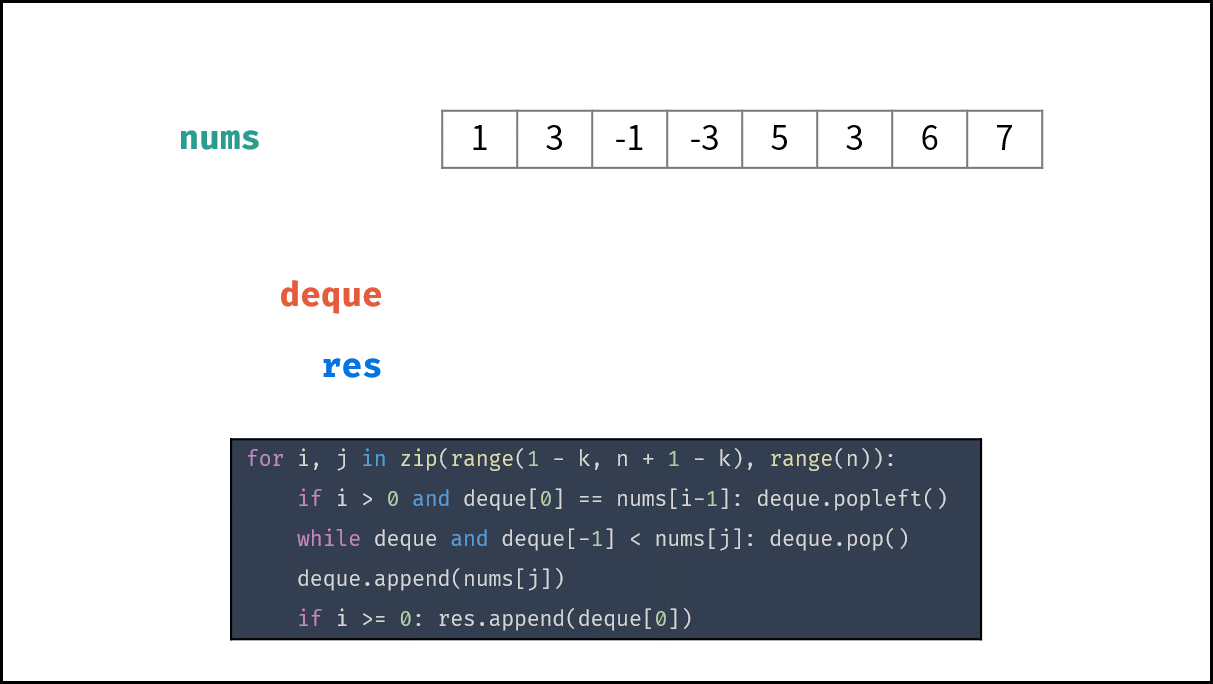
MySQL与磁盘存储
MySQL就是提供数据存储服务的,而最终存储的位置就是磁盘,但是磁盘存储速度慢,所以MySQL如何与磁盘交互,提高数据存储效率,即是MySQL和磁盘交互。
磁盘基础知识回顾
物理结构
- 磁道:磁盘是被划分成多个同心圆,每一个同心圆都是一个磁道
- 扇区:每个磁道又被划分成多个扇区,扇区是磁盘中最小的读写单位,一般情况下都是512或者4096字节(目前新的扇区有其他字节数,并非固定的数字)
- 半径方向上,距离圆心越近,扇面越小,距离圆心越远,那么扇区越大
- 柱面:在多碟片的磁盘中,不同磁片相同半径的磁道组成柱面
文件查询和磁盘关系
本质上,找到某个文件全部内容也就是找到该磁盘的扇区,只是一个反应在软件上一个体现在硬件上。

