1. leetcode997找到小镇的法官
小镇里有 n 个人,按从 1 到 n 的顺序编号。传言称,这些人中有一个暗地里是小镇法官。
如果小镇法官真的存在,那么:
小镇法官不会信任任何人。
每个人(除了小镇法官)都信任这位小镇法官。
只有一个人同时满足属性 1 和属性 2 。
给你一个数组 trust ,其中 trust[i] = [ai, bi] 表示编号为 ai 的人信任编号为 bi 的人。
如果小镇法官存在并且可以确定他的身份,请返回该法官的编号;否则,返回 -1 。
示例 1:
输入:n = 2, trust = [[1,2]]
输出:2
示例 2:
输入:n = 3, trust = [[1,3],[2,3]]
输出:3
示例 3:
输入:n = 3, trust = [[1,3],[2,3],[3,1]]
输出:-1
提示:
1 <= n <= 1000
0 <= trust.length <= 104
trust[i].length == 2
trust 中的所有trust[i] = [ai, bi] 互不相同
ai != bi
1 <= ai, bi <= n
class Solution {
public int findJudge(int n, int[][] trust) {
int[] cnt1 = new int[n + 1];
int[] cnt2 = new int[n + 1];
for (var t : trust) {
int a = t[0], b = t[1];
++cnt1[a];
++cnt2[b];
}
for (int i = 1; i <= n; ++i) {
if (cnt1[i] == 0 && cnt2[i] == n - 1) {
return i;
}
}
return -1;
}
}- 初始化计数数组:
-
cnt1数组用来统计每个人作为ai(即信任他人的人)出现的次数。cnt2数组用来统计每个人作为bi(即被他人信任的人)出现的次数。
- 遍历
trust数组:
-
- 对于
trust数组中的每一项[a, b],a是信任者,b是被信任者。 - 增加
cnt1[a]来表示a信任了至少一个人。 - 增加
cnt2[b]来表示至少有一个人信任了b。
- 对于
- 查找法官:
-
- 遍历
cnt1和cnt2数组,查找是否存在某个人i满足cnt1[i] == 0(即这个人不信任任何人)且cnt2[i] == n - 1(即这个人被除了他自己以外的所有人信任)。 - 如果找到了符合条件的人,返回该人的编号。
- 如果没有找到符合条件的人,返回
-1。
- 遍历
当然可以,下面是对这种方法的详细分析:
a. 方法一:计数
ⅰ. 思路与算法
为了找出小镇法官,我们需要确定是否有一人满足以下两个条件:
- 这个人不信任任何人。
- 除了这个人自己以外,所有人都信任这个人。
为了实现这一目标,我们可以创建两个数组 cnt1 和 cnt2 来记录每个人的信任情况:
cnt1[i]表示第i个人信任了多少人。cnt2[i]表示有多少人信任了第i个人。
ⅱ. 具体步骤
- 初始化计数数组:
-
- 创建两个长度为
n+1的数组cnt1和cnt2,用来记录每个人的信任情况。这里数组的长度为n+1是因为编号是从 1 开始的,而数组索引是从 0 开始的。
- 创建两个长度为
- 遍历信任关系:
-
- 遍历
trust数组中的每一对[ai, bi],表示ai信任bi。 - 对于每一个
ai,将cnt1[ai]加 1,表示ai信任了至少一个人。 - 对于每一个
bi,将cnt2[bi]加 1,表示至少有一个人信任了bi。
- 遍历
- 查找法官:
-
- 在编号范围
[1, n]内枚举每一个人i。 - 检查
cnt1[i]是否等于0,以及cnt2[i]是否等于n-1。 - 如果找到了满足这两个条件的
i,则i就是法官,直接返回i。 - 如果遍历完所有可能的编号都没有找到符合条件的人,则返回
-1。
- 在编号范围
ⅲ. 优点
- 算法简单直观,易于理解和实现。
- 时间复杂度较低,只需要两次线性扫描即可完成计算。
ⅳ. 缺点
- 需要额外的空间来存储计数数组,空间复杂度为 O(n)。
b. 方法二图论
997. 找到小镇的法官 - 力扣(LeetCode)
289. 生命游戏
根据 百度百科 , 生命游戏 ,简称为 生命 ,是英国数学家约翰·何顿·康威在 1970 年发明的细胞自动机。
给定一个包含 m × n 个格子的面板,每一个格子都可以看成是一个细胞。每个细胞都具有一个初始状态: 1 即为 活细胞 (live),或 0 即为 死细胞 (dead)。每个细胞与其八个相邻位置(水平,垂直,对角线)的细胞都遵循以下四条生存定律:
如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡;
如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活;
如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡;
如果死细胞周围正好有三个活细胞,则该位置死细胞复活;
下一个状态是通过将上述规则同时应用于当前状态下的每个细胞所形成的,其中细胞的出生和死亡是同时发生的。给你 m x n 网格面板 board 的当前状态,返回下一个状态。
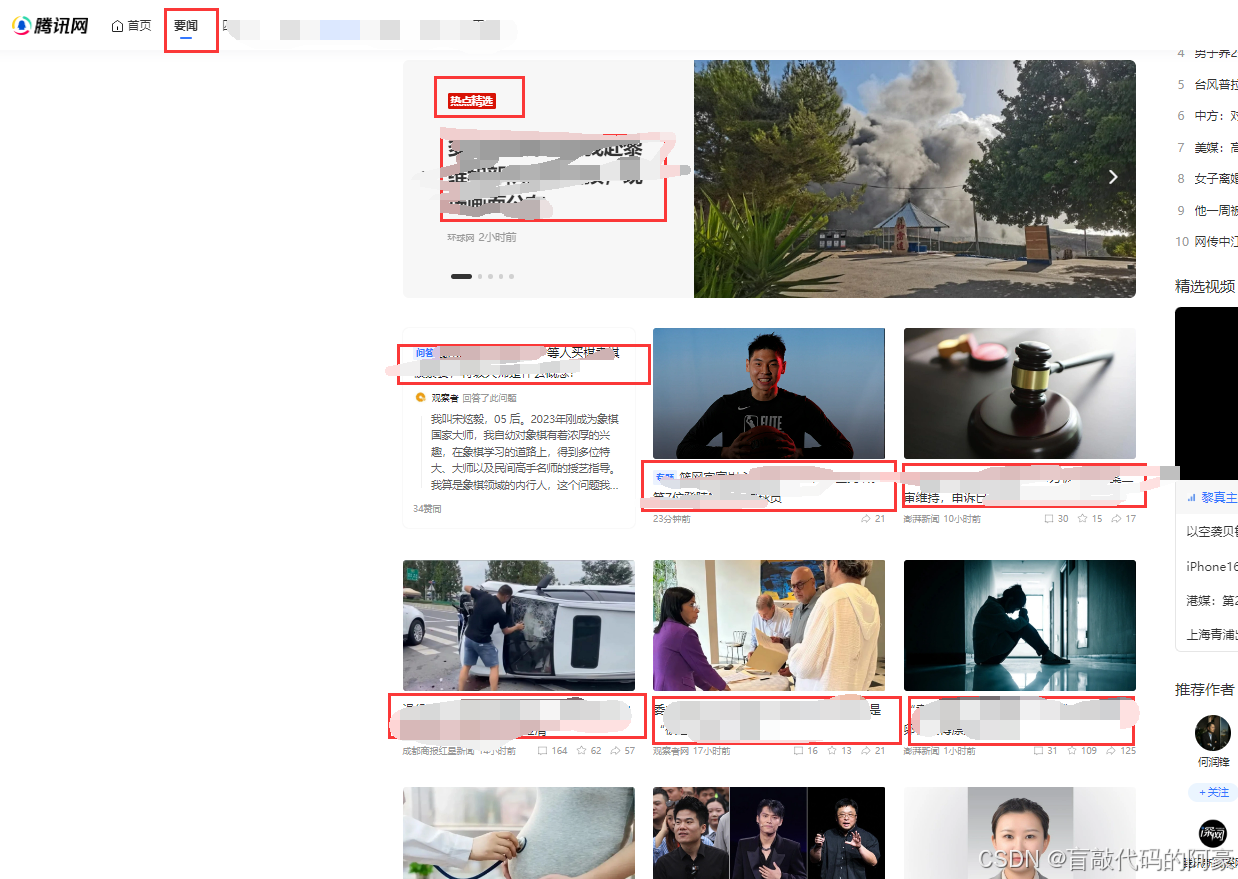
示例 1:
输入:board = [[0,1,0],[0,0,1],[1,1,1],[0,0,0]]
输出:[[0,0,0],[1,0,1],[0,1,1],[0,1,0]]
示例 2:
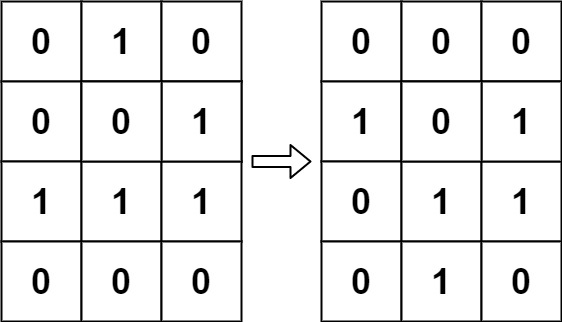
输入:board = [[1,1],[1,0]]
输出:[[1,1],[1,1]]
提示:
m == board.length
n == board[i].length
1 <= m, n <= 25
board[i][j] 为 0 或 1
进阶:
你可以使用原地算法解决本题吗?请注意,面板上所有格子需要同时被更新:你不能先更新某些格子,然后使用它们的更新后的值再更新其他格子。
本题中,我们使用二维数组来表示面板。原则上,面板是无限的,但当活细胞侵占了面板边界时会造成问题。你将如何解决这些问题?
