目录
第一部分 K8s概念和架构
1、k8s概述和特性
2、K8s架构组件
3、k8s核心概念
第二部分 从零搭建k8s集群
1、搭建k8s环境平台规划
2、服务器硬件配置要求
3、搭建k8s集群部署方式
(1) 基于客户端工具kubeadm
1、安装Docker
2、添加阿里云YUM软件源
3、安 装kubeadm, kubbelet和kubectl
4、部署Kubernetes Master
5、加入Kubernetes Node
6、部置CNI网络插件
7、测试kubernetes集群
附1:Kubernetes (k8s 1.23) 安装与卸载 (Kubernetes (k8s 1.23) 安装与卸载_卸载kubelet-CSDN博客)
附2: 卸载 kubernetes (卸载 kubernetes_[reset] no kubeadm config, using etcd pod spec to -CSDN博客)
(2) 基于二进制包方式
第三部分 k8s核心概念
1. kubectl简介
1)、kubectl语法格式
2)、kubectl子命令
3)、yaml文件详解
(1) 资源编排
(2)、如何快速编写yaml文件
2. Pod
1)、Pod基本概念
2)、Pod存在意义
3)、Pod实现机制
4)、Pod镜像拉取策略
5)、Pod资源限制
6)、Pod重启策略
7)、容器健康检查
8)、影响Pod调度
3. controller
1)、什么是controller
2)、Pod和Controller关系
3)、deployment应用场景
4)、使用deployment部署应用(yaml)
5)、应用升级回滚和弹性收缩
附: 缩扩容&更新(k8s学习笔记:缩扩容&更新_horizontal-pod-autoscaler-use-rest-clients-CSDN博客)
1. 前言
2. 手动调整服务规模
3. 自动缩扩容:极致弹性?
3.1 基本流程
3.2 监控指标
3.3 聚合算法
3.4 HPA实践
4. 更新、发布、回滚
5. 小结
4、Service
1、service存在意义
2、Pod和Service关系
3、常用Service类型
1)、ClusterIP: 集群内部使用
2)、NodePort:对外访问应用使用
3)、LoadBalancer: 对外访问应用使用,公有云
附: 正确删除pod
5、部署有状态应用
1)、无状态和有状态
2)、部署有状态应用
Kubernetes核心概念
Master
Master主要负责资源调度, 控制副本,和提供统一访问集群的入口
Node
Node由Master管理,并汇报容器状态给Master, 同时根据Master要求管理容器生命周期。
Node IP
Node节点的IP地址,是Kubernetes集群中每个节点的物理网卡的IP地址,是真是存在的物理网格,所有属于这个网格的服务器之间都能通过这个网格直接通信。
Pod
Pod直译是豆荚,可以把容器相像成豆荚里的豆子,把一个或多个关系紧密的豆子包在一起就是豆荚(一个Pod)。在K8s中我们不会直接操作容器,而是把容器包装成Pod再进行管理
运行于Node节点上,若干相关容器的组合,Pod内包含的容器运行在同一宿主机上,使用相同的网络命名空间,IP地址和端口,能够通过localhost进行通信, Pod是K8s进行创建、调度和管理的最小单位,它提供了比容器更高层次的抽象,使得Pod就是K8s世界的“应用”; 而一个应用,可以由多个容器组成。
第一部分 K8s概念和架构
1、k8s概述和特性
1. k8s概述
k8s是google在2014年开源的容器集群管理系统
使用k8s进行容器化应用部署
使用k8s利于应用扩展
k8s目标实施让部署容器化应用更加简洁和高效
2.特性
自动装箱: 基于容器对应用运行环境的资源配置要求自动部署应用容器
自我修复: 当容器失败时,会对容器进行重启,当所部署的Node节点有问题时,会对容器进行重新部署和重新调度。
当容器未通过监控检查时,会关闭此容器直到容器正常运行时,才会对外提供服务。
水平扩展: 通过简单的命令、用户UI界面或基于CPU等资源使用情况,对应用容器进行规模扩大或规模前裁。
服务发现:用户不需使用额外的服务发现机制,就能够基于Kubernetes自身能力实现服务发现和负载均衡。
滚动更新: 可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新。
版本回退: 可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退。
密钥和配置管理: 在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署。
存储编排: 自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要,存储系统可以来自于本地目录、网络存储(NFS、Gluster、 Ceph 等)、公共去存储服务。
批处理:提供一次性任务,定时任务,满足批量数据处理和分析的场景
2、K8s架构组件
Master(主控节点)和 Node(工作节点)
Master主要负责资源调度, 控制副本,和提供统一访问集群的入口
Node由Master管理,并汇报容器状态给Master, 同时根据Master要求管理容器生命周期。
(1)master组件
apiserver
集群统一入口,以restful方式,交给etcd存储
scheduler
节点调度, 选择node节点应用部署。
controller-manager
处理集群中常规后台任务,一个资源对应一个控制器,
etcd
存储系统,用于保存集群相关的数据
(2)node 组件
kubelet
master派到node节点代表,管理本机容器
kube-proxy
提供网络代理,负载均衡等操作
3、k8s核心概念
-
Pod
最小的布署单元
一组容器的集合
共享网络
生命周期是短暂的
-
Controller
确保预期的pod副本数量
无状态应用部署
有状态应用部署
确保所有的node运行同一个pod
一次性任务和定时任务
-
Service
定义一组pod的访问规则
第二部分 从零搭建k8s集群
1、搭建k8s环境平台规划
单master环境 缺点: master 出现故障,系统全挂着
多master集群
2、服务器硬件配置要求
测试环境: master 2核 4G 20G node 4核 8G 40G
生产环境: master 8核 16G 100G node 16核 64G 500G
3、搭建k8s集群部署方式
(1) 基于客户端工具kubeadm
kubeadm是官方社区推出的一个用于快速部署kubernets集群的工具,这个工具能通过两条指令完成一个kubernetes集群的部署:
第一、创建一个Master节点, kubeadm init;
第二、将Node节点加入到当前集群中 $ Kubeadm join <Master节点的IP 和 端口>
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
#关才selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config #永久
setenforce 0 #临时
#关闭swap
swapoff -a #临时
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久
#根据规划设置主机名
hostnamectl set-hostname <hostname>
#在master添加hosts
cat >> /etc/hosts << EOF
192.168.0.118 master
192.168.0.119 node1
192.168.0.120 node2
EOF
#将桥接r IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system #生效
#时间同步 -- centOS 7
yum install ntpdate -y
ntpdate time.windows.com
#设置时间同步 centos 8
#安装chrony
yum install -y chrony
#启动 chrony
systemctl start chronyd
#设为系统自动启动
systemctl enable chronyd
#编辑配置etc/chrony.conf
#注释掉 pool
#添加 system ntp.aliyun.com iburst所有节点安装Docker/kubeadm/kubelet
Kubernetes默认CRI(容器运行时)为Docker,因此先安装Docker
1、安装Docker
#安装依赖包
yum -y install yum-utils device-mapper-persistent-data lvm2
#配置docker数据源
curl -o /etc/yum.repos.d/docker-ce.repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#更新yum缓存
yum makecache
#安装docker-ce
yum -y install docker-ce --allowerasing
systemctl enable docker && systemctl start docker
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://0tqgzhgs.mirror.aliyuncs.com"]
}
EOF
systemctl daemon-reload
systemctl restart docker
#查询docker安装过的包:
yum list installed | grep docker
#删除安装包:
yum remove docker-ce.x86_64 ddocker-ce-cli.x86_64 -y
#删除镜像/容器等
rm -rf /var/lib/docker
#查看docker启动状态:
systemctl status docker
#查看所有仓库中所有docker版本,并选择特定版本安装:
yum list docker-ce --showduplicates | sort -r2、添加阿里云YUM软件源
cat > /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF3、安 装kubeadm, kubbelet和kubectl
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0 systemctl enable kubelet
4、部署Kubernetes Master
在192.168.0.118(Master)执行
kubeadm init --apiserver-advertise-address=192.168.0.123 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
kubeadmin reset /y 重启集群, 解决端口被占用


mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config #kubectl get nodes
5、加入Kubernetes Node
在(Node)节点执行
向集群添加新节点, 执行在kubeadm init输出的kubeadm join命令
kubeadm join 192.168.0.118:6443 --token lq2oya.bftqo13m58a6ah7r --discovery-token-ca-cert-hash sha256:a9da1cf3098477ab801dcab24b0d9c336e94568d7da602a5aef9d7f2a4cf996a
默认token 有效期为24小时,当过期之后,该token就不可用,这时需重新创建token,操作如下:
kubeadm token create --print-join-command
6、部置CNI网络插件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml

解决方法:
step-1
在 ip查询 查ip 网站ip查询 同ip网站查询 iP反查域名 iP查域名 同ip域名
输入raw.githubusercontent.com查询IP地址
step-2 修改hosts Ubuntu,CentOS及macOS直接在终端输入
sudo vi /etc/hosts 添加以下内容保存即可 (IP地址查询后相应修改,可以ping不同IP的延时 选择最佳IP地址) 或
cat >> /etc/hosts <<EOF 185.199.110.133 raw.githubusercontent.com 185.199.108.133 raw.githubusercontent.com 185.199.109.133 raw.githubusercontent.com 185.199.111.133 raw.githubusercontent.com 182.43.124.6 raw.githubusercontent.com EOF
默认镜像地址无法访问,sed命令修改为docker hub镜像仓库。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml kubectl get pods -n kube-system
7、测试kubernetes集群
在kubernetes集群中创建一个pod,验证是否正常运行.
在kubernetes集群中创建一个pod,验证是否正常运行:
kubectl create deployment nginx --image=nginx kubectl expose deployment nginx --port=80 --type=NodePort kubectl get pod,svc
访问地址:http://NodeIP:Port

