
Context Window 上下文窗口:捕捉信息的范围
上下文窗口指的是 AI 模型在生成回答时考虑的 Token 数量。它决定了模型能够捕捉信息的范围。上下文窗口越大,模型能够考虑的信息就越多,生成的回答也就越相关和连贯。

在语言模型中,上下文窗口对于理解和生成与特定上下文相关的文本至关重要。较大的上下文窗口可以提供更丰富的语义信息、消除歧义、处理上下文依赖性,并帮助模型生成连贯、准确的文本,还能更好地捕捉语言的上下文相关性,使得模型能够根据前文来做出更准确的预测或生成。
大型语言模型(LLM)往往会追求更长的「上下文窗口」,但由于微调成本高、长文本稀缺以及新token位置引入的灾难值(catastrophic values)等问题,目前模型的上下文窗口大多不超过128k个token
GPT-4 Turbo 拥有 128k 个 Token 的上下文窗口,相当于超过 300 页的文本。这使得 GPT-4 能够生成更具上下文相关性和微妙差别的回复。
再举个栗子:
比如一个 LLM 模型的 Context Window 为 5,那么在处理句子 “今天天气很好” 中的「天气」这个 Token 时,模型会同时考虑 “今天” 和 “很好” 这两个 Token 的信息,以此来更好地理解「天气」的含义。

扩展阅读:
最近有几个新的语言大模型(LLM)发布,这些模型可以使用非常大的上下文窗口,例如65K词元(MosaicML的MPT-7B-StoryWriter-65k+)和100K词元的上下文窗口(Antropic)。在Palm-2技术报告中,谷歌并没有透露具体上下文大小,但表示他们“显著增加了模型的上下文长度”。
相比之下,当前GPT-4模型可以使用32K输入词元的上下文长度,而大多数开源LLM的上下文长度为2K词元。
如此大的上下文长度意味着提示(prompt)可以达到一本书的大小。《了不起的盖茨比》有72K词元,210页,按1.7分钟/页的阅读速度计算,需要6小时的阅读时间。因此,模型可以扫描并保留此数量的“自定义”信息来处理查询!

注意思考以下几个问题:
-
为何上下文长度如此重要,且能在LLM中起到举足轻重的作用?
-
处理大型上下文长度时,原始Transformer架构的主要局限性是什么?
-
Transformer架构的计算复杂度
-
目前有哪些可以加速Transformer并将上下文长度增加到100K的优化技术?
注意: 在很多文章或者著作中,上下文长度”、“上下文窗口”和“输入词元数量”可以互相替换使用,并用n来表示。
我们先总结三个要点,来简单认识下上下文窗口的相关问题:
1)注意力层(attention layer)计算的二次方时间(Quadratic time)和空间复杂度,即输入词元数量n。
2)嵌入大小d的线性层的二次方时间复杂度。
3)原始架构中使用的位置正弦嵌入(Positional Sinusoidal Embedding )。

带着这三个问题我们来阅读下面的内容会更能理解其中的原理。
在Transformer架构中,可学习(learnable)矩阵权重的形状与输入词元n的数量无关。
因此,在2K上下文长度中训练的Transformer可以使用任意长度的词元,甚至是100K词元。但如果不是在100K词元上训练出来的,那么该模型在100K词元的推理过程中不会产生有意义的推理结果。
由于n、d相关的二次复杂度,在巨型语料库上训练Vanilla Transformer,并且只在较大的上下文长度上训练是不可行的。据估计,在2K上下文长度上训练LLaMA的费用约为300万美元,因此,100K的花费约为1.5亿美元。
一种选择是,可以在2K词元上下文中训练模型,然后在更长的上下文词元(例如65K)中微调。但由于位置正弦编码(Positional Sinusoidal Encoding)的存在,这不适用于原始Transformer模型。