要解决“生命游戏”的问题,我们需要遵循给定的规则来更新网格的状态。具体来说,我们需要计算每个细胞周围八个方向上的活细胞数量,并根据规则更新其状态。
解题思路
步骤1: 计算邻居状态
对于网格中的每一个细胞,我们需要计算其周围的活细胞数量。这可以通过遍历每个细胞周围的八个方向来实现。
步骤2: 应用规则更新状态
根据计算出的活细胞数量,应用以下规则来决定每个细胞的下一个状态:
- 如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡。
- 如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活。
- 如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡。
- 如果死细胞周围正好有三个活细胞,则该位置死细胞复活。
步骤3: 更新网格
为了避免在计算邻居状态时受到自身更新的影响,我们可以先计算每个细胞的新状态,然后再进行更新。
实现细节
为了简化状态的更新过程,可以在原始网格的基础上使用位运算来标记新旧状态。例如,可以用第二位来标记新状态,这样就可以在一个迭代过程中既保存旧状态又记录新状态。
以下是详细的步骤描述:
- 初始化:
-
- 使用现有的
board作为状态存储。
- 使用现有的
- 计算邻居状态并标记新状态:
-
- 遍历每个单元格
(i, j)。 - 计算其周围八个方向的活细胞数量。
- 根据上述规则确定新的状态,并用位运算标记在原数组中(例如,用
2或3标记新状态,具体取决于当前状态)。
- 遍历每个单元格
- 更新状态:
-
- 再次遍历整个数组,根据标记的新状态更新单元格的真实状态(例如,将
2和3转换回0或1)。
- 再次遍历整个数组,根据标记的新状态更新单元格的真实状态(例如,将
示例分析
假设我们有如下输入:
board = [[0,1,0],
[0,0,1],
[1,1,1],
[0,0,0]]根据规则,我们可以逐个单元格计算并更新状态。
例如,对于 (0, 1) 单元格:
- 周围的活细胞数量为
1(小于2),因此该位置的活细胞应该死亡。
对于 (2, 2) 单元格:
- 周围的活细胞数量为
3(恰好等于3),因此该位置的活细胞继续存活。
通过这种方式,我们可以计算出所有单元格的新状态,并最终得到输出:
[[0,0,0],
[1,0,1],
[0,1,1],
[0,1,0]]这种方法避免了使用额外的数组来存储临时状态,从而节省了空间。同时,通过一次遍历即可完成所有计算,保证了算法的效率。
这个问题看起来很简单,但有一个陷阱,如果你直接根据规则更新原始数组,那么就做不到题目中说的 同步 更新。假设你直接将更新后的细胞状态填入原始数组,那么当前轮次其他细胞状态的更新就会引用到当前轮已更新细胞的状态,但实际上每一轮更新需要依赖上一轮细胞的状态,是不能用这一轮的细胞状态来更新的。
算法
- 复制一份原始数组;
- 根据复制数组中邻居细胞的状态来更新
board中的细胞状态。
class Solution {
public void gameOfLife(int[][] board) {
int[] neighbors = {0, 1, -1};
int rows = board.length;
int cols = board[0].length;
// 遍历面板每一个格子里的细胞
for (int row = 0; row < rows; row++) {
for (int col = 0; col < cols; col++) {
// 对于每一个细胞统计其八个相邻位置里的活细胞数量
int liveNeighbors = 0;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
if (!(neighbors[i] == 0 && neighbors[j] == 0)) {
// 相邻位置的坐标
int r = (row + neighbors[i]);
int c = (col + neighbors[j]);
// 查看相邻的细胞是否是活细胞
if ((r < rows && r >= 0) && (c < cols && c >= 0) && (Math.abs(board[r][c]) == 1)) {
liveNeighbors += 1;
}
}
}
}
// 规则 1 或规则 3
if ((board[row][col] == 1) && (liveNeighbors < 2 || liveNeighbors > 3)) {
// -1 代表这个细胞过去是活的现在死了
board[row][col] = -1;
}
// 规则 4
if (board[row][col] == 0 && liveNeighbors == 3) {
// 2 代表这个细胞过去是死的现在活了
board[row][col] = 2;
}
}
}
// 遍历 board 得到一次更新后的状态
for (int row = 0; row < rows; row++) {
for (int col = 0; col < cols; col++) {
if (board[row][col] > 0) {
board[row][col] = 1;
} else {
board[row][col] = 0;
}
}
}
}
}
代码分析
初始化
- 定义了一个数组
neighbors来表示每个细胞周围的八个方向(包括水平、垂直和对角线方向)。
计算邻居状态并标记新状态
- 遍历
board的每一个单元格,计算每个细胞周围八个方向的活细胞数量。 - 对于每一个细胞
(row, col),使用双重循环来遍历neighbors,计算活细胞邻居的数量liveNeighbors。 - 通过边界检查来避免数组越界,并判断邻居是否是活细胞。
应用规则并标记新状态
- 根据规则1或规则3(活细胞周围少于两个或超过三个活细胞),将当前单元格标记为
-1(表示从活变死)。 - 根据规则4(死细胞周围正好有三个活细胞),将当前单元格标记为
2(表示从死变活)。
更新状态
- 最后,再次遍历
board,将标记的状态转换为最终的状态(活细胞1或死细胞0)。
关键点总结
- 邻居计算:使用
neighbors数组来简化对周围八个位置的访问。 - 边界检查:在访问邻居时,确保索引不越界。
- 标记新状态:使用
-1和2来分别标记从活变死和从死变活的情况。 - 状态更新:遍历一遍
board来将标记的状态转换为最终的状态。
代码解释
这段代码首先计算了每个细胞周围活细胞的数量,并根据生命游戏的规则标记了每个细胞的新状态。随后,它根据标记的状态更新了 board,使得每个单元格的状态反映了下一时刻的状态。
这种方法的优点在于它不需要额外的数组来存储中间状态,而是直接在原始数组上进行标记和更新,减少了空间复杂度。此外,这种方法的时间复杂度为 O(m*n),其中 m 和 n 分别是 board 的行数和列数,这是因为需要遍历每个单元格来计算其邻居状态并更新状态。
leetcode662.二叉树最大宽度
给你一棵二叉树的根节点 root ,返回树的 最大宽度 。
树的 最大宽度 是所有层中最大的 宽度 。
每一层的 宽度 被定义为该层最左和最右的非空节点(即,两个端点)之间的长度。将这个二叉树视作与满二叉树结构相同,两端点间会出现一些延伸到这一层的 null 节点,这些 null 节点也计入长度。
题目数据保证答案将会在 32 位 带符号整数范围内。
示例 1:
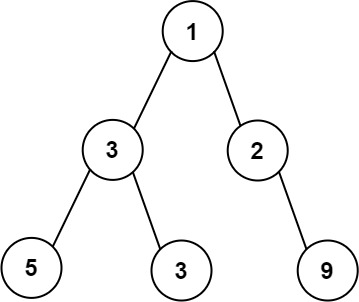
输入:root = [1,3,2,5,3,null,9]
输出:4
解释:最大宽度出现在树的第 3 层,宽度为 4 (5,3,null,9) 。示例 2:
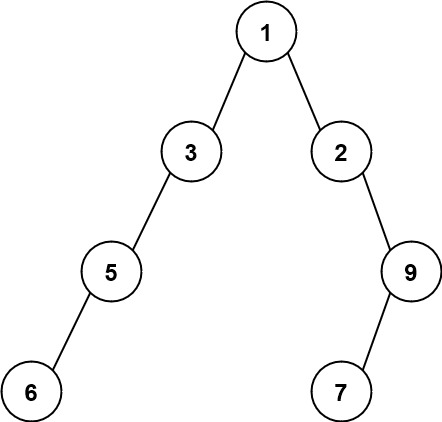
输入:root = [1,3,2,5,null,null,9,6,null,7]
输出:7
解释:最大宽度出现在树的第 4 层,宽度为 7 (6,null,null,null,null,null,7) 。示例 3:
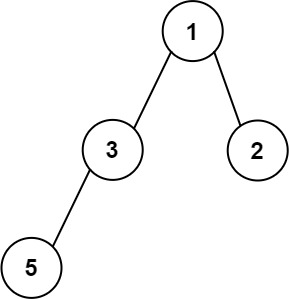
输入:root = [1,3,2,5]
输出:2
解释:最大宽度出现在树的第 2 层,宽度为 2 (3,2) 。提示:
- 树中节点的数目范围是
[1, 3000] -100 <= Node.val <= 100
方法一:广度优先搜索
思路
此题求二叉树所有层的最大宽度,比较直观的方法是求出每一层的宽度,然后求出最大值。求每一层的宽度时,因为两端点间的 null 节点也需要计入宽度,因此可以对节点进行编号。一个编号为 index 的左子节点的编号记为 2×index,右子节点的编号记为 2×index+1,计算每层宽度时,用每层节点的最大编号减去最小编号再加 1 即为宽度。
遍历节点时,可以用广度优先搜索来遍历每一层的节点,并求出最大值。
代码
作者:力扣官方题解
链接:. - 力扣(LeetCode)
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution {
public:
int widthOfBinaryTree(TreeNode* root) {
unsigned long long res = 1;
vector<pair<TreeNode *, unsigned long long>> arr;
arr.emplace_back(root, 1L);
while (!arr.empty()) {
vector<pair<TreeNode *, unsigned long long>> tmp;
for (auto &[node, index] : arr) {
if (node->left) {
tmp.emplace_back(node->left, index * 2);
}
if (node->right) {
tmp.emplace_back(node->right, index * 2 + 1);
}
}
res = max(res, arr.back().second - arr[0].second + 1);
arr = move(tmp);
}
return res;
}
};
class Solution {
public int widthOfBinaryTree(TreeNode root) {
int res = 1;
List<Pair<TreeNode, Integer>> arr = new ArrayList<Pair<TreeNode, Integer>>();
arr.add(new Pair<TreeNode, Integer>(root, 1));
while (!arr.isEmpty()) {
List<Pair<TreeNode, Integer>> tmp = new ArrayList<Pair<TreeNode, Integer>>();
for (Pair<TreeNode, Integer> pair : arr) {
TreeNode node = pair.getKey();
int index = pair.getValue();
if (node.left != null) {
tmp.add(new Pair<TreeNode, Integer>(node.left, index * 2));
}
if (node.right != null) {
tmp.add(new Pair<TreeNode, Integer>(node.right, index * 2 + 1));
}
}
res = Math.max(res, arr.get(arr.size() - 1).getValue() - arr.get(0).getValue() + 1);
arr = tmp;
}
算法的核心思想是:
- 给每个节点分配一个索引,根节点的索引为1。
- 每个节点的左子节点的索引为其父节点索引的两倍,右子节点的索引为其父节点索引的两倍加一。
- 在每一轮循环中,都计算当前层的最大索引值与最小索引值之差加一,得到当前层的最大宽度。
- 使用一个临时列表
tmp来保存下一层的节点及其索引。 - 每次循环结束之后,用
tmp替换arr,继续处理下一层。 - 最终返回记录的最大宽度
res。
这种方法保证了在遍历过程中可以正确地追踪每个节点的位置,并且通过比较每层的首尾索引来确定该层的最大宽度。
注意,此算法的时间复杂度为 O(N),其中 N 是树中的节点数,因为每个节点都被访问一次;空间复杂度也为 O(N),因为在最坏的情况下,队列可能需要存储所有最后一层的节点。
方法二:深度优先搜索
思路
仍然按照上述方法编号,可以用深度优先搜索来遍历。遍历时如果是先访问左子节点,再访问右子节点,每一层最先访问到的节点会是最左边的节点,即每一层编号的最小值,需要记录下来进行后续的比较。一次深度优先搜索中,需要当前节点到当前行最左边节点的宽度,以及对子节点进行深度优先搜索,求出最大宽度,并返回最大宽度。
class Solution {
Map<Integer, Integer> levelMin = new HashMap<Integer, Integer>();
public int widthOfBinaryTree(TreeNode root) {
return dfs(root, 1, 1);
}
public int dfs(TreeNode node, int depth, int index) {
if (node == null) {
return 0;
}
levelMin.putIfAbsent(depth, index); // 每一层最先访问到的节点会是最左边的节点,即每一层编号的最小值
return Math.max(index - levelMin.get(depth) + 1, Math.max(dfs(node.left, depth + 1, index * 2), dfs(node.right, depth + 1, index * 2 + 1)));
}
}java层序遍历经典写法
class Solution {
public int widthOfBinaryTree(TreeNode root) {
Deque<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int max = 0;
Map<TreeNode, Integer> map = new HashMap<>();
