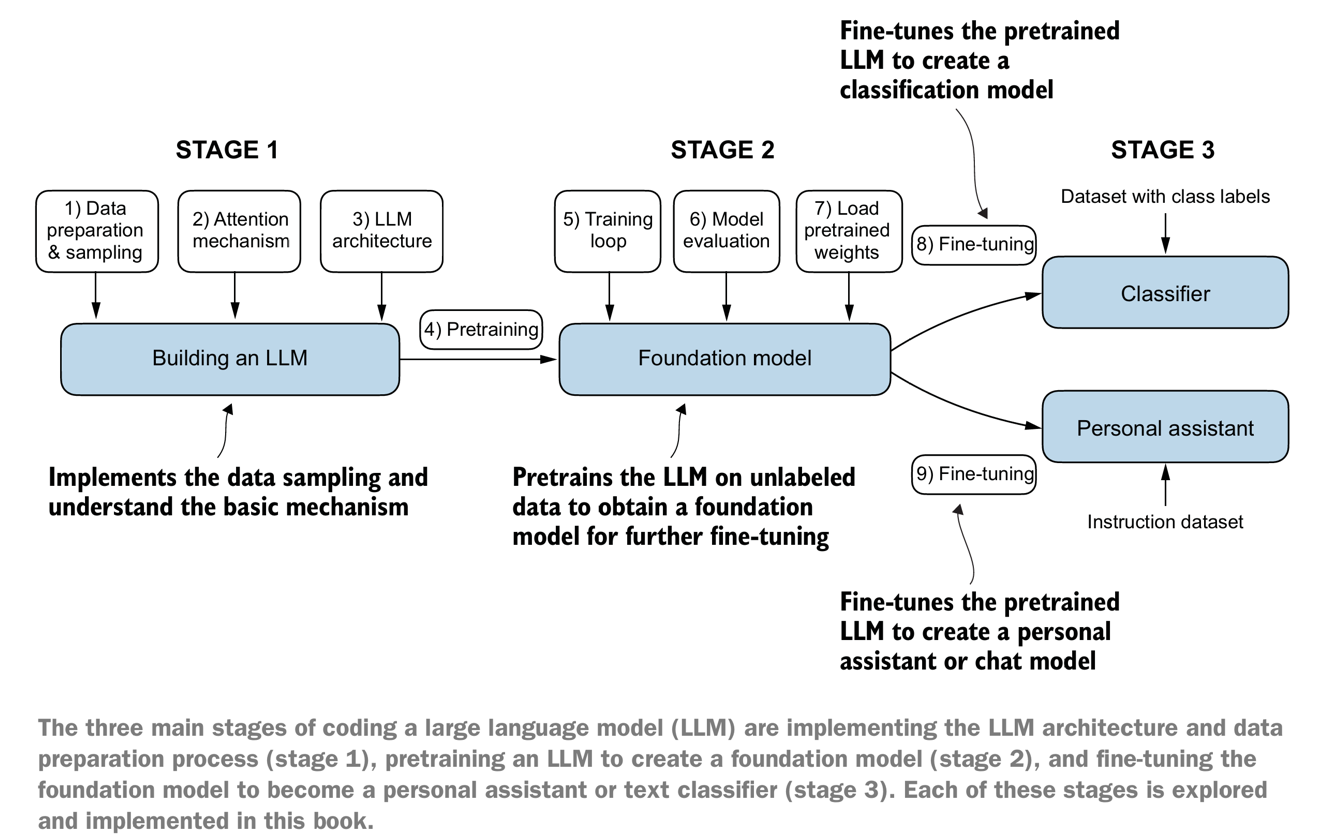
SQL面试常见题目涉及多个方面,包括数据查询、数据操作、表的设计与优化等。以下列举一些经典的SQL面试题目,并附上解析答案:
1. 查询一张表中重复的数据
题目:
给定一个表 employees,包含 id, name, salary 列。如何查找表中重复的 name 值?
SELECT name, COUNT(*) as count FROM employees GROUP BY name HAVING COUNT(*) > 1;
解析:
通过 GROUP BY 将 name 列分组,并使用 HAVING COUNT(*) > 1 来过滤掉那些重复出现的 name。COUNT(*) 用于统计每个 name 出现的次数。
2. 查找第 N 高的薪水
题目:
如何查询员工表 employees 中的第 N 高的薪水?
