论文链接:Segment Anything in 3D with Radiance Fields
代码链接:GitHub - Jumpat/SegmentAnythingin3D: Segment Anything in 3D with NeRFs (NeurIPS 2023)
作者:Jiazhong Cen, Jiemin Fang, Zanwei Zhou, Chen Yang, Lingxi Xie, Xiaopeng Zhang, Wei Shen, Qi Tian
发表单位:上海交通大学、华为公司、华中科技大学启蒙学院 .
会议/期刊:NeurIPS 2023
一、研究背景
计算机视觉领域一直在追求一个可以在任何场景下执行基本任务(如分割)的视觉基础模型。在这些研究中,Segment Anything Model (SAM) 是代表性工作之一,因为它在2D图像中的分割表现非常出色。然而,将SAM的能力扩展到3D场景仍然是一个未解决的难题。作者指出,尽管可以复用SAM的管道来采集和半自动注释大量3D场景数据,但由于3D数据的获取和密集注释远比2D复杂,采用这种数据驱动的方法变得不切实际。
获取并标注3D数据集的复杂性导致3D场景中数据稀缺,同时训练3D模型的计算开销大。这使得在3D场景中使用类似于SAM的分割模型成为一项巨大的挑战。传统的做法可能是从零开始建立一个3D基础模型,但这并不经济。
论文的作者意识到一个替代且高效的解决方案:通过3D表示模型为2D基础模型(即SAM)提供3D感知能力,而不是从头开始构建3D基础模型。为此,他们借鉴了辐射场(Radiance Fields)的理念,提出了一个名为Segment Anything in 3D (SA3D) 的新方法。
辐射场模型作为一种新颖的3D表示方式,通过可微渲染技术将多视图的2D图像与3D空间连接起来。该研究提出将SAM与辐射场整合,以促进3D分割。
论文的主要贡献总结如下:
-
提出了SA3D框架:该框架是一个创新性的3D分割方法,结合了2D分割基础模型Segment Anything Model (SAM)与辐射场模型(如NeRF和3D Gaussian Splatting),无需重新设计或重新训练即可执行3D分割任务。SA3D通过2D分割模型的扩展,提供了一种高效的方式,将2D图像信息提升到3D场景中,实现准确的3D分割。