map.put(root,1);
while(!queue.isEmpty()){
int size = queue.size();
int begin = -1, end = -1;
for(int i = 0; i < size; i++){
TreeNode out = queue.poll();
int index = map.get(out);
if (i == 0) {
begin = index;
}
if (i == size - 1){
end = index;
}
if (out.left != null) {
queue.offer(out.left);
map.put(out.left, index * 2);
}
if (out.right != null) {
queue.offer(out.right);
map.put(out.right, index * 2 + 1);
}
}
max = Math.max(max, end - begin + 1);
}
return max;
}
}这段代码同样用于解决“二叉树的最大宽度”问题,它采用了典型的层序遍历(Level Order Traversal)方法,并使用了队列来实现逐层遍历的功能。此外,为了跟踪节点的位置,代码使用了一个哈希表(Map)来存储节点与其对应的索引。
以下是代码的具体实现细节:
- 初始化:
-
- 创建一个双端队列
Deque<TreeNode>类型的队列queue并将根节点入队。 - 创建一个哈希表
map用于存储节点到其索引的映射,根节点的索引设为 1。 - 初始化最大宽度
max为 0。
- 创建一个双端队列
- 层序遍历:
-
- 当队列不为空时,获取队列当前大小
size,这代表当前层的节点数量。 - 遍历当前层的所有节点:
- 当队列不为空时,获取队列当前大小
-
-
- 从队列头部弹出节点
out。 - 获取该节点的索引
index。 - 如果这是当前层的第一个节点(即
i == 0),则记录该层开始的索引begin。 - 如果这是当前层的最后一个节点(即
i == size - 1),则记录该层结束的索引end。 - 如果当前节点有左右子节点,则将它们入队,并更新它们在哈希表中的索引位置。
- 从队列头部弹出节点
-
- 计算宽度:
-
- 每次遍历完一层后,更新最大宽度
max为当前层宽度end - begin + 1和之前的最大宽度中的较大值。
- 每次遍历完一层后,更新最大宽度
- 返回结果:
-
- 返回最终计算的最大宽度
max。
- 返回最终计算的最大宽度
这种实现方式确保了对于任何给定的二叉树,都能准确计算出最大的宽度。它的时间复杂度同样是 O(N),因为它遍历了树中的每一个节点一次。空间复杂度也是 O(N),因为最坏情况下需要存储所有最后一层的节点。这种方法的优点在于它的实现较为直观,容易理解。
leetcode387:字符串中的第一个唯一字符
给定一个字符串 s ,找到 它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回 -1 。
示例 1:
输入: s = "leetcode"
输出: 0示例 2:
输入: s = "loveleetcode"
输出: 2示例 3:
输入: s = "aabb"
输出: -1提示:
1 <= s.length <= 105s只包含小写字母
LeetCode 第 387 题“字符串中的第一个唯一字符”要求我们在一个给定的字符串中找到第一个不重复的字符,并返回它的索引。如果不存在这样的字符,则返回 -1。
这个问题可以通过两次遍历来解决:
- 第一次遍历统计每个字符出现的次数。
- 第二次遍历找到第一个只出现一次的字符并返回其索引。
public class Solution {
public int firstUniqChar(String s) {
// 使用一个数组来存储每个字符出现的次数,这里假设输入只包含小写字母
int[] charCount = new int[26];
// 第一次遍历,统计字符出现次数
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
charCount[c - 'a']++;
}
// 第二次遍历,找到第一个只出现一次的字符
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (charCount[c - 'a'] == 1) {
return i;
}
}
// 如果没有唯一的字符,则返回 -1
return -1;
}
}在这个实现中,我们利用了 ASCII 码中 'a' 到 'z' 的连续性,这样可以直接通过字符减去 'a' 获得它在数组中的索引。这种方法适用于只有小写字母的情况。如果字符串中可能包含其他字符,那么就需要使用其他数据结构(如哈希表)来存储字符计数。
可以使用 HashMap<Character, Integer> 来存储字符计数,如下所示:
import java.util.HashMap;
public class Solution {
public int firstUniqChar(String s) {
HashMap<Character, Integer> charCount = new HashMap<>();
// 第一次遍历,统计字符出现次数
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
charCount.put(c, charCount.getOrDefault(c, 0) + 1);
}
// 第二次遍历,找到第一个只出现一次的字符
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (charCount.get(c) == 1) {
return i;
}
}
// 如果没有唯一的字符,则返回 -1
return -1;
}
}这段代码可以处理任意字符集,并且逻辑更加清晰。无论哪种实现方式,时间复杂度都是 O(n),其中 n 是字符串的长度,因为我们最多只需要遍历两次字符串。哈希表(Hash Table)是一种常用的数据结构,它允许快速地插入、删除和查找元素。哈希表通常通过一个称为哈希函数的过程将键映射到数组的一个特定索引上,从而实现高效的数据存储和检索。
哈希表的基本原理
哈希表由以下几个关键部分组成:
- 哈希函数(Hash Function):一个函数,用于将键转换成一个固定范围内的整数(通常是数组索引)。理想的哈希函数应该均匀分布键值,使得不同的键尽可能映射到不同的索引上。
- 数组(Array):用于存储数据的实际结构。哈希函数的输出决定了元素在数组中的位置。
- 冲突解决策略(Collision Resolution Strategy):由于哈希函数的输出范围有限,不同的键可能会映射到同一个索引上,这种情况称为冲突。常用的冲突解决策略包括:
-
- 开放地址法(Open Addressing):如线性探测(Linear Probing)、二次探测(Quadratic Probing)、双重散列(Double Hashing)等。
- 链地址法(Separate Chaining):在每个数组索引位置维护一个链表或其它数据结构来存储多个键值对。
哈希表的工作流程
- 插入操作:
-
- 计算键的哈希值。
- 将键值对存放在计算出的索引位置。
- 如果发生冲突,则根据冲突解决策略进行处理。
- 查找操作:
-
- 计算键的哈希值。
- 查找计算出的索引位置上的键值对。
- 如果发生冲突,则根据冲突解决策略查找正确的键值对。
- 删除操作:
-
- 查找要删除的键值对。
- 标记该位置为已删除或实际删除该位置上的数据。
- 如果采用开放地址法,还需要调整后续的元素。
哈希表的优点
- 快速访问:平均情况下,哈希表的插入、删除和查找操作的时间复杂度接近 O(1),即常数时间。
- 灵活的数据类型支持:哈希表可以存储任意类型的键值对,只要能够为键定义一个合适的哈希函数。
哈希表的缺点
- 冲突处理:当多个键映射到相同的索引时,需要有效的冲突解决策略来保持性能。
- 负载因子(Load Factor):负载因子是指哈希表中存储的元素数量与数组容量的比例。高负载因子会导致更多的冲突,从而降低性能。
- 哈希函数的选择:选择一个好的哈希函数对于避免冲突和提高效率至关重要。
Java 中的哈希表实现
在 Java 中,常用的哈希表实现类包括 HashMap 和 Hashtable。HashMap 是非线程安全的,而 Hashtable 是线程安全的。此外,还有 ConcurrentHashMap 用于支持并发环境下的哈希表操作。
示例代码
以下是一个简单的 Java 实现,使用 HashMap 来存储字符及其出现次数:
import java.util.HashMap;
import java.util.Map;
public class Solution {
public int firstUniqChar(String s) {
Map<Character, Integer> charCount = new HashMap<>();
// 第一次遍历,统计字符出现次数
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
charCount.put(c, charCount.getOrDefault(c, 0) + 1);
}
// 第二次遍历,找到第一个只出现一次的字符
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (charCount.get(c) == 1) {
return i;
}
}
// 如果没有唯一的字符,则返回 -1
return -1;
}
// 测试函数
public static void main(String[] args) {
Solution solution = new Solution();
// 测试用例
String[] testStrings = {"leetcode", "loveleetcode", "aabb"};
int[] expectedResults = {0, 2, -1};
// 验证测试用例
for (int i = 0; i < testStrings.length; i++) {
int result = solution.firstUniqChar(testStrings[i]);
System.out.println("Test case: " + testStrings[i] + ", Expected: " + expectedResults[i] + ", Got: " + result);
assert result == expectedResults[i] : "Test case " + testStrings[i] + " failed";
}
System.out.println("All test cases passed!");
}
}在这个例子中,HashMap 用于存储每个字符及其出现次数。通过两次遍历字符串,我们能够找到第一个唯一字符的索引。这种方法利用了哈希表高效的插入和查找操作来提高算法的整体性能。
leetcode2555 两个线段获得的最多奖品
在 X轴 上有一些奖品。给你一个整数数组 prizePositions ,它按照 非递减 顺序排列,其中 prizePositions[i] 是第 i 件奖品的位置。数轴上一个位置可能会有多件奖品。再给你一个整数 k 。
你可以同时选择两个端点为整数的线段。每个线段的长度都必须是 k 。你可以获得位置在任一线段上的所有奖品(包括线段的两个端点)。注意,两个线段可能会有相交。
- 比方说
k = 2,你可以选择线段[1, 3]和[2, 4],你可以获得满足1 <= prizePositions[i] <= 3或者2 <= prizePositions[i] <= 4的所有奖品 i 。
请你返回在选择两个最优线段的前提下,可以获得的 最多 奖品数目。
示例 1:
输入:prizePositions = [1,1,2,2,3,3,5], k = 2
输出:7
解释:这个例子中,你可以选择线段 [1, 3] 和 [3, 5] ,获得 7 个奖品。示例 2:
输入:prizePositions = [1,2,3,4], k = 0
输出:2
解释:这个例子中,一个选择是选择线段 [3, 3] 和 [4, 4] ,获得 2 个奖品。提示:
1 <= prizePositions.length <= 1051 <= prizePositions[i] <= 1090 <= k <= 109prizePositions有序非递减。
两种不同的思两种不同的思考角度(Python/Java/C++/C/Go/JS/Rust)
灵茶山艾府
题意
一维数轴上有 n 个点,用两条长为 k 的线段,一共最多可以覆盖多少个点?
方法一:枚举右,维护左
一条线段
从特殊到一般,先想想只有一条线段要怎么做。
如果线段的右端点没有奖品,我们可以把线段左移,使其右端点恰好有奖品,这不会让线段覆盖的奖品个数变少。所以只需枚举 prizePositions[right] 为线段的右端点,然后需要算出最远(最小)覆盖的奖品的位置 prizePositions[left],此时覆盖的奖品的个数为
right−left+1
由于 right 变大时,left 也会变大,有单调性,可以用滑动窗口快速算出 left。原理见 滑动窗口【基础算法精讲 03】。
⚠注意:prizePositions[left] 不一定是线段的左端点。prizePositions[left] 只是最左边的被线段覆盖的那个奖品的位置,线段左端点可能比 prizePositions[left] 更小。
两条线段
两条线段一左一右。考虑枚举右(第二条线段),同时维护左(第一条线段)能覆盖的最多奖品个数。
贪心地想,两条线段不相交肯定比相交更好,覆盖的奖品可能更多。
设第二条线段右端点在 prizePositions[right] 时,最远(最小)覆盖的奖品的位置为 prizePositions[left]。
我们需要计算在 prizePositions[left] 左侧的第一条线段最多可以覆盖多少个奖品。这可以保证两条线段不相交。
定义 mx[i+1] 表示第一条线段右端点 ≤prizePositions[i] 时,最多可以覆盖多少个奖品。特别地,定义 mx[0]=0。
如何计算 mx?
