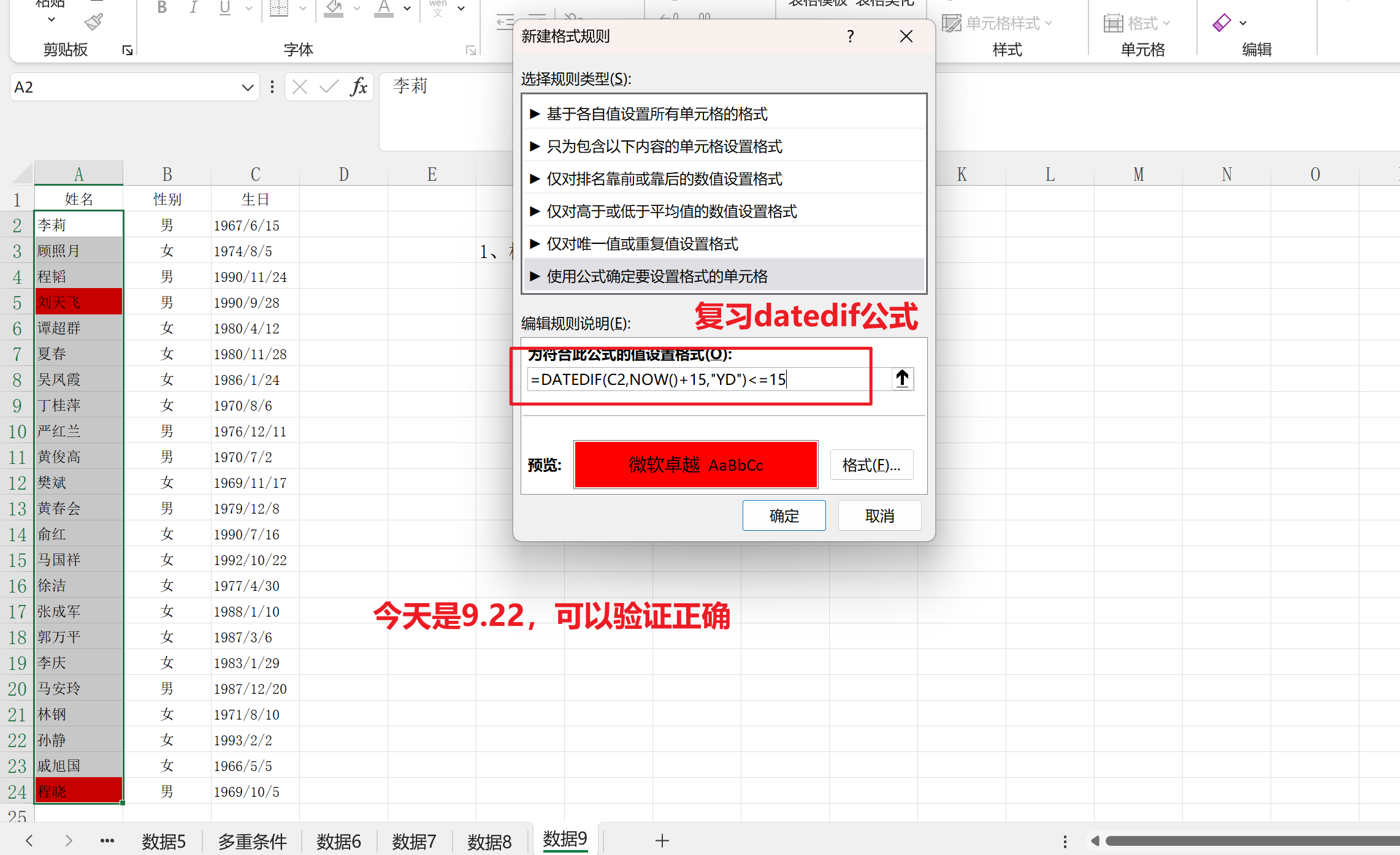
题目是要预测银行里什么样的客户会流失,流失的概率是多少
我这边先展示一下我写的二分类的算法
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 读取训练集和测试集数据
train = pd.read_csv("C:\\Users\\91144\\Desktop\\kaggle比赛数据\\Bank Churn 数据集进行二元分类\\playground-series-s4e1\\train.csv")
test = pd.read_csv("C:\\Users\\91144\\Desktop\\kaggle比赛数据\\Bank Churn 数据集进行二元分类\\playground-series-s4e1\\test.csv")
# 删除不需要的列
data = train
data.drop(['id','CustomerId','Surname'],axis=1,inplace=True)
# 对分类变量进行独热编码
object_cols = data.select_dtypes(include=['object']).columns
dumm = pd.get_dummies(data, columns=object_cols, prefix_sep='')
# 数据缩放
data = dumm
data['CreditScore'] = (data['CreditScore'] - data['CreditScore'].min()) / (data['CreditScore'].max() - data['CreditScore'].min())
data['EstimatedSalary'] = (data['EstimatedSalary'] - data['EstimatedSalary'].min()) / (data['EstimatedSalary'].max() - data['EstimatedSalary'].min())
# 划分训练集和测试集
X = data.drop('Exited',axis=1) # 特征集 X
y = data['Exited'] # 标签集 y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 使用逻辑回归模型进行训练和预测
LR = LogisticRegression()
LR.fit(X_train, y_train)
print('训练集准确率:\n', LR.score(X_train, y_train))
print('验证集准确率:\n', LR.score(X_test, y_test))
# 对测试集进行预测
data = test
data.drop(['id','CustomerId','Surname'],axis=1,inplace=True)
object_cols = data.select_dtypes(include=['object']).columns
dumm = pd.get_dummies(data, columns=object_cols, prefix_sep='')
# 数据缩放
data = dumm
data['CreditScore'] = (data['CreditScore'] - data['CreditScore'].min()) / (data['CreditScore'].max() - data['CreditScore'].min())
data['EstimatedSalary'] = (data['EstimatedSalary'] - data['EstimatedSalary'].min()) / (data['EstimatedSalary'].max() - data['EstimatedSalary'].min())
# 进行预测
y_pred = LR.predict(data)
print(y_pred)
# 将预测结果保存到CSV文件中
df = pd.read_csv("C:\\Users\\91144\\Desktop\\kaggle比赛数据\\Bank Churn 数据集进行二元分类\\playground-series-s4e1\\test.csv")
id = df['id']
result = pd.DataFrame({'id':id, 'Exited':y_pred})
result.to_csv('2combined_columns.csv', index=False)
但是我预测出来基本Exited全是0

这里我应该是特征处理做的太草率,或者是数据参数问题
跑了这么多分

然后加以了改进,我用到了管道,交叉验证
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 读取训练集和测试集数据
train = pd.read_csv("C:\\Users\\91144\\Desktop\\kaggle比赛数据\\Bank Churn 数据集进行二元分类\\playground-series-s4e1\\train.csv")
test = pd.read_csv("C:\\Users\\91144\\Desktop\\kaggle比赛数据\\Bank Churn 数据集进行二元分类\\playground-series-s4e1\\test.csv")
# 删除不需要的列
train.drop(['id', 'CustomerId', 'Surname'], axis=1, inplace=True)
test.drop(['id', 'CustomerId', 'Surname'], axis=1, inplace=True)
# 定义特征和目标变量
X = train.drop('Exited', axis=1)