-
设计了掩码逆向渲染和自提示机制:该方法包含两大核心步骤:掩码逆向渲染用于将2D分割结果投影到3D空间,自提示机制通过在不同视角下生成可靠的提示点,进一步优化分割结果。这一双重过程不断迭代,最终生成精准的3D掩码。
-
引入了特征缓存机制:为了加快推理速度,SA3D引入了特征缓存机制,通过预缓存SAM提取的特征显著提升了分割速度,特别是在高效表示如3D Gaussian Splatting的场景下,可将分割速度缩短至2秒内。
-
适应不同类型的辐射场:论文中展示了SA3D在不同类型的辐射场下的适应能力,证明了该方法的通用性,能够处理从前向视角到360度全景场景的多种复杂场景。
-
扩展了实验评估:论文提供了大量实验结果,包括消融研究和对各组件的深入分析,进一步展示了SA3D在不同场景和数据集上的表现,验证了该方法的有效性和高效性。

给定一个预先训练的辐射场,SA3D会从一个将单个渲染视图作为输入,并输出3D分割结果针对特定目标。
二、预备知识总结
2.1 神经辐射场(NeRF)
NeRF(Neural Radiance Fields)是用于表示3D场景的连续函数,通过多层感知机(MLP)将空间坐标 和视角方向
映射到相应位置的颜色
和体积密度
。渲染图像时,NeRF通过光线投射技术生成每个像素点的颜色,公式如下:
其中,权重 表示在射线路径 r(t)上的透明度和体积密度的综合效果,公式如下:
其中 tn 和 t 分别为光线的近界和远界。
2.2 3D Gaussian Splatting (3D-GS)
3D Gaussian Splatting 是辐射场的一个最新发展。与NeRF不同,3D-GS不通过函数映射来渲染,而是采用一组3D高斯分布来保存渲染所需的颜色和不透明度等属性。对于每条光线 r,它通过叠加多个3D高斯分布来计算最终的颜色,公式如下:
其中 ωgi 为高斯分布的权重,cgi 为每个高斯分布的颜色值。高斯分布的引入以及光栅化算法的使用,使得3D-GS避免了在空白区域查询,极大提升了渲染和训练速度。
2.3 Segment Anything Model (SAM)
SAM模型采用了编码器-解码器架构,首先通过编码器提取图像的特征,然后结合输入的提示信息(如点、框、文本等)生成相应的2D分割掩码。