考虑动态规划:
- 线段右端点等于 prizePositions[i] 时,可以覆盖最多的奖品,即 i−lefti+1。其中 lefti 表示右端点覆盖奖品 prizePositions[i] 时,最左边的被线段覆盖的奖品。
- 线段右端点小于 prizePositions[i] 时,可以覆盖最多的奖品,这等价于右端点 ≤prizePositions[i−1] 时,最多可以覆盖多少个奖品,即 mx[i]。注:这里可以说明为什么状态要定义成 mx[i+1] 而不是 mx[i],这可以避免当 i=0 时出现 i−1=−1 这种情况。
二者取最大值,得
mx[i+1]=max(mx[i],i−lefti+1)
上式也可以理解为 i−lefti+1 的前缀最大值。
如何计算两条线段可以覆盖的奖品个数?
- 第二条线段覆盖的奖品个数为 right−left+1。
- 第一条线段覆盖的奖品个数为线段右端点 ≤prizePositions[left−1] 时,最多覆盖的奖品个数,即 mx[left]。
综上,两条线段可以覆盖的奖品个数为
mx[left]+right−left+1
枚举 right 的过程中,取上式的最大值,即为答案。
我们遍历了所有的奖品作为第二条线段的右端点,通过 mx[left] 保证第一条线段与第二条线段不相交,且第一条线段覆盖了第二条线段左侧的最多奖品。那么这样遍历后,算出的答案就一定是所有情况中的最大值。
⚠注意:可以在计算第二条线段的滑动窗口的同时,更新和第一条线段有关的 mx。这是因为两条线段一样长,第二条线段移动到 right 时所覆盖的奖品个数,也是第一条线段移动到 right 时所覆盖的奖品个数。
如果脑中没有一幅直观的图像,可以看看 视频讲解【双周赛 97】的第三题。
小优化:如果 2k+1≥prizePositions[n−1]−prizePositions[0],说明所有奖品都可以被覆盖,直接返回 n。例如 prizePositions=[0,1,2,3], k=1,那么第一条线段覆盖 0 和 1,第二条线段覆盖 2 和 3,即可覆盖所有奖品。
class Solution {
public int maximizeWin(int[] prizePositions, int k) {
int n = prizePositions.length;
if (k * 2 + 1 >= prizePositions[n - 1] - prizePositions[0]) {
return n;
}
int ans = 0;
int left = 0;
int[] mx = new int[n + 1];
for (int right = 0; right < n; right++) {
while (prizePositions[right] - prizePositions[left] > k) {
left++;
}
ans = Math.max(ans, mx[left] + right - left + 1);
mx[right + 1] = Math.max(mx[right], right - left + 1);
}
return ans;
}
}复杂度分析
- 时间复杂度:O(n),其中 n 为 prizePositions 的长度。虽然写了个二重循环,但是内层循环中对 left 加一的总执行次数不会超过 n 次,所以总的时间复杂度为 O(n)。
- 空间复杂度:O(n)。
方法二:换一个角度
两条线段一共涉及到 4 个下标:
- 第一条线段覆盖的最小奖品下标。
- 第一条线段覆盖的最大奖品下标。
- 第二条线段覆盖的最小奖品下标。
- 第二条线段覆盖的最大奖品下标。
考虑「枚举中间」,也就是第一条线段覆盖的最大奖品下标,和第二条线段覆盖的最小奖品下标。
第一条线段
写一个和方法一一样的滑动窗口:
- 枚举覆盖的最大奖品下标为 right,维护覆盖的最小奖品下标 left。
- 向右移动 right,如果发现 prizePositions[right]−prizePositions[left]>k,就向右移动 left。
- 循环结束时,覆盖的奖品个数为 right−left+1。
第二条线段
仍然是滑动窗口,但改成枚举 left,维护 right。
- 向右移动 left,如果发现 prizePositions[right]−prizePositions[left]≤k,就向右移动 right。
- 循环结束时,right−1 是覆盖的最大奖品下标,覆盖的奖品个数为 right−left。
合二为一
枚举 mid,既作为第一条线段的 right,又作为第二条线段的 left。
同方法一,用滑动窗口枚举第二条线段,同时维护第一条线段能覆盖的最多奖品个数 mx。
枚举 mid:
- 首先,跑第二条线段的滑动窗口。
- 用 mx+right−mid 更新答案的最大值。
- 然后,跑第一条线段的滑动窗口。
- 用 mid−left+1 更新 mx 的最大值。
⚠注意:不能先跑第一条线段的滑动窗口,否则 mx+right−mid 可能会把 mid 处的奖品计入两次。
class Solution {
public int maximizeWin(int[] prizePositions, int k) {
int n = prizePositions.length;
if (k * 2 + 1 >= prizePositions[n - 1] - prizePositions[0]) {
return n;
}
int ans = 0;
int mx = 0;
int left = 0;
int right = 0;
for (int mid = 0; mid < n; mid++) {
// 把 prizePositions[mid] 视作第二条线段的左端点,计算第二条线段可以覆盖的最大奖品下标
while (right < n && prizePositions[right] - prizePositions[mid] <= k) {
right++;
}
// 循环结束后,right-1 是第二条线段可以覆盖的最大奖品下标
ans = Math.max(ans, mx + right - mid);
// 把 prizePositions[mid] 视作第一条线段的右端点,计算第一条线段可以覆盖的最小奖品下标
while (prizePositions[mid] - prizePositions[left] > k) {
left++;
}
// 循环结束后,left 是第一条线段可以覆盖的最小奖品下标
mx = Math.max(mx, mid - left + 1);
}
return ans;
}
}复杂度分析
- 时间复杂度:O(n),其中 n 为 prizePositions 的长度。理由同方法一的复杂度分析。
- 空间复杂度:O(1)。
leetcode 94 二叉树的中序遍历
- 二叉树的中序遍历
简单
相关标签
相关企业
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:
输入:root = [1,null,2,3]
输出:[1,3,2]
示例 2:
输入:root = []
输出:[]
示例 3:
输入:root = [1]
输出:[1]
提示:
树中节点数目在范围 [0, 100] 内
-100 <= Node.val <= 100
进阶: 递归算法很简单,你可以通过迭代算法完成吗?
因此,我在这里介绍一种 “颜色标记法” (瞎起的名字……),兼具栈迭代方法的高效,又像递归方法一样简洁易懂,更重要的是,这种方法对于前序、中序、后序遍历,能够写出完全一致的代码。
其核心思想如下:
使用颜色标记节点的状态,新节点为白色,已访问的节点为灰色。
如果遇到的节点为白色,则将其标记为灰色,然后将其右子节点、自身、左子节点依次入栈。
如果遇到的节点为灰色,则将节点的值输出。
使用这种方法实现的中序遍历如下:
作者:henry
链接:. - 力扣(LeetCode)
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
颜色标记法
class Solution {
class Node {
TreeNode node;
int color;
Node(TreeNode node, int color) {
this.node = node;
this.color = color;
}
}
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
Deque<Node> stack = new LinkedList<>();
if(root == null) return ans;
stack.push(new Node(root, 1));
while (!stack.isEmpty()) {
Node cur = stack.pop();
if (cur.node == null) continue;
if (cur.color == 1) {
stack.push(new Node(cur.node.right, 1));
stack.push(new Node(cur.node, 2));
stack.push(new Node(cur.node.left, 1));
} else {
ans.add(cur.node.val);
}
}
return ans;
}
}二叉树的中序遍历
方法一:递归
思路与算法
首先我们需要了解什么是二叉树的中序遍历:按照访问左子树——根节点——右子树的方式遍历这棵树,而在访问左子树或者右子树的时候我们按照同样的方式遍历,直到遍历完整棵树。因此整个遍历过程天然具有递归的性质,我们可以直接用递归函数来模拟这一过程。
定义 inorder(root) 表示当前遍历到 root 节点的答案,那么按照定义,我们只要递归调用 inorder(root.left) 来遍历 root 节点的左子树,然后将 root 节点的值加入答案,再递归调用inorder(root.right) 来遍历 root 节点的右子树即可,递归终止的条件为碰到空节点。
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<Integer>();
inorder(root, res);
return res;
}
public void inorder(TreeNode root, List<Integer> res) {
if (root == null) {
return;
}
inorder(root.left, res);
res.add(root.val);
inorder(root.right, res);
}
}
复杂度分析
时间复杂度:O(n),其中 n 为二叉树节点的个数。二叉树的遍历中每个节点会被访问一次且只会被访问一次。
空间复杂度:O(n)。空间复杂度取决于递归的栈深度,而栈深度在二叉树为一条链的情况下会达到 O(n) 的级别。
方法二:迭代
思路与算法
方法一的递归函数我们也可以用迭代的方式实现,两种方式是等价的,区别在于递归的时候隐式地维护了一个栈,而我们在迭代的时候需要显式地将这个栈模拟出来,其他都相同,具体实现可以看下面的代码。
代码
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<Integer>();
Deque<TreeNode> stk = new LinkedList<TreeNode>();
while (root != null || !stk.isEmpty()) {
while (root != null) {
stk.push(root);
root = root.left;
}
root = stk.pop();
res.add(root.val);
root = root.right;
}
return res;
}
}
复杂度分析
时间复杂度:O(n),其中 n 为二叉树节点的个数。二叉树的遍历中每个节点会被访问一次且只会被访问一次。
空间复杂度:O(n)。空间复杂度取决于栈深度,而栈深度在二叉树为一条链的情况下会达到 O(n) 的级别。
方法三:Morris 中序遍历
思路与算法
Morris 遍历算法是另一种遍历二叉树的方法,它能将非递归的中序遍历空间复杂度降为 O(1)。
Morris 遍历算法整体步骤如下(假设当前遍历到的节点为 x):
如果 x 无左孩子,先将 x 的值加入答案数组,再访问 x 的右孩子,即 x=x.right。
如果 x 有左孩子,则找到 x 左子树上最右的节点(即左子树中序遍历的最后一个节点,x 在中序遍历中的前驱节点),我们记为 predecessor。根据 predecessor 的右孩子是否为空,进行如下操作。
如果 predecessor 的右孩子为空,则将其右孩子指向 x,然后访问 x 的左孩子,即 x=x.left。
如果 predecessor 的右孩子不为空,则此时其右孩子指向 x,说明我们已经遍历完 x 的左子树,我们将 predecessor 的右孩子置空,将 x 的值加入答案数组,然后访问 x 的右孩子,即 x=x.right。
重复上述操作,直至访问完整棵树。
其实整个过程我们就多做一步:假设当前遍历到的节点为 x,将 x 的左子树中最右边的节点的右孩子指向 x,这样在左子树遍历完成后我们通过这个指向走回了 x,且能通过这个指向知晓我们已经遍历完成了左子树,而不用再通过栈来维护,省去了栈的空间复杂度。
代码
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<Integer>();
TreeNode predecessor = null;
while (root != null) {
if (root.left != null) {
// predecessor 节点就是当前 root 节点向左走一步,然后一直向右走至无法走为止
predecessor = root.left;
while (predecessor.right != null && predecessor.right != root) {
predecessor = predecessor.right;
}
// 让 predecessor 的右指针指向 root,继续遍历左子树
if (predecessor.right == null) {
predecessor.right = root;
root = root.left;
}
// 说明左子树已经访问完了,我们需要断开链接
else {
res.add(root.val);
predecessor.right = null;
root = root.right;
}
}
// 如果没有左孩子,则直接访问右孩子
else {
res.add(root.val);
root = root.right;
}
}
return res;
}
}
复杂度分析
时间复杂度:O(n),其中 n 为二叉树的节点个数。Morris 遍历中每个节点会被访问两次,因此总时间复杂度为 O(2n)=O(n)。
空间复杂度:O(1)。
leetcode 402移掉k位数字
一招吃遍力扣四道题,妈妈再也不用担心我被套路啦~

lucifer

我花了几天时间,从力扣中精选了四道相同思想的题目,来帮助大家解套,如果觉得文章对你有用,记得点赞分享,让我看到你的认可,有动力继续做下去。
这就是接下来要给大家讲的四个题,其中 1081 和 316 题只是换了说法而已。
- 316. 去除重复字母 (困难)
- 321. 拼接最大数 (困难)
- 402. 移掉 K 位数字 (中等)
- 1081. 不同字符的最小子序列 (中等)
402. 移掉 K 位数字(中等)
我们从一个简单的问题入手,识别一下这种题的基本形式和套路,为之后的三道题打基础。
题目描述
给定一个以字符串表示的非负整数 num,移除这个数中的 k 位数字,使得剩下的数字最小。
注意:
num 的长度小于 10002 且 ≥ k。
num 不会包含任何前导零。
示例 1 :
输入: num = "1432219", k = 3
输出: "1219"
解释: 移除掉三个数字 4, 3, 和 2 形成一个新的最小的数字 1219。
示例 2 :
输入: num = "10200", k = 1
输出: "200"
解释: 移掉首位的 1 剩下的数字为 200. 注意输出不能有任何前导零。
示例 3 :
输入: num = "10", k = 2
输出: "0"
解释: 从原数字移除所有的数字,剩余为空就是 0。前置知识
- 数学
思路
这道题让我们从一个字符串数字中删除 k 个数字,使得剩下的数最小。也就说,我们要保持原来的数字的相对位置不变。
以题目中的 num = 1432219, k = 3 为例,我们需要返回一个长度为 4 的字符串,问题在于: 我们怎么才能求出这四个位置依次是什么呢?
