全网没找到一个完整的翻译,用chatgpt翻译如下,可能有的地方不够准确,推荐结合原文对照着看更。
摘要
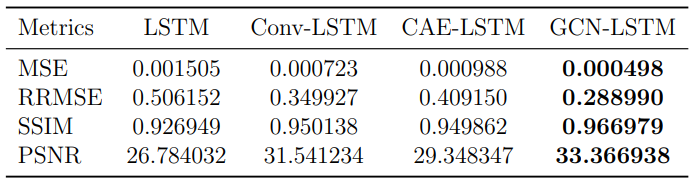
尽管基于骨架的动作识别在近年来取得了巨大的成功,但大多数现有方法可能面临模型规模庞大和执行速度缓慢的问题。为了解决这个问题,我们分析了骨架序列的特性,提出了一种双特征双运动网络(DD-Net)用于基于骨架的动作识别。通过使用轻量级网络结构(即15万参数),DD-Net能够实现超快的速度,在一台GPU上达到3500帧每秒(FPS),在一台CPU上达到2000 FPS。通过采用稳健的特征,DD-Net在我们的实验数据集上(即SHREC(手部动作)和JHMDB(身体动作))达到了最先进的性能。我们的代码可在https://github.com/fandulu/DD-Net上找到。
I. 引言
基于骨架的动作识别已广泛应用于多媒体应用中,如人机交互 [1]、人类行为理解 [2] 和医疗辅助应用 [3]。然而,大多数现有方法可能面临模型规模庞大和执行速度缓慢的问题 [4]、[5]、[6]、[7]、[8]。
在实际应用中,一个理想的基于骨架的动作识别模型应该能够高效运行,使用较少的参数,并且能够适应各种应用场景(例如,手部/身体、2D/3D骨架,以及与全局轨迹相关或无关的动作)。为了实现这个目标,我们研究了骨架序列的特性,提出了一种轻量级的双特征双运动网络(DD-Net),该网络配备了关节集合距离(JCD)特征和双尺度全局运动特征。

更具体地说,我们对四种类型的骨架序列特性进行了研究(见图1):(a) 位置-视角变化,(b) 运动尺度变化,(c) 与全局轨迹相关/无关,(4) 不相关的关节索引。为了应对这些特性所带来的挑战,以前的工作往往倾向于提出复杂的神经网络模型,最终导致模型规模庞大。
相反,我们通过简化输入特征和网络结构来解决这些挑战。我们的JCD特征包含骨架序列的位置-视角不变信息。与其他类似特征相比,它易于计算并包含较少的元素。由于全局运动无法纳入位置-视角不变特征,我们引入了双尺度全局运动特征,以提高DD-Net的泛化能力。此外,它的双尺度结构使其对运动尺度变化具有鲁棒性。通过嵌入过程,DD-Net可以自动学习关节之间的适当关联,这在通过关节索引预定义时是困难的。
与依赖复杂模型结构的方法相比,DD-Net提供了更高的动作识别准确性,并在我们的实验数据集上展示了其泛化能力。凭借其在计算复杂度和参数数量方面的高效性,DD-Net足以应用于实际应用中。
II. 相关工作
如今,随着深度学习的快速发展,骨架获取不再仅限于使用动作捕捉系统 [10] 和深度摄像头 [11]。例如,RGB数据可以用于实时推断2D骨架 [12]、[13] 或3D骨架 [14]、[15]。此外,甚至WiFi信号也可以用于估计骨架数据 [16]、[17]。这些成就使得基于骨架的动作识别能够应用于大量多媒体资源,从而促进了模型的发展。
一般来说,为了实现基于骨架的动作识别的更好性能,以前的研究主要关注两个方面:为骨架序列引入新特征 [18]、[19]、[20]、[21]、[22]、[8]、[23],以及提出新颖的神经网络架构 [24]、[25]、[26]、[27]、[5]、[6]、[28]。
一个良好的骨架序列表示应包含全局运动信息,并且具有位置-视角不变性。然而,满足这两个要求的特征是具有挑战性的。研究 [19]、[21]、[8]、[23] 专注于全局运动而没有考虑特征中的位置-视角变化。相反,其他研究 [18]、[20]、[22] 引入了位置-视角不变特征,但没有考虑全局运动。我们的工作通过无缝地将位置-视角不变特征和双尺度全局运动特征结合在一起来填补它们之间的空白。
尽管循环神经网络(RNNs)在基于骨架的动作识别中被广泛使用 [29]、[30]、[31]、[32]、[33]、[22],我们认为与使用卷积神经网络(CNNs)的方法 [24]、[5]、[23] 相比,RNN相对较慢且难以进行并行计算。由于我们将模型速度作为优先考虑的因素之一,因此我们利用1D CNN构建DD-Net的主干网络。
III. 方法论
双特征双运动网络(DD-Net)的网络架构如图2所示。在下面,我们将解释我们设计DD-Net的输入特征和网络结构的动机。