编码器 Se:给定图像 I,编码器生成对应的特征 fI:
解码器Sd:结合特征 fI和提示信息 P,生成2D分割掩码 M SAM:
相比之下,编码器在计算上的开销较大,而解码器则相对轻量化。
三、整体框架
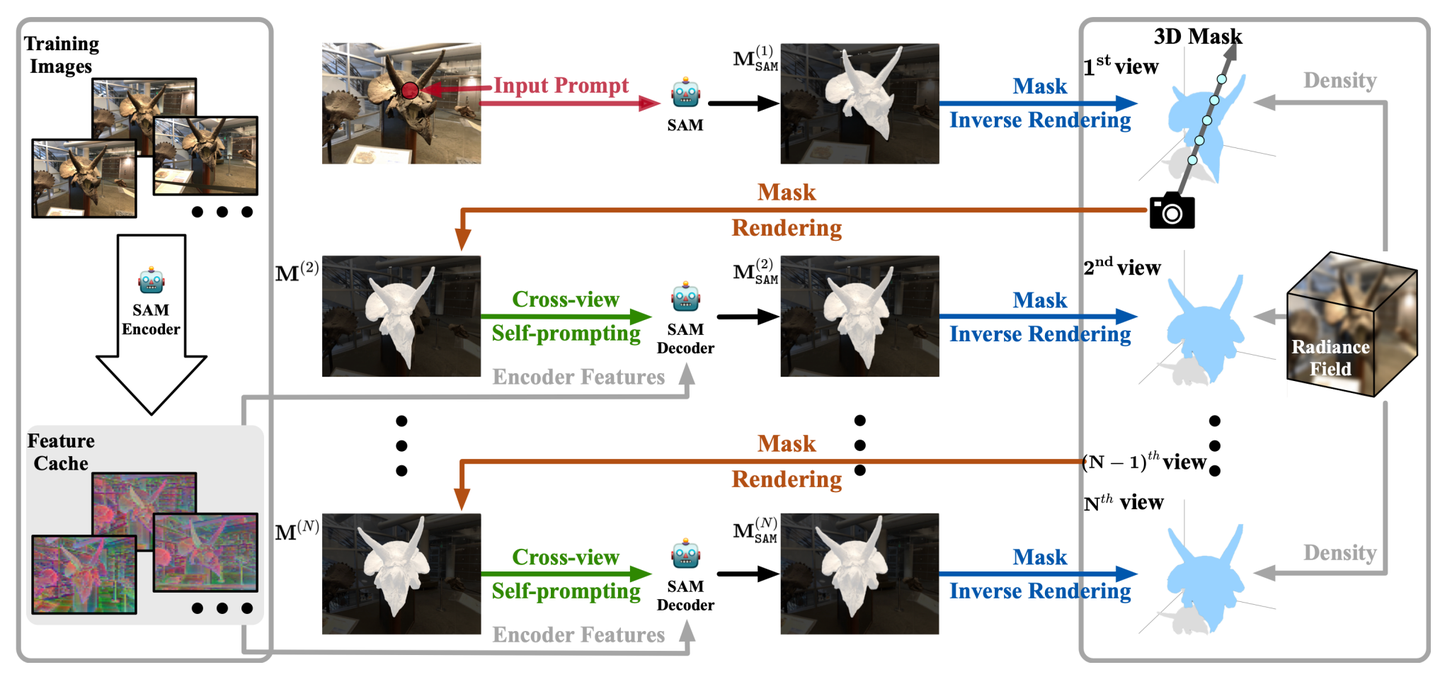
整体流程
SA3D的核心目标是通过结合2D分割模型(SAM)和辐射场模型来高效完成3D分割。它通过一个训练好的辐射场模型,接收从单个视角输入的2D提示(如点击点),然后逐步生成3D分割掩码。
-
输入多视角2D图像:首先,模型从多个视角下拍摄的2D图像开始,这些图像是训练好的辐射场模型的输入。
-
SAM编码器提取特征:将这些2D图像输入到SAM的编码器中,提取图像特征。这些特征随后被缓存下来,形成特征缓存(Feature Cache),用于后续的分割和渲染。
-
输入提示生成:用户在特定的视角下对目标物体提供2D提示,例如在物体上的点击点。这些提示作为SAM的输入,帮助模型生成初始的2D分割掩码
,这一掩码表示该视角下的初步分割结果。
-
投影到3D空间:初步生成的2D掩码通过掩码逆向渲染步骤被投影到3D空间中。此时,使用辐射场的密度信息,将2D掩码与3D物体的几何信息关联起来,形成一个粗略的3D分割掩码。
-
掩码渲染(Mask Rendering):基于3D掩码,在新的视角下生成新的2D掩码
。由于最初的3D掩码可能不够精确,可能会导致新视角下的2D分割不准确。
-
跨视角自提示(Cross-view Self-prompting):为了提高分割精度,系统自动从新视角的2D渲染掩码中生成提示信息。这些提示与特征缓存中的图像特征结合,进一步优化视角下的2D分割掩码。
-
迭代过程:这一流程会在多个视角上反复执行,每个视角下生成的2D掩码都通过逆向渲染投影到3D空间中,逐步优化3D分割掩码。
四、核心方法
4.1 3D Mask Representation
对于NeRF,论文采用3D体素网格(3D Voxel Grids)来表示3D掩码。具体来说,每个体素网格的顶点都会存储一个初始为零的软掩码置信度分数。利用这些体素网格,论文通过如下公式将某个视角下的2D掩码渲染为对应的3D掩码:
其中:
-
V(r(t)) 表示通过体素网格得到的3D掩码置信度。
