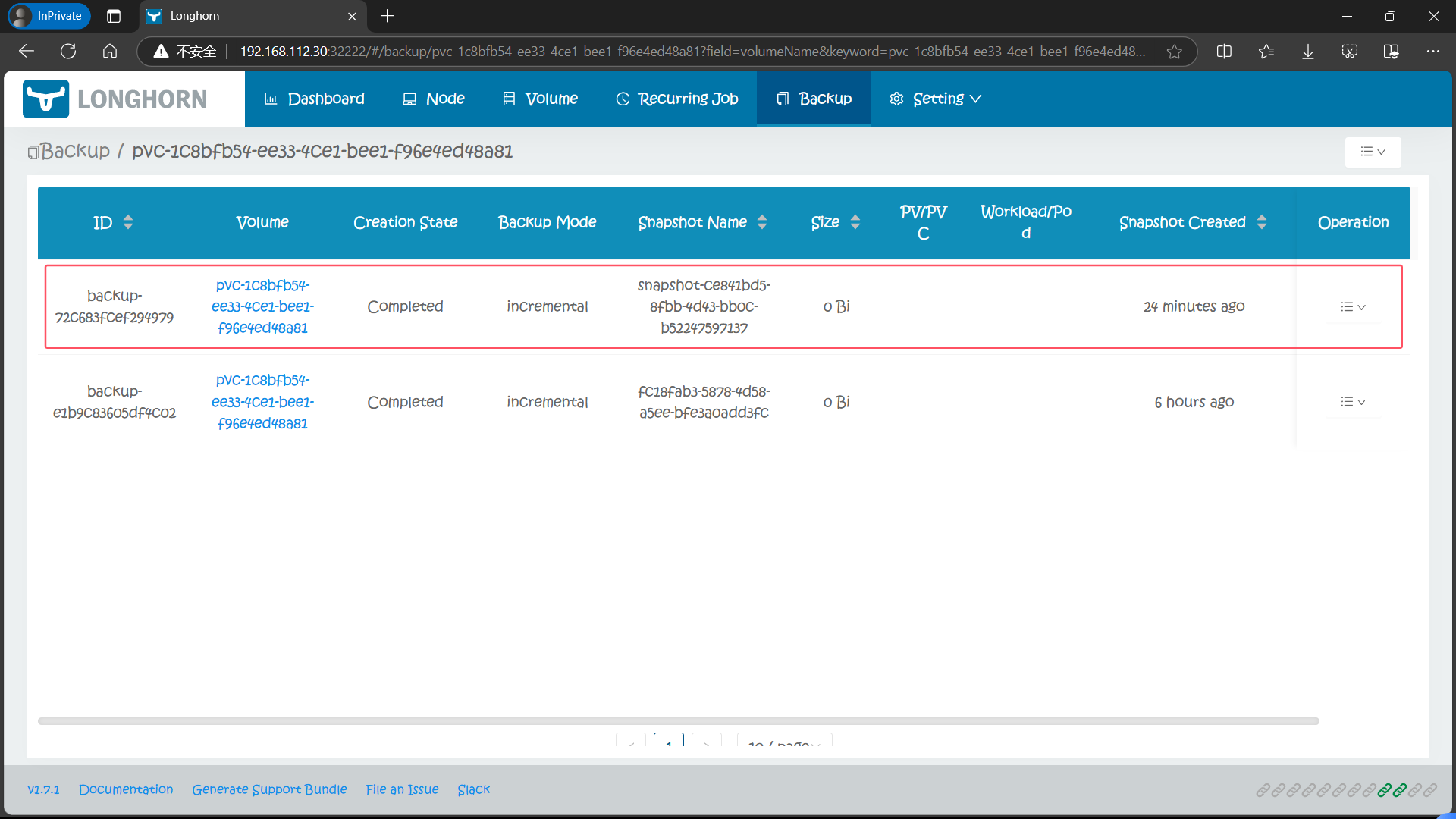
6、基于快照创建/恢复新的 PVC
Kubernetes 对基于快照创建存储卷在 1.17 版本更新到了 Beta 版本,要启用该特性,就需要在 kube-apiserver、kube-controller-manager 和 kubelet 的 Feature Gate 中启用 --feature-gates=…,VolumeSnapshotDataSource,然后就可以基于某个快照创建一个新的 PVC 存储卷了,比如现在我们来基于上面创建的 mysql-snapshot-demo 这个对象来创建一个新的 PVC:
6.1、基于创建的 volumesnapshot 创建新的 PVC
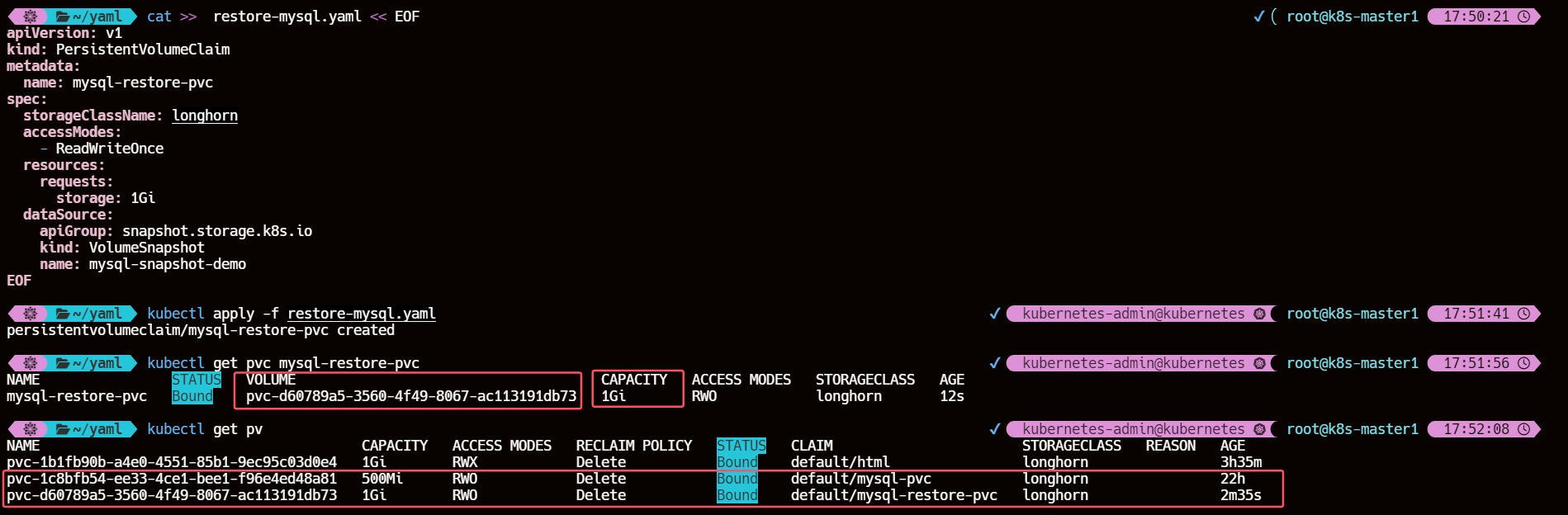