为了能解决上述的这些问题,我们可以采用一些小技巧进行处理:
-
[技巧 1 ]
-
为解决此问题,可删除位置正弦编码并使用ALiBi,这一简单位置嵌入不会影响准确性。然后可以在2K词元上训练,在100K词元上微调。
-
[技巧 2 ]
-
无需计算所有词元间的注意力分数(attention scores)。某些词元比其他词元更重要,因此可使用稀疏注意力。这将提升训练和推理速度。
-
[技巧 3 ]
-
Flash Attention有效地实现了GPU的注意力层。它使用切片(tiling)技术,避免生成不适合GPU SRAM容量的大型中间矩阵(n,n)。这将提升训练和推理速度。
-
[技巧 4 ]
-
选择多查询注意力(Multi-Query attention),而非多头注意力。这意味着线性投影K和V时,可在跨所有注意力头(head)中共享权重。这极大地加快了增量(incremental)推理速度。
-
[技巧 5 ]
-
条件计算(Conditional computation)避免将所有模型参数应用于输入序列中的所有词元。CoLT5仅对最重要的词元应用重量级计算,并使用较轻量级的层处理其余词元。这将加速训练和推理。
-
[技巧 6 ]
-
为适应大型上下文,需要GPU中有大量RAM,因此人们使用80GB的A100 GPU。
********训练和推理速度越快,可使用的上下文长度就越大。********
针对上述的问题和一些内容下面我们进行详细的阐述,希望能帮助大家深入理解大模型的上下文窗口
为何上下文长度如此重要?
上下文长度是LLM的关键限制之一,将其增加到现在的100K是一项难以置信的成就。
对于语言大模型,其中一个重要用例是人们想要“将大量自定义数据输入LLM”(与公司或特定问题相关的文档,各种异构文本等),并询问有关此特定数据的问题,而不是LLM在训练期间接入一些来自互联网的抽象数据。
为了克服这一局限性,人们做了以下尝试:
-
尝试总结技巧和复杂的链式提示。
-
维护向量数据库以保留自定义文档的嵌入,然后通过相似性指标在它们之间展开“搜索”。
-
尽可能使用自定义数据微调LLM(并非所有商业LLM都允许自定义微调,对开源LLM进行自定义微调并不常见)。
-
为特定数据开发定制小型LLM(同样,这并非常规任务)
较大的上下文长度能够让已经很强大的LLM(用整个互联网数据训练的模型)查询用户的上下文和数据,以更强的个性化在完全不同的层面与你交互。所有这些都无需更改模型权重并能够“在内存中”即时“训练”。
总体而言,大型上下文窗口可让模型更加准确、流畅,提升模型创造力。
这就好比是计算机的RAM,操作系统保留了所有应用程序的实时上下文,由于上下文长度充足,LLM可以像“推理计算机”一样,保留大量用户上下文。
2
原始Transformer和上下文长度
需要注意的是,在Transformer架构中,所有可学习矩阵权重的形状与输入词元数量n无关。所有可训练参数(嵌入查找、投影层、softmax层和注意力层)都不依赖于输入长度,并且必须处理可变长度(variable-length)的输入。该架构具有的开箱即用的特性非常不错。
这意味着,如果你用2K的上下文长度训练了一个Transformer模型,可以对任意大小的词元序列进行推断,唯一的问题在于,如果模型没有在上下文长度为100K的情况下进行训练,那么它在推断过程中将无法对100K个词元产出有意义的结果。这种情况下,训练数据的分布与推断过程中的分布相差很远,模型的表现就像任何其他机器学习模型一样,面临失败风险。
为训练具有较大上下文长度Transformer,我们的解决方案是将其分为两个阶段进行训练:首先在2K个词元的上下文长度上训练基本模型,然后继续在更长的上下文中进行训练(微调),例如65K或100K。MosaicML就采用这种方法。但问题是,原始的Transformer架构无法直接实现这一点,因此需要使用一些技巧(请参阅后文的技巧1)。
3
多头注意力回顾
大型上下文长度所面临的挑战与Transformer架构的计算复杂度有关。为讨论复杂度,我们首先回顾一下注意力层的工作原理。
Q - 查询(query),K - 键(key),V - 值(value),这些符号是论文中与信息检索相关的符号表示法。在信息检索中,你可以将一个“查询”输入系统,并搜索与之最接近的“键”。
n - 输入的词元数量
d - 文本嵌入维度
h - 注意力头的数量
k - Q和K的线性投影大小
v - V的线性投影大小
多头注意力(Multi-Head Attention)
1. 我们有一个查找嵌入层,用于接收词元作为输入,并返回大小为(1,d)的向量。因此,对于一个由n个词元组成的序列,我们得到大小为(n,d)的文本嵌入矩阵X,然后将其与位置正弦嵌入相加。
2. 多头注意力层旨在为词元序列计算新的嵌入表示,该词元序列可以被视为对原始文本编码X,但需要,(1)根据词元间相对于上下文的重要性进行加权,(2)根据词元的相对位置进行加权。
3. 我们使用h个注意力头对嵌入矩阵X(n×d)进行并行处理。为了使所有的注意力头都得到Q、K和V,我们需要对X进行线性投影,将其分别投影到k、k和v维度。为此,可以通过将X分别与形状为(d,k)、(d,k)和(d,v)的h个矩阵相乘来实现。你可将其理解为用(n,d)乘以(h,d,k)、(h,d,k)和(h,d,v)。
4. 注意力头返回大小为(n,v)的h个注意力分数矩阵。然后,我们将来自所有注意力头(n,h*v)的片段进行连接,并对其进行线性投影,为后续步骤做准备。

