一、容器基本实现原理
- Docker 主要通过如下三个方面来实现容器化:
- ① 使用操作系统的 namespace 隔离系统资源技术,通过隔离 网络、PID 进程、系统信号量、文件系统挂载、主机名和域名,来实现在同一宿主机系统中,运行不同的容器,并且每个容器之间是 相互隔离,运行互不干扰 。
- ② 使用操作系统的 cgroups 系统资源配额功能,限制资源包括:CPU、内存(Memory)、块设备(Blkio)、网络(Network)。
- ③ 通过 OverlayFS 数据存储技术,实现容器 镜像 的物理存储和新建 容器 存储。
1. Namesapce
隔离性
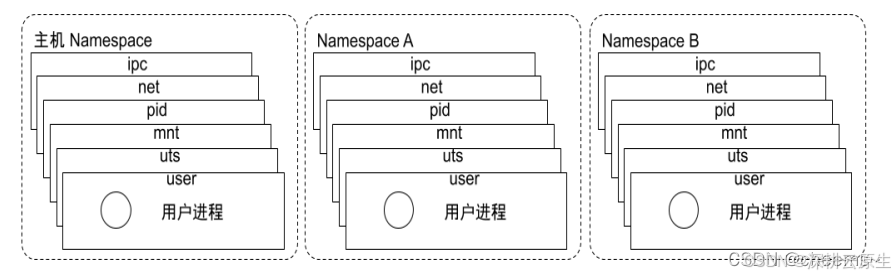
- 当一台物理主机(宿主机)运行容器的时候,为了避免容器所需系统资源之间的相干扰。Docker 就利用了操作系统的隔离技术 – namespace ,来实现在同一个操作系统中,不同容器之间的资源可以独立运行。
- Linux 中的 namespace 是 Linux 系统提供的一种资源隔离技术,可以实现系统资源隔离的列表如下:
namespace 系统调用参数 隔离内容
UTS CLONE_NEWUTS 主机和域名。
IPC CLONE_NEWIPC 信号量、消息队列和共享内存。
PID CLONE_NEWPID 进程编号。
Network CLONE_NEWNET 网络设备、网络栈、端口等。
Mount CLONE_NEWNS 挂载点(文件系统)。
User CLONE_NEWUSER 用户和用户组。
Pid namespace
- 不同用户的进程就是通过 Pid namespace 隔离开的,且不同 namespace 中可以有相同 Pid。
- 有了 Pid namespace, 每个 namespace 中的 Pid 能够相互隔离。
net namespace
- 网络隔离是通过 net namespace 实现的, 每个 net namespace 有独立的network devices, IP addresses, IP routing tables, /proc/net 目录。
- Docker 默认采用 veth 的方式将 container 中的虚拟网卡同 host 上的一个 docker bridge: docker0 连接在一起。
ipc namespace
- Container 中进程交互还是采用 linux 常见的进程间交互方法 (interprocess communication – IPC), 包括常见的信号量、消息队列和共享内存。
- container 的进程间交互实际上还是 host上 具有相同 Pid namespace 中的进程间交互,因此需要在 IPC 资源申请时加入 namespace 信息 - 每个 IPC 资源有一个唯一的 32 位 ID。
mnt namespace
- mnt namespace 允许不同 namespace 的进程看到的文件结构不同,这样每个 namespace 中的进程所看到的文件目录就被隔离开了。
uts namespace
- UTS(“UNIX Time-sharing System”) namespace允许每个 container 拥有独立的 hostname 和 domain name, 使其在网络上可以被视作一个独立的节点而非 Host 上的一个进程。
user namespace
- 每个 container 可以有不同的 user 和 group id, 也就是说可以在 container 内部用 container 内部的用户执行程序而非 Host 上的用户。
常用操作
- 查看某进程资源隔离
# 查找某进程,记下进程的 PID
ps aux | grep ssh

查找 namespace
ls -lah /proc/818/ns/

- 查看宿主机当前的命名空间:
ls -alh /proc/self/ns/
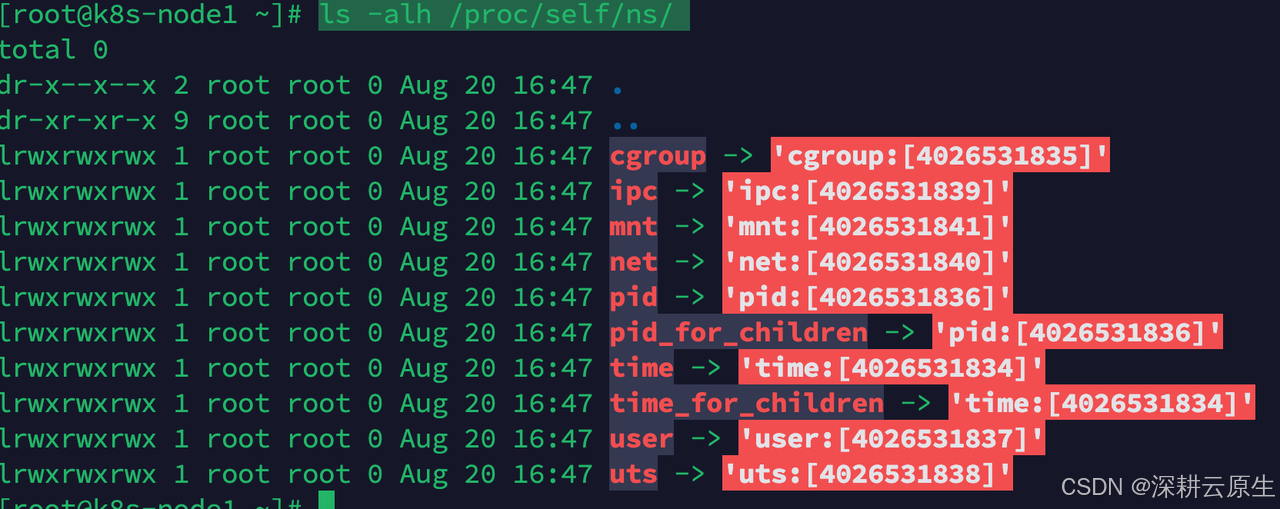
#查看任意symlink
lsns |grep 4026531841