-
ω(r(t))是光线渲染权重,基于体素的密度和透明度计算。
3D-GS采用了3D高斯分布作为基本的渲染单元。论文将掩码置信度作为每个高斯分布的一个新属性,即每个高斯分布要么被完全分配给目标对象,要么被分配给背景。这种设计下不需要额外的掩码网格,而是利用可微光栅化算法进行渲染,公式如下:
其中:
-
ωgi 表示每个高斯分布的权重。
-
mgi 是高斯分布的掩码置信度。
内存优化:与NeRF的体素网格表示相比,3D-GS只需要储存场景中的高斯分布,每个场景的高斯分布通常不超过1000万,远少于32³体素网格所需的条目数(大约3277万)。因此,在GPU内存消耗上,3D-GS更具优势。
计算效率提升:体素网格的表示需要在渲染阶段额外查询每个体素的掩码置信度,而3D-GS则通过直接对每个高斯分布进行处理,减少了计算开销。
4.2 Mask Inverse Rendering
Mask Inverse Rendering 是SA3D框架中的一个关键步骤,它通过将从2D视图生成的分割掩码投影到3D空间来生成准确的3D掩码。
每个像素的颜色由沿射线的加权颜色和权重决定。公式如下:
其中,ω(r(t)) 是该点的权重,表示该点接近目标表面的程度。权重值较高的点表示该点更接近物体的表面。因此,基于这些权重可以推断出物体在3D空间中的结构。
掩码逆向渲染的目标是将2D掩码投影到3D空间,并基于上述权重生成3D掩码。具体步骤如下:
-
首先,假设SAM生成的2D掩码为 MSAM(r),当 M SAM(r)=1时,系统的目标是增加与权重 ω 相关的3D掩码值 V(r(t))或 mgi(对于3D-GS来说)。
-
优化过程采用梯度下降算法,通过最小化投影损失函数来进行。投影损失定义为:
其中 R(I)表示图像 I 中的射线集合。
为了进一步优化3D掩码,论文还引入了一个负修正项,用以保持多视角掩码的一致性。修正后的损失函数为:
其中 λ 是一个超参数,用于控制负项的大小。通过引入这个负修正项,只有当SAM在多个视角下都一致地将某个区域预测为前景时,SA3D才会将对应的3D区域标记为前景。
通过最小化上述损失函数,SA3D能够在多个视角下优化3D掩码。掩码逆向渲染结合了2D视图中的分割信息和3D辐射场中的几何信息,从而生成精确的3D分割结果。