《Attention is All You Need》论文中注意力架构的高级图解
缩放点积注意力(Scaled Dot-Product Attention)
现在详细讨论一个注意力头。
Q、K、V是X的3个线性投影,大小分别为(n,k)、(n,k)和(n,v),通过乘以每个注意力头的可学习权重(learnable weight)获得。
通过计算Q和K(转置)之间的距离(点积),我们得到了注意力分数。将矩阵(n,k)与(k,n)相乘,得到矩阵(n,n),然后我们将其与掩码矩阵相乘,以将一些词元置零(在解码器中需要)。接下来,我们对其进行缩放,并应用softmax函数,使注意力分数范围在0到1之间。这样,我们就得到一个形状为(n,n)的矩阵,其中n_ij表示第i个和第j个词元之间的相对注意力分数(0-1之间),这展示了这些词元在给定长度为n的特定上下文中有多“接近(close)”。
然后,我们将这个注意力分数矩阵(n,n)乘以大小为(n,d)的“值(value)”V,以获得由这些相对注意力分数加权得到的文本嵌入。
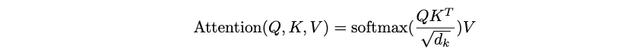
在原始论文中,一个注意力头中的注意力分数矩阵通过该公式计算
下图是Multi-Query注意力论文的代码片段,展示了如何使用批(batching)处理计算多头注意力,并且在每一步都清晰地给出了形状信息。代码里还包括在解码过程中使用的掩码乘法操作。