y = train['Exited']
# 划分训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义数值和分类特征
num_cols = ['CreditScore', 'Age', 'Balance', 'EstimatedSalary']
cat_cols = ['Geography', 'Gender', 'Tenure', 'NumOfProducts', 'HasCrCard', 'IsActiveMember']
# 创建预处理步骤
numeric_transformer = Pipeline(steps=[
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, num_cols),
('cat', categorical_transformer, cat_cols)
])
# 创建逻辑回归模型的管道
model = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression(max_iter=1000))
])
# 定义要尝试的参数网格
param_grid = {
'classifier__C': [0.1, 1, 10], # 逻辑回归的正则化强度
'classifier__penalty': ['l1', 'l2'] # 正则化类型
}
# 创建 GridSearchCV 对象
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='accuracy', verbose=1)
# 训练模型
grid_search.fit(X_train, y_train)
# 获取最佳参数和最佳模型
best_params = grid_search.best_params_
best_model = grid_search.best_estimator_
# 训练模型
model.fit(X_train, y_train)
# 验证模型
y_val_pred = best_model.predict(X_val)
print('验证集准确率:', accuracy_score(y_val, y_val_pred))
print(confusion_matrix(y_val, y_val_pred))
print(classification_report(y_val, y_val_pred))
# 对测试集进行预测
test_predictions = best_model.predict(test)
test = pd.read_csv("C:\\Users\\91144\\Desktop\\kaggle比赛数据\\Bank Churn 数据集进行二元分类\\playground-series-s4e1\\test.csv")
# 将预测结果保存到CSV文件中
submission = pd.DataFrame({
'id': test['id'], # 如果需要保留 id 列
'Exited': test_predictions
})
submission.to_csv('3catboost_submission.csv', index=False)
print("Submission file created: catboost_submission.csv")-
数据预处理整合到管道中:通过使用
ColumnTransformer和Pipeline,将数据预处理步骤(包括数值特征的标准化和分类特征的独热编码)整合到了模型训练的管道中。这样做的好处是,预处理步骤和模型训练步骤可以一起执行,简化了代码,并且确保了训练集和测试集使用相同的预处理步骤。 -
使用
GridSearchCV进行参数调优:这是一个重要的改进,因为模型的性能很大程度上取决于其参数的设置。 -
避免数据泄露:通过在管道中整合预处理步骤,您确保了测试集的预测是在与训练集相同的预处理步骤之后进行的,这有助于避免数据泄露。
-
模型参数调整:在
LogisticRegression中设置了max_iter=1000,这有助于确保收敛,特别是在处理较大的数据集时。
跑了这么多分

然后还有一大佬写的用GBM梯度提升来做的
导入库
# import libraries
# to handle the data
import pandas as pd
import numpy as np
# to visualize the dataset
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.graph_objects as go
# to preprocess the data
from sklearn.preprocessing import MinMaxScaler, LabelEncoder #用于将特征缩放到给定的最小值和最大值之间。#用于将标签编码为从0开始的连续整数
# machine learning
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_extraction.text import TfidfVectorizer #用于将文本数据转换为TF-IDF特征向量。
from sklearn.decomposition import TruncatedSVD #用于降维的奇异值分解(SVD)方法。
from sklearn.model_selection import cross_val_score
# model
import lightgbm as lgb
from catboost import CatBoostClassifier, Pool
import xgboost as xgb
