特征处理
import os
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.impute import SimpleImputer
from sklearn.pipeline import FeatureUnion
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelBinarizer
from sklearn.base import BaseEstimator, TransformerMixin
# 读取数据
# 数据来源:https://github.com/bophancong/Handson_ml2-master/tree/master/datasets/housing
housing = pd.read_csv("housing.csv")
# income_cat
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"]<5, 5.0, inplace=True)
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
# 分层抽样:根据 income_cat 划分数据集
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
# 删除 income_cat
for set in (strat_train_set, strat_test_set):
set.drop(["income_cat"], axis=1, inplace=True)
###################我们有了训练集和测试集#####################################
# 处理训练集
# 将特征和目标值拆分
train_features = strat_train_set.drop('median_house_value', axis=1)
train_target = strat_train_set['median_house_value'].copy()
# 测试集
test_features = strat_test_set.drop('median_house_value', axis=1)
test_target = strat_test_set['median_house_value'].copy()
# 查看离散特征和连续特征个数 【记得把id和标签去掉】
cat_features = list(train_features.select_dtypes(include=['object']))
print('离散特征Categorical: {} features'.format(len(cat_features)))
cont_features = [cont for cont in list(train_features.select_dtypes(include=['float64','int64'])) if cont not in ['median_house_value','id']]
print('连续特征Continuous: {} features'.format(len(cont_features)))# 利用下面的四个特征构造新特征
rooms_ix, bedrooms_ix, population_ix, household_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_pre_room=True):
self.add_bedrooms_pre_room = add_bedrooms_pre_room
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
rooms_pre_household = X[:, rooms_ix] / X[:, household_ix]
population_pre_household = X[:, population_ix] / X[:, household_ix]
if self.add_bedrooms_pre_room:
bedrooms_pre_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_pre_household, population_pre_household, bedrooms_pre_room]
else:
return np.c_[X, rooms_pre_household, population_pre_household]
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names=attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values
class MyLabelBinarizer(BaseEstimator, TransformerMixin):
def __init__(self, *args, **kwargs):
self.encoder = LabelBinarizer(*args, **kwargs)
def fit(self, x, y=None):
self.encoder.fit(x)
return self
def transform(self, x, y=None):
return self.encoder.transform(x)train_num = train_features.drop('ocean_proximity', axis=1)
num_attribs = list(train_num)
cat_attribs = ['ocean_proximity']
num_pipline = Pipeline([('selector', DataFrameSelector(num_attribs)),
('imputer', SimpleImputer(strategy='median')),
('attribs_addr', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
cat_pipline = Pipeline([('selector', DataFrameSelector(cat_attribs)),
('label_binarizer', MyLabelBinarizer()),
])
full_pipeline = FeatureUnion(transformer_list=[('num_pipeline', num_pipline),
('cat_pipeline', cat_pipline),
])
final_train_features = full_pipeline.fit_transform(train_features)
final_train_target = train_target
# 同样的道理可以处理test_features
final_test_features = full_pipeline.transform(test_features)
final_test_target = test_target至此,训练集的特征和目标值,以及测试集的特征和目标值均已经可用。。。
尝试各个机器学习方法,找到最优
线性回归
# 回归模型
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 线性回归
