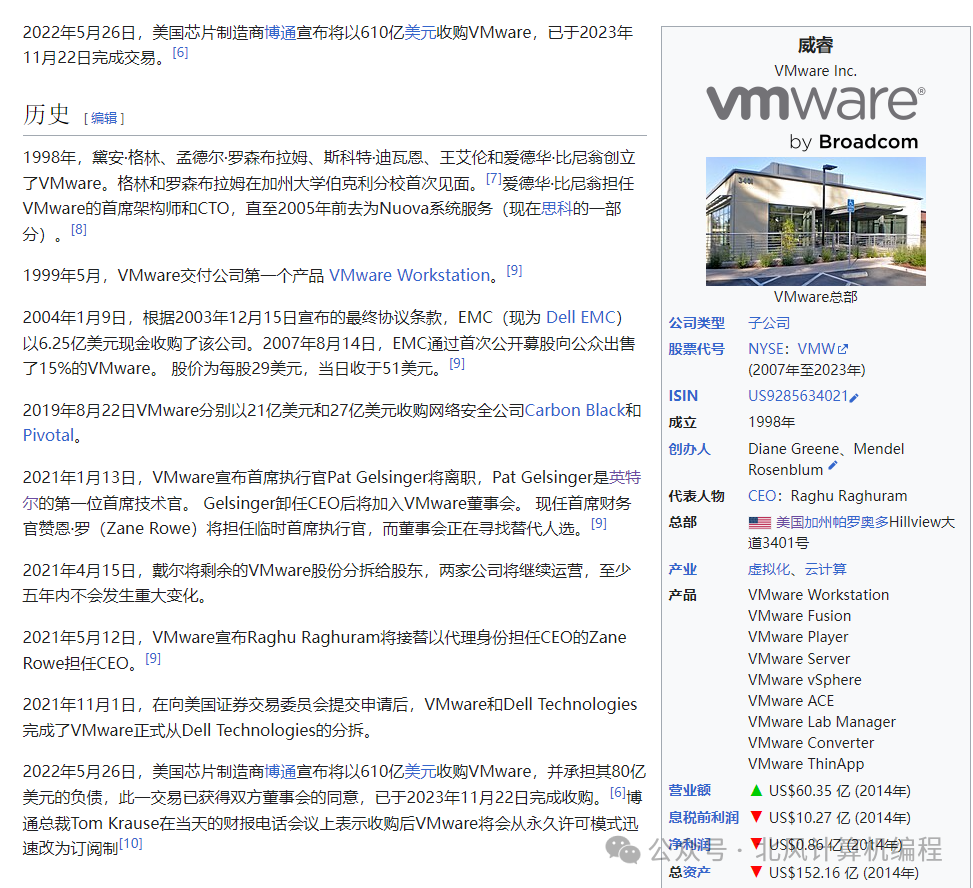
入门参考:跟着chatgpt一起学|多模态入门-CSDN博客
学习参考:多模态论文串讲·上【论文精读·46】_哔哩哔哩_bilibili,强烈推荐这个博主啊,感觉比沐神讲的还要清楚,非常喜欢。
本文介绍只使用transformer encoder的方法,下中会介绍使用transformer encoder和decoder的方法。
目录
1.ViLT CLip回顾
(a) VSE
(b) CLIP
(c)ViLBERT/UNITER
(d) ViLT
一个好的模型结构:
2.ALBEF
摘要:
模型结构:
动量蒸馏
消融实验
3.VLMO
摘要:
模型结构
MoME Transformer:
LOSS
分阶段预训练
模型效果
1.ViLT CLip回顾

图片部分对应4种类型的图文多模态模型,蓝色部分是从这个模型中学到的较好的部分,最右边的是融合这些好的部分的模型结构。
(a) VSE
visual embedding(VE)的大小远大于text embedding(TE),两者也都远大于最终的模态交互(MI),其中VE是来源于目标检测(OD)预训练算法中的,MI就是简单的点乘。
(b) CLIP
之前也有讲过:【经典论文】打通文本图像的里程碑--clip_clip论文-CSDN博客
双塔模型,通过对比学习,将已有的图片文本对在空间上拉的更近。
对图文匹配任务而言效果好,且高效。
缺点:在VQA,VR,VE这些任务上性能不够好(模态之间的交互不足)
(c)ViLBERT/UNITER
在VSE的基础上,使用transformer的encoder或者别的更复杂的模型结构来进行模态之间的交互
(d) ViLT
为了将目标检测从视觉端拿掉,有局限性。
使用基于patch的视觉特征来替代使用基于bounding box的视觉特征,visual embedding是基于patch的,所以VE的大小较小,大大降低了复杂度。而相应的MI,类似与上面的C类里的方法,复杂度较高。
缺点:
性能不够高,可能比不过c类中的方法。有可能是数据集的bias,也有可能是视觉部分不够强。(VE是随机初始化的)
推理快,但是训练慢。(4million的数据集,64张32G GPU训练3天)
一个好的模型结构:
ITC:Image Text Contrastive Loss,对比学习的loss
MLM:Mask Language Modeling Loss,bert中的loss,遮住一个词再去预判这个词
ITM:Image Text Matching Loss
更大的视觉特征
2.ALBEF