cat >> restore-mysql.yaml << EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-restore-pvc
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
dataSource:
apiGroup: snapshot.storage.k8s.io
kind: VolumeSnapshot
name: mysql-snapshot-demo
EOF
上面的 PVC 对象和我们平时声明的方式基本一致,唯一不同的是通过一个 dataSource 字段配置了基于名为 mysql-snapshot-demo 的存储快照进行创建,创建上面的资源对象后同样会自动创建一个 PV 与之绑定:
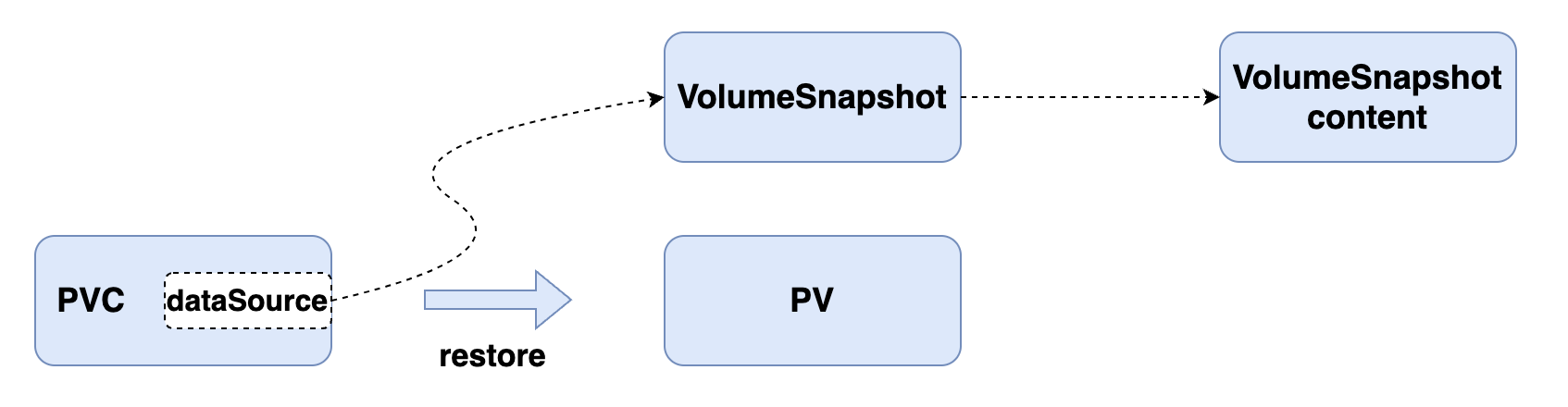