SELECT DISTINCT salary FROM employees ORDER BY salary DESC LIMIT 1 OFFSET N-1;
解析:
使用 ORDER BY salary DESC 按工资降序排序,并通过 LIMIT 1 OFFSET N-1 跳过前 N-1 个记录,直接选出第 N 高的薪水。DISTINCT 确保只返回不同的薪水值。
3. 自连接:查找员工的直属上司
题目:
有一个员工表 employees,其中有 id、name 和 manager_id,每个员工都有一个直属上司,manager_id 是上司的员工ID。写一个 SQL 查询,找出每个员工及其上司的姓名。
SELECT e.name AS employee_name, m.name AS manager_name
FROM employees e LEFT JOIN employees m ON e.manager_id = m.id;
解析:
通过自连接将员工表连接两次,分别表示员工和上司。LEFT JOIN 确保即使某些员工没有上司(如CEO),也能查询到其信息。
4. 删除表中重复记录,保留一条
题目:
给定一个表 employees,如何删除表中的重复记录,只保留一条?
DELETE FROM employees WHERE id NOT IN ( SELECT MIN(id) FROM employees GROUP BY name, salary );
解析:SELECT MIN(id) 从每组相同的 name 和 salary 中选择最小的 id,通过 DELETE 删除那些 id 不在这些最小值中的记录。
5. 查找两个表中共有的数据
题目:
给定两个表 employees 和 departments,如何查找两张表中共有的 name?
SELECT e.name FROM employees e INNER JOIN departments d ON e.name = d.name;
解析:
使用 INNER JOIN 将 employees 和 departments 表按 name 进行匹配,返回共有的 name。
6. 获取每个部门的最高薪资员工
题目:
给定一个 employees 表(包含 id, name, salary, department_id 列),如何查询每个部门中薪资最高的员工?
SQL 查询:
SELECT e1.department_id, e1.name, e1.salary FROM employees e1 WHERE e1.salary = ( SELECT MAX(e2.salary) FROM employees e2 WHERE e2.department_id = e1.department_id ); 解析:
使用子查询 SELECT MAX(e2.salary) 来获取每个部门的最高薪资,并通过外层查询获取对应的员工信息。

7. 统计表中每个部门的人数
题目:
给定一个员工表 employees,如何统计每个部门的员工数量?
SELECT department_id, COUNT(*) AS employee_count FROM employees
GROUP BY department_id;
解析:
使用 GROUP BY 按部门分组,COUNT(*) 统计每个部门的员工数量。
8. 查询日期范围内的数据
题目:
查询 employees 表中 hire_date 在 2022-01-01 到 2022-12-31 之间的员工信息。
SELECT * FROM employees WHERE hire_date BETWEEN '2022-01-01' AND '2022-12-31';
解析:
使用 BETWEEN 语法进行日期范围过滤,确保 hire_date 在指定的时间范围内。
9. 找出工资比上司高的员工
题目:
如何找出工资比直属上司高的员工?
SQL 查询:
SELECT e.name AS employee_name, e.salary AS employee_salary, m.salary AS manager_salary FROM employees e JOIN employees m ON e.manager_id = m.id WHERE e.salary > m.salary;
解析:
通过自连接员工表,分别表示员工和上司,并通过 WHERE 过滤出那些员工工资高于上司工资的记录。
10. 查找连续出现的记录(未懂)
题目:
如何查询表中某个字段连续出现多次的记录?例如,查找某个用户登录连续3天以上的记录。
SQL 查询:
SELECT user_id, login_date FROM ( SELECT user_id, login_date, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY login_date) - ROW_NUMBER() OVER (ORDER BY login_date) AS grp FROM logins ) t GROUP BY user_id, grp HAVING COUNT(*) >= 3;
解析:
使用窗口函数 ROW_NUMBER() 来生成连续行的编号,并通过计算差值将连续登录的记录分为一组,最后通过 HAVING COUNT(*) >= 3 筛选出连续登录超过3天的用户。
这些是SQL面试中一些常见问题的示例及其解答。在面试中,考查的内容通常会根据公司具体业务的不同而有所差异,理解SQL的基础和灵活应用非常重要。
------------------------------------------------------------------------------------------------------------------
11.JOIN
JOIN ON 是 SQL 中用于连接多个表的关键语法,用来根据两个表之间的关联条件组合数据。连接可以是 INNER JOIN、LEFT JOIN、RIGHT JOIN 等,ON 子句则定义了表之间的连接条件,通常是通过某个键(如外键)进行匹配。
SELECT e.name, e.salary, e.department_id
FROM employees e
JOIN (
SELECT department_id, MAX(salary) AS max_salary
FROM employees
GROUP BY department_id
) max_salaries
ON e.department_id = max_salaries.department_id AND e.salary = max_salaries.max_salary;
