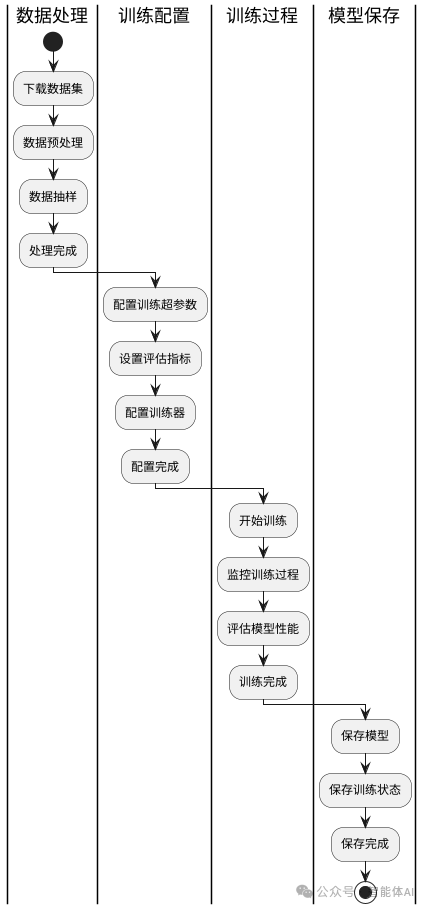
在自然语言处理(NLP)领域,模型微调(Fine-Tuning)是提升预训练模型在特定任务上表现的关键步骤。本文将详细介绍如何使用 Hugging Face Transformers 库进行模型微调训练,涵盖数据集下载、数据预处理、训练配置、评估、训练过程以及模型保存。我们将以 YelpReviewFull 数据集为例,逐步带您完成模型微调训练的整个过程。
一、数据集下载
1.1 获取 YelpReviewFull 数据集
YelpReviewFull 数据集是一个经典的情感分析数据集,包含了大量来自 Yelp 的评论。数据集从 Yelp Dataset Challenge 2015 数据中提取,主要用于文本分类任务,目标是预测评论的情感分数。数据集的评论主要用英语编写,适合进行情感分类研究。
1.2 数据集结构与实例
数据集包含两个主要字段:
- text: 评论的文本内容。
- label: 评论的情感标签,范围从 1 到 5。
例如,一个典型的数据点如下:
{
'label': 0,
'text': 'I got \'new\' tires from them and within two weeks got a flat...'
}
** **
1.3 数据拆分
数据集的总量为 700,000 条记录,其中包括 650,000 个训练样本和 50,000 个测试样本。在实际操作中,我们通常会将数据集随机拆分为训练集和测试集。例如,我们可以选择 130,000 个训练样本和 10,000 个测试样本用于模型训练和评估。
1.4 下载数据集代码
可以使用 Hugging Face 的 datasets 库来下载数据集:

二、数据预处理
2.1 数据预处理步骤
下载数据集后,我们需要对文本数据进行预处理,以便于模型的训练。预处理包括将文本转换为模型可以接受的输入格式。通常,我们使用 Tokenizer 对文本进行编码,并进行填充(padding)和截断(truncation)。
以下代码展示了如何使用 BERT Tokenizer 对数据集进行预处理:


2.2 数据抽样
在训练过程中,为了更好地控制训练过程,我们可以从数据集中抽样出一部分数据进行测试。例如,选择 1000 个样本进行小规模训练:
# 从数据集中抽样 1000 个训练样本
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
# 从数据集中抽样 1000 个测试样本
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
三、训练评估指标设置
3.1 微调训练配置
在微调模型之前,我们需要配置训练参数,包括加载模型和设置训练超参数。以下代码展示了如何加载 BERT 模型,并为情感分类任务配置输出标签数量:
from transformers import AutoModelForSequenceClassification
# 加载 BERT 模型,并设置标签数量为 5(情感评分从 1 到 5)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
3.2 训练超参数配置(TrainingArguments)
我们使用 TrainingArguments 来配置训练超参数。这些参数包括训练批次大小、训练轮数、日志记录频率等。以下是一个示例配置:

四、训练器基本介绍
4.1 训练指标评估
Hugging Face 提供了 evaluate 库来计算模型的评估指标。例如,我们可以使用准确率(accuracy)作为评估指标。以下代码展示了如何使用 evaluate 库计算模型的准确率:

4.2 训练器(Trainer)
Trainer 类是 Hugging Face 提供的用于训练和评估模型的工具。我们需要将模型、训练参数、数据集以及计算指标的函数传递给 Trainer:

五、实战训练
5.1 训练过程中的指标监控
为了监控训练过程中的评估指标,我们可以配置 TrainingArguments 中的 evaluation_strategy 参数,以便在每个 epoch 结束时报告评估指标:

5.2 开始训练
使用 Trainer 类的 train 方法开始训练模型:
# 开始训练
trainer.train()
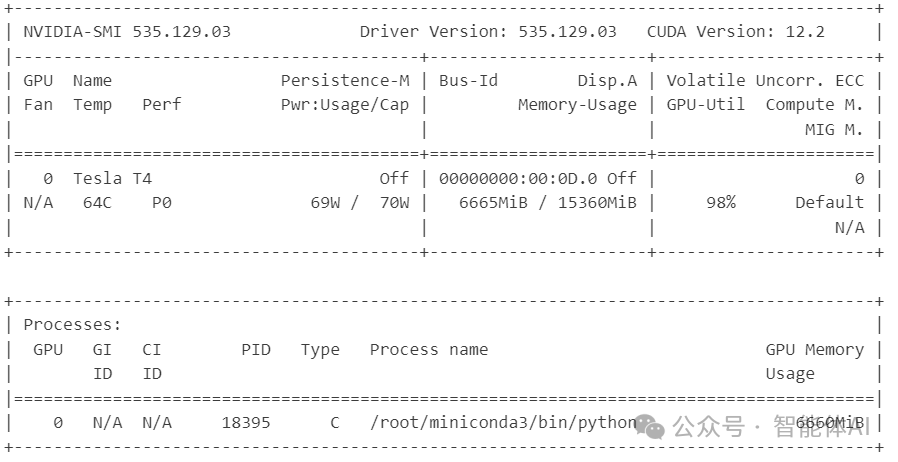
5.3 使用 nvidia-smi 监控 GPU 使用
在训练过程中,使用 nvidia-smi 命令监控 GPU 的使用情况,以确保训练过程的高效进行:
watch -n 1 nvidia-smi
六、模型保存
6.1 保存模型和训练状态
训练完成后,我们需要保存模型及其训练状态,以便后续加载和使用:

通过 trainer.save_model 方法保存模型,您可以使用 from_pretrained() 方法重新加载模型。trainer.save_state() 方法保存训练状态,便于后续继续训练或评估。
七、完整代码汇总
下面是包含所有步骤的完整代码示例:
# 导入必要的库
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
import numpy as np
import evaluate
# 数据集下载
dataset = load_dataset("yelp_review_full")
# 数据预处理t
okenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
"""
使用 Tokenizer 对文本进行编码,并进行填充和截断
"""
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 数据抽样
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
# 模型加载与训练配置
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
model_dir = "models/bert-base-cased-finetune-yelp"
training_args = TrainingArguments(
output_dir=model_dir,
per_device_train_batch_size=16,
num_train_epochs=5,
logging_steps=100
)
# 指标评估
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
"""
计算准确率
"""
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 实例化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics
)
# 开始训练
trainer.train()
# 监控 GPU 使用
# 使用命令行工具: watch -n 1 nvidia-smi
# 保存模型和训练状态
trainer.save_model(model_dir)
trainer.save_state()
八、总结
本文详细介绍了使用 Hugging Face Transformers 库进行模型微调训练的完整流程,包括数据集下载、数据预处理、训练配置、评估、训练过程和模型保存等步骤。希望这些信息能帮助您更好地进行模型微调,提高模型在特定任务上的表现。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。




![[uni-app]小兔鲜-02项目首页](https://img-blog.csdnimg.cn/img_convert/76ac29ad7495165212f0eb20b78e3949.png)







![[数据集][目标检测]手机识别检测数据集VOC+YOLO格式9997张1类别](https://i-blog.csdnimg.cn/direct/64685cdaf4b34c31838a52310e11cb9f.png)