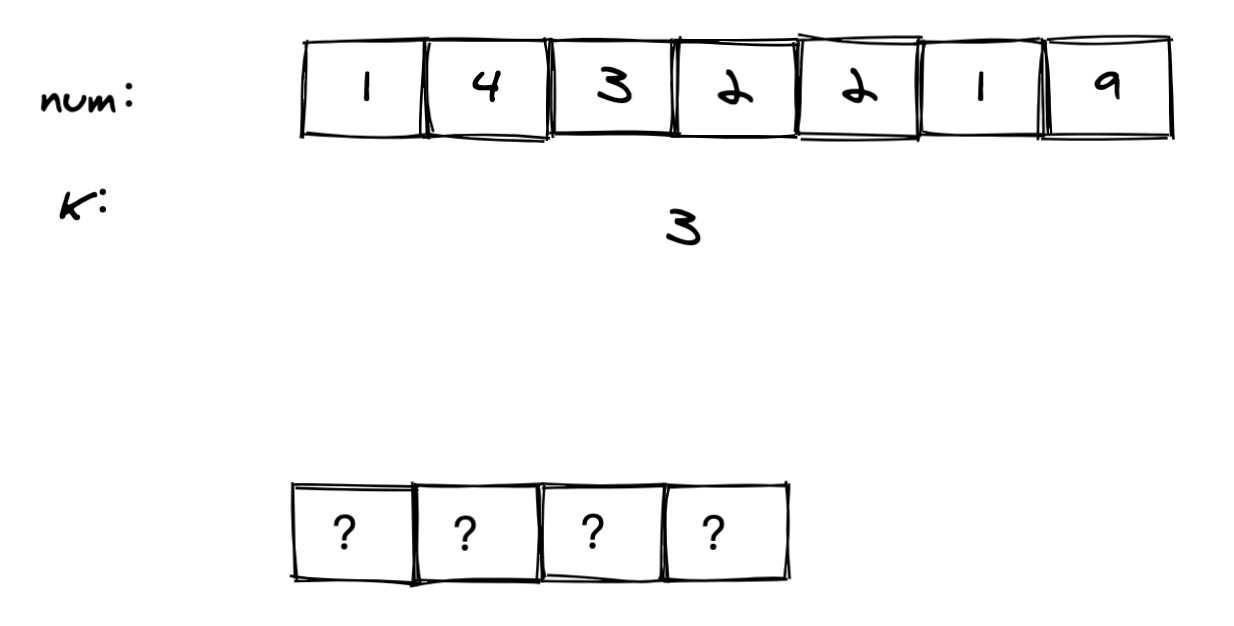
(图 1)
暴力法的话,我们需要枚举C_n^(n - k) 种序列(其中 n 为数字长度),并逐个比较最大。这个时间复杂度是指数级别的,必须进行优化。
一个思路是:
- 从左到右遍历
- 对于每一个遍历到的元素,我们决定是丢弃还是保留
问题的关键是:我们怎么知道,一个元素是应该保留还是丢弃呢?
这里有一个前置知识:对于两个数 123a456 和 123b456,如果 a > b, 那么数字 123a456 大于 数字 123b456,否则数字 123a456 小于等于数字 123b456。也就说,两个相同位数的数字大小关系取决于第一个不同的数的大小。
因此我们的思路就是:
- 从左到右遍历
- 对于遍历到的元素,我们选择保留。
- 但是我们可以选择性丢弃前面相邻的元素。
- 丢弃与否的依据如上面的前置知识中阐述中的方法。
以题目中的 num = 1432219, k = 3 为例的图解过程如下:
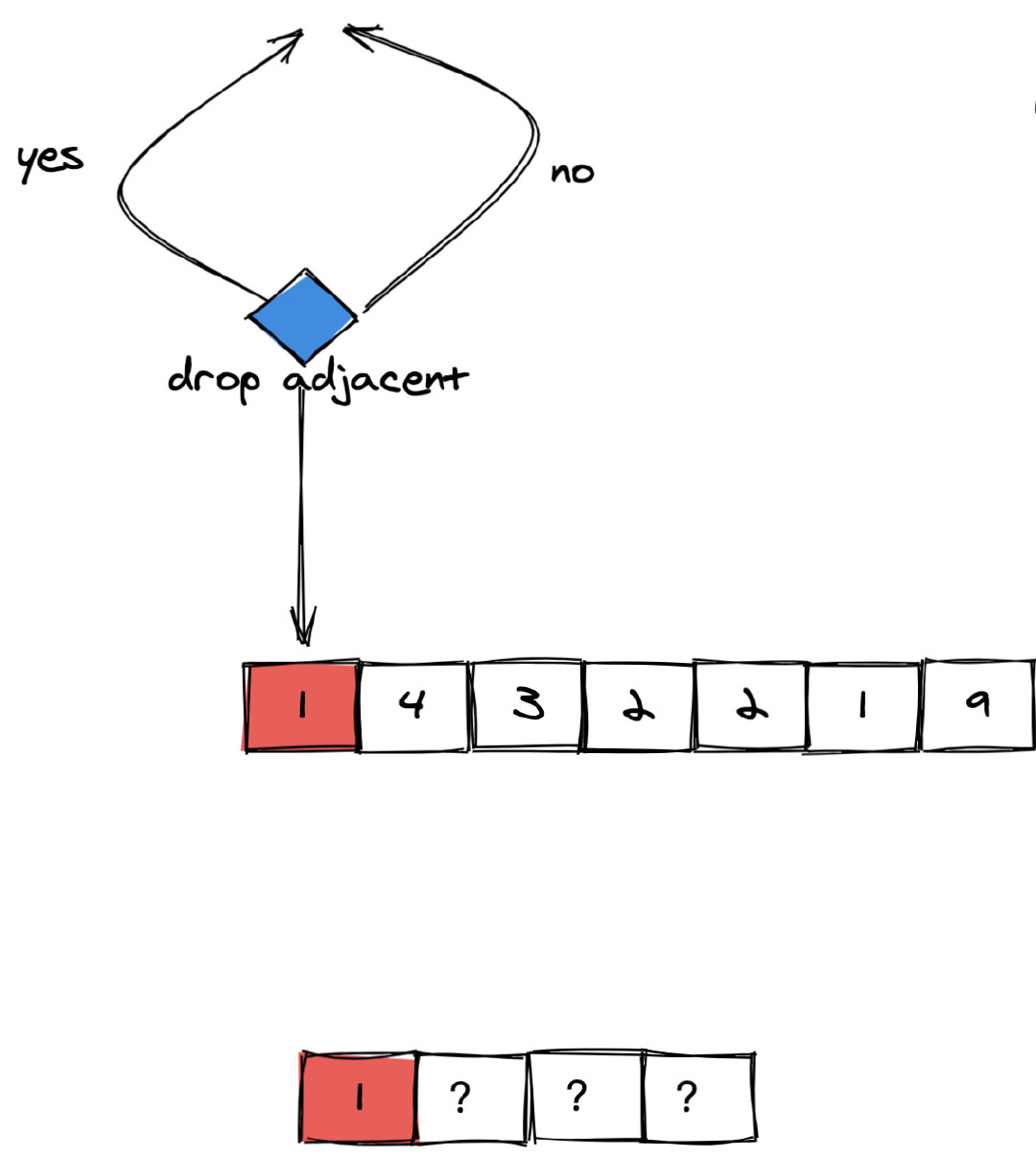
(图 2)
由于没有左侧相邻元素,因此没办法丢弃。
(图 3)
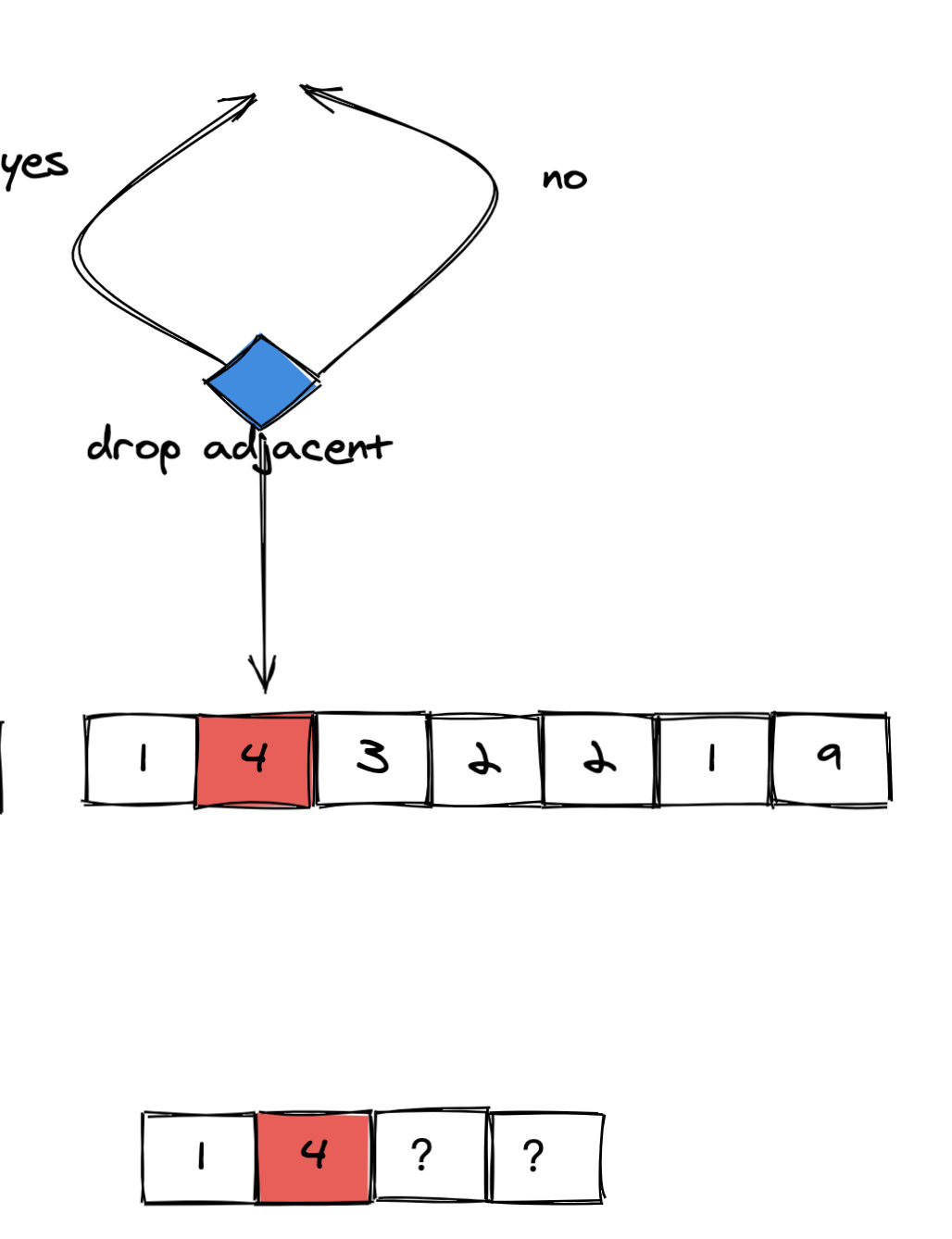
由于 4 比左侧相邻的 1 大。如果选择丢弃左侧的 1,那么会使得剩下的数字更大(开头的数从 1 变成了 4)。因此我们仍然选择不丢弃。
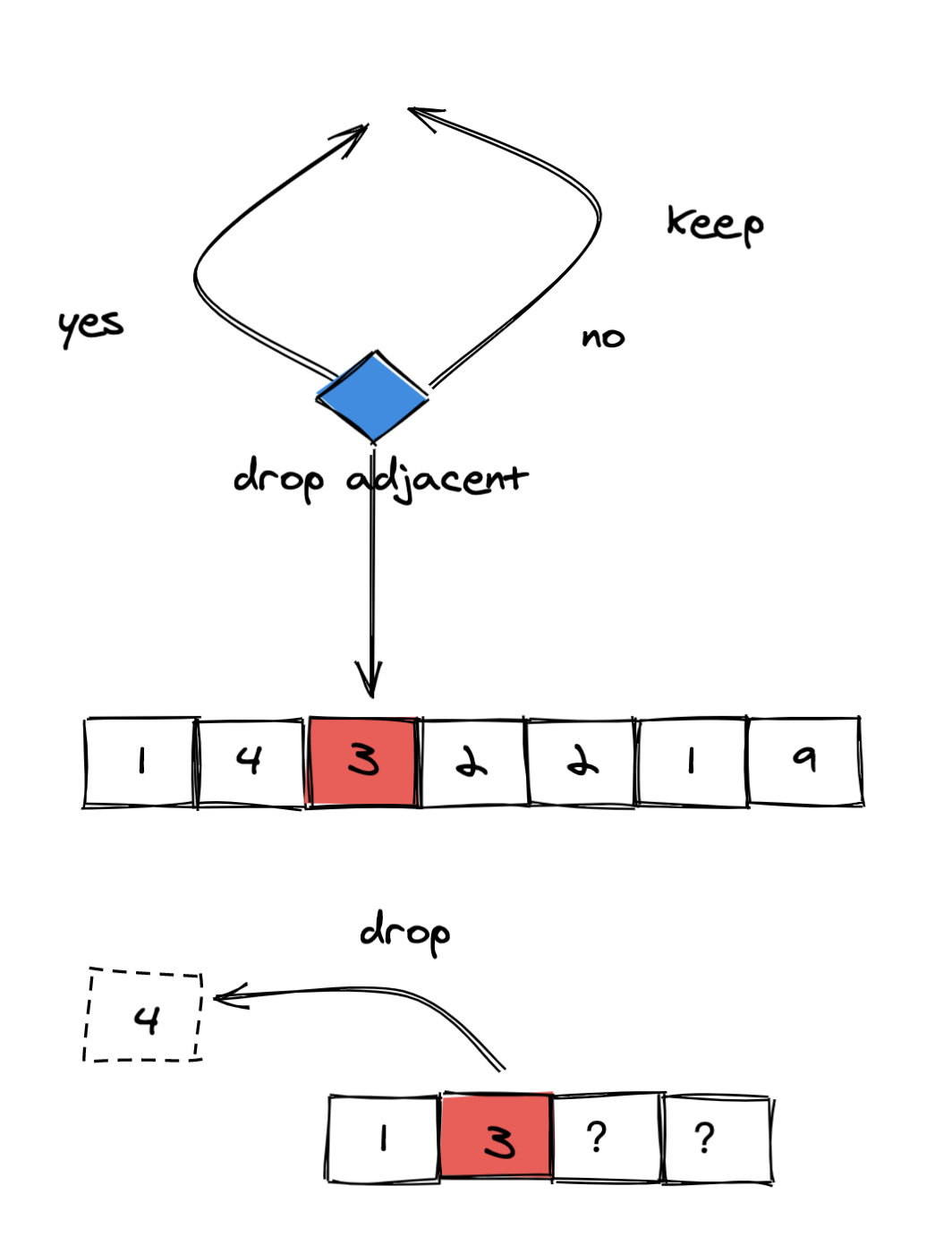
(图 4)
由于 3 比左侧相邻的 4 小。 如果选择丢弃左侧的 4,那么会使得剩下的数字更小(开头的数从 4 变成了 3)。因此我们选择丢弃。
。。。
后面的思路类似,我就不继续分析啦。
然而需要注意的是,如果给定的数字是一个单调递增的数字,那么我们的算法会永远选择不丢弃。这个题目中要求的,我们要永远确保丢弃 k 个矛盾。
一个简单的思路就是:
- 每次丢弃一次,k 减去 1。当 k 减到 0 ,我们可以提前终止遍历。
- 而当遍历完成,如果 k 仍然大于 0。不妨假设最终还剩下 x 个需要丢弃,那么我们需要选择删除末尾 x 个元素。
上面的思路可行,但是稍显复杂。

(图 5)
