启动HBase:
1.启动hadoop,进入hadoop的sbin中
cd /opt/hadoop/sbin/
2.初始化namenode
hdfs namenode -format
3.启动hdfs
./start-all.sh
4.启动hbase
cd /opt/hbase/bin
./start-hbase.sh
5.使用jps查看进程
jps以下图片则是hbase启动成功~

运行HBase
./hbase shell接下来就可以开始建表啦~

shell操作:
HBase创建数据库建表:
语法:
create '表名','列族名1','列族名2',...,'列族名N'查看所有数据库:
list
查看表结构:
discribe '表名'

计算表中所有记录的数量:
count '表名' 
HBase数据库表数据的增、删、查、改
(1)HBase增加数据的语法格式:
put '表名','rowKey','列族:列','值'
(2)HBase查询数据的语法格式:
scan查询所有表记录
scan '表名' 
get查询某个rowKey的所有记录
get '表名','rowKey' 
get查询某个rowKey列族的记录
get '表名','rowKey','列族'
get查询rowKey列族的某个列记录
get '表名','rowKey','列族:列'
(2)HBase 删除数据:
删除表的所有记录:(drop)
disable '表名'
drop '表名'删除表的某一条记录:(delete)
delete '表名','行名','列族:列' 
删除表的整行记录
deleteall '表名','rowKey' 
清空表的所有记录
truncate '表名'
(4)HBase更新数据
用put重新写一遍,可以覆盖
下面以建如下表结构为例

1.创建一个名为student的表,字段包括stuInfo和grades
creat 'student','stuInfo','grades' 
2.向表中插入数据
put 'student','001','stuInfo:name','alice'
put 'student','001','stuInfo:age','18'
put 'student','001','stuInfo:sex','female'
put 'student','001','grades:English','80'
put 'student','001','grades:math','90'
put 'student','002','stuInfo:name','nancy'
put 'student','002','stuInfo:sex','male'
put 'student','002','stuInfo:class','1802'
put 'student','002','grades:English','85'
put 'student','002','grades:math','78'
put 'student','002','grades:bigdata','88'
put 'student','003','stuInfo:name','harry'
put 'student','003','stuInfo:age','19'
put 'student','003','stuInfo:sex','male'
put 'student','003','grades:English','90'
put 'student','003','grades:bigdata','90'过滤操作:
1.行键过滤器(RowFilter、KeyOnlyFilter、FirstKeyOnlyFilter等)
格式:scan '表名',{FILTER=>"过滤器(比较运算符,'比较器')"}
(1)RowFilter:针对行键进行过滤
例1: 显示行键前缀0开头的键值对
scan 'student',{FILTER=>"RowFilter(=,'substring:001')"}
例2:显示行键字节顺序大于002的键值对
scan 'student',FILTER=>"RowFilter(>,'binary:002')"
(2)PrefixFilter:行键前缀过滤器
例1:扫描前缀为001的行键
scan 'student',FILTER=>"PrefixFilter('001')"
(3)FirstKeyOnlyFilter:扫描全表,显示每个逻辑行的第一个键值对
scan 'student',FILTER=>"FirstKeyOnlyFilter()"
(4)InclusiveStopFilter:替代EndRow返回终止条件行
例:扫描显示行键001道002的范围内的键值对
scan 'student',{STARTROW=>'001',FILTER=>"InclusiveStopFilter('002')"}等同于:
scan 'student',{STARTROW=>'001',ENDROW=>'003'}
2.列族与过滤器
(1)Family:针对列族进行比较和过滤
例1:显示列族前缀为stu开头的键值对
scan 'student',FILTER=>"FamilyFilter(=,'substring:stu')"
scan 'student',FILTER=>"FamilyFilter(=,'binary:stu')"

(2)QualifierFilter:列标识过滤器
例:显示列名为name的记录
scan 'student',FILTER=>"QualifierFilter(=,'substring:name')"
等价于
(3)ColumnPrefixFilter:对列名前缀进行过滤
例:显示列名为name的记录
scan 'student',FILTER=>"ColumnPrefixFilter('name')"
等价于
scan 'student',FILTER=>"QualifierFilter(=,'substring:name')"(4)MultipleColumnPrefixFilter:可以指定多个前缀
例:显示列名为name和age的记录
scan 'student',FILTER=>"ColumnPrefixFilter('name')"scan 'student',FILTER=>"MultipleColumnPrefixFilter('name','age')"
(5)ColumnRangeFilter:设置范围按字典序对列名进行过滤
例:
scan 'student',FILTER=>"ColumnRangeFilter('bi',true,'na',true)"
3.值过滤器
(1)ValueFilter:值过滤器
例:查询等于19的所有键值对
scan 'student',FILTER=>"ValueFilter(=,'binary:19') "
scan 'student',FILTER=>"ValueFilter(=,'substring:19')" 
(2)SingleColumnValueFilter:在指定的列族和列中进行值过滤器
例:查询studiofo列族age列中值等于19的所有键值对
scan 'student',{COLUMN=>'stuInfo:age',FILTER=>"SingleColumnValueFilter('stuInfo','age',=,'binary:19')"}
4.其他过滤器
(1)ColumnCountGetFilter:限制每个逻辑行返回的键值对数
例:返回行键位001的前3个键值对
get 'student','001',FILTER=>"ColumnCountGetFilter(3)"
(2)PageFilter:基于行的分页过滤器,设置返回的行数
例:显示1行
scan 'student',FILTER=>"PageFilter(1)"
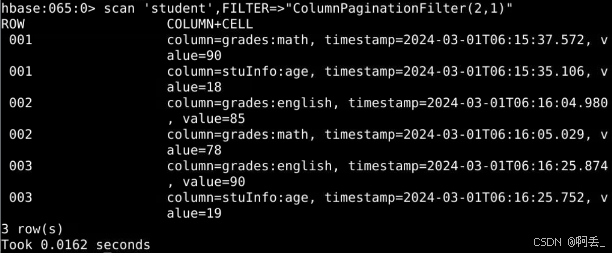
(3)ColumnPaginationFilter:基于列的进行分页过滤器,需要设置偏移量与返回数量
例:显示每行第1列之后的第二个键值对
scan 'student',FILTER=>"ColumnPaginationFilter(2,1)"