发现是systemd ,因为现在的命名空间是 “systemd” 进程的命名空间(PID 为 1),默认情况下进程会继承其父进程(systemd)的命名空间。
为什么systemd是其他进程的父进程?因为systemd是最常见的初始化系统(init system),它在系统启动时作为第一个用户空间进程启动,PID 通常为 1。systemd 启动后,它创建了一系列的命名空间(如 mnt、pid、net 等),并在这些命名空间中启动所有后续的系统服务和用户进程。
- 进入某 namespace 运行命令:
# nsenter -t <pid> -n ip addr
# -n ip addr 表示查看net 的ns 的网络配置
root@iv-yda4ksktts5i3z33qz30:~# nsenter -t 1 -n ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state
...
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc
...
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc
...
- 查看容器命名空间资源
运行个测试容器看一下ip
[root@iv-ydazohee4gwh2yo8570p ~]# docker run -it --name centos -P centos /bin/bash
[root@694bd98ec67c /]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
14: eth0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
[root@iv-ydazohee4gwh2yo8570p ~]# docker ps|grep centos
694bd98ec67c centos "/bin/bash" 51 seconds ago Up 50 seconds centos
[root@iv-ydazohee4gwh2yo8570p ~]# docker inspect 694bd98ec67c | grep -i pid
"Pid": 239303,
"PidMode": "",
"PidsLimit": null,
#通过nsenter看容器内的网路
[root@iv-ydazohee4gwh2yo8570p ~]# nsenter -t 239303 -n ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
14: eth0@if15: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
#通过nsenter看容器内的挂载信息
[root@iv-ydazohee4gwh2yo8570p ~]# nsenter -t 239303 -n mount
#宿主机查看容器挂载信息
[root@iv-ydazohee4gwh2yo8570p ~]# cat /proc/239303/mounts
overlay / overlay rw,relatime,lowerdir=/var/lib/docker/overlay2/l/25EZYMEZ4ON3GV4WACDJUGTWF6:/var/lib/docker/overlay2/l/EGKB7OUE54LT2NXS2OQA2D2JWB,upperdir=/var/lib/docker/overlay2/863adb34d0db8eb59ae7d1ab26db43dfde27740cf228355c0a64cd3bbe840bfe/diff,workdir=/var/lib/docker/overlay2/863adb34d0db8eb59ae7d1ab26db43dfde27740cf228355c0a64cd3bbe840bfe/work 0 0
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0
tmpfs /dev tmpfs rw,nosuid,size=65536k,mode=755,inode64 0 0
devpts /dev/pts devpts rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=666 0 0
sysfs /sys sysfs ro,nosuid,nodev,noexec,relatime 0 0
cgroup /sys/fs/cgroup cgroup2 ro,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot 0 0
mqueue /dev/mqueue mqueue rw,nosuid,nodev,noexec,relatime 0 0
shm /dev/shm tmpfs rw,nosuid,nodev,noexec,relatime,size=65536k,inode64 0 0
/dev/vda2 /etc/resolv.conf ext4 rw,relatime,errors=remount-ro 0 0
/dev/vda2 /etc/hostname ext4 rw,relatime,errors=remount-ro 0 0
/dev/vda2 /etc/hosts ext4 rw,relatime,errors=remount-ro 0 0
devpts /dev/console devpts rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=666 0 0
proc /proc/bus proc ro,nosuid,nodev,noexec,relatime 0 0
proc /proc/fs proc ro,nosuid,nodev,noexec,relatime 0 0
proc /proc/irq proc ro,nosuid,nodev,noexec,relatime 0 0
proc /proc/sys proc ro,nosuid,nodev,noexec,relatime 0 0
proc /proc/sysrq-trigger proc ro,nosuid,nodev,noexec,relatime 0 0
namespace 系统调用
namespace 有三个系统调用可以使用:
- clone() — 实现线程的系统调用,用来创建一个新的进程,并可以通过设计上述参数达到隔离。
- unshare() — 使某个进程脱离某个 namespace
- setns(int fd, int nstype) — 把某进程加入到某个 namespace
UTS Namespace
UTS Namespace 主要是用来隔离主机名的,也就是每个容器都有自己的主机名。我们使用如下的代码来进行演示。注意:假如在容器内部没有设置主机名的话会使用主机的主机名的;假如在容器内部设置了主机名但是没有使用 CLONE_NEWUTS 的话那么改变的其实是主机的主机名。
c代码示例:
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <sys/mount.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024 * 1024)
static char container_stack[STACK_SIZE];
char* const container_args[] = {
"/bin/bash",
NULL
};
int container_main(void* arg) {
printf("Container [%5d] - inside the container!\n", getpid());
sethostname("container_dawn", 15);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main() {
printf("Parent [%5d] - start a container!\n", getpid());
int container_id = clone(container_main, container_stack + STACK_SIZE,
CLONE_NEWUTS | SIGCHLD, NULL);
waitpid(container_id, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
go代码示例:
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
log.Fatalln(err)
}
}
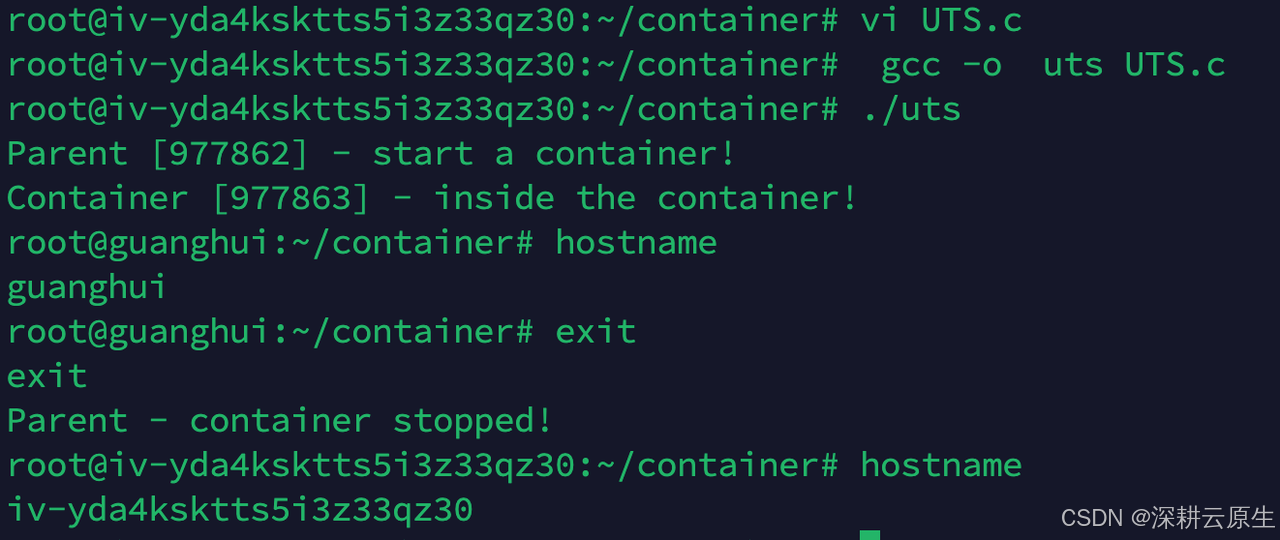
执行go run main.go
root@iv-yda4ksktts5i3z33qz30:~/container# go run main.go
查看以下是否真的进入了新的 UTS Namespace。 执行pstree -pl 重点关注:

main程序pid为979334,后续新创建的sh pid为979338,现在查看二者uts是否相同即可:

