前言
我是从去年年底开始入门时间序列研究,但直到最近我读FITS这篇文章的代码时,才发现从去年12月25号就有人发现了数个时间序列Baseline的代码Bug。如果你已经知道这个Bug了,那可以忽略本文~
这个错误最初在Informer(AAAI 2021 最佳论文)中被发现,是爱丁堡大学的Luke Nicholas Darlow发现。这个问题对时间序列预测领域的一系列广泛研究都有影响,这个Bug影响了包括Patch TST、DLinear、Informer、Autoformer、Fedformer、FiLM在内的经典baseline。
-
PatchTST (ICLR 2023) - Link to affected code
-
DLinear (AAAI 2022 reported version) - Link to affected code
-
Informer (AAAI 2021 Best Paper) - Link to affected code
-
Autoformer (NIPS 2021 reported version) - Link to affected code
-
Fedformer (ICML 2022) - Link to affected code
-
FiLM (ICLR 2023) - Link to affected code
FITS这篇文章发布一个修复方法,以帮助社区在他们的工作中解决这个问题。参考链接:https://anonymous.4open.science/r/FITS/README.md
错误描述
这个错误源于数据加载器中的错误实现。测试数据加载器(test dataloader)使用了drop_last=True,那么模型的评估可能会基于不完整的测试数据集,从而导致对模型性能的不准确评估,甚至可能导致不同模型之间比较的不公平。这个问题在使用较大批量大小时尤为明显,因为更大的批量大小更容易导致数据集大小不能被整除的情况。
注:在PyTorch等数据加载框架中,drop_last参数通常用于控制当数据集大小不能被批量大小整除时,是否丢弃最后一个不完整的批量。在训练过程中,为了保持每个epoch迭代次数的稳定性,通常会设置drop_last=True。然而,在测试或验证过程中,为了获得对模型性能的准确评估,应该确保所有测试数据都被使用,因此应该设置drop_last=False。
解决方法
在data_factory.py 中,修改代码:
if flag == 'test':shuffle_flag = Falsedrop_last = Truebatch_size = args.batch_sizefreq = args.freq
如下:
if flag == 'test':shuffle_flag = Falsedrop_last = False #Truebatch_size = args.batch_sizefreq = args.freq
在代码 script 文件夹(e.g., ./exp/exp_main.py), 做出如下修改 (约在 290行),from
preds = np.array(preds)trues = np.array(trues)inputx = np.array(inputx) # some times there is not this line, it does not matter
to:
preds = np.concatenate(preds, axis=0)trues = np.concatenate(trues, axis=0)inputx = np.concatenate(inputx, axis=0) # if there is not that line, ignore this
作者说可以通过在维度0(即batch大小)上拼接(concatenate)剩余的数据解决问题,而不必丢弃最后一个不完整的batch。
结果更新
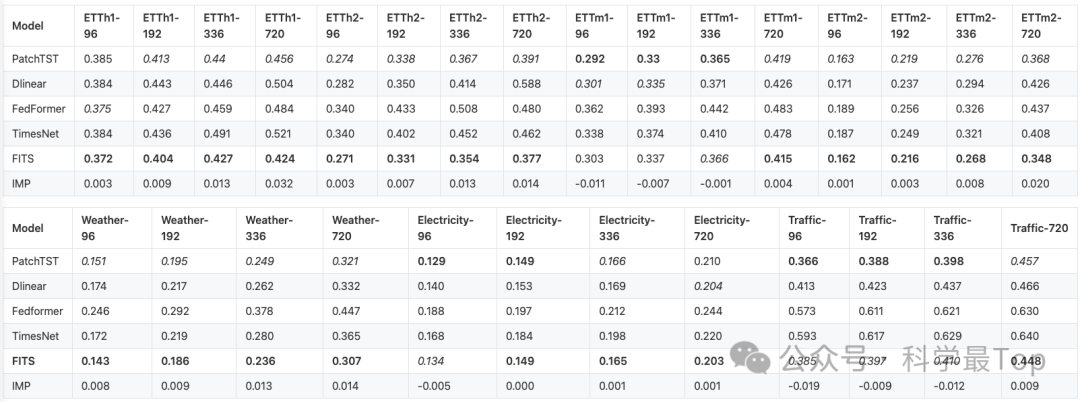
已发现的错误主要影响像ETTh1和ETTh2这样的小型数据集的结果。有趣的是,对于其他数据集,如ETTm1上的PatchTST等某些模型,却表现出了增强的性能。FITS(假设是指某个时间序列预测模型)仍然保持了足够好且与其他最先进模型相媲美的性能。
从更新后的结果我们发现,最能打还是Patch TST以及FITS。关于这两篇论文,我之前做过详细的解读,感兴趣可以关注阅读。
大家一定要关注我的公众号【科学最top】,第一时间follow时序高水平论文解读!!!