摘要:
1.ALBEF使用ITC(图像文本对比损失函数),在融合之前,将视觉特征和文本特征进行了对齐。
之前的工作,使用Transformer来融合视觉特征和文本特征,而这个视觉特征是已经学习好的,后续并没有基于end-end继续学习,所以视觉特征和文本特征是没有对齐的。
2.使用momentum distillation这种自训练的方式去学习,提升模型在noisy数据集上的表现。
使用momentum model来生成伪标签,再使用momentum distillation来提升表现。
模型结构:
- 视觉特征:ViT,一个标准的ViT(什么是VIT?-CSDN博客)
- 预训练参数:Data Efficient Vision Transformer(DEiT)
- 文本特征:Bert,使用Bert模型进行初始化,但是只用了bert中的6层做文本特征,另外6层做模态之间的交互。
- Momentum Model:也是一个ViT和Bert,参数是从上述的ViT和Bert通过moving average得到。阈值:0.995,Momentum Model会更稳定,产出更稳定的图像文本特征。(可参考MOCO)
- ITM:判断VE和TE是否是同一个对。
- 缺点:太简单了,负样本很容易学出来。
- hard negative:每个batch内,每个图片基于ITC,找到和当前图片最相似的作为负样本。
- MLM:类似于bert,也是对文本进行mask,但是会借助图像特征来帮助预测。
ALBEF每次做2次forward,一次使用原始的I和T(ITC,ITM),一次使用原始的I和mask之后的T’(MLM)
动量蒸馏
原因:网上爬下来的数据是noisy data,里面的正样本对中的文本可能和图片没什么关系,而负样本反而能很好地描述这个图像,可能比ground_truth还好。这种one-hot的label对于ITC和MLM而言是不友好的,使得模型学习困难。
构建:在已有的模型之上,使用EMA(exponential moving average),生成伪标签。
LOSS:在已有的基础上,添加基于伪标签的loss,因为伪标签是softmax score,所以使用KL散度来计算loss
ITC loss 公式:

MLM loss公式

伪标签示例,可以看到,伪标签描述的可能比ground_truth结果更好。

消融实验

在4M的数据集上,Momentum Modeling的提升可能比其他几种方式的提升要小一些,但是方向是不错的。在14M的数据集上,可能会更好。


 3.VLMO
3.VLMO
论文地址:https://arxiv.org/abs/2111.02358v2
摘要:
之前模型的弊端:
双塔模型,clip和align,速度快,但是在其他下游任务中的表现不好。
单塔模型:fusion-encoder,效果好,但是下游任务推理速度特别慢。
贡献:
- 提出了Mixture-of-Modality-Expert,后续推理时,根据任务的不同,选择不同的Expert网络。
- 提出了stage-wise pretraining strategy,利用单模态领域丰富的数据集,分阶段进行训练。
模型结构

MoME Transformer:
在Transformer的结构基础上,针对不同的输入,用3个FFN替代原先的FFN,分别代表了三个专家网络。
self-attention层是完全share weights的。
LOSS
和ALBEF一致
ITC:计算时类似一个clip模型,双塔输入
ITM/MLM:Fusion Encoder,单塔输入,图像和文本一起输入,
64张V100的卡训练2天。
分阶段预训练

- 使用图像数据进行预训练,V-FFN和self-attention层都可以进行训练,没有需要冻住的。
- 使用文本数据进行预训练,此时V-FFN和self-attention层都被冻住,仅训练L-FFN。
- 比较有意思的一点是,仅在图像数据上预训练好的self-attention在文本数据中也工作的很好,也在很多工作上验证过。但是反过来不行,推测可能图像数据蕴含的内容更丰富?
- 都可以进行训练
模型效果