定位扇区
CHS寻址方法,也就是借助柱面、磁头和扇区来标识磁盘上数据的位置
- 选择柱面:硬盘控制器,通过磁盘上的电磁轨道选择某个柱面(也就是磁盘垂直方向上相同半径下所有盘片的磁道形成的圆柱体--类似于一堆光碟的堆积)
- 选择磁头:根据需要访问的数据所在的盘面,磁头定位到相应的磁道上
- 选择扇区:也就是磁头在磁道上找到目标扇区,开始进行读/写操作
目前主流的方式是LBA(逻辑块寻址),简单来说就是将硬盘的扇区编号为连续的逻辑块号,乜咯逻辑块对应一个扇区,操作系统则通过逻辑快号(LBA)来访问硬盘数据,而不再依赖柱面、磁头和扇区的物理结构。
分析:系统软件不按照硬件访问内存的大小进行I/O交互的原因
结论肯定是不可以,因为如果按照硬件读取磁盘的大小进行设计系统软件,那么每一次硬件读取磁盘大小的变化,系统软件都需要重新设计一次,所以不显示。而文件系统的出现就是为了解决该问题,文件系统的基本单位是数据块,不是扇区,其基本单位是4kb。
操作系统与磁盘的交互中,操作系统不会直接处理扇区,而是通过块来读取数据,可以说扇区是硬件的最小读写单元,而块则是操作系统用来管理数据的逻辑单位,通常块的大小是多个扇区组成的。
简单理解块是什么
块就是操作系统中用于存储数据的最小单位,一般情况是4KB(也就是8个512字节的扇区,或者一个4096的扇区)。操作系统为了简化管理这些块,将数据以块为单位进行组织,同时文件系统会使用这些块来存储文件。数据存储在硬盘上,是以块的形式进行存储的。
虽然硬盘的最小物理存储单位是扇区,但是操作系统通过文件系统将多个扇区组合成块来使用。这也就导致了块的大小对性能影响较大,如果块太小,可能需要更多的寻道操作,导致性能下降;如果块要太大的话,会导致浪费空间。
磁盘随机访问与顺序访问
随机访问
随机访问具体来说就是在不同磁盘区域之间来回读写数据的过程,这也就意味着每次 I/O操作,磁盘的读写磁头必须在不同的位置移动,以此来定位到不同扇区。但是硬盘是机械设备,磁头的物理移动会产生延迟,也就是寻道时间。寻道时间就是影响效率的根源。
因为每次I/O操作之间都是没有规律的,磁头是需要频繁移动的,所以随机访问更适合去访问那些需要频繁访问但是比较小的文件。
顺序访问
顺序访问就是磁盘读写数据的时候按照连续的地址顺序进行,一般情况磁头只需要进行较小的移动就可以找到数据。该种方式可以有效降低寻道时间,所以该种方法效率高,适合大文件读取。
随机与顺序访问的实际影响
- 数据库:处理大规模小查询的时候,如果此时数据存放的物理位置不同,系统就会产生大量的随机访问,会影响数据库的整体性能
- 文件系统碎片化:如果文件是分散存储在不同磁盘区域中的时候,读取该文件需要多次随机访问,这样同样会降低读写性能
固态硬盘SSD对传统磁盘的性能突破分析
固态硬盘的访问方式则是对机械硬盘的访问进行了颠覆,其本身是没有磁头等,也就不需要寻道时间也没有旋转延迟,所以SSD的随机读取速度是比机械快很多。
所以如果使用的是SSD,那么系统设计者应该更加关注I/O操作而不是存放位置所带来的性能消耗。
现代操作系统和磁盘的关系
目前的操作系统则是通过缓存和预读的技术来减少磁盘访问次数,具体来说就是将一部分常用的数据存储在内存中,从而减少每次访问都需要去磁盘中读取的需求。
操作系统也是通过文件系统来管理数据,通过将文件分配到连续的块来优化顺序访问的性能。但是文件系统还需要处理文件碎片问题,尽可能将文件存储在连续的物理位置,从而减少随机访问带来的性能损耗。
MySQL与磁盘交互基本单位
MySQL的基本I/O单位
MySQL的InnoDB存储引擎中,页面是基本的存储和管理单位,每个InnoDB页的默认大小都是16Kb,MySQL的数据操作和磁盘I/O都是以页面为单位进行的,这样可以提高I/O效率,减少频繁的磁盘寻道和数据传输而导致的性能下降问题
页大小为16kb原因
- 使用更大的数据块,可以一次性读写更多的数据,从而减少硬盘读写的次数,也就提升了I/O效率
- 可以提高顺序读取的效率