一段非常好的代码,展示了注意力层中每一步的形状。来源:Multi-Query
Transformer的复杂度和上下文长度
2个矩阵乘法(a,b)*(b,c)的复杂度为O(a*b*c)。
为简单起见,我们假设k*h = O(d),并利用这个假设来推导注意力机制的复杂度。
注意力层的复杂度由两部分组成:
1. 线性投影得到Q,K,V:大小为(n,d)的嵌入矩阵乘以h个可学习矩阵(d,k),(d,k)和(d,v)。因此,复杂度约为O(nd²)
2. 将Q与变换后的K相乘,然后再乘以V:(n,k)*(k,n)=(n,n),以及(n,n)*(n,v)=(n,v)。复杂度约为O(n²d)。
因此,注意力层的复杂度为O(n²d + nd²),其中n是上下文长度(输入词元的数量), d是嵌入大小。从这里我们可以看出,注意力层计算的复杂度与输入词元数n和嵌入大小d相关,分别是二次方关系。
当d>n时(例如,在LLaMa中,n=2K,d=4K),O(nd²)这个术语非常重要。
当n>d时(例如,在使用n=65K和d=4K进行MosaicML训练时),O(n²d)这个术语非常重要。
提醒一下,二次方增长的情况有多糟糕:
2000²=4000000, 100000²=10000000000
举例说明一下二次方复杂度是如何影响模型训练成本的。LLaMa模型的训练估计价格约为300万美元(https://matt-rickard.com/commoditization-of-large-language-models-part-3),具有650亿个参数,2K的上下文长度和4K的嵌入大小。预估时间大部分是GPU训练时间。如果我们将上下文长度从2K增加到100K(增加了50倍),训练时间也会增加大约50倍(由于上下文更大,迭代次数较少,但每次迭代的时间更长)。因此,以100K上下文训练LLaMa模型的成本约为1.5亿美元。
对该计算稍作详细说明:
假设token数量为n时,注意力的复杂度为O(n²d + nd²),需要进行M次迭代来进行训练。如果我们将上下文长度从n增加到p*n,由于上下文长度变大,所需的迭代次数将变为M/p(这里简单假设它是线性的,实际情况可能会高点或低点,具体取决于任务)。现在我们有两个方程式:
(1)n的复杂度为M * (n²d + nd²)
(2)pn的复杂度为M/p * ((pn)²d + (pn)d²)
经过一系列简化和除法,得到比值(2)/(1)的近似为 (d + p*n)/(d + n)。
如果 d << n,将n增加p倍将导致迭代次数增加约p倍。
如果 d ~ n,将n增加p倍将导致迭代次数增加约p/2倍。
Transformer训练阶段和推理阶段的区别
在深入研究优化技术之前,最后需要讨论的是训练和推理过程中计算的差异。
在训练过程中,你可以并行计算;而在推理过程生成文本时,你需要按顺序逐步生成,因为下一个词元依赖于前面的词元。实现推理的直接方式是逐步计算注意力分数,并缓存以前的结果供未来的词元使用。
这种区别导致了加速训练和推理具有不同方法。因此,下面的一些技巧既可以优化训练阶段,也可以优化推理阶段,但也有一些只能优化推理阶段。
4
增加上下文长度的优化技术
接下来谈谈研究人员是如何克服所有这些挑战,并能够训练具有较大上下文长度的语言模型。
[技巧1] 更好的位置编码——ALiBi
为训练具有较大上下文长度Transformer,我们的解决方案是将其分为两个阶段进行训练:首先在2K个词元的上下文长度上训练基本模型,然后在更长的上下文(例如65K)上进行微调。但是之前我们提到原始的Transformer架构不适用于这种方法,为什么?
这是因为位置正弦编码没有“外推(extrapolation)”能力。在ALiBI[4]论文中,作者表明,在推理过程中,位置正弦编码对于上下文窗口的扩展不具有健壮性,在增加了一些词元后,性能开始下降。因此,缺乏“外推”能力基本上意味着在推理/微调过程中不能使用比训练时更大的上下文长度。关于“外推”的概念和各种位置编码的比较详见[4]。
在原始Transformer论文中,位置正弦嵌入与底层架构中的词元嵌入相加,以添加关于单词顺序的信息。如果你想了解位置正弦嵌入的计算方式,推荐观看这个视频(https://www.youtube.com/watch?v=dichIcUZfOw),其中对其进行了直观且详细的解释。
因此,第一个技巧是移除位置正弦嵌入,并由另一种位置嵌入来替代,即线性偏置注意力(ALiBI)。
它应用于注意力头部(而非网络底部),并通过与其距离成比例的惩罚来偏置查询键的注意力分数(在softmax之前)。
![]()
这一技巧能够加速训练进程。

计算每个注意力头的注意力分数时,ALiBi为每个注意力分数(qi · kj,左侧)添加了一个常数偏置(右侧)。与未修改的注意力子层一样,之后对这些分数用softmax函数进行转化,其余计算保持不变。m是一个特定于注意力头的标量,在训练期间为定值,且不进行学习。(摘自ALiBi论文)
[技巧2] 稀疏注意力机制
在大小为100K的上下文中,并非所有词元之间都存在相关性。为了减少计算量,一种方法是在计算注意力分数时仅考虑部分词元。添加稀疏性的目的是使计算复杂度与n呈线性关系,而非二次方关系。有多种方法可以选择词元之间的连接方式,这篇Google博客文章
(https://ai.googleblog.com/2021/03/constructing-transformers-for-longer.html)中有出色的示例。