附1:Kubernetes (k8s 1.23) 安装与卸载 (Kubernetes (k8s 1.23) 安装与卸载_卸载kubelet-CSDN博客)
请注意k8s在1.24版本不支持docker容器,本文使用kubeadm进行搭建 linux版本 centos7 docker版本 主节点 19版本, 从节点 20版本 k8s版本 1.23.5 1.查看系统版本信息以及修改配置信息 1.1 安装k8s时,临时关闭swap ,如果不关闭在执行kubeadm部分命令会报错
swapoff -a
或直接注释swap(需要重启生效)
cat /etc/fstab # # /etc/fstab # Created by anaconda on Tue Apr 19 11:43:17 2022 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # /dev/mapper/centos_hhdcloudrd6-root / xfs defaults 0 0 UUID=13a8fe45-33c8-4258-a434-133ce183d3c3 /boot xfs defaults 0 0 #/dev/mapper/centos_hhdcloudrd6-swap swap swap defaults 0 0
1.2 安装k8s时,可以临时关闭selinux,减少额外配置
setenforce 0
或修改 /etc/sysconfig/selinux 文件 后重启
cat /etc/sysconfig/selinux # This file controls the state of SELinux on the system. # SELINUX= can take one of these three values: # enforcing - SELinux security policy is enforced. # permissive - SELinux prints warnings instead of enforcing. # disabled - No SELinux policy is loaded. SELINUX=disabled # SELINUXTYPE= can take one of three values: # targeted - Targeted processes are protected, # minimum - Modification of targeted policy. Only selected processes are protected. # mls - Multi Level Security protection. SELINUXTYPE=targeted
1.3 关闭防火墙
systemctl stop firewalld systemctl disable firewalld
1.4 启用 bridge-nf-call-iptables 预防网络问题
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
1.5 设置网桥参数
cat << EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF
1.6 修改hosts文件 方便查看域名映射
cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.34.7 k8s-master 192.168.5.129 k8s-node1 192.168.34.8 k8s-node2
1.7 查看系统版本信息 修改hostname
hostnamectl Static hostname: localhost.localdomain Icon name: computer-vm Chassis: vm Machine ID: 5c2c4826a7cd442a85c37d3b4dba39e0 Boot ID: 3f70bab69c37412da8eada29d50cc12c Virtualization: vmware Operating System: CentOS Linux 7 (Core) CPE OS Name: cpe:/o:centos:centos:7 Kernel: Linux 3.10.0-1160.el7.x86_64 Architecture: x86-64
hostnamectl set-hostname k8s-node1 su root
1.8 查看cpu信息 k8s安装至少需要2核2G的环境,否则会安装失败
1 2 1.8 查看cpu信息 k8s安装至少需要2核2G的环境,否则会安装失败
lscpu
-
安装docker 进入查看docker基础 2.1 使用阿里云安装
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
2.2 修改docker的 /etc/docker/daemon.json文件
2.2 修改docker的 /etc/docker/daemon.json文件
[root@localhost /]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://t81qmnz6.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
2.3 修改完成后 重启docker ,使docker与kubelet的cgroup 驱动一致
systemctl daemon-reload systemctl restart docker systemctl enable docker
2.4 查看kubelet驱动
cat /var/lib/kubelet/config.yaml |grep group
1 3.安装kubeadm kubelet kubectl 3.1 配置k8s下载资源配置文件
cat << EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
3.2 安装 kubelet kubeadm kubectl
yum install -y --nogpgcheck kubelet-1.23.5 kubeadm-1.23.5 kubectl-1.23.5
kubelet :运行在cluster,负责启动pod管理容器 kubeadm :k8s快速构建工具,用于初始化cluster kubectl :k8s命令工具,部署和管理应用,维护组件 3.2.1 查看是否安装成功
kubelet --version kubectl version kubeadm version
3.3 启动kubelet
systemctl daemon-reload systemctl start kubelet systemctl enable kubelet
3.4 拉取init-config配置 并修改配置 ps. init-config 主要是由 api server、etcd、scheduler、controller-manager、coredns等镜像构成
kubeadm config print init-defaults > init-config.yaml
3.4.1 修改 刚才拉取的init-config.yaml文件
imageRepository: registry.aliyuncs.com/google_containers
[root@localhost /]# cat init-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.34.7 #master节点IP地址
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
imagePullPolicy: IfNotPresent
name: master #master节点node的名称
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers #修改为阿里云地址
kind: ClusterConfiguration
kubernetesVersion: 1.23.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
scheduler: {}
3.5 拉取k8s相关镜像
kubeadm config images pull --config=init-config.yaml
多次尝试都是超时,上网时找了很多方法依旧不行,之后找到一个命令可以查看需要拉取的镜像
使用下边的命令可以查看 需要拉取的镜像
[root@localhost /]# kubeadm config images list --config init-config.yaml registry.aliyuncs.com/google_containers/kube-apiserver:v1.23.0 registry.aliyuncs.com/google_containers/kube-controller-manager:v1.23.0 registry.aliyuncs.com/google_containers/kube-scheduler:v1.23.0 registry.aliyuncs.com/google_containers/kube-proxy:v1.23.0 registry.aliyuncs.com/google_containers/pause:3.6 registry.aliyuncs.com/google_containers/etcd:3.5.3-0 registry.aliyuncs.com/google_containers/coredns:v1.8.6
同理可得 以下脚本
#!/bin/bash
images=`kubeadm config images list --config init-config.yaml`
if [[ -n ${images} ]]
then
echo "开始拉取镜像"
for i in ${images};
do
echo $i
docker pull $i;
done
else
echo "没有可拉取的镜像"
fi
最终拉取镜像成功 注意我图片上是1.24版本 这个版本不支持docker容器 给大家提个醒
3.6 运行kubeadm init安装master节点 主要两种方法 2选一即可 主要是初始化master节点 其他node节点通过 kubeadm join 进来
#方法一 kubeadm init --config=init-config.yaml
#方法二 kubeadm init --apiserver-advertise-address=192.168.34.7 --apiserver-bind-port=6443 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --kubernetes-version=1.23.5 --image-repository registry.aliyuncs.com/google_containers
推荐使用第二种方法,我在使用第一种方法时候遇到了网络插件pod启动失败导致corndns的pod也创建失败的情况,我是用的是kube-flannel,他的状态一直是CrashLoopBackOff 经过查看log信息,需要去 /etc/kubernetes/manifests/kube-controller-manager.yaml下增加这两条信息
--allocate-node-cidrs=true --cluster-cidr=10.244.0.0/16
下载完成后可以看到这个界面 ps. 如果下载失败执行 kubeadm reset ,重新执行kubeadm init
之前有使用kubeadm安装过,需要提前把之前的kube文件删除掉
rm -rf $HOME/.kube
在master节点运行以下三行命令 执行完成后可以通过 kubeadm token list获取token
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果是使用1.24版本需要安装对应的CRI容器要不然就会报这个错误 [ERROR CRI]: container runtime is not running: output: time=“2022-05-19T16:02:33+08:00” level=fatal msg=“getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService” , error: exit status 1
3.7 查看token信息 以及生成 永久token 3.7.1 查看存在的token
kubeadm token list
3.7.2 生成永久token
kubeadm token create --ttl 0
1 3.7.3 生成 Master 节点的 ca 证书 sha256 编码 hash 值
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
3.7.4 在node节点 执行加入master命令
kubeadm join 192.168.34.7:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:d06b56614f1fcbf3e852bc440ab96a9c8846f7b2f1efd740fe320dc22705f485
3.7.5 在master节点查看 加入的node节点 或删除节点
kubectl get nodes kubectl delete nodes 节点名称
3.7.6 master节点删除node节点后,node节点再次加入需要在node节点执行 kubeadm reset
3.7.7 部署网络插件 kube-flannel.yml 并 应用获取运行中容器
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
3.7.8 或使用 weave 网络插件 和 kube-flannel 2选一就可以
wget http://static.corecore.cn/weave.v2.8.1.yaml
kubectl apply -f weave.v2.8.1.yaml
3.8 查看kubelet日志
1 3.8 查看kubelet日志
journalctl -xefu kubelet
3.9 kubernetes中文文档 Kubernetes中文社区 (Kubernetes(K8S)中文文档_Kubernetes中文社区) | 中文文档 (Kubernetes(K8S)中文文档_Kubernetes中文社区)
3.10 使用kubeadm安装k8s集群的小bug,查看时候会出现不健康状态
处理方法
##进入到k8s的yaml文件目录下,将文件中的--port=0删除掉,无需重启,一会后再查看健康状态就会恢复正常
cd /etc/kubernetes/manifests
4.卸载k8s
yum -y remove kubelet kubeadm kubectl sudo kubeadm reset -f sudo rm -rvf $HOME/.kube sudo rm -rvf ~/.kube/ sudo rm -rvf /etc/kubernetes/ sudo rm -rvf /etc/systemd/system/kubelet.service.d sudo rm -rvf /etc/systemd/system/kubelet.service sudo rm -rvf /usr/bin/kube* sudo rm -rvf /etc/cni sudo rm -rvf /opt/cni sudo rm -rvf /var/lib/etcd sudo rm -rvf /var/etcd
附2: 卸载 kubernetes (卸载 kubernetes_[reset] no kubeadm config, using etcd pod spec to -CSDN博客)
1.重置集群
[root@localhost ~]# kubeadm reset -f [preflight] Running pre-flight checks W1204 18:14:33.123415 3064 removeetcdmember.go:79] [reset] No kubeadm config, using etcd pod spec to get data directory
2.删除配置
[root@localhost ~]# modprobe -r ipip [root@localhost ~]# lsmod Module Size Used by xt_comment 16384 3 [root@localhost ~]# rm -rf ~/.kube/ [root@localhost ~]# rm -rf /etc/kubernetes/ [root@localhost ~]# rm -rf /etc/systemd/system/kubelet.service.d [root@localhost ~]# rm -rf /etc/systemd/system/kubelet.service [root@localhost ~]# rm -rf /usr/bin/kube* [root@localhost ~]# rm -rf /etc/cni [root@localhost ~]# rm -rf /opt/cni [root@localhost ~]# rm -rf /var/lib/etcd [root@localhost ~]# rm -rf /var/etcd
3.卸载kubeadm
[root@localhost ~]# yum remove kubeadm Repository extras is listed more than once in the configuration Dependencies resolved.
4.卸载 kubelet
[root@localhost ~]# yum remove kubelet Repository extras is listed more than once in the configuration Dependencies resolved
. 5.最后在清理一下
[root@localhost ~]# yum remove kube* Repository extras is listed more than once in the configuration No match for argument: kube-flannel.yml No packages marked for removal. Dependencies resolved. Nothing to do. Complete!
整体命令:
kubeadm reset -f modprobe -r ipip lsmod rm -rf ~/.kube/ rm -rf /etc/kubernetes/ rm -rf /etc/systemd/system/kubelet.service.d rm -rf /etc/systemd/system/kubelet.service rm -rf /usr/bin/kube* rm -rf /etc/cni rm -rf /opt/cni rm -rf /var/lib/etcd rm -rf /var/etcd yum remove kubeadm yum remove kubelet yum clean all yum remove kube*
(2) 基于二进制包方式
1、初始化操作系统
2、生成cfssl自签证书
ca-key.pem, ca.pem, server-key.pem, server.pem
3、部署ectd集群
本质把etcd服务,交给system管理
(1) 把生成证书复制过来, 启动, 设置开机启动
4、为apiserver自签证书
生成过程和etcd类似
5、部署master组件
(1) apiserver
(2)controller-manager
(3)scheduler
交给systemd管理组件--组件启动,设置开机启动。
安装最新1.19版本,下载二进制文件进行安装
6、部署node组件
(1) docker
(2) kubelet
(3)kube-proxy
交给system管理组件-组件启动,设置开机启动.
(4)批准kubelet证书申请并加入集群
7、部署CNI网络插件
搭建k8s集群方式比较
| kubeadm搭建k8s集群 | 二进制方式搭建k8s集群 | |
|---|---|---|
| 1、安装虚拟机,在虚拟机安装linux操作系统 | 1、安装虚拟机和操作系统, | |
| 2、对操作系统初始化操作 | 2、对操作系统初始化 | |
| 3、有所有节点(master, node) 安装docker、kubelet、kubectl、kubeadm (1)、安装docker, 使用yum, 不指定版本安装最新的docker版本install docker-ce-18.06.1.ce-3.e17 #不指定版本,安装最新的 | 3、生成cfssl自签证书 ca-key.pem ca.pem server-key.pem server.pem | |
| (2)、修改docker仓库地址,yum源地址,改为阿里云地址 | ||
| (3)、安装kubeadm, kubelet和kubectl | ||
| 4、部署etcd集群 | ||
| 本质把etcd服务,交给systemd管理 (1) 把生成证书复制过来,启动,设置开机启动。 | ||
| 5、这apiserver自签证书 | ||
| 生成过程和etcd类似 | ||
| 6、部署master组件 | ||
| (1) apiserver | ||
| (2) controller-manager |
第三部分 k8s核心概念
1. kubectl简介
kubectl是Kubernetes集群的命令行工具,通过kubectlc能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署。
1)、kubectl语法格式
kubectl [command] [TYPE] [NAME] [flage]
(1) command: 指定要对资源执行的操作, 例如: create、 get、describe 和 delete
(2) TYPE:指定资源类型,资源类型是大小写敏感的,开发都能够以单数,复数和缩略的形式。例如:
kubectl get pod pod1
kubectl get pods pod1
kubectl get po pod1
kubectl apple -f
(3) NAME: 指定资源的名称,名称也大小写敏感。如果省略名称,则会显示所有的资源。
帮助命令:

kubectl --help
具体查看某个操作
kubectl get --help
2)、kubectl子命令
| 基础命令 | |
|---|---|
| create | 通过文件名或标准办输入创建资源 |
| expose | 将一个资源公开为一个新的Service |
| run | 在集群中运行一个特定的镜像 |
| set | 在对象上设置特定的镜像 |
| get | 显示一个或多个资源 |
| explain | 文档参考资料 |
| edit | 使用默认的编辑器编辑一个资源 |
| delete | 通过文件名、标准输入、资源名称或标签选择器来删除资源 |
| 部署命令 | |
| rollout | 管理资源的发布 |
| rolling-update | 对给定的复制控制器滚动更新 |
| scale | 扩容或缩容Pod数时,Deployment、ReplicaSet、RC或Job |
| autoacale | 创建一个自动选择扩容或缩容并设置Pod数量 |
| 集群管理命令 | |
| certificate | 修改证书资源 |
| cluster-info | 显示集群信息 |
| top | 显示资源(CPU/Memory/Storage)使用。需要Heapster运行 |
| cordon | 标记节点不可调度 |
| uncordon | 标记节点可调度 |
| drain | 驱逐节点上的应用,准备下线维护 |
| taint | 修改节点taint标记 |
| 故障诊断和调试命令 | |
| describe | 显示特定资源或资源组的详细信息 |
| logs | 在一个Pod中打印一个容器日志,如果Pod只有一个容器,容器名称是可选的 |
| attach | 附加到一个运行的容器 |
| exec | 执行命令到容器 |
| port-forward | 转发一个或多个本地端口到一个pod |
| proxy | 运行一个proxy到Kubernetes API server |
| cp | 拷贝文件或目录到容器中 |
| auth | 检查授权 |
| 高级命令 | |
| apply | 通过文件名或标准输入对资源应用配置 |
| patch | 使用补丁修改、更新资源的字段 |
| replace | 通过文件名或标准输入替换一个资源 |
| convert | 不同的API版本之间转换配置文件 |
| 设置命令 | |
|---|---|
| label | 更新资源上的标签 |
| annotate | 更新资源上的注解 |
| completion | 用于实现kubectl工具自动补全 |
| 其他命令 | |
| api-versions | 打印受支持的API版本 |
| config | 修改kubeconfig文件(用于访问API, 比如配置认证信息) |
| help | 所用命令帮助 |
| plugin | 运行一个命令行插件 |
| version | 打印客户端和服务版本信息 |
3)、yaml文件详解
资源清单文件
(1) 资源编排
1.语法格式
* 通过缩进表示层级关系 * 不能使用Tab进行缩进,只能使用空格 * 一般开头缩进两个空格 * 字符后缩进一个空格,比哪冒号,逗号等后面 * 使用---表示新的yml文件开始 * 使用#代表注释
2.ymal文件组成部分
(1)控制器有定义
(2)被控制对象
3. 常用字段含义

(2)、如何快速编写yaml文件
第一种 使用kubectl create 命令生成yaml文件
kubectl create deployment web --image=nginx -o yaml --dry-run > my.yaml
第二种 使用kubectl get 命令导出yaml文件
kubectl get deploy kubectl get deploy nginx -o=yaml --export > my2.yaml
2. Pod
Pod是k8s系统中可以创建和管理的最小单元,是资源对象模型中由用户创建或部署的最小资源对象模型,也是在k8s上运行容器化应用的资源对象,其他的资源对象都是用来支撑或者扩展Pod对象功能的,比如控制器对象是用来管控Pod对象的,Service或者Ingress资源对象是用来暴露Pod引用对象的, PresistentVolume资源对象是用来为Pod提供存储等等,k8s不会直接处理容器,而是Pod, Pod是由一个或多个container组成.
Pod是Kubernetes的最重要概念,每一个Pod都有一个特殊的被称为"根容器"的Pause容器。Pause容器对应的镜像属于Kubernetes平台的一部分,除了Pause容器,每个Pod还包含一个或多个紧密相关的用户业务容器。
1)、Pod基本概念
(1) 最小部署的单元
(2) 包含多个容器(一组容器的集合)
(3)一个pod中容器共享网络命名空间
(4)pod是短暂的
2)、Pod存在意义
(1) 创建容器使用docker, 一个docker对应一个容器,一个容器,有进程,一个容器运行一个应用程序。
(2) Pod是多进程设计,运行多个应用程序
一个Pod有多个容器,一个容器里面运行一个应用程序
(3) Pod存在为了亲密性应用
两个应用之间进行交互
网络之间调用
两个应用需要频繁调用
3)、Pod实现机制
容器使用docker实现, 容器本身之间相互隔离的, namespace, group 进行隔离
(1) 共享网络
通过根容器pause,把其他业务容器加入到Pause容器里,让所有业务容器在同一个名称空间中,可以实现网络 共享
(2)共享存储
共享存储:引入数据卷概念Volumn,使用数据卷进行持久华存储
4)、Pod镜像拉取策略
imagePullPolicy有三种策略:
IfNotPresent: 默认值,镜像在宿主机上不存在时才拉取
Always: 每次创建Pod都会重新拉取一次镜像
Never: Pod永远不会主动拉取这个镜像
5)、Pod资源限制
Pod和Container的资源请求和限制:
spec.containers[].resources.limits.cpu
spec.containers[].resources.limits.memory
spec.containers[].resources.requests.cpu
spec.containers[].resources.requests.memory
6)、Pod重启策略
restartPolicy的参数:
Always: 当容器终止退出后, 总是重启容器,默认策略
OnFailure: 当容器异常退出(退出状态码非0)时,才重启容器
Never: 当容器终止退出,从不重启容器
7)、容器健康检查
livenessProbe(存活检查)
如查检查失败, 将杀死容器, 根据Pod的restartPolicy来操作。
readinessProbe(就绪检查)
如果检查失败,Kubernetes会把Pod从service endpoints中易除。
Probe支持以下三种检查方法
httpGet: 发送HTTP请求, 返回200 - 400 范围状态码为成功。
exec: 执行Shell命令返回状态码是0为成功
tcpSocket: 发起 TCP Socket建立成功
创建Pod流程