4.3 Cross-view Self-prompting
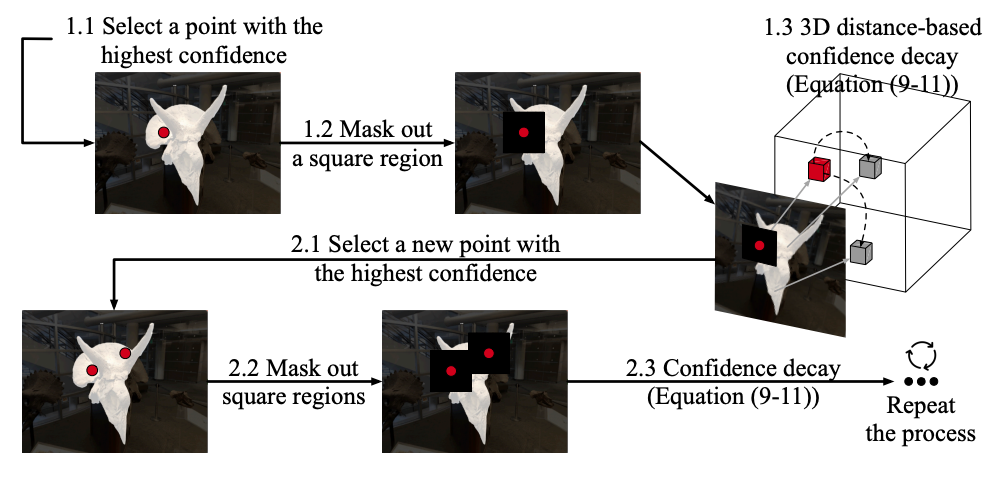
Cross-view Self-prompting 演示图
核心思想是在一个视角下生成的2D分割掩码,用于自动生成新的提示点,以便在其他视角中进一步优化分割掩码。这种自提示机制帮助系统在多个视角之间实现一致的分割效果,以下是对图中内容的流程阐述:
(1.1)选择最高置信度的点:首先,系统从当前的2D分割结果中选择一个具有最高置信度的点(图中红色圆点表示)。这一点代表系统在该位置上对于物体前景区域的分割信心最高。
(1.2) 方形区域掩码:选择了最高置信度的点后,系统会围绕该点生成一个方形区域,并将其掩码掉。这一操作防止同一个区域被多次选择,从而确保分割提示点均匀分布。
(1.3)基于3D距离的置信度衰减:接下来,系统根据该点在3D空间中的位置,对该点及其周围区域进行置信度衰减。置信度衰减是通过3D距离来计算的,表示在物体上相邻的点不再具有相同的提示优先级。具体衰减公式如下:
其中,d(pi,pj) 是两个点之间的3D距离,α 是一个控制衰减速度的参数。这个公式确保随着距离的增大,提示点的置信度逐渐衰减,从而避免在相近的区域选择多个提示点。
接着选择新点并重复流程:
(2.1)选择新的高置信度点:在初次提示生成并掩码后,系统继续从剩余区域中选择下一个具有最高置信度的点。这一过程与步骤1.1类似,新的提示点同样是根据当前2D分割结果的置信度确定的。
(2.2)掩码新的方形区域:选择新点后,系统再次生成一个新的方形掩码区域,将该区域的置信度降低,并避免该区域再次被选作提示点。
(2.3)基于距离的置信度衰减:类似于步骤1.3,系统对新选定点周围的区域根据距离进行置信度衰减,防止选取过于相邻的点。这一步骤通过公式继续计算,并且随着更多提示点的选择,置信度衰减的影响在整个图像中逐步扩展。
这一选择和掩码、置信度衰减的流程会在所有视角下不断重复,直到所有必要的提示点生成完毕。生成的提示点随后被输入到SAM模型中,用于在不同视角下生成更准确的2D掩码。
两个重要策略——Self-prompting Strategy 和 IoU-aware View Rejection
4.3.1 Self-prompting Strategy(自提示策略)
