[ 知识是人生的灯塔,只有不断学习,才能照亮前行的道路 ]
0x00 前言概述
在 Linux 运维以及Shell脚本编程中往往会使用到各种文本处理工具(例如,文本三剑客 awk、grep、sed)以及Shell脚本编程(后续作者会在#运维从业必学专栏中发布),在使用时往往都有正则表达式的身影,使用正则表达式可以非常方便的从大量的文本数据中匹配过滤出特定的数据(例如,只从 ip addr 命令中提取 ip 地址),除此之外在Windows系统、防火墙/WAF规则以及各种编程语言中也是支持,只不过有些许扩展正则表达式可能有所不同,但都大同小异,综上所述,无论是运维、开发、安全都要好好的学习正则表达式。

本文是作者花费一定的时间,从学习、运维开发工作中总结而来,算是在Linux中Shell编程学习文章中讲解表达式比较全和精炼的,让各位初学者可以快速了解什么是正则表达式、正则表达式的分类,以及简单使用正则表达式在Linux中进行特定字符串数据的提取过滤,使之看友们可以自行根据需要编写出更加复杂的正则表达式,这也是作者的初衷,如果感觉此文对你有帮助的话,就请多多支持作者【#运维从业必学】专栏。
正则表达式介绍
定义描述:正则表达式(RE's,regular expression)是你所定义的模式模板(pattern template),采用不同算法通常使用PCRE(Perl Compatible Regular Expressions)软件模块来处理正则表达式,Linux 命令行工具可以用它来过滤文本,例如 grep、sed 编辑器或 gawk 程序能够在处理数据时使用正则表达式对数据进行模式匹配,如果数据匹配模式,它就会被接受并进一步处理;如果数据不匹配模式,它就会被滤掉。
区别问题:正则表达式与我们常常使用的星号通配符(*)有何区别呢? 描述:正则表达式模式利用通配符来描述数据流中的一个或多个字符(不确定的数据),而星号通配符允许你只列出满足特定条件的文件,即要么前缀、要么后缀,要么前后缀,例如 ls -alh *user*,匹配带有user字符串的文件名称。
# 通配符,带有 user 字符串的都将显示。
$ ls *user*
testuser user.patch user.txt userrr.txt userr.txt
# 正则,带有 user 字符串且紧随其后的多个r字符都将被匹配。
$ ls | grep "user*"
testuser
user.patch
userrr.txt
userr.txt
user.txt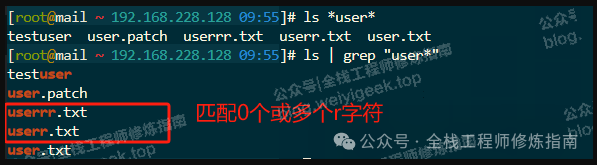
总结:虽然上述生成的效果一样,但是正则匹配出的高亮显示的却有不同,实际上使用场景也是不同的,通配符主要是找寻匹配文件名,例如,find,ls,cp,mv等命令中使用,而正则则处理文本内容中的字符,例如gerp、awk、sed、vim、expr等命令中使用。
正则表达式分类
在 Linux 系统 Shell 编程中的正则表达式,便是使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,这里可以将POSIX正则表达式分为基本正则表达式(BRE,Basic Regular Expressions)和扩展表达式(ERE,Extended Regular Expressions)以及Perl正则表达式(PRE,Perl Regular Expressions), 但是不同的 Linux 文本处理命令支持的正则比表达式有所不同,我们可执行man 7 regex命令查看帮助。
命令支持情况:
| 类型 | grep | grep -E | grep -P | sed | sed -r | vi | more | egrep | awk |
|---|---|---|---|---|---|---|---|---|---|
| BRE | √ | √ | √ | √ | |||||
| ERE | √ | √ | √ | √ | |||||
| PRE | √ |
正则表达式元字符(Shell):
| 字符 | 含义 | 支持的类型 |
|---|---|---|
| \ | 将下一个字符标记为特殊字符,或者将一个元字符转义为普通字符,例如,\{ 表示一个{字符。 | BOTH |
| ^ | 匹配输入字符串的开始位置 | BOTH |