# evaluation
from sklearn.metrics import roc_auc_score, accuracy_score
# max columns
pd.set_option('display.max_columns', None)
# hide warnings
import warnings
warnings.filterwarnings('ignore')数据
df_train = pd.read_csv("C:\\Users\\91144\\Desktop\\kaggle比赛数据\\Bank Churn 数据集进行二元分类\\playground-series-s4e1\\train.csv")
df_test = pd.read_csv("C:\\Users\\91144\\Desktop\\kaggle比赛数据\\Bank Churn 数据集进行二元分类\\playground-series-s4e1\\test.csv")处理缺失值
#缺失值
train_null = df_train.isnull().sum().sum()
test_null = df_test.isnull().sum().sum()
print(f"Null count in Training Data: {train_null}")
print(f"Null count in Test Data: {test_null}")
处理重复值
#重复值
train_duplicate = df_train.drop("id",axis = 1).duplicated().sum()
test_duplicate = df_test.drop("id",axis = 1).duplicated().sum()
print(f"Duplicate count in Training Data: {train_duplicate}")
print(f"Duplicate count in Test Data: {test_duplicate}")df_train.info()
df_train.describe().T
查看各个特征对流失率的影响
#目标变量是不平衡的,所以我们对这个不平衡的数据集使用分层交叉验证
fig, ax = plt.subplots(figsize=(9, 4))
# Create the count plot
sns.countplot(y="Exited", data=df_train, ax=ax, palette="deep")
# Customize the plot
ax.set_title("Distribution of Exited", fontsize=18, fontweight='semibold', pad=20)
ax.set_xlabel("Count", fontsize=14, labelpad=10)
ax.set_ylabel("Exited", fontsize=14, labelpad=10)
# Add value labels to the bars
for container in ax.containers:
ax.bar_label(container, label_type='center', fontsize=12, padding=5, color='white', fontweight='bold')
plt.show()
# Create the figure and axes
fig, ax = plt.subplots(figsize=(9, 4))
# Create the count plot
sns.countplot(y="Gender", data=df_train, ax=ax, palette="deep")
# Customize the plot
ax.set_title("Distribution of Gender", fontsize=18, fontweight='semibold', pad=20)
ax.set_xlabel("Count", fontsize=14, labelpad=10)
ax.set_ylabel("Gender", fontsize=14, labelpad=10)
# Add value labels to the bars
for container in ax.containers:
ax.bar_label(container, label_type='center', fontsize=12, padding=5, color='white', fontweight='bold')
plt.show()

# Create the figure and axes
fig, ax = plt.subplots(figsize=(9, 4))
# Create the count plot
sns.countplot(y="Tenure", data=df_train, ax=ax, palette="deep")
# Customize the plot
ax.set_title("Distribution of Tenure", fontsize=18, fontweight='semibold', pad=20)
ax.set_xlabel("Count", fontsize=14, labelpad=10)
ax.set_ylabel("Tenure", fontsize=14, labelpad=10)
# Add value labels to the bars
for container in ax.containers:
ax.bar_label(container, label_type='edge', fontsize=10, padding=2, color='black', fontweight='normal')
# Adjust layout to prevent label cutoff
plt.tight_layout()