可以看到它们确实不在同一个UTS Namespace中。由于UTS Namespace对hostname做了隔离,所以在这个环境内修改hostname不影响外部主机。
PIDNamespace
每个容器都有自己的进程环境中,也就是相当于容器内进程的 PID 从 1 开始命名,此时主机上的 PID 其实也还是从 1 开始命名的,就相当于有两个进程环境:一个主机上的从 1 开始,另一个容器里的从 1 开始。
为啥 PID 从 1 开始就相当于进程环境的隔离了呢?因此在传统的 UNIX 系统中,PID 为 1 的进程是 init,地位特殊。它作为所有进程的父进程,有很多特权。另外,其还会检查所有进程的状态,我们知道如果某个进程脱离了父进程(父进程没有 wait 它),那么 init 就会负责回收资源并结束这个子进程。所以要想做到进程的隔离,首先需要创建出 PID 为 1 的进程。
int container_main(void* arg) {
printf("Container [%5d] - inside the container!\n", getpid());
sethostname("container_dawn", 15);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main() {
printf("Parent [%5d] - start a container!\n", getpid());
int container_id = clone(container_main, container_stack + STACK_SIZE,
CLONE_NEWUTS | CLONE_NEWPID | SIGCHLD, NULL);
waitpid(container_id, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
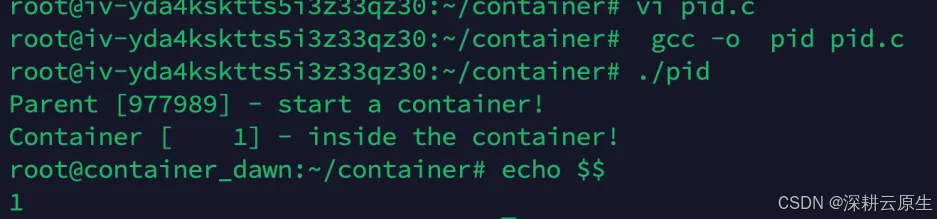
如果此时你在子进程的 shell 中输入 ps、top 等命令,我们还是可以看到所有进程。这是因为,ps、top 这些命令是去读 /proc 文件系统,由于此时文件系统并没有隔离,所以父进程和子进程通过命令看到的情况都是一样的。
go代码示例:
调整程序,增加 PID flags。
cmd.SysProcAttr = &syscall.SysProcAttr{
// Cloneflags: syscall.CLONE_NEWUTS,
// Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC,
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID,
}

发现pid 是1,说明再新开的 PID Namespace 中只有一个 bash 这个进程,而且被伪装成了 1 号进程。
IPCNamespace
常见的 IPC 有共享内存、信号量、消息队列等。当使用 IPC Namespace 把 IPC 隔离起来之后,只有同一个 Namespace 下的进程才能相互通信,因为主机的 IPC 和其他 Namespace 中的 IPC 都是看不到了的。而这个的隔离主要是因为创建出来的 IPC 都会有一个唯一的 ID,那么主要对这个 ID 进行隔离就好了。
想要启动 IPC 隔离,只需要在调用 clone 的时候加上 CLONE_NEWIPC 参数就可以了。
c代码示例:
int container_main(void* arg) {
printf("Container [%5d] - inside the container!\n", getpid());
sethostname("container_dawn", 15);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main() {
printf("Parent [%5d] - start a container!\n", getpid());
int container_id = clone(container_main, container_stack + STACK_SIZE,
CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWIPC | SIGCHLD, NULL);
waitpid(container_id, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
测试方法同下文
go代码示例:
IPC Namespace 用来隔离 sys V IPC和 POSIX message queues。
每个 IPC Namespace 都有自己的 Sys V IPC 和 POSIX message queues。
微调一下程序,只是修改了 Cloneflags,新增了 CLONE_NEWIPC,表示同时创建 IPC Namespace。
root@iv-yda4ksktts5i3z33qz30:~/container# cat main.go
package main
import (
"log"
"os"
"os/exec"
"syscall"
)
func main() {
cmd := exec.Command("sh")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
// Cloneflags: syscall.CLONE_NEWUTS,
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC,
}
if err := cmd.Run(); err != nil {
log.Fatalln(err)
}
}
运行并且进行测试:
# 先查看宿主机上的 ipc message queue
root@iZ2zed7Z:~# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
# 然后创建一个
root@iZ2zed7Z:~# ipcmk -Q
Message queue id: 0
# 再次查看,发现有了
root@iZ2zed7Z:~# ipcs -q
------ Message Queues --------
key msqid owner perms used-bytes messages
0x75c132a7 0 root 644 0 0
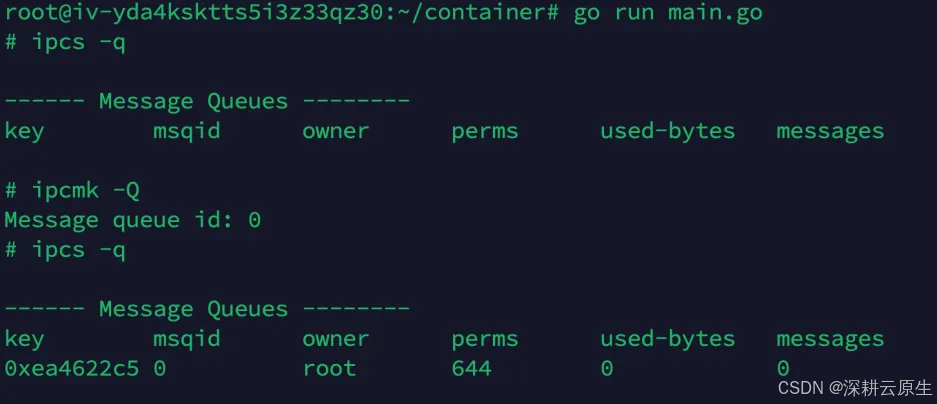
运行程序进入新的 shell