lin_reg = LinearRegression();
lin_reg.fit(final_train_features, final_train_target)
# 计算RSME
lr_pred_train_target = lin_reg.predict(final_train_features)
lin_mse = mean_squared_error(final_train_target, lr_pred_train_target)
lin_rmse = np.sqrt(lin_mse)
# 打印lin_rmse 的值
print(lin_rmse)决策树
# 决策树
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor();
tree_reg.fit(final_train_features, final_train_target)
dtr_pred_train_target = tree_reg.predict(final_train_features)
tree_mse = mean_squared_error(final_train_target, dtr_pred_train_target)
tree_rmse = np.sqrt(tree_mse)
# tree_rmse 的值
print(tree_rmse)随机森林
# 随机森林
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor()
forest_reg.fit(final_train_features, final_train_target)
rf_pred_train_target = forest_reg.predict(final_train_features)
forest_mse = mean_squared_error(final_train_target, rf_pred_train_target)
forest_rmse = np.sqrt(forest_mse)
# 打印结果
print(forest_rmse)分别交叉验证
# 使用交叉验证来做更佳的评估
from sklearn.model_selection import cross_val_score
# 定义一个函数来打印交叉验证的结果
def displayScores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Std:", scores.std())
# 计算决策树模型的交叉验证结果
dtr_scores = cross_val_score(tree_reg, final_train_features, final_train_target,
scoring='neg_mean_squared_error', cv=10)
tree_rmse_scores = np.sqrt(-dtr_scores)
print("---------Decision Tree Regression")
displayScores(tree_rmse_scores)
# 计算线性模型的交叉验证结果
lr_scores = cross_val_score(lin_reg, final_train_features, final_train_target,
scoring='neg_mean_squared_error', cv=10)
lin_rmse_scores = np.sqrt(-lr_scores)
print("---------Linear Regression")
displayScores(lin_rmse_scores)
# 随机森林
rf_scores = cross_val_score(forest_reg, final_train_features, final_train_target,
scoring='neg_mean_squared_error', cv=10)
forest_rmse_scores = np.sqrt(-rf_scores)
print("---------Random Forest")
displayScores(forest_rmse_scores)- 普通逻辑回归:显然回归模型欠拟合,特征没有提供足够多的信息来做一个好的预测,或者模型不够强大
- 普通决策树结果:显然模型可能过拟合
- 交叉验证结果:判断没错:决策树模型过拟合很严重,它的性能比线性回归模型还差
- 目前来看,随机森林效果是最好的,下面对随机森林模型进行模型微调
模型保存和读取
# 保存模型
import joblib
output_path = 'model/'
if not os.path.isdir(output_path):
os.makedirs(output_path)
joblib.dump(forest_reg, output_path+'forest_reg.pkl')
# 清除缓存
import gc
del forest_reg
gc.collect()
# 加载离线模型,并且测试
forest_reg = joblib.load(output_path + 'forest_reg.pkl')
forest_reg.predict(final_train_features)对最优的机器学习方法调参
- 网格搜索
- 随机搜索
- 集成方法
网格搜索
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestRegressor
param_grid = [
{'n_estimators': [3,10,30], 'max_features': [2,4,6,8]},
{'bootstrap': [False], 'n_estimators': [3,10], 'max_features': [2,3,4]},
]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring='neg_mean_squared_error')
grid_search.fit(final_train_features, final_train_target)
# 打印grid_search.best_params_
print(grid_search.best_params_)
print(grid_search.best_estimator_)
# 评估每个参数组合的评分
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres['mean_test_score'], cvres['params']):
print(np.sqrt(-mean_score), params)随机搜索
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestRegressor
distributions = dict(n_estimators=[3,10,30], max_features=[2,4,6,8])
forest_reg_rs = RandomForestRegressor()
grid_search_rs = RandomizedSearchCV(forest_reg_rs, distributions,
random_state=0, cv=5,
scoring='neg_mean_squared_error')
grid_search_rs.fit(final_train_features, final_train_target)