kubectl get pvc mysql-restore-pvc
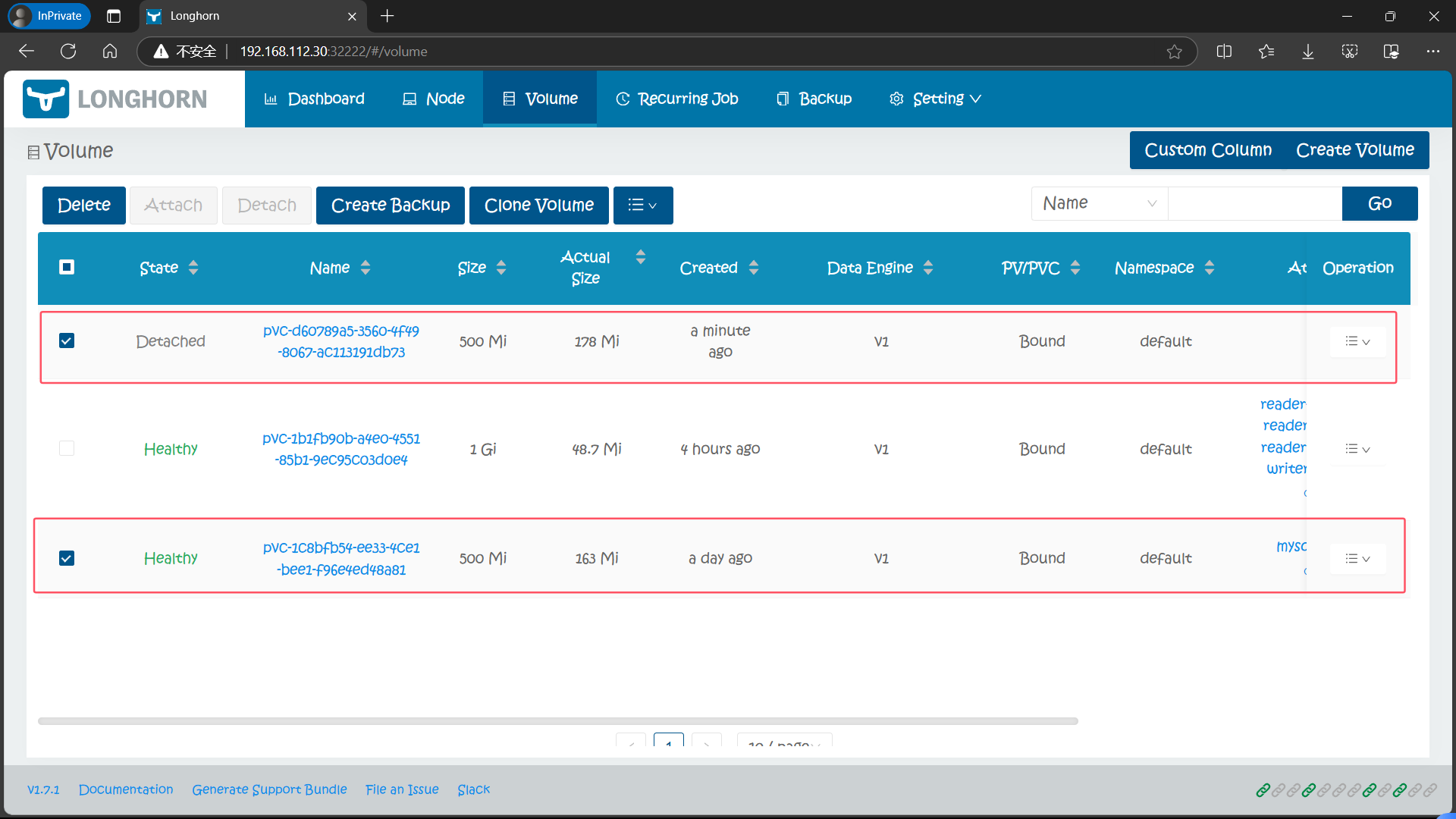
在 Longhorn UI 中去查看该卷,可以看到该卷的实际大小并不为 0,这是因为我们是从快照中创建过来的,相当于从上面的快照中恢复的数据
值得注意的是我们在定义该 PVC 资源对象时申请的是 1Gi,在k8s 中也是给其分配了 1Gi 的PV 卷,但是在 Longhorn UI 中显示的还是基于快照的状态也就是 500Mi
7、卷克隆
除了基于快照创建新的 PVC 对象之外,CSI 类型的存储还支持存储的克隆功能,可以基于已经存在的 PVC 克隆一个新的 PVC,实现方式也是通过在 dataSource 字段中来设置源 PVC 来实现。
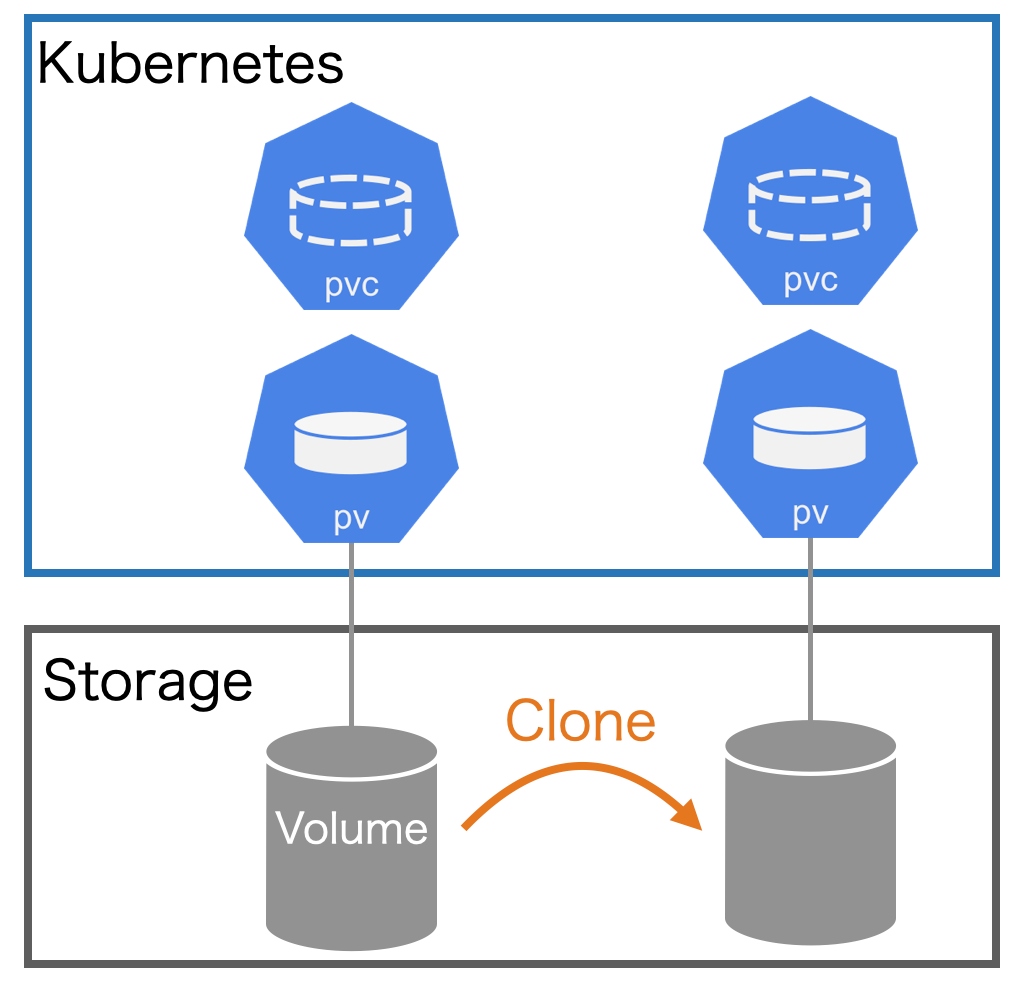