可以发现,在新的 Namespace 中已经看不到宿主机上的 message queue 了。说明 IPC Namespace 创建成功,IPC 已经被隔离。
Mount Namespace
Mount Namespace 可以让容器有自己的 root 文件系统。需要注意的是,在通过 CLONE_NEWNS 创建 mount namespace 之后,父进程会把自己的文件结构复制给子进程中。所以当子进程中不重新 mount 的话,子进程和父进程的文件系统视图是一样的,假如想要改变容器进程的视图,一定需要重新 mount(这个是 mount namespace 和其他 namespace 不同的地方)。
另外,子进程中新的 namespace 中的所有 mount 操作都只影响自身的文件系统(注意这边是 mount 操作,而创建文件等操作都是会有所影响的),而不对外界产生任何影响,这样可以做到比较严格地隔离(当然这边是除 share mount 之外的)。
下面我们重新挂载子进程的 /proc 目录,从而可以使用 ps 来查看容器内部的情况。
c代码示例:
int container_main(void* arg) {
printf("Container [%5d] - inside the container!\n", getpid());
sethostname("container_dawn", 15);
if (mount("proc", "/proc", "proc", 0, NULL) !=0 ) {
perror("proc");
}
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main() {
printf("Parent [%5d] - start a container!\n", getpid());
int container_id = clone(container_main, container_stack + STACK_SIZE,
CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL);
waitpid(container_id, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
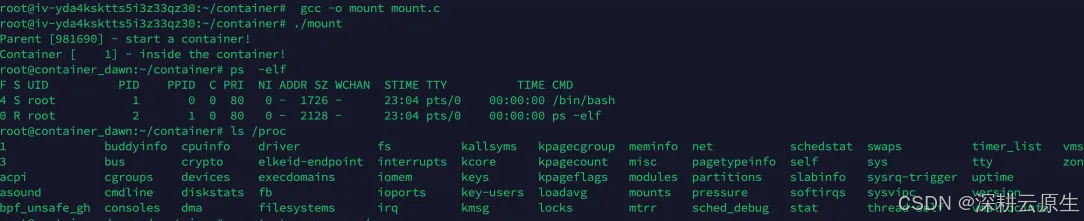
可以看到,在当前 Namespace 中 bash 为 1 号进程。
这就说明,当前 Mount Namespace 中的 mount 和外部是隔离的,mount 操作并没有影响到外部,Docker volume 也是利用了这个特性。
上面仅仅重新 mount 了 /proc 这个目录,其他的目录还是跟父进程一样视图的。一般来说,容器创建之后,容器进程需要看到的是一个独立的隔离环境,而不是继承宿主机的文件系统。所以需要 mount。整个rootfs 目录
这里将 busybox 镜像导出成一个 rootfs 目录,解压后在当前目录下执行改c代码:
char* const container_args[] = {
"/bin/sh",
NULL
};
int container_main(void* arg) {
printf("Container [%5d] - inside the container!\n", getpid());
sethostname("container_dawn", 15);
if (mount("proc", "rootfs/proc", "proc", 0, NULL) != 0) {
perror("proc");
}
if (mount("sysfs", "rootfs/sys", "sysfs", 0, NULL)!=0) {
perror("sys");
}
if (mount("none", "rootfs/tmp", "tmpfs", 0, NULL)!=0) {
perror("tmp");
}
if (mount("udev", "rootfs/dev", "devtmpfs", 0, NULL)!=0) {
perror("dev");
}
if (mount("devpts", "rootfs/dev/pts", "devpts", 0, NULL)!=0) {
perror("dev/pts");
}
if (mount("shm", "rootfs/dev/shm", "tmpfs", 0, NULL)!=0) {
perror("dev/shm");
}
if (mount("tmpfs", "rootfs/run", "tmpfs", 0, NULL)!=0) {
perror("run");
}
if ( chdir("./rootfs") || chroot("./") != 0 ){
perror("chdir/chroot");
}
// 改变根目录之后,那么 /bin/bash 是从改变之后的根目录中搜索了
execv(container_args[0], container_args);
perror("exec");
printf("Something's wrong!\n");
return 1;
}
int main() {
printf("Parent [%5d] - start a container!\n", getpid());
int container_id = clone(container_main, container_stack + STACK_SIZE,
CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL);
waitpid(container_id, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
实际上,Mount Namespace 是基于 chroot 的不断改良才被发明出来的,chroot 可以算是 Linux 中第一个 Namespace。那么上面被挂载在容器根目录上、用来为容器镜像提供隔离后执行环境的文件系统,就是所谓的容器镜像,也被叫做 rootfs(根文件系统)。需要明确的是,rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。
go代码示例:
在上文的基础上加上这一段测试即可
cmd.SysProcAttr = &syscall.SysProcAttr{
// Cloneflags: syscall.CLONE_NEWUTS,
// Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC,
// Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID,
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
User Namespace
User Narespace 主要是隔离用户的用户组ID。
也就是说,一个进程的 UserID 和GroupID 在不同的 User Namespace 中可以是不同的。
比较常用的是,在宿主机上以一个非 root 用户运行创建一个 User Namespace, 然后在 User Namespace 里面却映射成 root 用户。这意味着,这个进程在 User Namespace 里面有 root 权限,但是在 User Namespace 外面却没有 root 的权限。
int pipefd[2];
void set_map(char* file, int inside_id, int outside_id, int len) {
FILE* mapfd = fopen(file, "w");
if (NULL == mapfd) {
perror("open file error");
return;
}
fprintf(mapfd, "%d %d %d", inside_id, outside_id, len);
fclose(mapfd);
}
void set_uid_map(pid_t pid, int inside_id, int outside_id, int len) {
char file[256];
sprintf(file, "/proc/%d/uid_map", pid);
set_map(file, inside_id, outside_id, len);
}
int container_main(void* arg) {
printf("Container [%5d] - inside the container!\n", getpid());
printf("Container: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n",
(long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid());
/* 等待父进程通知后再往下执行(进程间的同步) */
char ch;
close(pipefd[1]);
read(pipefd[0], &ch, 1);
printf("Container [%5d] - setup hostname!\n", getpid());
//set hostname
sethostname("container",10);
//remount "/proc" to make sure the "top" and "ps" show container's information
mount("proc", "/proc", "proc", 0, NULL);
execv(container_args[0], container_args);
printf("Something's wrong!\n");
return 1;
}
int main() {
const int gid=getgid(), uid=getuid();
printf("Parent: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n",
(long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid());
pipe(pipefd);
printf("Parent [%5d] - start a container!\n", getpid());
int container_pid = clone(container_main, container_stack+STACK_SIZE,
CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWUSER | SIGCHLD, NULL);
printf("Parent [%5d] - Container [%5d]!\n", getpid(), container_pid);
//To map the uid/gid,
// we need edit the /proc/PID/uid_map (or /proc/PID/gid_map) in parent
set_uid_map(container_pid, 0, uid, 1);
printf("Parent [%5d] - user/group mapping done!\n", getpid());
/* 通知子进程 */
close(pipefd[1]);
waitpid(container_pid, NULL, 0);
printf("Parent - container stopped!\n");
return 0;
}
go代码示例:

可以看到,此时是 root 用户。
运行程序,进入新的 sh 环境,可以看到,UID 是不同的,说明 User Namespace 生效了。
Network Namespace
Network Namespace 是用来隔离网络设备、IP 地址端口等网络栈的 Namespace。 Network Namespace 可以让每个容器拥有自己独立的(虛拟的)网络设备,而且容器内的应用可以绑定到自己的端口,每个 Namespace 内的端口都不会互相冲突。
在宿主机上搭建网桥后,就能很方便地实现容器之间的通信,而且不同容器上的应用可以使用相同的端口。
go代码示例:
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWIPC | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS |
syscall.CLONE_NEWUSER | syscall.CLONE_NEWNET,
}
运行并测试:
先看宿主机的

有 lo、eth0 等10个设备,运行程序:

可以发现,新的 Namespace 中只有1个设备了,说明 Network Namespace 生效了。
namespace 系统调用与命名空间数据结构关系
进程数据结构
struct task_struct {
pid_t pid; // 进程ID
pid_t tgid; // 线程组ID
long state; // 进程状态
unsigned int prio; // 进程优先级
struct mm_struct *mm; // 内存描述符
struct fs_struct *fs; // 文件系统信息
struct files_struct *files; // 打开文件的信息
struct signal_struct *signal; // 信号处理信息
struct task_struct *parent; // 父进程
struct list_head children; // 子进程链表
struct list_head sibling; // 兄弟进程链表
struct nsproxy *nsproxy; // 命名空间信息
// 其他字段...
};
Namespace 数据结构
struct nsproxy {
atomic_t count; // 引用计数器,跟踪有多少进程使用这个 nsproxy 结构体
struct uts_namespace *uts_ns; // 指向 UTS(Unix Time-Sharing)命名空间的指针,管理主机名和域名
struct ipc_namespace *ipc_ns; // 指向 IPC(Inter-Process Communication)命名空间的指针,管理进程间通信资源
struct mnt_namespace *mnt_ns; // 指向挂载命名空间的指针,控制进程的文件系统挂载点视图
struct pid_namespace *pid_ns_for_children; // 指向 PID 命名空间的指针,用于子进程的进程 ID 视图
struct net *net_ns; // 指向网络命名空间的指针,管理进程的网络接口和协议栈
};
假设使用 unshare(CLONE_NEWNET) 创建一个新的网络命名空间,内核会执行以下操作:
- 创建一个新的 struct net 数据结构实例。
- 更新当前进程的 nsproxy 结构体中的 net_ns 指针,指向新的 struct net 实例。
- 进程在新的网络命名空间中将看到独立的网络接口和协议栈。
# 在新的网络命名空间中启动一个新的 shell
sudo unshare --net /bin/bash
# 在新的网络命名空间中查看网络接口,你会看到这里的网卡比宿主机少很多
ip a
# 创建并配置网络接口
ip link add veth0 type veth peer name veth1
ip link set veth0 up
ip addr add 192.168.1.1/24 dev veth0
ip link set veth1 up
# 退出新的命名空间
exit
2.Cgroups
cgroupsV1
cgroupsV2
本文示例为cgroup1,如果你的系统是cgroup2部分操作请参考上面文档
mount | grep cgroup 可以看本机的cgroup版本
● 在操作系统解决了 资源相互隔离 的问题之后,还需要解决 资源限制 的问题,即避免在同一个操作系统中,防止有些资源消耗较大的容器,将整个物理机器(宿主机)的硬件资源(如:CPU、内存等)占满。
● 在 Linux 系统中 cgropus 能够限制的资源列表如下:
子系统 功能
cpu 使用调度程序控制任务对 CPU 的使用。
cpuacct(CPU Accounting) 自动生成 cgroup 中任务对 CPU 资源使用情况的报告。
cpuset 为 cgroup 中的任务分配独立的 CPU (多处理器系统时)和内存。
devices 开启或关闭 cgroup 中任务对设备的访问。
freezer 挂起或恢复 cgroup 中的任务。
memory 设定 cgroup 中任务对内存使用量的限定,并生成这些任务对内存资源使用情况的报告。
perf_event(Linux CPU 性能探测器) 使 cgroup 中的任务可以进行统一的性能测试。
net_cls(Docker 未使用) 通过等级识别符标记网络数据包,从而允许 Linux 流量监控程序(Traffic Controller)识别从具体 cgroup 中生成的数据包。
● 查看系统实现的资源限制
cat /proc/cgroups
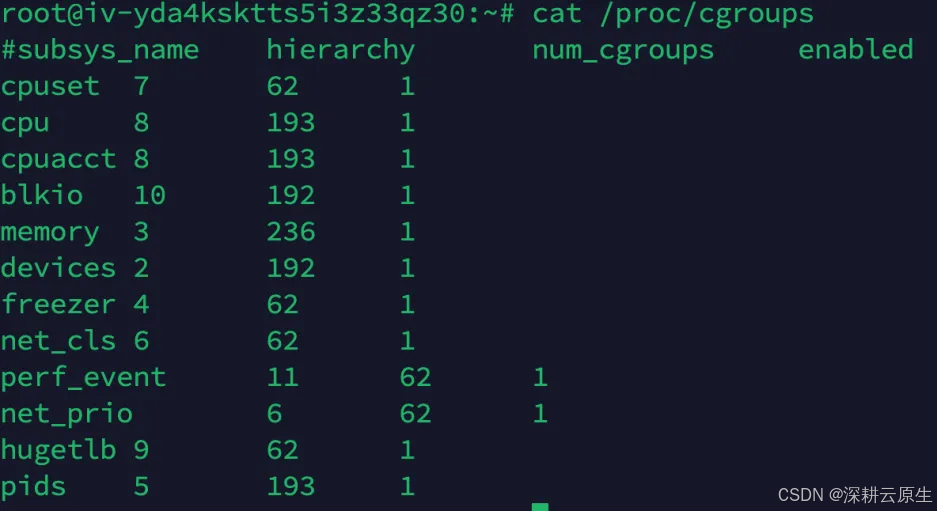
subsys_name: 控制器名称。
hierarchy: 控制器所属的层级(hierarchy)ID。
num_cgroups: 使用该控制器的 cgroups 数量。
enabled: 控制器是否启用(1 为启用,0 为禁用)。
● 查看所有的 cgroup 子系统
示例:查看CPU 子系统
ls /sys/fs/cgroup/cpu
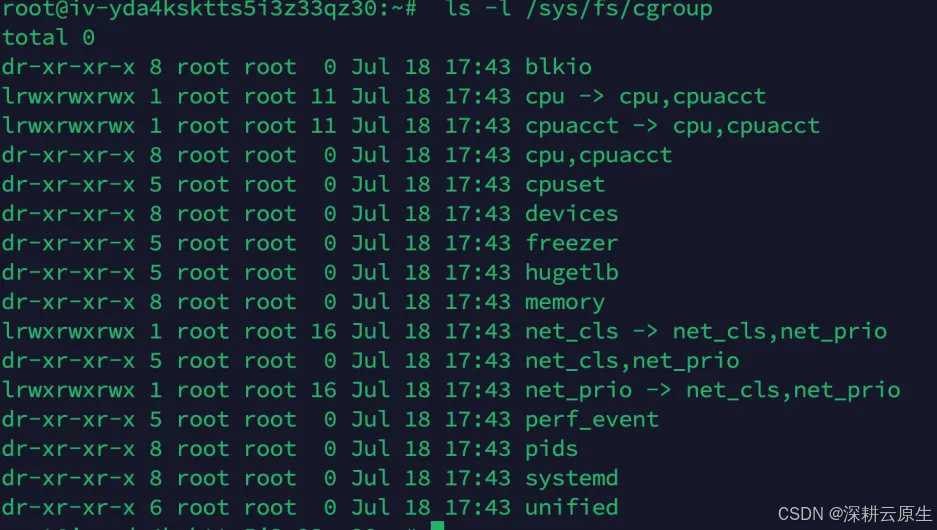
cpu.shares:可出让的能获得CPU 使用时间的相对值。
cpu.cfs_period_us:cfs_period_us 用来配置时间周期长度,单位为us(微秒)。
cpu.cfs_quota_us:cfs_quota_us 用来配置当前Cgroup 在cfs_period_us 时间内最多能使用的CPU时间数,单位为us(微秒)。
cpu.stat :Cgroup 内的进程使用的CPU 时间统计。
cfs_period 和 cfs_quota 这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间
那cgroup下的配置文件又是怎样实现资源限制的呢?
首先我们/sys/fs/cgroup/cpu目录下,新建一个container目录:

这个目录就称为一个“控制组”。你会发现,操作系统会在你新创建的 container 目录下,自动生成该子系统对应的资源限制文件
接下来执行这样这样一条脚本
root@iv-yda4ksktts5i3z33qz30:/sys/fs/cgroup/cpu/container# while : ; do : ; done &
[1] 985573
显然,它执行了一个死循环,可以把计算机的 CPU 吃到 100%,根据它的输出,我们可以看到这个脚本在后台运行的进程号(PID)是 985573,使用top命令可以看到985573这个进程的cpu到100%。
而此时,我们可以通过查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us)
root@iv-yda4ksktts5i3z33qz30:/sys/fs/cgroup/cpu/container# cat /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
-1
root@iv-yda4ksktts5i3z33qz30:/sys/fs/cgroup/cpu/container# cat /sys/fs/cgroup/cpu/container/cpu.cfs_period_us
100000
这时我们可以通过修改这些文件的内容来设置限制。比如,向 container 组里的 cfs_quota 文件写入 20 ms(20000 us):
echo 20000 > /sys/fs/cgroup/cpu/container/cpu.cfs_quota_us
在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程只能使用到 20% 的 CPU 带宽。
最后,我们把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了
echo 985573 > /sys/fs/cgroup/cpu/container/tasks
我们再次通过top查看进程资源消耗时,会发现进程985573 ()的cpu消耗在20%
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。而至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,比如这样一条命令:
[root@iv-ydcklmhi4gcva4fjq9ad ~]# docker run -it -d --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
[root@iv-ydcklmhi4gcva4fjq9ad ~]# docker ps |grep ubuntu |awk '{print $1}'
2c930cb4afb4
[root@iv-ydcklmhi4gcva4fjq9ad ~]# docker inspect 2c930cb4afb4|grep Pid
"Pid": 2956,
"PidMode": "",
"PidsLimit": null,
[root@iv-ydcklmhi4gcva4fjq9ad ~]# find /sys/fs/cgroup -type f -name 'cgroup.procs' -exec grep 2956 {} +
/sys/fs/cgroup/hugetlb/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/devices/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/freezer/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/memory/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/blkio/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/pids/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/cpuset/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/cpu,cpuacct/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/perf_event/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/net_cls,net_prio/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
/sys/fs/cgroup/systemd/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cgroup.procs:2956
[root@iv-ydcklmhi4gcva4fjq9ad ~]# cat /sys/fs/cgroup/cpu,cpuacct/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cpu.cfs_period_us
100000
[root@iv-ydcklmhi4gcva4fjq9ad ~]# cat /sys/fs/cgroup/cpu,cpuacct/system.slice/docker-2c930cb4afb45d8efcabafa576afaa1aabffa1bc9b967f9e65364d5045ff4ff2.scope/cpu.cfs_quota_us
20000
这就意味着这个 Docker 容器,只能使用到 20% 的 CPU 带宽。
3.OverlayFS
● OverlayFS 是一种堆叠文件系统,它依赖并建立在其它的文件系统之上,如:ext4fs 、xfs 等,但是 OverlayFS 并不直接参与磁盘空间结构的划分,仅仅将原来系统文件中的文件和目录进行 "合并"一起 的功能,最终给用户展示"合并"的文件是在同一级目录 的现象,这就是联合挂载技术,相对于 AUFS(Docker 1.12 之前使用的存储技术),OverlayFS 速度更快,实现更为简单。
● Linux 内核为 Docker 提供的 OverlayFS 驱动有两种:Overlay 和 Overlay2 。其中,Overlay2 是相对于 Overlay 的一种改进,在 Inode 利用率方面比 Overlay 更为高效。但是, Overlay 有环境的要求:Docker 版本是 17.06.02 + ,并且 宿主机文件系统需要是 EXT4 或 XFS 格式 。
OverlayFS 的实现方式
● OverlayFS 通过三个目录:lower 目录、upper 目录、以及 work 目录来实现的。其中,lower 目录可以是多个,upper 目录可以进行读写操作的目录,而 work 目录为工作基础目录,挂载后内容会被清空,并且在使用过程中其内容用户是不可见的,最后联合挂载完成之后给用户呈现的统一视图就被称为 merged 目录。