在系统处理每个新视角时,基于当前3D掩码渲染的2D掩码可能存在一定的不准确性。因此,系统会通过一个自提示机制从当前视角的2D掩码中自动提取提示点。这些提示点通过以下策略自动生成:
-
置信度选择:通过计算2D掩码中每个像素的置信度,选择那些置信度最高的像素点作为新的提示点(例如图中选择的红色点)。
-
置信度公式:置信度 C(pi) 表示每个点 pi是前景物体的可能性,可以通过如下公式计算:
其中,SAM(pi) 是SAM模型对点 pi 的分割结果,softmax函数用于归一化每个像素点的前景概率。
-
通过上述置信度计算选取提示点后,系统会将这些提示点输入SAM的解码器部分,生成当前视角下的精确2D分割掩码。这一步使得SA3D能够通过自动提示生成机制,不断优化不同视角下的分割精度。
自提示策略会在每个视角下反复进行,通过多个视角的遍历,逐步生成更精确的3D分割掩码。
4.3.2 IoU-aware View Rejection(基于IoU的视角拒绝策略)
IoU-aware View Rejection 是一个用于过滤掉低质量视角的策略,确保SA3D只在有助于优化的视角上进行分割优化。IoU(交并比)用于衡量新视角下的2D分割掩码与已有分割结果之间的重叠程度。具体流程如下:
在每个新的视角下,系统首先通过3D掩码生成一个新的2D分割掩码。为了判断该视角的分割结果是否值得进一步优化,系统会计算这个视角下的新分割掩码与之前视角的分割结果之间的交并比。交并比的计算公式如下:
其中:
-
Mnew 表示当前视角下生成的2D掩码。
-
Mref 表示前一个视角下的2D分割掩码。
IoU门限值过滤。如果某个视角的2D分割结果与之前视角的分割结果有很大的差异,即交并比较低,则系统可能会拒绝该视角,认为其分割结果不可靠。这种过滤策略确保了系统不会花费计算资源在低质量的视角上。视角拒绝基于以下条件进行:
其中,τ 是预设的IoU阈值,通常可以根据实验设置一个合理的值,例如 0.5。
通过这种基于IoU的视角拒绝策略,SA3D能够过滤掉那些可能导致误差的视角,从而提高整体分割的准确性和效率。这一策略确保系统只在有用的视角上进行优化,从而避免了无用的计算开销。
五、实验结果
在实验中,SA3D被集成到三种不同类型的辐射场模型中,分别是:
-