克隆一个 PVC 其实就是对已存在的存储卷创建一个副本,唯一的区别是,系统在为克隆 PVC 提供后端存储资源时,不是新建一个空的 PV,而是复制一个与原 PVC 绑定 PV 完全一样的 PV。
从 Kubernetes API 的角度看,克隆的实现只是在创建新的 PVC 时, 增加了指定一个现有 PVC 作为数据源的能力,源 PVC 必须是 bound 状态且可用的。
用户在使用该功能时,需要注意以下事项:
- 克隆仅适用于 CSI 驱动
- 克隆仅适用于动态供应
- 克隆功能取决于具体的 CSI 驱动是否实现该功能
- 要求目标 PVC 和源 PVC 必须处于同一个命名空间
- 只支持在相同的 StorageClass 中(可以使用默认的)
- 两个存储卷的存储模式(VolumeMode)要一致
7.1、对 mysql-pvc 存储卷克隆
同样我们来对前面的 mysql-pvc 这个存储卷进行克隆操作,对应的 PVC 声明如下所示:
cat >> mysql-clone-pvc.yaml << EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-clone-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 500Mi # 必须大于或等于源的值
dataSource:
kind: PersistentVolumeClaim
name: mysql-pvc
EOF
该 PVC 和源 PVC 声明一样的配置,唯一不同的是通过 dataSource 指定了源 PVC 的名称,直接创建这个资源对象,结果是 mysql-clone-pvc 这个新的 PVC 与源 mysql-pvc 拥有相同的数据。
7.2、与源 PVC 的对比
kubectl get pvc mysql-clone-pvc