我们需要把思路逆转过来。刚才我的关注点一直是丢弃,题目要求我们丢弃 k 个。反过来说,不就是让我们保留 n−k 个元素么?其中 n 为数字长度。 那么我们只需要按照上面的方法遍历完成之后,再截取前n - k个元素即可。
按照上面的思路,我们来选择数据结构。由于我们需要保留和丢弃相邻的元素,因此使用栈这种在一端进行添加和删除的数据结构是再合适不过了,我们来看下代码实现。
代码(Python)
class Solution(object):
def removeKdigits(self, num, k):
stack = []
remain = len(num) - k
for digit in num:
while k and stack and stack[-1] > digit:
stack.pop()
k -= 1
stack.append(digit)
return ''.join(stack[:remain]).lstrip('0') or '0'复杂度分析
- 时间复杂度:虽然内层还有一个 while 循环,但是由于每个数字最多仅会入栈出栈一次,因此时间复杂度仍然为 O(N),其中 N 为数字长度。
- 空间复杂度:我们使用了额外的栈来存储数字,因此空间复杂度为 O(N),其中 N 为数字长度。
提示: 如果题目改成求删除 k 个字符之后的最大数,我们只需要将 stack[-1] > digit 中的大于号改成小于号即可。
316. 去除重复字母(困难)
题目描述
给你一个仅包含小写字母的字符串,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
示例 1:
输入: "bcabc"
输出: "abc"
示例 2:
输入: "cbacdcbc"
输出: "acdb"前置知识
- 字典序
- 数学
思路
与上面题目不同,这道题没有一个全局的删除次数 k。而是对于每一个在字符串 s 中出现的字母 c 都有一个 k 值。这个 k 是 c 出现次数 - 1。
沿用上面的知识的话,我们首先要做的就是计算每一个字符的 k,可以用一个字典来描述这种关系,其中 key 为 字符 c,value 为其出现的次数。
具体算法:
- 建立一个字典。其中 key 为 字符 c,value 为其出现的剩余次数。
- 从左往右遍历字符串,每次遍历到一个字符,其剩余出现次数 - 1.