Vanilla-NeRF:这是基于MLP(多层感知机)的纯隐式表示方法,用于建模3D场景。
-
TensoRF:一种混合表示方法,采用向量矩阵(VM)分解和轻量级MLP解码器来构建3D场景。
-
3D-GS(3D Gaussian Splatting):显式使用3D高斯分布,不依赖任何神经网络来表示3D场景。
实验结果表明,SA3D能够无缝适应多种辐射场表示模型,且展示了其在各种场景和任务中的通用性。
实验使用了多个数据集进行定量评估,包括:
-
NVOS数据集:基于LLFF数据集,包含几个前向场景。该数据集提供带有涂鸦的参考视图和目标视图的注释分割掩码。
-
SPIn-NeRF数据集:手动注释了一些NeRF数据集,用于评估交互式3D分割性能。
-
Replica数据集:提供了高质量的室内场景重建,包括密集几何、高清纹理、语义类等丰富的信息。
定性分析使用了以下数据集:
-
LLFF数据集:用于展示在复杂3D场景中的分割性能。
-
MIP-360数据集:展示了SA3D在全景场景中的表现。
-
LERF数据集:该数据集包含了更加真实且具有挑战性的场景,用于进一步验证SA3D在更复杂场景中的适应性。
SA3D的实现基于PyTorch,并在Nvidia Geforce RTX3090 GPU上进行训练。不同的辐射场模型的预训练迭代次数如下:
-
Vanilla-NeRF:200,000次迭代。
-
TensoRF:在LLFF和MIP-360数据集上进行了20,000次迭代训练,其他数据集上进行了40,000次迭代。
-
3D-GS:进行了30,000次迭代。
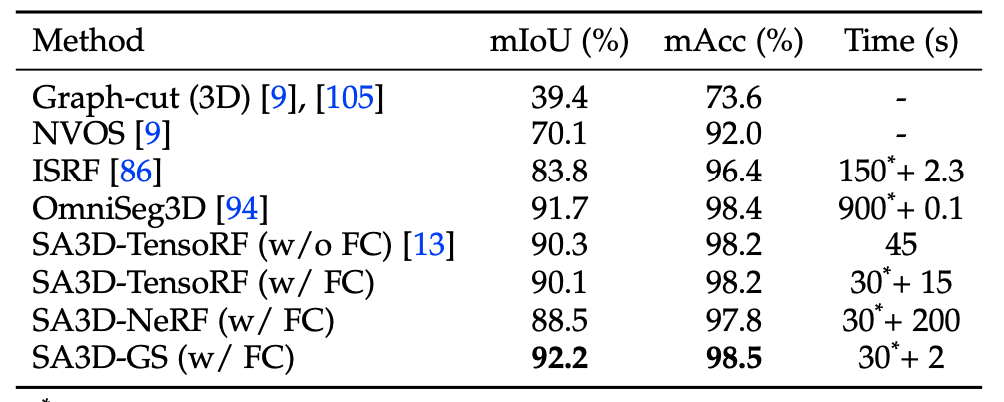
NVOS 的定量结果。 “FC”表示特征缓存。比较方法的时间成本是根据其论文中的描述来估计的。
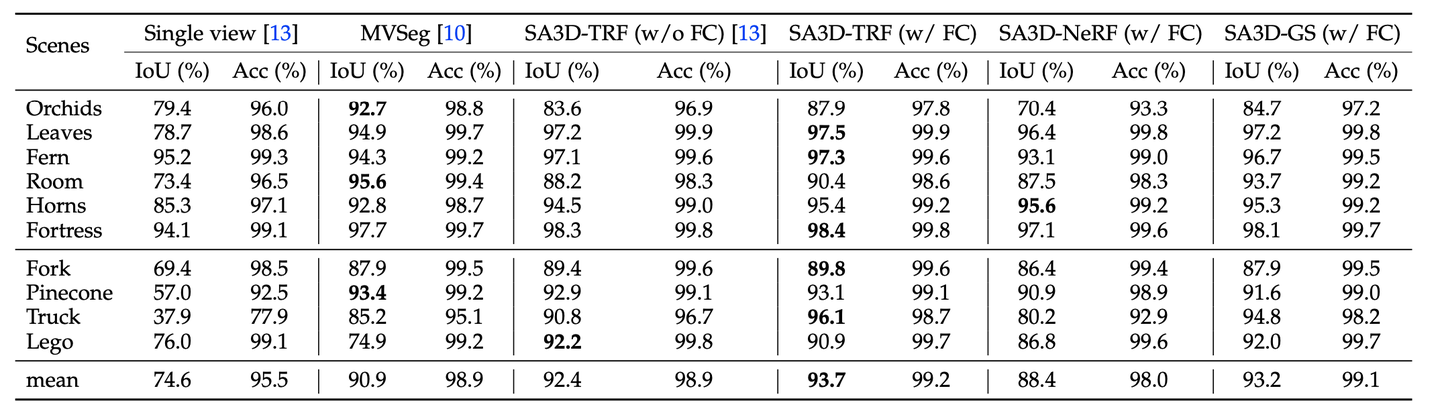
SPIn-NeRF 数据集的定量结果。 “FC”表示特征缓存。 “TRF”表示“TensoRF”。

Replica的定量结果 (mIoU)。 “FC”表示特征缓存。【3D GS性能不佳-错误学习的几何图形会混淆分割模型并导致性能下降】

不同场景中的一些可视化结果
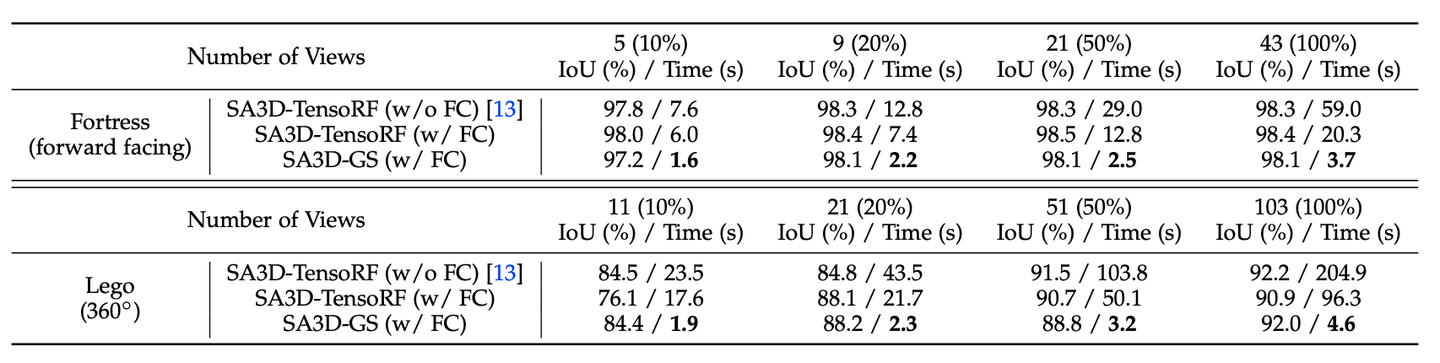