MySQL通过将访问磁盘的基本单位扩大到16KB页面,有效提升了磁盘的I/O效率,特别是处理大规模的数据的时候,减少了频繁的小块读写操作。
MySQL与I/O操作的基本原理
MySQL可以通过内存缓存机制和page单位操作,从而优化磁盘I/O,进而提高数据库性能
- page单位存储
- MySQL上的数据文件都是以page进行存储的,一个page就是16KB
- CURD操作与计算
- MySQL的增删查改操作都是涉及到存储为止的查找或者数据的修改,这些操作也是依赖计算来确定数据在磁盘上的位置
- 内存与磁盘交互
- CPU使用数据的时候会先将数据放入到内存中,然后再进行访问,这样可以提高访问速度,数据刷新的基本单位也就是page
- Buffer Pool
- MySQL在服务器内存中分配的有对应缓冲区,也就是Buffer Pool,用于缓存从磁盘中读取的数据并减少磁盘的I/O次数
深入理解索引
索引使用
创建员工信息表,然后再name字段上创建单列索引,同时在age和department上创建组合索引

插入信息

查询索引,分析索引的作用

单个和多个page
MySQL和磁盘交互时,使用page本质目的就是为了减少I/O次数,从而提高性能
单个page

InnoDB存储引擎中,page是数据存储和管理的基本单位,默认大小是16KB,页目录类似于一本书的目录,也就是在查询的时候不需要扫描整页内容,只需要通过页目录定位到数据的位置
一个page中的内容
- 文件头:记录页的也谢基本信息,例如页类型、大小等
- 页头:页的具体属性,例如记录数、页的空闲空间等
- infimum 和 supremum记录:每个页都有两个虚拟的最小和最大记录
- 用户记录:实际存储的数据行
- 空闲空间:用于存储新插入的数据
- 文件尾:效验页的完整性
多个page

如果存储的数据超过了单个page的容量时候,数据就会存储到其他page中,这样也就出现了多个page。数据库采用索引结构(例如B+树)管理和检索分布在不同的page的数据。
例如图书馆的书架,索引就像目录,page就像书架上的书本,通过目录可以快速找到所需要的书,而不需要一本一本的翻找。
单页与多页的情况
单页情况
- 所有的数据都放在一个page内,查找速度快,只需要进行一次I/O就可以完成查找
- 页内查找是可以通过页目录加速
多页情况
- 数据分布在多个page中,需要通过索引定位到具体的page
- 如果查找的话是需要进行多次磁盘I/O,但是如果通过B+树等数据结构,可以减少I/O的次数,从而提高效率、
在多页情况下,索引的作用体现的更加明显,因为可以帮助在多个page中快速定位到自己需要寻找的数据,从而实现自己调用数据的目的。
B+树和B树