7.3、在 Longhorn UI 进行查看
在 Longhorn UI 页面中也可以看到对应的卷:
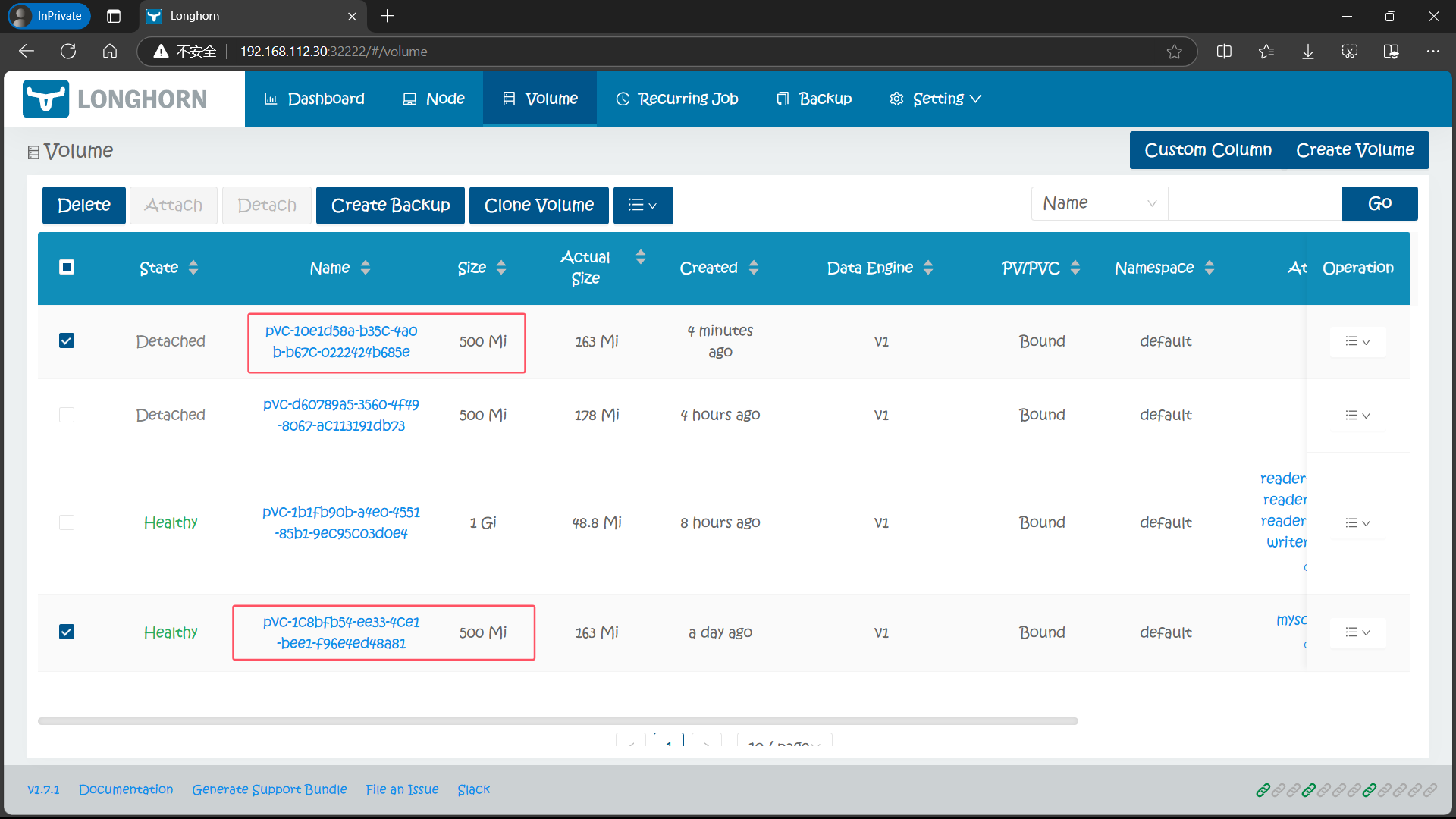
一旦新的 PVC 可用,被克隆的 PVC 就可以像其他 PVC 一样被使用了,也可以对其进行克隆、快照、删除等操作。
8、卷动态扩容
PV 要做扩容操作是需要底层存储支持该操作才能实现,Longhorn 底层是支持卷扩容操作的,但是要求扩展的卷必须处于 detached 状态才能操作,有两种方法可以扩容 Longhorn 卷:修改 PVC 和使用 Longhorn UI。
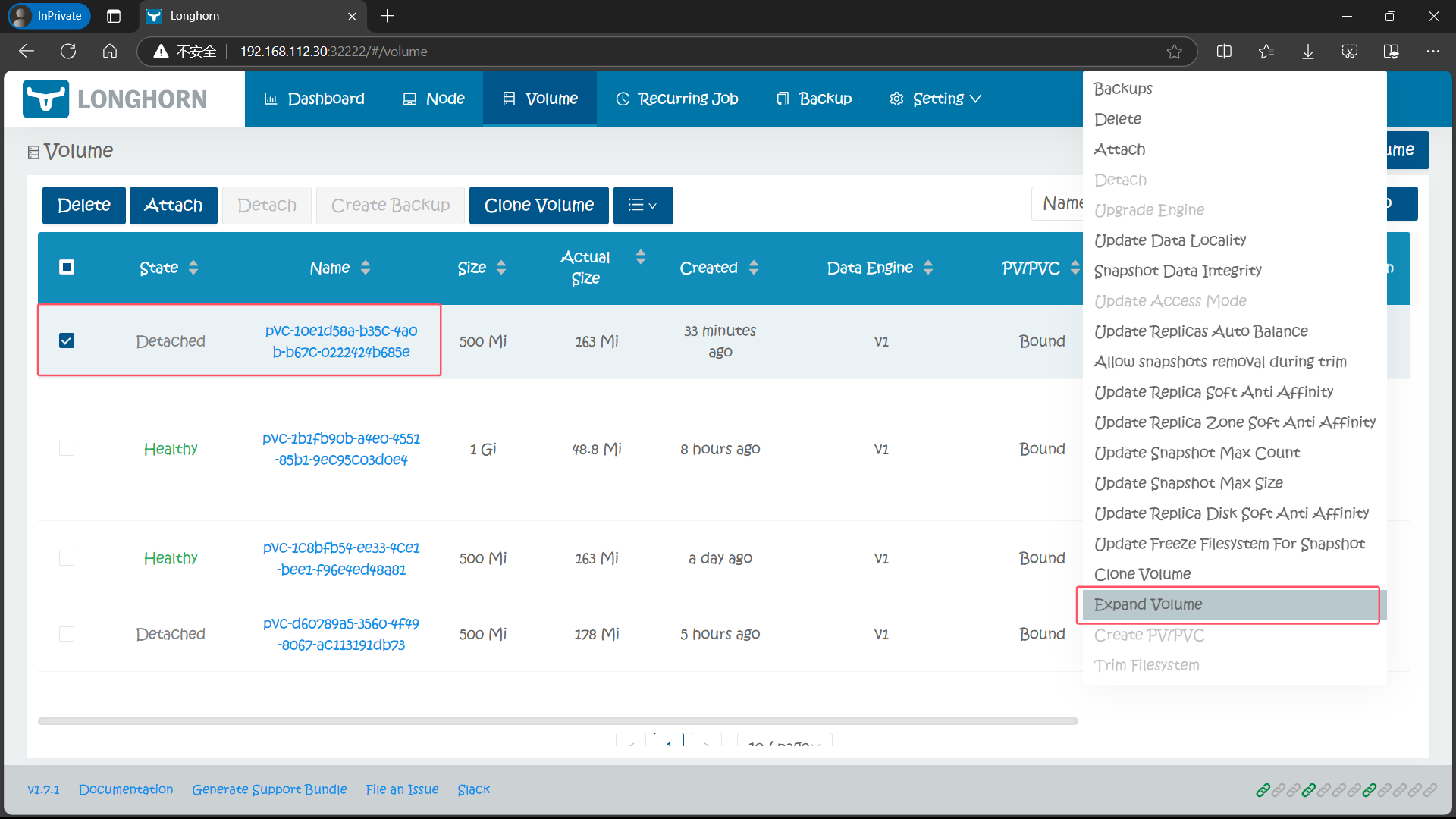
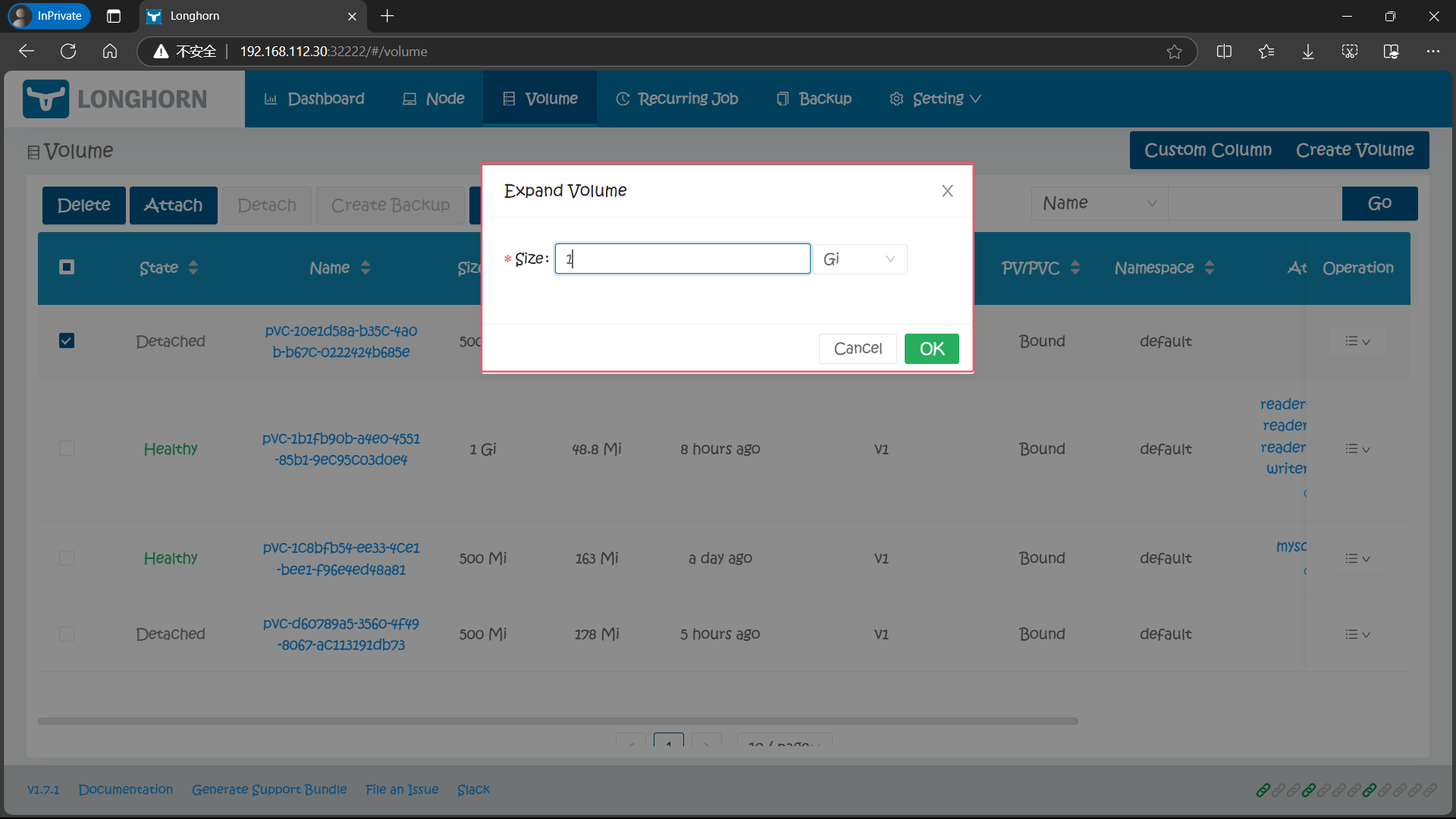
8.1、通过 Longhorn UI 进行卷扩容
