1. 入门
1.1 什么是 awk?
①Awk是一种文本处理工具,适用于处理结构化数据,例如表格数据。
②它可以读取一个或多个文本文件,并执行模式扫描和处理等指定的操作。
③基本逻辑涉及数据的提取,排序和计算。
④支持复杂的条件语句。
1.2 awk的安装和运行?
一般Linux会自带该工具
1.3基本字段解析
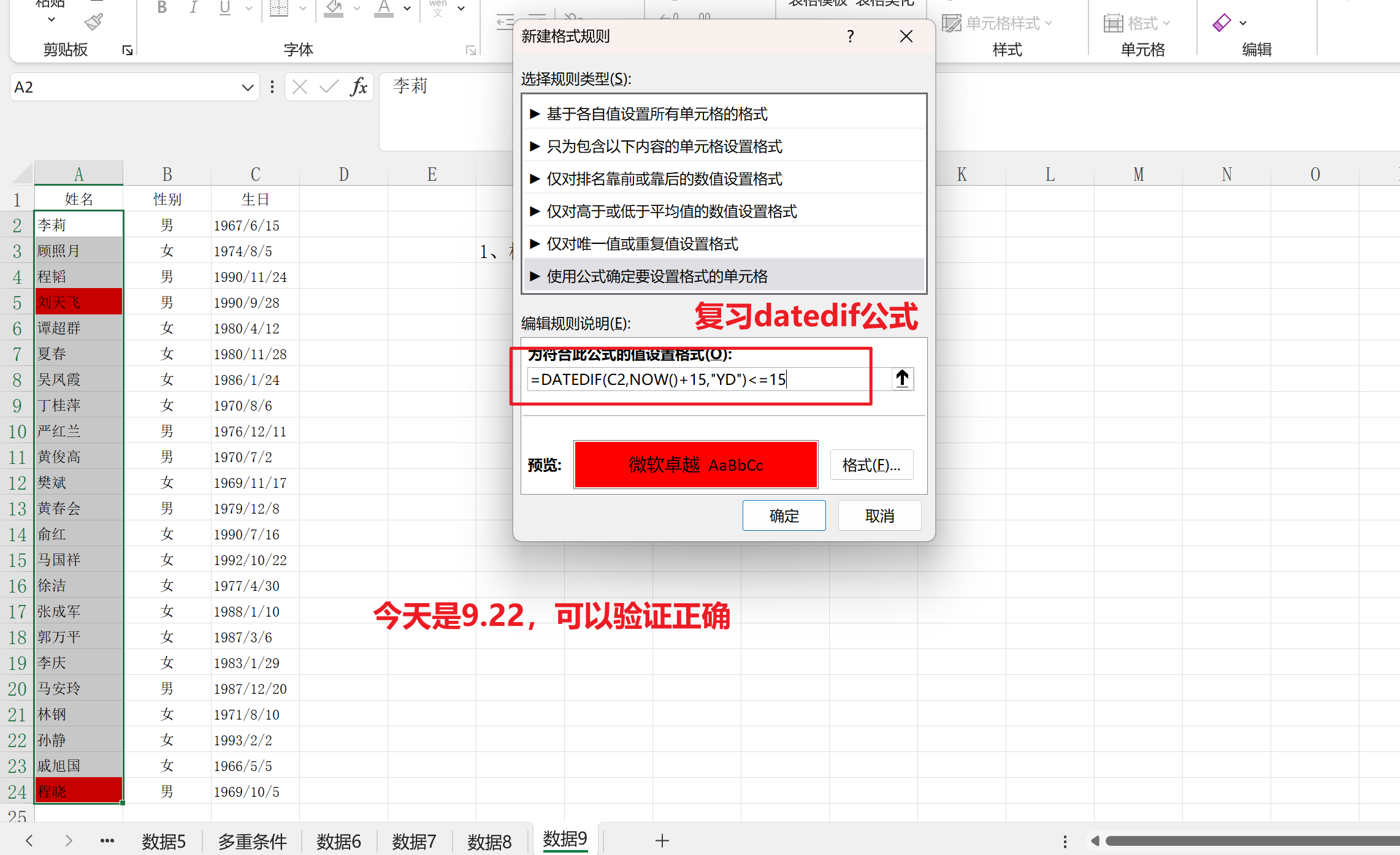
①指定对应字段:$
当前行:$0;
指定字段:$1 ~ $n:n代表指定字段
②当前行数,从1开始:NR
③当前记录字段个数:NF
例1:打印每行的字段数和内容awk '{print "Number of fields: " NF, "Content: " $0}' output.txt例2:打印每行的记录号和内容awk '{print "Record number: " NR, "Content: " $0}' output.txt
1.4基本语法
读取文件并打印指定的字段
例:echo “nihao shijie” | awk '{print $2,$1}'![]()
1.5字符串
格式符由 % 字符开始,后跟一个或多个字符,用于指定输出的格式。常用的格式说明符包括:
%s:字符串
%d:十进制整数
%f:浮点数
%c:字符
%x:十六进制数
%o:八进制数
%b:二进制数
%e:科学计数法表示的浮点数
注:%s %c %d %f 都是格式替代符
%s 输出一个字符串
%d 整型输出
%c 输出一个字符
%f 输出实数,以小数形式输出
例:
%-10s 指一个宽度为 10 个字符(- 表示左对齐,没有则表示右对齐),任何字符都会被显示在 10 个字符宽的字符内,如果不足则自动以空格填充,超过也会将内容全部显示出来。
%-4.2f 指格式化为小数,其中 .2 指保留 2 位小数。
2.基本操作
2.1打印和格式化输出
①使用print打印文本
例:打印每行的第3哥和第6个字段awk '{print $3,$6}' output.txt
②使用printf格式化输出
例:格式化输出每行的第3个和第6个字段awk '{printf "Name: %s, Score: %d\n", $3,$6}' output.txt
2.2内置变量
①FS: 分隔符,默认是空格。
例:设置字段分隔符为逗号awk 'BEGIN{FS=","} {print $1, $2}' output.txt
②OFS: 输出分隔符。
例:设置输出字段分隔符为制表符awk 'BEGIN{OFS="\t"} {print $1, $2}' output.txt例:设置输出字段分隔符为,awk -F" " -v OFS="," '{print $1 "," $3}' output.txt
③RS:输入记录的分隔符,默认是 换行符 \n
④ORS :输出记录的分隔符,默认也是换行符 \n
例:修改记录的 输入输出分隔符awk -v RS="\n\n" -v ORS="\n\n" '{print $0}' output.txtawk -v RS=";" -v ORS="\n--\n" '{print $0}' output.txt
3.模式与动作
3.1 模式匹配(pattern)
①学习如何使用正则表达式进行模式匹配。
例:匹配包含 "error" 的行awk '/error/ {print}' logfile.txt例:匹配 以"error"开头的行awk '/^error/ {print}' logfile.txt
②学习如何使用条件表达式进行模式匹配。
例:匹配第三个字段大于50的行awk '$3 > 50 {print}' output.txt
3.2动作
①学习常见的动作,如print,if-else,for,while等。
例:使用 if-else 进行条件判断awk '{if ($3 > 50) print $1, $3; else print $1, "Fail"}' output.txt
②结合模式和动作处理更复杂的任务。