plt.show()
# Create the figure and axes
fig, ax = plt.subplots(figsize=(9, 4))
# Create the count plot
sns.countplot(y="NumOfProducts", data=df_train, ax=ax, palette="deep")
# Customize the plot
ax.set_title("Distribution of NumOfProducts", fontsize=18, fontweight='semibold', pad=20)
ax.set_xlabel("Count", fontsize=14, labelpad=10)
ax.set_ylabel("NumOfProducts", fontsize=14, labelpad=10)
# Add value labels to the bars
for container in ax.containers:
ax.bar_label(container, label_type='edge', fontsize=10, padding=2, color='black', fontweight='normal')
# Adjust layout to prevent label cutoff
plt.tight_layout()
plt.show()
# Create the figure and axes
fig, ax = plt.subplots(figsize=(9, 4))
# Create the count plot
sns.countplot(y="HasCrCard", data=df_train, ax=ax, palette="deep")
# Customize the plot
ax.set_title("Distribution of HasCrCard", fontsize=18, fontweight='semibold', pad=20)
ax.set_xlabel("Count", fontsize=14, labelpad=10)
ax.set_ylabel("HasCrCard", fontsize=14, labelpad=10)
# Add value labels to the bars
for container in ax.containers:
ax.bar_label(container, label_type='center', fontsize=12, padding=5, color='white', fontweight='bold')
plt.show()
# Create the figure and axes
fig, ax = plt.subplots(figsize=(9, 4))
# Create the count plot
sns.countplot(y="IsActiveMember", data=df_train, ax=ax, palette="deep")
# Customize the plot
ax.set_title("Distribution of IsActiveMember", fontsize=18, fontweight='semibold', pad=20)
ax.set_xlabel("Count", fontsize=14, labelpad=10)
ax.set_ylabel("IsActiveMember", fontsize=14, labelpad=10)
# Add value labels to the bars
for container in ax.containers:
ax.bar_label(container, label_type='center', fontsize=12, padding=5, color='white', fontweight='bold')
plt.show()
cat_cols = ['Geography', 'Gender', 'Tenure', 'NumOfProducts', 'HasCrCard',
'IsActiveMember']
target = 'Exited'
fig = plt.figure(figsize=(9, len(cat_cols)*1.8))
# background_color = 'grey'
for i, col in enumerate(cat_cols):
plt.subplot(len(cat_cols)//2 + len(cat_cols) % 2, 2, i+1)
sns.countplot(x=col, hue=target, data=df_train, palette='deep', color='#26090b', edgecolor='#26090b')
plt.title(f"{col} countplot by target", fontweight = 'bold')
plt.ylim(0, df_train[col].value_counts().max() + 10)
plt.tight_layout()
plt.show()
num_cols = ['CreditScore', 'Age', 'Balance', 'EstimatedSalary']
colors = ['#4e79a7', '#f28e2b', '#e15759', '#76b7b2']
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
fig.suptitle("Distribution of Numerical Features", fontsize=20, fontweight='bold', y=1.02)