全注意力(Full attention)可视作一张完整图。
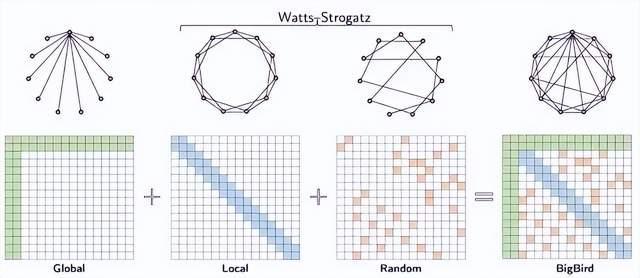
稀疏注意力方法
例如,滑动窗口注意力(Sliding Window Attention ,也称局部注意力)在每个词元周围采用了固定大小的窗口注意力。在这一注意力机制中,给定一个固定的窗口大小w,每个词元会关注其两侧的w/2个词元。这种注意力机制的计算复杂度为O(n*w),与输入序列的长度n成线性关系。为提高计算效率,w应相对于n较小。技巧在于注意力信息在相邻的词元中“流动(flows)”,近似完全的图。
BigBird(https://arxiv.org/abs/2007.14062)注意力分数方法结合了全局、局部和随机机制。在这篇论文中,作者展示了一个重要的观察结果,即在计算相似性分数和不同节点间的信息流动之间存在固有的张力(tension)关系(即一个词元对其他词元的影响能力)。
这一技巧可加快训练和推理。
[技巧3] FlashAttention——用于GPU的注意力层高效实现
在注意力层中,有几个计算操作会反复执行:
1. S = Q*K
2. P = softmax(S)
3. O = P*V
请记住P、S和O结果的概念,稍后将用到。FlashAttention的作者“融合”了这些操作:他们实现了一个能有效利用GPU内存,并计算准确注意力的注意力层算法(论文:https://arxiv.org/abs/2205.14135)。
为使GPU执行一个运算,输入数据必须在名为SRAM的“快速(quick)”内存中。数据从“慢速”的HBM(高带宽内存)复制到SRAM中,并在计算完成后返回到HBM。SRAM内存的速度比HBM快得多,但容量小得多(例如,A100 40GB GPU中的SRAM为20MB,而HBM为40GB)。
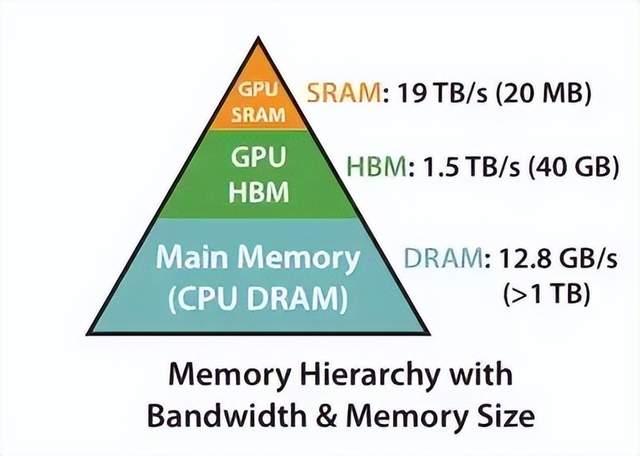
A100 GPU内存层次结构
因此,访问HBM的运算成本很高。
就GPU内存利用而言,注意力层面临的主要问题是“中间(intermediate)”乘法结果P、S和O的大小(n,n),需要将它们保存至HBM中,并在注意力运算之间再次读取。将P、S和O从HBM移动到SRAM,以及反向移动是瓶颈所在,作者在论文中解决了这一问题。
FlashAttentio算法的主要思路是将输入的Q、K和V矩阵划分成块(block),将这些块从HBM加载至SRAM中,然后根据这些块来计算注意力输出。这个过程被称为“切片(tiling)”。
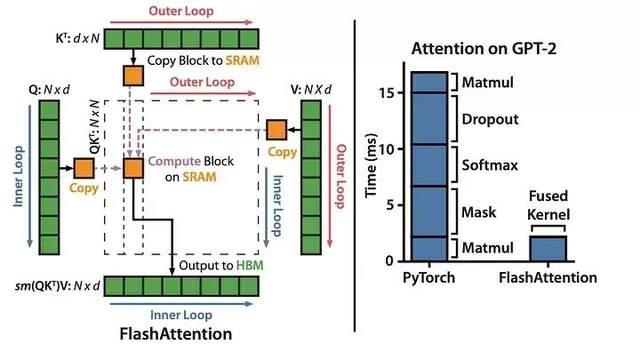
左图:FlashAttention使用切片技术,防止将大型n × n注意力矩阵(虚线框内)存储到HBM中。在外部循环(红色箭头)中,FlashAttention循环遍历K和V矩阵的块,并将它们加载到SRAM中。在每个块中,FlashAttention循环遍历Q矩阵的块(蓝色箭头),将它们加载到SRAM中,并将注意力计算的输出写回至HBM。
右图:加速比为7.6倍。
“矩阵乘法”运算已经针对GPU进行了优化,可将FlashAttention算法视为针对GPU进行优化的“注意力层”运算的实现。作者通过切片和优化HBM访问,融合了多个乘法和softmax操作。