示例:演示 OverlayFS 挂载操作
#创建文件夹
mkdir /lower{1..3}
mkdir /upper /work /merged
#挂载文件系统
mount -t overlay overlay -o lowerdir=/lower1:/lower2:/lower3,upperdir=/upper,workdir=/work /merged
# 查看挂载
mount | grep merged
# 向 /upper 目录中写入文件
touch /upper/upper.txt
# 查看 /merged 中是否存在
ls -lah /merged
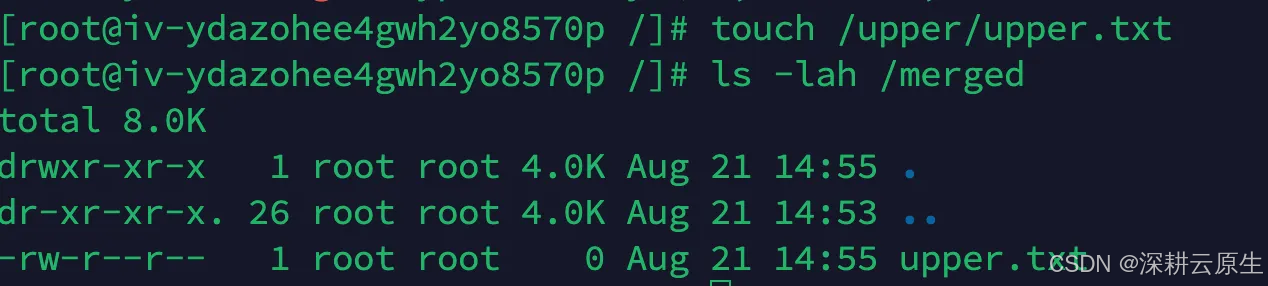
# 在 /merged 中写入文件,查看是否存储到了 /upper
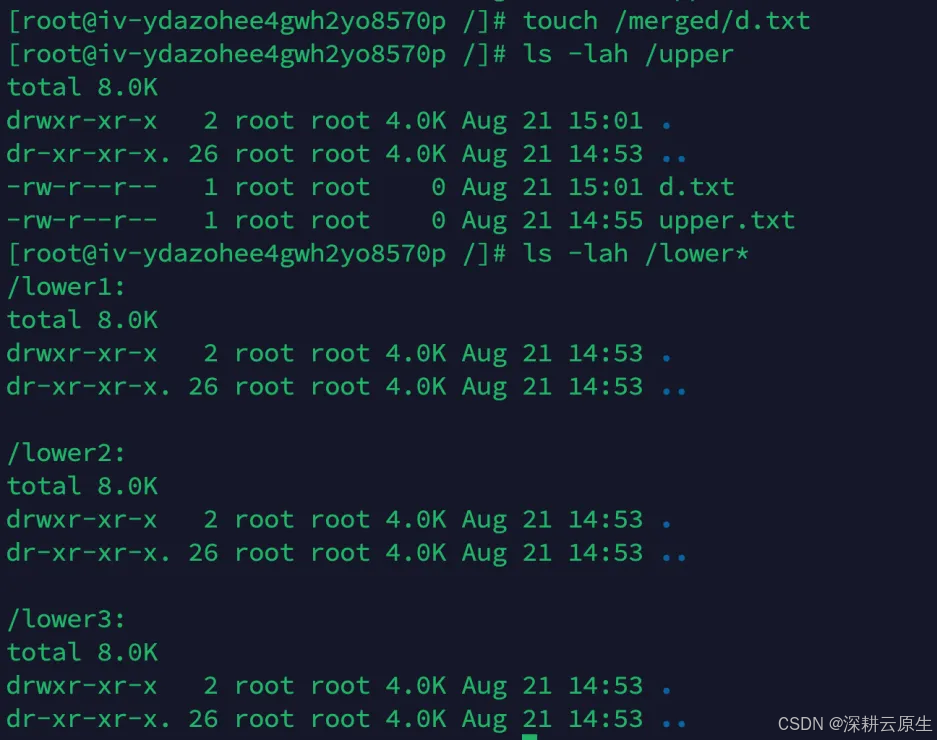
touch /merged/d.txt
ls -lah /upper
ls -lah /lower*
# 如果没有 upper 层,那么 merged 是只读的
umount /merged
mount -t overlay overlay -o lowerdir=/lower1:/lower2:/lower3 /merged
touch /merged/c.txt

Docker 中的 overlay 驱动

在上述图中可以看到三个层结构,即:lowerdir、uperdir、merged,其中 lowerdir 是只读的 image layer,其实就是 rootfs,对比我们上述演示的目录/lower{1…3},我们知道 image layer 可以分很多层,所以对应的 lowerdir 是可以有多个目录。而 upperdir 则是在 lowerdir 之上的一层,这层是读写层,在启动一个容器时候会进行创建,所有的对容器数据更改都发生在这里层,对比示例中的/upper 。最后 merged 目录是容器的挂载点,也就是给用户暴露的统一视角,对比示例中的 / tmp/test。而这些目录层都保存在了 / var/lib/docker/overlay2 / 或者 / var/lib/docker/overlay/(如果使用 overlay)。
● 启动一个容器,查看其 overlay 挂载点, 可以发现其挂载的 merged 目录、lowerdir、upperdir 以及 workdir:
[root@iv-ydazohee4gwh2yo8570p /]# docker run -it --name test ubuntu /bin/bash
root@4328559f09e6:/# ls
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
root@4328559f09e6:/# mount |grep overlay
overlay on / type overlay (rw,relatime,lowerdir=/var/lib/docker/overlay2/l/KPUNXRY4NPVEN3MNK63LYLQI4A:/var/lib/docker/overlay2/l/S3NMVWNMTQJINAGVINQEOIAVLB,
upperdir=/var/lib/docker/overlay2/48337e1a795feee8d387bd31ccb902810874e6f08a98feeb8ff533cee0160a8d/diff,
workdir=/var/lib/docker/overlay2/48337e1a795feee8d387bd31ccb902810874e6f08a98feeb8ff533cee0160a8d/work)

在容器中创建了一文件,此时到宿主的 merged 目录就能看到对应的文件:
root@4328559f09e6:/# touch /tmp/zgh.txt
root@4328559f09e6:/# echo "hello" >>/tmp/zgh.txt
root@4328559f09e6:/# exit
exit
[root@iv-ydazohee4gwh2yo8570p /]# ls /var/lib/docker/overlay2/48337e1a795feee8d387bd31ccb902810874e6f08a98feeb8ff533cee0160a8d/diff
root tmp
[root@iv-ydazohee4gwh2yo8570p /]# cat /var/lib/docker/overlay2/48337e1a795feee8d387bd31ccb902810874e6f08a98feeb8ff533cee0160a8d/diff/tmp/zgh.txt
hello