createpod -- apiserver --etcd
scheduler -- apiserver--etcd -- 调度复法,把pod调度某个node节点上
node(节点)
kubectl -- apiserver --读取etcd拿到分配给当前节点opod, --docker创建容器
8)、影响Pod调度
1、Pod 资源限制对Pod调用产生影响
影响调度的属性: request.memory request.cpu
根据request找到足够node节点进行调度.
2、节点选择器标签影响Pod调度
sped.nodeSelector. env_role:dev
3、节点亲和性影响Pod调度
节点亲和性 nodeAffinity和之前nodeSelector基本一样的,根据节点上标签约束来绝对Pod调度到哪些节点上
(1) 硬亲和性
约束条件必须满足
(2)软亲和性
尝试满足, 不保证
支持常用操作符 In, NotIn Exists Gt Lt DoesNotExists
4、污点和污点容忍
1、基本介绍
nodeSelector和nodeAffinity: Pod调度到某些节点上, Pod属性,调度时候实现.
Taint污点: 节点不做普通分配调度,是节点属性
2、场景
专用节点
配置特点硬件节点
基于Taint驱逐
3、具体演示
(1) 查看节点污点情况
kubectl describe node master | grep Taint

污点值有三个
NoSchedule: 一定不被调度
PreferNoSechdule: 尽量不被调度
NoExecute: 不会调度, 并且还会驱逐Node已有Pod
(2) 为节点添加污点
kubectl taint nodw [node] key=value: 污点三个值
(3)删除污点
kubectl taint node node1 env_role:NoSchedule
(4)污点容忍
3. controller
确保预期的pod副本数量
无状态应用部署
有施状态应用部署
确保所有的node运行同一个pod
一次性任务和定时任务
1)、什么是controller
在集群上管理和运行容器的对象
2)、Pod和Controller关系
Pod是通过Controller实现应用的运维
比如伸缩,滚动升级等等
Pod和Controller之间通过label标签建立关系
selector
3)、deployment应用场景
部署无状态应用,
管理Pod和ReplicaSet
部署,滚动升级等功能
应用场景: web服务, 微服务
4)、使用deployment部署应用(yaml)
第一步: 导出 yaml文件
kubectl create deployment web --image=nginx --dry-run -o yaml > web2.yaml

第二步:使用yaml 部署应用
kubectl apply -f web2.yaml kubectl get pods
第三步:对外发布(暴露对外端口号)
kubectl expose --help 查看帮助
kubectl expose deployment web --port=80 --type=NodePort --target-port=80 --name=web3 -o yaml> web3.yaml
kubectl get pods,svc
5)、应用升级回滚和弹性收缩
kubectl delete pods --allkubectl apply -f web1.yaml #应用升级 kubectl set image deployment web nginx=nginx:1.15 #查看升级状态 kubectl rollout status deployment web#查看升级版本 kubectl rollout history deployment web#回泫到上一个版本 kubectl rollout undo deployment web#回滚到指定版本 kubectl rollout undo deployment web --to-revision=1# 弹性升缩 kubectl scale deployment web --replicas=10