通过 Longhorn UI 操作比较简单,直接在页面中选择要扩容的卷,在操作中选择 Expand Volume 进行操作即可:
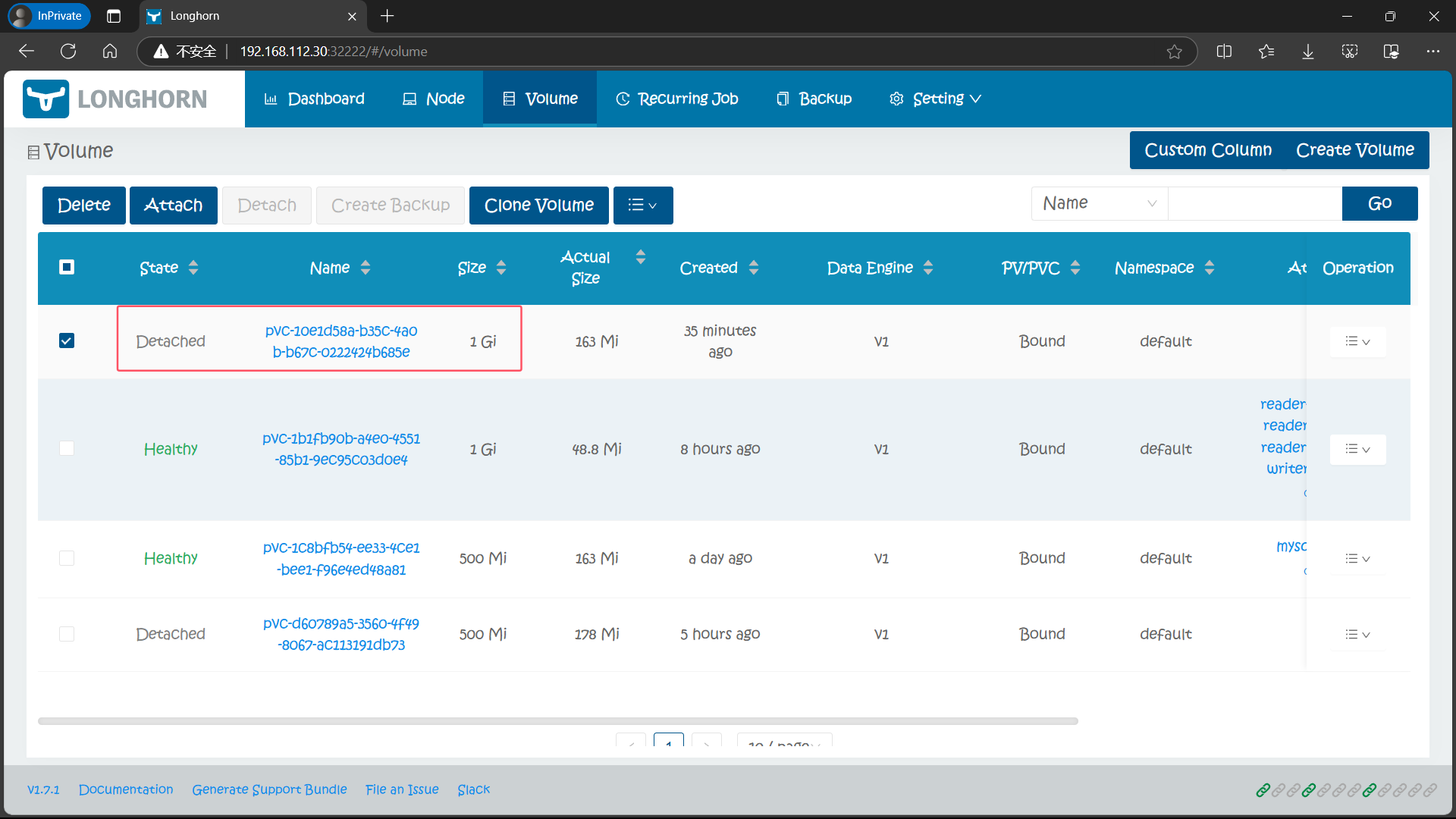

8.2、通过 PVC 进行扩容
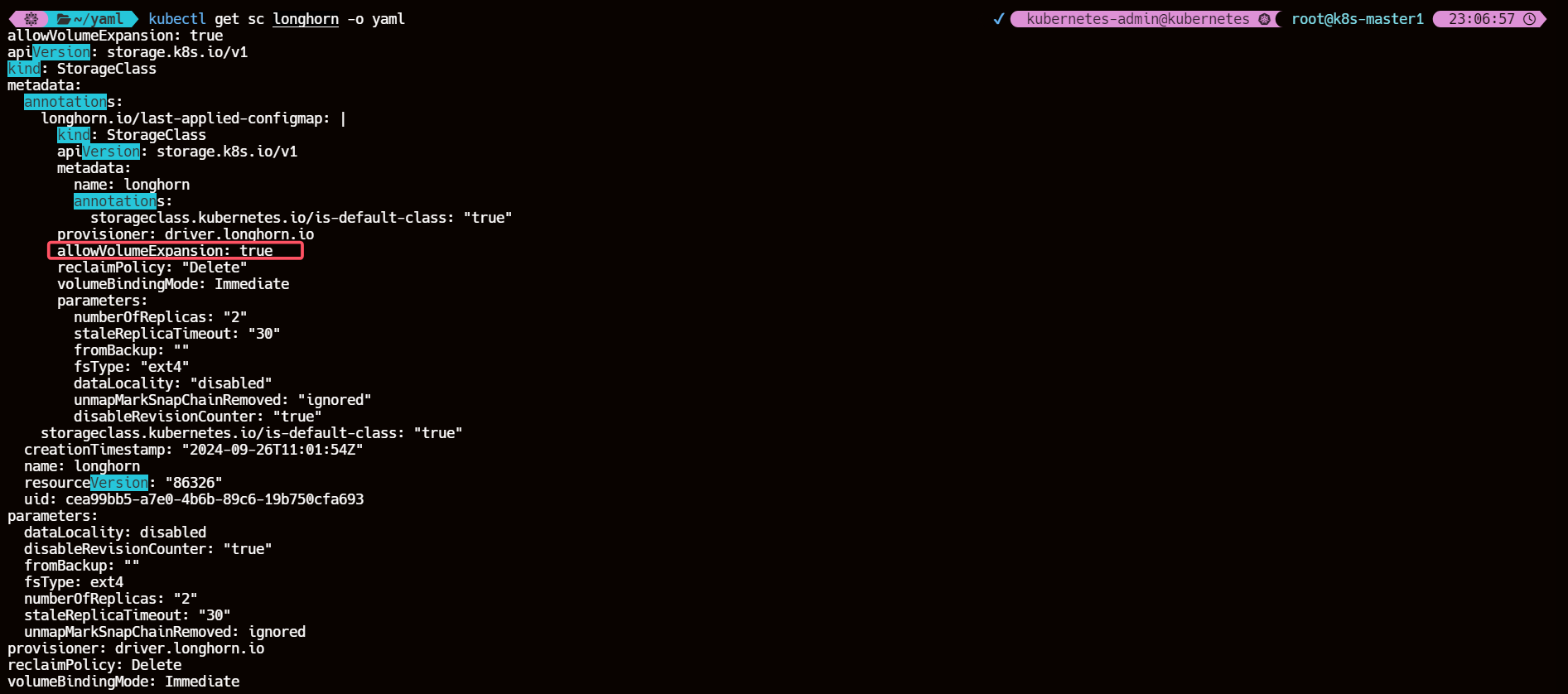
要通过 PVC 来进行扩容首先需要 PVC 由 Longhorn StorageClass 进行动态供应,并且在 StorageClass 中 allowVolumeExpansion 属性设置为 true,建议使用这种方法,因为 PVC 和 PV 会自动更新,并且在扩容后都会保持一致。
8.2.1、确认 StroageClass longhorn 开启了 allowVolumeExpansion
kubectl get sc longhorn -o yaml