- 对于每一个字符,如果其对应的剩余出现次数大于 1,我们可以选择丢弃(也可以选择不丢弃),否则不可以丢弃。
- 是否丢弃的标准和上面题目类似。如果栈中相邻的元素字典序更大,那么我们选择丢弃相邻的栈中的元素。
还记得上面题目的边界条件么?如果栈中剩下的元素大于 n−k,我们选择截取前 n−k 个数字。然而本题中的 k 是分散在各个字符中的,因此这种思路不可行的。
不过不必担心。由于题目是要求只出现一次。我们可以在遍历的时候简单地判断其是否在栈上即可。
代码:
Python
class Solution:
def removeDuplicateLetters(self, s) -> int:
stack = []
remain_counter = collections.Counter(s)
for c in s:
if c not in stack:
while stack and c < stack[-1] and remain_counter[stack[-1]] > 0:
stack.pop()
stack.append(c)
remain_counter[c] -= 1
return ''.join(stack)复杂度分析
- 时间复杂度:由于判断当前字符是否在栈上存在需要 O(N) 的时间,因此总的时间复杂度就是 O(N2),其中 N 为字符串长度。
- 空间复杂度:我们使用了额外的栈来存储数字,因此空间复杂度为 O(N),其中 N 为字符串长度。
查询给定字符是否在一个序列中存在的方法。根本上来说,有两种可能:
- 有序序列: 可以二分法,时间复杂度大致是 O(N)。
- 无序序列: 可以使用遍历的方式,最坏的情况下时间复杂度为 O(N)。我们也可以使用空间换时间的方式,使用 N的空间 换取 O(1)的时间复杂度。
由于本题中的 stack 并不是有序的,因此我们的优化点考虑空间换时间。而由于每种字符仅可以出现一次,这里使用 hashset 即可。
代码(Python)
Python
class Solution:
def removeDuplicateLetters(self, s) -> int:
stack = []
seen = set()
remain_counter = collections.Counter(s)
for c in s:
if c not in seen:
while stack and c < stack[-1] and remain_counter[stack[-1]] > 0:
seen.discard(stack.pop())
seen.add(c)
stack.append(c)
remain_counter[c] -= 1
return ''.join(stack)复杂度分析
- 时间复杂度:O(N),其中 N 为字符串长度。
- 空间复杂度:我们使用了额外的栈和 hashset,因此空间复杂度为 O(N),其中 N 为字符串长度。
LeetCode 《1081. 不同字符的最小子序列》 和本题一样,不再赘述。
321. 拼接最大数(困难)
题目描述
给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
示例 1:
输入:
nums1 = [3, 4, 6, 5]
nums2 = [9, 1, 2, 5, 8, 3]
k = 5
输出:
[9, 8, 6, 5, 3]
示例 2:
输入:
nums1 = [6, 7]
nums2 = [6, 0, 4]
k = 5
输出:
[6, 7, 6, 0, 4]
示例 3:
输入:
nums1 = [3, 9]
nums2 = [8, 9]
k = 3
输出:
[9, 8, 9]前置知识
- 分治
- 数学
思路
和第一道题类似,只不不过这一次是两个数组,而不是一个,并且是求最大数。
最大最小是无关紧要的,关键在于是两个数组,并且要求从两个数组选取的元素个数加起来一共是 k。
然而在一个数组中取 k 个数字,并保持其最小(或者最大),我们已经会了。但是如果问题扩展到两个,会有什么变化呢?
实际上,问题本质并没有发生变化。 假设我们从 nums1 中取了 k1 个,从 num2 中取了 k2 个,其中 k1 + k2 = k。而 k1 和 k2 这 两个子问题我们是会解决的。由于这两个子问题是相互独立的,因此我们只需要分别求解,然后将结果合并即可。
假如 k1 和 k2 个数字,已经取出来了。那么剩下要做的就是将这个长度分别为 k1 和 k2 的数字,合并成一个长度为 k 的数组合并成一个最大的数组。
以题目的 nums1 = [3, 4, 6, 5] nums2 = [9, 1, 2, 5, 8, 3] k = 5 为例。 假如我们从 num1 中取出 1 个数字,那么就要从 nums2 中取出 4 个数字。
运用第一题的方法,我们计算出应该取 nums1 的 [6],并取 nums2 的 [9,5,8,3]。 如何将 [6] 和 [9,5,8,3],使得数字尽可能大,并且保持相对位置不变呢?
实际上这个过程有点类似归并排序中的治,而上面我们分别计算 num1 和 num2 的最大数的过程类似归并排序中的分。
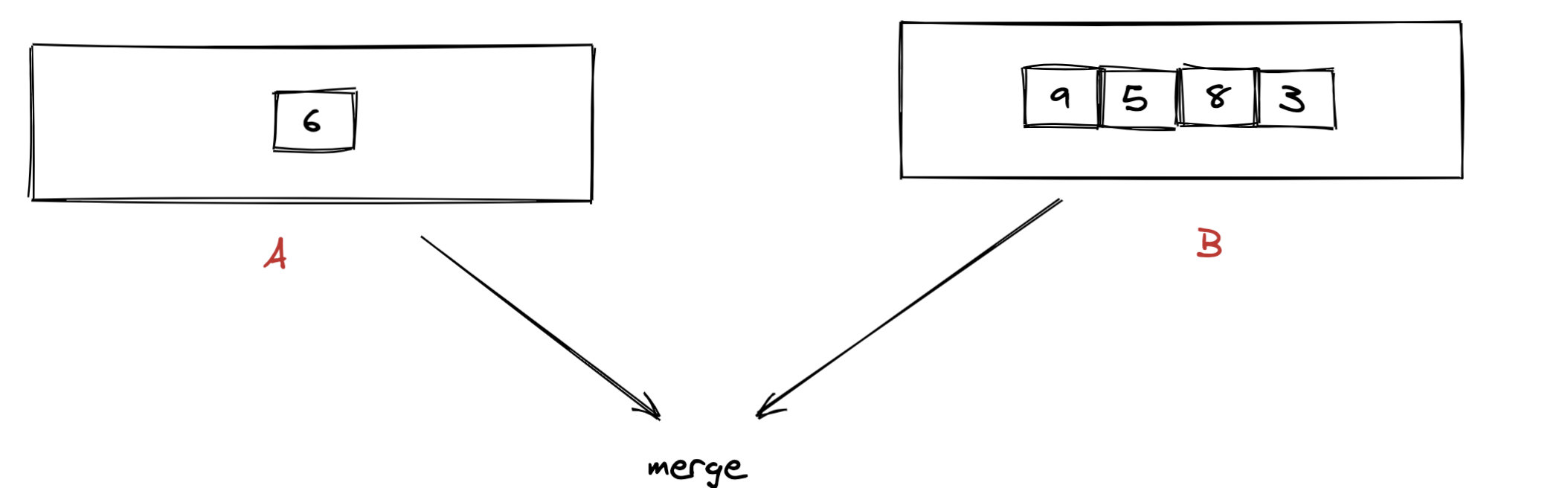
(图 6)
代码:
我们将从 num1 中挑选的 k1 个数组成的数组称之为 A,将从 num2 中挑选的 k2 个数组成的数组称之为 B,
Python
def merge(A, B):
ans = []
while A or B:
bigger = A if A > B else B
ans.append(bigger[0])
bigger.pop(0)
return ans这里需要说明一下。 在很多编程语言中:如果 A 和 B 是两个数组,当前仅当 A 的首个元素字典序大于 B 的首个元素,A > B 返回 true,否则返回 false。
比如:
A = [1,2]
B = [2]
A < B # True
A = [1,2]
B = [1,2,3]
A < B # False以合并 [6] 和 [9,5,8,3] 为例,图解过程如下:
(图 7)
具体算法:
- 从 nums1 中 取 min(i,len(nums1)) 个数形成新的数组 A(取的逻辑同第一题),其中 i 等于 0,1,2, ... k。
- 从 nums2 中 对应取 min(j,len(nums2)) 个数形成新的数组 B(取的逻辑同第一题),其中 j 等于 k - i。
- 将 A 和 B 按照上面的 merge 方法合并
- 上面我们暴力了 k 种组合情况,我们只需要将 k 种情况取出最大值即可。
代码(Python)
Python
class Solution:
def maxNumber(self, nums1, nums2, k):
def pick_max(nums, k):
stack = []
drop = len(nums) - k
for num in nums:
while drop and stack and stack[-1] < num:
stack.pop()
drop -= 1
stack.append(num)
return stack[:k]
def merge(A, B):
ans = []
while A or B:
bigger = A if A > B else B
ans.append(bigger[0])
bigger.pop(0)
return ans
return max(merge(pick_max(nums1, i), pick_max(nums2, k-i)) for i in range(k+1) if i <= len(nums1) and k-i <= len(nums2))复杂度分析
- 时间复杂度:pick_max 的时间复杂度为 O(M+N) ,其中 M 为 nums1 的长度,N 为 nums2 的长度。 merge 的时间复杂度为 O(k),再加上外层遍历所有的 k 中可能性。因此总的时间复杂度为 O(k2∗(M+N))。
- 空间复杂度:我们使用了额外的 stack 和 ans 数组,因此空间复杂度为 O(max(M,N,k)),其中 M 为 nums1 的长度,N 为 nums2 的长度。
总结
这四道题都是删除或者保留若干个字符,使得剩下的数字最小(或最大)或者字典序最小(或最大)。而解决问题的前提是要有一定数学前提。而基于这个数学前提,我们贪心地删除栈中相邻的字符。如果你会了这个套路,那么这四个题目应该都可以轻松解决。
316. 去除重复字母(困难),我们使用 hashmap 代替了数组的遍历查找,属于典型的空间换时间方式,可以认识到数据结构的灵活使用是多么的重要。背后的思路是怎么样的?为什么想到空间换时间的方式,我在文中也进行了详细的说明,这都是值得大家思考的问题。然而实际上,这些题目中使用的栈也都是空间换时间的思想。大家下次碰到需要空间换取时间的场景,是否能够想到本文给大家介绍的栈和哈希表呢?