附: 缩扩容&更新(k8s学习笔记:缩扩容&更新_horizontal-pod-autoscaler-use-rest-clients-CSDN博客)
1. 前言
自动缩扩容是现代化的容器调度平台带给我们的最激动人心的一项能力。在上规模的业务系统中我们无时无刻不面临着这样的难题:用户的流量往往随着时间波动,甚至偶尔出现不可预测的峰值(毛刺流量),每当流量增加时都需要手工的对应用进行扩容,峰值流量消失后又需要将扩容的机器回收,运维起来费时费力。
幸运的是,k8s这样的容器调度平台正在逐渐帮助我们解决这样的问题,它带来的AutoScaler功能目前已经支持在多个不同维度上的弹性缩扩容,可以根据应用的负载情况进行自适应。尽管在一些较为苛刻的场景下,由于容器启动速度等原因的限制,AutoScaler的效果还不尽人意,但相信在不久的将来,自动缩扩容方案将会完全成熟,届时我们将轻松获取具有强大弹性能力的服务集群。
现在来试着使用一下k8s的Scale相关功能吧。
2. 手动调整服务规模
我们可以使用kubectl提供的命令来手动调整某个Deployment的规模,也就是其包含的Pod数量,这里拿上一节里创建的HelloWorld服务来作为例子,当前的deployment状态如下: 
-
DISIRED表示配置时声明的期望副本数 -
CURRENT表示当前正在运行的副本数 -
UP-TO-DATE表示符合预期状态的副本数(比如某个副本宕机了,这里就不会计算那个副本) -
AVAILABLE表示目前可用的副本数
我们可以使用kubectl scale命令来手动调整deployment的规模,现在尝试把helloworld服务的副本数量扩充到4个:
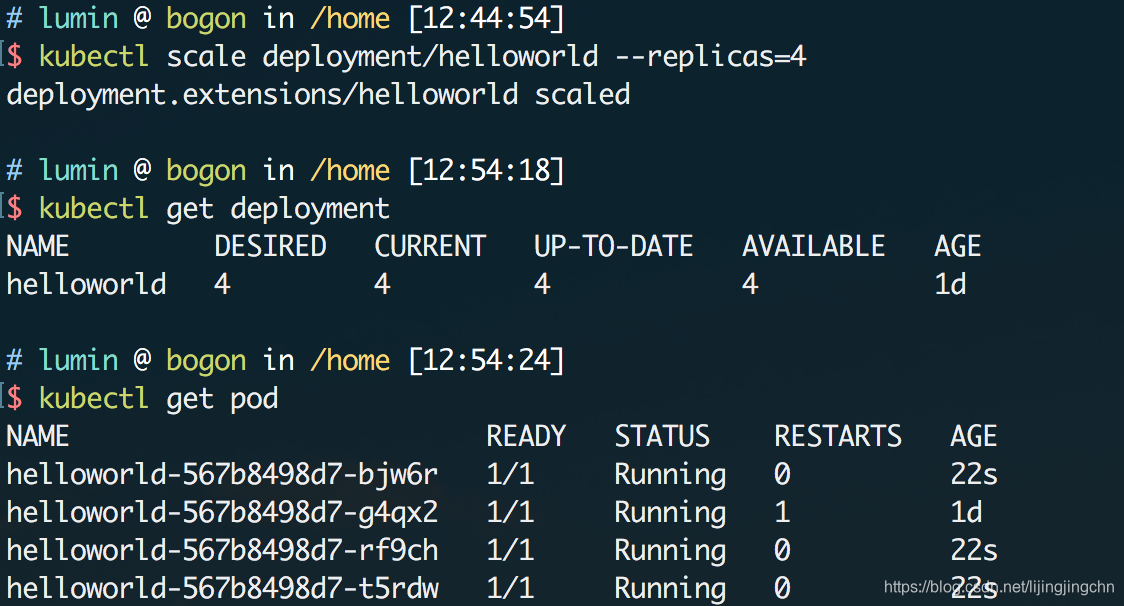
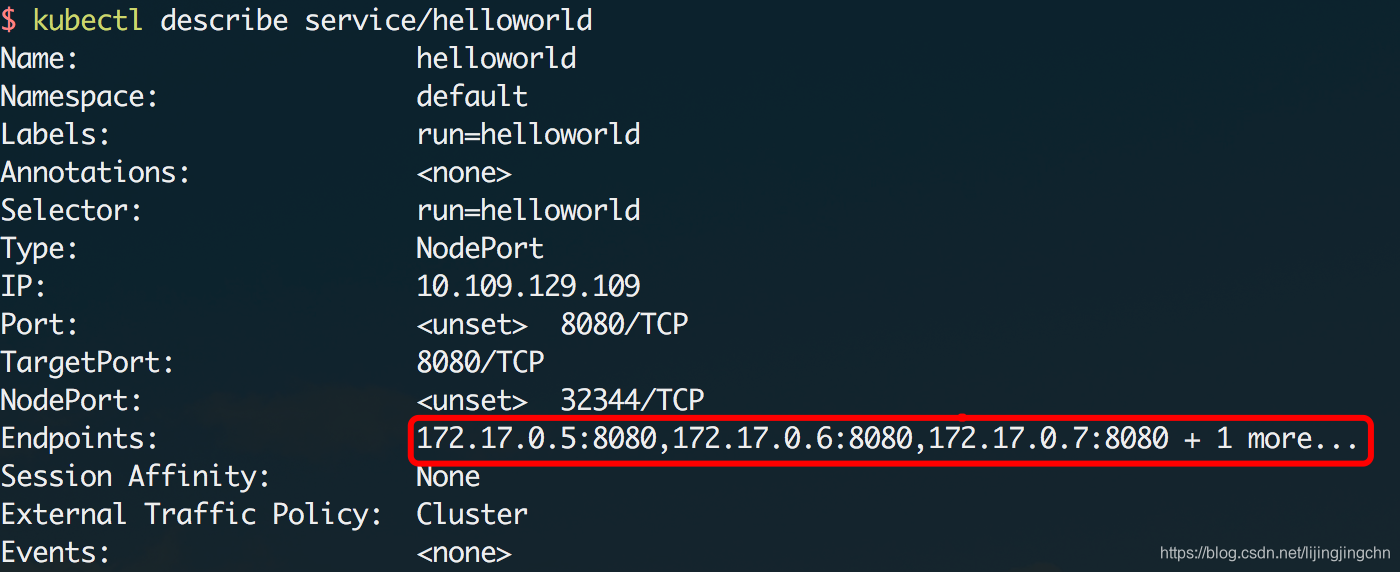
执行命令后,k8s很快就为我们创建了另外3个helloworld的副本,这时候整个服务就有多个实例在运行了,那么对应Service的负载均衡功能便会生效,可以看到Service的状态里已经侦测到多个EndPoint:
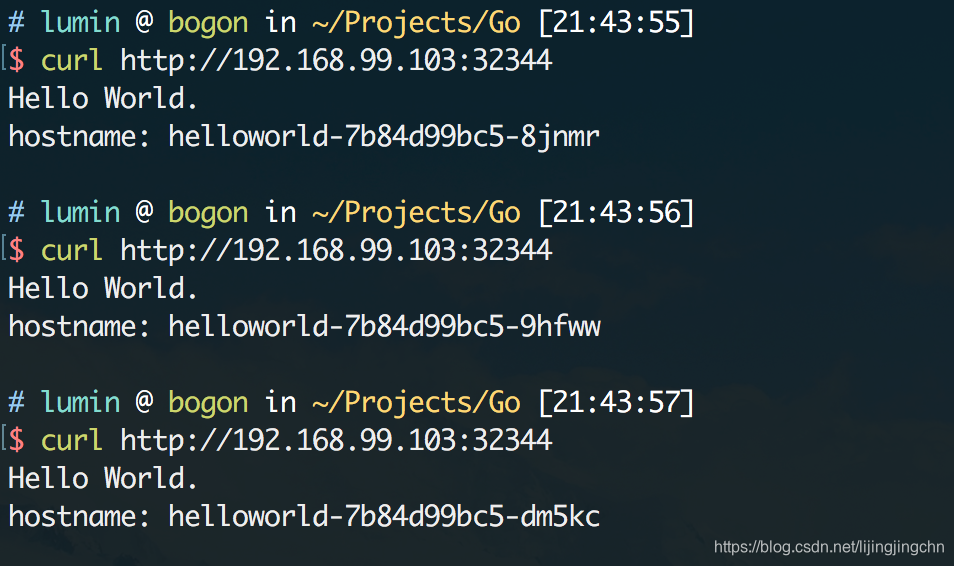
当我们连续调用service时,可以看到每次实际调用的pod都不同(这里对服务的源码做了一些修改,打印出了hostname):
同理,我们也可以用同样的方式把服务缩容,比如把副本集的数量下调到两个:
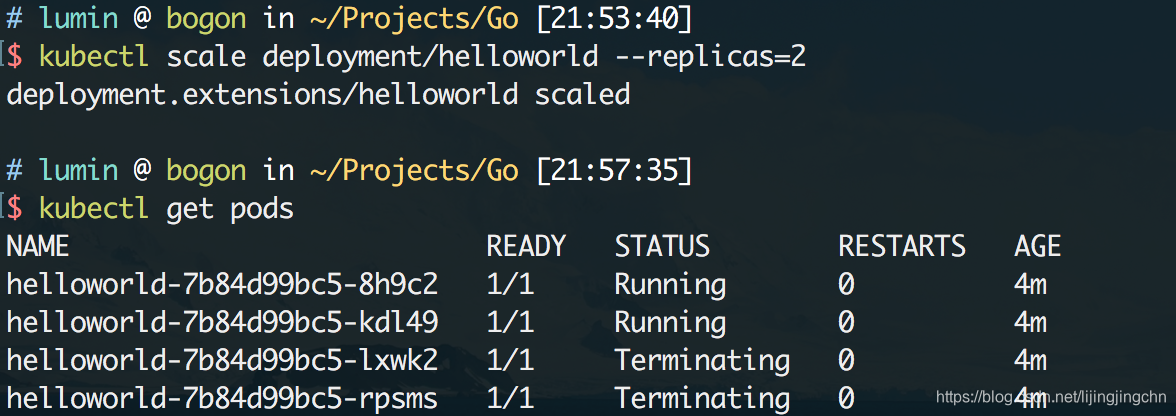
3. 自动缩扩容:极致弹性?
参考好文
刚才的例子中,我们是通过命令行的方式来手动调整服务规模的,显然在面对线上真实流量时是不能这么做的,我们希望调度平台能够根据服务的负载来智能地调控规模,进行弹性缩扩容。这时候就轮到k8s中的AutoScaler出场了。
到目前为止,k8s一共提供了3个不同维度的AutoScaler,如下图:

k8s把弹性伸缩分为两类:
-
资源维度:保障集群资源池大小满足整体规划,当集群内的资源不足以支撑产出新的pod时,就会触发边界进行扩容
-
应用维度:保障应用的负载处在预期的容量规划内
对应两种伸缩策略:
-
水平伸缩
-
集群维度:自动调整资源池规模(新增/删除Worker节点)
-
Pod维度:自动调整Pod的副本集数量
-
-
垂直伸缩
-
集群维度:不支持
-
Pod维度:自动调整应用的资源分配(增大/减少pod的cpu、内存占用)
-
其中最为成熟也是最为常用的伸缩策略就是HPA(水平Pod伸缩),所以下面以它为例来重点分析,官方文档在此:kubernetes.io/docs/tasks/…
3.1 基本流程
任何弹性系统的缩扩容都无外乎于以下几个步骤:
-
采集监控指标
-
聚合监控指标,判断是否需要执行缩扩容
-
执行缩扩容动作
下面就按照这个顺序来分析HPA的工作方式,这里先给出一个HPA大体的架构图:
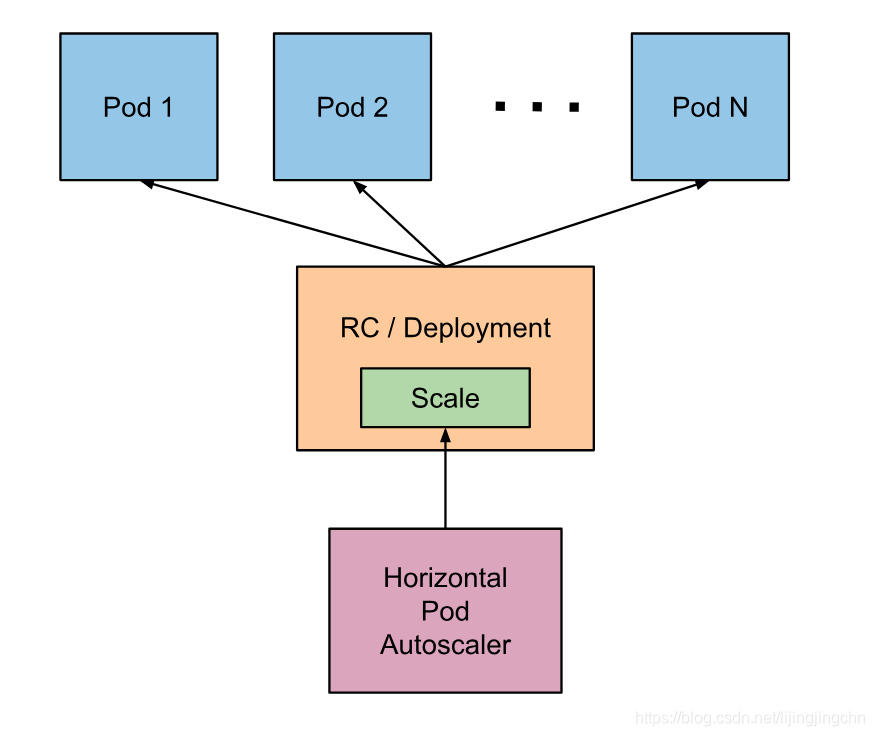
3.2 监控指标
根据官方文档的描述,HPA是使用巡检(Control Loop)的机制来采集Pod资源使用情况的,默认采集间隔为15s,可以通过Controller Manager(Master节点上的一个进程)的–horizontal-pod-autoscaler-sync-period参数来手动控制。
目前HPA默认采集指标的实现是Heapster,它主要采集CPU的使用率;beta版本也支持自定义的监控指标采集,但尚不稳定,不推荐使用。
因此可以简单认为,HPA就是通过CPU的使用率作为监控指标的。
3.3 聚合算法
采集到CPU指标后,k8s通过下面的公式来判断需要扩容多少个pod:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )] 1
复制代码ceil表示向上取整,举个实际例子,假设某个服务运行了4个Pod,当前的CPU使用率为50%,预期的CPU使用率为25%,那么满足预期的实际Pod数量就是4 * (50% / 25%) = 8个,即需要将Pod容量扩大一倍,增加4个Pod来满足需求。
当然上述的指标并不是绝对精确的,首先,k8s会尽可能的让指标往期望值靠近,而不是完全相等,其次HPA设置了一个容忍度(tolerance)的概念,允许指标在一定范围内偏离期望值,默认是0.1,这就意味着如果你设置调度策略为CPU预期使用率 = 50%,实际的调度策略会是小于45%或者大于55%进行缩扩容,HPA会尽力把指标控制在这个范围内(容忍度可以通过–horizontal-pod-autoscaler-tolerance来调整)。
另外有两点需要说明的细节:
-
k8s做出决策的间隔,它不会连续地执行扩缩容动作,而是存在一定的
cd,目前扩容动作的cd为3分钟,缩容则为5分钟。 -
k8s针对扩容做了一个最大限制,每次扩容的pod数量不会大于当前副本数量的2倍。
3.4 HPA实践
最后我们来尝试实际使用一下HPA,依然是使用kubectl命令行的方式来创建:
kubectl autoscale deployment helloworld --cpu-percent=10 --min=1 --max=5 1
复制代码运行上面的命令后,可以在dashboard看到HPA已经被创建,策略是以CPU使用率10%为临界值,最少副本集数量为1,最大为5:

使用kubectl get hpa也可以看到:

但是这里出现了异常,targets的当前CPU使用率始终显示为unknown,网上说是因为副本集里没有配置resources导致的。我们需要在dashboard里找到对应的副本集,然后在spec.containers.resources里声明requests和limits值:

其中requests表示pod所需要分配的资源配额,limits表示单个pod最大能够获取到的资源配额。
配置完之后还是没有出现指标,继续百度,发现没有安装heapster支持,那就安装,具体方法可见此文,注意需要把国外gcr的镜像通过阿里云代理一把才能安装(如果你不太会搞,可以用我转好的,见github),influxDB,grafana和heapster三个组件都装好后,记得再装一把heapster rbac(在kubeconfig/rbac目录下),最后重启一波minikube,打开控制台,可以看到节点页面已经有了指标图像:
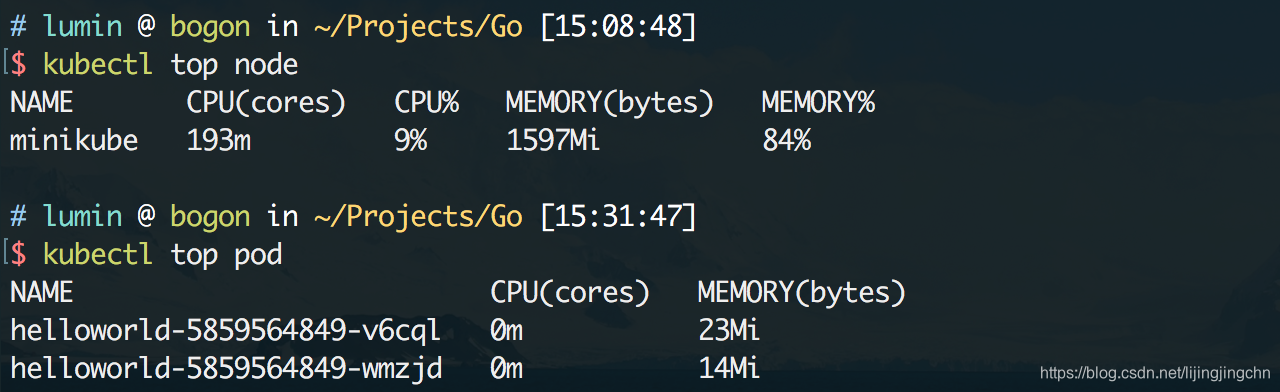
kubectl top命令也能正常返回数值了:
然而,kubectl get hpa显示cpu的当前指标还是unknown,郁闷,进到deployment里看一把日志:
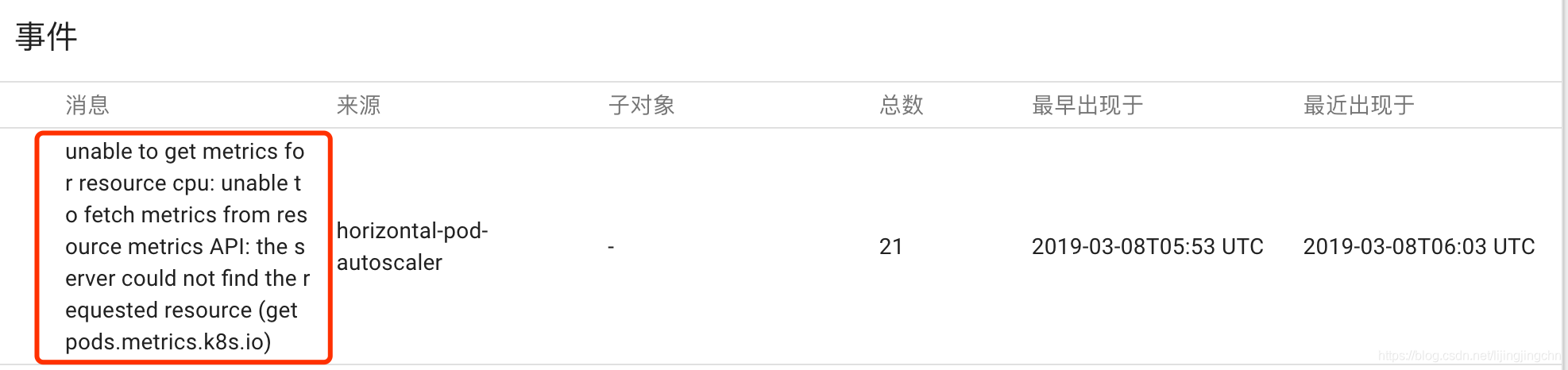
可以看到HPA一直在报无法从metrics API获取请求资源的错误,github走一波,找到一个类似的issue,原因是1.9版本以后的k8s默认的监控指标来源从heapster变成了metrics-server(我用的1.0,坑),不过要再安装一套metrics-server实在太麻烦了,可以通过修改kube-controller-manager的启动参数来禁用这个新特性。 minikube ssh进入到vm内部,然后找到/etc/kubernetes/manifests/kube-controller-manager.yaml这个文件,在启动参数里加上–horizontal-pod-autoscaler-use-rest-clients=false,这时候对应的容器组会自动重启更新,再执行kubectl get hpa,可以看到cpu的指标终于Ok了:
 留下了感动的泪水,终于可以开始压测试水了,赶紧搞个
留下了感动的泪水,终于可以开始压测试水了,赶紧搞个buzybox压起来:
kubectl run -i --tty load-generator --image=busybox /bin/sh 1
写个循环去访问我们的helloworld服务(为了更快的出效果,我把服务的scale缩减到只有一个副本集,直接压这个pod的ip)
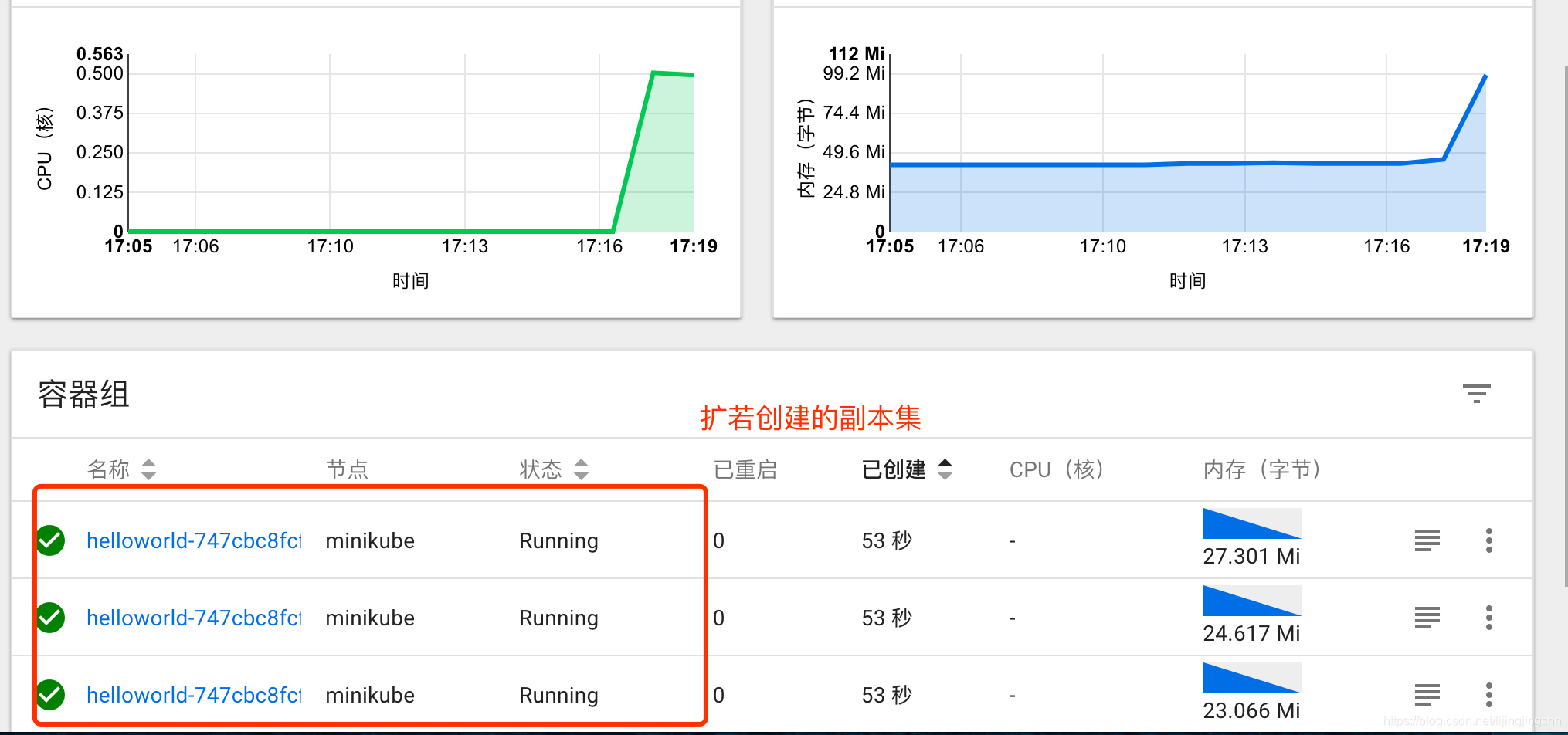
/ # while true; do wget -q -O- http://172.17.0.5:8080; done 1
大概2,3分钟后就能看到结果,此时查看hpa的状态,可以看到已经触发水平扩容,副本集的数量由1个追加到4个:

dashboard上也能看到效果:
关掉压测脚本,静置一会儿,再看HPA的状态:
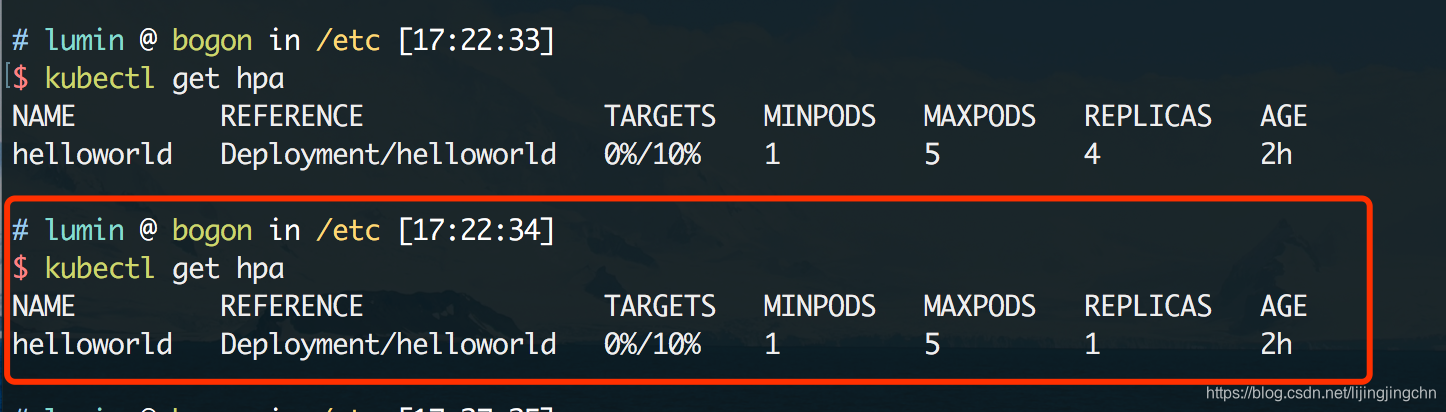
自动缩容到了1个副本集,那么HPA的实践使用到这里就算是结束了。
4. 更新、发布、回滚
服务代码必然是会经常修改的,当代码发生变动时,就需要重新打包生成镜像,然后进行发布和部署,来看看在k8s中是如何对这些步骤进行处理的。
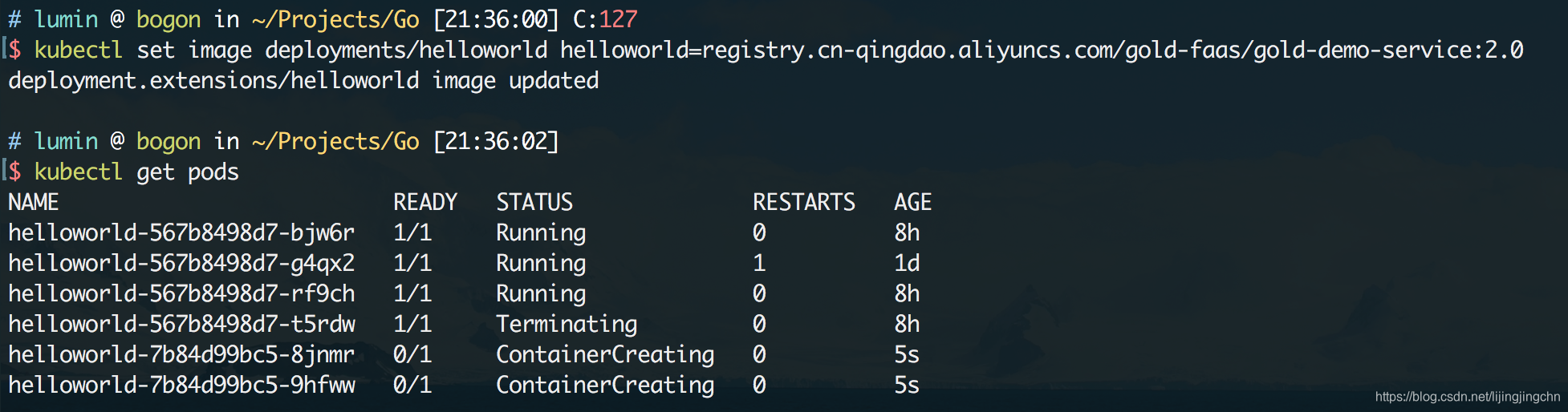
现在我们对代码做了一些改动,加上了hostname的输出,然后打包形成了一个2.0版本的新镜像,下面需要把这个新版本的镜像部署到k8s的容器集群上,使用kubectl set image在deployment上指定新的镜像:
kubectl set image deployments/helloworld helloworld=registry.cn-qingdao.aliyuncs.com/gold-faas/gold-demo-service:2.0 1
执行该命令后,可以从kubectl和dashboard中看到,新的容器组正在被创建,同时旧的容器组也在被回收:
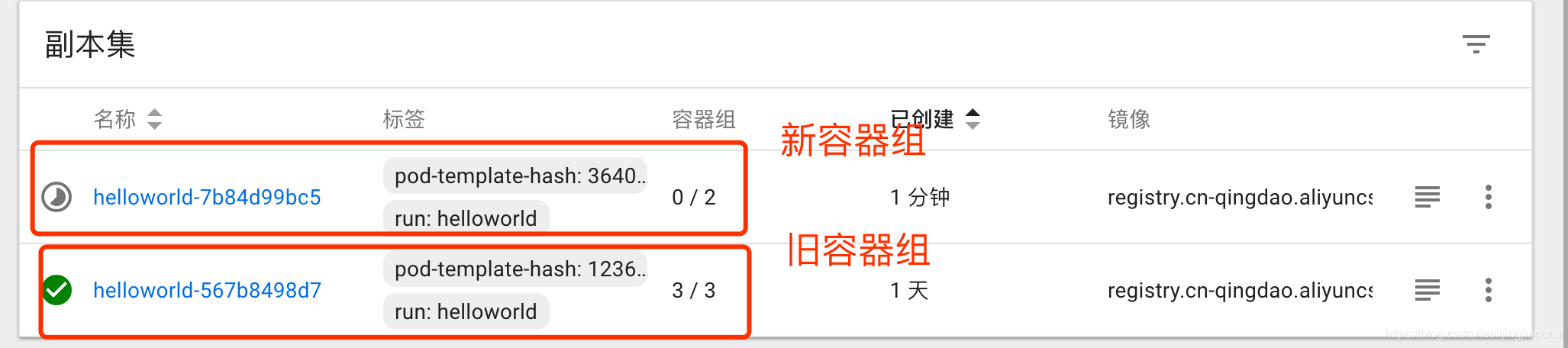
最终所有的旧版本pod都会被回收,只留下新发布版本的容器组副本集:
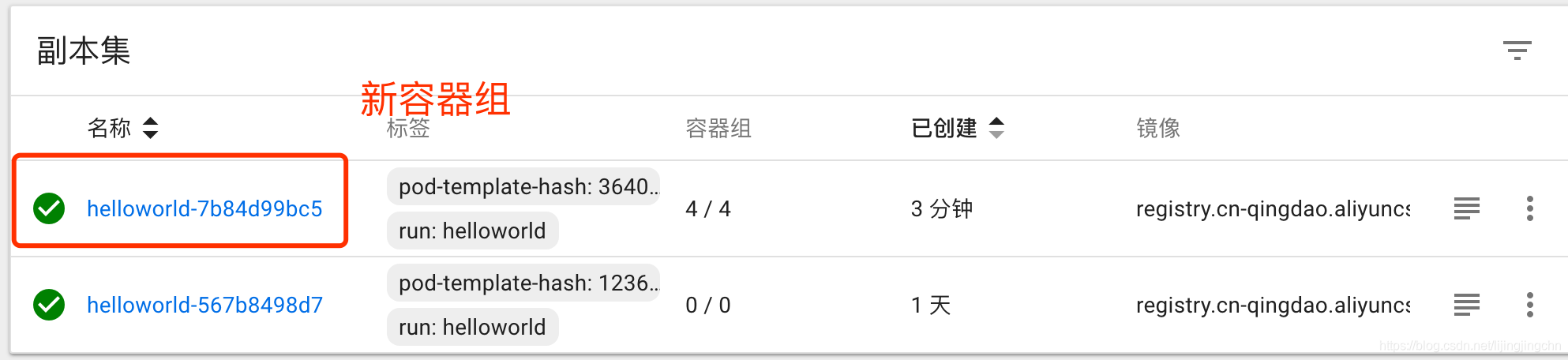
来测试一下服务是否更新:

假设我们的发布到线上的版本出现了致命的问题,需要紧急将服务回退到上一个版本,该怎么做呢?使用kubectl rollout undo即可,来看看效果:
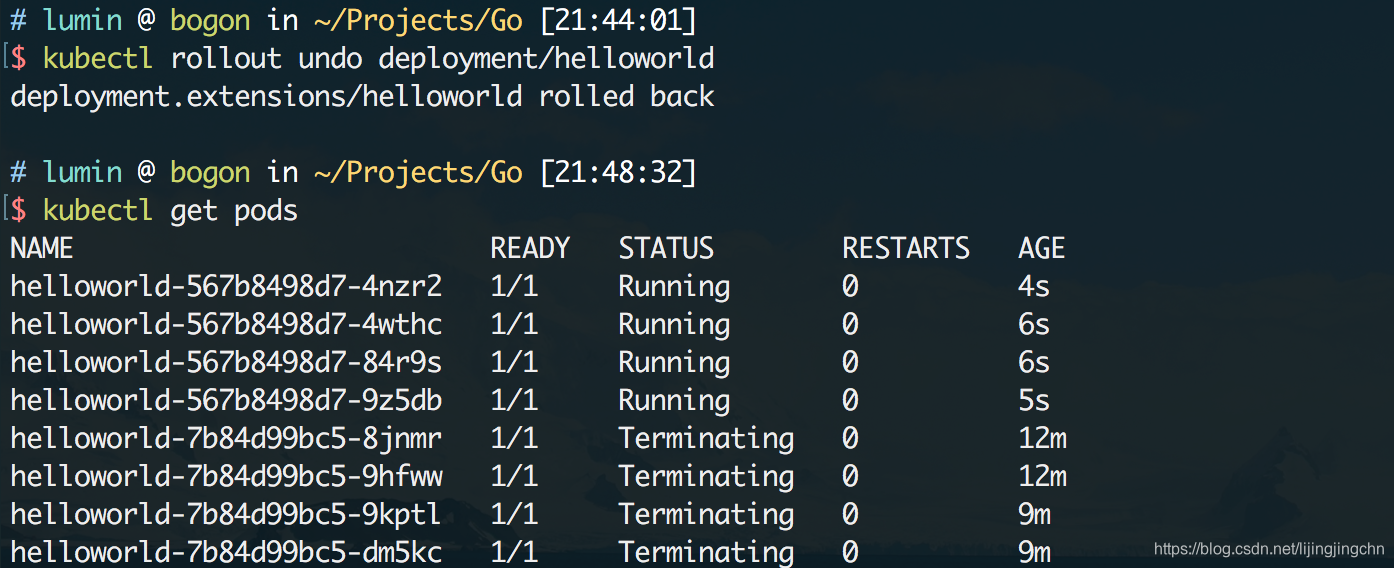
可以看到执行回滚命令后,新版本的pod开始被回收,同时上一个版本镜像所对应的pod被唤醒(这里速度非常快,我感觉k8s在发布完新服务后可能并不会立刻销毁历史版本的pod实例,而是会缓存一段时间,这样非常快速的回滚,只要把service的负载均衡指回历史版本的pod就可以了)
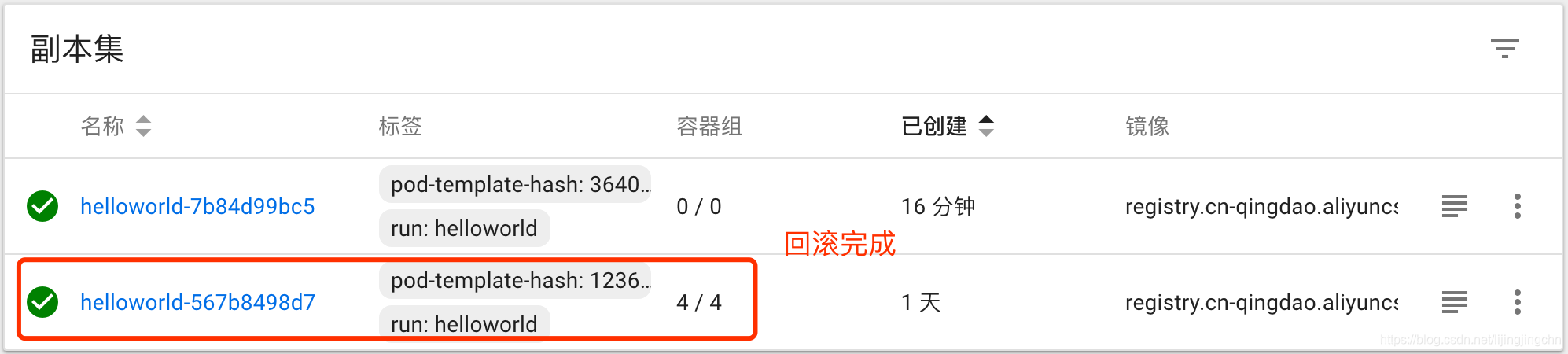
回滚完成后再度请求服务,可以发现服务已经变回了上一个版本的内容:

上面这些发布和回滚的特性在k8s中被称为滚动更新,它允许我们按照一定的比例逐步(可以手工设置百分比)更新pod,从而实现平滑的更新和回滚,也可以借此实现类似蓝绿发布和金丝雀发布的功能。
5. 小结
通过实际操作体验了k8s的缩扩容以及发布机制,虽然遇到了几个坑,但整体上用起来还是非常丝滑的,到这里k8s的基本功能就探索的差不多了,从下一篇开始将会继续深入分析k8s的原理,敬请期待!
4、Service
1、service存在意义
(1)防止Pod失连(服务发现)
(2)定义一组Pod访问策略(负载均衡)


2、Pod和Service关系
根据label和selector标签建立关联
selector: app: nginx ..... labels: app:nginx

3、常用Service类型
kubectl expose --help

1)、ClusterIP: 集群内部使用
kubectl apply -f web1.yaml kubectl get pods kubectl expose deployment web --port=80 --target-port=80 --dry-run -o yaml > servicel.yaml kubectl apply -f servicel.yaml

2)、NodePort:对外访问应用使用
vi servicel.yaml


3)、LoadBalancer: 对外访问应用使用,公有云
node内网部署应用,外网一般不能访 问到的
找到一台可以进行外网访问机器,安装nginx, 反向代理
手动把可以访问节点添加到nginx里面
LoadBalancer: 公有云,负载均衡,控制器
kubectl delete svc nginx kubectl delete svc web2 web3
附: 正确删除pod
1、先删除pod 2、再删除对应的deployment 否则只是删除pod是不管用的,还会看到pod,因为deployment.yaml文件中定义了副本数量 实例如下: 删除pod 强制删除命令:kubectl delete pod pod-name -n test --force --grace-period=0 [root@test2 ~]# kubectl get pod -n jenkins NAME READY STATUS RESTARTS AGE jenkins2-8698b5449c-grbdm 1/1 Running 0 8s [root@test2 ~]# kubectl delete pod jenkins2-8698b5449c-grbdm -n jenkins pod "jenkins2-8698b5449c-grbdm" deleted 查看pod仍然存储 [root@test2 ~]# kubectl get pod -n jenkins NAME READY STATUS RESTARTS AGE jenkins2-8698b5449c-dbqqb 1/1 Running 0 8s [root@test2 ~]# 删除deployment [root@test2 ~]# kubectl get deployment -n jenkins NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE jenkins2 1 1 1 1 17h [root@test2 ~]# kubectl delete deployment jenkins2 -n jenkins 再次查看pod消失 deployment.extensions "jenkins2" deleted [root@test2 ~]# kubectl get deployment -n jenkins No resources found. [root@test2 ~]# [root@test2 ~]# kubectl get pod -n jenkins No resources found.
5、部署有状态应用
1)、无状态和有状态
1、无状态
认为Pod都是一样的
没有顺序要求
不用考虑在哪个node运行
随意进行伸缩和扩展
2、有状态
上面因素都需要考虑到
让每个pod独立的,保持pod启动顺序和唯一性
唯一的网络标识符,持久存储
有序,比如mysql主从
2)、部署有状态应用
(未完,后补)