8.2.2、修改 spec.resources.requests.storage 的值
然后直接修改 mysql-pvc 这个卷下面的
spec.resources.requests.storage值即可可以看到PVC 与其绑定的 PV 大小均扩容为 2Gi
kubectl patch pvc mysql-clone-pvc -p '{"spec":{"resources":{"requests":{"storage":"2Gi"}}}}}'

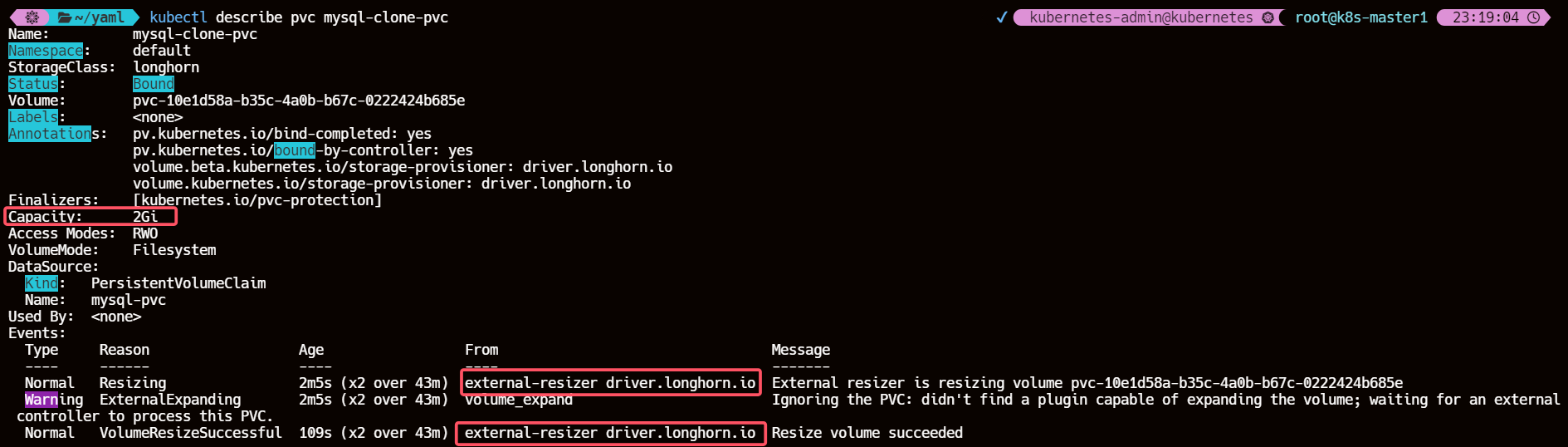
8.2.3、查看 PVC 的 events 信息
可以看到通过
external-resizer组件实现了 Resize 操作
kubectl describe pvc mysql-clone-pvc
8.3、通过 Longhorn UI 查看
也可以看到 PV 卷成功扩容