for i, column in enumerate(num_cols):
ax = axes[i//2, i%2]
sns.histplot(data=df_train, x=column, kde=True, bins=30, ax=ax, color=colors[i], edgecolor='white', linewidth=0.8)
mean, median = df_train[column].mean(), df_train[column].median()
ax.axvline(mean, color='red', linestyle='dashed', linewidth=2, label=f'Mean: {mean:.2f}')
ax.axvline(median, color='blue', linestyle='dashed', linewidth=2, label=f'Median: {median:.2f}')
ax.set_title(column, fontsize=16, pad=15)
ax.set_xlabel(column, fontsize=14, labelpad=10)
ax.set_ylabel('Frequency', fontsize=14, labelpad=10)
ax.tick_params(axis='both', which='major', labelsize=12)
ax.grid(True, linestyle='--', alpha=0.7)
ax.set_axisbelow(True)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.legend(fontsize=12)
plt.tight_layout()
fig.subplots_adjust(top=0.93, hspace=0.3, wspace=0.25)
plt.show()
palette_cmap = ["#6c9a76","#cc4b57","#764a23","#f25a29","#f7941d"]
df_corr = df_train.copy()
catcol = [col for col in df_corr.columns if df_corr[col].dtype == "object"]
le = LabelEncoder()
for col in catcol:
df_corr[col] = le.fit_transform(df_corr[col])
plt.subplots(figsize =(10, 10))
sns.heatmap(df_corr.corr(), cmap = palette_cmap, square=True, cbar_kws=dict(shrink =.82),
annot=True, vmin=-1, vmax=1, linewidths=3,linecolor='#e0b583',annot_kws=dict(fontsize =8))
plt.title("Pearson Correlation Of Features\n", fontsize=25)
plt.xticks(rotation=90)
plt.yticks(rotation=0)
plt.show()

我们可以看到,年龄和人口流动之间有很强的正相关性,这意味着,当年龄越大,人口流动的可能性越大,这可以告诉我们,随着年龄的增长,人口流动的可能性越大。
此外,我们可以看到这次(产品数量和活跃成员)与退出概率之间的强烈负相关,这告诉我们,当一个人更活跃的时候,他们退出的概率是低的,也是当一个客户有更多的产品在银行,他们不太可能搅局。
由此我们可以看出,这两个变量在决定客户流失的可能性是非常重要的。
numeirc_cols = ['Age','CreditScore', 'Balance','EstimatedSalary']
#Use Loop Function
for col in numeirc_cols:
sc = MinMaxScaler()
df_train[col+"_scaled"] = sc.fit_transform(df_train[[col]])
df_test[col+"_scaled"] = sc.fit_transform(df_test[[col]])拼接
df_train['Sur_Geo_Gend_Sal'] = df_train['CustomerId'].astype(str) + \
df_train['Surname'] + \
df_train['Geography'] + \
df_train['Gender'] + \
np.round(df_train['EstimatedSalary']).astype(str)
df_test['Sur_Geo_Gend_Sal'] = df_test['CustomerId'].astype(str) + \
df_test['Surname'] + \
df_test['Geography'] + \
df_test['Gender'] + \
np.round(df_test['EstimatedSalary']).astype(str)将文本数据转换为TF-IDF特征向量
def get_vectors(df_train,df_test,col_name):
vectorizer = TfidfVectorizer(max_features=1000)
vectors_train = vectorizer.fit_transform(df_train[col_name])
vectors_test = vectorizer.transform(df_test[col_name])
#用svd降维
svd = TruncatedSVD(3)
x_sv_train = svd.fit_transform(vectors_train)