# 打印grid_search.best_params_
print(grid_search_rs.best_params_)
print(grid_search_rs.best_estimator_)
# 评估评分
cvres_rs = grid_search_rs.cv_results_
for mean_score_rs, params_rs in zip(cvres_rs['mean_test_score'], cvres_rs['params']):
print(np.sqrt(-mean_score_rs), params_rs)集成方法
暂无
分析最佳模型和他们的误差
- 根据特征重要性,丢弃一些无用特征
- 观察系统误差,搞清为什么有这些误差,如何改正问题(添加、去掉、清洗异常值等措施)
# 打印特征重要性
feature_importances = grid_search_rs.best_estimator_.feature_importances_
# 获取特征名称
# 对于数值特征,直接使用 num_attribs
# 对于分类特征,使用 MyLabelBinarizer 转换后的特征名称
label_binarizer = MyLabelBinarizer()
label_binarizer.fit(train_features['ocean_proximity'])
cat_feature_names = label_binarizer.encoder.classes_
# 构造完整的特征名称列表
feature_names = num_attribs + ['rooms_per_household', 'population_per_household', 'bedrooms_per_room'] + list(cat_feature_names)
# 确保特征重要性的长度与特征名称列表的长度相匹配
# 由于分类特征被转换为独热编码,每个分类特征将有多个特征重要性值
# 我们需要扩展特征重要性数组以匹配特征名称列表的长度
extended_importances = np.zeros(len(feature_names))
num_features = len(num_attribs) + 3 # 数值特征 + 新增的3个特征
extended_importances[:num_features] = feature_importances[:num_features]
extended_importances[num_features:] = feature_importances[num_features:]
# 将特征重要性和特征名称组合成一个DataFrame
feature_importances_df = pd.DataFrame({
'feature': feature_names,
'importance': extended_importances
}).sort_values('importance', ascending=False)
# 打印每个特征的重要性
print(feature_importances_df)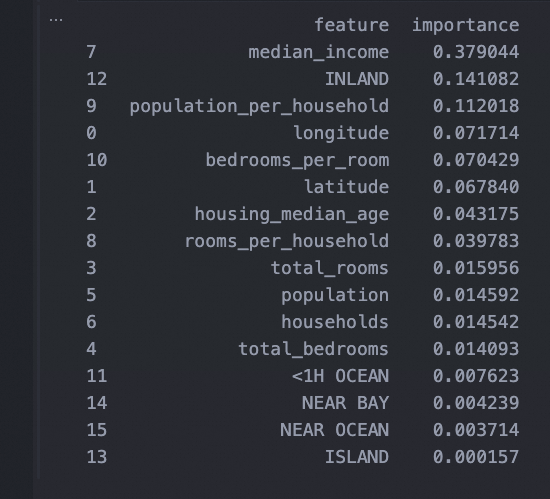
测试集评估
from sklearn.metrics import mean_squared_error
final_model = grid_search.best_estimator_
final_predictions = final_model.predict(final_test_features)
final_mse = mean_squared_error(final_test_target, final_predictions)
final_rmse = np.sqrt(final_mse)
print(final_rmse)代码汇总
import os
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.impute import SimpleImputer
from sklearn.pipeline import FeatureUnion
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelBinarizer
from sklearn.base import BaseEstimator, TransformerMixin
# 读取数据
# 数据来源:https://github.com/bophancong/Handson_ml2-master/tree/master/datasets/housing
housing = pd.read_csv("housing.csv")
# income_cat
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"]<5, 5.0, inplace=True)
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
# 分层抽样:根据 income_cat 划分数据集
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
# 删除 income_cat
for set in (strat_train_set, strat_test_set):
set.drop(["income_cat"], axis=1, inplace=True)
###################我们有了训练集和测试集#####################################
# 处理训练集
# 将特征和目标值拆分
train_features = strat_train_set.drop('median_house_value', axis=1)
train_target = strat_train_set['median_house_value'].copy()
# 测试集
test_features = strat_test_set.drop('median_house_value', axis=1)
test_target = strat_test_set['median_house_value'].copy()
# 利用下面的四个特征构造新特征
rooms_ix, bedrooms_ix, population_ix, household_ix = 3, 4, 5, 6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_pre_room=True):
self.add_bedrooms_pre_room = add_bedrooms_pre_room
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
rooms_pre_household = X[:, rooms_ix] / X[:, household_ix]
population_pre_household = X[:, population_ix] / X[:, household_ix]
if self.add_bedrooms_pre_room:
bedrooms_pre_room = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_pre_household, population_pre_household, bedrooms_pre_room]