321. 拼接最大数(困难)则需要我们能够对问题进行分解,这绝对不是一件简单的事情。但是对难以解决的问题进行分解是一种很重要的技能,希望大家能够通过这道题加深这种分治思想的理解。 大家可以结合我之前写过的几个题解练习一下,它们分别是:
- 【简单易懂】归并排序(Python)
leetcode 575 分糖果
Alice 有 n 枚糖,其中第 i 枚糖的类型为 candyType[i] 。Alice 注意到她的体重正在增长,所以前去拜访了一位医生。
医生建议 Alice 要少摄入糖分,只吃掉她所有糖的 n / 2 即可(n 是一个偶数)。Alice 非常喜欢这些糖,她想要在遵循医生建议的情况下,尽可能吃到最多不同种类的糖。
给你一个长度为 n 的整数数组 candyType ,返回: Alice 在仅吃掉 n / 2 枚糖的情况下,可以吃到糖的 最多 种类数。
示例 1:
输入:candyType = [1,1,2,2,3,3]
输出:3
解释:Alice 只能吃 6 / 2 = 3 枚糖,由于只有 3 种糖,她可以每种吃一枚。示例 2:
输入:candyType = [1,1,2,3]
输出:2
解释:Alice 只能吃 4 / 2 = 2 枚糖,不管她选择吃的种类是 [1,2]、[1,3] 还是 [2,3],她只能吃到两种不同类的糖。示例 3:
输入:candyType = [6,6,6,6]
输出:1
解释:Alice 只能吃 4 / 2 = 2 枚糖,尽管她能吃 2 枚,但只能吃到 1 种糖。题目背景
题目描述如下:给你 n 个糖果,每个糖果都有一个类型编号。你想把这些糖果分给两个朋友,每个朋友都要分到相同数量的糖果。你需要找出最多可以分给两个朋友的糖果种类数。
解题思路
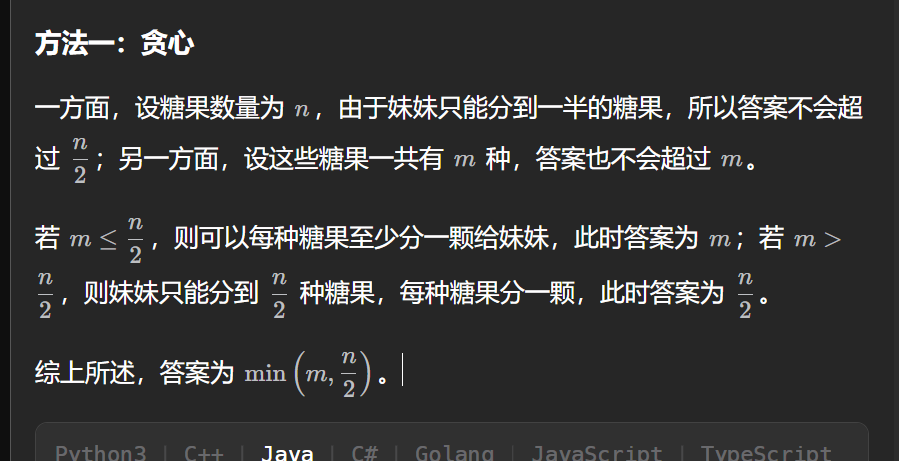
- 确定答案的上限:
-
- 由于每个朋友只能分到一半的糖果,因此答案不会超过
n / 2。 - 同时,答案也不会超过糖果的种类数
m。
- 由于每个朋友只能分到一半的糖果,因此答案不会超过
- 确定答案:
-
- 如果糖果的种类数
m小于或等于n / 2,那么每个朋友都可以至少分到一种糖果,答案为m。 - 如果糖果的种类数
m大于n / 2,那么即使每个朋友都分到不同种类的糖果,也只能分到n / 2种,答案为n / 2。
- 如果糖果的种类数
- 综合考虑:
-
- 答案为
min(m, n / 2)。
- 答案为
示例代码
下面是使用 Java 实现的解决方案:
import java.util.HashSet;
import java.util.Set;
class Solution {
public int distributeCandies(int[] candyType) {
Set<Integer> set = new HashSet<>();
for (int candy : candyType) {
set.add(candy);
}
return Math.min(set.size(), candyType.length / 2);
}
}解释
- 初始化集合:使用
HashSet来存储每种糖果的类型,自动去重。 - 遍历糖果数组:遍历
candyType数组,将每种糖果的类型加入到集合中。 - 计算答案:返回糖果种类数
set.size()和candyType.length / 2的较小值。
复杂度分析
- 时间复杂度:O(n),其中 n 是数组
candyType的长度。需要遍历整个数组。 - 空间复杂度:O(n)。最坏情况下,所有糖果都是不同种类,需要 O(n) 的空间来存储。
测试用例
public static void main(String[] args) {
Solution solution = new Solution();
// 测试用例 1
int[] candyType1 = {1, 1, 2, 2, 3, 3};
System.out.println(solution.distributeCandies(candyType1)); // 输出:3
// 测试用例 2
int[] candyType2 = {1, 1, 2, 3};
System.out.println(solution.distributeCandies(candyType2)); // 输出:2
// 测试用例 3
int[] candyType3 = {1, 1, 1, 1, 2};
System.out.println(solution.distributeCandies(candyType3)); // 输出:2
}这些测试用例覆盖了不同的情况,包括糖果种类少于或等于一半糖果数量的情况,以及种类多于一半糖果数量的情况。通过这些测试用例,可以验证算法的正确性。
class Solution {
public int distributeCandies(int[] candyType) {
Set<Integer> set = new HashSet<Integer>();
for (int candy : candyType) {
set.add(candy);
}
return Math.min(set.size(), candyType.length / 2);
}
}leetcode239 滑动窗口最大值
- 滑动窗口最大值
困难
相关标签
相关企业
提示
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
示例 1:
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
示例 2:
输入:nums = [1], k = 1
输出:[1]
提示:
1 <= nums.length <= 105
-104 <= nums[i] <= 104
1 <= k <= nums.length
239. 滑动窗口最大值(单调队列,清晰图解)

Krahets
解题思路:
设窗口区间为 [i,j] ,最大值为 xj 。当窗口向前移动一格,则区间变为 [i+1,j+1] ,即添加了 nums[j+1] ,删除了 nums[i] 。
若只向窗口 [i,j] 右边添加数字 nums[j+1] ,则新窗口最大值可以 通过一次对比 使用 O(1) 时间得到,即:
xj+1=max(xj,nums[j+1])
而由于删除的 nums[i] 可能恰好是窗口内唯一的最大值 xj ,因此不能通过以上方法计算 xj+1 ,而必须使用 O(j−i) 时间, 遍历整个窗口区间 获取最大值,即:
xj+1=max(nums(i+1),⋯,num(j+1))
根据以上分析,可得 暴力法 的时间复杂度为 O((n−k+1)k)≈O(nk) 。
- 设数组 nums 的长度为 n ,则共有 (n−k+1) 个窗口;
- 获取每个窗口最大值需线性遍历,时间复杂度为 O(k) 。

本题难点: 如何在每次窗口滑动后,将 “获取窗口内最大值” 的时间复杂度从 O(k) 降低至 O(1) 。
回忆 最小栈 ,其使用 单调栈 实现了随意入栈、出栈情况下的 O(1) 时间获取 “栈内最小值” 。本题同理,不同点在于 “出栈操作” 删除的是 “列表尾部元素” ,而 “窗口滑动” 删除的是 “列表首部元素” 。
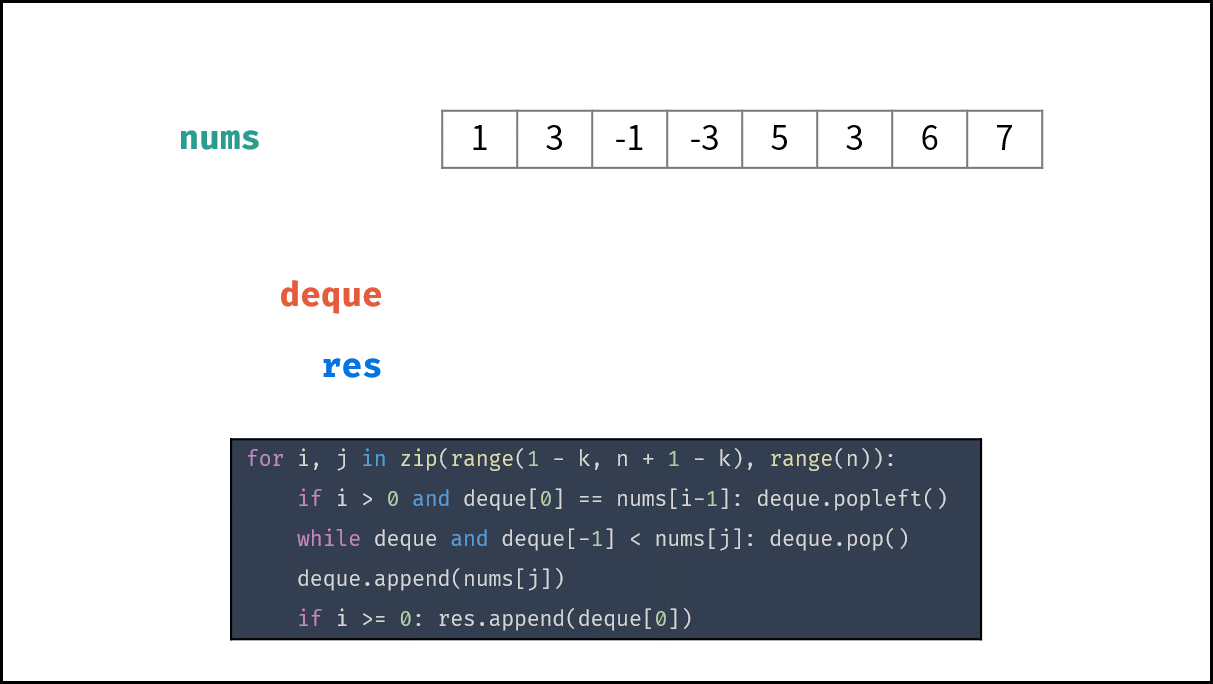
窗口对应的数据结构为 双端队列 ,本题使用 单调队列 即可解决以上问题。遍历数组时,每轮保证单调队列 deque :
- deque 内 仅包含窗口内的元素 ⇒ 每轮窗口滑动移除了元素 nums[i−1] ,需将 deque 内的对应元素一起删除。
- deque 内的元素 非严格递减 ⇒ 每轮窗口滑动添加了元素 nums[j+1] ,需将 deque 内所有 <nums[j+1] 的元素删除。
算法流程:
- 初始化: 双端队列 deque ,结果列表 res ,数组长度 n ;
- 滑动窗口: 左边界范围 i∈[1−k,n−k] ,右边界范围 j∈[0,n−1] ;
-
- 若 i>0 且 队首元素 deque[0] = 被删除元素 nums[i−1] :则队首元素出队;
- 删除 deque 内所有 <nums[j] 的元素,以保持 deque 递减;
- 将 nums[j] 添加至 deque 尾部;
- 若已形成窗口(即 i≥0 ):将窗口最大值(即队首元素 deque[0] )添加至列表 res ;
- 返回值: 返回结果列表 res ;
1 / 10
代码:
通过 zip(range(), range()) 可实现滑动窗口的左右边界 i, j 同时遍历。
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if(nums.length == 0 || k == 0) return new int[0];
Deque<Integer> deque = new LinkedList<>();
int[] res = new int[nums.length - k + 1];
for(int j = 0, i = 1 - k; j < nums.length; i++, j++) {
// 删除 deque 中对应的 nums[i-1]
if(i > 0 && deque.peekFirst() == nums[i - 1])
deque.removeFirst();
// 保持 deque 递减
while(!deque.isEmpty() && deque.peekLast() < nums[j])
deque.removeLast();
deque.addLast(nums[j]);
// 记录窗口最大值
if(i >= 0)
res[i] = deque.peekFirst();
}
return res;
}
}可以将 “未形成窗口” 和 “形成窗口后” 两个阶段拆分到两个循环里实现。代码虽变长,但减少了冗余的判断操作。
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if(nums.length == 0 || k == 0) return new int[0];
Deque<Integer> deque = new LinkedList<>();
int[] res = new int[nums.length - k + 1];
// 未形成窗口
for(int i = 0; i < k; i++) {
while(!deque.isEmpty() && deque.peekLast() < nums[i])
deque.removeLast();
deque.addLast(nums[i]);
}
res[0] = deque.peekFirst();
// 形成窗口后
for(int i = k; i < nums.length; i++) {
if(deque.peekFirst() == nums[i - k])
deque.removeFirst();
while(!deque.isEmpty() && deque.peekLast() < nums[i])
deque.removeLast();
deque.addLast(nums[i]);
res[i - k + 1] = deque.peekFirst();
}
return res;
}
}复杂度分析:
- 时间复杂度 O(n) : 其中 n 为数组 nums 长度;线性遍历 nums 占用 O(n) ;每个元素最多仅入队和出队一次,因此单调队列 deque 占用 O(2n) 。
- 空间复杂度 O(k) : 双端队列 deque 中最多同时存储 k 个元素(即窗口大小)。