例:使用模式和动作过滤并处理数据awk '/error/ {count++} END {print "Number of errors:", count}' logfile.txt
4.进阶操作
4.1 内置函数
①学习awkd内置函数,如gsub,sub,length,substr,split等。
例:使用 gsub 替换字符串中的空格为下划线awk '{gsub(/ /, "_", $0); print}' input.txt
②练习使用这些函数进行字符串和数字的处理。
例:计算每行字符串的长度awk '{print $0, "Length:", length($0)}' input.txt
4.2 用户自定义函数
①学习如何定义和调用自定义函数。
例:定义一个函数计算平方awk 'function square(x) {return x * x} {print $1, square($1)}' input.txt
②编写一些简单的自定义函数以解决特定问题。
4.3 数组与关联数组
①学习如何使用数组和关联数组。
例:使用数组统计单词出现次数awk '{for (i=1; i<=NF; i++) word[$i]++} END {for (w in word) print w, word[w]}' input.txt
5. 实战案例展示
①提取日志文件中访问次数最多的 IP 地址:
awk '{ip[$1]++} END {for (i in ip) if (ip[i] > max) {max = ip[i]; max_ip = i} print "Most frequent IP:", max_ip, "with", max, "visits"}' access.log②计算 CSV 文件中每列的平均值:
awk -F, '{for(i=1; i<=NF; i++) sum[i] += $i} END {for(i=1; i<=NF; i++) print "Column", i, "Average:", sum[i]/NR}' data.csv③从文本文件中提取特定模式的行并统计出现次数:
awk '/pattern/ {count++} END {print "Pattern found:", count, "times"}' file.txt④过滤 CSV 文件中某一列满足特定条件的行:
awk -F, '$3 > 100 {print}' data.csv⑤合并多个 CSV 文件并计算总和:
awk -F, '{for(i=1; i<=NF; i++) sum[i] += $i} END {for(i=1; i<=NF; i++) print "Column", i, "Sum:", sum[i]}' file1.csv file2.csv⑥按列统计文本文件中每个单词的频率:
awk '{for(i=1; i<=NF; i++) freq[$i]++} END {for(word in freq) print word, freq[word]}' text.txt⑦处理日志文件,计算每小时的访问量:
awk '{split($4, datetime, ":"); hour=datetime[2]; count[hour]++} END {for(hour in count) print hour, count[hour]}' logfile.txt⑧统计文本文件中最长的行及其长度:
awk '{if(length($0) > max_length) {max_length = length($0); longest_line = $0}} END {print "Longest line:", longest_line, "Length:", max_length}' text.txt⑨计算一个 CSV 文件中某列的标准差:
awk -F, '{sum+=$3; sumsq+=$3*$3} END {print "Standard Deviation:", sqrt(sumsq/NR - (