else:
return np.c_[X, rooms_pre_household, population_pre_household]
# 特征选择
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names=attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names].values
# 标签编码
class MyLabelBinarizer(BaseEstimator, TransformerMixin):
def __init__(self, *args, **kwargs):
self.encoder = LabelBinarizer(*args, **kwargs)
def fit(self, x, y=None):
self.encoder.fit(x)
return self
def transform(self, x, y=None):
return self.encoder.transform(x)
train_num = train_features.drop('ocean_proximity', axis=1)
num_attribs = list(train_num)
cat_attribs = ['ocean_proximity']
num_pipline = Pipeline([('selector', DataFrameSelector(num_attribs)),
('imputer', SimpleImputer(strategy='median')),
('attribs_addr', CombinedAttributesAdder()),
('std_scaler', StandardScaler()),
])
cat_pipline = Pipeline([('selector', DataFrameSelector(cat_attribs)),
('label_binarizer', MyLabelBinarizer()),
])
full_pipeline = FeatureUnion(transformer_list=[('num_pipeline', num_pipline),
('cat_pipeline', cat_pipline),
])
final_train_features = full_pipeline.fit_transform(train_features)
final_train_target = train_target
# 同样的道理可以处理test_features
final_test_features = full_pipeline.transform(test_features)
final_test_target = test_target
# 随机搜索
from sklearn.model_selection import RandomizedSearchCV
from sklearn.ensemble import RandomForestRegressor
distributions = dict(n_estimators=[3,10,30], max_features=[2,4,6,8])
forest_reg_rs = RandomForestRegressor()
grid_search_rs = RandomizedSearchCV(forest_reg_rs, distributions,
random_state=0, cv=5,
scoring='neg_mean_squared_error')
grid_search_rs.fit(final_train_features, final_train_target)
# 打印特征重要性
feature_importances = grid_search_rs.best_estimator_.feature_importances_
# 获取特征名称
# 对于数值特征,直接使用 num_attribs
# 对于分类特征,使用 MyLabelBinarizer 转换后的特征名称
label_binarizer = MyLabelBinarizer()
label_binarizer.fit(train_features['ocean_proximity'])
cat_feature_names = label_binarizer.encoder.classes_
# 构造完整的特征名称列表
feature_names = num_attribs + ['rooms_per_household', 'population_per_household', 'bedrooms_per_room'] + list(cat_feature_names)
# 确保特征重要性的长度与特征名称列表的长度相匹配
# 由于分类特征被转换为独热编码,每个分类特征将有多个特征重要性值
# 我们需要扩展特征重要性数组以匹配特征名称列表的长度
extended_importances = np.zeros(len(feature_names))
num_features = len(num_attribs) + 3 # 数值特征 + 新增的3个特征
extended_importances[:num_features] = feature_importances[:num_features]
extended_importances[num_features:] = feature_importances[num_features:]
# 将特征重要性和特征名称组合成一个DataFrame
feature_importances_df = pd.DataFrame({
'feature': feature_names,
'importance': extended_importances
}).sort_values('importance', ascending=False)
# 打印每个特征的重要性
print(feature_importances_df)
from sklearn.metrics import mean_squared_error
final_model = grid_search_rs.best_estimator_
final_predictions = final_model.predict(final_test_features)
final_mse = mean_squared_error(final_test_target, final_predictions)
final_rmse = np.sqrt(final_mse)
print(final_rmse)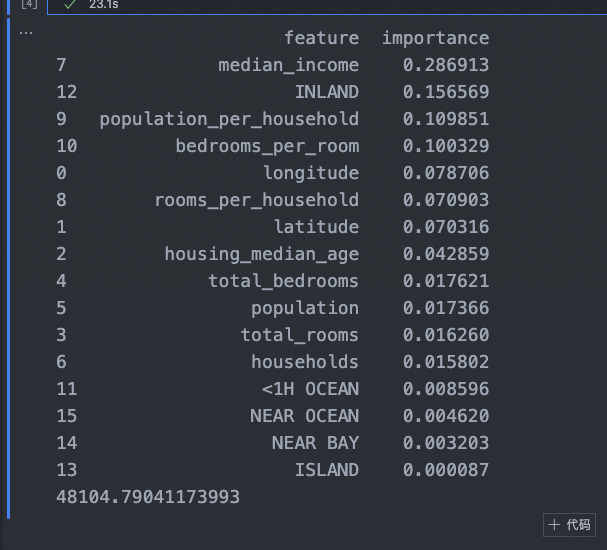
参考:
- Machine-Learning/ML_0_20201224_前言.ipynb at master · myhaa/Machine-Learning · GitHub
- Machine-Learning/ML_2_20201225_一个完整的机器学习项目.ipynb at master · myhaa/Machine-Learning · GitHub







![[系统设计总结] - Proximity Service算法介绍](https://i-blog.csdnimg.cn/direct/1688ec6ae66749c799f876e0a965ce7d.png)