x_sv_test = svd.transform(vectors_test)
#将数据转换为 pandas 的 DataFrame 结构
tfidf_df_train = pd.DataFrame(x_sv_train)
tfidf_df_test = pd.DataFrame(x_sv_test)
#命名
cols = [(col_name + "_tfidf_" + str(f)) for f in tfidf_df_train.columns.to_list()]
tfidf_df_train.columns = cols
tfidf_df_test.columns = cols
#合并
df_train = df_train.reset_index(drop=True)
df_test = df_test.reset_index(drop=True)
df_train = pd.concat([df_train, tfidf_df_train], axis="columns")
df_test = pd.concat([df_test, tfidf_df_test], axis="columns")
return df_train,df_testSVD降维通常用于文本挖掘(如TF-IDF矩阵降维)、图像处理、推荐系统等领域。然而,SVD也有一些局限性,比如计算复杂度较高,对于非常大的数据集可能不够高效。此外,SVD是一种线性降维方法,可能无法捕捉到数据中的所有非线性结构。在这些情况下,可以考虑使用其他降维技术,如主成分分析(PCA)或t-SNE。
df_train,df_test = get_vectors(df_train,df_test,'Surname')
df_train,df_test = get_vectors(df_train,df_test,'Sur_Geo_Gend_Sal')df_train.head()
将数据集中的某些列转换为新的特征,并对这些特征进行处理
def feature_data(df):
df['Senior'] = df['Age'].apply(lambda x: 1 if x >= 60 else 0)
df['Active_by_CreditCard'] = df['HasCrCard'] * df['IsActiveMember']
df['Products_Per_Tenure'] = df['Tenure'] / df['NumOfProducts']
df['AgeCat'] = np.round(df.Age/20).astype('int').astype('category')
cat_cols = ['Geography', 'Gender', 'NumOfProducts','AgeCat'] #onehotEncoding
df=pd.get_dummies(df,columns=cat_cols)
return df#Genrating New Features
df_train = feature_data(df_train)
df_test = feature_data(df_test)
##Selecting Columns FOr use
feat_cols=df_train.columns.drop(['id', 'CustomerId', 'Surname','Exited','Sur_Geo_Gend_Sal'])
feat_cols=feat_cols.drop(numeirc_cols)
#Printing
print(feat_cols)
df_train.head()

X=df_train[feat_cols]
y=df_train['Exited']# LightGBM Parameters
lgbParams = {'n_estimators': 1000,
'max_depth': 25,
'learning_rate': 0.025,
'min_child_weight': 3.43,
'min_child_samples': 216,
'subsample': 0.782,
'subsample_freq': 4,
'colsample_bytree': 0.29,
'num_leaves': 21,
'verbose':-1}
lgb_model = lgb.LGBMClassifier(**lgbParams)
lgb_cv_scores = cross_val_score(lgb_model, X, y, cv=10, scoring='roc_auc')
print("Cross-validation scores:", lgb_cv_scores)
print("Mean AUC:", lgb_cv_scores.mean())这段代码是使用Python的LightGBM库进行机器学习模型训练和交叉验证的例子。LightGBM是一个梯度提升框架,用于训练预测模型,它在处理大型数据集时非常高效。

lgb_model.fit(X,y)
test_predictions = lgb_model.predict_proba(df_test[feat_cols])[:, 1]
# Create a submission DataFrame
submission = pd.DataFrame({
'id': df_test['id'],
'Exited': test_predictions
})
# # Save the submission file
submission.to_csv('3submission.csv', index=False)
# Initialize CatBoostClassifier
cat_model = CatBoostClassifier(
eval_metric='AUC',
learning_rate=0.022,