4.重新认识容器
在namespace系统调用中想必你已经知道进程的Namespace是可以进入的,容器本身就是个进程。一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
而这个操作所依赖的,乃是一个名叫 setns() 的 Linux 系统调用。它的调用方法,我可以用如下一段小程序为你说明:
#define _GNU_SOURCE
#include <fcntl.h>
#include <sched.h>
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#define errExit(msg) do { perror(msg); exit(EXIT_FAILURE);} while (0)
int main(int argc, char *argv[]) {
int fd;
fd = open(argv[1], O_RDONLY);
if (setns(fd, 0) == -1) {
errExit("setns");
}
execvp(argv[2], &argv[2]);
errExit("execvp");
}
这段代码功能非常简单:它一共接收两个参数,第一个参数是 argv[1],即当前进程要加入的 Namespace 文件的路径,比如 /proc/25686/ns/net;而第二个参数,则是你要在这个 Namespace 里运行的进程,比如 /bin/bash。
这段代码的的核心操作,则是通过 open() 系统调用打开了指定的 Namespace 文件,并把这个文件的描述符 fd 交给 setns() 使用。在 setns() 执行后,当前进程就加入了这个文件对应的 Linux Namespace 当中了。
现在,你可以编译执行一下这个程序,加入到容器进程(PID=25686)的 Network Namespace 中:
$ gcc -o set_ns set_ns.c
$ ./set_ns /proc/25686/ns/net /bin/bash
$ ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:02
inet addr:172.17.0.2 Bcast:0.0.0.0 Mask:255.255.0.0
inet6 addr: fe80::42:acff:fe11:2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:12 errors:0 dropped:0 overruns:0 frame:0
TX packets:10 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:976 (976.0 B) TX bytes:796 (796.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
正如上所示,当我们执行 ifconfig 命令查看网络设备时,我会发现能看到的网卡“变少”了:只有两个。而我的宿主机则至少有四个网卡。这是怎么回事呢?
实际上,在 setns() 之后我看到的这两个网卡,正是我在前面启动的 Docker 容器里的网卡。也就是说,我新创建的这个 /bin/bash 进程,由于加入了该容器进程(PID=25686)的 Network Namepace,它看到的网络设备与这个容器里是一样的,即:/bin/bash 进程的网络设备视图,也被修改了。
而一旦一个进程加入到了另一个 Namespace 当中,在宿主机的 Namespace 文件上,也会有所体现。
在宿主机上,你可以用 ps 指令找到这个 set_ns 程序执行的 /bin/bash 进程,其真实的 PID 是 28499:
# 在宿主机上
ps aux | grep /bin/bash
root 28499 0.0 0.0 19944 3612 pts/0 S 14:15 0:00 /bin/bash
这时,如果按照前面介绍过的方法,查看一下这个 PID=28499 的进程的 Namespace,你就会发现这样一个事实:
$ ls -l /proc/28499/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:18 /proc/28499/ns/net -> net:[4026532281]
$ ls -l /proc/25686/ns/net
lrwxrwxrwx 1 root root 0 Aug 13 14:05 /proc/25686/ns/net -> net:[4026532281]
在 /proc/[PID]/ns/net 目录下,这个 PID=28499 进程,与我们前面的 Docker 容器进程(PID=25686)指向的 Network Namespace 文件完全一样。这说明这两个进程,共享了这个名叫 net:[4026532281] 的 Network Namespace。
此外,Docker 还专门提供了一个参数,可以让你启动一个容器并“加入”到另一个容器的 Network Namespace 里,这个参数就是 -net,比如:
$ docker run -it --net container:4ddf4638572d busybox ifconfig
这样,我们新启动的这个容器,就会直接加入到 ID=4ddf4638572d 的容器,而如果我指定–net=host,就意味着这个容器不会为进程启用 Network Namespace。这就意味着,这个容器拆除了 Network Namespace 的“隔离墙”,所以,它会和宿主机上的其他普通进程一样,直接共享宿主机的网络栈。这就为容器直接操作和使用宿主机网络提供了一个渠道。
5.问题
创建了测试pod,进入容器终端后发现top命令统计的还是宿主机的数据,原因是: /proc不了解cgroups限制的存在。这个问题为什么没有部署lxcfs进行修正?
例子:比如说宿主机内存为64G,设置容器的内存为4G,在容器上运行java应用程序,由于没有设置jvm参数,即默认的,最后oom了,用命令查看容器的内存占用情况,竟然发现内存竟然有60多g。 那应该显示的是宿主机的内存了,jvm按照宿主机内存大小分配的默认内存应该大于4g 所以还没full gc 就oom了。这也是在企业中,容器化应用碰到的一个常见问题,也是容器相较于虚拟机另一个不尽如人意的地方。
问题解决:
在社区查询后了解到,java为了更好的使用容器环境,在Java 10 引入了 +UseContainerSupport(默认情况下启用),通过这个特性,可以使得JVM在容器环境分配合理的堆内存。
后来这个特性也合入了JDK8U191版本,在JDK8U191版本之后的java8也是可以获取容器的内存限制的。
UseContainerSupport允许JVM 从主机读取cgroup限制,例如可用的CPU和RAM,并进行相应的配置。这样当容器超过内存限制时,会抛出OOM异常,而不是杀死容器。 该特性在Java 8u191 +,10及更高版本上可用
在应用的启动参数,设置 -XX:+UseContainerSupport,设置-XX:MaxRAMPercentage=75.0,这样为其他进程(debug、监控)留下足够的内存空间,又不会太浪费RAM。
-XX:MaxRAMPercentage=75.0:这意味着 JVM 会将容器可用内存的 75% 作为最大堆内存(即 -Xmx 的值)。如果容器限制了内存,例如通过 Kubernetes resources.limits.memory 指定了 4Gi 内存,那么 JVM 的最大堆内存将是 4Gi 的 75%,即 3Gi。
测试容器中 /proc 文件系统对 Cgroups 资源限制的反映情况,可以使用一个简单的 Java 应用程序来查看容器内获取的内存和 CPU 信息:
ResourceInfo.java
public class ResourceInfo {
public static void main(String[] args) {
// 获取 JVM 可用内存
long maxMemory = Runtime.getRuntime().maxMemory();
// 获取 JVM 可用的处理器数量
int availableProcessors = Runtime.getRuntime().availableProcessors();
System.out.println("Max Memory (bytes): " + maxMemory);
System.out.println("Available Processors: " + availableProcessors);
// 转换为人类可读格式
long maxMemoryMB = maxMemory / (1024 * 1024);
System.out.println("Max Memory (MB): " + maxMemoryMB);
}
}
manifest.txt
Main-Class: ResourceInfo
javac ResourceInfo.java
jar -cf resourceinfo.jar ResourceInfo.class
# 使用官方的 OpenJDK 作为基础镜像
FROM openjdk:8-jre-alpine
# 将编译后的 JAR 文件复制到容器中
COPY resourceinfo.jar /app/resourceinfo.jar
# 运行 Java 应用程序
CMD ["java", "-jar", "/app/resourceinfo.jar"]
docker build -t your_docker_registry/resourceinfo:v1 .
docker push your_docker_registry/resourceinfo:v1
```yaml
apiVersion: v1
kind: Pod
metadata:
name: resourceinfo-pod
spec:
containers:
- name: resourceinfo
image: your_docker_registry/resourceinfo:v1
resources:
limits:
memory: "512Mi"
cpu: "1"
kubectl logs resourceinfo-pod
持续更新中关注不迷糊。。。