1. JOIN 概述
JOIN是 SQL 用于将两个或多个表中的记录根据某些条件组合在一起的操作。ON用于指定连接两个表的条件,通常是一个等值匹配。
2. ON 子句的作用
ON 子句的作用是指定连接的条件,告诉 SQL 服务器如何将表之间的记录进行匹配。通常,连接条件基于两个表中的一列或多列,这些列可以是主键和外键,也可以是其他列。
常见的连接条件:
- 等值连接:使用相等关系匹配两张表的列,如
table1.column = table2.column。 - 非等值连接:也可以使用其他条件,如大于 (
>) 或小于 (<)。 - 多个条件连接:可以使用
AND或OR来组合多个条件。
3. JOIN ON 语法
SELECT column_name(s)
FROM table1
JOIN table2
ON table1.column = table2.column;
table1和table2是要连接的两个表。ON后面的条件是两个表的连接条件,一般是基于某个公共列。
4. JOIN 类型详解
JOIN 的类型不同,决定了如何处理没有匹配记录的情况。下面详细介绍几种常见的 JOIN 类型,以及如何使用 ON 子句。
4.1 INNER JOIN
-
定义:只返回两个表中满足
ON条件的匹配记录。如果某一表中的记录没有匹配的记录,则该记录不会出现在结果集中。 -
SQL 示例:
SELECT e.name, d.department_name
FROM employees e
INNER JOIN departments d
ON e.department_id = d.id;
-
解释:
这个查询返回所有匹配的员工及其部门信息。如果员工没有部门,则不会出现在结果中。
4.2 LEFT JOIN(或 LEFT OUTER JOIN)
-
定义:保留左表中的所有记录,即使右表中没有匹配的记录,未匹配的右表字段会显示为
NULL。 -
SQL 示例:
SELECT e.name, d.department_name
FROM employees e
LEFT JOIN departments d
ON e.department_id = d.id;
-
解释:
这个查询会返回所有员工信息,即使某些员工没有部门(department_id在departments表中没有匹配),部门列会显示NULL。
4.3 RIGHT JOIN(或 RIGHT OUTER JOIN)
-
定义:保留右表中的所有记录,即使左表中没有匹配的记录,未匹配的左表字段会显示为
NULL。 -
SQL 示例:
SELECT e.name, d.department_name
FROM employees e
RIGHT JOIN departments d
ON e.department_id = d.id;
-
解释:
这个查询会返回所有部门,即使有些部门没有员工(employees表中没有匹配的department_id),这些部门的员工信息会显示为NULL。
4.4 FULL OUTER JOIN
-
定义:保留两张表中所有记录,无论它们是否有匹配的记录。对于没有匹配的记录,另一表中的值为
NULL。 -
SQL 示例:
SELECT e.name, d.department_name
FROM employees e
FULL OUTER JOIN departments d
ON e.department_id = d.id;
-
解释:
这个查询会返回所有员工和所有部门。如果员工没有部门或部门没有员工,相关信息将显示为NULL。
5. ON 与 USING 的区别
在 JOIN 操作中,有时会看到 ON 和 USING 的混用。它们的主要区别如下:
-
ON:明确地指定两个表之间连接的列,即使列名不同也可以使用。
SELECT e.name, d.department_name
FROM employees e
JOIN departments d
ON e.department_id = d.id;
USING:只能在列名相同的情况下使用,语法简洁。
SELECT e.name, d.department_name
FROM employees e
JOIN departments d
USING (department_id);
-
在这个例子中,
USING只适用于employees和departments表中都有department_id且列名一致的情况。
6. 复杂连接条件
ON 子句不仅可以使用等值条件,还可以使用更多复杂的条件来定义连接,比如多个条件组合或非等值连接。
示例:多个条件连接
SELECT e.name, d.department_name
FROM employees e
JOIN departments d
ON e.department_id = d.id AND e.hire_date > '2020-01-01';
解释:
除了匹配 department_id 外,还添加了一个 hire_date 条件,筛选入职日期在 2020 年后的员工。
示例:非等值连接
SELECT e.name, p.project_name
FROM employees e
JOIN projects p
ON e.salary > p.budget;
解释:
这个查询返回员工工资高于项目预算的所有员工和项目的组合。这里 ON 子句中的条件是非等值的。
7. ON 与 WHERE 的区别
有时候,ON 和 WHERE 都可以用于过滤数据,但它们的作用范围不同:
ON作用于连接表之间的条件,用于连接两个表的匹配。WHERE则是在连接完成之后对结果集进行进一步过滤。
示例:
-- 使用 ON 进行连接
SELECT e.name, d.department_name
FROM employees e
LEFT JOIN departments d
ON e.department_id = d.id
WHERE e.salary > 5000;
解释:ON 子句处理表连接,WHERE 子句则是对连接后的结果进行过滤,返回工资大于 5000 的员工及其部门。
总结
JOIN ON:用于连接多个表,ON子句定义了表之间的匹配条件。- JOIN 类型:包括
INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL OUTER JOIN,决定了如何处理没有匹配的记录。 ON子句的灵活性:不仅可以用于等值连接,还可以使用复杂条件进行多表关联。
JOIN ON 是 SQL 中的一个核心概念,理解不同类型的 JOIN 和 ON 的用法可以帮助你在处理复杂的多表查询时选择合适的策略。