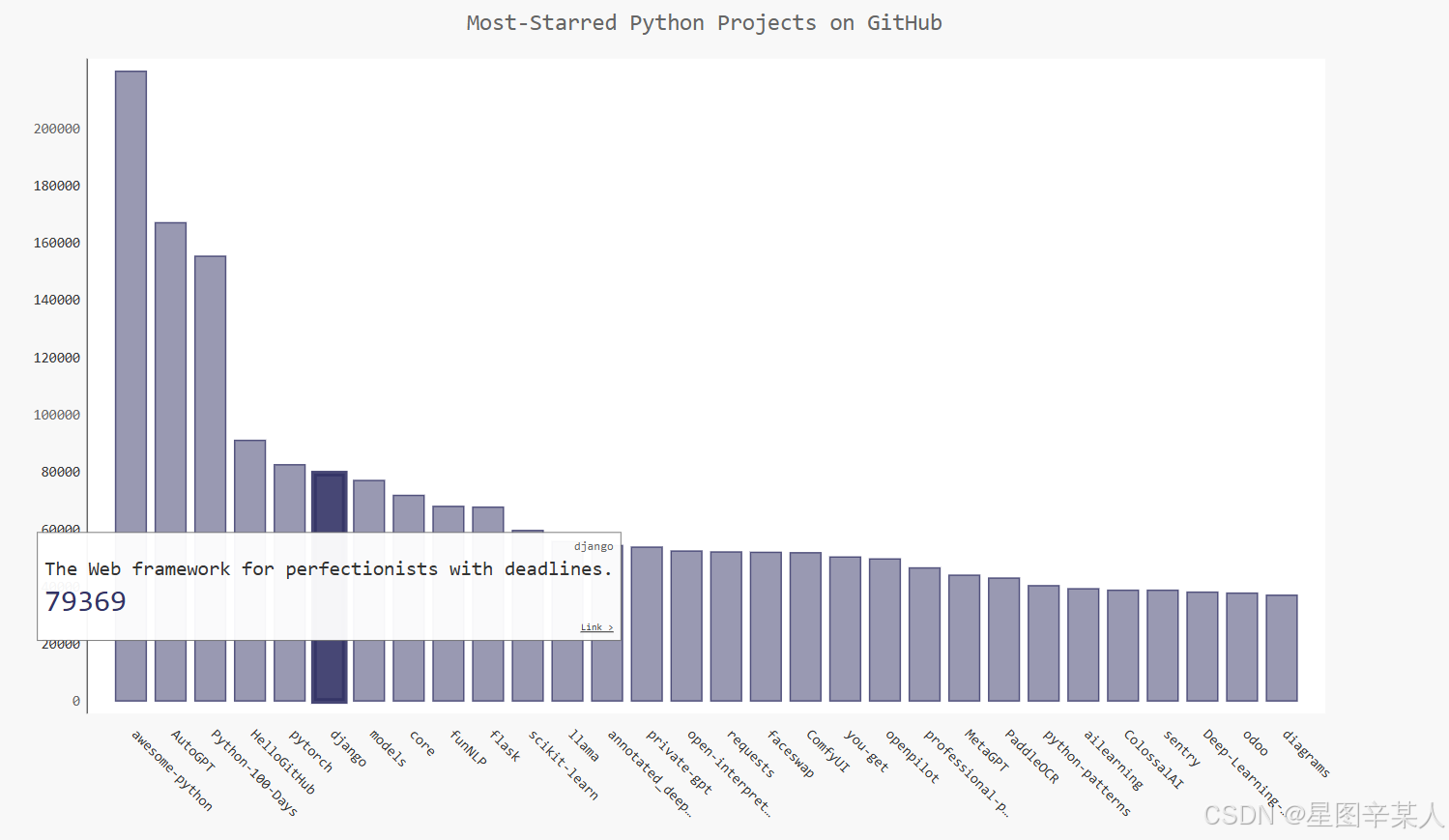
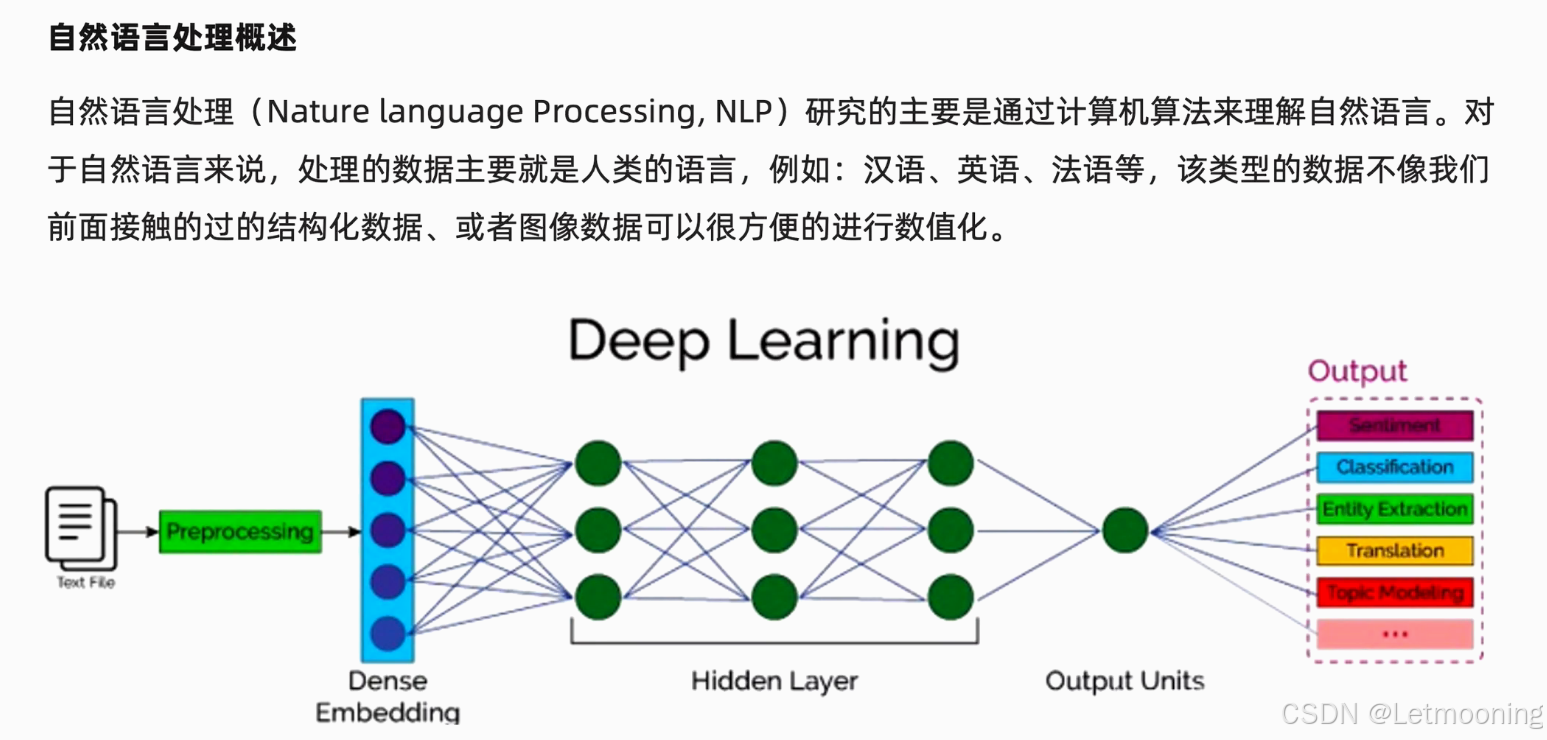
1 自然语言处理概述
- 语料:一个样本,句子/文章
- 语料库:由语料组成
- 词表:分词之后的词语去重保存成为词表

2 词嵌入层



import jieba
import torch.nn as nn
import torch
# 文本数据
text='北京东奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。'
# 分词
words=jieba.lcut(text)
print(words)
# 构建词表
uwords=list(set(words))
print(uwords)
words_num=len(uwords)
print(words_num)
# 构建词向量矩阵
embed=nn.Embedding(num_embeddings=words_num,embedding_dim=5)
print(embed(torch.tensor(1)))
# 输出结果
for i,word in enumerate(uwords):
print(word,end=' ')
print(embed(torch.tensor(i)))
['北京', '东奥', '的', '进度条', '已经', '过半', ',', '不少', '外国', '运动员&