A. 通过关节集合距离(JCD)建模位置-视角不变特征
在基于骨架的动作识别中,常用的两种输入特征是几何特征 [18]、[22] 和笛卡尔坐标特征 [31]、[32]、[34]、[6]、[7]。笛卡尔坐标特征对位置和视角具有变异性。如图1(a)所示,当骨架被旋转或移动时,笛卡尔坐标特征可能会发生显著变化。另一方面,几何特征(例如角度/距离)具有位置-视角不变性,因此在基于骨架的动作识别中已经被使用了一段时间。然而,现有的几何特征可能需要在不同数据集之间进行大量重新设计 [18]、[22],或者包含冗余元素 [33]。为了解决这些问题,我们引入了关节集合距离(JCD)特征。
我们计算一对集合关节之间的欧几里得距离,以获得一个对称矩阵。为了减少冗余,仅使用不带对角线的下三角矩阵作为JCD特征(见图3)。因此,JCD特征的大小不到 [33] 的一半。




IV. 实验
A. 实验数据集
我们选择了两个基于骨架的动作识别数据集,即SHREC数据集和JHMDB数据集,以从不同角度评估我们的DD-Net(见表I)。尽管有其他信息(例如RGB数据),但我们的实验仅使用骨架信息。SHREC数据集提供的3D骨架源自RGB-D数据,并包含更多的空间信息。而JHMDB数据集中的2D骨架是从RGB视频中推断得出的,可以应用于推断深度信息可能困难或不可能的更一般的情况。此外,SHREC数据集中的动作与受试者的全局轨迹紧密相关(例如,手划出“V”形),而JHMDB数据集与全局轨迹的关联可能较弱。我们展示了这些属性如何影响性能,并在消融研究中证明了DD-Net的通用性。

B. 评估设置
SHREC数据集在两种情况下进行评估:14种手势和28种手势。JHMDB数据集通过使用手动标注的骨架进行评估,我们对来自三个训练/测试集的结果进行平均。在消融研究中,我们通过移除一个组件而保持其他组件不变,探索每个DD-Net组件对动作识别性能的贡献。此外,我们还探索了通过调整图2中滤波器的值,模型大小对性能的影响。
C. 实现细节
由于DD-Net体积较小,可以将所有训练集放入单个GTX 1080Ti GPU的一个批次中。我们选择Adam优化器(β₁ = 0.9,β₂ = 0.999),采用学习率从1e-3降至1e-5的退火策略。在训练期间,DD-Net仅进行时间增强,随机选择全部帧的90%。为了展示DD-Net的优越性,我们没有应用任何集成策略或预训练权重来提升性能。为了使DD-Net能够轻松部署到实际应用中,我们在TensorFlow的Keras后端实现了它,后者因其执行速度较慢而“臭名昭著”。使用其他神经网络框架可能会使DD-Net更快。
D. 结果分析与讨论
SHREC数据集的动作识别结果见表II,更多细节在其混淆矩阵中列出。14个动作和28个动作的混淆矩阵分别是图4和图5。JHMDB数据集的动作识别结果见表III。

总体而言,尽管DD-Net参数较少,但在SHREC数据集和JHMDB数据集上都能取得优异的结果。混淆矩阵还表明,DD-Net对每个动作类别都很稳健。尽管数据属性存在差异,DD-Net展示了其泛化能力,这表明它可以适应广泛的基于骨架的动作识别场景。
从消融研究中,我们可以观察到,当动作与全局轨迹紧密相关时(例如,SHREC数据集),仅使用JCD特征无法产生令人满意的性能。而当动作与全局轨迹不紧密相关时(例如,JHMDB数据集),全局运动特征仍然有助于提高性能,但不如前一种情况显著。这些结果与我们的假设一致:尽管JCD特征是位置-视角不变的,但它与全局运动是孤立的。结果还表明,使用双尺度运动特征的分类准确率高于仅使用单尺度运动特征,这表明我们提出的双尺度全局运动特征对运动尺度变化更具鲁棒性。
在相同组件下,DD-Net可以通过修改卷积层中的滤波器值来调整其模型大小。我们选择64、32和16作为滤波器的值进行实验。当DD-Net在SHREC和JHMDB数据集上达到最佳性能时,滤波器的值为64。值得注意的是,DD-Net仅使用15万参数即可生成可比的结果。


此外,由于DD-Net采用一维CNN提取特征,其速度远快于其他使用RNN或2D/3D CNN的模型。在推理期间,DD-Net的速度可以在一块GPU(即GTX 1080Ti)上达到约3500 FPS,或在一台CPU(即Intel E5-2620)上达到2000 FPS。而基于RNN的模型在并行处理方面面临巨大挑战(由于序列依赖),我们的DD-Net则没有这个问题,因为使用的是CNN。因此,无论是低计算(例如,在小设备上)还是高计算应用(例如,在并行计算站上),我们的DD-Net都享有显著的优势。
V. 结论
通过分析骨架序列的基本属性,我们提出了两种特征和一个用于高效骨架动作识别的DD-Net。尽管DD-Net只包含少量参数,但在我们的实验数据集上可以实现最先进的性能。由于DD-Net的简单性,存在许多可能性来增强/扩展它以进行更广泛的研究。例如,可以通过修改帧采样策略来处理在线动作识别;可以使用RGB数据或深度数据进一步提高动作识别性能;也可以通过添加与时间分割相关的模块将其扩展到时间动作检测中。