在不同数量的视图上进行消融以生成 3D 掩模。括号中的数字表示视角次数占总训练视角次数的百分比。 “FC”表示特征缓存。

不同 IoU 感知拒绝阈值的消融 τ 在副本 Office_0 上。

不同负项系数的消融 λ 在副本 Office_0 上。

自我提示策略的置信度衰减项的消融。
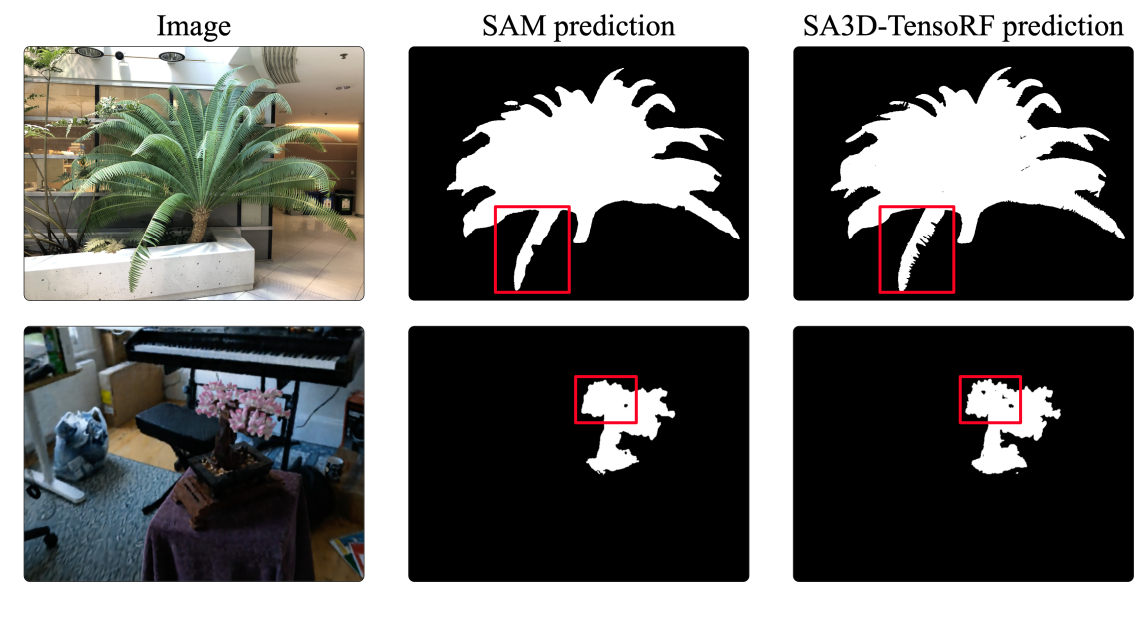
LLFF-fern场景和 360-bonsai场景的 SAM 2D 分割结果和 SA3D 3D 分割结果。 SA3D 生成 SAM 分割结果中缺失的更多细节。
六、结论
辐射场为SA3D提供了细粒度的深度估计(或几何信息),这对于捕捉物体的复杂细节如小孔和间隙非常重要。二维分割模型(如SAM)在处理这些细节时经常面临挑战,尤其是由于分辨率限制导致的分割误差。虽然SAM具有细粒度分割能力,但在某些情况下仍会忽略这些小区域。通过引入辐射场,SA3D能够利用三维几何信息来纠正这些误差,从而提升分割性能。
在投影损失(Projection Loss)中引入了负细化项,用以处理那些被SAM忽略的区域。例如,当SAM忽略物体上的小孔和间隙时,2D掩码可能会穿过这些区域,并投射到物体后的背景上。随着视角的变化,原先的错误分割区域会从目标物体的后方转移到侧面。这时,由于视角不同,SAM对这些区域的预测会发生变化,前景预测不再包括这些错误区域。通过负细化项,这些区域的掩码置信度会被有效抑制,从而提升分割的准确性。
尽管SA3D通过辐射场提升了分割性能,但由于3D-GS(3D Gaussian Splatting)生成的伪影,系统性能在某些情况下有所下降。具体来说,3D-GS在处理Replica等合成数据集时,因缺乏足够的纹理信息支持,容易产生伪影。3D-GS使用Colmap技术从多视角图像获取初始点云,但在处理纹理不完整或细节缺失的图像时,可能会导致伪影的产生(3D-GS 过度拟合特定视图并在空间中生成大量半透明伪像)。由于这些伪影在三维空间中呈半透明状态,2D掩码在渲染时可能会错误地投影到这些伪影上,进而影响整体性能。

![[3]Opengl ES着色器](https://i-blog.csdnimg.cn/blog_migrate/73b82ae18ecf1bdd7fb8f98dae7e5b19.png)