iterations=1000,
verbose=False
)
# Perform cross-validation with StratifiedKFold
catboost_cv_scores = cross_val_score(cat_model, X, y, cv=5, scoring='roc_auc')
print("Cross-validation scores:", catboost_cv_scores)
print("Mean AUC:", catboost_cv_scores.mean())![]()
#Cat_features
cat_features = np.where(X.dtypes != np.float64)[0]
# Train the model on the entire dataset
train_pool = Pool(X, y, cat_features=cat_features)
cat_model.fit(train_pool)
# Make predictions on the test set
test_pool = Pool(df_test[feat_cols], cat_features=cat_features)
test_predictions = cat_model.predict_proba(test_pool)[:, 1]
# Create submission DataFrame
submission = pd.DataFrame({
'id': df_test['id'],
'Exited': test_predictions
})
# Save the submission file
submission.to_csv('catboost_submission.csv', index=False)
print("Submission file created: catboost_submission.csv")xgb_params = {
'max_depth': 6,
'learning_rate': 0.01,
'n_estimators': 1000,
'min_child_weight': 1,
'subsample': 0.8,
'colsample_bytree': 0.8,
'gamma': 0,
'objective': 'binary:logistic',
'eval_metric': 'auc',
'use_label_encoder': False,
'nthread': -1,
'random_state': 42
}
# Initialize XGBoost Classifier
xgb_model = xgb.XGBClassifier(**xgb_params)
# Perform cross-validation with StratifiedKFold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
xgb_cv_scores = cross_val_score(xgb_model, X, y, cv=cv, scoring='roc_auc')
print("Cross-validation scores:", xgb_cv_scores)
print("Mean AUC:", xgb_cv_scores.mean())
classifiers = ['LightGBM', 'CatBoost', 'XGBoost']
auc_scores = [lgb_cv_scores.mean(), catboost_cv_scores.mean(), xgb_cv_scores.mean()]# Create data for the plot
colors = ['#4e79a7', '#f28e2b', '#e15759']
# Create the figure with optimized settings
fig = go.Figure(data=[go.Bar(
x=classifiers,
y=auc_scores,
name='AUC Score',
marker_color=colors
)])
# Update layout with optimized settings
fig.update_layout(
title='AUC Comparison',
xaxis_title='Classifier',
yaxis_title='AUC Score',
template='plotly_white',
font=dict(family="Arial", size=12),
width=600,
margin=dict(l=50, r=50, t=50, b=50)
)
# Add gridlines
fig.update_yaxes(showgrid=True, gridwidth=1, gridcolor='#E0E0E0')
# Show the plot
fig.show()创建一个柱状图,用于比较不同分类器的 AUC 分数。

# Selcting Best and Highest AUC_Score from Above trained Models
# Find the index of the maximum AUc_Score
best_accuracy_index = auc_scores.index(max(auc_scores))
# Print the best model for accuracy
print(f'Best Accuracy: {auc_scores[best_accuracy_index]:.4f} with Model: {classifiers[best_accuracy_index]}')Best Accuracy: 0.8946 with Model: LightGBM