| $ | 匹配输入字符串的结束位置 | BOTH |
| . | 匹配除\n之外的任何单个字符 | BOTH |
| * | 匹配前面的子表达式0次或者多次,例如, zo*能匹配z和zoo | BOTH |
| ? | 匹配前面的子表达式0次或者1次 | ERE |
| + | 匹配前面的子表达式1次或者多次,例如, zo+能匹配zo和zoo,但不能匹配z | ERE |
| | | 匹配于|符号前或后的正则表达式 | ERE |
| {n,m} | 最少匹配n次,最多匹配m次和BRE的区别是不需要加\ | ERE |
| () | 元组可以包含在其中表达式匹配的字符串进行调用和BRE的区别是不需要加\ | ERE |
| < | 匹配词(word)的开始 | BRE |
| > | 匹配词(word)的结束 | BRE |
| \b | 匹配单词开头和结尾位置 | BRE |
| \B | 匹配非单词开头和结尾位置 | BRE |
| \d | 匹配一个数字字符 | RRE |
| \D | 匹配一个非数字字符 | PRE |
| \w | 匹配包括下划线的任何单词字符,"单词"字符使用Unicode字符集,等价于[[:alnum:]] | PRE |
| \W | 匹配任何非单词字符,等价于[^[:alnum:]] | PRE |
| \f | 匹配一个换页符 : 00001100 14 12 0C FF (NP form feed, new page) | PRE |
| \n | 匹配一个换行符 :00001010 12 10 0A LF (NL line feed, new line) | PRE |
| \r | 匹配一个回车符 :00001101 15 13 0D CR (carriage return) | PRE |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符,等价于[ \f\n\r\t\v]。 | PRE |
| \S | 匹配任何可见字符,等价于[^ \f\n\r\t\v] | PRE |
| \t | 匹配一个水平制表符 : 00001001 11 9 9 HT (horizontal tab) | PRE |
| \v | 匹配一个垂直制表符 : 00001011 13 11 0B VT (vertical tab) | PRE |
| \cx | 匹配由x指明的控制字符 | BRE |
| {n} | 匹配前面的子表达式n次 | BRE |
| {n,} | 至少匹配前面的子表达式n次 | BRE |
| {,m} | 最多匹配前面的子表达式m次 | BRE |
| {n,m} | 最少匹配n次,最多匹配m次 | BRE |
| () | 元组,将(与)间的模式存储在特殊的保留空间 | BRE |
| ()\数字 | 重复在(与)方括号内第n个子模式至此点的模式,例如 ls | grep "\(user\)\1" 将()元字符匹配到的数据进行调用 | BRE |
| [xyz] | 匹配xyz中的任何一个字符 | BOTH |
| [^xyz] | 匹配未包含的任意字符 | BOTH |
| [x-z] | 匹配小写的字符 | BOTH |
除了定义自己的字符组外,BRE 还包含了一些特殊的字符组,可用来匹配特定类型的字符,注意:此特殊元字符有的命名是不支持的,经测试vi , grep , awk , sed , expr等命令是支持殊字符组。
[[:alpha:]] 匹配任意字母字符,不管是大写还是小写
[[:alnum:]] 匹配任意字母数字字符 0~9、A~Z 或 a~z
[[:blank:]] 匹配空格或制表符 " " 和 TAB 字符
[[:digit:]] 匹配 0~9 之间的数字
[[:lower:]] 匹配小写字母字符 a~z
[[:upper:]] 匹配任意大写字母字符 A~Z
[[:print:]] 匹配任意可打印字符
[[:punct:]] 匹配标点符号
[[:space:]] 匹配任意空白字符:空格、制表符、NL、FF、VT 和 CR特别注意,Linux 系统语系的配置会影响正则表达式的匹配结果,例如:LANG=C、LANG=zh_CN,由于不同语系的编码数据不同,所以造成不同语系的数据选取结果有所差异。因此在使用正则表达式时要特别留意语系,由于我们一般使用的兼容与 POSIX 的标准,建议使用 C 语系;