数据结构可视化 (usfca.edu)
B树的特点
- 所有的节点都存储键和值
- 叶子节点和内部节点都可能包含数据
- 不利于范围查询,因为数据都分布在各个节点上
B+树特点
- 只有叶子节点存储真正的数据,内部节点仅仅存储键和指针
- 叶子节点通过双向链表连接,便于顺序遍历和范围查询
- 树的高度更低,查询效率更高
B+树的理解
- 类似于一个有层级的目录,顶部是章节标题(内部节点),底部是具体的内容页(叶子节点),如果要找某个内容,只需要根据章节标题就可以快速定位到对应的内容页
InnoDB选择B+树的原因
- 因为B+树的设计就像一本精心设计的百科全书,目录清晰查找方便,无论是想要寻找哪一页,都需要翻过相同数量的页数,确保了查找的稳定性
- B+树的优点
- 磁盘I/O性能优化:内部节点小,磁盘读取的时候可以加载更多的信息,减少I/O的次数
- 顺序访问性能高:因为叶子节点是通过链表相连接的
- 性能稳定:树的高度平衡,任何数据的查找路径都是相同的
聚簇索引和非聚簇索引
基本概念
- 聚簇索引:数据行按照主键的顺序存储,叶子节点包含了完整的数据行
- 非聚簇索引:索引的叶子节点存储的是键值和指向数据行的指针
聚簇索引就像一本按照章节编订的书籍,章节内容紧密连接(没有目录的书)。而非聚簇索引就像是书的索引页,指出关键词所在的章节,需要翻到对应的章节去阅读。
聚簇索引的特点
- 每个表只有一个聚簇索引
- 插入的新数据可能会导致数据的物理移动,影响插入性能
- 数据物理上是按照主键顺序存储的,有利于范围查询和排序
非聚簇索引特点
- 适用于非频繁查询的列
- 叶子节点存储索引列和主键值,需要通过主键回表查询完整数据
- 插入和更新对非聚簇索引的影响小
MyISAM(非聚簇索引)
该搜索引擎中,索引诶和数据是分开的
- B+树的叶子节点中存储的不是实际行数据,而是指向数据所在位置的地址,这些指针指向的是数据文件中的物理位置,也就是访问实际数据需要借助其地址找到其数据
- 该引擎中的主键索引和二级索引结构是没有本质区别,叶子节点都是存储指向数据的指针
创建表插入数据

查看表结构和索引

InnoDB(聚簇索引)
该搜索引擎的主键索引就是聚簇索引,也就是说B+树的叶子节点中存储了实际的行数据。每个表的主键都会自动创建为聚簇索引,也就是说数据和主键在物理空间上是存储在一起的,如果查询的时候使用主键,就可以直接在主键的叶子节点获取完整的行数据
二级索引在叶子节点存储的是主键值而不是物理地址,因此通过二级索引查找到数据后,还是需要通过主键索引再次定位到实际数据的物理位置
创建表插入数据

表结构和索引

验证聚簇查询速度

索引的使用
不同索引类型
主键索引:每个表中只允许有一个主键索引,主键列的值是唯一的,用于唯一标识表中的每一行数据
CREATE TABLE Employee (
emp_id INT PRIMARY KEY, -- 创建主键索引
name VARCHAR(50),
age INT
);唯一索引:保证索引列的值是唯一的,允许NULL值,其可以避免表中某列包含的重复值,表中是可以有多个唯一索引的,唯一索引允许多个NULL值
CREATE UNIQUE INDEX idx_unique_email ON Users (email); -- 创建唯一索引普通索引:不对列的值进行唯一性约束,主要用于加速查询,同时也不会对数据的唯一性进行强制检查
CREATE INDEX idx_name ON Employee (name); -- 创建普通索引全文索引:专门用于全文检索,比常规的Like查询高效,适用于大量文本内容的检索
CREATE FULLTEXT INDEX idx_fulltext ON Articles (content); -- 创建全文索引查询索引:通过show index 来查看某个表的索引,索引查询可以帮助理解当前表的索引结构

删除索引
DROP INDEX idx_name ON Employee; -- 删除普通索引索引的使用与测试
创建表与插入大量数据(可以通过.sql文件的方式进行插入)
CREATE TABLE Employees (
emp_id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
department_id INT,
hire_date DATE,
salary DECIMAL(10, 2)
) ENGINE=InnoDB;DELIMITER $$
CREATE PROCEDURE InsertEmployees()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
INSERT INTO Employees (first_name, last_name, email, department_id, hire_date, salary)
VALUES (CONCAT('First', i), CONCAT('Last', i), CONCAT('email', i, '@company.com'), FLOOR(1 + (RAND() * 10)),
'2020-01-01', FLOOR(30000 + (RAND() * 70000)));
SET i = i + 1;
END WHILE;
END $$
DELIMITER ;
CALL InsertEmployees();
无索引下搜索某个数据
此时需要扫描整个数据表去查找这个数据,逐行查出目标数据

创建普通索引并测试查询性能




![[Redis] 渐进式遍历+使用jedis操作Redis+使用Spring操作Redis](https://i-blog.csdnimg.cn/direct/da9f462fd19d4cd5a64eacf477146cc9.png)