这里有一篇针对FlashAttention相关论文的完整综述(https://shreyansh26.github.io/post/2023-03-26_flash-attention/)。
最近,PyTorch 2.0已经内置了FlashAttention,作者通过使用Triton语言进行实现(https://discuss.pytorch.org/t/flash-attention/174955)。
这一技巧可加快训练和推理。
[技巧4] 多查询注意力(Multi-Query Attention,MQA)
原始的多头注意力(Multi-Head Attention,MHA)在每个注意力头都有单独的线性层用于K和V矩阵。
在推理过程中,为了避免重复计算,解码器中之前的词元的键(key)和值(value)被缓存,因此每生成一个词元,GPU内存使用量都会增加。
多查询注意力是一种优化方法,线性投影K和V时在所有注意力头之间共享权重,因此只需保留大小为(n,k)和(n,v)的两个矩阵。一个大型模型可拥有多达96个注意力头(如GPT-3),这意味着使用MQA可以节省96倍于键/值解码器缓存的内存消耗。
这一优化在生成长文本时大有助益。例如,当上下文长度较长或需要进行长时间的重要分析或总结时。
这一方法的主要优势在于:推理过程中能够显著加快增量注意力分数的计算。训练速度则大体不变。如PaLM正在使用该方法(https://arxiv.org/pdf/2204.02311.pdf)。
[技巧5] 条件计算
当d > n时,速度瓶颈不在注意力层,而是在前馈层(feedforward)和投影层。减少浮点运算的常见方法是采用某种条件计算,避免将所有模型参数应用于输入序列的所有词元。
在上文“稀疏注意力”部分探讨了一些更重要的词元。顺着这一思路,在CoLT5论文(https://arxiv.org/pdf/2303.09752.pdf)中,作者将所有前馈和注意力计算划为两个分支:重型分支(heavy)和轻型分支(light)。轻型层应用于所有词元,而重型层仅应用于重要的词元。
“轻型和重型前馈分支仅在其隐藏层维度上有所不同,其中轻型分支的隐藏层维度小于标准T5前馈层,而重型分支的隐藏维度更高。”
这一方法已被证明在处理长达64K个输入词元的极长序列时,无论速度还是准确性都优于现有的LongT5模型。

一个带条件计算的CoLT5 Transformer层概述。所有词元都经轻量级注意力和多层感知器(MLP)层处理,q路由的查询词元在v路由的键值词元上执行更重的注意力计算,而m路由的词元则经过一个更重的多层感知器层处理。
[技巧6] 大型内存GPU
这并不算一个技巧,而是一个必要条件。为了容纳大量上下文,需要大型内存GPU,因此通常使用80GB的A100 GPU。
通过上面的文章我们掌握了数十亿参数的大型语言模型是如何在65-100K个词元的超大上下文窗口中进行训练的,从不同的角度解决同一问题,不断进行优化并提出精彩的想法,所有一起努力,让大模型在现实世界中更能深入的理解我们的原生语言,以及一些上下文信息。











![[Excel VBA]如何使用VBA按行拆分Excel工作表](https://i-blog.csdnimg.cn/direct/16be55135b9b4ca5834d6a9d2cdf5589.png)






